


深入解析数据分页:从源码到实战 - 指南
目录
那么用户操作在哪里展示了?——分页组件(pagination)
根据接口找到后端代码——ISysOperlogController.java
第一步:开启 startPage() —— 从 HTTP 到 ThreadLocal
第三步:包装结果 getDataTable —— 取出 total
那么用户操作在哪里展示了?——分页组件(pagination)
1、创建 MyPage 类:继承 ArrayList,增加 total 属性
2、在 Service 层添加 selectNameList()
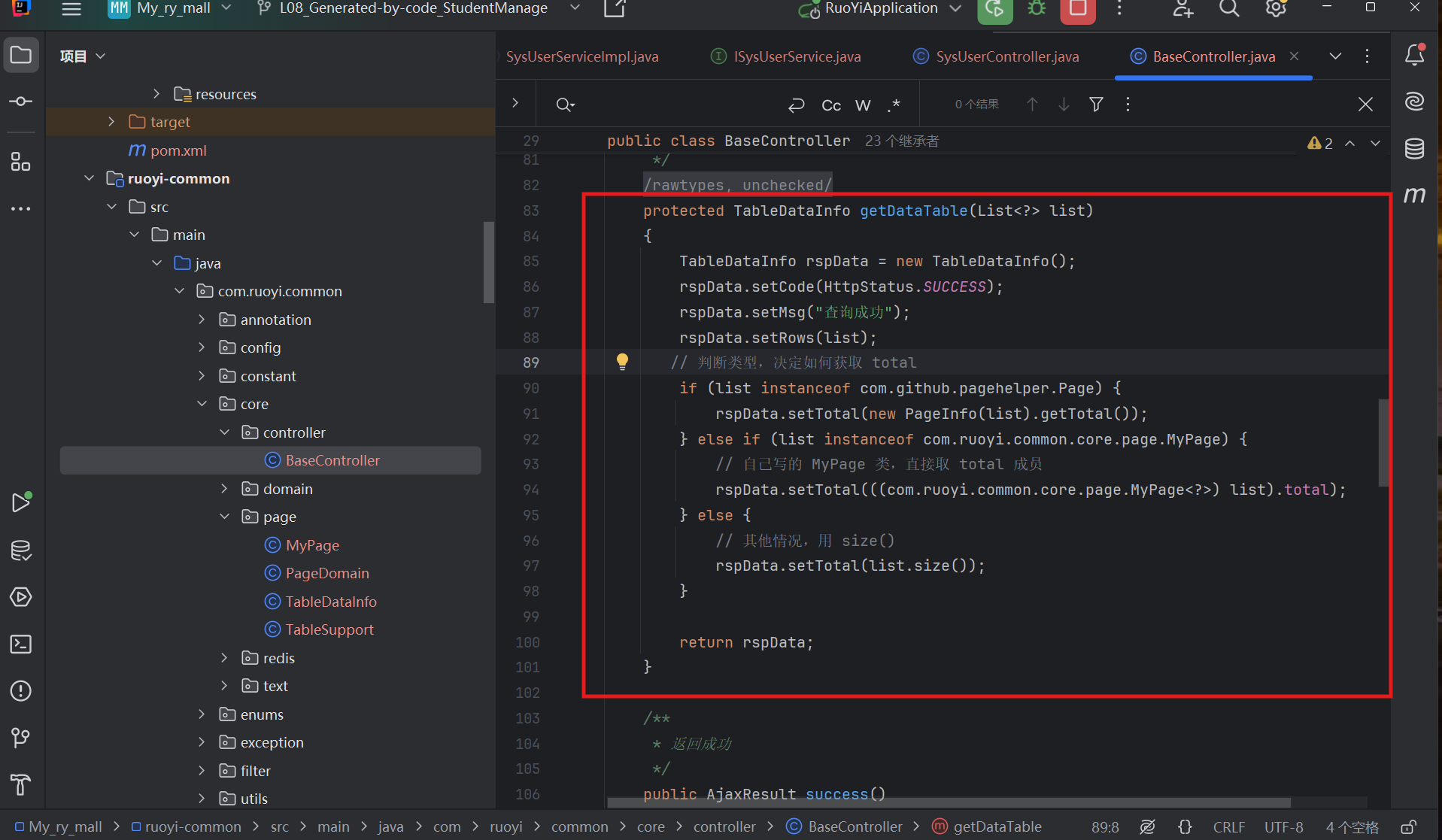
4、改造 BaseController.getDataTable()(关键!)
第一部分:什么是数据分页,为什么要进行数据分页?
场景:
- 想象你有一本厚达10,000 页的百科全书(数据库里有 1 万条日志数据)。
材料分页?就是1. 什么
- “不要一次性把整本书的内容全摊开在桌子上”就是数据分页就,
而是“一次只读一页”。- 在软件里,我们告诉框架:“我要看第1页,每页展示10 条数据”。
系统就会只给你拿第 1 到第 10 条,而不是把 1 万条全扔给你。2. 为什么要进行数据分页?
- 性能(后端 & 数据库):假设数据库里100万条执行日志,若是不分页一次性全查出来,数据库会累死(查询慢),服务器内存会撑爆(OOM),系统直接卡死
- 体验(前端&用户):如果你在浏览器里一次性渲染100万行表格,浏览器会直接崩溃白屏。而且用户也不能一次性看完100万条数据,他们也是一页一页看的
- 流量(网络):传输10条数据可能只要10KB,传输100万条数据可能要几百MB。分页行节省大量的网络带宽
第二部分:源码分析——以操作日志页面为例
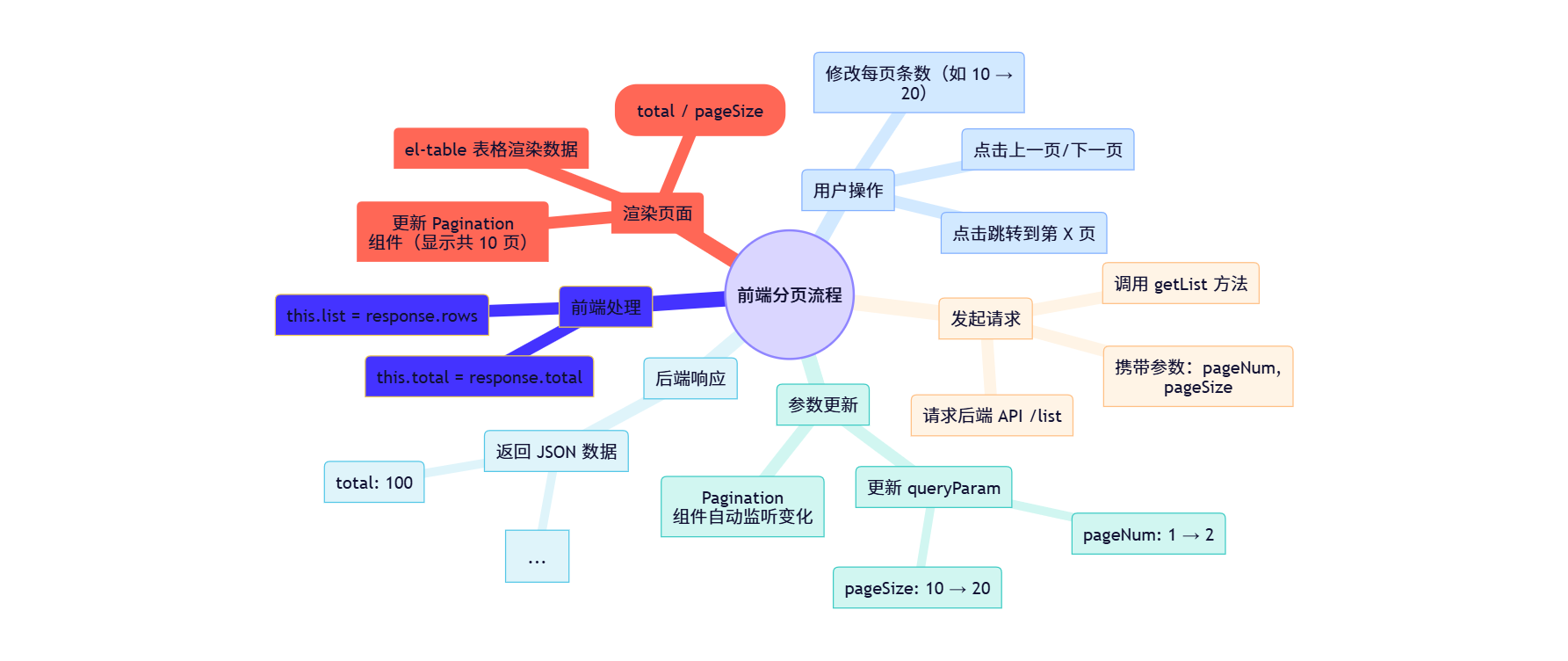
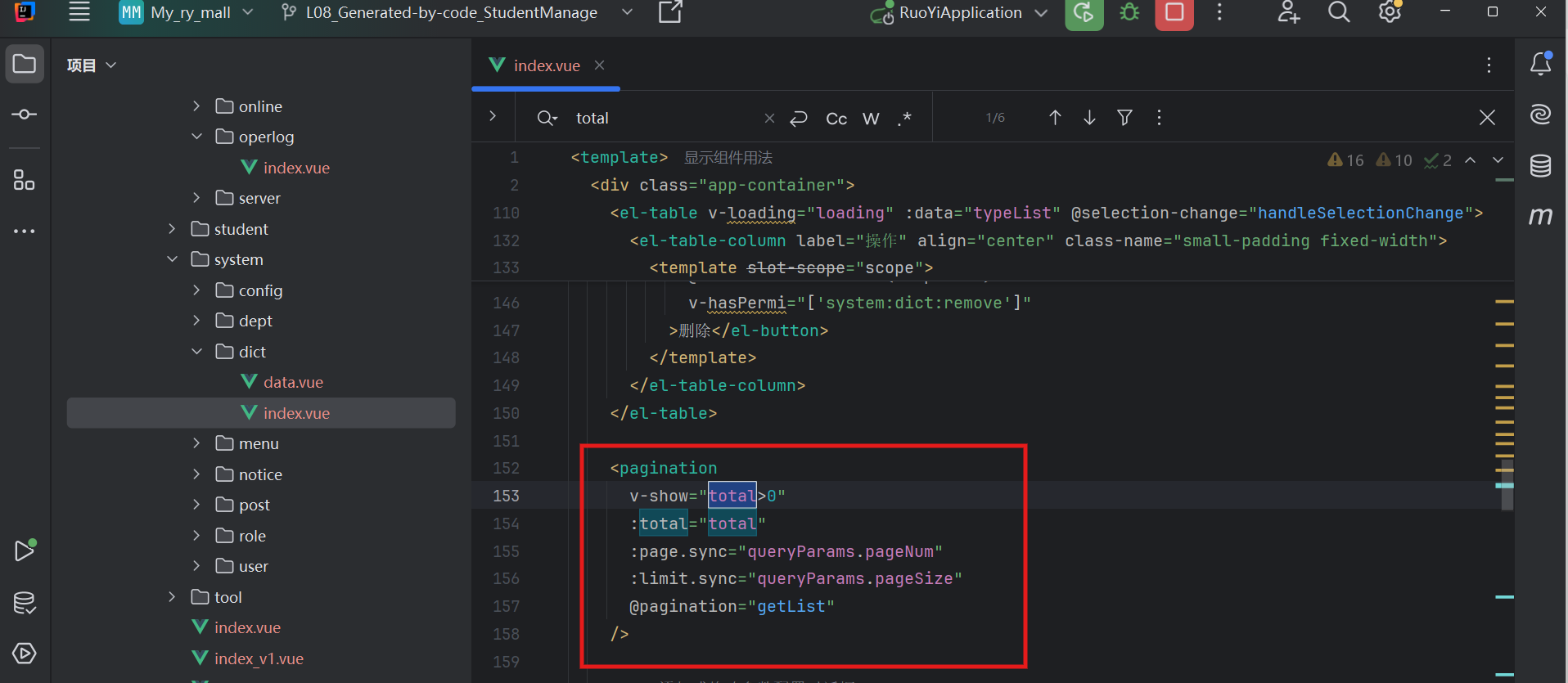
第一步:前端(Vue 页面)
- 位置:找到操作日志的前端代码档案(index.vue)
- 目标:用哪个变量来接收后端返回的total的就是看看前端在“发请求”时带了什么参数(Eg:pageNum-页面编号,pageSize-页面大小), 以及前端
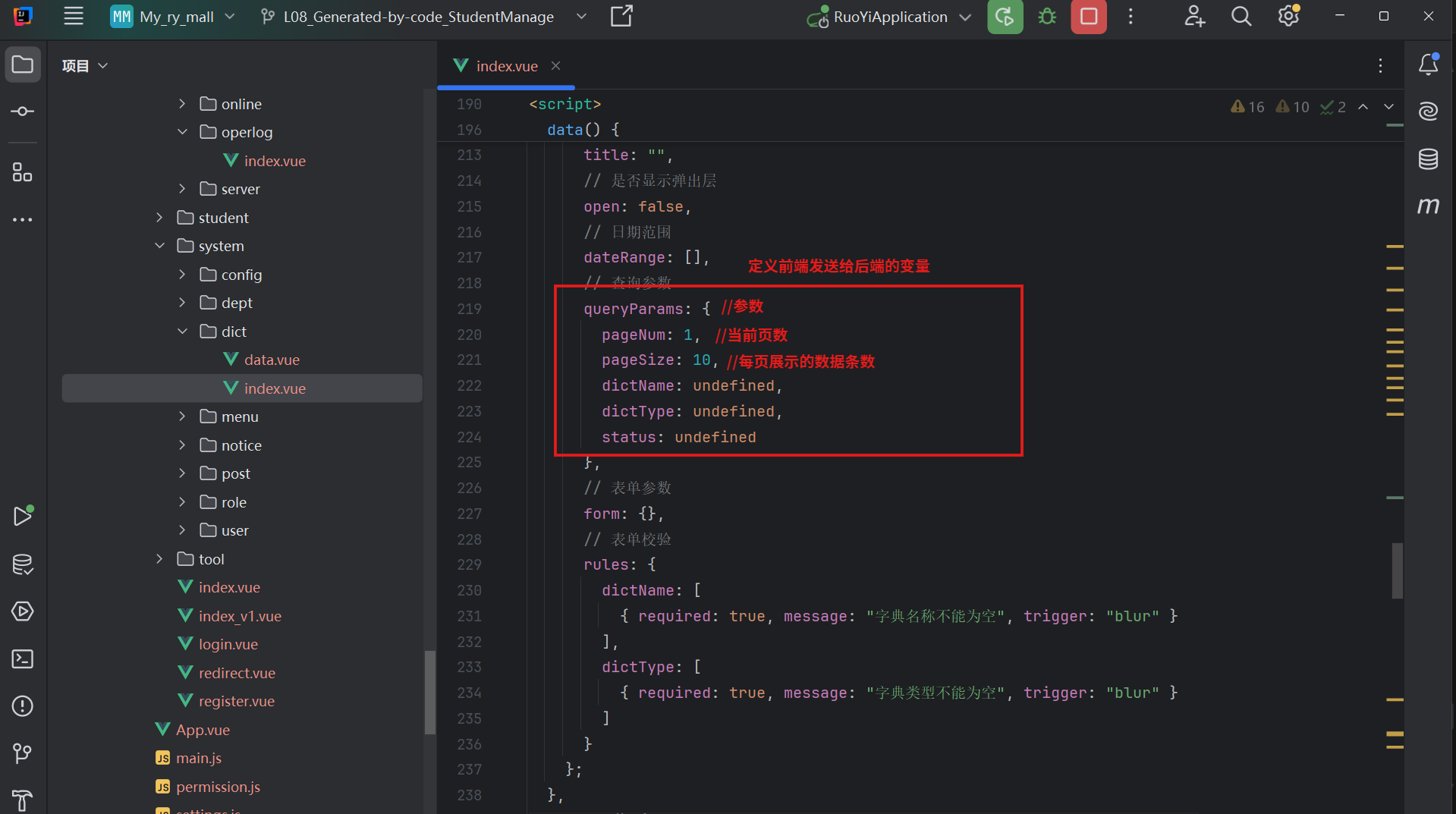
定义前端发给后端的“信使-参数”
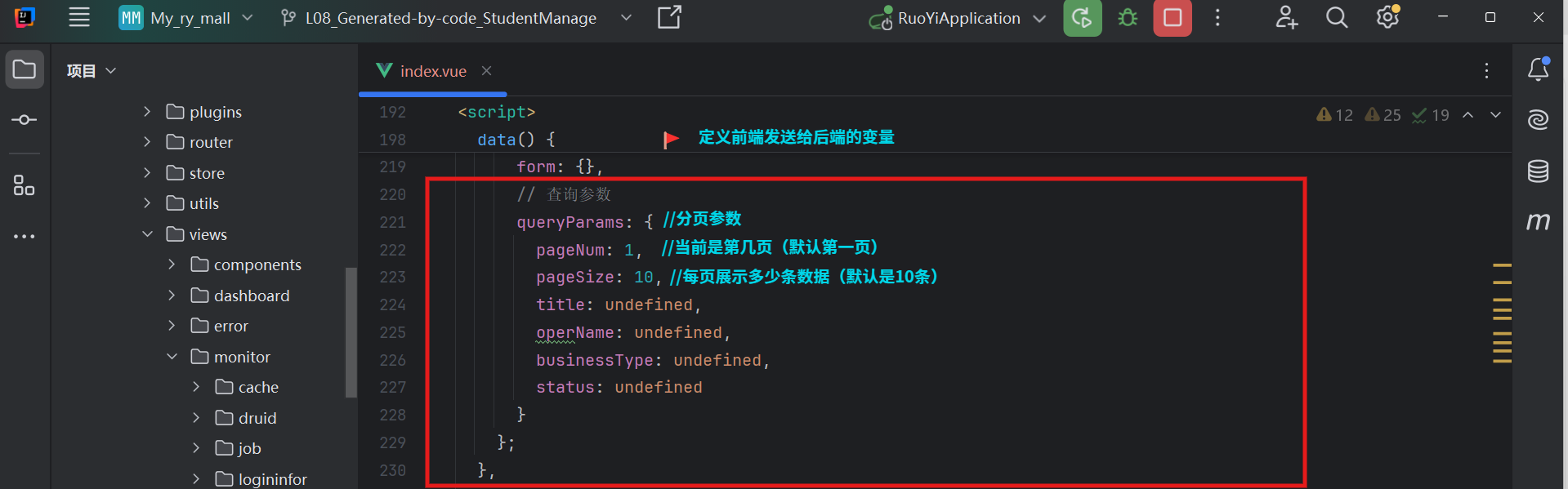 这两个变量是核心,他们决定了你要看那一部分数据
这两个变量是核心,他们决定了你要看那一部分数据
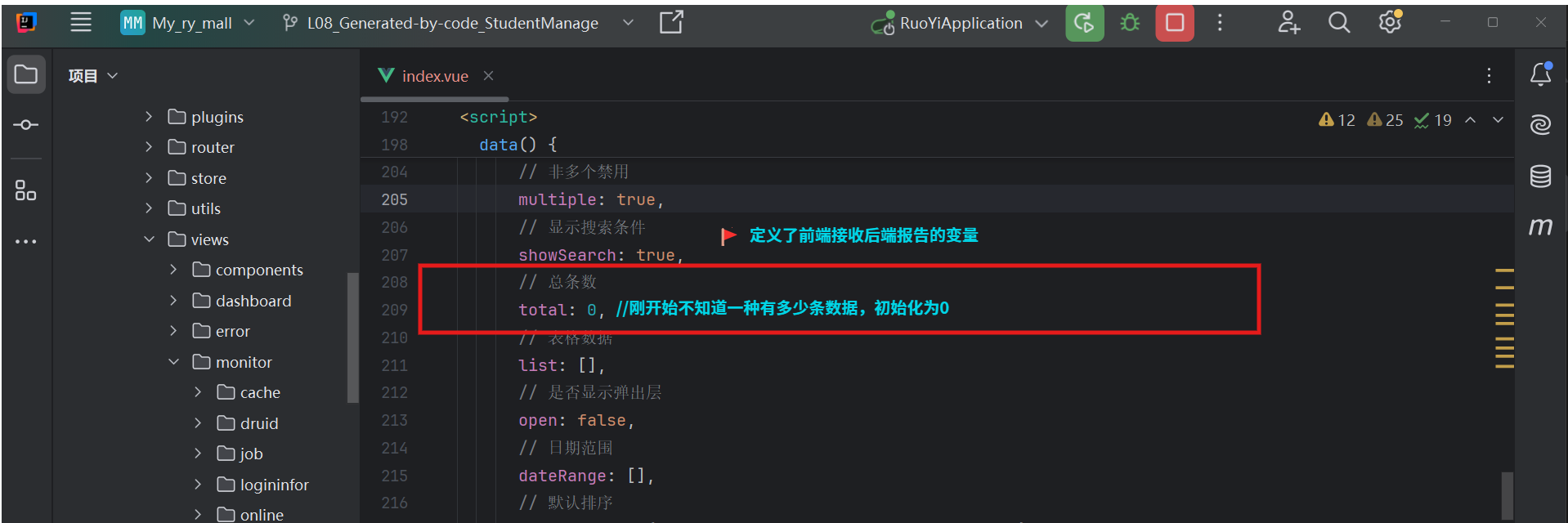
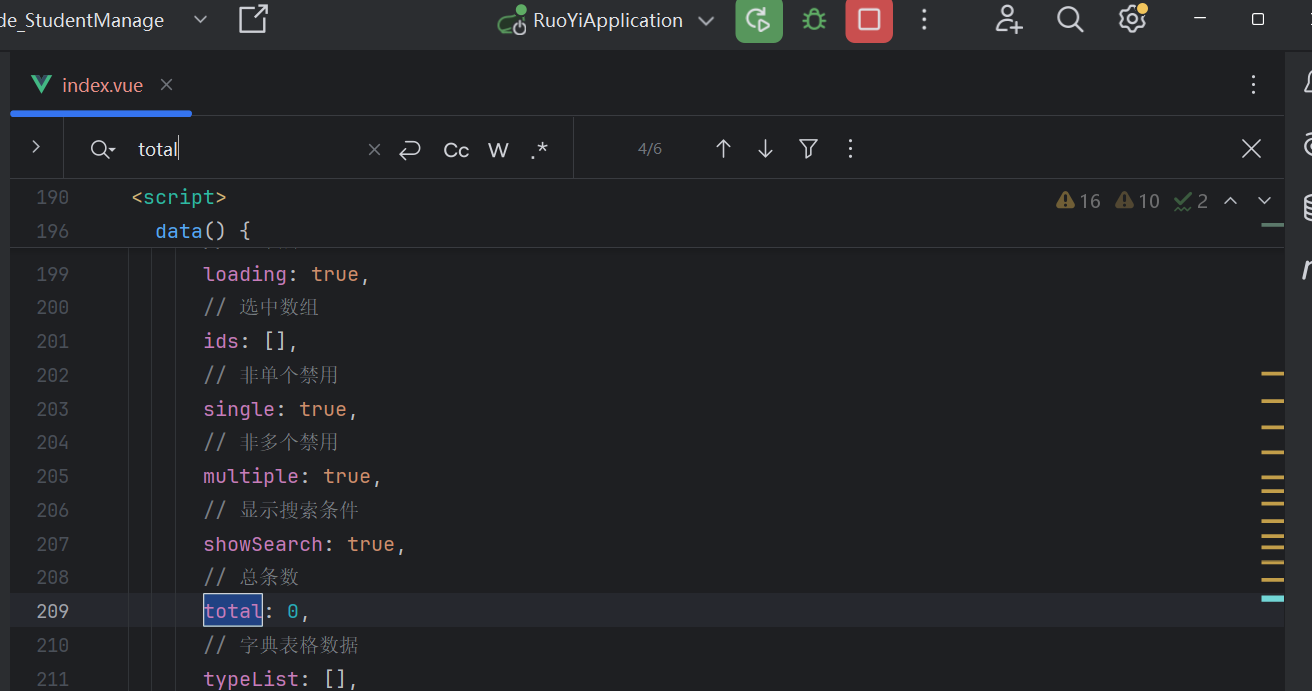
后端回信:总条数-total
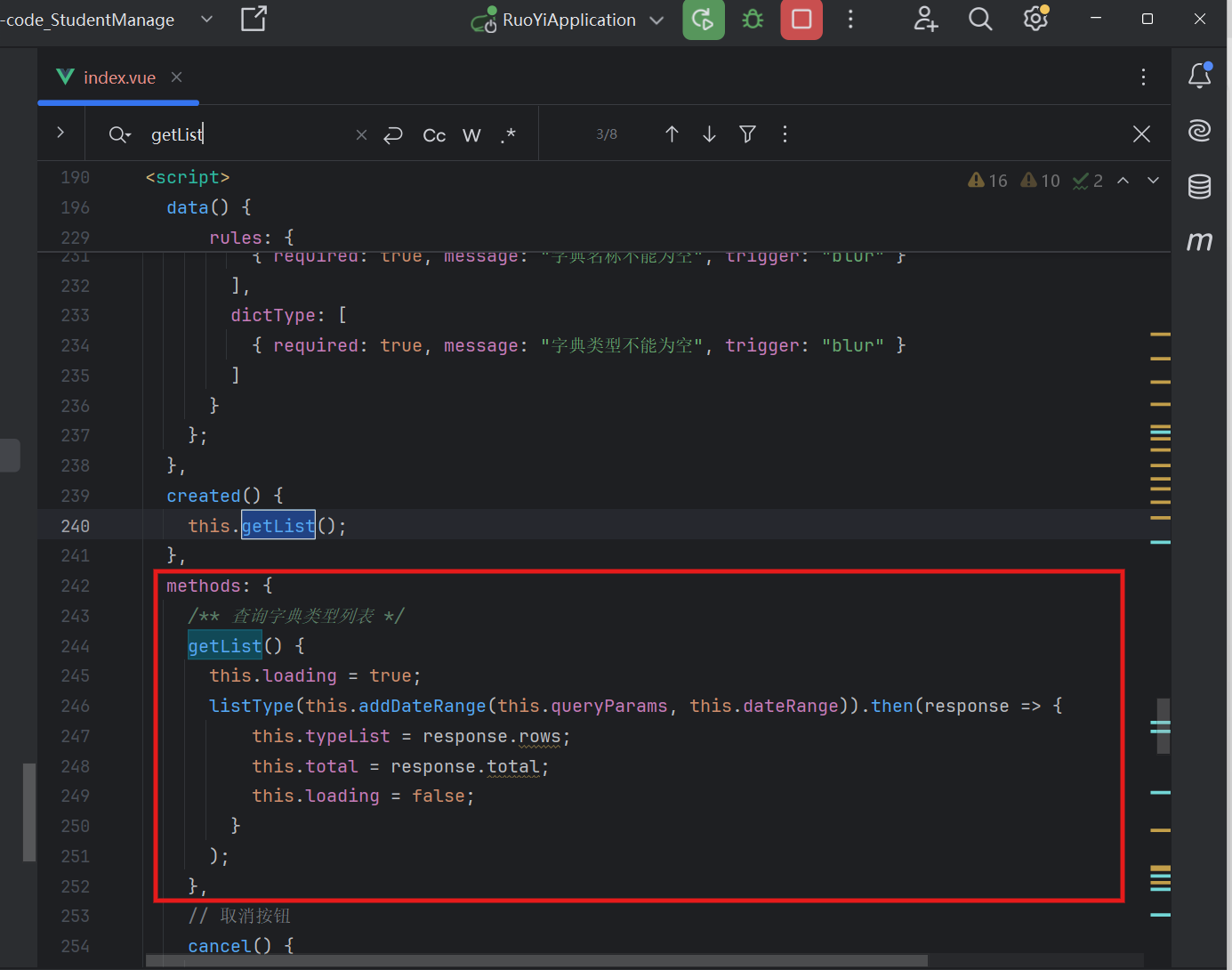
用户操作:点击上一页或下一页等触发getList()方法
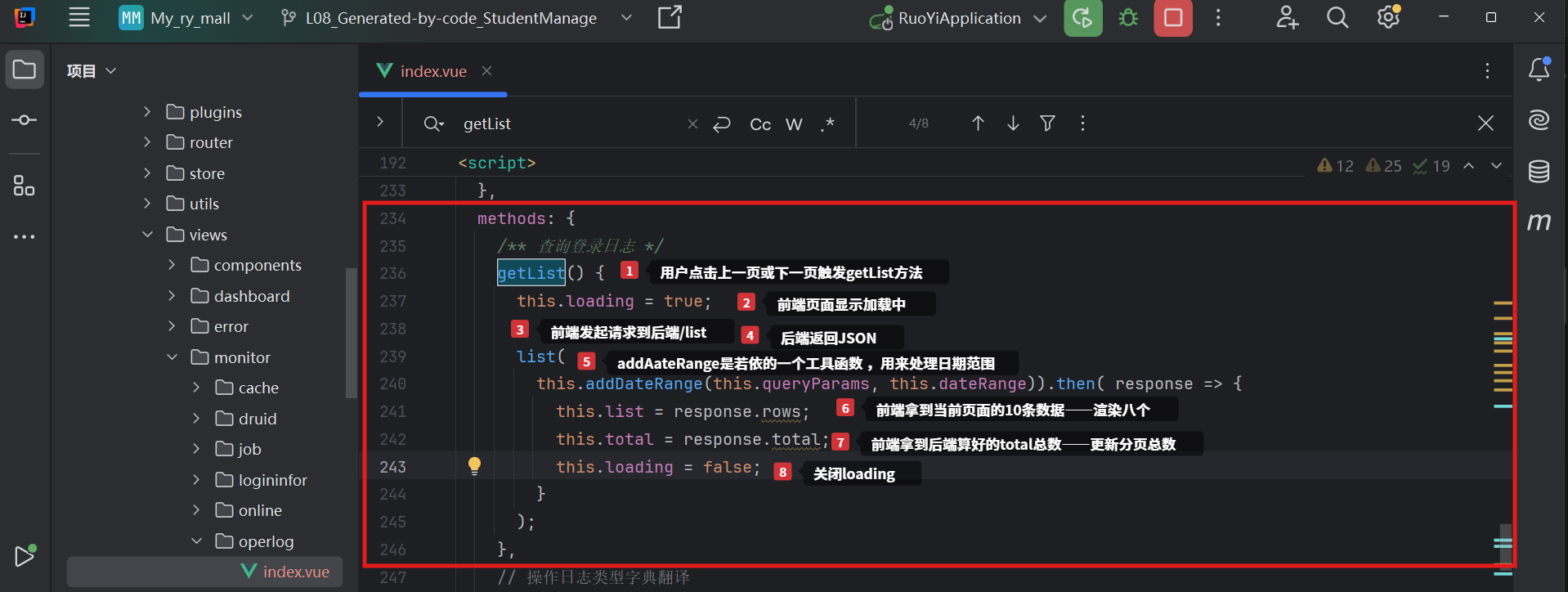
- 前端得知总数的唯一途径就是关键:this.total = response.total;——这
- 思路流程图:

那么用户操作在哪里展示了?——分页组件(pagination)
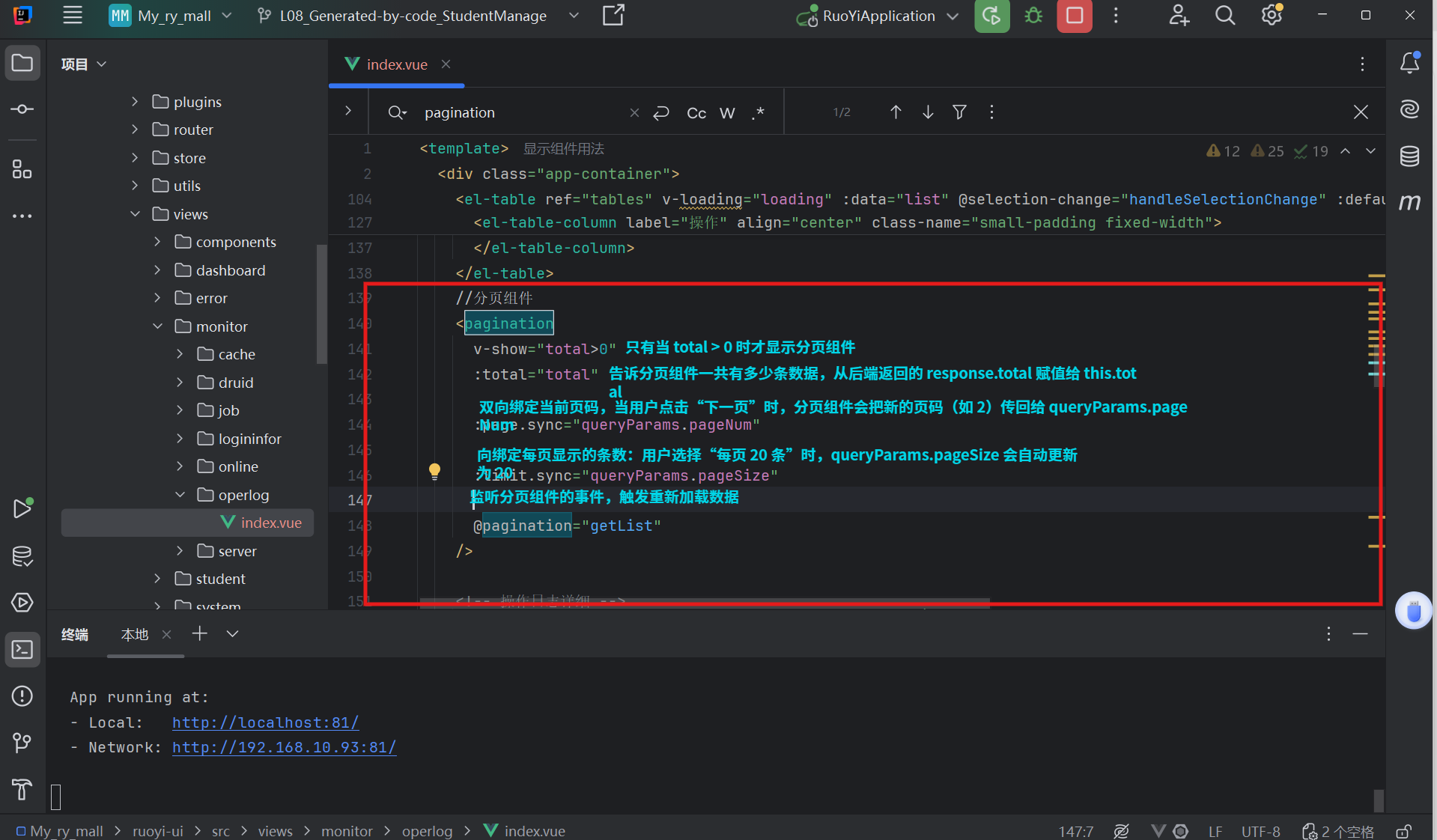
- 当什么情况发生时触发?
- 用户点击“上一页/下一页”
- 用户修改“每页条数”
- 用户跳转到某一页
- 触发后做什么?
- 执行
getList()方法 - 发起新的请求,获取新页面的数据
- 执行
整个流程:改变参数 → 触发请求 → 更新信息

小结
- 前端其实很便捷,它只负责“提要求”(我要第2页,10条数据)和“展示结果怎么算出来的,前端完全不知道,全靠后端给。就是”(渲染表格,根据total渲染页码)。至于78条总数
- 补充:Vue 小技巧:
.sync是一个魔法修饰符。意思是:当你在界面上点击“下一页”时,组件会自动修改queryParams.pageNum的值,然后通过 pagination="getList" 再次触发查询。
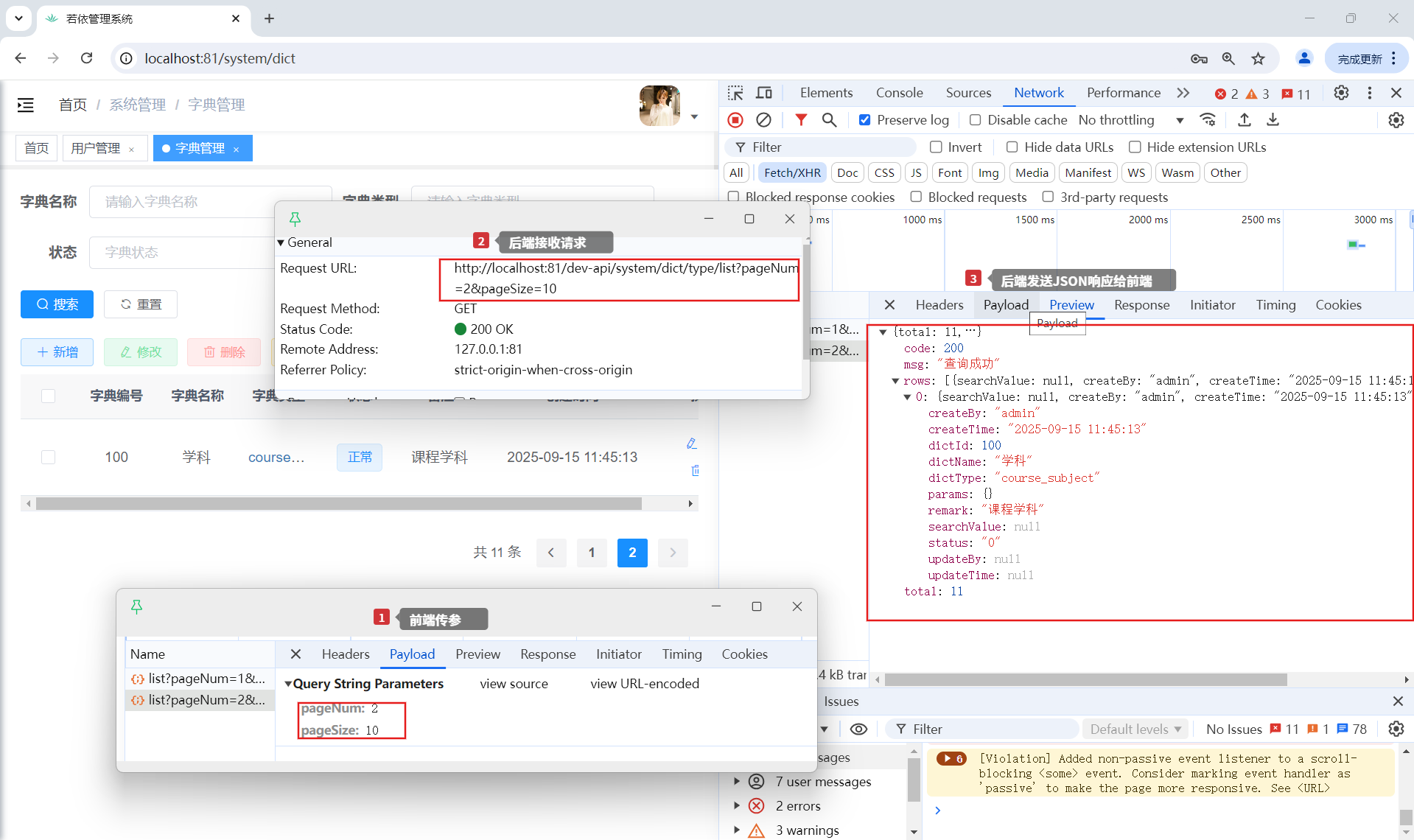
第二步:网络拦截
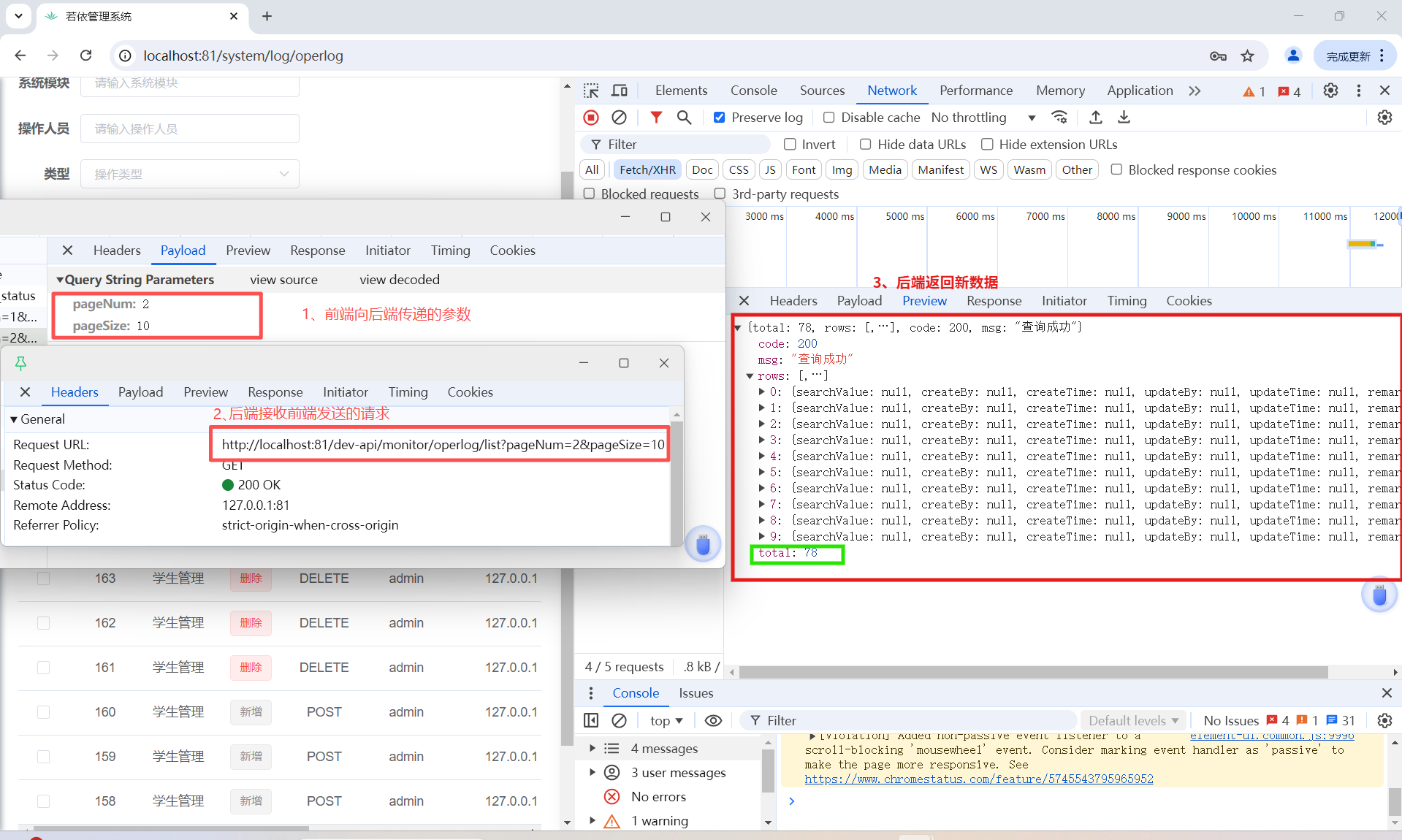
第三步:后端分页处理
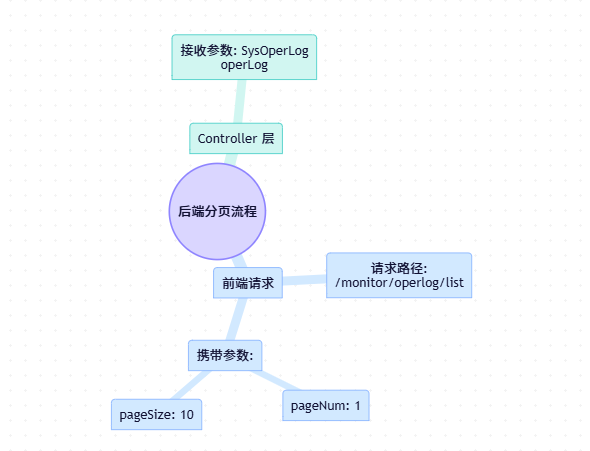
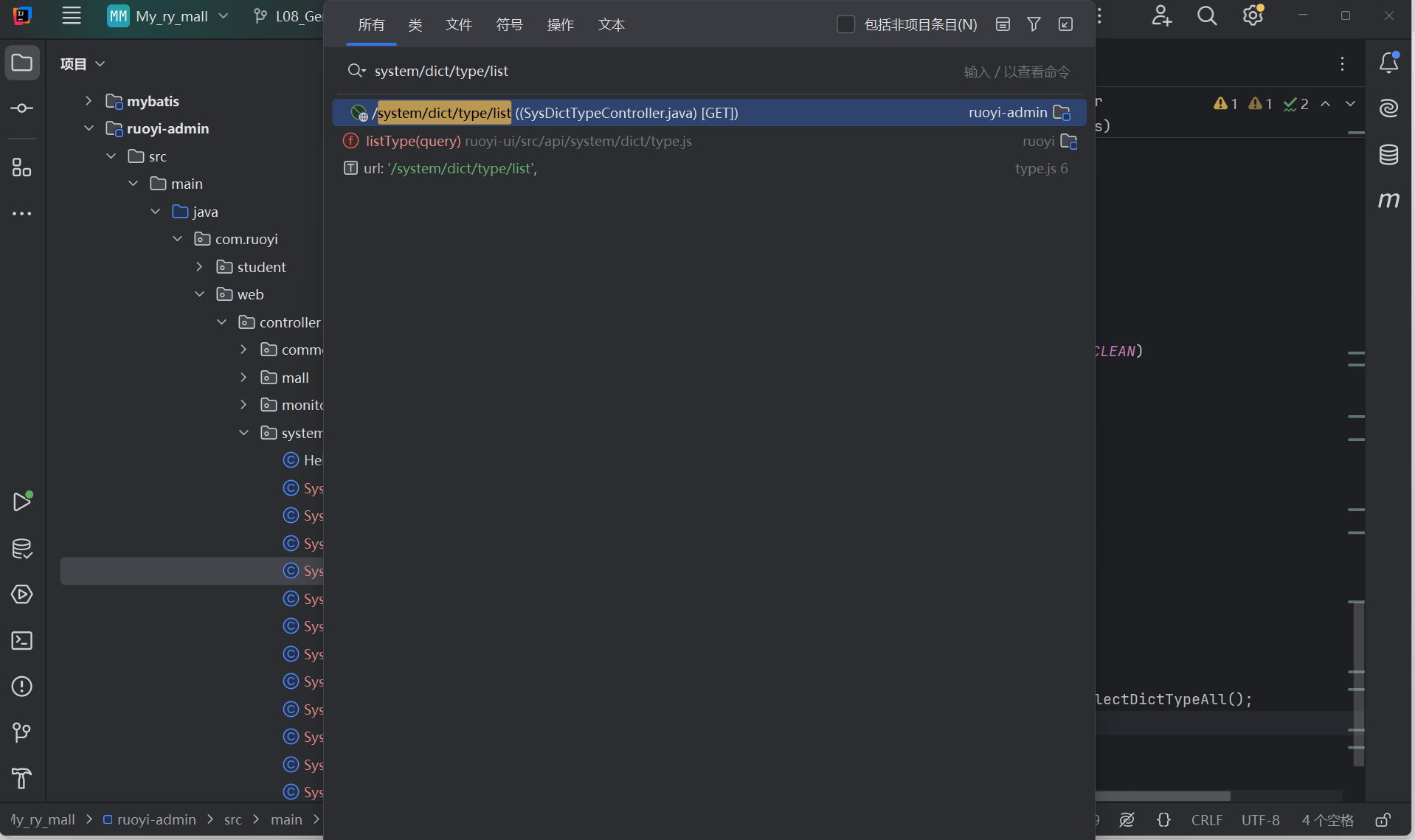
根据接口找到后端代码——ISysOperlogController.java
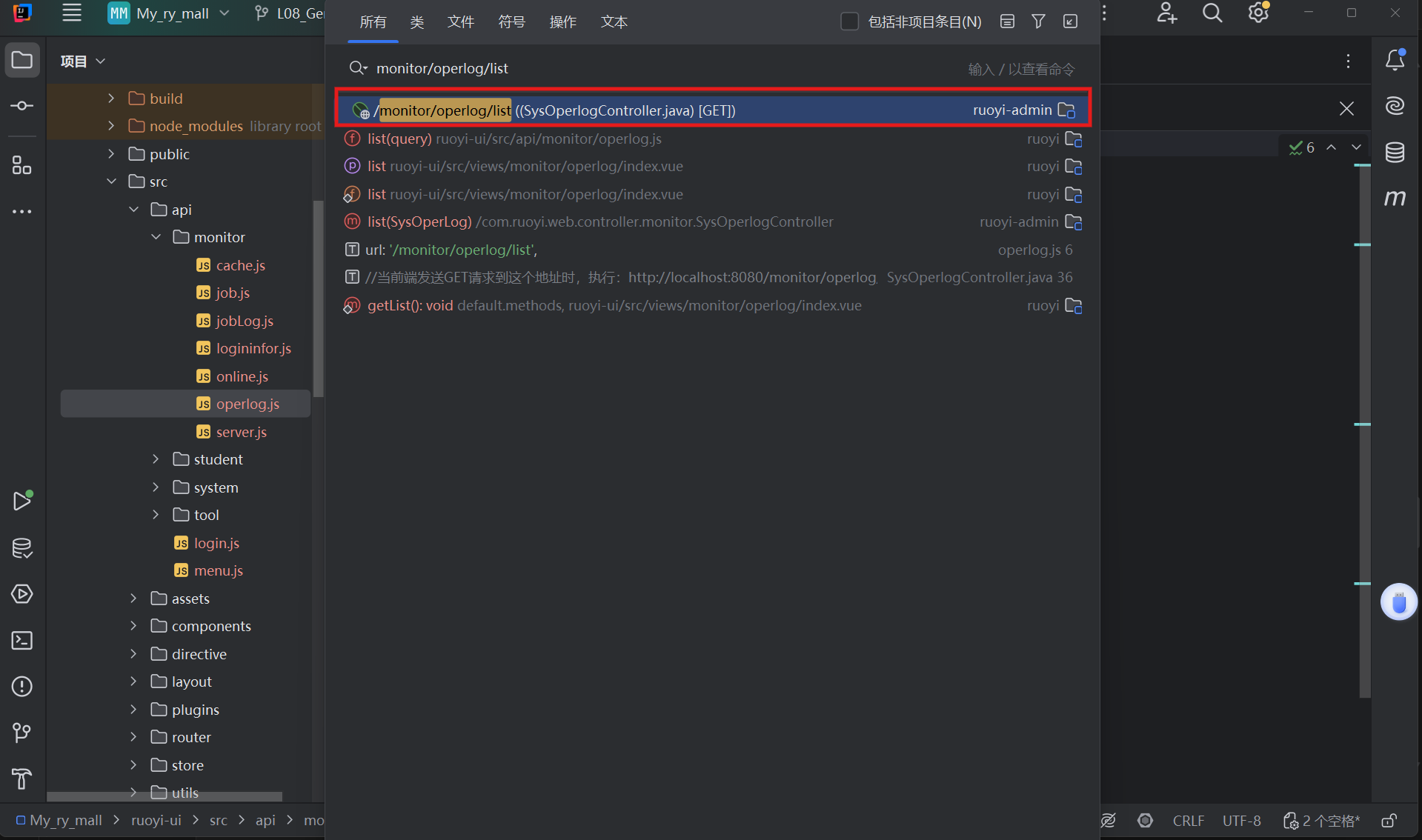
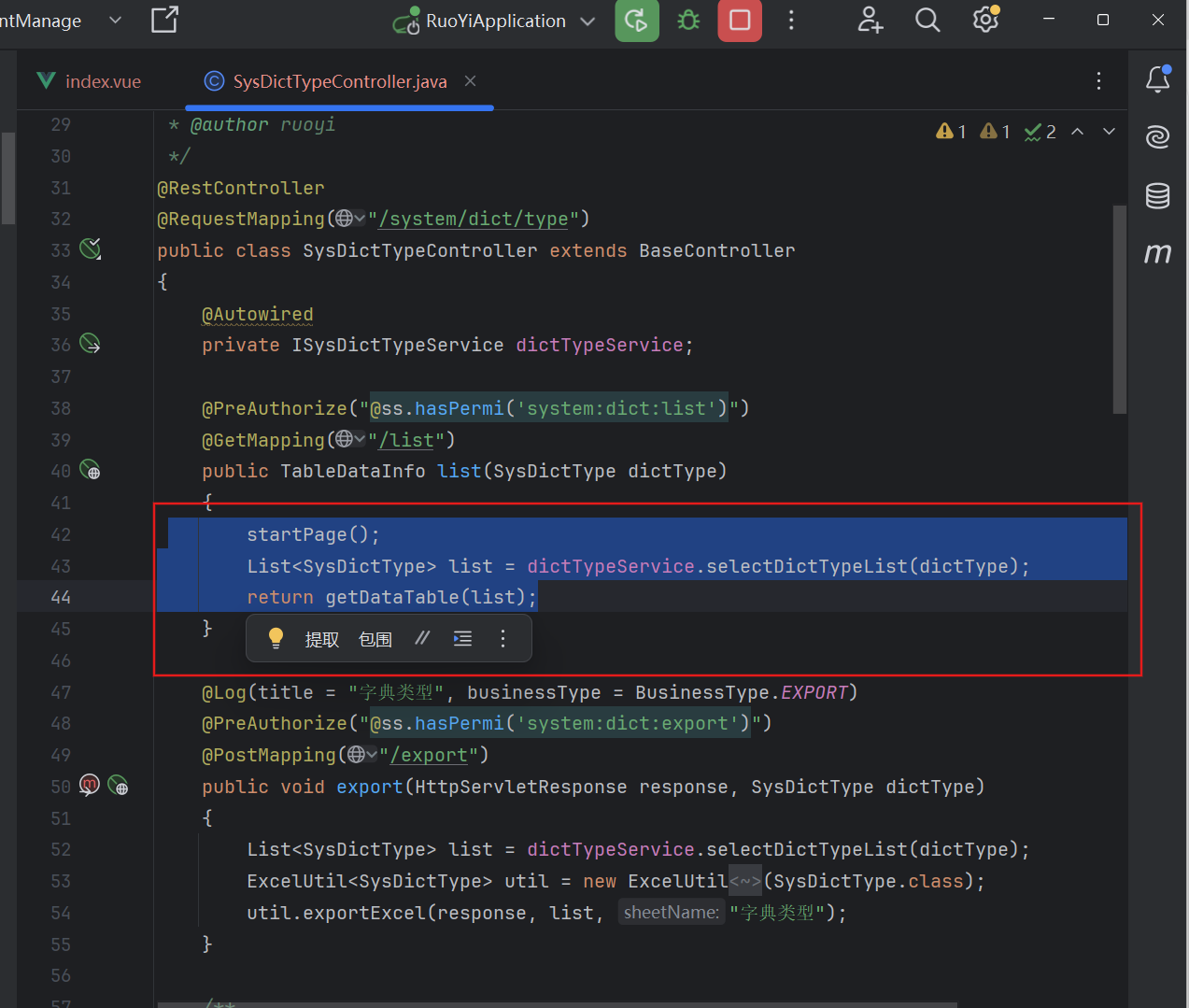
 第一步:开启
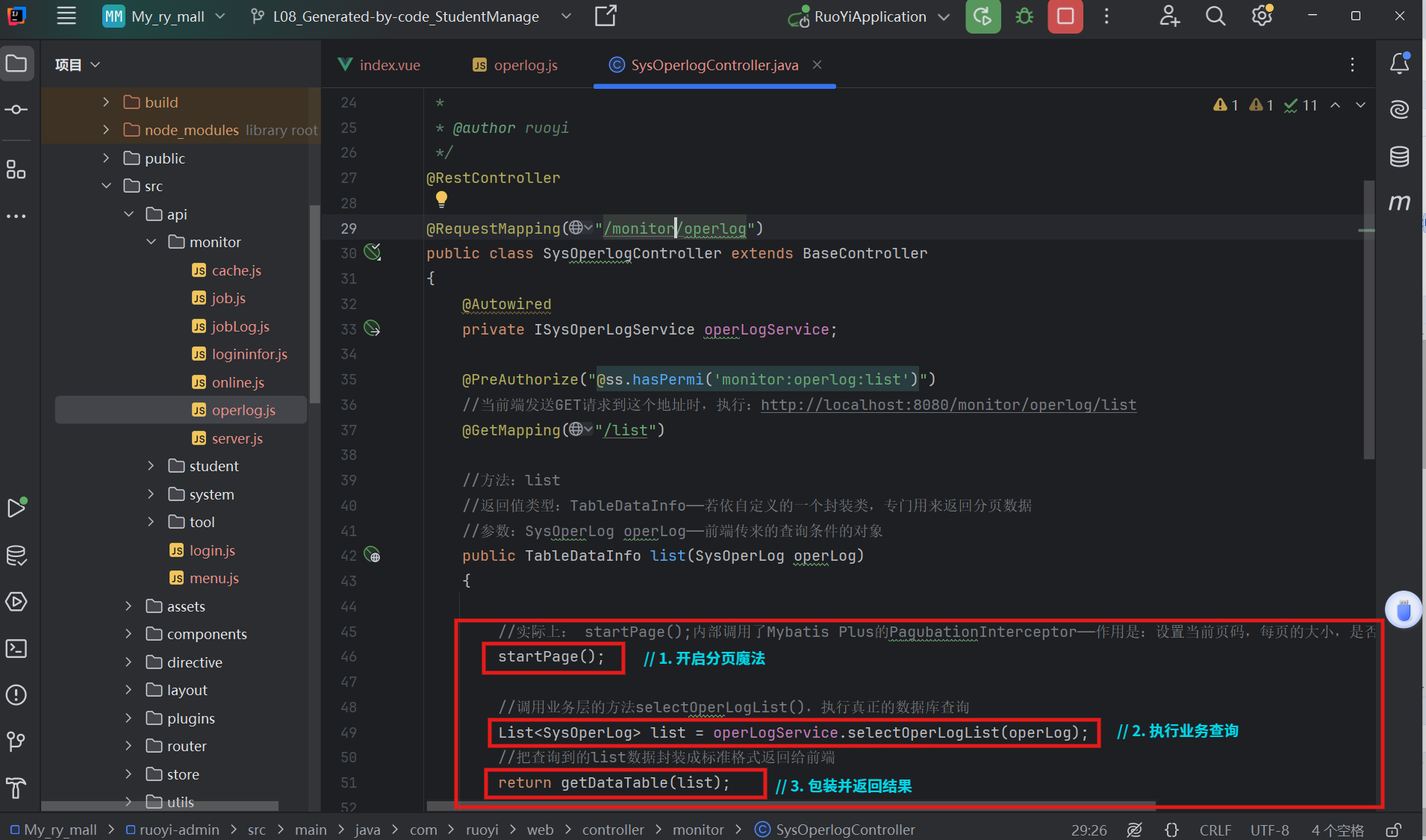
第一步:开启 startPage() —— 从 HTTP 到 ThreadLocal
疑问:参数pageNum和pageSize去哪里了?没有看到有代码接收他们
解决:(代码追踪)
- Controller层(ISysOperlogController.java)

- 父类BaseController(BaseController.java)——[ctrl+startPage+鼠标]
- 应用类(PageUtils.java)
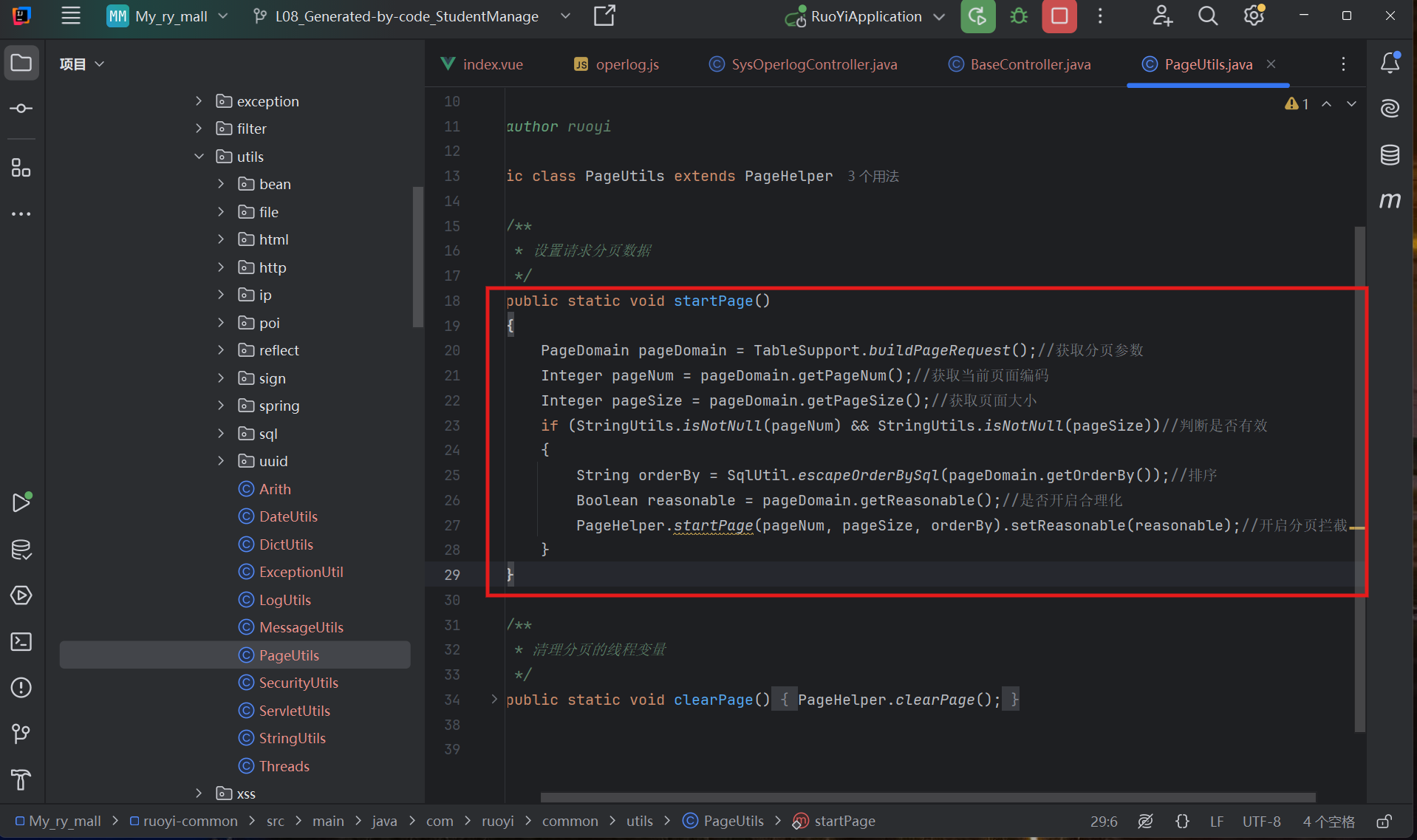
行号 代码 作用 ① TableSupport.buildPageRequest()从当前 HTTP 请求中提取 pageNum和pageSize参数
→ 来自前端 URL:?pageNum=2&pageSize=10② pageDomain.getPageNum()获取当前页码(如 2) ③ pageDomain.getPageSize()获取每页大小(如 10) ④ isNotNull(pageNum) && isNotNull(pageSize)判断参数是否有效,防止空值导致异常 ⑤ SqlUtil.escapeOrderBySql(...)安全处理排序字段(防 SQL 注入),比如将 desc转成DESC⑥ pageDomain.getReasonable()是否开启“合理化分页”(默认 true)
→ 如果用户输入pageNum=999,pageSize=10,但总记录只有 50 条,则自动跳转到第 5 页⑦ PageHelper.startPage(...)关键!调用 PageHelper 核心方式,开启分页拦截
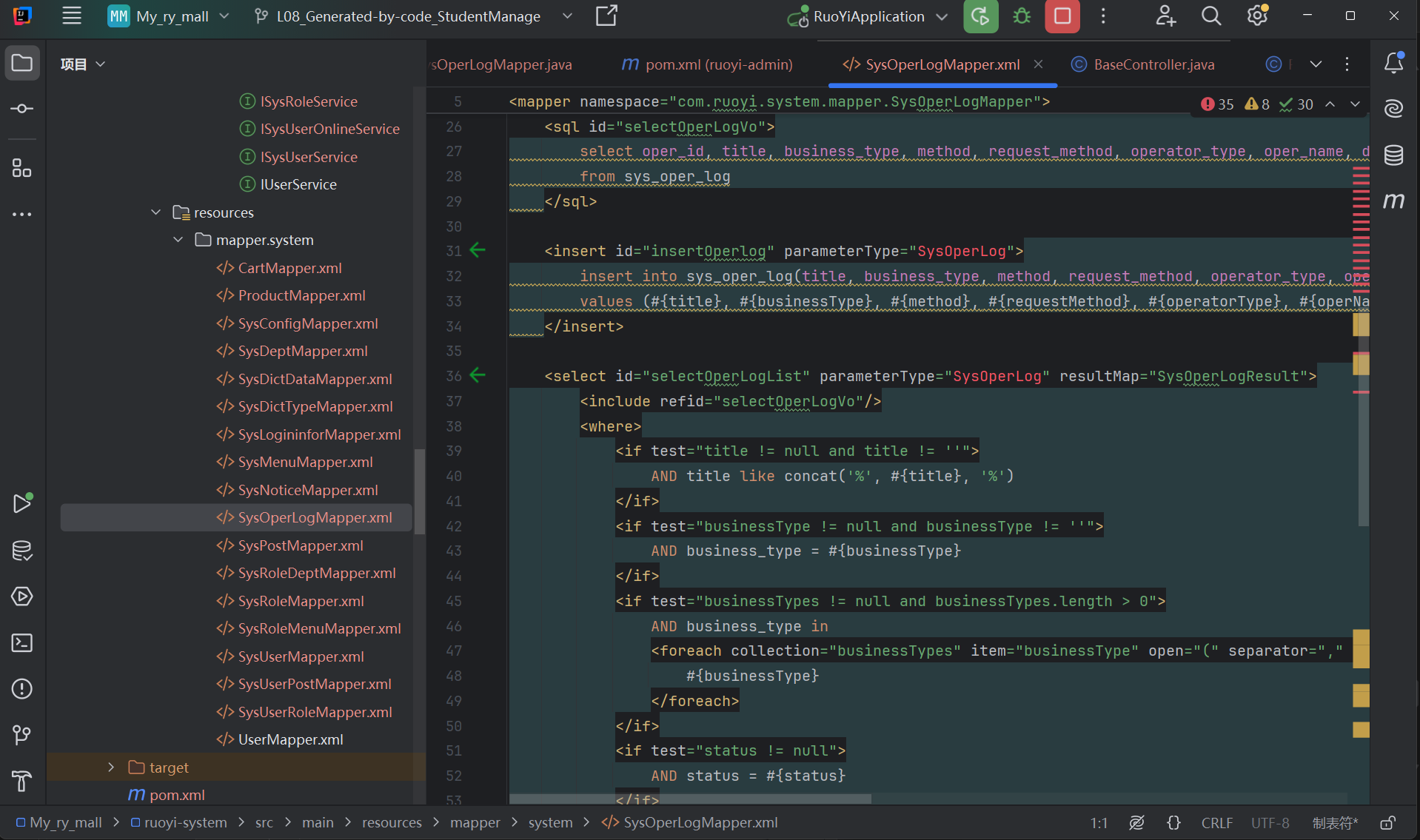
第二步: 执行查询:selectOperLogList

疑问:为什么只写了查询所有,它却知道要去查 total 并分页?
解决:(代码追踪)
- Service层——把任务直接交给Mapper层,JVM并没有直接执行java办法,而是调用了Mybatis生成的代理对象
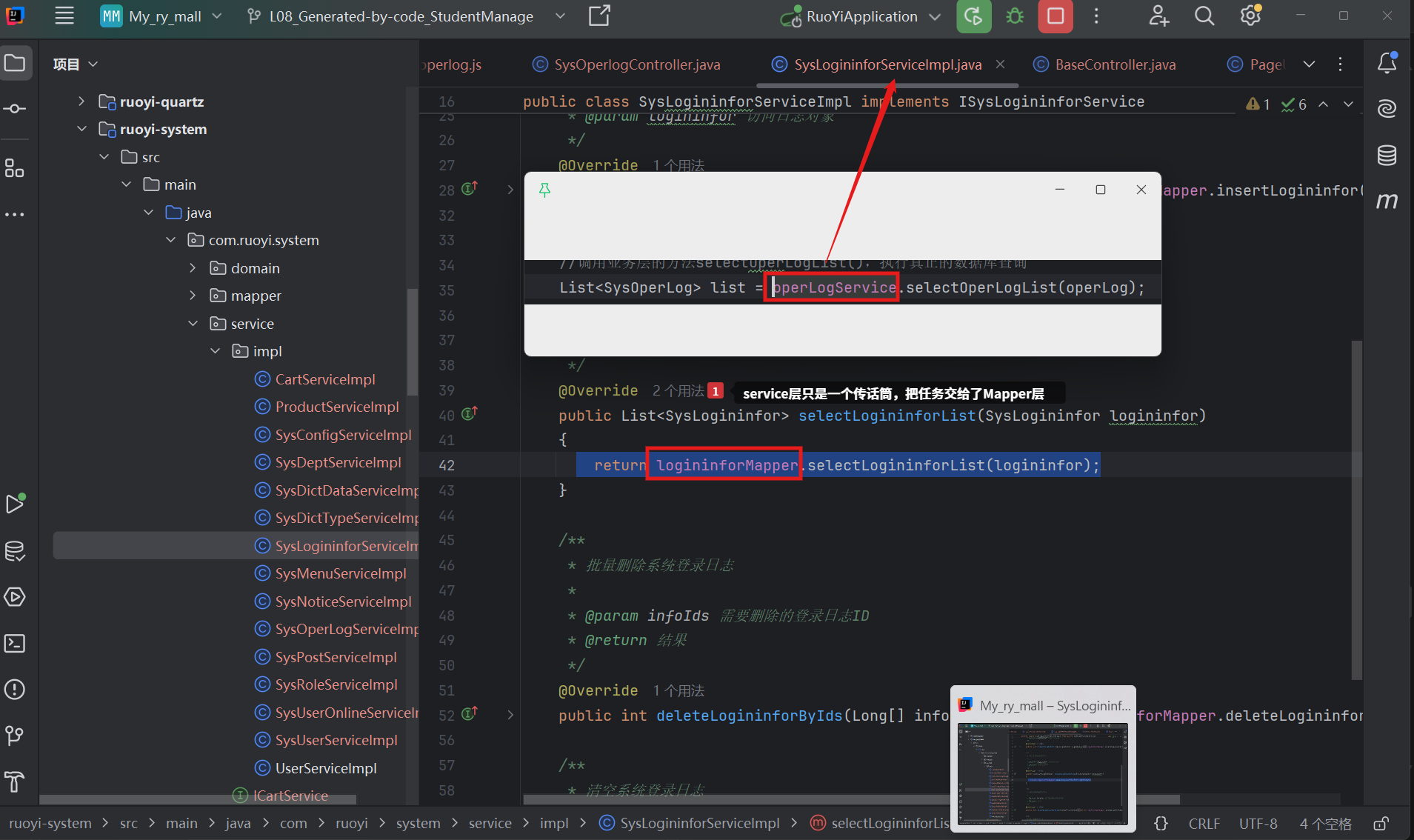
- Mapper层——准备要去执行SQL
- 拦截器——PageHelper 插件——
PageInterceptor.java(在 jar 包里)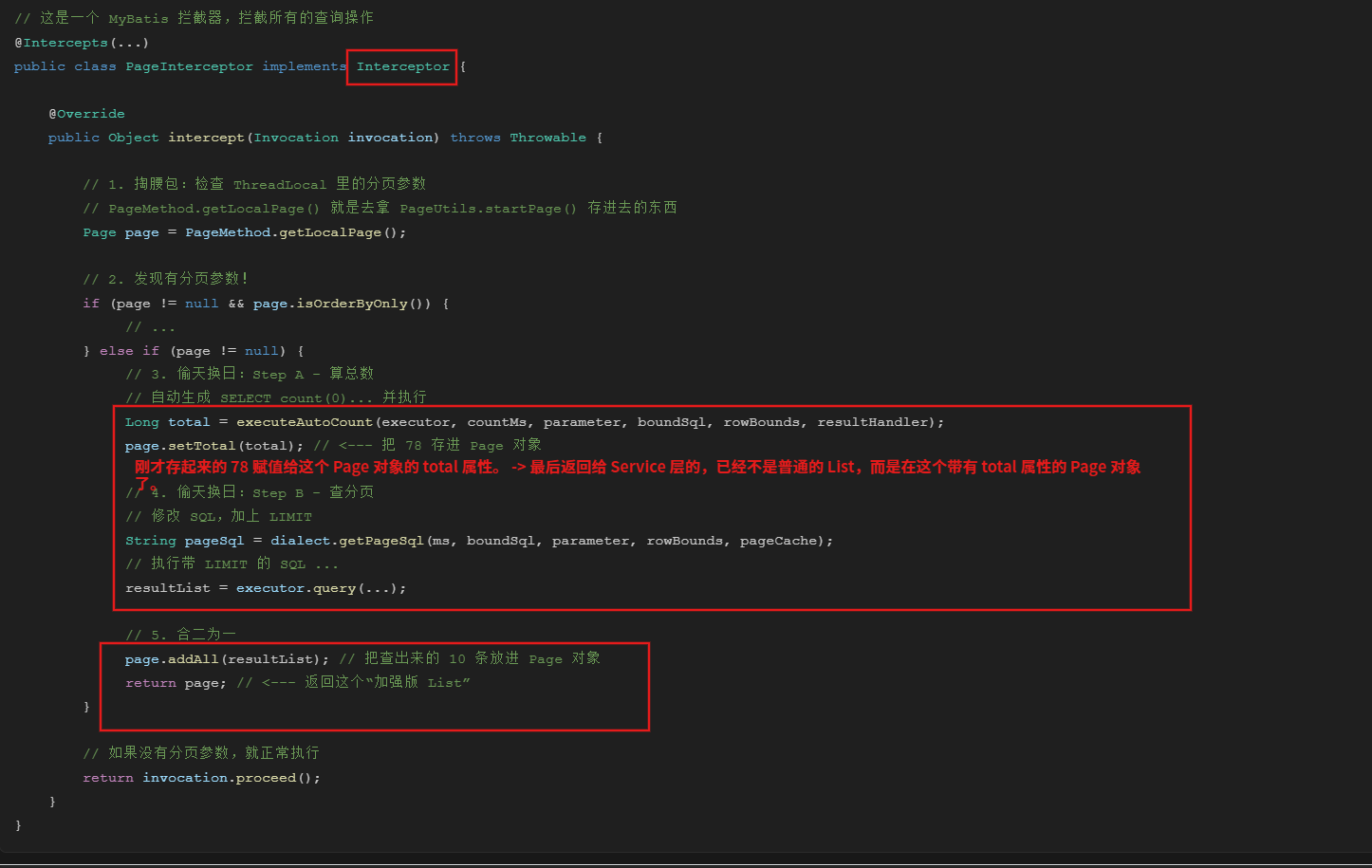
- 分析日志
pageHelper计算总数:
查询数据(The Query):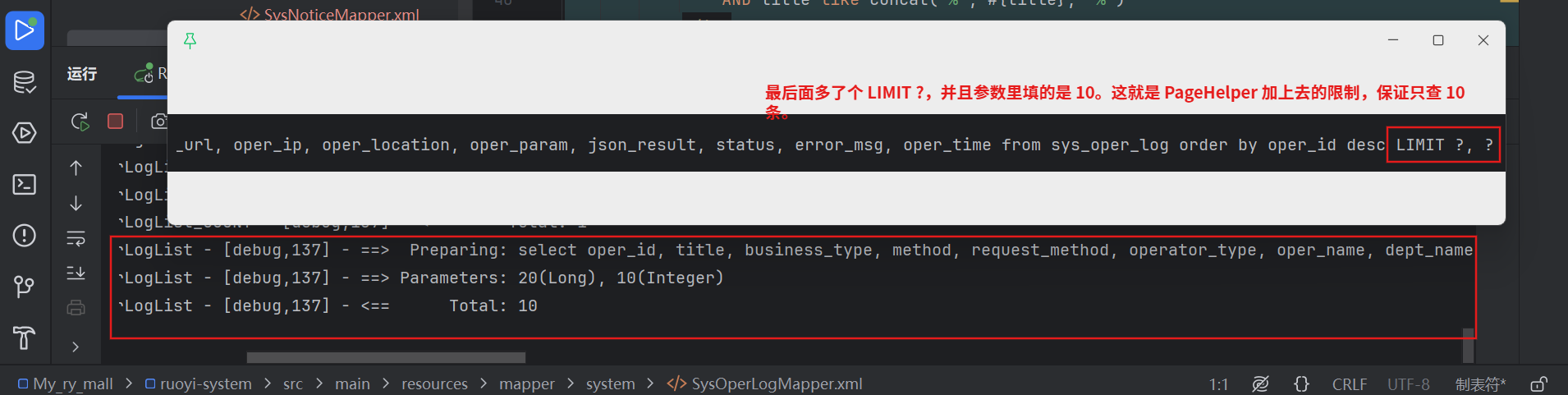
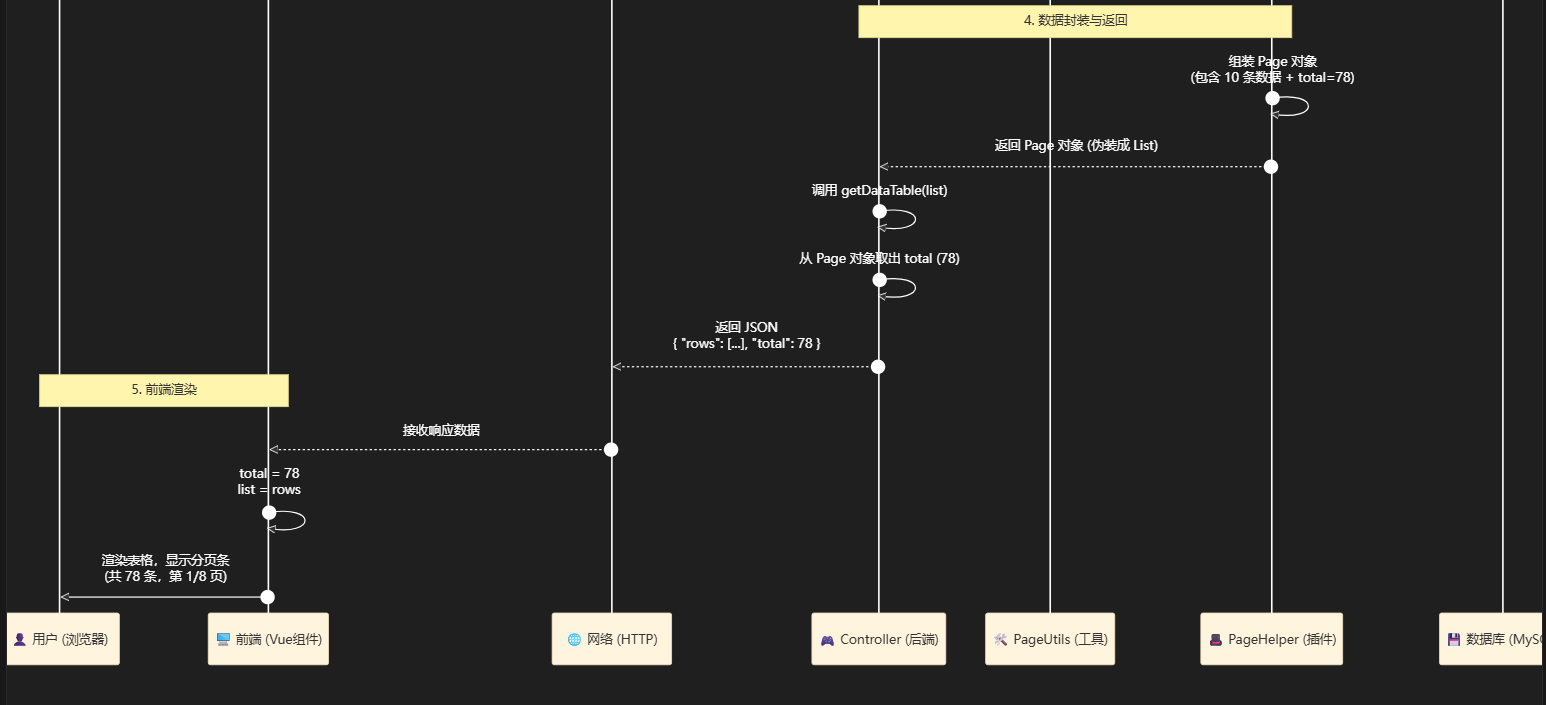
第三步:包装结果 getDataTable —— 取出 total
疑问:getDataTable 是怎么找到 total
解决:(代码追踪)
BaseController.java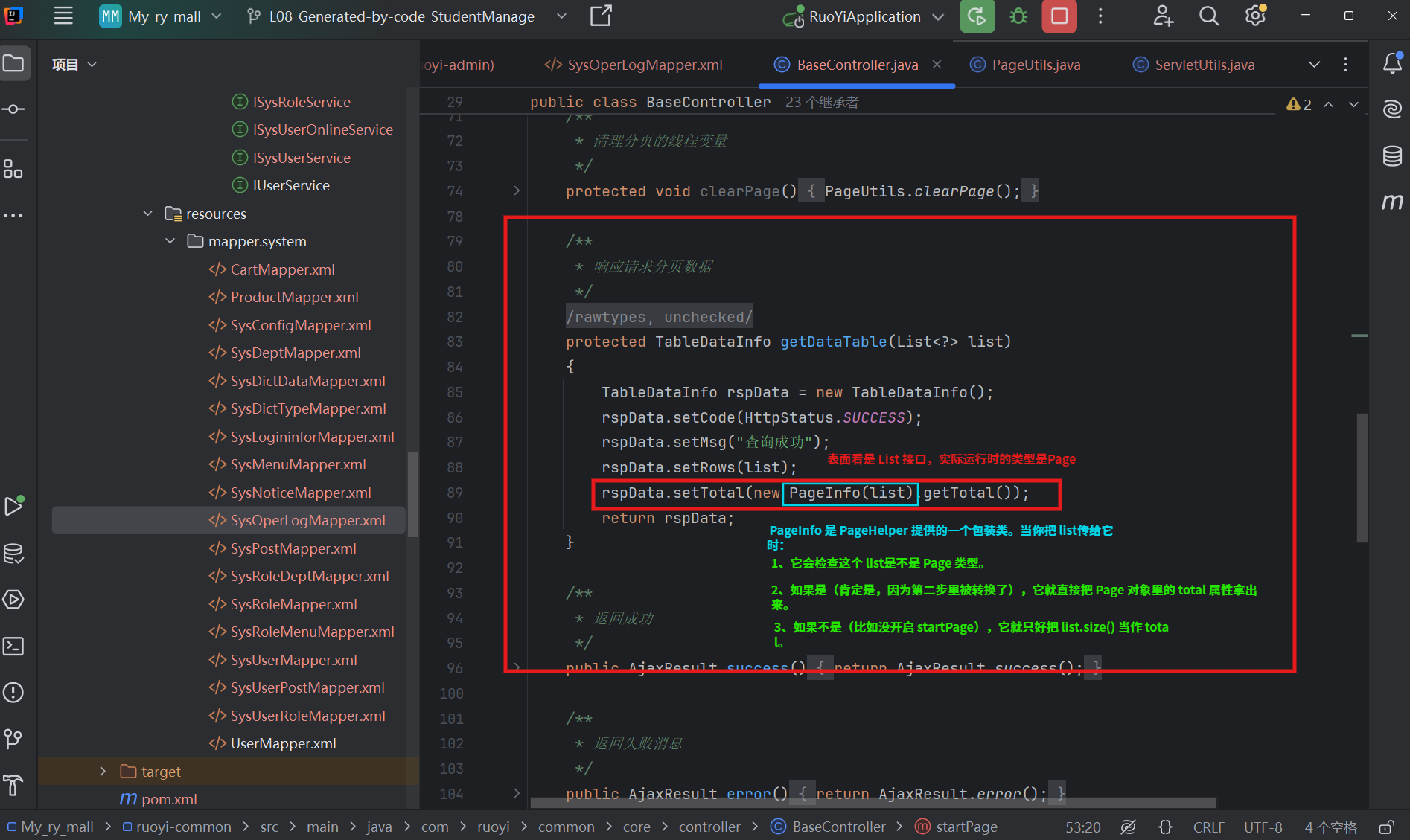
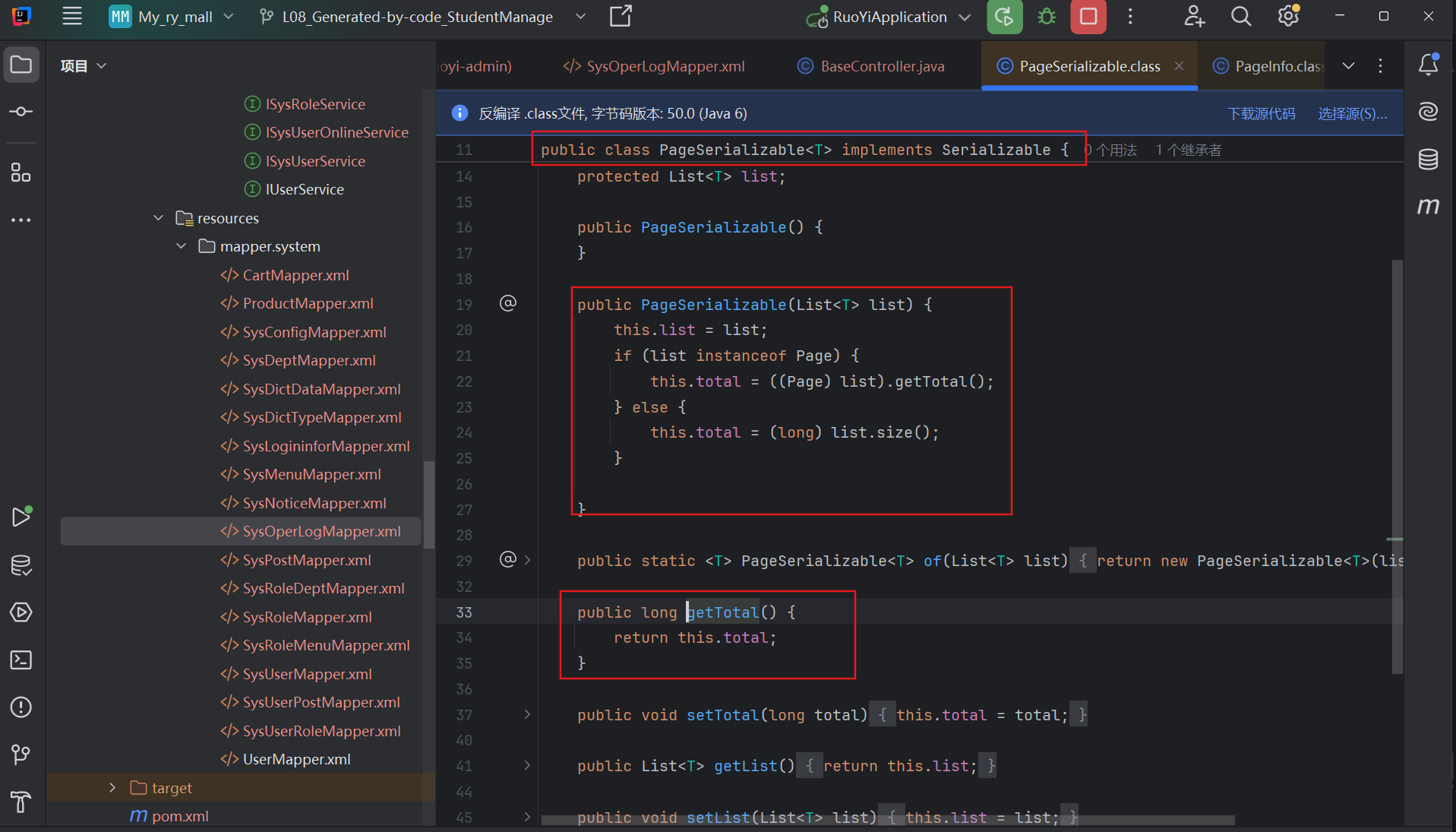
- 最后,
rspData这个对象被转换成 JSON: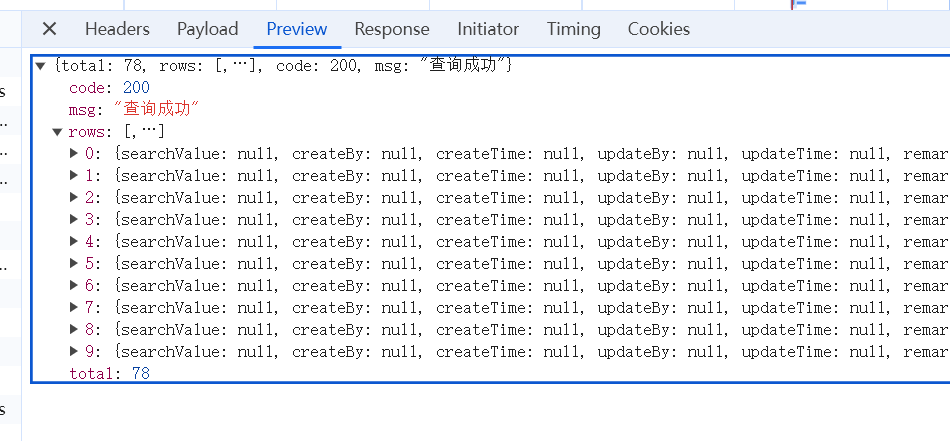
前端收到JSON对象,任务闭环
第四步总结:
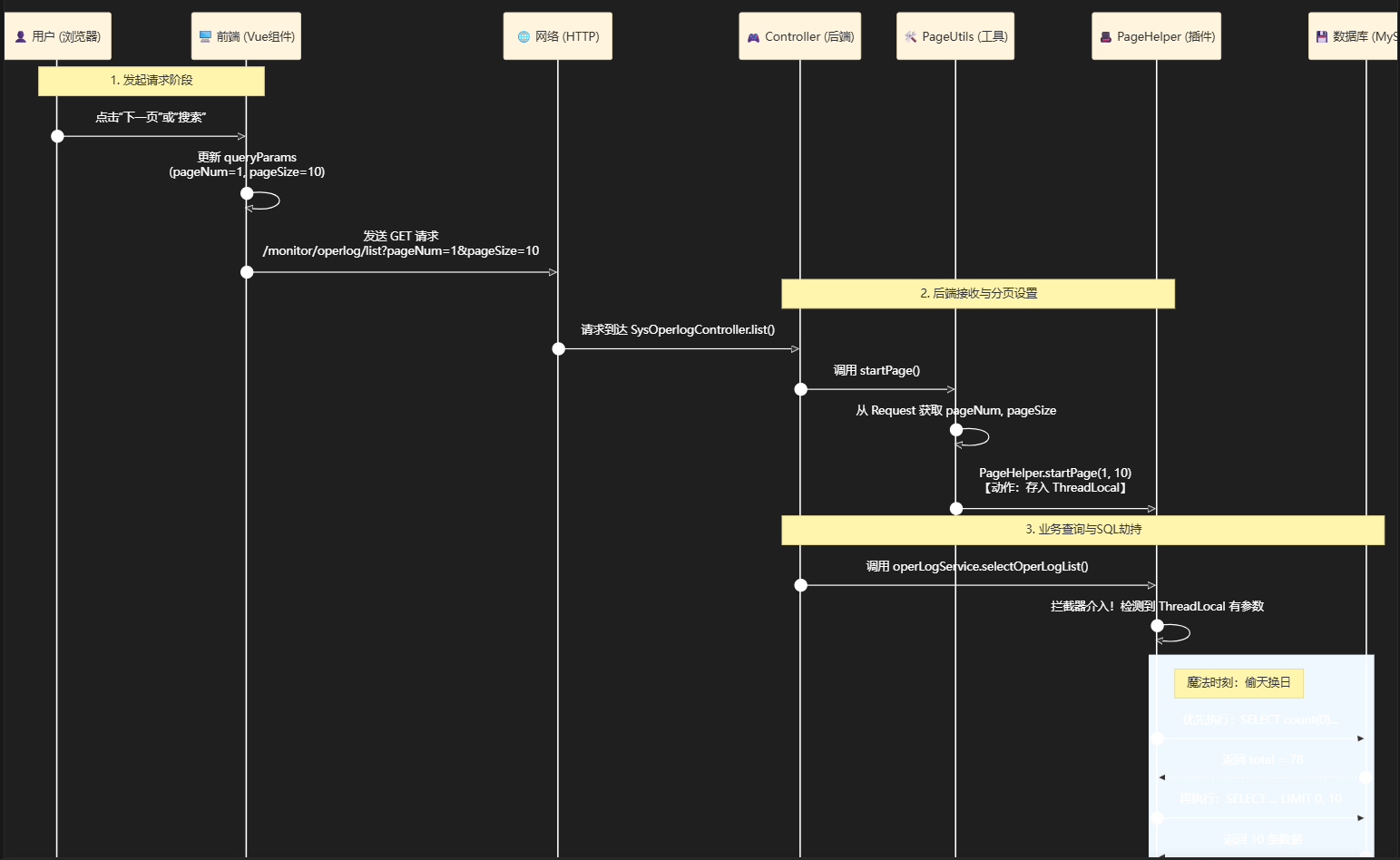
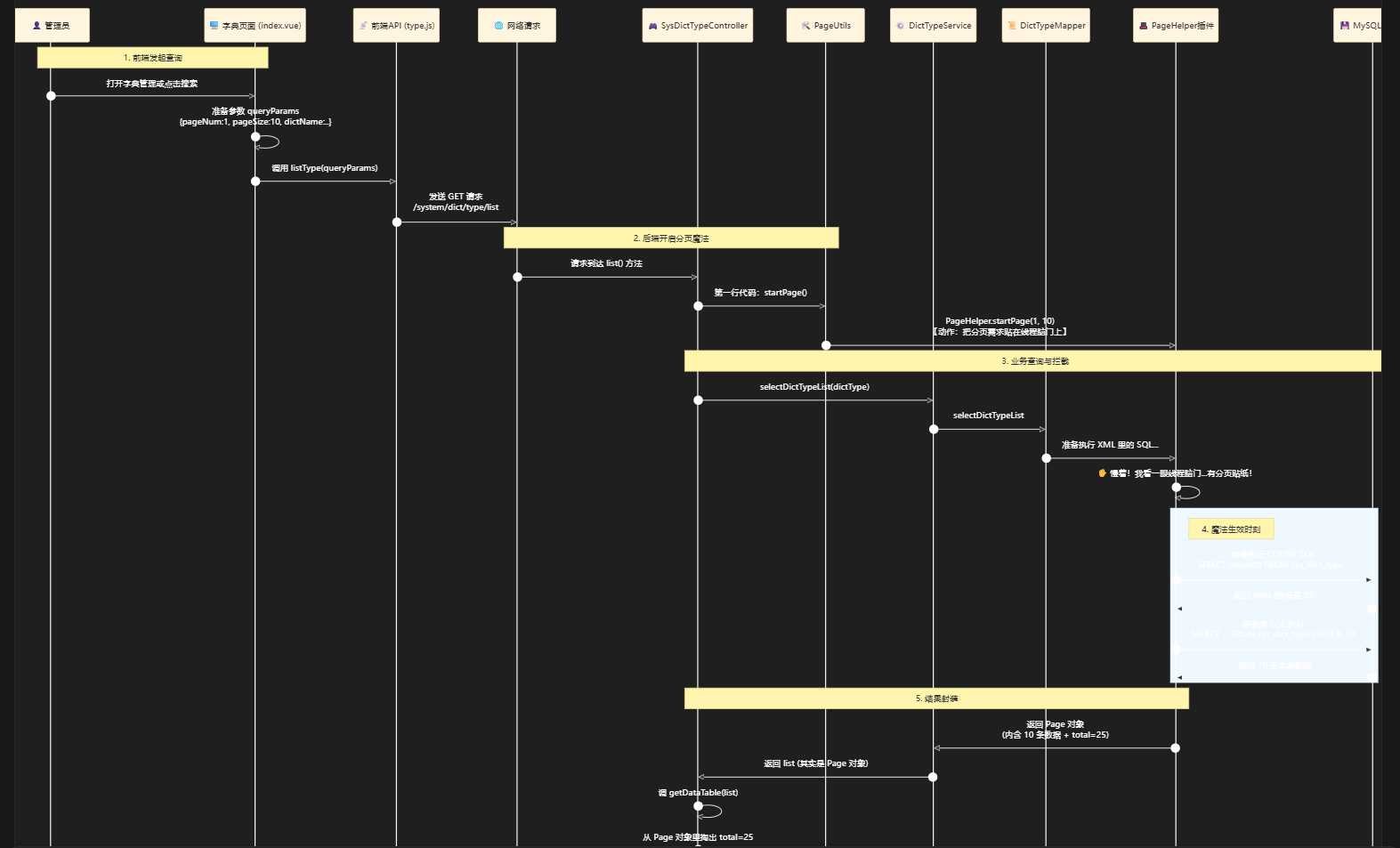
第三部分:源码分析——以若依系统中字典管理为例
——和第二部分一样
第一步:前端分页处理(Vue页面)
定义前端发给后端的“信使-参数”
后端回信:总条数-total
用户管理:点击上一页或下一页等触发getList()方法
那么用户操作在哪里展示了?——分页组件(pagination)
第二步:网络拦截
第三步:后端分页处理
根据接口找到后端代码——ISysOperlogController.java
- 开启分页startPage()
- 执行查询
- 包装结构
这三部分的深入解析和第二部分的完全一样(所以这里不做重复赘述)
第四步:总结
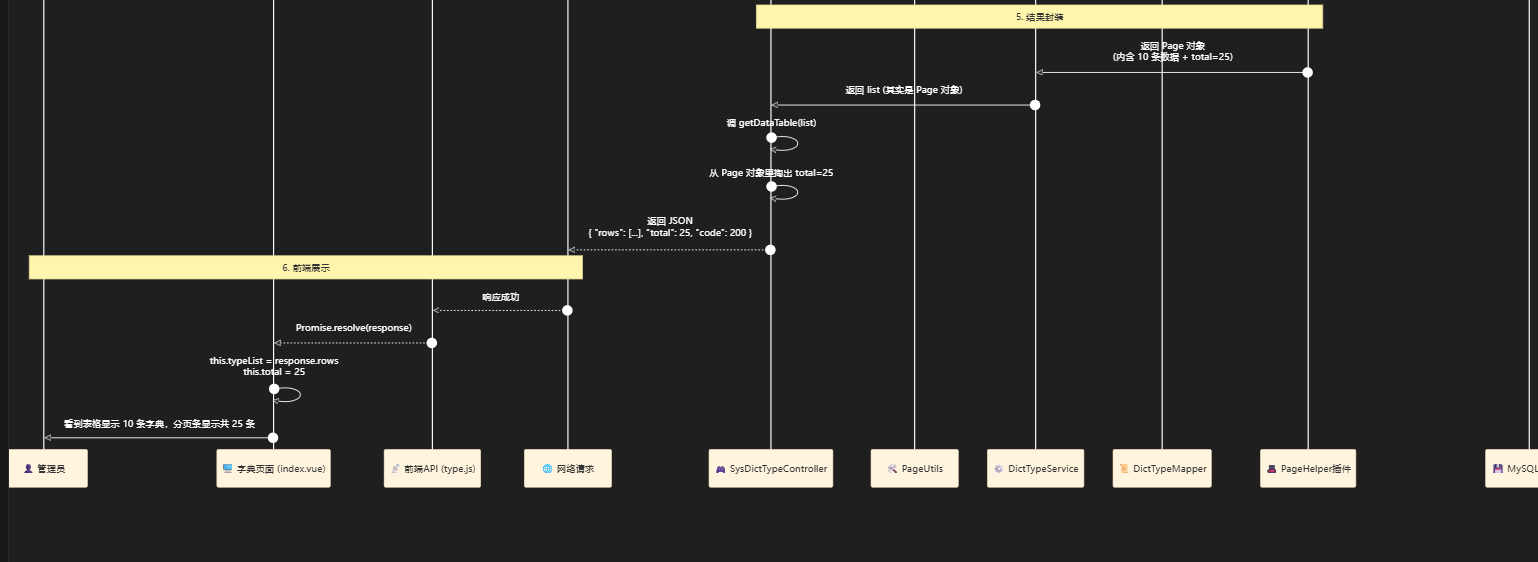
第四部分:模仿类Page,自定义一个类MyPage
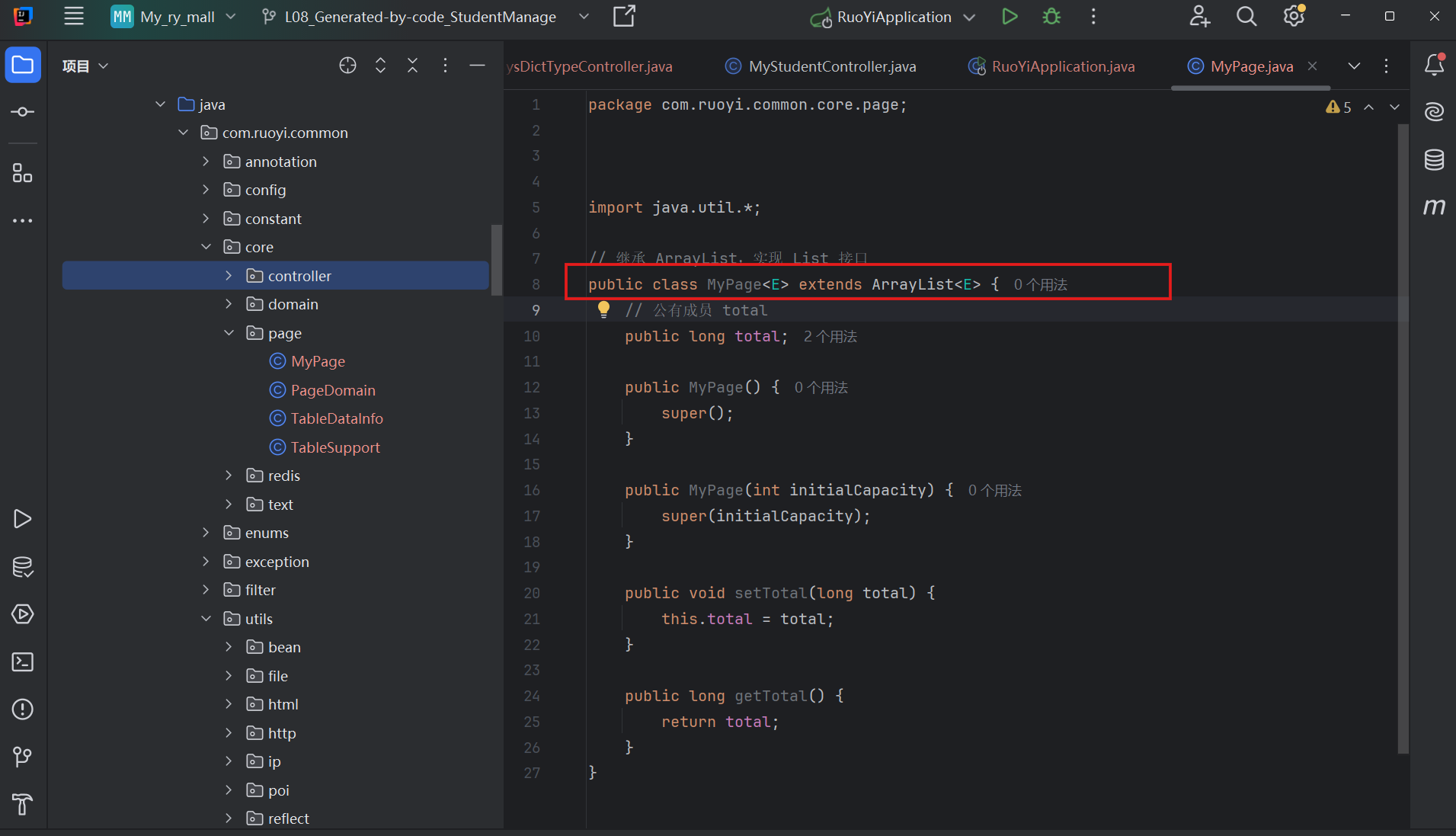
1、创建 MyPage 类:继承 ArrayList,增加 total 属性
- 路径:
ruoyi-common/src/main/java/com/ruoyi/common/core/page/MyPage.java
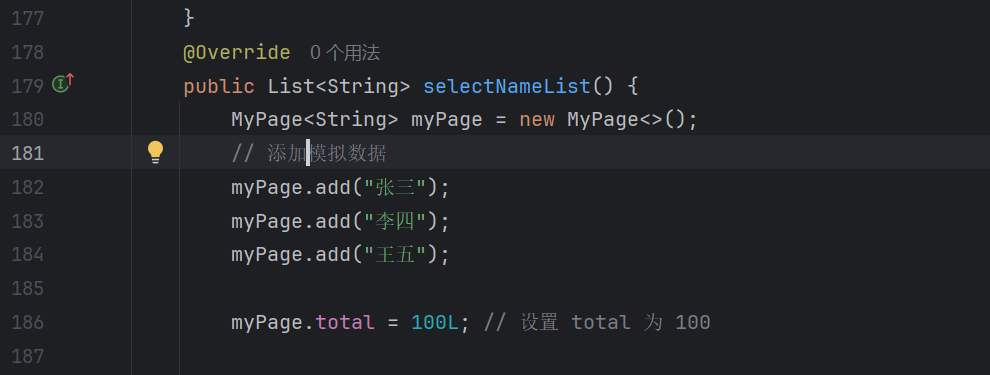
2、在 Service 层添加 selectNameList()
- 路径:ruoyi-system/src/main/java/com/ruoyi/system/service/impl/SysUserServiceImpl.java
同时在接口中声明(ISysUserService.java):

3、在 Controller 中暴露接口
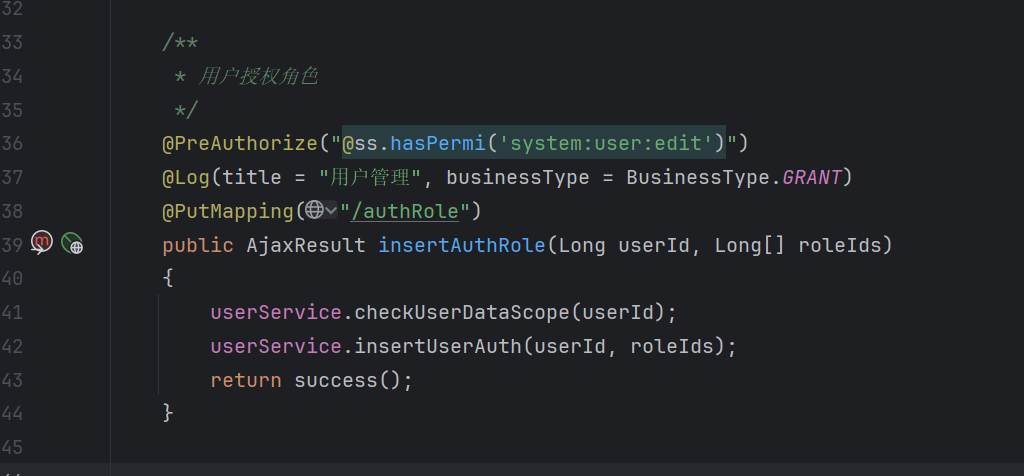
⚠️ 注意:必须用 getDataTable(list),因为它是提取 total 的关键!
4、改造 BaseController.getDataTable()(关键!)
打开:ruoyi-common/src/main/java/com/ruoyi/common/core/controller/BaseController.java
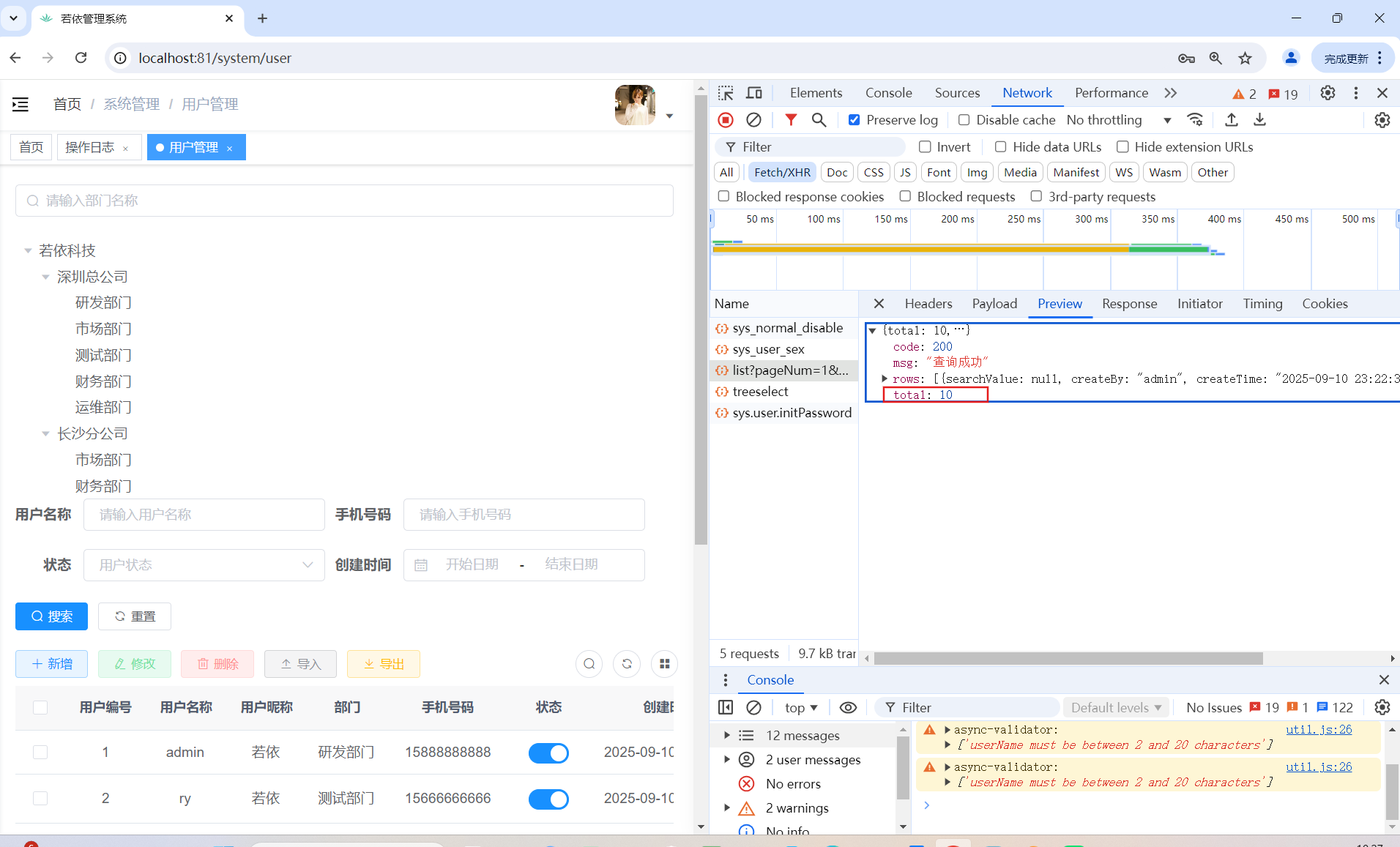
5、测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号