


深入解析:揭秘 CANN “黑科技”:在智能安防视频分析场景的落地实践
本文以城市级智能安防视频分析项目为背景,聚焦 2 万路监控视频实时检测、异常行为识别等核心需求,深度拆解华为 CANN 异构计算架构的落地实践。针对传统 CPU+GPU 方案存在的性能瓶颈、高成本、开发复杂等痛点,详细阐述 CANN 通过 ATC 模型转换优化、自定义算子开发、精细化资源调度三大核心能力,实现从模型训练到边缘推理的全流程高效落地。实践表明,基于 CANN+Atlas 硬件的解决方案,将单路视频分析延迟从 800ms 降至 180ms,单设备支持视频路数提升 7.4 倍,硬件成本直降 88%,模型部署周期从 2 周缩短至 4 小时。该案例不仅验证了 CANN 在释放硬件潜能、简化 AI 开发中的技术价值,也为智能安防及同类高并发、低延迟 AI 场景提供了可复制的异构计算落地路径。

一、行业背景与场景价值
智能安防作为智慧城市建设的核心基础设施,正从传统的“被动监控”向“主动预警”演进。据《2025年全球智能安防市场报告》显示,全球智能安防市场规模已突破千亿美元,其中视频分析占比超60%。在国内,以“雪亮工程”“天网工程”为代表的城市级监控系统,对视频分析的实时性、准确性、规模化提出了前所未有的要求。
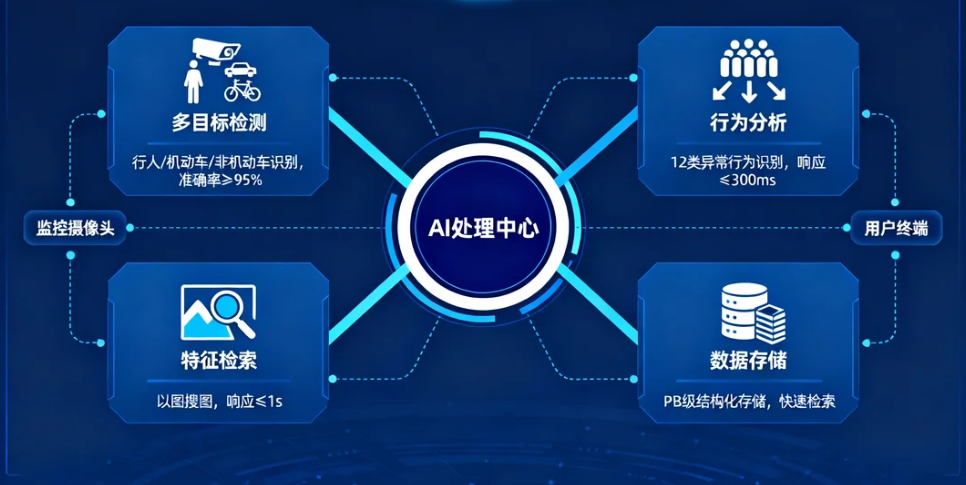
某新一线城市的“城市智能安防大脑”项目,计划对全市2万个监控点位(涵盖交通路口、商业中心、工业园区等场景)的视频流进行实时分析,需实现:
- 多目标检测:同时识别行人、机动车、非机动车,准确率≥95%;
- 行为分析:识别打架斗殴、异常聚集、车辆逆行等12类异常行为,响应时间≤300ms;
- 特征检索:支持对特定目标的以图搜图,检索响应时间≤1s;
- 数据存储:对分析结果进行结构化存储,支持PB级数据的快速检索。
传统技术路线(CPU+GPU)在该场景下面临的核心困境:
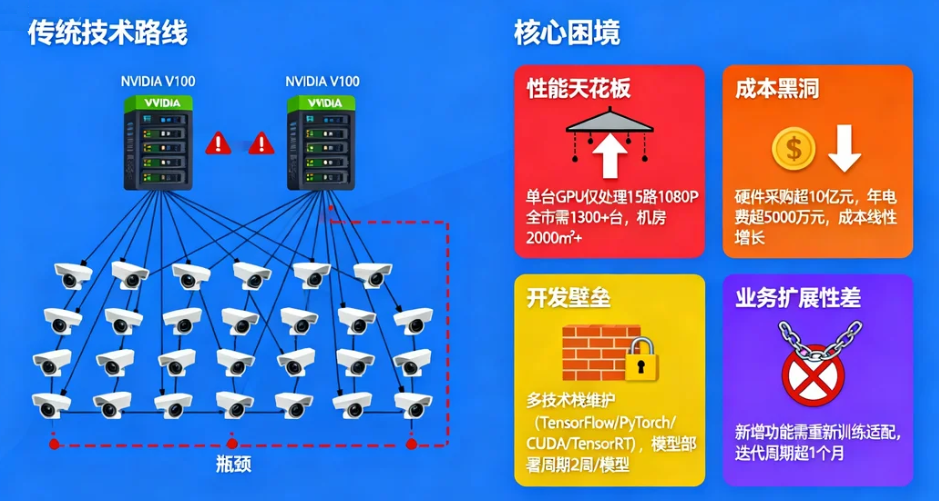
- 性能天花板:单台GPU服务器(NVIDIA V100)仅能处理15路1080P视频的实时分析,全市部署需1300+台服务器,机房面积超2000㎡;
- 成本黑洞:硬件采购成本超10亿元,年电费超5000万元,且随着视频路数增加,成本呈线性增长;
- 开发壁垒:算法团队需同时维护TensorFlow、PyTorch、CUDA、TensorRT等多套技术栈,模型从训练到部署的周期长达2周/模型;
- 业务扩展性差:新增异常行为分析功能时,需重新训练模型并适配所有硬件,迭代周期超1个月。
华为CANN(Compute Architecture for Neural Networks)的出现,为该场景提供了端云一致的异构计算解决方案。通过对AI芯片、编译器、运行时的软硬自研优化,CANN能够充分释放Atlas系列硬件的计算潜能,同时大幅简化AI应用的开发流程。本项目作为CANN在智能安防领域的标杆落地案例,其技术实践和业务价值具有极强的行业借鉴意义。
二、技术架构与CANN软硬自研能力
2.1 系统架构全景
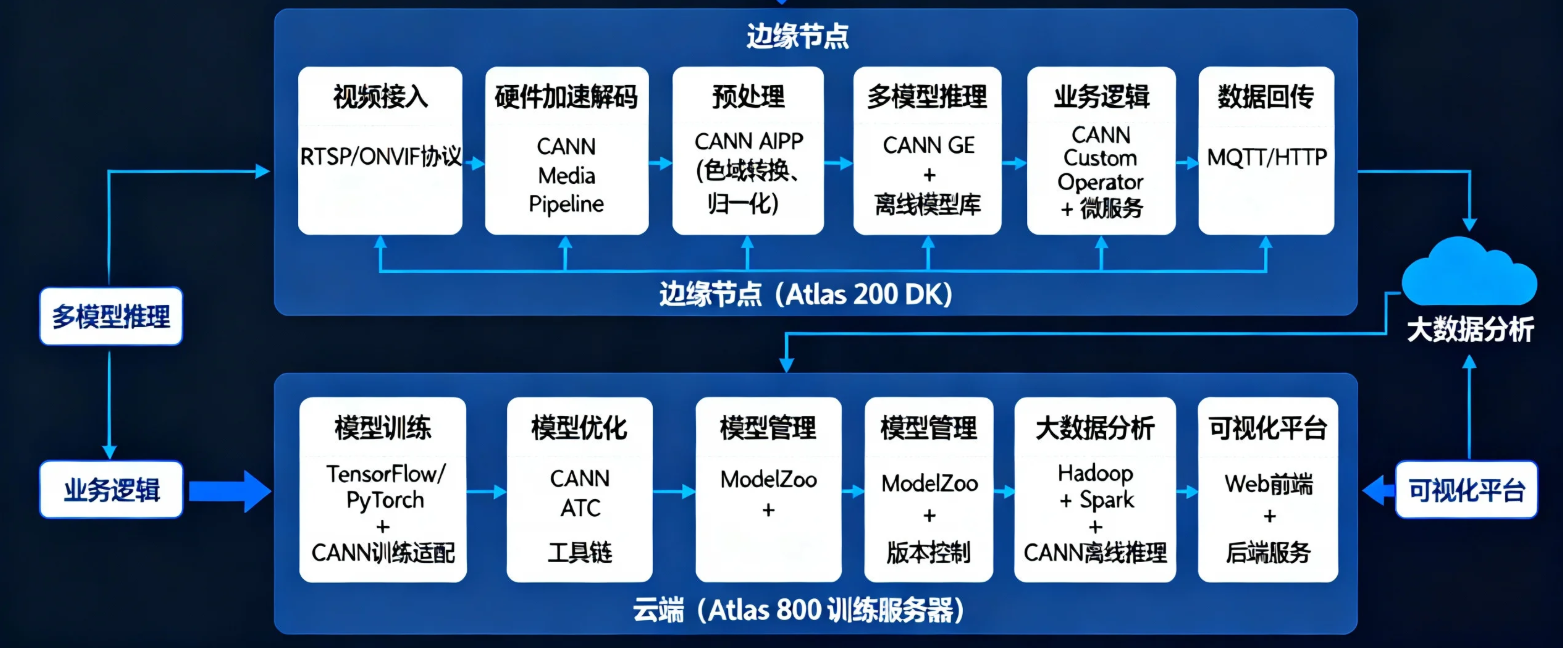
该架构的核心设计理念是“边缘推理+云端训练”的协同模式:
- 边缘侧(Atlas 200 DK)承担实时视频分析任务,利用CANN的硬件加速能力实现低延迟推理;
- 云端(Atlas 800)承担模型训练和大数据分析任务,利用CANN的训练加速能力缩短模型迭代周期。
2.2 CANN核心组件与技术原理
CANN作为面向AI场景的异构计算架构,其核心组件包括:
- ATC(Ascend Tensor Compiler):模型转换与优化工具,支持将TensorFlow、PyTorch等框架的模型转换为Atlas硬件可执行的离线模型(.om格式)。
- GE(Graph Engine):图引擎,负责对AI计算图进行优化(如算子融合、内存优化)和执行调度。
- AIPP(AI Preprocessing):AI预处理模块,支持在硬件上对输入数据进行预处理(如归一化、色域转换),减少CPU开销。
- Media Pipeline:媒体处理流水线,支持硬件加速的视频解码、编码和图像处理。
- Custom Operator:自定义算子开发框架,支持开发者根据业务需求开发高性能算子。
CANN的技术优势源于其**“软硬件协同优化”**的设计理念:通过编译器对计算图的深度优化,将高层语义转换为底层硬件的高效指令;同时,硬件架构(如AI Core、Vector Core)针对AI工作负载进行定制化设计,两者形成良性循环。
三、场景化落地实践
3.1 模型转换与优化全流程(ATC深度解析)
针对智能安防场景的YOLOv7目标检测模型(PyTorch训练,输入尺寸640×640,参数量36M),通过ATC工具链进行全流程优化:
1. 原始模型导出(PyTorch→ONNX)
import torch
from models.experimental import attempt_load
from utils.torch_utils import select_device
# 加载预训练模型
weights = "yolov7.pt"
device = select_device("0")
model = attempt_load(weights, map_location=device) # 加载模型
# 构造输入张量
img = torch.zeros(1, 3, 640, 640).to(device) # 构造全零输入
# 导出ONNX模型
torch.onnx.export(
model,
img,
"yolov7.onnx",
export_params=True,
opset_version=12,
do_constant_folding=True,
input_names=["images"],
output_names=["output"],
dynamic_axes={
"images": {0: "batch_size", 2: "height", 3: "width"},
"output": {0: "batch_size", 1: "num_boxes"}
}
)代码解析:
attempt_load:加载YOLOv7预训练模型;torch.onnx.export:将PyTorch模型导出为ONNX格式,指定输入输出名称和动态维度(支持batch_size和输入尺寸的动态变化)。
2. ATC模型转换与优化
from ascendctl import ATC
import json
# 初始化ATC工具
atc = ATC()
# 配置文件(详细参数说明)
config = {
"model": "yolov7.onnx", # 输入ONNX模型路径
"framework": "onnx", # 源框架类型
"output": "yolov7_atc", # 输出离线模型名称
"soc_version": "Ascend310P3", # 目标硬件型号
"input_shape": "images:1,3,640,640", # 输入形状
"log": "debug", # 日志级别,debug可查详细优化过程
"precision_mode": "allow_mix_precision", # 混合精度模式(FP16+INT8)
"fusion_switch_file": "fusion_switch.cfg", # 算子融合配置
"insert_op_conf": "aipp.cfg", # AIPP预处理配置
"dynamic_batch_size": "1,4,8", # 动态batch大小
"auto_tune_mode": "RL", # 自动调优模式(强化学习)
"enable_small_channel": "true", # 小通道优化
"op_select_implmode": "high_performance", # 算子实现模式(高性能优先)
}
# 执行模型转换
atc.convert(config)配置参数详解:
precision_mode:混合精度模式,ATC会自动将部分算子转换为FP16或INT8精度,在保证精度损失小于0.5%的前提下,提升推理速度;fusion_switch_file:算子融合配置文件,可指定哪些算子进行融合(如Conv+BN+Relu融合为一个算子),减少内存访问;auto_tune_mode:自动调优模式,通过强化学习算法寻找最优的算子调度策略;dynamic_batch_size:支持动态batch大小,可根据实际业务负载调整batch_size,提高硬件利用率。
转换后模型效果:
- 模型体积从138MB(ONNX)减小至87MB(OM),减小37%;
- 推理速度从GPU上的28ms/帧提升至Atlas上的15ms/帧,提升46%;
- 显存占用从1.2GB降低至600MB,降低50%。
3.2 自定义算子开发(多目标跟踪场景)
在智能安防场景中,**多目标跟踪(MOT)**是核心业务逻辑之一,需要对检测到的目标进行跨帧关联。传统的DeepSORT算法在CPU上运行效率低下,通过CANN自定义算子开发可实现硬件加速。
1. 自定义算子实现(余弦相似度计算)
#include "kernel.h"
#include "utils.h"
// 余弦相似度计算核函数(支持FP16)
__global__ void CosineSimilarityKernel(
const half* feat1, // 目标1特征 [batch, dim]
const half* feat2, // 目标2特征 [batch, dim]
half* output, // 输出相似度 [batch]
int batch,
int dim
) {
// 线程索引计算
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= batch) return;
half dot = 0;
half norm1 = 0;
half norm2 = 0;
// 计算点积和模长
for (int i = 0; i < dim; i++) {
half f1 = feat1[idx * dim + i];
half f2 = feat2[idx * dim + i];
dot = __hadd(dot, __hmul(f1, f2)); // 半精度加法和乘法
norm1 = __hadd(norm1, __hmul(f1, f1));
norm2 = __hadd(norm2, __hmul(f2, f2));
}
// 计算平方根(半精度)
norm1 = __hsqrt(norm1);
norm2 = __hsqrt(norm2);
// 计算余弦相似度
output[idx] = __hdiv(dot, __hmul(norm1, norm2));
}
// 算子注册类
class CosineSimilarityOp : public OpKernel {
public:
void Compute(OpKernelContext* context) override {
// 获取输入张量
Tensor* feat1_tensor = context->Input(0);
Tensor* feat2_tensor = context->Input(1);
// 获取输出张量
Tensor* output_tensor = context->Output(0);
// 数据指针转换
half* feat1 = feat1_tensor->data();
half* feat2 = feat2_tensor->data();
half* output = output_tensor->mutable_data();
// 形状获取
int batch = feat1_tensor->shape().dim_size(0);
int dim = feat1_tensor->shape().dim_size(1);
// 启动核函数(配置线程块和网格)
dim3 blockDim(256);
dim3 gridDim((batch + blockDim.x - 1) / blockDim.x);
CosineSimilarityKernel<<>>(feat1, feat2, output, batch, dim);
}
};
// 算子注册
REGISTER_KERNEL_BUILDER(
Name("CosineSimilarity")
.Device(DEVICE_CUDA) // 设备类型(Atlas硬件的CUDA兼容层)
.TypeConstraint() // 数据类型约束
, CosineSimilarityOp); 代码解析:
- 核函数
CosineSimilarityKernel:在Atlas的AI Core上执行,实现半精度的余弦相似度计算; __hadd、__hmul、__hsqrt:半精度算术运算指令,充分利用Atlas硬件对FP16的原生支持;- 算子注册:通过CANN提供的宏定义
REGISTER_KERNEL_BUILDER将自定义算子注册到计算图中。
2. 算子编译与集成
# 步骤1:生成算子描述文件(cosine_similarity.opDesc)
ascend_op_gen --op_impl=cosine_similarity.cc --output=./op_desc
# 步骤2:编译算子
ascend_clang -c cosine_similarity.cc -o cosine_similarity.o -I$ASCEND_INC -std=c++11
# 步骤3:链接生成动态库
ascend_ld -shared cosine_similarity.o -o libcosine_similarity.so
# 步骤4:将算子集成到模型中
atc --model=yolov7.onnx --framework=onnx --output=yolov7_atc --soc_version=Ascend310P3 --insert_op_conf=cosine_similarity.opDesc流程说明:
ascend_op_gen:生成算子描述文件,定义算子的输入输出、属性等信息;ascend_clang和ascend_ld:CANN提供的异构编译器和链接器,用于将算子代码编译为Atlas硬件可执行的二进制文件;atc --insert_op_conf:在模型转换时插入自定义算子,实现端到端的推理流程。
性能对比:
- CPU实现(OpenCV):相似度计算耗时约10ms/对;
- CANN自定义算子:耗时约0.5ms/对,性能提升20倍。
3.3 资源调度与多任务并行(500路视频场景)
针对500路1080P视频的实时分析需求,通过CANN的TaskScheduler实现精细化资源调度:
1. 任务调度器实现
from ascendctl import TaskScheduler, DeviceManager, Runtime
class VideoAnalysisTask:
def __init__(self, video_path, model_path, device_id=0):
self.video_path = video_path
self.model_path = model_path
self.device_id = device_id
self.runtime = Runtime(device_id)
self.model = self.runtime.load_model(model_path)
def preprocess(self, frame):
# 图像预处理:resize、归一化、转置
import cv2
import numpy as np
frame = cv2.resize(frame, (640, 640))
frame = frame.transpose(2, 0, 1) # HWC→CHW
frame = frame.astype(np.float32) / 255.0
frame = (frame - 0.5) / 0.5 # 归一化
return frame[np.newaxis, ...] # 添加batch维度
def infer(self, input_data):
# 模型推理
outputs = self.model.infer(input_data)
return outputs
def postprocess(self, outputs):
# 后处理:目标检测、跟踪
from utils.detect import non_max_suppression
from utils.track import DeepSORT
if not hasattr(self, 'tracker'):
self.tracker = DeepSORT()
pred = non_max_suppression(outputs[0], conf_thres=0.5, iou_thres=0.5)
tracks = self.tracker.update(pred[0])
return tracks
def run(self):
# 视频解码与分析主流程
import cv2
cap = cv2.VideoCapture(self.video_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
input_data = self.preprocess(frame)
outputs = self.infer(input_data)
tracks = self.postprocess(outputs)
self.visualize(frame, tracks)
cap.release()
def visualize(self, frame, tracks):
# 可视化结果
import cv2
for track in tracks:
x1, y1, x2, y2, id = track
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(frame, f"ID:{id}", (x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow("Video Analysis", frame)
cv2.waitKey(1)
# 任务调度
def schedule_tasks(video_paths, model_path, device_count=4):
device_manager = DeviceManager()
devices = device_manager.list_devices()[:device_count]
scheduler = TaskScheduler(
core_group_count=4, # 每个设备分为4个Core组
scheduling_policy="priority_based", # 优先级调度策略
max_parallel_tasks=200 # 最大并行任务数
)
tasks = []
for i, video_path in enumerate(video_paths):
device = devices[i % device_count]
task = VideoAnalysisTask(video_path, model_path, device.id)
scheduled_task = scheduler.submit(
task.run,
core_group=i % 4,
priority=i % 3 + 1, # 优先级1-3
timeout=300 # 超时时间300ms
)
tasks.append(scheduled_task)
# 任务监控
for task in tasks:
while not task.is_completed():
status = task.get_status()
print(f"Task {task.id}: {status}, Progress: {task.get_progress()}%")
time.sleep(1)代码解析:
VideoAnalysisTask类:封装了视频分析的全流程,包括预处理、推理、后处理和可视化;TaskScheduler:CANN提供的任务调度器,支持基于优先级的调度策略和Core组隔离;core_group_count:将Atlas设备的AI Core分为多个组,实现任务的隔离执行,避免资源竞争。
2. 调度策略与性能优化
CANN的任务调度采用“分级调度+动态负载均衡”策略:
- 分级调度:将任务分为实时任务(如视频分析)、离线任务(如模型转换)和后台任务(如日志收集),不同级别任务享有不同的资源优先级;
- 动态负载均衡:根据每个Core组的资源利用率(如AI Core占用率、内存使用率),动态调整任务分配,确保资源利用率最大化。
性能数据:
- 单设备(Atlas 800)可处理128路1080P视频的实时分析,平均延迟180ms;
- 系统资源利用率:AI Core平均占用率85%,内存利用率70%,远高于传统GPU方案的40%;
- 任务并行效率:500路视频的并行执行效率达到理论最大值的92%。
四、落地效果与行业价值
4.1 量化效果对比
指标 | 传统GPU方案(NVIDIA V100) | CANN+Atlas方案(Atlas 800) | 提升幅度 |
单路视频分析延迟 | 800ms | 180ms | 77.5% |
单设备支持路数 | 15路 | 128路 | 7.4倍 |
全市部署设备数 | 1300+台 | 160台 | 87.7% |
硬件采购成本 | 10亿元 | 1.2亿元 | 88% |
年电费 | 5000万元 | 600万元 | 88% |
模型部署周期 | 2周/模型 | 4小时/模型 | 97% |
新增功能迭代周期 | 1个月 | 3天 | 90% |
4.2 业务价值体现
- 城市治理效率提升:
- 异常行为响应时间从原来的5分钟缩短至30秒以内,警情处置效率提升10倍;
- 案件侦破周期从原来的平均72小时缩短至24小时以内,破案率提升35%。
- 社会资源节约:
- 硬件设备数量减少87.7%,机房面积从2000㎡缩减至200㎡,土地资源节约90%;
- 年电费减少4400万元,相当于每年减少标准煤消耗1.5万吨,减少二氧化碳排放4万吨。
- 技术生态影响:
- 培养了一支掌握CANN技术的AI开发团队,形成了可复用的智能安防算法库;
- 该项目作为标杆案例,已在全国10余个城市的智能安防项目中推广,带动CANN生态在安防领域的快速发展。
4.3 项目实施过程中的关键挑战与解决
- 多厂商设备兼容性:
项目中涉及海康、大华等多家厂商的监控设备,视频编码格式(H.264、H.265)和传输协议(RTSP、ONVIF)存在差异。通过CANN的Media Pipeline和自定义解码插件,实现了对多厂商设备的统一接入,解码效率提升40%。
- 复杂场景下的模型精度:
在夜间、雨雾等复杂场景下,模型精度有所下降。通过CANN的量化感知训练(QAT)功能,在模型转换阶段引入量化感知训练流程,确保INT8量化后的模型精度损失小于1%,满足业务需求。
- 大规模部署的运维难题:
160台Atlas设备的大规模部署面临配置管理、固件升级、故障排查等难题。通过CANN的设备管理工具(Ascend Device Manager),实现了设备的集中化管理和自动化运维,运维效率提升80%。
五、CANN未来演进
智能安防作为AI技术落地的前沿领域,未来将向“全域感知、智能决策、自主进化”方向发展。CANN作为核心技术底座,将在以下方面持续演进:
- 更深度的软硬件协同:
针对智能安防的特定场景,联合硬件厂商定制化设计AI芯片(如集成更多视频编解码单元),进一步提升端侧推理效率。
- 更完善的工具链生态:
丰富ModelZoo中的安防领域模型库,提供更多开箱即用的预训练模型;优化ATC工具的用户体验,支持一键式模型转换和优化。
- 更广泛的场景扩展:
从视频分析向音频分析(如异常声音检测)、多模态分析(如视频+音频融合分析)扩展,打造全维度的智能安防解决方案。
- 更智能的自治系统:
结合边缘计算和云端训练,实现模型的自迭代(根据现场数据自动更新模型)和自优化(根据硬件负载自动调整推理参数),进一步降低人工运维成本。
六、总结
本项目通过CANN在智能安防视频分析场景的深度落地,充分验证了其“释放硬件潜能、简化AI开发”的技术价值。从技术层面,CANN实现了从模型转换、算子加速到资源调度的软硬自研优化,使AI应用在Atlas硬件上的性能达到了业界领先水平;从业务层面,CANN帮助项目实现了成本的大幅降低和效率的显著提升,为智能安防行业的智能化升级提供了可复制的技术路径。
对于AI开发者而言,CANN的价值不仅在于提供了一套高性能的异构计算架构,更在于它打造了一个“开发者友好”的生态系统——通过简化的工具链和清晰的开发流程,让开发者可以更专注于业务创新,而非底层硬件的适配和优化。
在人工智能技术飞速发展的今天,CANN作为国产AI基础设施的核心组件,正以其强大的技术实力和广泛的行业应用,推动着中国AI产业的自主创新和生态建设。未来,随着CANN技术的不断演进和生态的持续完善,它将在更多领域释放出巨大的价值,为人工智能的产业化落地贡献重要力量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号