


C++ map 全面解析:从基础用法到实战技巧 - 指南

个人主页:Cx330
❄️个人专栏:《C语言》《LeetCode刷题集》《数据结构-初阶》《C++知识分享》
《优选算法指南-必刷经典100题》《Linux操作系统》:从入门到入魔
心向往之行必能至
Cx330的简介:

目录
前言:
在 C++ 标准库的容器中,
std::map是一款兼具有序性和高效查找的核心容器,广泛应用于字典映射、配置存储、数据去重等场景。它基于红黑树(平衡二叉搜索树)实现,既能保证键(key)的唯一性,又能自动对键进行排序,是开发中不可或缺的工具。本文将从基础概念到进阶实战,带你全面掌握std::map的用法
一、map 核心概念与特性
1. 什么是 map?
std::map是一种关联容器,存储的是键值对(key-value pair) 集合。其核心特点是:
- 键(key)唯一:不允许重复的键,插入重复键会失败(或覆盖,取决于用法);
- 自动排序:默认按键的升序排列(可自定义排序规则);
- 底层实现:基于红黑树,插入、查找、删除的时间复杂度均为 O(log n)(n 为元素个数);
std::map参考文档:map - C++ Reference
2. 头文件与命名空间
使用 map 需包含头文件 <map>,并使用 std 命名空间(或显式指定 std::map):
#include 3. map模板参数与内部类型
// map 模板定义
template , // 键的比较方式(默认升序)
class Alloc = allocator> // 空间配置器
> class map;
// 核心内部类型
typedef pair value_type; // 红黑树节点存储的键值对(Key 不可改)
typedef Key key_type; // 键的类型
typedef T mapped_type; // 值的类型 
value_type:map 存储的是 pair<const Key, T> 类型,其中 Key 被 const 修饰,意味着不能通过迭代器修改 Key(会破坏红黑树结构),但可以修改 T(Value)
Compare:默认用 less<Key> 实现升序,若需降序,可传入 greater<Key>(如 map<int, int, greater<int>>)
pair文档:pair - C++ Reference
4. 常见初始化方式:
// 1. 空 map(默认键升序)
map m1;
// 2. 初始化列表(C++11 及以上)
map m2 = {
{1, "apple"},
{2, "banana"},
{3, "cherry"}
};
// 3. 拷贝构造
map m3(m2);
// 4. 范围构造(从迭代器区间拷贝)
map m4(m2.begin(), m2.end());
// 5. 自定义排序规则(降序)
map> m5 = {{1, "a"}, {2, "b"}}; // 结果:2→b, 1→a 二、map 基础用法(必备知识点)
2.1 构造与初始化
map 支持多种构造方式,包括默认构造、迭代器区间构造、初始化列表构造等,实际开发中初始化列表构造最常用:
#include
#include 
注意: dict 遍历结果按 Key 升序排列(left < right < sort,按 ASCII 码比较),体现 map 自动排序特性
2.2 遍历
map的迭代器是双向迭代器,支持 ++/-- 操作,遍历方式包括 “迭代器循环”“范围 for”“结构化绑定”,其中结构化绑定(C++17+)最简洁:
1. 迭代器遍历(三种方式):
如上图,我们采取的就是迭代器遍历的方式,再给大家展示一遍:
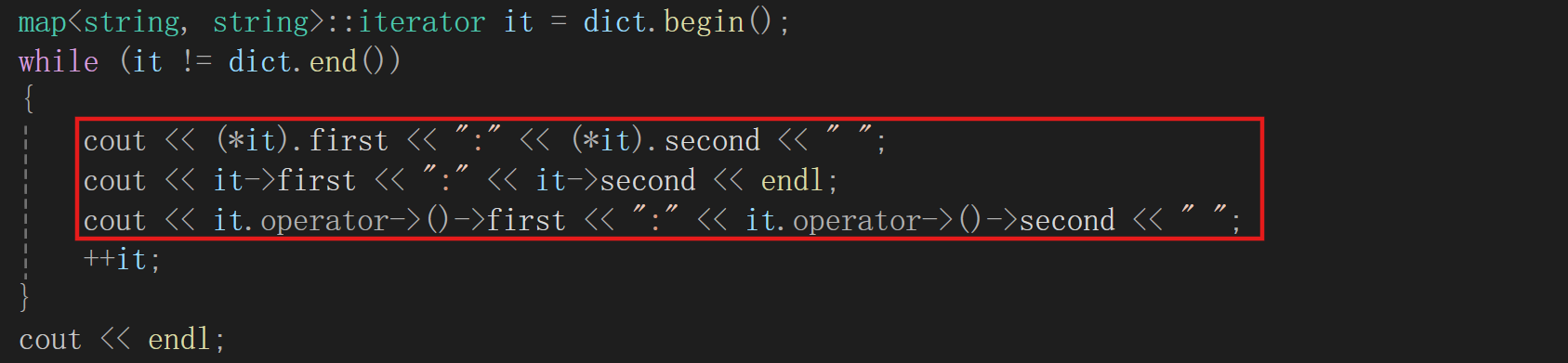
核心细节:
map的iterator和const_iterator都不能修改 Key,但iterator可以修改 Value;若只需读取,优先用const auto&传引用,避免拷贝开销
注意:这三种方式任选其一即可
2. 范围for遍历

3. 结构化绑定(C++17支持):

2.3 插入操作(insert):
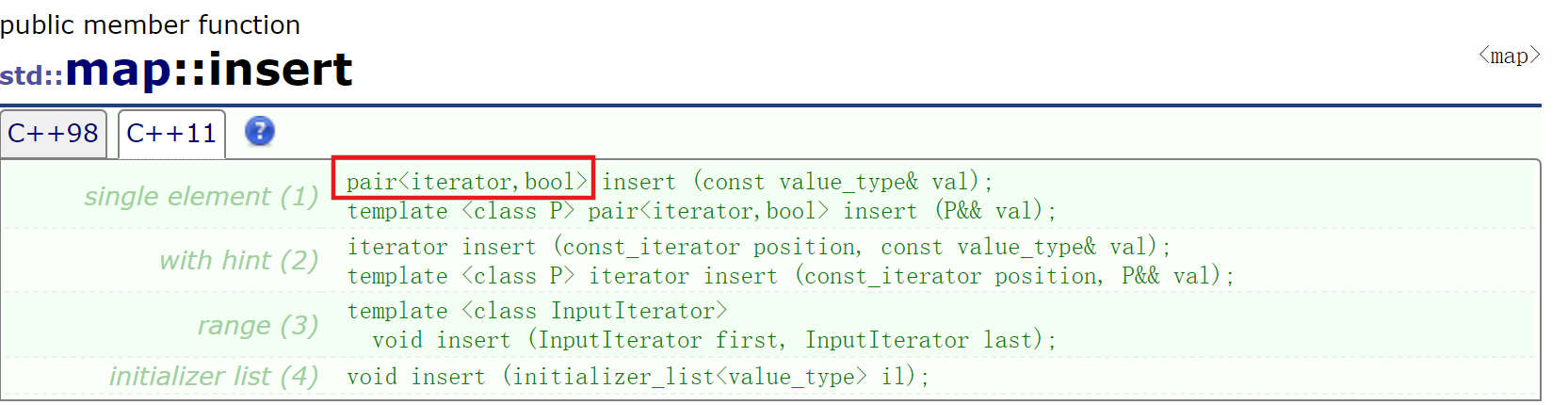
map 的 insert 接口用于插入键值对,返回 pair<iterator, bool>,其中:
iterator:指向插入成功的新节点,或已存在的相同 Key 节点;bool:true 表示插入成功,false 表示 Key 已存在、插入失败

#include
#include 
2.4 查找与删除(find/erase)
(1)查找:find 与 count
find(Key):查找指定 Key,返回指向该 Key 的迭代器;若不存在,返回 end()(O(log N) 效率);count(Key):返回 Key 的出现次数(map 中 Key 唯一,故返回 0 或 1,可间接用于查找)
2)删除:eraseerase支持三种删除形式:删除指定迭代器、删除指定 Key、删除迭代器区间,其中 “删除迭代器” 需先通过 find 确认 Key 存在,避免删除 end() 崩溃:
void test_map03()
{
map dict =
{
{"sort", "排序"}, {"left", "左边"}, {"right", "右边"}
};
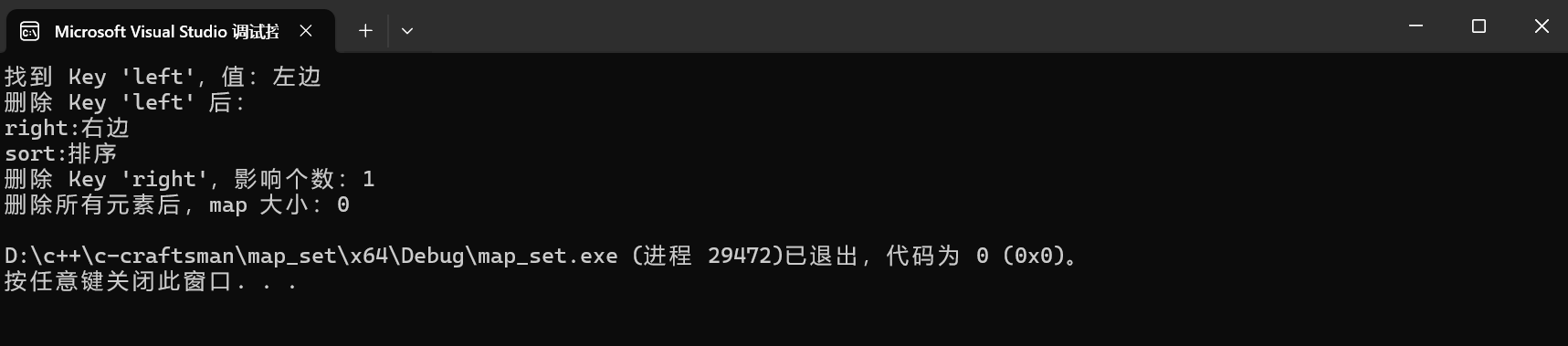
// 1. 查找 Key 'left'
auto pos = dict.find("left");
if (pos != dict.end())
{
cout << "找到 Key 'left',值:" << pos->second << endl;
// 2. 删除迭代器指向的节点(安全删除)
dict.erase(pos);
cout << "删除 Key 'left' 后:" << endl;
for (const auto& [k, v] : dict)
{
cout << k << ":" << v << endl;
}
}
// 3. 直接删除指定 Key(返回删除的个数,map 中 0 或 1)
size_t del_cnt = dict.erase("right");
cout << "删除 Key 'right',影响个数:" << del_cnt << endl;
// 4. 删除迭代器区间(删除所有元素)
dict.erase(dict.begin(), dict.end());
cout << "删除所有元素后,map 大小:" << dict.size() << endl;
}
int main()
{
//test_map01();
//test_map1();
test_map03();
//test_map2();
//test_map3();
return 0;
} 
2.5 核心特性:operator [] 的多功能性
map 的 operator[]是最灵活的接口,兼具 “插入、查找、修改” 三种功能,其内部实现依赖 insert,逻辑如下:
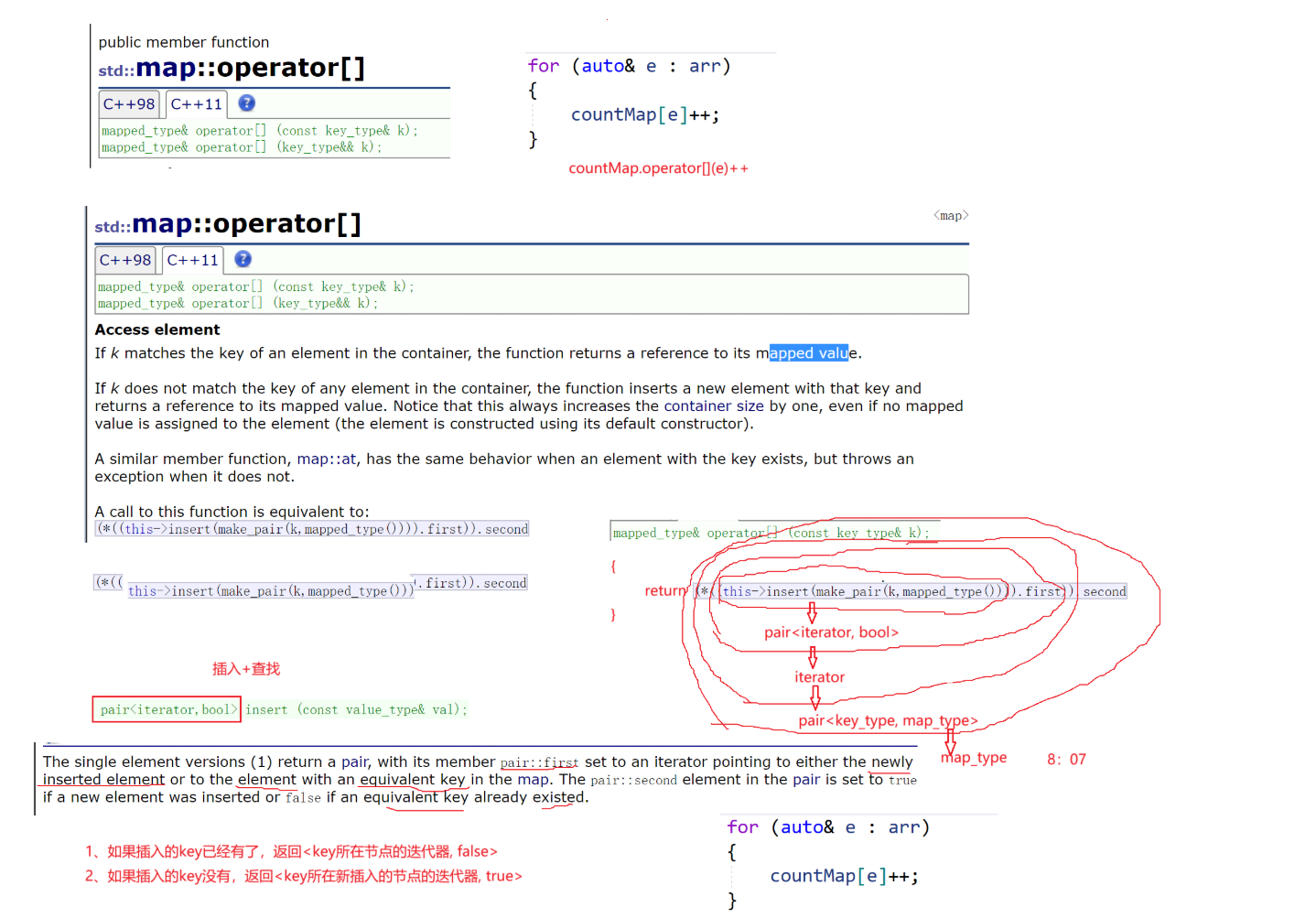
void test_map5()
{
map countMap; // 统计水果出现次数
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "香蕉" };
// 这样很麻烦
//for (auto& e : arr)
//{
// auto it = countMap.find(e);
// if (it != countMap.end())
// {
// it->second++;
// }
// else
// {
// countMap.insert({ e,1 });
// }
//}
// 场景1:插入 + 修改(统计次数,最常用)
for (const auto& fruit : arr)
{
// 若 fruit 不存在:插入 {fruit, 0},返回 0 的引用,++ 后变为 1;
// 若 fruit 已存在:返回现有 Value 的引用,++ 后次数增加;
countMap[fruit]++;
}
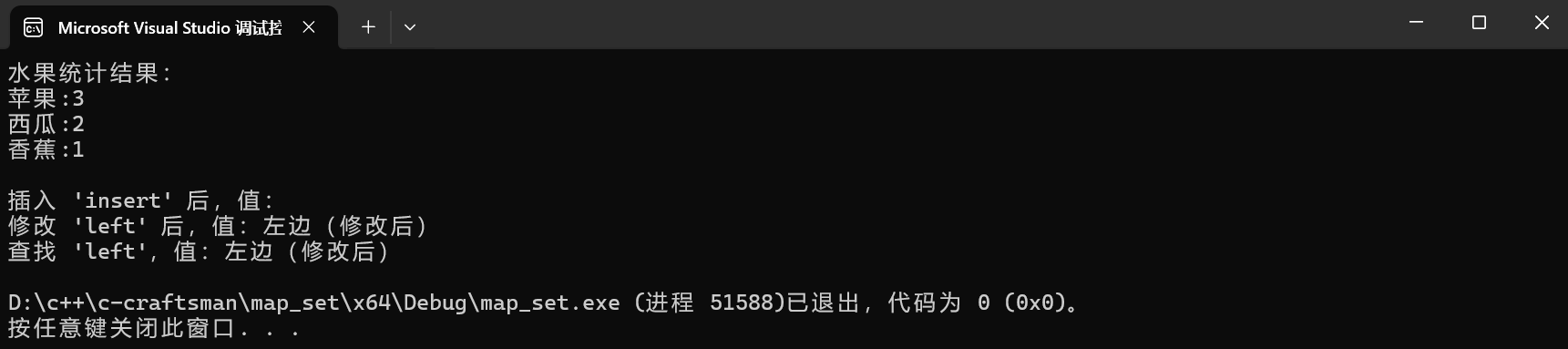
cout << "水果统计结果:" << endl;
for (const auto& [fruit, cnt] : countMap)
{
cout << fruit << ":" << cnt << endl;
}
cout << endl;
// 场景2:纯粹插入(Key 不存在时,插入默认 Value)
map dict;
dict["insert"]; // 插入 { "insert", "" }(string 默认空)
cout << "插入 'insert' 后,值:" << dict["insert"] << endl;
// 场景3:插入 + 修改(Key 不存在时插入,存在时修改)
dict["left"] = "左边"; // 插入 { "left", "左边" }
dict["left"] = "左边(修改后)"; // 修改 Value 为 "左边(修改后)"
cout << "修改 'left' 后,值:" << dict["left"] << endl;
// 场景4:纯粹查找(Key 存在时,返回 Value 引用)
cout << "查找 'left',值:" << dict["left"] << endl;
// 对比:at() 接口(仅支持查找+修改,Key 不存在时抛异常,不插入)
dict.at("left") = "左边(at 修改)"; // 合法,修改 Value
// dict.at("nonexist") = "不存在"; // 抛出异常:out_of_range
}
int main()
{
test_map5();
} 
关键区别:operator[]在 Key 不存在时会插入默认值,而 at() 会抛异常;若需 “严格查找”(不存在时不插入),优先用 find;若需 “统计次数”“快速赋值”,优先用 operator[]
三. map 与 multimap 的差异
multimap 和 map 的使用基本完全类似,主要区别点在于 multimap 支持关键值 key 冗余,那么 insert/find/count/erase 都围绕着支持关键值 key 冗余有所差异,这里跟 set 和 multiset 完全一样,比如 find 时,有多个 key,返回中序第一个。其次就是 multimap 不支持 [],因为支持 key 冗余,[] 就只能支持插入了,不能支持修改
最佳实践:
void test_multimap()
{
//multimap没有[]
multimap dict;
dict.insert({ "right", "右边" });
dict.insert({ "left", "左边" });
dict.insert({ "right", "右边xx" });
dict.insert({ "right", "右边" });
for (const auto& [k, v] : dict)
{
cout << k << ":" << v << endl;
}
cout << endl;
}
int main()
{
test_multimap();
} 
四、实战技巧:map经典例题
4.1 随机链表的复制
题目链接:
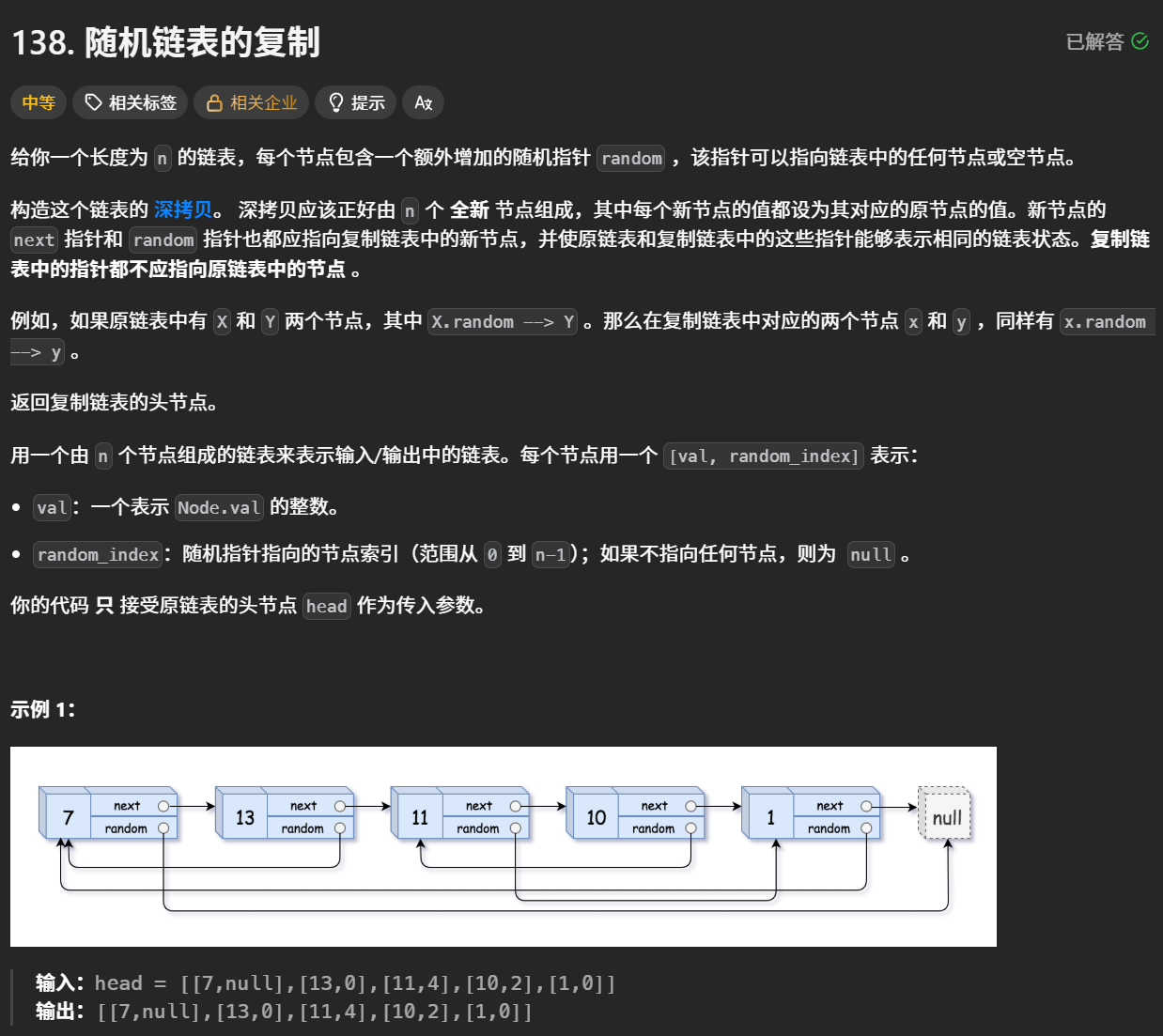
数据结构初阶阶段,为了控制随机指针,我们将拷贝结点链接在原节点的后面解决,后面拷贝节点还得解下来链接,非常麻烦,我们直接让 {原节点,拷贝节点}映射回到map容器,控制随机指
针会非常简单方便,这里体现了map在解决⼀些问题时的价值,完全是降维打击
代码实现:
class Solution {
public:
Node* copyRandomList(Node* head) {
map NodeMap;
Node*copyhead=nullptr,*copytail=nullptr;
Node*cur=head;
while(cur)
{
if(copyhead==nullptr)
{
copyhead=copytail=new Node(cur->val);
}
else{
copytail->next=new Node(cur->val);
copytail=copytail->next;
}
//原节点和拷贝节点通过map,kv存储
NodeMap.insert({cur,copytail});
cur=cur->next;
}
//处理random
cur=head;
Node* copy = copyhead;
while(cur)
{
if(cur->random==nullptr)
copy->random = nullptr;
else
// 查找
copy->random=NodeMap[cur->random];
cur=cur->next;
copy=copy->next;
}
return copyhead;
}
}; 4.2 前k个高频单词
题目链接:

用排序找前k个单词,因为map中已经对key单词排序过,也就意味着遍历map时,次数相同的单词,字典序小的在前面,字典序大的在后面,那么我们将数据放到vector中用一个稳定的排序就可以实现上面特殊要求,但是 sort底层是快排 ,是不稳定的,所以我们要用 stable_sort,他是稳定的
class Solution {
public:
struct kv_pair
{
bool operator()(const pair& x, const pair& y)
{
return x.second > y.second;
}
};
vector topKFrequent(vector& words, int k) {
map CountMap;
for(auto& e:words)
{
CountMap[e]++;
}
vector> v(CountMap.begin(),CountMap.end());
//sort(v.begin(),v.end(),kv_pair());
// 得稳定排序
stable_sort(v.begin(),v.end(),kv_pair());
vector ret;
for(size_t i=0;i
思路2:(vector 与 priority_queue)
将map统计出的次数的数据放到vector中排序,或者放到priority_queue中来选出前k个。利用仿函数强行控制次数相等的,字典序小的在前面
解法一:vector
class Solution {
public:
struct kv_pair
{
// 次数多的在前面,次数相等的时候,字典序小的在前面
bool operator()(const pair& x, const pair& y)
{
return x.second > y.second || (x.second == y.second && x.first < y.first);
}
};
vector topKFrequent(vector& words, int k) {
map CountMap;
for(auto& e:words)
{
CountMap[e]++;
}
vector> v(CountMap.begin(),CountMap.end());
sort(v.begin(),v.end(),kv_pair());
vector ret;
for(size_t i=0;i
解法二:priority_queue:
class Solution {
public:
struct kv_pair
{
// 次数多的在前面,次数相等的时候,字典序小的在前面
bool operator()(const pair& x, const pair& y)
{
// 要注意优先级队列底层是反的,大堆要实现小于比较,所以这里次数相等,想要字典序小的在前面要比较字典序大的为真
return x.second < y.second || (x.second == y.second && x.first > y.first);
}
};
vector topKFrequent(vector& words, int k) {
map CountMap;
for(auto& e:words)
{
CountMap[e]++;
}
priority_queue,vector>,kv_pair> q(CountMap.begin(),CountMap.end());
vector ret;
for(size_t i=0;i
结尾:
往期回顾:
结语:std::map是 C++ 中兼具有序性和高效查找的关联容器,基于红黑树实现,核心优势是键唯一、自动排序、O (log n) 时间复杂度的增删改查,掌握 map 的用法,能让你在处理 “键值映射” 类问题时更高效、更简洁。根据实际场景选择 map 或unordered_map,结合本文技巧,可大幅提升代码质量和开发效率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号