
【每天一个AI小知识】:什么是生成式AI? - 指南

目录
5.1.1 GPT系列(Generative Pre-trained Transformer)
5.1.2 BART(Bidirectional and Auto-Regressive Transformers)
5.1.3 T5(Text-to-Text Transfer Transformer)
8.3 使用Hugging Face Transformers生成文本
9.1.1 BLEU(Bilingual Evaluation Understudy)
9.1.2 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
9.2.2 Fréchet Inception Distance(FID)
一、设计师小张的创意困境:从故事说起
小张是一家广告公司的平面设计师,最近接到了一个重要任务:为一款新上市的智能手表设计宣传海报。客户要求海报既要体现科技感,又要传达出时尚、年轻的品牌调性,而且希望能提供至少5套不同风格的设计方案。
小张感到压力很大,他需要在短时间内创作出大量创意素材,但灵感似乎总是来得很慢。就在他一筹莫展的时候,同事向他推荐了一个AI工具。小张半信半疑地尝试输入了几个关键词:"智能手表、科技感、时尚、蓝色调、年轻",没想到几秒钟后,AI就生成了几十张风格各异的海报设计稿。
小张惊喜地发现,这些设计稿不仅质量很高,而且涵盖了多种他自己可能想不到的创意方向。他从中挑选了几张最符合客户需求的设计,稍作修改后提交给了客户,客户对最终方案非常满意。
这个帮助小张解决创意困境的AI工具,就是生成式AI(Generative AI)的一种应用。生成式AI是当前人工智能领域最热门的技术之一,它正在改变我们创作内容、解决问题的方式。
二、生成式AI的基本概念
2.1 什么是生成式AI?
生成式AI是人工智能的一个分支,它专注于创建新内容而不是简单地分析或分类现有数据。这些内容可以是文本、图像、音频、视频、代码、3D模型等多种形式。
与传统的判别式AI(Discriminative AI)不同,生成式AI不是判断"这是什么",而是回答"这应该是什么样子"。例如,判别式AI可以识别一张图片是猫还是狗,而生成式AI可以根据描述"一只戴墨镜的橘猫在沙滩上晒太阳"创作出一张全新的图片。
2.2 生成式AI的分类
根据生成内容的形式,生成式AI可以分为以下几类:
- 文本生成:生成自然语言文本,如文章、诗歌、对话等
- 图像生成:生成图像、插画、设计稿等
- 音频生成:生成音乐、语音、音效等
- 视频生成:生成视频片段、动画等
- 代码生成:生成计算机代码
- 3D模型生成:生成3D物体模型
- 多模态生成:同时生成多种形式的内容,如根据文本生成图像和描述
2.3 生成式AI与其他AI技术的区别
| AI技术类型 | 核心任务 | 典型应用 | 代表算法 |
|---|---|---|---|
| 判别式AI | 分类、识别、预测 | 图像分类、语音识别、垃圾邮件检测 | CNN、RNN、SVM |
| 生成式AI | 创建新内容 | 文本生成、图像生成、音乐创作 | GAN、VAE、Transformer |
| 强化学习 | 学习最优策略 | 游戏AI、机器人控制 | DQN、PPO、AlphaGo |
2.4 生成式AI的基本原理
生成式AI的基本原理是学习数据的概率分布,然后从这个分布中采样生成新的内容。简单来说,就是让AI通过学习大量现有数据,理解数据的内在规律和模式,然后根据这些规律创造出新的、类似但又不完全相同的内容。
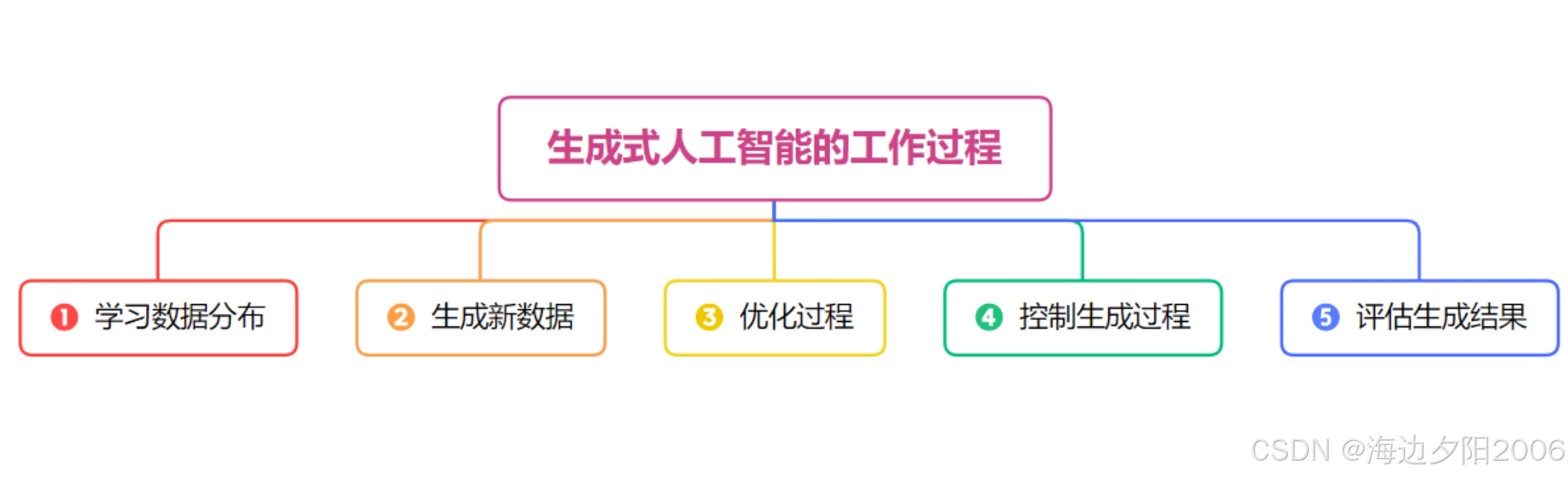
例如,一个文本生成模型通过学习大量小说、文章,理解语言的语法、词汇和写作风格,然后可以生成新的小说章节;一个图像生成模型通过学习大量图片,理解物体的形状、颜色、纹理和布局,然后可以生成新的图片。
三、生成式AI的发展历史
3.1 萌芽期(1950s-2000s)
生成式AI的概念可以追溯到人工智能的早期研究。
- 1950年:图灵提出了著名的"图灵测试",思考机器是否能表现出与人类相当的智能
- 1957年:乔姆斯基提出了生成语法理论,为自然语言生成奠定了理论基础
- 1960s:出现了最早的文本生成系统,如Eliza聊天机器人
- 1980s:隐马尔可夫模型(HMM)被应用于语音生成
- 1990s:生成对抗网络(GAN)的前身——对抗训练思想开始出现
- 2000s:变分自编码器(VAE)的理论框架逐渐形成
3.2 发展期(2010s)
深度学习的兴起为生成式AI带来了突破性进展。
- 2014年:Ian Goodfellow等人提出了生成对抗网络(GAN),这是生成式AI发展的里程碑
- 2015年:Google提出了WaveNet,用于生成高质量语音
- 2017年:Transformer架构的提出,为大型语言模型奠定了基础
- 2018年:OpenAI发布了GPT-1,这是第一个基于Transformer的大型语言模型
- 2019年:OpenAI发布GPT-2,展示了强大的文本生成能力
- 2019年:NVIDIA发布StyleGAN,能够生成高度逼真的人脸图像
3.3 爆发期(2020年至今)
生成式AI进入了爆发式发展阶段,各种强大的模型不断涌现。
- 2020年:OpenAI发布GPT-3,参数量达到1750亿,展示了惊人的文本生成和理解能力
- 2021年:OpenAI发布DALL-E,能够根据文本描述生成图像
- 2022年:OpenAI发布DALL-E 2,图像生成质量大幅提升
- 2022年:Stable Diffusion发布,这是第一个开源的高质量图像生成模型
- 2022年:Google发布Imagen,展示了强大的文本到图像生成能力
- 2022年:Meta发布OPT模型,这是一个开源的大型语言模型
- 2023年:OpenAI发布GPT-4,参数量和能力进一步提升
- 2023年:GPT-4V、Gemini等多模态模型发布,能够处理文本、图像、音频等多种输入
- 2023年:各种垂直领域的生成式AI模型不断涌现,如代码生成、3D模型生成等
四、生成式AI的核心技术原理
4.1 生成模型的基本框架
生成式AI的核心是生成模型,它的目标是学习数据的概率分布P(x),然后从这个分布中采样生成新的样本。根据建模方式的不同,生成模型可以分为以下几类:
4.1.1 基于 likelihood 的生成模型
这类模型直接对数据的概率分布进行建模,常见的有:
- 自回归模型(Autoregressive Models):如GPT系列,通过逐个生成元素(如单词、像素)来生成序列数据
- 变分自编码器(Variational Autoencoders,VAE):通过编码器将数据映射到潜在空间,然后通过解码器从潜在空间生成新数据
- 流动模型(Flow-based Models):通过一系列可逆变换将复杂分布转换为简单分布,然后通过逆变换生成新数据
4.1.2 基于对抗训练的生成模型
这类模型通过两个网络的对抗训练来生成数据,最著名的是:
- 生成对抗网络(Generative Adversarial Networks,GAN):包含生成器(Generator)和判别器(Discriminator)两个网络,生成器试图生成逼真的数据,判别器试图区分真实数据和生成数据
4.1.3 基于能量的生成模型
这类模型通过能量函数来建模数据的概率分布,常见的有:
- 玻尔兹曼机(Boltzmann Machines):基于统计力学的生成模型
- 受限玻尔兹曼机(Restricted Boltzmann Machines,RBM):玻尔兹曼机的简化版本
4.2 Transformer架构:生成式AI的核心
Transformer架构是当前生成式AI的核心技术之一,它由Google在2017年提出,最初用于机器翻译任务。Transformer的关键创新是自注意力机制(Self-Attention Mechanism),它能够捕捉序列数据中元素之间的长距离依赖关系。
Transformer架构主要由两部分组成:
- 编码器(Encoder):负责处理输入数据,提取特征表示
- 解码器(Decoder):负责生成输出数据,利用编码器的特征表示和自回归方式生成序列
GPT系列模型只使用了Transformer的解码器部分,而BERT等模型只使用了编码器部分。DALL-E、Stable Diffusion等图像生成模型也采用了Transformer架构或其变体。
4.3 预训练与微调
当前最强大的生成式AI模型大多采用预训练+微调的范式:
- 预训练:在大规模无标签数据集上训练模型,学习通用的知识和模式
- 微调:在特定任务的小数据集上对预训练模型进行微调,使其适应特定任务
这种范式的优点是能够充分利用大规模数据的信息,同时在特定任务上取得很好的性能。GPT系列、DALL-E、Stable Diffusion等模型都采用了这种范式。
五、生成式AI的主要模型与算法
5.1 文本生成模型
5.1.1 GPT系列(Generative Pre-trained Transformer)
GPT系列是OpenAI开发的大型语言模型,是当前最强大的文本生成模型之一。
技术特点:
- 基于Transformer解码器架构
- 采用自回归生成方式
- 参数量从GPT-1的1.17亿增加到GPT-4的万亿级别
- 能够生成高质量、连贯的文本
- 支持多轮对话、文本摘要、翻译等多种任务
应用场景:内容创作、对话系统、代码生成、教育辅导等
5.1.2 BART(Bidirectional and Auto-Regressive Transformers)
BART是Facebook开发的序列到序列生成模型,结合了BERT的双向编码和GPT的自回归生成能力。
技术特点:
- 基于Transformer编码器-解码器架构
- 采用去噪自编码器的训练方式
- 在文本摘要、机器翻译等任务上表现出色
应用场景:文本摘要、机器翻译、文本修改等
5.1.3 T5(Text-to-Text Transfer Transformer)
T5是Google开发的统一文本生成模型,将所有NLP任务都转化为文本到文本的形式。
技术特点:
- 基于Transformer编码器-解码器架构
- 统一的文本到文本框架
- 在多种NLP任务上表现出色
应用场景:问答系统、文本分类、文本生成等
5.2 图像生成模型
5.2.1 GAN系列
GAN是生成对抗网络的缩写,是图像生成领域的重要模型。
技术特点:
- 包含生成器和判别器两个网络
- 通过对抗训练提高生成质量
- 变体众多,如DCGAN、StyleGAN、BigGAN等
应用场景:图像生成、图像编辑、风格迁移等
5.2.2 DALL-E系列
DALL-E是OpenAI开发的文本到图像生成模型。
技术特点:
- 基于Transformer架构
- 能够根据文本描述生成高质量图像
- DALL-E 2支持图像编辑、扩展等功能
应用场景:创意设计、内容创作、视觉效果等
5.2.3 Stable Diffusion
Stable Diffusion是 Stability AI 开发的开源文本到图像生成模型。
技术特点:
- 基于扩散模型(Diffusion Models)
- 开源免费,可在本地部署
- 生成质量高,速度快
- 支持文本到图像、图像到图像等多种任务
应用场景:创意设计、内容创作、教育等
5.2.4 MidJourney
MidJourney是一个基于Discord的AI图像生成服务。
技术特点:
- 基于扩散模型
- 生成风格独特,艺术感强
- 通过Discord平台提供服务
应用场景:艺术创作、创意设计、概念设计等
5.3 音频生成模型
5.3.1 WaveNet
WaveNet是Google开发的语音生成模型。
技术特点:
- 基于扩张卷积神经网络
- 能够生成高质量、自然的语音
- 支持多种语言和说话人
应用场景:语音合成、虚拟助手、有声书等
5.3.2 Jukebox
Jukebox是OpenAI开发的音乐生成模型。
技术特点:
- 基于VQ-VAE和Transformer架构
- 能够生成不同风格、不同艺术家的音乐
- 支持歌词到音乐的生成
应用场景:音乐创作、游戏配乐、广告音乐等
5.4 多模态生成模型
5.4.1 GPT-4V
GPT-4V是OpenAI开发的多模态模型,支持文本和图像输入。
技术特点:
- 基于GPT-4架构扩展
- 能够理解图像内容并生成相关文本
- 支持图像描述、图像问答等任务
应用场景:图像理解、视觉问答、内容创作等
5.4.2 Gemini
Gemini是Google开发的多模态模型,支持文本、图像、音频、视频等多种输入。
技术特点:
- 基于Transformer架构
- 支持多种模态的理解和生成
- 在多模态任务上表现出色
应用场景:多模态内容创作、智能助手、教育等
六、生成式AI的工作流程
让我们以文本生成模型为例,了解生成式AI的基本工作流程:
- 数据收集:收集大规模的文本数据,如书籍、网页、文章等
- 数据预处理:对数据进行清洗、分词、编码等处理
- 模型架构设计:选择合适的模型架构,如Transformer
- 预训练:在大规模无标签数据上训练模型,学习语言的统计规律和知识
- 微调:在特定任务的数据集上对预训练模型进行微调
- 推理生成:输入提示(Prompt),模型生成相应的文本
- 后处理:对生成的文本进行过滤、编辑等处理
- 评估:评估生成文本的质量、连贯性、准确性等
- 部署:将模型部署到实际应用中
对于图像生成模型,工作流程类似,但数据和预处理步骤有所不同。
七、生成式AI的应用场景
生成式AI已经广泛应用于各个领域,让我们看看它的主要应用场景:
7.1 内容创作
- 文本创作:生成文章、诗歌、小说、广告文案等
- 图像创作:生成插画、设计稿、概念图、艺术作品等
- 音乐创作:生成背景音乐、歌曲、音效等
- 视频创作:生成短视频、动画、特效等
7.2 设计领域
- 平面设计:生成海报、Logo、宣传册等
- UI/UX设计:生成界面设计、原型设计等
- 产品设计:生成产品概念图、3D模型等
- 时尚设计:生成服装、配饰设计等
7.3 教育领域
- 个性化学习:生成定制化的学习材料、练习题目等
- 内容生成:生成教案、课件、教育视频等
- 语言学习:生成对话练习、翻译练习等
- 答疑解惑:作为智能 tutor 回答学生问题
7.4 商业与营销
- 广告创意:生成广告文案、广告图像、广告视频等
- 市场分析:生成市场报告、竞争对手分析等
- 客户服务:作为智能客服与客户对话
- 产品描述:生成产品说明、营销文案等
7.5 科技领域
- 代码生成:生成程序代码、API文档等
- 药物研发:生成新的分子结构、药物设计等
- 材料科学:生成新的材料配方、材料结构等
- 数据分析:生成数据分析报告、可视化内容等
7.6 娱乐领域
- 游戏开发:生成游戏角色、场景、剧情等
- 影视制作:生成特效、场景、角色等
- 虚拟偶像:生成虚拟人物、虚拟主播等
- 互动内容:生成互动故事、互动游戏等
7.7 医疗健康
- 医学图像生成:生成医学影像用于教学和训练
- 病例报告:生成标准化的病例报告
- 健康建议:生成个性化的健康建议
- 药物发现:生成新的药物分子
八、生成式AI的代码实现
8.1 使用OpenAI API生成文本
OpenAI提供了简单易用的API,可以方便地调用GPT系列模型生成文本。
import openai
# 设置API密钥
openai.api_key = "your-api-key"
# 定义生成文本的函数
def generate_text(prompt, model="gpt-3.5-turbo", max_tokens=100, temperature=0.7):
response = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=max_tokens,
temperature=temperature
)
return response["choices"][0]["message"]["content"]
# 使用示例
prompt = "写一首关于春天的短诗,要求语言优美,富有画面感"
poem = generate_text(prompt, max_tokens=200)
print("生成的诗歌:")
print(poem)8.2 使用Stable Diffusion生成图像
Stable Diffusion是开源的图像生成模型,可以在本地部署和使用。
from diffusers import StableDiffusionPipeline
import torch
# 加载模型
model_id = "runwayml/stable-diffusion-v1-5"
pipeline = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipeline = pipeline.to("cuda") # 如果有GPU的话
# 生成图像
prompt = "a beautiful sunset over the mountains, digital art, highly detailed"
image = pipeline(prompt).images[0]
# 保存图像
image.save("sunset_mountains.png")
print("图像生成完成,已保存为 sunset_mountains.png")8.3 使用Hugging Face Transformers生成文本
Hugging Face Transformers库提供了多种预训练的生成式模型。
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型和分词器
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 生成文本
prompt = "Once upon a time, in a magical kingdom,"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(
inputs["input_ids"],
max_length=100,
temperature=0.7,
top_p=0.95,
repetition_penalty=1.2,
do_sample=True
)
# 解码并输出结果
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("生成的故事:")
print(generated_text)九、生成式AI的评估指标
9.1 文本生成评估指标
9.1.1 BLEU(Bilingual Evaluation Understudy)
BLEU是评估机器翻译质量的指标,也用于评估文本生成质量。它衡量生成文本与参考文本之间的n-gram重叠程度。
计算公式:
其中,BP是 brevity penalty( brevity penalty),是n-gram的精确率,
是权重。
取值范围:0-1,分数越高表示生成质量越好。
9.1.2 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
ROUGE是评估文本摘要质量的指标,包括ROUGE-N、ROUGE-L、ROUGE-W等变体。
ROUGE-N:衡量生成文本与参考文本之间的n-gram召回率
ROUGE-L:衡量生成文本与参考文本之间的最长公共子序列(LCS)
ROUGE-W:带权重的LCS
取值范围:0-1,分数越高表示生成质量越好。
9.1.3 Perplexity(困惑度)
Perplexity是评估语言模型的指标,衡量模型预测下一个词的难度。
计算公式:
其中,N是序列长度,是模型预测第i个词的概率。
取值范围:大于等于1,分数越低表示模型性能越好。
9.2 图像生成评估指标
9.2.1 Inception Score(IS)
Inception Score是评估图像生成质量的指标,衡量生成图像的多样性和逼真度。
计算公式:
其中,x是生成图像,y是图像类别,KL是Kullback-Leibler散度。
取值范围:大于等于1,分数越高表示生成质量越好。
9.2.2 Fréchet Inception Distance(FID)
FID是评估图像生成质量的指标,衡量生成图像分布与真实图像分布之间的距离。
计算公式:
其中,和
分别是真实图像和生成图像的特征均值,
和
分别是真实图像和生成图像的特征协方差矩阵。
取值范围:大于等于0,分数越低表示生成质量越好。
9.2.3 CLIP Score
CLIP Score是评估文本到图像生成质量的指标,衡量生成图像与文本描述之间的相关性。
计算公式:
其中,是文本描述的嵌入向量,
是生成图像的嵌入向量。
取值范围:-1到1,分数越高表示生成图像与文本描述越相关。
十、生成式AI的挑战与解决方案
10.1 挑战一:生成内容的质量与可控性
问题:生成式AI有时会生成低质量、不准确或不符合要求的内容,而且难以精确控制生成内容的各个方面。
解决方案:
- 提高模型参数量和训练数据质量
- 采用更先进的模型架构和训练方法
- 引入人类反馈强化学习(RLHF)技术
- 开发更好的提示工程方法
- 增加生成过程中的控制机制,如条件生成、约束生成等
10.2 挑战二:数据隐私与版权问题
问题:生成式AI模型通常在大规模数据集上训练,这些数据可能包含隐私信息或受版权保护的内容。
解决方案:
- 采用隐私保护技术,如差分隐私、联邦学习等
- 对训练数据进行去标识化处理
- 建立数据使用的合规机制
- 开发基于少量数据或特定数据集的生成模型
- 探索生成式AI的版权归属问题
10.3 挑战三:偏见与公平性
问题:生成式AI模型可能会学习并放大训练数据中的偏见,导致生成内容存在性别、种族、文化等方面的偏见。
解决方案:
- 优化训练数据的多样性和代表性
- 开发偏见检测和缓解技术
- 在模型训练中引入公平性约束
- 建立多维度的评估体系,包括公平性评估
10.4 挑战四:计算资源需求
问题:大型生成式AI模型需要大量的计算资源进行训练和推理,这限制了模型的普及和应用。
解决方案:
- 开发模型压缩技术,如知识蒸馏、量化等
- 优化模型架构,提高计算效率
- 采用分布式训练和推理技术
- 开发轻量级的生成式AI模型
- 提供云服务,让用户无需拥有强大的计算资源即可使用生成式AI
10.5 挑战五:伦理与社会影响
问题:生成式AI可能会被用于生成虚假信息、深度伪造内容等,对社会造成负面影响。
解决方案:
- 开发内容检测技术,识别AI生成的内容
- 建立生成式AI的伦理准则和使用规范
- 加强法律法规建设,规范生成式AI的使用
- 提高公众对生成式AI的认识和理解
- 促进生成式AI的负责任创新和使用
十一、生成式AI的发展趋势
11.1 技术发展趋势
- 多模态融合:将文本、图像、音频、视频等多种模态融合到一个模型中,实现更自然、更丰富的生成能力
- 可控生成:提高生成内容的可控性,让用户能够更精确地控制生成内容的各个方面
- 小样本学习:减少模型对大规模数据的依赖,提高模型在小样本情况下的性能
- 轻量化模型:开发更轻量级、更高效的生成式AI模型,提高模型的普及度和应用范围
- 实时生成:提高生成速度,实现实时生成和交互
- 可解释性增强:提高生成式AI的可解释性,让用户了解模型生成内容的过程和依据
11.2 应用发展趋势
- 个性化服务:提供更加个性化的生成式AI服务,满足用户的特定需求
- 垂直领域深化:在各个垂直领域开发专用的生成式AI模型,如医疗、法律、教育等
- 协作式创作:人类与AI协作创作内容,发挥各自的优势
- 自动化程度提高:将生成式AI与其他技术结合,实现更高度的自动化
- 普及化应用:生成式AI将更加普及,成为人们工作和生活中的常用工具
11.3 社会影响趋势
- 工作方式变革:改变人们的工作方式,提高工作效率,创造新的工作岗位
- 教育模式创新:推动教育模式的创新,提供更加个性化、高效的教育服务
- 文化创作繁荣:促进文化创作的繁荣,丰富人们的精神生活
- 伦理法规完善:生成式AI的伦理准则和法律法规将不断完善
- 数字鸿沟挑战:需要关注生成式AI带来的数字鸿沟问题,确保技术的公平使用
十二、生成式AI的哲学思考
12.1 创造力的本质
生成式AI能够生成具有创造性的内容,这让我们重新思考创造力的本质。创造力是否仅仅是对现有知识和模式的组合和重组?人类的创造力是否有其独特的本质?
12.2 作者身份与版权
当AI生成了一篇文章、一幅画或一首音乐时,谁应该被视为作者?AI生成的内容是否应该受到版权保护?这些问题挑战了传统的版权观念。
12.3 真实性与虚假性
生成式AI能够生成高度逼真的虚假内容,这模糊了真实与虚假的界限。我们如何在AI生成内容日益普及的时代,辨别信息的真实性?
12.4 人类与机器的关系
生成式AI的发展改变了人类与机器的关系。AI不再仅仅是工具,而是成为了我们的合作伙伴和创意源泉。我们应该如何定义这种新的关系?
12.5 技术的责任与伦理
生成式AI的发展带来了一系列伦理问题,如隐私、偏见、公平性等。我们应该如何确保生成式AI的负责任发展和使用?技术开发者、使用者、政策制定者各自应该承担什么责任?
十四、结语
生成式AI是人工智能领域的重大突破,它正在改变我们创作内容、解决问题、与技术交互的方式。从文本生成到图像生成,从内容创作到科学研究,生成式AI已经渗透到我们生活的方方面面。
尽管生成式AI面临着诸多挑战,如内容质量、隐私保护、伦理道德等,但它的发展潜力是巨大的。随着技术的不断进步和应用的不断深化,生成式AI将为人类带来更多的便利和创新。
作为一项强大的技术,生成式AI的发展需要我们保持开放和谨慎的态度。我们应该积极探索生成式AI的潜力,同时认真应对它带来的挑战,确保技术的负责任发展和使用。
生成式AI的故事才刚刚开始,让我们一起见证和参与这个激动人心的技术革命!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号