

完整教程:论文串读--OpenAI-GPT系列1.2.3.4--大语言模型标准架构和预训练流程
写在前面
本文在机器学习、Transformer的基础上介绍了GPT系列模型的技术演进路线。具体基础在我的专栏机器学习和博客代表网络模型串讲中有涉及,本文中相关地方也有具体的transformer的理解示例。
GPT 的核心技术:Decoder-only Transformer一个就是,从GPT1-4一直沿用。在没有标号的的大量文本材料上训练一个语言模型来获得一个预训练模型,再在每个子任务上做微调。因为其本质自回归语言模型(Autoregressive LM)。不需要双向理解,不需要 seq2seq,只需要看前文 → 预测下文,因此只要 decoder。
BERT 是用Encoder-only Transformer,收集一个更大的数据集做预训练。适用于分类、句子关系、阅读理解等任务,是一个双向上下文理解模型。
如今的VLM主流是Encoder → Decoder架构,如BLIP、Qwen2-VL、LLaVA、MiniGPT-4和Encoder–Decoder + Decoder-only 混合架构,如Flamingo、Gemini。即现代 VLM 的视觉部分是 Encoder(如ViT,而非BERT),语言部分基本都是 Decoder(LLM),两者通过一个投影器或跨模态模块融合。
我学习的内容是论文、技术报告原文和李沐(link2gpt1-3)、朱毅(link2gpt4)老师的b站视频讲解。
目录
1.GPT
原论文《Improving language understanding by generative pre-training》
1.1.要解决的问题和方法概述
有标签的数据太少,很难训练出高质量的、针对具体任务的分类模型。
解决方法:先在没有标签的材料上训练一个语言预训练模型,再在有标签的子任务上训练一个分辨的微调模型。并且在微调时,构造和任务相关的输入,从而使得模型架构不需要大改。
核心:如何更好的利用无监督的文本并很好的迁移至下游任务?
- 当时效果最好的文本表示模型:词嵌入Word2Vec-- Word Embedding(浅层建模)。
- 当时的困难:
- 不知道用什么样的优化目标函数(一个目标函数只能针对相关度高的子任务)
- 不知道如何把学到的文本表示传递到下游的子任务上(没有一种简单统一的方式,使得一种表示能一致的迁移到所有的子任务上)
- 本文提出的方法:(原文中叫)一种半监督方法(现在在gpt和bert中叫自监督学习),在无标签的数据上训练一个大的语言模型,再在子任务上微调。模型架构基于Transformer(能抽取出句子和段落层面更好的语义信息,在迁移学习时学到的特征比RNN更稳健),并在迁移时利用任务相关的输入表示。
- 半监督Semi-Supervised:已有少部分labeled材料和大量的unlabeled但相似的数据,把高置信度预测作为“伪标签”继续训练。
- 自监督学习Self-Supervised Learning, SSL:用数据本身构造任务,让模型自己学习表示(表征),完全不需要人工标注。主流重建任务(MAE、BERT)、对比学习(CLIP)、生成式任务(GPT、VedioMAE)都用的自监督学习。
1.2.模型框架
1.2.1.预训练
给定一系列无监督的tokens{u1.u2…un},用一个标准的语言模型(用到的是Transformer-Decoder)建模最大似然函数,记作L1。
- 语言模型就是要预测第i个词出现的概率(L1:给一个序列预测序列中的下一个词)。
- Transformer-Decoder有掩码机制,所以不会看到再后面的词是谁。
- GPT 只用了 Decoder 的第一种注意力:Masked Multi-Head Self-Attention。
- 完全没有 Encoder,所以也不会有 Cross-Attention(从 Encoder 获取 K、V,用于翻译)。
- 每次用k(窗口大小,从神经网络的角度而言即输入序列的长度)个连续的词去预测第k+1个词是什么。
- 对每一个位置(每个i)取log,再求和,得到第一个目标函数,即这个文本出现的联合概率(最大概率输出和要的文本一样的一些文章)。
例:要生成“我下午要去操场跑步”这句话
模型训练时会(学会一个注意力模式):
- tokenizer 分词:["我", "下午", "要", "去", "操场", "跑步"]
- 在生成时,GPT 一开始只输入第一个 token:["我"],并且会加上词嵌入和位置编码。
- 第一轮的掩码多头注意力:
Query\Key | 我 |
|---|---|
我 | 1.00 |
- 第一个 token 没有历史,因而模型只能基于它自己的向量做预测。输出下一个词的分布概率。于是模型取概率最高的,(假设)如“下午”。
- 把生成的 token拼接到输入里,下一轮输入:["我", "下午"]
- 第二次 attention 中,“下午” 可以 attend 到 “我”,但“我” 不能 attend 到 “下午”(因为掩码)
- 重复进行 token-by-token 的自回归生成,举例(一个合理的)第四轮的注意力:
- 去” 主要 attend 到 “要”。
- 因果 mask 阻止它看到未来 token。
Query\Key | 我 | 下午 | 要 | 去 |
|---|---|---|---|---|
我 | 1.00 | 0.00 | 0.00 | 0.00 |
下午 | 0.55 | 0.45 | 0.00 | 0.00 |
要 | 0.20 | 0.50 | 0.30 | 0.00 |
去 | 0.10 | 0.30 | 0.50 | 0.10 |
- 训练时计算预测分布与真实答案的交叉熵损失,然后通过反向传播更新参数:
- attention 权重矩阵 Q、K、V
- 前馈网络 FFN
- embedding
- LayerNorm
- softmax 线性层
注意力不是“被模型使用的固定规则”,而是模型训练后学会的“有效的注意机制”。推理(生成)阶段才会用训练好的注意力来选择下一个 token。根据训练好的 Attention + FFN 计算输出 logits。
- 输入当前上下文,如 [“我 下午 要”],并转成embedding加位置编码
- 进入训练好的注意力层,注意力机制会:
- 让“要”关注“下午”和“我”
- 让“操场”关注“去”
- 等等
- 经过多个layer块,得到当前上下文的语义表示(hidden state),把上下文总结成一个高维向量:
- 当前语义
- 句子结构
- 下一步要说什么的线索
- Linear + Softmax → 得到下一个 token 的概率分布,随后模型选概率最高的(或采样一个)作为下一个 token。
1.2.2.微调(有监督)
对一组有标签的数据集C,包含了一系列的输入token{x1,x2…xm}和一个对应的标签y,每次给这一系列输入{x1,x2…xm}去预测标签y(的概率最标准的就是)。用预训练的最后一个transformer块的输出*参数W再Softmax。用到的分类目标函数,记作L2(L2:给完整的序列,预测序列对应的label)。
微调阶段的目标函数则为L2+a*L1,这两个目标函数一起训练训练效果是最佳的。
1.2.3.子任务的输入表示
目的是要把NLP中一些很不同的子任务表示成1.2.2.微调中所需的形式,即一系列token序列和该序列所对应的label。图1中左边是预训练模块和需要微调的部分,并在右边给了NLP四大最常见的应用(在所有任务中,label都是以正常的token形式输入的):
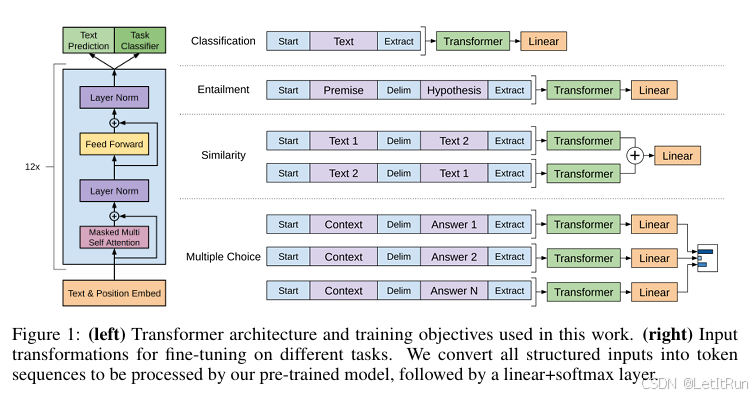
- 分类:给一句话或一段文本并判断他的label。把分类任务改写成“预测下一个 token”的生成任务。
- 在要分类的文字前面放一个初始的词元、在后面加一个抽取的词元。把这个序列放入Transformer-Decoder,并将最后一个词元的特征通过线性层投影到分类空间。
- 微调输入序列:[Start] Text tokens [Extract] Label
- 推理输入序列:[Start] Text tokens [Extract]
- 初始词元:<s>,自回归模型都需要一个开始位,且使不同任务输入保持统一格式。
- 抽取词元:<e>,prediction target position。微调训练时,Extract = 任务指示符(一个特殊的可训练token,告诉模型下一token是标签),Loss 仅在Label的位置(序列的最后一个 token)计算;推理时,模型在extract的下一个token处生成一组 logits → softmax → 分类结果。
- Decoder-only 模型不能有“空 token”作为占位符。
- 线性层投影:若做10分类任务,线性层输出大小就是10。
- 蕴含:给一段话,再给一段假设,判断前面这段话有没有蕴含假设所提出的内容。改写成给前提 Premise 和 假设 Hypothesis,预测这两句关系对应的标签 token。(其实也就是一个两段文本的多分类问题)
- 分隔符<$>
- 微调输入序列:[Start] Premise <Delim> Hypothesis [Extract] Label
- 推理输入序列:[Start] Premise <Delim> Hypothesis [Extract],同样,GPT 会在 Extract 后输出一组 logits。
- 在真实表达中,这些“符号”都不是用真实的这些单词放入--因为文本中可能也会出现这些单词,必须用特殊记号,通过微调的训练过程去认识这些符号标记。
- 相似:搜索词和文档 或 两个文档是否是相似的。改写成给定 “文本对(A,B)” → 预测一个 label token(如 same / different)相似的就是。(得到是否二分类问题)
- 相似是个对称的关系,但在语言模型中有先后顺序,所以做两个序列。第一个序列中第一段文字放在第二段文字前;第二个序列中第二段文字放在第一段文字前。仍然采用开始符、分隔符、抽取符。两段文字分别进入模型对两个方向输出 logits,两个方向的 logits 相加(或者平均)再进入线性层(不是做 embedding 相似度)。
- 多选:根据一个问题从几个答案中选出正确的那个。改写成对每个选项构造一句“挑战 + 选项 + Extract”,令模型预测 Extract 之后的 label token(correct/incorrect)。
- 有n个答案就构造n个序列,其中前半部分都是“问题”,后半部分都是“选项”。每个序列分别进入模型,线性投影层输出大小是1,即这个回答属于这个困难的置信度,最后做softmax。
V.S.相对较晚的BERT,bert 的训练过程中用了掩码mask。
1.3.实验
数据集:BooksCorpus -- 有7000篇没有被发表的书。
12层的transformer解码器,每一层维度768。
2.GPT-2
原论文《Language Models are Unsupervised Multitask Learners》语言模型是无监督的多任务学习器。
现在来看,是作为GPT到GPT-3(“大的统一的语言模型”)的过渡。
2.1.要解决的问题和方法概述
回应BERT(编码器)再更大的资料集使用更大的模型参数超越了GPT(解码器)的性能。并点出了Zero-shot的设定。
- 提升泛化性能:当时主流的途径是对一个任务收集一个信息集,并在上面训练模型做预测。说明当时的模型泛化性不佳。
- 多任务学习:在多个资料集上训练一个模型,并通过多个损失函数使同一个模型能够在多个任务上都能用。但在当时的NLP任务中用的并不多,当时的主流就是像GPT和BERT做预训练-有监督微调。问题:对于不同的任务还是需重新微调训练,且还是需要收集有标签的数据集。
本文提出的语言模型在做下游任务时,不需要下游任务的任何标注的信息,也不需要重新训练模型,只训练一个模型便在任何地方都能用。
2.2.模型途径
GPT-2和GPT在模型上基本上长得一样。区别在于主张不需要微调。创新点在于主张纯预训练即可 zero-shot 完成任务。
最主要贡献:由于没有微调环节了,而GPT-1中构造输入序列中用到的三种特殊符号都是在微调训练过程中让模型认识的。所以在构造下游任务的输入时就不能引入<开始符><分隔符><抽取符>了。---->推理时出现了Prompt的雏形,举例:
- 翻译任务的推理:序列可以被写作{translate to French, english text, french text}
- 阅读理解的推理:序列可以被写作{answer the question, document, question, answer}
- 训练阶段:不构造任务格式,完全照原始数据训练
推理过程能够这么构造“提示”的原因,作者认为:
- 通过模型本身足够强大,能够理解提示的意义和作用;
- 训练集足够大且在训练集文本中类似的话语也很常见,翻译任务例如表一:

- GPT-2 从这种真实文本中学(训练)到了“语言 A → 语言 B”的模式。所有“task format”都是从自然语言本身中学到的,而不是工程构造的。推理时仅靠 prompt(自然语言提示)即可工作。
- 对于推理阶段:只需要给一句 prompt,GPT-2 就能推断任务模式。这个“Translate to French:” 不需要是特殊 token,它就是普通文本 prompt。GPT-2 能理解它完全是因为它在训练过程中见过类似格式。
- 推理时,要将英语翻译成法语,构造{translate to French, english text},对于模型来说,要输出的下一个token就是这句话的法语。
2.3.实验
数据集:
- 当时通常使用是Common Crawl网页抓取爬虫项目,TB数量级,比较容易下载(Common Crawl - Registry of Open Data on AWS),但信噪比低质量不高;
- WebText-- 本文创新的数据集,有百万的文本,从Reddit(美国的一个新闻聚合网页)中爬取有至少3个“karma高质量评价”的帖子(4500w链接,中含800w文本,40GB的文字)。远大于之前工作的BooksCorpus和Wikipedia数据集。
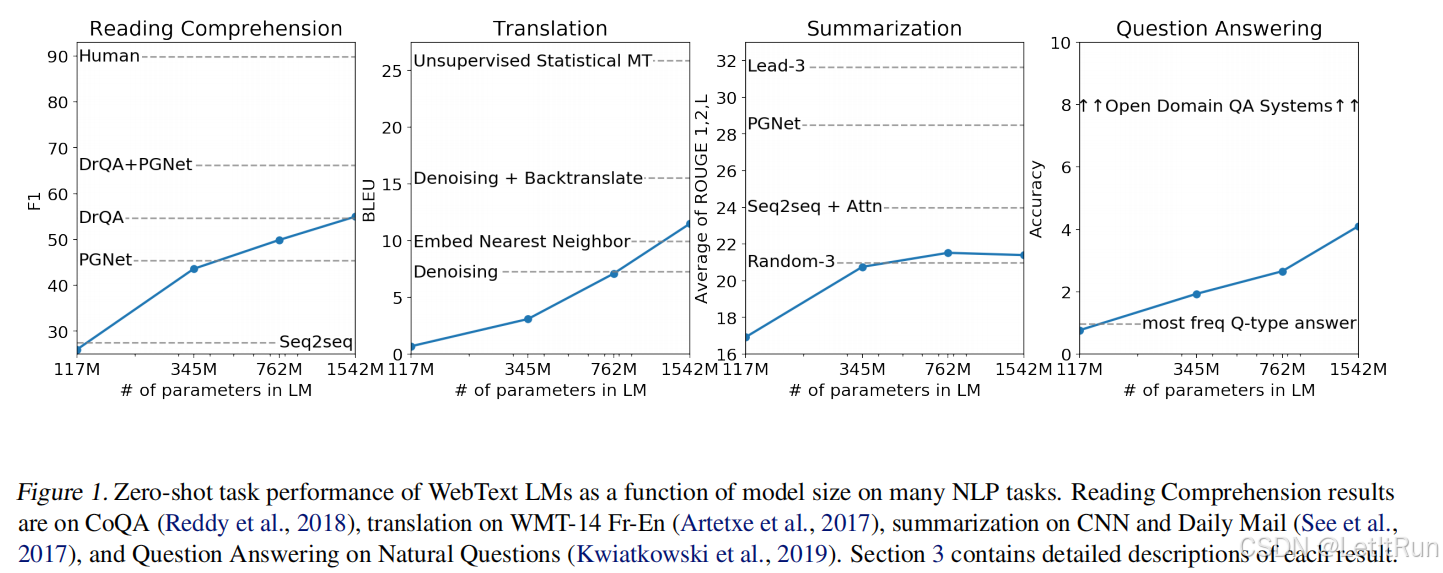
做大训练到了1.5B(15亿)个参数的Transformer,48层,1600维。(最小的12层,768维,117M个参数)。随着模型增大,性能上升,但距离有监督模型的SOTA结果还差了一点。
3.GPT-3
原论文《Language Models are Few-Shot Learners》
列举了目前所有基于GPT-3的一些应用:https://gpt3demo.com/,如GitHub-Copilot。
3.1.要消除的难题和方式概述
要克服GPT-2的有效性,又回到了GPT一开始考虑的few-shot设置,不再去追求很极致的子任务zero-shot。
因为模型更大了,若要对于每个子任务微调则成本更大了,所以它在每个子任务上同GPT-2,不做任何的梯度更新或微调。且性能远高于GPT-2。且用巨大的数据集达到所谓的zero-shot不能完全证明当前的大模型泛化能力好,说不定是在预训练时已经拟合过了类似当前需要推理的数据。
- 若微调(不是GPT-3用的),若使用batch size为1即每次用1个样本进行训练,因为有label就允许计算损失,反向传播对权重进行更新。微调的数据量要求<从0开始训练,且通常学习率能够设置的较小。
最主要贡献:正式取消微调(SFT),全面转向 Few-shot + Zero-shot。只依赖 pre-training + prompting。在无监督的预训练中通过SGD随机梯度下降来学习,能力来自元学习(meta-learning,本文新定义的)和上下文学习(in-context learning,也是本文新定义的)。
- 元学习:训练一个很大的模型,泛化性还不错。(在大量的、有多样性的段落的数据集上训练,从多个任务中总结学习的方法)
- 若是普通学习是“学会开车”,Meta-learning 是“学会快捷学会任何交通工具”。
- 上下文学习:在推理时即使做一些few-shot,也不更新预训练模型的权重,完全靠上下文示例引导行为。(在每一个段落中的训练,从上下文中来得到一些相关的信息)
3.2.模型方法
模型架构和GPT-2一样,但是用了Sparse Transformer做改进。
- Sparse Transformer,是一种让注意力不再对每个 token 都做全连接,而只关注“少量有意义的位置”的稀疏注意力机制。复杂度从普通注意力机制的O(n2)降至了O(nlogn),从而支持更长序列 + 更大模型。典型的稀疏注意力结构包括:
- 计算量对比:假设序列长度 = 4096,普通4096×4096=16,777,216计算量;稀疏4096×128=524,288计算量。
- 局部注意力(Local Attention):每个 token 只关注附近窗口(例如前后 128 个 token)。类似卷积,只看邻居,而不是全局。
- Strided Attention(跳跃式注意力):Strided Attention(跳跃式注意力)(例如步长=128)。带来一种“金字塔式”的全局视野。
- BigBird / Sparse Blocks(类似块状注意力):把序列分块,每个块内部自关注,并与少量全局位置连接。
- GPT-3 的最大模型(175B)在训练时使用了“局部稀疏注意力的组合”(并非单一种类),用于:
- 训练阶段优化计算速度
- 帮助更长的上下文(2048 tokens)
- 降低显存和 FLOPs 消耗
- GPT-3在推理阶段 并不依赖稀疏注意力结构。
采用三种设置:few-shot(10-100);one-shot;zero-shot。推理阶段输入的构造方法:
Zero-shot:类似GPT-2,如翻译,则构造{translate to French, english text =>},即 { 任务描述,任务 =>}。(箭头,告诉模型接下来该输出了)
One-shot:{translate to French, english example => french example, english text =>},即 { 任务描述,样 =>例,prompt =>}
上下文学习的体现:在前向推理时,能够从example中经过注意力机制抽取出有用的信息。
例如:
{ Translate to French:cat => chat
I am happy => }
第一步先将输入序列(所有字符) token 化,并构造 embedding;
继而注意力学习到“example pattern”,如“=>” 表示翻译关系;
预测第一个输出 token 的注意力示例(预测第一个法语token--Je时):
Key Token
注意力权重
说明
Translate
0.12
任务提示:翻译
to
0.03
附带
French
0.17
强信号:翻译成法语
:
0.01
标点
cat
0.05
示例英文
=>
0.03
示例箭头
chat
0.08
示例法语
I
0.20
需要翻译的句子开头
am
0.15
句子结构
happy
0.12
情感词,更接近法语输出
=>
0.04
当前箭头,标志翻译开始
模型强关注 French(17%)翻译就是→ 任务
强关注 I, am, happy(一起 47%)→ 提取要翻译的英文
中度关注 示例 cat/chat(13%)→ 提取“翻译模式”
剩下是结构词元
最终,经过 FFN + Linear + Softmax → 得到概率
预测第二个 token(例如 “suis”)注意力示例:
Key Token
注意力权重
说明
French
0.10
任务语言提醒
cat/chat
0.03 / 0.07
减弱但仍有结构参考
I
0.22
英语主语 → 法语主语
am
0.32
“am” 强影响“suis”
happy
0.06
还没到翻译它
=>
0.05
翻译开始标记
Je
0.15
当前生成序列
……GPT 的“In-context Learning” 本质是在 Attention 中自动形成的。
Few-shot,给更多的example。
后续还衍生出了模型上下文记忆等内容。
3.3.实验
训练数据:基于Common Crawl。先用GPT-2的数据集作为正类,过滤掉很负类即质量很低的数据;然后做去重(lsh算法,判断两个大的词的集合的相似度)。同时加入了BERT用到的维基百科数据集和GPT-2的数据集。在采样时按不同的采样率对不同的素材集进行采样,在每个batch中还是有41%的来自除CommonCrawl之外的高质量材料。总共将近5000亿个字。
1750亿个可学习的参数(比之前的非稀疏模型大10倍),分布式训练、模型分割和信息分割
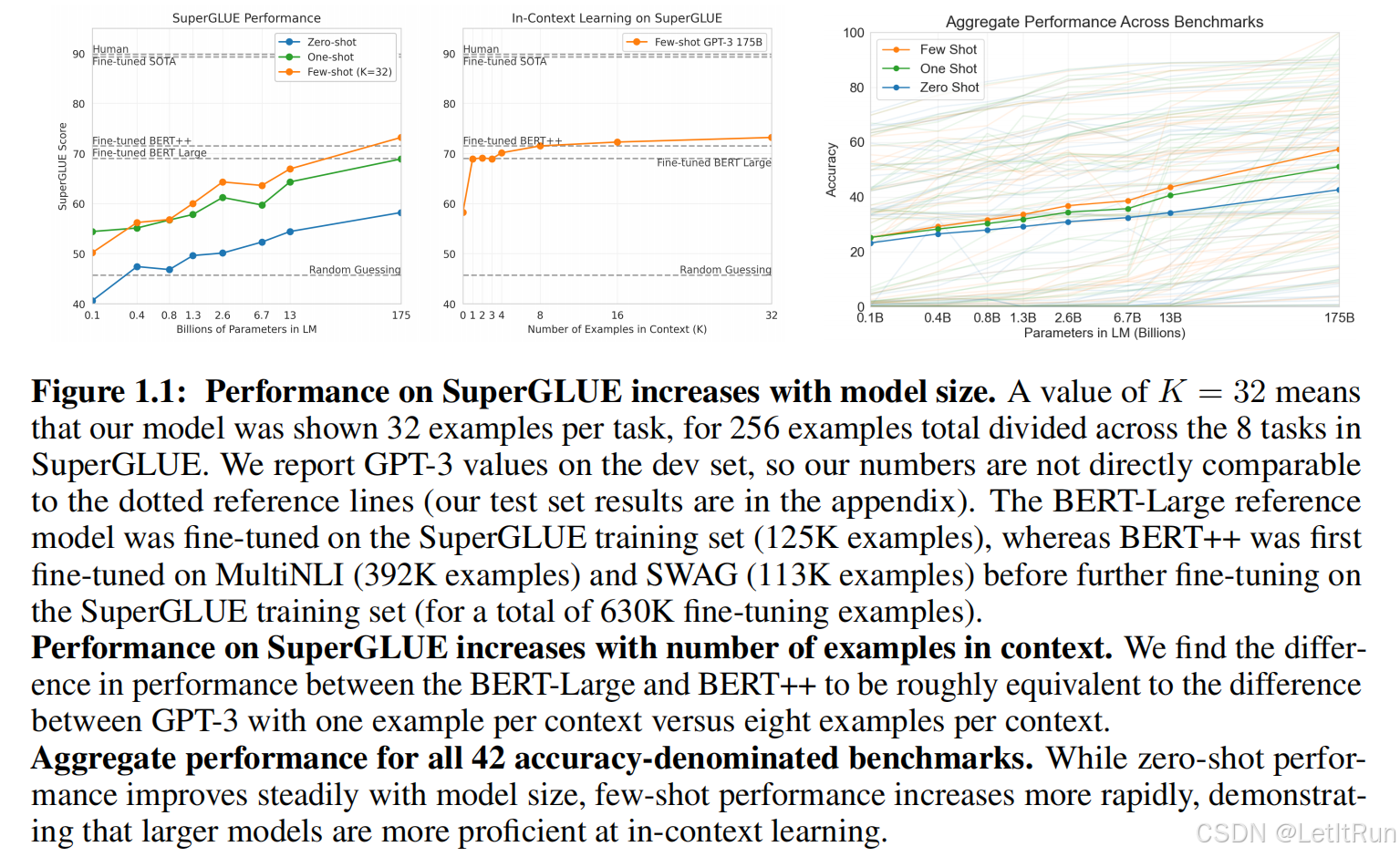
评估采用三种设置:few-shot(10-100);one-shot;zero-shot,最右图展示了三种设置(不同参数)下的效果(GPT-2约是1.3B,主打的zeroshot,30%;GPT-3是175B,主打的few-shot,60%):
3.4.评估
在每个下游任务中,在训练集中采样k个样本作为条件,
对于多选(多分类)”Answer: “或”A: ”(要干什么事情,样本,Answer:)。就是:prompt用的
对于二分类false。因为T/F在训练数据中出现的频率比0或1高。就是:答案要么是true要么
对于自由形式的答案(如做问答):采用Beam Search。
Beam Search 是“保留多个可能的候选序列,并从中选择整体概率最高的输出”的解码算法。他介于Greedy Search(只保留 1 个)和Exhaustive Search(保留所有可能)之间。
对于生成序列(自由回答的障碍来说),每个位置有成百上千个 token 候选。如果逐步贪心(Greedy)只选当前“最可能”的 token,可能全局不最优;如果全枚举,成本爆炸(指数级)。
核心思想:假设 beam size = 2,模型生成序列时,每一步
计算所有候选 token 的概率
扩展当前的 2 条候选序列
在所有扩展出的序列里选出概率排名前 2 的继续保留
重复直到结束 token(EOS)出现
终从完整序列里选出概率最高的一条作为输出。
例:beam size = 2,
假设模型第一次生成 token 的候选是:
token
概率
I
0.4(第一高,保留)
You
0.3(第二高,保留)
They
0.2
He
0.1
第二步扩展每个序列,假设第二个字预测如下(示例):
续写自
token
概率
序列总概率
I
am
0.5
0.4 × 0.5 = 0.20(第一高,保留)
I
was
0.1
0.4 × 0.1 = 0.04
You
are
0.4
0.3 × 0.4 = 0.12(第二高,保留)
You
were
0.2
0.3 × 0.2 = 0.06
继续生成第三个 token……,直到最终得到最高概率的,如I am happy.
结果好,且有些接近人类的感觉。对于翻译任务,别的语言翻到英语通常比英语翻到别的语言要好。
3.5.局限性
- 文本生成能力仍然不算强,尤其是对于长文本,没有一个“骨干向前推进的剧情”。
- 很均匀的去预测每一个词,包括一些毫无意义的虚词。没有重点。
- 没有其他模态,不知道物理真实的交互。
- 样本有效性不够。
- 不确定从训练集中找到了一个类似的就是对于prompt,是真的学到了prompt的模式还是只。
- 怎么做的,就是无解释性,关键决策会有瞎扯和幻觉。
- 具有社会责任感的讨论,社会危害、不实消息造假、偏见……
4.GPT-4
列举了目前所有基于GPT-4的一些应用:https://gpt4demo.com/
目前只有99页的技术报告,且其中很大篇幅都在讲实验效果,所以首要浏览了其技术博客。
4.1.模型概述
gpt4是一个多模态输入-文本输出的模型。
和之前的gpt系列一样,也是以预测下一个词(language modeling loss)的方式训练。并且,由于训练集的规模太大,难免有不正确的推理或数据,为了和人类的意图尽可能保持一致,就用RLHF(Reinforcement Learning with Human Feedback)做了微调。此外,GPT-4的贡献还在于提出了“可预测性扩展”。
- RLHF:作用不体现在模型性能,性能主要就是靠堆数据和算力。RLHF 的作用是让模型更能知道人类输入的意图,并按照人类喜欢的方式去做出回答。
- 具体InstructGPT《Training language models to follow instructions with human feedbacks》
- 可预测性扩展:解决“模型太大,不可能做大规模的调参。如何构建一个深度学习infra,并预测计算成本提升后的效果”。
- 用不同计算资源得出不同的loss,之后拟合曲线。
任务难度越增加,越能体现出GPT-4超越GPT-3.5的可靠性、创造力和能处理更加细微的人类的指示。
重新引入了有监督微调(SFT),但它不用于任务分类,而是用于:强化模型对齐(alignment),不是 GPT-1 那种任务式 label 预测。并且实现了通过小规模训练去预估计算成本扩大后模型能达到的效果。
4.2.视觉输入
只能看出性能好+包含OCR,但没说具体的多模态融合和如何输入。
4.3.可控性
用参数/第一句输入的prompt可以定义ai用什么语气语调来回答。--源自在prompt中加一些特殊的控制需求,gpt就能实现。
5.GPT1-4迭代脉络总结
GPT 首次提出 GPT 框架,“用 Transformer Decoder 做语言模型 + 用少量监督数据微调” + 特定的推理输入序列,并首次证明“无监督预训练 + 少量监督微调”可超越传统架构。
通过GPT-2 规模变大,提出“无监督多任务学习”,从“预训练 + 微调”转向“纯预训练即可结束任务”,结论是一个足够大的纯语言模型,能够不用微调,直接完成多种 NLP 任务。
一个强大的元学习器”,在gpt-2的基础上进一步提出 Few-shot / One-shot / Zero-shot 三种范式,基本沿用 GPT-2 的架构,只加入局部稀疏注意力以提升规模训练效率。获得跨任务的强泛化能力。就是GPT-3 规模变大,发现“语言模型本身
GPT-4 规模变大,从大语言模型 → 多模态通用智能的关键跨越,首次达成真正的“大规模多模态模型”,推理能力显著增强,安全性与 RLHF 大规模投入。
关键创新包括:始终采用自回归语言模型目标、逐步扩大模型规模、从单模态扩展到多模态、引入稀疏注意力优化计算效率。该系列发展展现了统一架构下,通过数据规模扩大和训练方法改进持续提升模型能力的路径,为现代大语言模型奠定了基础范式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号