


供应链计划系统架构实战(三):全球平台数据与实现难点分析
前两篇描写了系统的概述和核心业务的介绍,在全球化运营的背景下,一套高效的配件供应链计划系统已成为工程机械、高端制造等行业的核心竞争力。大家构建了一个覆盖全球的四级仓储网络,并辅以动态的储备策略。然而,支撑这一庞大网络的“大脑”——计划环境,在设计与实现过程中,遭遇了前所未有的技术挑战。本文将深入剖析其中四大核心计算难点。
一、亿级数据量的存储与计算挑战
全球业务的规模直接体现在数据量上,这绝非传统单体应用能够应对。
表:环境数据规模与挑战
数据类别 | 数据量级 | 具体说明 | 带来的挑战 |
物料主数据 | 2500万行 | 管理的SKU总量 | 数据关联查询性能低下 |
动销SKU | 200万个 | 实际有销售记录的SKU | 计算范围巨大 |
历史销量内容 | 600万行 | 历史交易记录 | 需求预测计算复杂 |
仓库节点 | 160+个 | 全球库存地点 | 网络关系复杂 |
OSBOM | 上亿行 | 主机bom清单 | 数据查询量大 |
过程/结果数据 | 超4亿行 | 6个月滚动计划产生的中间及最终材料 | 存储与计算效率的终极考验 |
架构解决方案:混合存储与分布式计算
- MySQL分库分表: 核心业务库(如MySQL)按仓库分表,支撑高并发交易。
- 多数据源引擎: 引入Apache Doris等分析引擎,卸载繁琐查询。
- 自研分布式框架: 克服核心计算效率问题
二、超级复杂供应网络—递归计算逻辑
补货计划并非独立计算每个仓库,而是从网络最末端向前端逐级汇总,这是一个典型的递归过程。
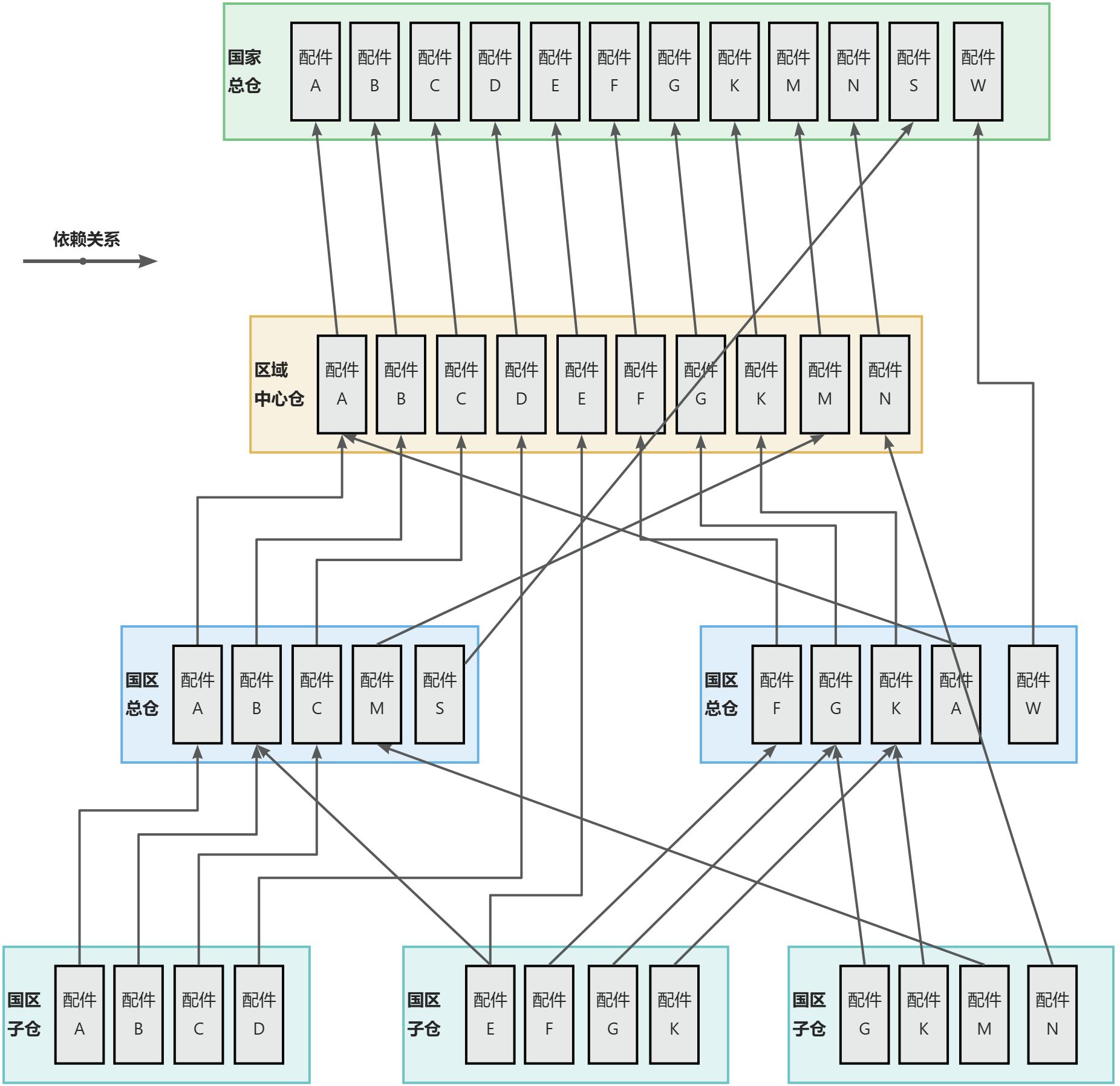
如上图所示,仓库之间有依赖关系,上游仓库计算必须依赖下游关系的计算结果,这是一个典型的递归场景,且全球160+仓库+200wSKU之间实际构成的一个依赖关系,远远超过上图示例的复杂度,常常有7-8层深度的一个依赖结构。假如使用递归算法去进行计算,这个算法不仅占用时间很长,对系统资源的要求也特别高。
计算算法:SKU依赖抽象树结构,递归转化成逆向计算。
三、超长的计算链路
计算链路覆盖数据中台与系统计算逻辑
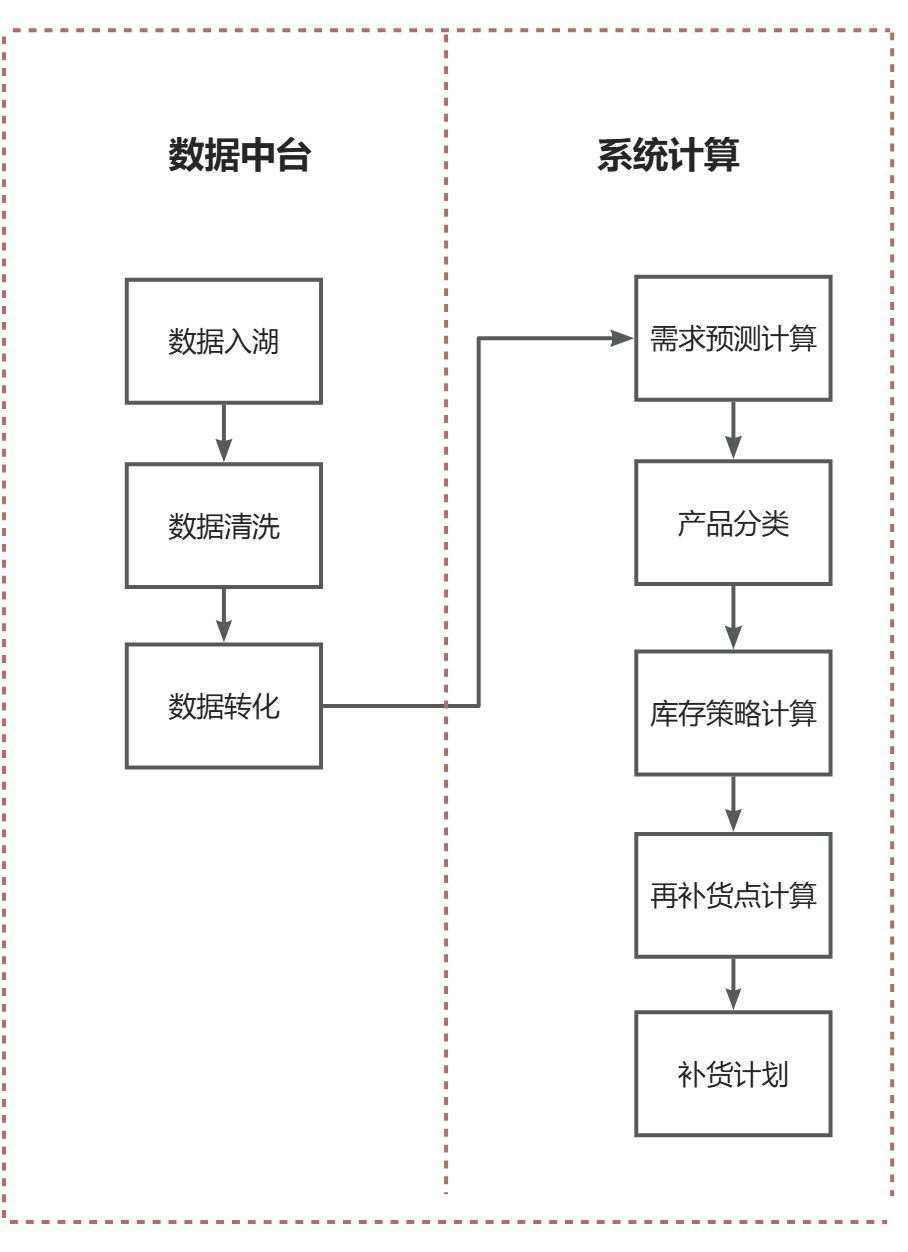
如图所示:计算链路比较长,且每一步都涉及到了超大量的数据处理与计算逻辑。每个仓库的计算流程都如图所示,需求比较复杂。
四、跨时区协同难题
当系统得在同一业务时点(如全球日终)为全球仓库进行计算时,物理时区的不同带来了巨大挑战。
表:全球仓库时区与计划窗口冲突示例
仓库节点 | 所在时区 | 物理时间 (当UTC为0:00) | 计划触发本地时间 | 挑战 |
上海总仓 | CST (UTC+8) | 08:00 AM | 02:00 AM | 无冲突,业务低峰期 |
欧洲中心仓 | CET (UTC+1) | 01:00 AM | 02:00 AM | 无冲突,业务低峰期 |
美国中心仓 | PST (UTC-8) | 04:00 PM (前一天) | 02:00 AM | 严重冲突,正值下午运营高峰 |
每个时区的计划员上班时间都不一致,且所有计划都必须在计划员上班之前就抛出相应的计划结果,这对系统本身来说也是一个挑战。
总结
上述四点都是技术上所会碰到的难题。实际上来说,除了工艺上碰到的难题,业务上需要解决的难题也不在少数,下列列举一下其他方面的一些难题。
难点类别 | 核心挑战 | 关键克服思路 |
数据与业务 | 信息质量、预测判断、合规 | 主素材治理、算法优化与业务反馈制度 |
软性挑战 | 系统灵活性、人的接受度 | 高度参数化、用户共创 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号