


43、【Ubuntu】【Gitlab】拉出内网 Web 服务:静态&动态服务 - 详解
【声明】本博客所有内容均为个人业余时间创作,所述技巧案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技能,如有侵权请联系删除
背景
上篇 blog
【Ubuntu】【远程开发】拉出内网 Web 服务:后台运行(三)
初步讲了如何从内网拉出由 Sphinx 构建出的静态 HTML,结合之前 blog
【Ubuntu】【GitLab】局域网用 Ubuntu 搭建 GitLab
最开始搭建的局域网代码托管平台 Gitlab,下面将详细分析 Gitlab 的内网拉出过程
静态&动态服务
在拉出 Gitlab 内网服务前,首先回顾下之前用 Sphinx 配合 python http.server 的构建命令
python -m http.server 8000在这里,Python 将启动一个非常简单的 HTTP静态文件服务器,该服务器会:
- 把当前目录当作网站根目录
- 对请求的路径(比如
/index.html)直接映射到本地文件系统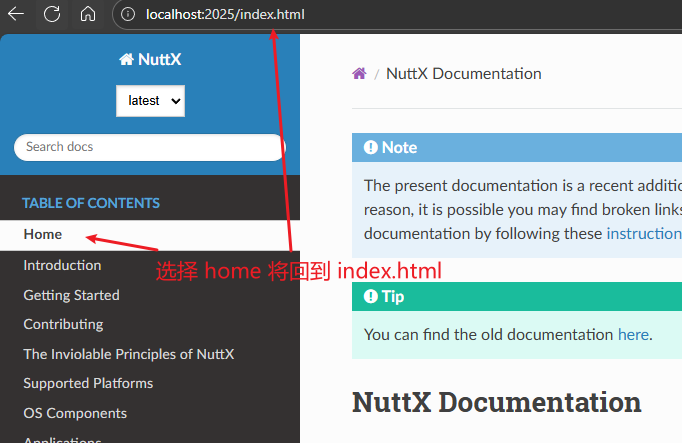
- 这种服务器不执行任何后端逻辑,只提供静态资料,适合用来临时预览静态
HTML文件,比如这里的 Sphinx 打包构建后的产物
所以总结一下,Sphinx 构建打包成功后,会生成一个完整的纯静态网站(从服务器上看就是一个文件夹),里面存放着包括 index.html,*.css,*.js,图片等资源,内部链接都是相对路径或绝对路径(相对于站点根),这些文件不需要服务端处理,只要能通过 HTTP 正确返回文件内容即可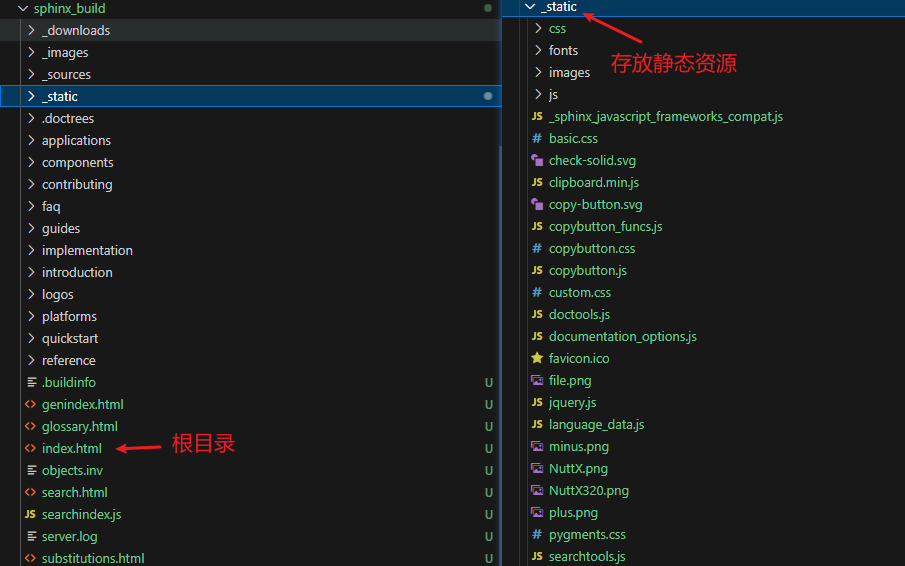
这里的静态网站指的是一堆预先写好的 HTML,*.css,*.js,图片等文件,服务器直接原样返回给浏览器,不做任何修改或计算,比如用户访问 Sphinx 构建好的网站 http://ServerIp:ServerPort/index.html,服务器会直接把 index.html 文件内容发过去,这期间
- 没有数据库查询;
- 没有用户登录状态判断;
- 没有根据用户不同显示不同内容(除非用前端 JS 动态处理)
也就是内容在服务器上是提前准备好,固定不变,无需服务器计算的,不会因为谁访问,什么时候访问而改变
OK,分析完 Sphinx 构建的静态内容,下面再来看下动态与之的区别
- 内容生成时机:静态网站是构建时提前生成好,而动态网站是用户访问时实时生成
- 后端程序:静态网站不需要后端代码,只要把对应位置的文件内容返回即可,而动态网站则应该后端程序,比如 Ruby,Node.js 等
- 数据库依赖:静态网站不需要依赖数据库,其内容来源于目录下的文件,而动态网站通常需要数据库,用来存储一些结构化的,可变的数据,比如用户信息,内容数据,交互内容,日志等
- 响应速度:静态网站直接返回记录,响应很快,而动态网站相对较慢,基于要计算,查库
- 典型例子:静态网站如 Sphinx 文档,博客,企业官网等,而动态网站如 GitLab,淘宝,微信,知乎等涉及内容交互的
对于 GitLab 来说,典型的动态网站就是GitLab 提供的 Web 服务,比如
- 浏览器发送请求到内网中的 GitLab 服务器
- 否已登录,权限如何,然后接着查询数据库,查看这个项目下的文件,以及最近的提交都有哪些就是GitLab 后端(Ruby)收到请求后,第一查看用户是谁,
- 收集完这些信息,再动态拼接处一个 HTML 页面,最后把这个页面返还给用户
可以看到,GitLab 的网页内容是和用户有交互,动态生成的,而不是提前写死的 HTML 文件,所以后面分析的,会和之前 Sphinx 构建的静态网站有所区别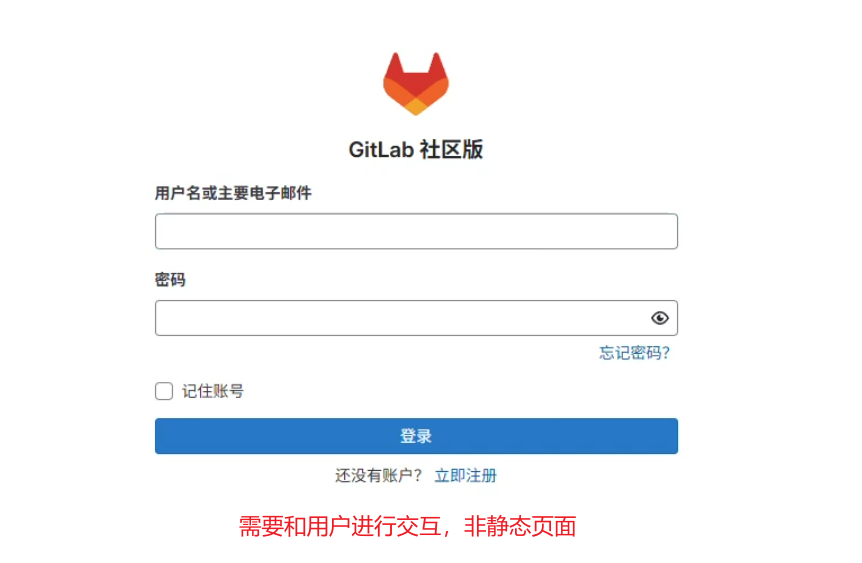
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog
【Ubuntu】【Gitlab】拉出内网 Web 服务:http.server 分析(一)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号