


深入解析:Cambrian-S:迈向视频中的空间超感知
Cambrian-S:迈向视频中的空间超感知
摘要
https://arxiv.org/abs/2511.04670
不够的。我们提出预测性感知作为前进的路径,并展示了一个概念验证,其中自监督的下一潜在帧预测器利用惊奇(预测误差)来驱动记忆和事件分割。在VSi-SuPeR上,这种方法显著优于领先的专有基线,表明空间超感知需要的模型不仅要能"看见",还要能预测、选择和组织经验。就是我们认为,真正多模态智能的进展得从反应式、任务驱动的系统和暴力长上下文处理转向一个更广泛的超感知范式。我们将空间超感知定义为超越纯语言理解的四个阶段:语义感知(命名所见之物)、流事件认知(在连续体验中维持记忆)、隐式3D空间认知(推断像素背后的世界)以及预测性世界建模(创建过滤和组织信息的内部模型)。当前的基准测试主要只检验早期阶段,对空间认知的覆盖范围狭窄,并且很少以需要真正世界建模的方式来挑战模型。为了推动空间超感知的进展,我们提出了VSi-SupeR,一个包含两部分的基准:vSR(长视野视觉空间回忆)和vSC(连续视觉空间计数)。这些任务需要任意长的视频输入,但对暴力上下文扩展具有抵抗性。之后,我们通过整理VSi-590K数据集并训练Cambrian-S来测试数据扩展的极限,在VSI-Bench上实现了+30%的绝对性能提升,且未牺牲通用能力。然而,在VSI-SUPER上的表现仍然有限,表明仅靠规模扩展对于空间超感知
网站 https://cambrian-mllm.github.io
代码 https://github.com/cambrian-mllm/cambrian-s
Cambrian-S 模型 https://hf.co/collections/nyu-visionx/cambrian-s
VSI-590K 数据集 https://hf.co/datasets/nyu-visionx/vsi-590k
VSI-SUPER 基准 https://hf.co/collections/nyu-visionx/vsi-super
目录
1 引言 3
2 空间超感知基准测试 4
2.1 解构现有视频基准 …5
2.2 VSI-SUPER:迈向多模态LLM中的空间超感知基准测试 . … .6
3 当前范式下的空间感知 10
3.1 基础模型训练:升级版Cambrian-1 10
3.2 空间视频数据整理:VSI-590K .10
3.3 空间感知的后训练方法 . :12
3.4 Cambrian-S:空间接地的MLLMs 13
3.5 实证结果:改进的空间认知 14
4 预测性感知作为新范式 16
4.1 通过潜在帧预测进行预测性感知 .16
4.2 案例研究 I:用于VSI-SUPeR回忆的惊奇驱动记忆管理系统.17
4.3 案例研究 II:用于VSi-SuPER计数的惊奇驱动连续视频分割. . …19
5 相关工作 21
9 结论 22
参考文献 23
A 基准诊断测试结果 33
B VSI-SUPER基准 33
B.1 VSI-SUPER回忆 33
B.2 VSI-SUPER计数 34
C VSI-590K内容集 34
C.1 问题类型定义详情 . .34
C.2 详细的问答对构建流程…34
C.3 额外消融研究…36
C.4 VSI-590K示例 36
D Cambrian-S实现细节 36
D.1 模型架构 . .36
D.2 训练数据混合 36
D.3 训练方法 37
D.4 基础设施 39
E Cambrian-S额外结果 39
E.1 详细评估设置 39
E.2 在图像和视频基准上的详细性能…39
E.3 基于图像和基于视频的指令微调的贡献 .39
E.4 空间感知与通用视频理解之间的权衡 41
F 预测性感知 42
F.1 潜在帧预测搭建细节.42
F.2 VSI-SuPER回忆的记忆框架设计 F.3 VSI-SuPER计数的智能体框架设计 F.4 与现有长视频办法的比较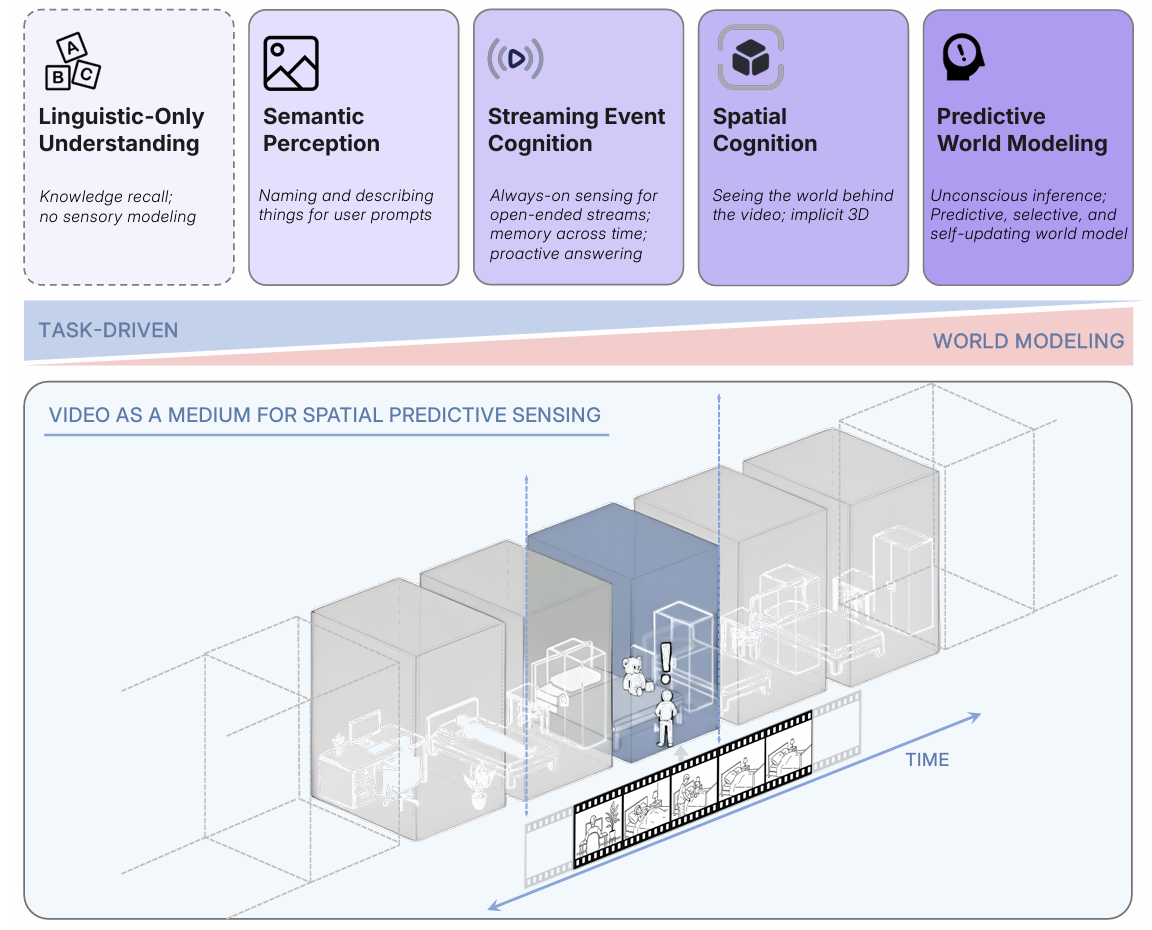
1. 引言
视频不仅仅是孤立的帧序列。它是一个隐藏的、不断演化的3D世界到像素的持续、高带宽投影[46, 90]。尽管多模态大语言模型(MLLMs)通过将强大的图像编码器与语言模型配对而迅速发展[1, 122, 3, 78, 124],但大多数视频扩展[137, 65, 9]仍然受到根本性限制。它们仍然将视频视为稀疏帧,未能充分表征空间结构和动态[148],并且严重依赖文本回忆[168],从而忽视了视频模态独特强大之处。
在本文中,我们认为,向真正的多模态智能迈进需要从以语言为中心的感知转向空间超感知:不仅能够看见,还能够从连续感官体验中构建、更新和预测一个隐式的3D世界模型。我们并非声称在此实现了超感知;相反,我们通过阐述可能引领此方向的发展路径,并展示沿此路径的早期原型,迈出了朝向它的第一步:
- (纯语言理解):无感官能力;推理局限于文本和符号。当前的MLLMs已经超越此阶段,但仍保留其偏见的痕迹。
- 语义感知:将像素解析为对象、属性和关系。这对应于MLLMs中存在的强大多模态"展示与讲述"能力。
- 流事件认知:处理实时的、无界的流,同时主动解释和响应正在进行的事件。这与将MLLMs打造成实时助手的努力相一致。
- 隐式3D空间认知:将视频理解为3D世界的投影。智能体必须知道存在什么、在哪里、事物如何关联以及配置如何随时间变化。今天的视频模型在这方面仍然有限。
- 预测性世界建模:大脑通过基于先验期望预测潜在世界状态来进行无意识推断[130]。当这些预测被违反时,惊奇引导注意力、记忆和学习[41, 120, 60]。然而,当前的多模态系统缺乏一个能够预测未来状态并利用惊奇来组织感知以用于记忆和决策的内部模型。
我们的论文分为三部分展开。首先(第2节),我们通过我们的超感知层次结构重新审视现有基准测试。我们发现大多数基准测试对应于前几个阶段,而一些基准测试,如VSI-Bench [148],开始探究空间推理。然而,没有一个基准测试充分涉及预测性世界建模这一关键的末了阶段。为了使这一差距具体化并激励方法的转变,我们引入了VSI-SuPeR(VSI代表视觉空间智能),这是一个用于空间超感知的两部分基准:VSi-SuPeR回忆(vSR)针对长视野空间观察和回忆,而VSi-SupeR计数(vSC)测试在不断变化的视角和场景下的连续计数。这些任务构建自任意长的时空视频,并刻意抵抗主流的多模态方法;它们要求感知具有选择性且结构化,而非不加区分地积累。我们展示了即使是最好的长上下文商业模型在VSi-SuPER上也表现挣扎。
一个材料问题。我们整理了VSi-590K,一个专注于空间的、涵盖图像和视频的指令微调语料库,并用它来训练Cambrian-S,一个空间接地的视频MLLM系列。在当前范式下,精细的内容设计和训练将Cambrian-S推向了VSI-Bench上最先进的空间认知水平(>30%绝对增益),且未牺牲通用能力。尽管如此,Cambrian-S在VSi-SupER上仍然表现不佳,表明虽然规模扩展奠定了关键基础,但仅靠它自身不足以达成空间超感知。就是其次(第3节),我们研究了空间超感知是否仅仅
这激发了第三也是最后一部分(第4节),大家提出预测性感知作为迈向新范式的第一步。我们展示了一个基于自监督下一潜在帧预测的概念验证解决方案。在这里,我们利用模型的预测误差,或称"惊奇",来实现两个关键功能:(1)依据将资源分配给意外事件来管理记忆;(2)事件分割,将无界的流分解为有意义的片段。我们证明,这种方法虽然方便,但在我们的两个新任务上显著优于强大的长上下文基线,如Gemini-2.5。尽管这不是最终解决方案,但这一结果为真正的超感知之路得模型不仅能"看见"而且能主动预测和学习世界提供了令人信服的证据。
我们的工作做出了以下贡献。(1)我们定义了空间超感知的层次结构,并引入了VSi-SuPER,一个揭示当前范式局限性的超感知基准。(2)我们开发了Cambrian-S,一个在空间认知方面达到最先进水平的模型。Cambrian-S作为一个强大的新基线,并通过在我们的新基准上界定当前方法的边界,为新范式铺平了道路。(3)我们提出预测性感知作为MLLMs一个有前景的新方向,表明利用模型惊奇对于长视野空间推理比被动上下文扩展更有效。
2. 空间超感知基准测试
为了夯实大家对空间超感知的追求,我们首先确立如何衡量它。本节对基准测试这种能力进行了两部分调查。我们首先审核了一系列流行的视频MLLM基准测试,我们的分析(图3)揭示了它们绝大多数侧重于语言理解和语义感知,而忽视了超感知所需的更高级的空间和时间推理(第2.1节)。为了弥补这一关键差距,我们随后引入了VSi-SuPER,一个专门设计用于探究这些更困难的、连续的空间智能方面的新基准测试(第2.2节)。我们在本文余下部分使用该基准测试来测试当前MLLM范式的极限。
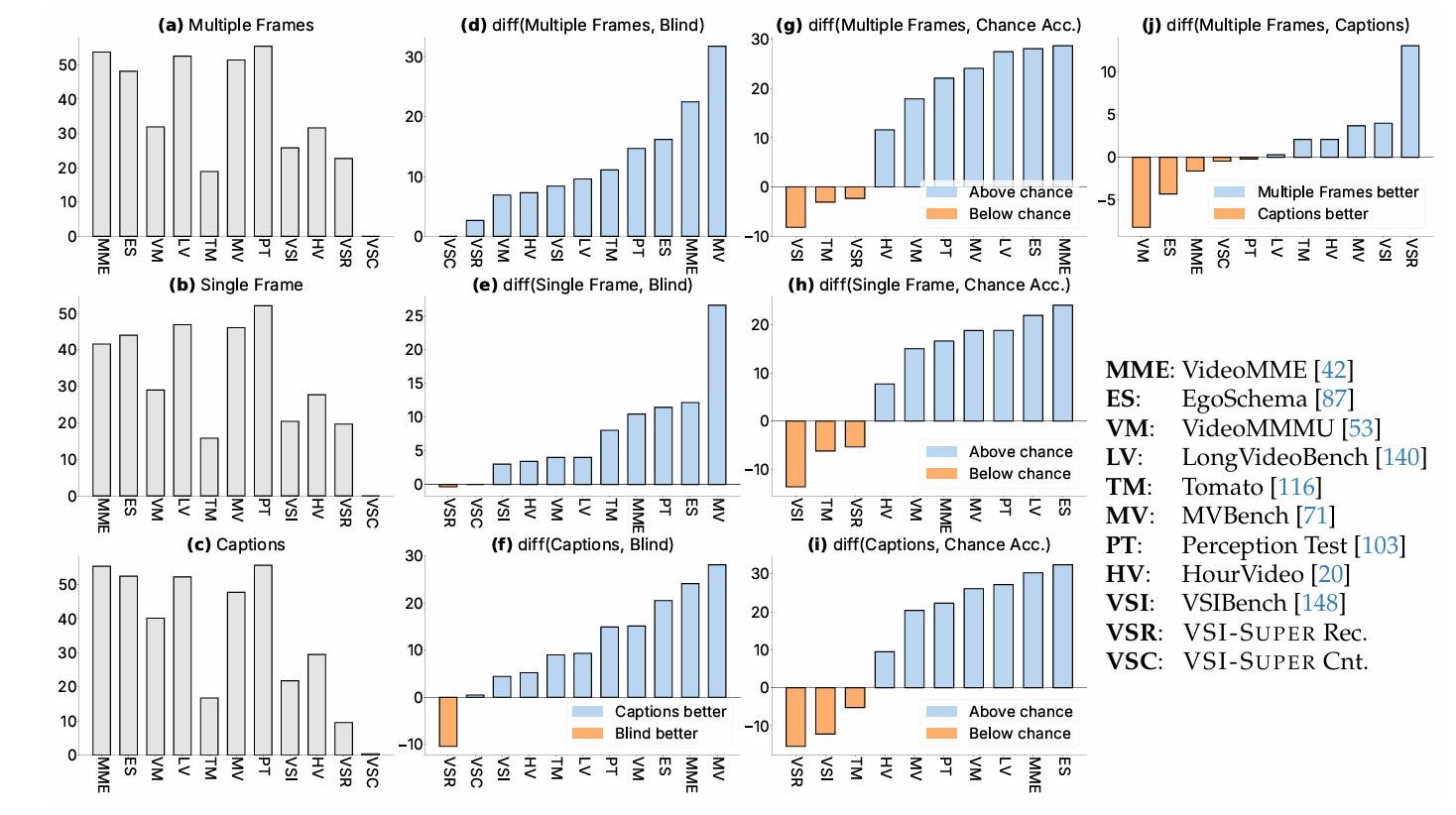
2.1. 解构现有视频基准测试
MLLMs的近期进展导致了视频问答基准测试的激增。然而,一个关键问题仍然存在:现有的视频基准测试在多大程度上真正检验了视觉感知能力,而不是便捷地测试语言先验?大家的诊断测试通过改变视觉输入的丰富程度和文本线索的信息量,来区分模型对视觉感知与语言先验的依赖程度。可仅用文本输入(例如,描述或盲MLLM)解决的基准测试偏向于检验语言理解。相反,只有凭借多帧输入才能回答的问题则需要真正的视觉感知。我们使用基于图像的多模态大语言模型Cambrian-1 [124]进行评估,这使我们能够探究底层任务需求,而不将其与视频特定架构和后训练方法的能力混为一谈。
我们为向Cambrian-1 [124]模型输入视频建立了几个实验条件:
多帧:模型处理从视频片段中均匀采样的32帧。这是文献中表示视频输入的标准手段[65]。
单帧:模型仅处理给定视频片段的中间帧。此条件测试模型对最小化、上下文中心视觉信息的依赖程度。
帧描述:模型接收与相同的32个均匀采样帧对应的描述,而不是视频帧。此条件旨在揭示在没有低层感知 grounding 的情况下任务的可解性。我们使用Gemini-2.0-Flash API重新描述视频帧。
为了将这些条件下的性能置于背景中,我们引入了另外两个基线:
盲测:模型仅使用任务的障碍进行尝试。所有视觉输入被忽略,不使用视觉描述。此基线衡量模型基于其先验知识、语言先验以及基准测试问题中任何潜在偏见的性能。
机会准确率:这代表了通过针对特定任务格式(例如,多项选择题)随机猜测可达到的准确率,作为性能的下限。
我们利用比较这些条件和基线之间的性能,对每个基准测试的特征进行了细粒度分析。我们关注以下关键比较(diff(A,B) = A-B):
- diff(x, Blind), x ∈ {Multiple, Single, Captions} 用于量化不同输入模态相对于盲基线的提升;
- diff(x, Chance), x ∈ {Multiple, Single, Captions} 用于衡量相对于机会的性能增益;
- diff(Multiple, Captions) 用于理解当前主流实践与强语言基线之间的性能差距。
图2(a-c)中呈现的结果表明,Cambrian-1 [124],一个基于图像的、没有任何视频后训练的MLLM,可以在许多基准测试上获得合理的性能,在某些情况下甚至超过机会水平准确率10-30%(见图2-g,h)。这表明这些基准测试所针对的大部分知识可能经过标准的单图像指令微调流程获取。然而,在两个现有材料集VSI-Bench [148]和Tomato [116]上,模型的性能低于机会水平。对于VSI-Bench,这主要是因为它涉及空间理解的问题需要真正的视频感知以及针对性的数据整理和训练。对于Tomato,这种表现不佳是预期的:该基准测试要求从更高帧率的视频中理解细粒度细节,使得核心时间下采样的单帧和32帧输入不足。
启用文本描述代替视觉输入也产生了显著的性能改进,在诸如EgoSchema [87]、VideoMME [42]、LongVideoBench [140]、VideoMMMU [53]、Perception Test [103]和MVBench [71]等基准测试上,超过机会准确率20%以上(图2-i)。与盲测结果比较时也能够得出类似的结论(图2d,f)。这种性能意味着这些基准测试主要探究的是能够从视频内容的文本摘要中推断出的能力。解释使用"多帧"和"帧描述"之间的性能差异(图2-j),显著的正差(支持多帧输入)意味着基准测试需要细微的视觉感知。相反,小或负的差(更支持"帧描述")表明其更具语言中心性。我们的分析将VideoMMMU、EgoSchema、VideoMME、Perception Test和LongVideoBench归入后一类,表明它们可能依赖于语言理解而非视觉线索。一个值得注意的例外是VSC,它对当前的MLLMs来说极具挑战性,以至于所有三种输入条件都产生接近零的性能,使得它们之间的任何有意义的比较都无法进行。
现有基准测试绝大多数侧重于语言理解和语义感知,而忽视了超感知所需的更高级的空间和时间推理。
我们希望强调基准测试固有的挑战性以及创建单一、包罗万象的基准测试来评估每种能力的不可行性。例如,对语言先验的依赖不应仅仅被视为一个缺点,因为在许多场景中,访问丰富的世界知识并有效检索它无疑是有益的。我们认为,视频基准测试不应被视为衡量单一、统一的"视频理解"概念。相反,它们的设计和评估应基于它们旨在评估的具体能力。因此,前面的分析旨在指导开发更有效推动空间超感知进展的任务,这将是本文剩余部分的核心焦点。
2.2. VSi-SuPER:迈向多模态LLM中的空间超感知基准测试
参考图1,空间超感知要求MLLMs具备四个关键能力:语义感知、流事件认知、隐式3D空间认知和预测性世界建模。然而,正如我们在图2中的分析所概述的,大多数现有的视频QA基准测试主要评估语言理解和语义感知方面,这些方面更具反应性并由特定任务驱动[42, 87, 53]。即使最近的研究已经开始通过持续感知、记忆架构和主动回答来解决流事件认知[24, 104, 97, 139, 119, 159],但此种能力通常在测试时被工程化,而不是作为模型的固有技能。此外,尽管空间推理偶尔作为现有基准测试中的一个类别出现,但这些任务很少达到真正空间认知的水平,并且远未触及定义超感知的世界建模能力(图3)。虽然VSI-Bench [148]在检验空间认知方面迈出了第一步,但其视频仍然是短格式和单场景的,并且它既没有形式化问题,也没有评估预测性世界建模的基本能力。
,它们对暴力上下文扩展具有抵抗力,暴露了真正空间推理的需求。我们在下面详细说明这两个组成部分。就是为了阐明当前MLLMs与空间超感知之间的差距,我们引入了VSi-SuPeR,一个用于连续空间感知的两部分基准测试。这些任务直观且通常对人类来说很容易,只需观察并跟踪发生的事情,但对机器来说却出奇地具有挑战性。它们需要在无界的空间视频上选择性地过滤和结构化地积累视觉信息,以维持连贯的理解并回答问题。重要的


VSI-SUPeR回忆:长视野空间观察和回忆。VSR基准要求MLLMs观察长视野的时空视频,并依次回忆一个不寻常物体的位置。如图4所示,为了构建这个基准,人类标注者利用图像编辑模型(即Gemini [30])在捕捉室内环境遍历的视频的四个不同帧(和空间位置)中插入令人惊奇或不协调的物体(例如,泰迪熊)[33, 153, 12]。接着,这个编辑后的视频与其他类似的房间导览视频连接起来,创建一个任意长且连续的视觉流。这个任务类似于语言领域中常用的干草堆寻针(NiAH)测试,用于对LLMs的长上下文能力进行压力测试[79]。类似的NiAH设置也已被提出用于长视频评估[162, 138, 54]。然而,与插入不相关文本片段或帧的基准测试不同,VSR通过帧内编辑保留了"针"的真实感。它通过要求顺序回忆(本质上是一个多跳推理任务)进一步扩展了挑战,并且在视频长度上可以任意扩展。为了全面评估模型在不同时间尺度上的性能,该基准测试献出了五种时长:10、30、60、120和240分钟。关于VSR基准构建的更多细节在附录B中提供。
VSi-SupeR计数:在不断变化的视角和场景下的连续计数。这里我们测试MLLMs在长格式空间视频中持续积累信息的能力。为了构建VsC,我们连接了来自VSi-Bench [148]的多个房间导览视频片段,并要求模型计算所有房间中目标对象的总数(见图5)。这个设置具有挑战性,因为模型必须处理视角变化、重复观察和场景转换,同时保持一致的累积计数。对于人类来说,计数是一个直观且可推广的过程。一旦理解了"一"的概念,将其扩展到更大的数量是很自然的。相反,正如我们后面将展示的,当前的MLLMs缺乏真正的空间认知,并且过度依赖学习到的统计模式。
除了标准评估(即在视频结束时提问)之外,我们在多个时间戳查询模型,以评估其在流式设置中的性能,其中VSC中的正确答案随时间动态演变。为了检查长期一致性,VSC包括四种视频时长:10、30、60和120分钟。对于这个定量任务,我们利用平均相对准确率(MRA)指标报告结果,与VSI-Bench评估协议[148]一致。

最先进的模型在VSi-SuPER上表现挣扎。为了测试VSI-SuPER是否对前沿MLLMs构成真正的挑战,我们评估了最新的Gemini-2.5-Flash [122]。如表1所示,该模型在处理两小时视频时达到了其上下文极限,尽管其上下文长度为1,048,576个令牌。这凸显了视频理解的开源性,其中连续流实际上应该"无限输入,无限输出"的上下文,并且可以任意增长,表明仅仅扩展令牌、上下文长度或模型大小可能是不够的。尽管是合成的,我们的基准测试反映了空间超感知中的一个真实挑战:人类能够轻松地整合和保留来自持续数小时或数年的持续感官体验的信息,而当前的模型缺乏可比的持续感知和记忆机制。Gemini-2.5-Flash在语义感知和语言理解为重点的视频基准测试(如VideoMME [42]和VideoMMMU [53])上表现出色,达到了约80%的准确率。然而,即使在VSi-SuPER中落在其上下文窗口内的60分钟视频上,VSR和VSC的表现仍然有限——分别仅为41.5和10.9。如图6所示,模型预测的物体数量未能随视频长度或真实物体数量成比例增长,而是饱和在一个小的常数值,表明计数能力缺乏泛化性,并且依赖于训练分布先验。

VSi-SuPER如何挑战当前范式。尽管任务设置简单,但VSi-SupER带来的挑战超越了空间推理,并揭示了当前MLLM范式的根本局限性。
VSi-SUPER任务挑战了仅靠扩展就能保证进展的信念。
通过允许模拟流式认知动态的任意长视频输入,VSiSUPER被刻意构建为超过任何固定上下文窗口。这种设计表明,逐帧令牌化和处理作为长期解决方案在计算上不太可能可行。人类通过选择性地注意和保留仅一小部分感官输入来高效和自适应地解决此类问题,通常是无意识的[40, 130]。这种预测性和选择性机制,是人类认知的核心,在当前MLLMs中仍然缺失,但对于预测性世界模型来说是基础性的。
VSi-SUPER任务要求在测试时泛化到新的时间和空间尺度。
例如,VSC需要在任意长的视频中计数,类似于理解计数概念的人类能够将其扩展到任何数字。关键不是维持一个极长的上下文窗口(人类不会保留扩展视觉体验中的每一个视觉细节),而是学习计数过程本身。预测性感知依据将连续视觉流分割成连贯的事件,利用"惊奇"时刻施加时间结构来促进这一点。此种分割作为一种分治机制,允许模型在动态变化的场景中决定何时开始、继续或重置行为。
这些挑战共同跨越了计算效率、泛化性以及无意识推断和预测性感知等认知机制,呼唤范式的转变。未来的模型不应仅仅依赖扩展数据、参数或上下文长度,而应学习能够跨时空在无限展开的视觉世界中感知和预测的内部世界模型。
为了进一步激励此种范式转变,下一节研究了依据改进的工程和针对性的素材整理,在当前范式内能在多大程度上取得进展。我们评估现有的MLLM框架是否可以适应以应对VSI-SuPeR带来的挑战。这些努力,虽然在当前框架的限制内运作,但对于构建下一代空间超感知模型的数据和实证基础是不可或缺的。
3. 当前范式下的空间感知
如前一节所示,Gemini-2.5-Flash在空间感知任务上表现不佳(见表1)。这一观察引发了一个关键问题:有限的空间感知是否仅仅是一个数据问题?这是一个有效的问题,缘于当前的视频MLLMs在训练期间并未明确优先考虑空间聚焦的视频,并且现有的预训练和后训练设计是否适合我们的目标任务仍然是一个悬而未决的问题。我们首先借助一系列架构和训练改进来增强Cambrian-1 [124],以建立一个更强的图像MLLM作为我们的基础模型(第3.1节)。我们接着构建了一个大规模的、空间聚焦的指令微调内容集VSi-590K(第3.2节)。该资料集从不同来源整理并经过仔细标注。由于此类数据目前尚未公开存在,VSI-590K旨在为空间感知提供强大的数据基础。结果,通过改进的训练方法(第3.3节),我们引入了空间接地的Cambrian-S模型系列(第3.4节)。
Cambrian-S模型系列在已建立的空间推理基准测试(如VSI-Bench [148])上表现出强大的性能,并为空间超感知的基础模型设计、内容整理和训练策略给出了宝贵的见解。然而,尽管有这些进展,这种方法并未直接解决VSi-SuPER的持续感知挑战(第3.5节);相反,它提供了一个关键的基础,激励了(第4节)中引入的新范式。
3.1. 基础模型训练:升级版Cambrian-1
大家首先编写一个基于图像的MLLM基础模型,因为强大的语义感知构成了高级空间认知的基础。我们遵循Cambrian-1 [124]的两阶段训练流程。我们将视觉编码器升级为SigLIP2-SO400m [128],语言模型升级为指令微调过的Qwen2.5 [145]。对于视觉语言连接器,我们采用一个容易的两层MLP,主导是出于其计算效率。Cambrian-1的其他训练组件,包括超参数和资料方式,保持不变。完整的实现细节在附录D中提供。
3.2. 空间视频资料整理:VSI-590K
众所周知,资料质量和多样性在MLLMs的训练中起着关键作用[124, 93]。我们假设VSI-Bench [148]上的性能差距核心来自于当前指令微调数据集中缺乏高质量、空间接地的数据[161, 32]。为了填补这一空白,我们构建了VSi-590K,一个大规模指令微调素材集,旨在改进视觉空间理解。
数据整理和处理。大家从多样化的数据源和类型(即模拟和真实)构建VSi-590K。参见表2了解数据源以及关于视频数量、图像数量和问答对数量的信息集统计信息。
我们发现这产生了一个比从单一来源获得的同等规模数据集更稳健的数据集。下面,我们详细说明数据处理过程。
标注的真实视频。多模态视觉空间推理依赖于对3D几何和空间关系的扎实理解。遵循VSI-Bench,我们重新利用现有的室内扫描和第一人称视频内容集的训练分割,这些数据集献出3D实例级标注,包括S3DIS [4]、ScanNet [33]、ScanNet++ V2 [153]、ARKitScenes[12]和ADT [102]。对于每个数据集,标注被整合到一个元信息文件中,捕获场景级属性,例如按类别的物体数量、物体边界框、房间尺寸和相关元素材。继而自动实例化问题模板以生成相应的问题。
模拟数据。由于3D标注数据的可用性有限,仅从真实标注视频构建大规模和多样化的3D标注SFT数据集具有挑战性。遵循SiMSV [13],大家利用具身模拟器来程序化地生成空间接地的视频轨迹和问答对,在ProcTHOR [36]场景内渲染625个视频遍历,具有多样化的布局、物体配置和视觉外观。我们将相同的方法应用于Hypersim [113],从461个室内场景中采样5,113张图像。使用实例级边界框,我们生成与标注真实视频设置一致的问答对。
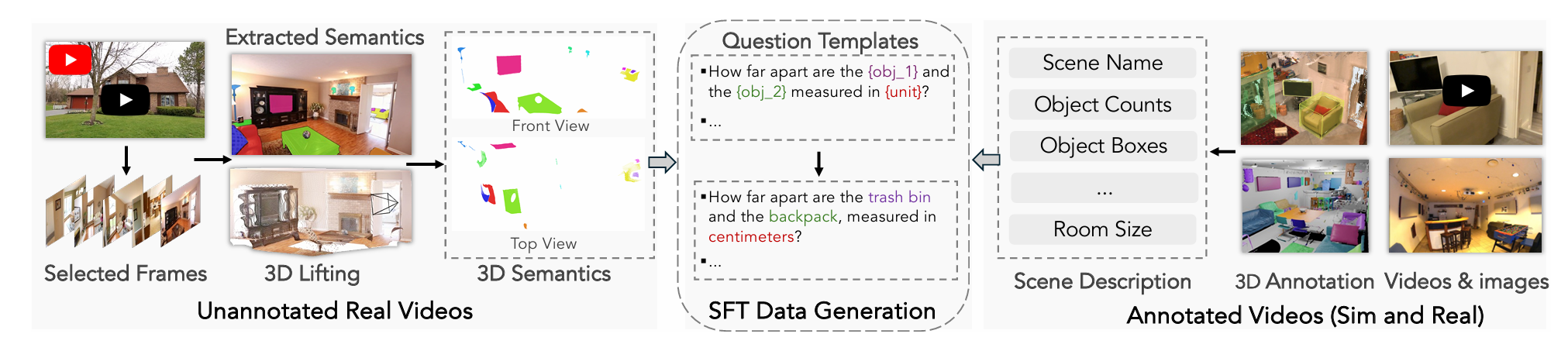
未标注的真实视频。尽管网络来源的视频缺乏明确的标注,但它们提供了室内环境类型、地理区域和空间布局的丰富多样性。大家从YouTube收集了大约19K个房间导览视频,并额外加入了来自机器人学习数据集的视频,包括Open-X-Embodiment [100]和AgiBot-World [16]。由于这些视频不包含构建空间指令微调数据所需的3D标注,我们研发了一个伪标注流程。如图7所示,我们对视频帧进行下采样和过滤,应用物体检测[80]、分割模型[109]和3D重建模型[133],按照SpatialVLM [21]的方法生成伪标注图像。我们选择在图像级别生成标注,而不是跨完整视频,因为从识别和重建模型导出的全视频伪标注对于训练来说往往噪声太大。
问题类型定义和模板增强。大家在时空分类法中定义了12种挑战类型,以构建一个全面且多样化的困难集用于指令微调。我们定义了五种核心问题类型——尺寸、方向、计数、距离和出现顺序——大致归类为测量配置、度量或时空能力,遵循[148]。除了出现顺序类型外,每个问题类别都包括相对和绝对变体,反映了这些互补的推理形式在视觉空间理解中的重要性[148]。例如,对于尺寸,我们既询问两个物体之间的尺寸比较(相对),也询问物体的公制尺寸(绝对)。为了增强多样性,我们在制定方向和距离挑战时改变了使用的视角。例如,一个距离问题可能会问两个物体中哪一个更靠近相机,或者哪个物体更靠近第三个参考物体。我们还通过问题措辞和度量单位(例如,米与英尺)的变化来使数据集多样化。数据集的更多细节在附录C中提供。
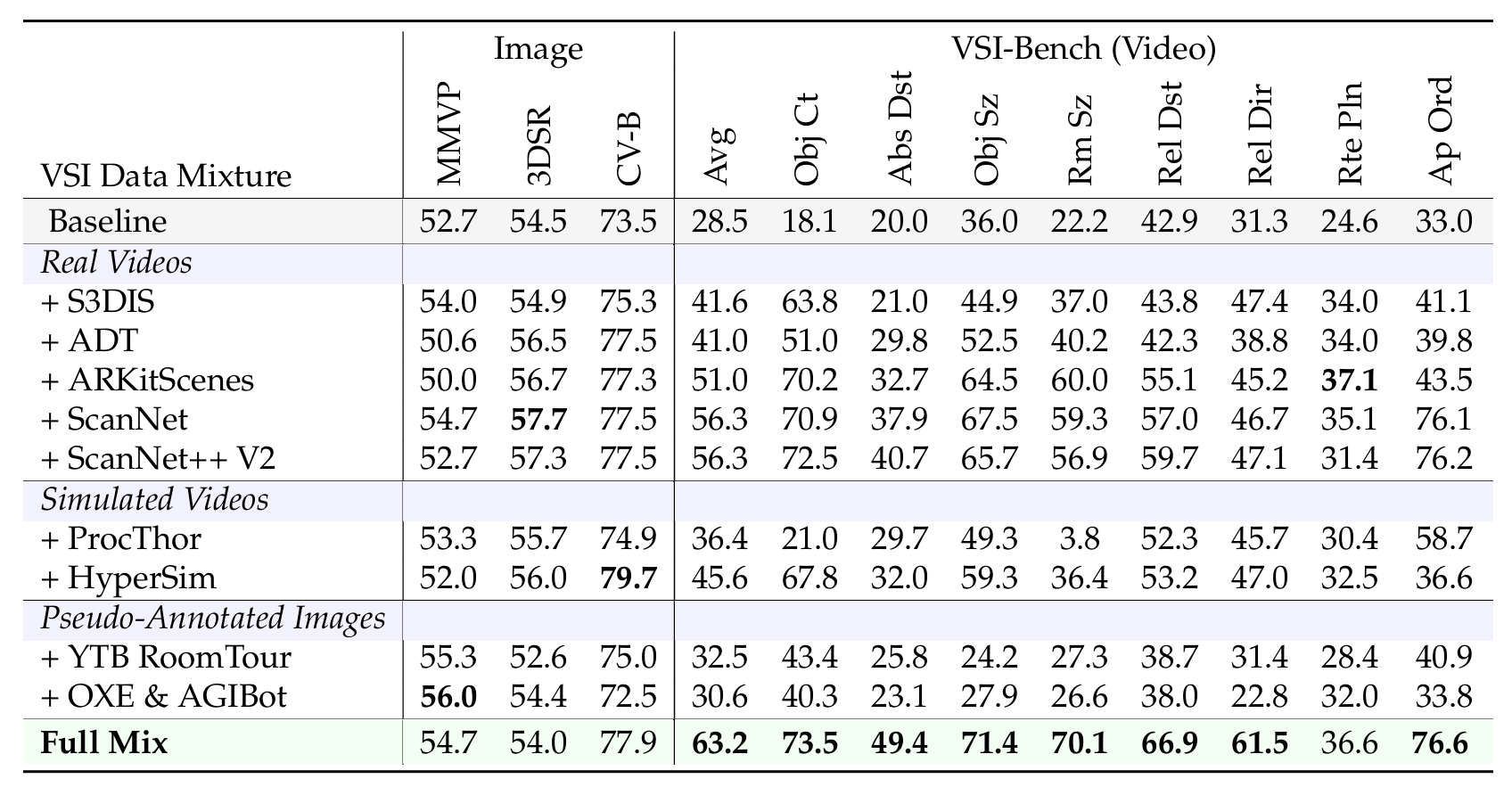
VSI-590K数据源消融。为了评估大家提出的VSI-590K数据集的有效性,我们进行了一项消融研究,通过使用LLaVA-Video-178K [161]中的部分视频指令微调样本对第3.1节中描述的改进的Cambrian-1 MLLM进行微调。该模型在表3中作为基线。借助分别在单个数据集及其组合上微调模型来评估每个数据源的贡献。VSI-590K完整混合在所有视频空间推理任务上实现了最高的整体性能,优于基线和所有单源对应模型。所有数据源在微调后都产生了积极贡献,尽管它们的有效性各不相同。
数据有效性排序为:标注的真实视频 > 模拟数据 > 伪标注图像。
这表明视频本质上比静态图像对空间推理更具信息量,由于仅在视频数据上训练能在基于视频和基于图像的空间推理基准测试上产生更优的性能。这些发现帮助了这样的直觉:视频的时间连续性和多视角多样性是发展稳健空间表示的关键。
3.3. 空间感知的后训练方法
我们进一步分析和消融了我们的视频指令微调流程,重点关注预训练基础视频模型和指令微调资料集混合的作用。如表4所示,我们从四个基础模型开始,这些模型代表了视频理解能力的逐步提升:
- A1 仅使用Cambrian-1对齐数据在图像-文本对齐上进行训练。语言模型与基础QwenLM相同,因为它在训练期间被冻结。
- 大家改进的Cambrian-1。就是A2 在A1的基础上运用图像指令微调进行微调,本质上
- A3 从A2初始化,并在429K视频指令微调数据上进行微调。
- A4 从A2初始化,并在3M视频指令微调数据上进行微调。
然后,我们启用两种不同的信息方法对这些模型进行微调:(1)仅VSi-590K,以及(2)VSI-590K与相似数量的通用视频指令微调数据混合。
表 4 | 空间感知的后训练探索。我们检查了四个基础模型,它们从仅图像训练到广泛视频训练,逐步增加对视觉数据的接触,并分析了它们在两种不同数据方法下进行空间感知微调时的不同趋势。A1:仅连接器被训练用于图像-语言对齐;A2:A1 + Cambrian-7M图像指令微调数据;A3:A2进一步在429K视频指令微调样本上微调;A4:A2进一步在3M视频指令微调样本上微调。从A1到A4,模型在视频理解能力上表明出单调改进。I-IT和V-IT分别表示在图像和视频数据上的指令微调。结果,我们显示更强的基础模型在空间感知任务上产生更好的SFT性能。
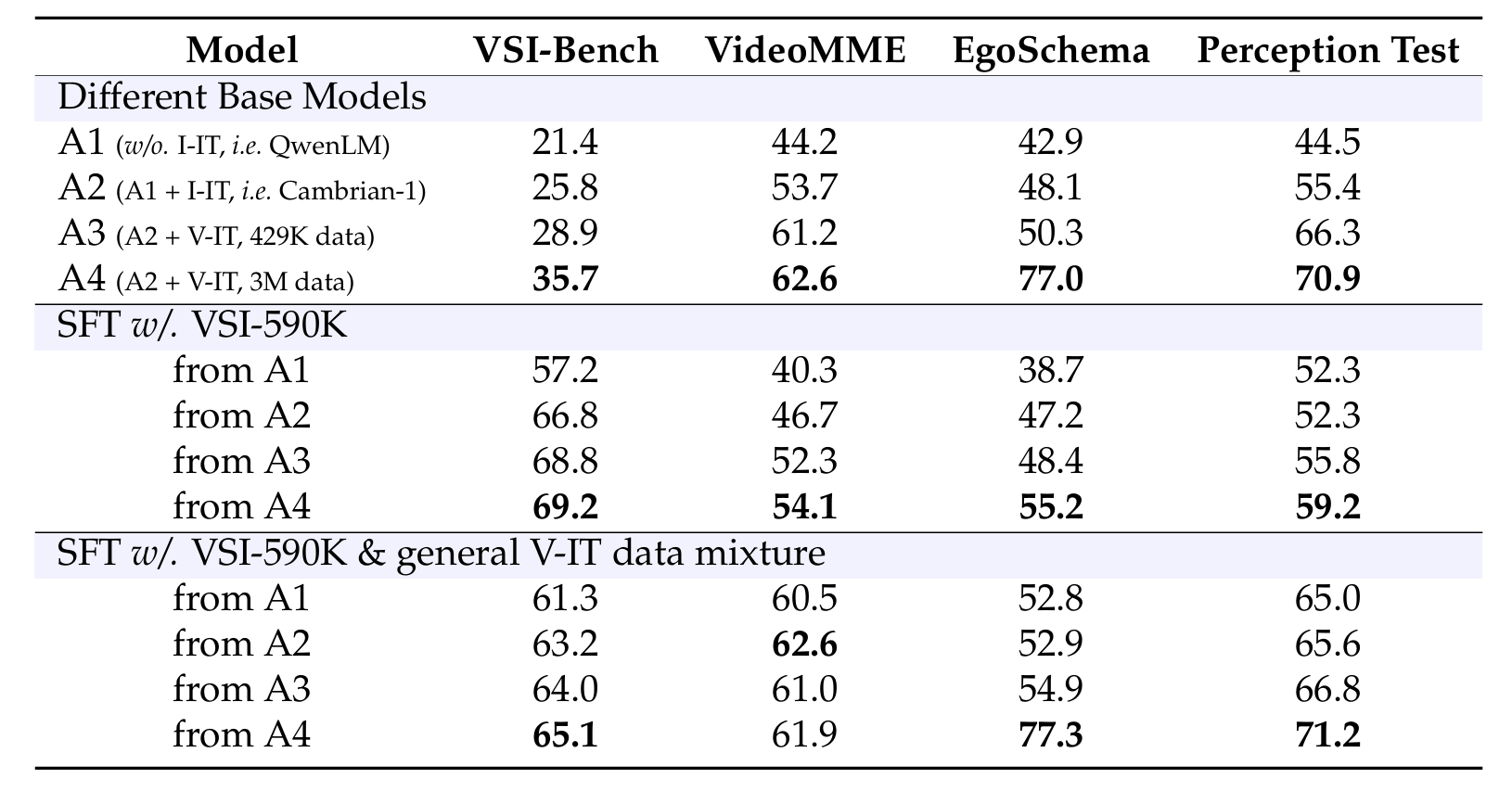
一个接触更多通用视频数据的更强基础模型在SFT后能带来改进的空间感知。
如表4所示,使用一个在通用视频基准测试(如VideoMME [42]和EgoSchema [87])上表现良好的更强基础模型进行SFT,能够增强空间理解能力。这突显了在基础模型训练期间广泛接触通用视频数据的重要性。
通过混合通用视频数据能够防止领域内SFT导致的泛化损失。
此外,虽然仅在领域内VSi-590K上进行SFT在VSI-Bench上达到了最高性能,但它导致了通用视频基准测试上的显著下降。然而,通过训练具备通用视频的数据混合,可以有效地缓解这种性能下降。
3.4. Cambrian-S:空间接地的MLLMs
基于之前的所有见解,我们开发了Cambrian-S,一个具有不同LLM规模(0.5B、1.5B、3B和7B参数)的空间接地模型系列。这些模型通过一个四阶段训练流程构建,专门设计为先建立通用语义感知,然后发展专门的空间感知技能,如图8所示。
关键的第4阶段,模型针对空间感知进行训练。在这里,我们在一个混合语料库上微调模型,该语料库结合了我们专门的VSi-590K和第3阶段使用的通用视频数据的比例子集,遵循表4中描述的设置。完整的训练细节在附录D.3中提供。就是前两个阶段遵循Cambrian-1框架来发展强大的图像理解能力。在第3阶段,我们通过在CambrianS-3M上进行通用视频指令微调来将模型扩展到视频,CambrianS-3M是一个由300万个样本组成的精选材料集(详细组成见图16)。此阶段在引入专门技能之前为通用视频理解奠定了坚实的基础。在终于也

3.5. 实证结果:改进的空间认知
接下来大家评估Cambrian-S多模态模型,以评估我们数据驱动方法的优势和局限性。
改进的空间认知。如表5所示,我们的模型在视频视觉空间理解方面达到了最先进的性能。Cambrian-S-7B在VSi-Bench上达到了67.5%,显著优于所有开源模型,并超过专有的Gemini-2.5-Pro超过16个绝对百分点。由于我们在这部分的工作可能被视为数据扩展的努力,一个自然的问题是:性能改进是否仅仅是由于更广泛的数据覆盖(包括更多样化的视觉配置和问答对),还是模型实际上发展了更强的空间认知?首先,我们强调VSI-590K和基准内容集之间没有资料重叠。尽管一些素材集来自相同的来源(例如来自ScanNet),但我们只使用训练分割,而基准测试使用验证和测试分割。此外,我们观察到空间推理泛化的明显迹象。例如,在具有挑战性的"路线规划"子任务中,由于其高标注成本,其问题类型在VSi-590K中不存在,但Cambrian-S-7B仍然表现强劲,并且随着模型大小的增加也显示出明显的扩展行为(见表6)。
此外,大家的训练方法即使对于较小的模型大小也非常高效:我们最小的0.5B模型在VSI-Bench上的性能与Gemini-1.5 Pro相当。重要的是,这种对空间推理的强调并非以牺牲通用能力为代价:Cambrian-S在标准视频基准测试(如Perception Test [103]和EgoSchema [87])上继续提供有竞争力的结果(完整结果见表14)。
Cambrian-S实现了最先进的空间感知性能,对未见过的空间问题类型具有稳健的泛化能力,同时在通用视频理解方面保持竞争力。
在VSI-Bench-Debiased上的稳健空间推理。一个专门设计用于通过去偏差消除语言捷径的基准测试。如表5所示,尽管与标准VSI-Bench相比性能下降了约8%,但我们的模型仍然优于专有对应模型,展示了稳健的视觉空间推理能力,并证实了我们的训练超越了基于语言的学习。就是最近的一项研究[14]揭示,模型可以依赖强大的语言先验进行空间推理任务。例如,当被要求估计桌子的长度时,模型可能会利用关于典型桌子尺寸(例如,120-180厘米)的自然世界知识,而不是分析视觉证据。为了调查Cambrian-S是否学会了视觉推理,我们在VSI-Bench-Debiased [14]上评估它,这
在VSi-Super上的结果:持续空间感知的局限性。尽管Cambrian-S在VSi-Bench中短的、预分割视频的空间推理任务上表现强劲,但它并未为持续空间感知做好充分准备。这种局限性体现在两个方面。最初,其在长视频上的性能显著恶化。如表7所示,当在流式风格设置中以1 FPS采样评估VSI-SuPER时,随着视频长度从10分钟增加到60分钟,分数从38.3%稳步下降到6.0%,并且对于超过60分钟的视频,模型完全失败。其次,模型难以泛化到新的测试场景。尽管在多房间房屋导览视频上训练,但它无法处理仅涵盖几个额外房间的未见过的示例。这个问题不仅仅是关于上下文长度:即使在模型上下文窗口内 comfortably 容纳的短10分钟视频上,性能也会下降。这些结果突显了在当前MLLM框架内纯粹的数据驱动方法,无论投入多少信息或工程努力,都面临根本性的限制。应对这些局限性需要向能够主动建模和预测世界同时更有效地组织其经验的AI架构进行范式转变,大家将在下一部分探讨这一点。
扩展数据和模型是必要的,但仅凭它们无法解锁真正的空间超感知。
4. 预测性感知作为新范式
Gemini-2.5-Flash(表1)和Cambrian-S(表7)的性能在VSI-SUPER上都急剧下降,揭示了一个根本的范式差距:仅扩展数据和上下文对于超感知是不够的。我们提出预测性感知作为前进的道路,模型学会预测其感官输入并构建内部世界模型来处理无界的视觉流。这种设计灵感来自人类认知理论。与当前将整个数据流令牌化并处理的视频多模态模型不同,人类感知(和记忆)是高度选择性的,仅保留一小部分感官输入[130, 95, 52, 108]。大脑不断更新内部模型以预测传入的刺激,压缩或丢弃不提供新信息的可预测输入[29, 41]。相反,违反预测的意外感官信息产生"惊奇"并驱动增加的注意力和记忆编码[115, 45, 60]。我们通过自监督下一潜在帧预测方法(第4.1节)原型化了这一概念。由此产生的预测误差作为两个关键能力的控制信号:用于选择性保留重要信息的记忆管理(第4.2节),以及用于将无界流分割成有意义块的事件分割(第4.3节)。我们通过在VSi-SupER上的两个案例研究证明,这种方法显著优于强大的长上下文和流式视频模型基线。
4.1. 依据潜在帧预测进行预测性感知
我们通过一个轻量级的、自监督的模块来实现我们的预测性感知范式,该模块称为潜在帧预测(LFP)头,它与主要的指令微调目标联合训练。这是经过修改第4阶段训练方法实现的:
潜在帧预测头。我们引入了一个LFP头,一个与语言头并行运行的两层MLP,用于预测后续视频帧的潜在表示。该架构如图9左上角所示。
学习目标。为了优化LFP头,我们引入了两个辅助损失,均方误差(MSE)和余弦距离,它们测量预测的潜在特征与下一帧的真实特征之间的差异。一个加权系数平衡了LFP损失与核心的指令微调下一令牌预测目标。
用于LFP训练的信息。我们用专门用于LFP目标的VSI-590K中的290K视频子集增强了第4阶段数据。与指令微调不同,这些视频以1 FPS的恒定速率采样,以确保潜在帧预测的时间间隔均匀。
在这个修改后的第4阶段微调期间,我们端到端地联合训练连接器、语言模型以及语言头和LFP头,同时保持SigLIP视觉编码器冻结。所有其他训练设置与原始第4阶段安装保持一致。为简洁起见,在后续实验中,我们仍将与LFP目标联合优化的模型表示为Cambrian-S。
推理:通过预测误差估计惊奇。在推理过程中,我们利用训练好的LFP头来评估每个传入的视觉感官输入的"惊奇"。在心理学中,这个框架通常被描述为期望违背(VoE)范式[17]。具体来说,在推理过程中,视频帧以恒定采样率输入到Cambrian-S。除非另有说明,以下实验中的视频在输入模型之前以1 FPS采样。当模型接收传入的视频帧时,它持续预测下一帧的潜在特征。然后,我们测量模型的预测与该传入帧的实际真实特征之间的余弦距离。这个距离作为惊奇的定量度量:较大的值表示与模型学习到的期望有更大的偏差。这个惊奇分数作为接下来探索的下游任务的有力、自监督的指导信号。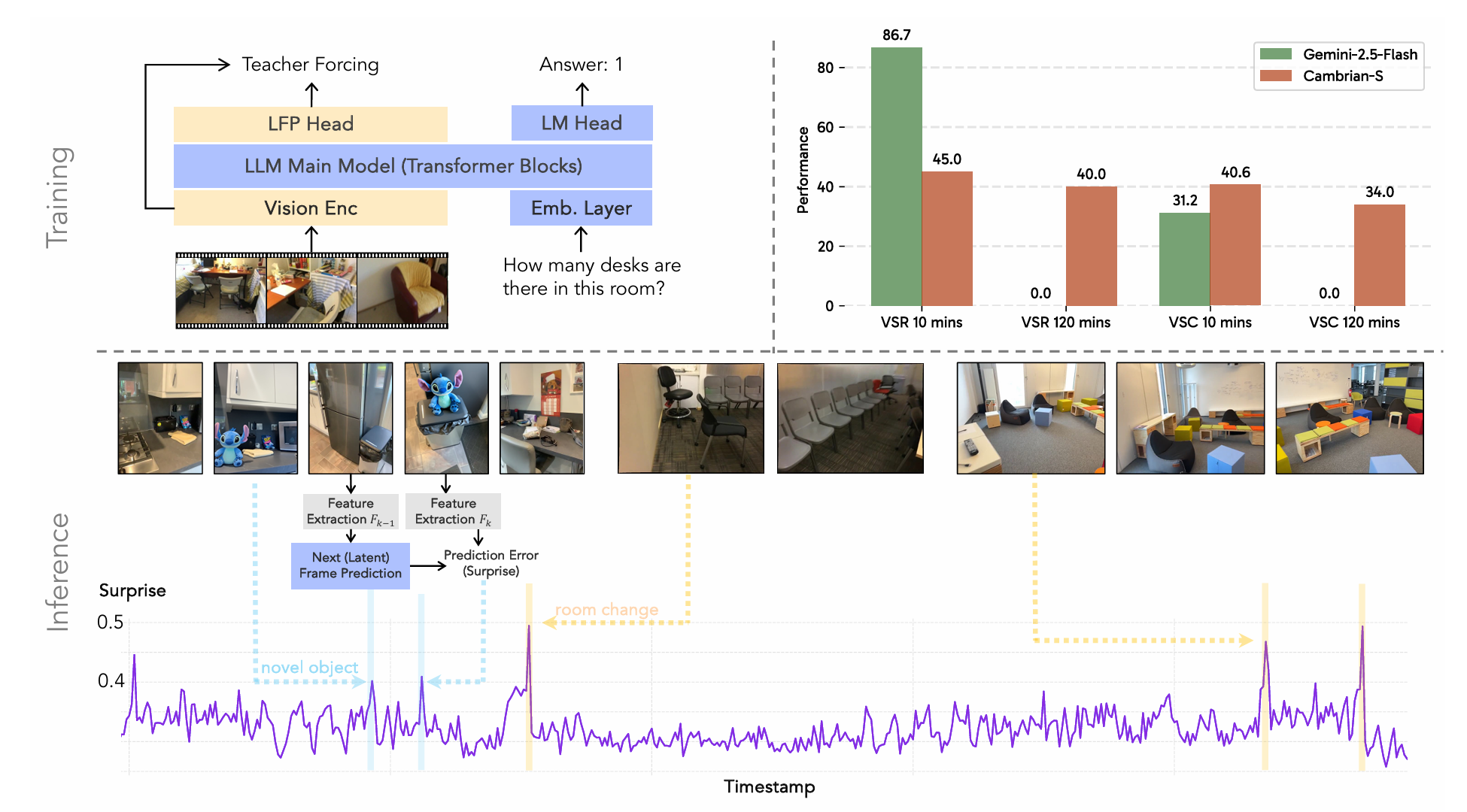
4.2. 案例研究 I:用于VSi-SuPeR回忆的惊奇驱动记忆管理系统
大多数当前的MLLMs平等对待所有视频帧,存储每一帧而不进行选择性压缩或遗忘,这限制了效率和可扩展性。在这个案例研究中,我们探索为MLLMs增强一个惊奇驱动的记忆管理框架,以承受长时视频上的持续空间感知问答。我们展示了通过惊奇引导的压缩,CambrianS保持了稳定的准确率和GPU内存占用,与视频长度无关。
惊奇驱动记忆管理系统。我们的记忆管理系统基于"惊奇"估计动态压缩和整合视觉流。如图10-a所示,我们使用固定窗口大小的滑动窗口注意力对传入帧进行编码。然后,潜在帧预测模块测量一个"惊奇水平"并将其分配给每个帧的KV缓存。惊奇水平低于预定义阈值的帧在被推入长期记忆之前进行2倍压缩。为了维持稳定的GPU内存占用,该长期记忆被限制在一个固定大小,通过一个再次基于惊奇操作的整合函数:根据它们的惊奇分数丢弃或合并帧(见图10-b)。最后,在接收到用户查询时,环境通过计算查询与存储的帧特征之间的余弦相似度,从长期记忆中检索最相关的top-K帧(见图10-c)。更多设计细节见附录F.2。虽然先前的工作已经探索了长视频的记忆系统设计[119, 159],但我们的重点是探索预测误差(即惊奇)作为指导信号。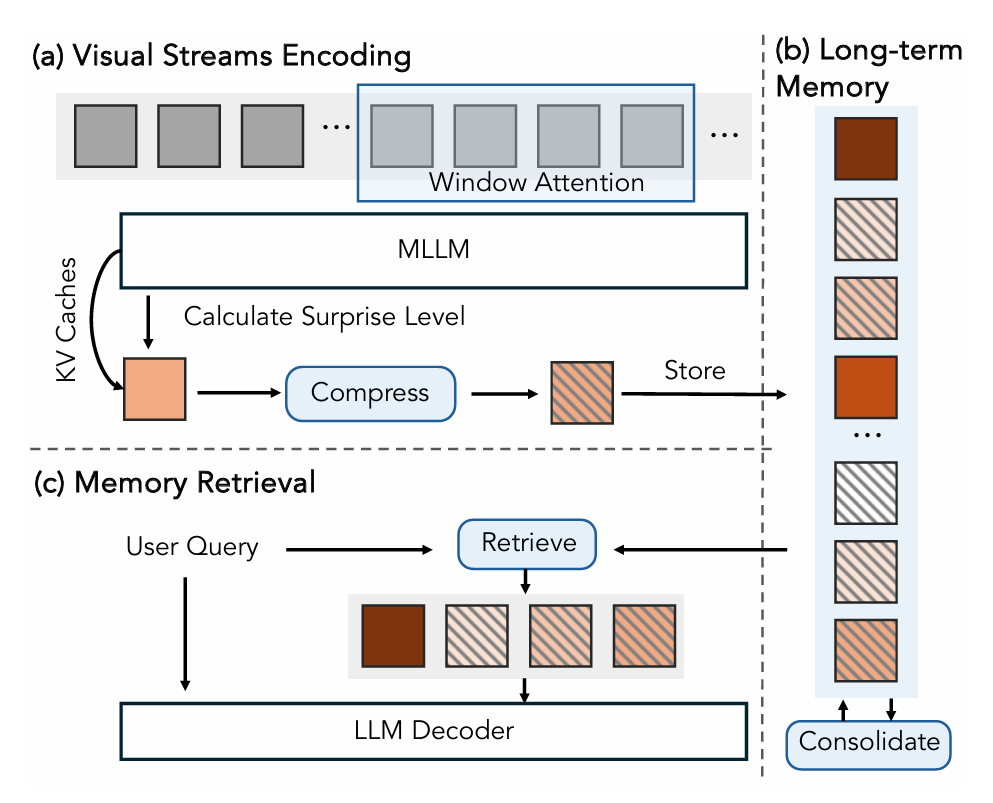
结果。我们将带有和不带有基于惊奇的记忆系统的Cambrian-S与两个先进的专有模型Gemini-1.5-Flash [122]和Gemini-2.5-Flash [30]在VSR基准上进行比较。如图11a所示,Cambrian-S(带记忆)在所有视频长度上都优于Gemini-1.5-Flash和Cambrian-S(不带记忆),展示了跨视频时长的持续空间感知性能。尽管Gemini-2.5-Flash在一小时内的视频上产生了强劲的结果,但它无法处理更长的输入。除了保持高准确率外,Cambrian-S(带记忆)还在不同视频长度上保持了稳定的GPU内存使用(图11b)。这表明基于惊奇的记忆有效地压缩了冗余数据而不会丢失关键信息。我们在表17中包含了两个长视频基线MovieChat [119]和Flash-VStream[159]进行比较。
关于惊奇测量的消融。测量惊奇的机制,它决定了帧在被动感知方式下如何被压缩或整合——不假设任何关于未来查询的先验知识。在这里,我们将我们的设计,即预测误差作为惊奇,与另一个直接的基线进行比较:相邻帧视觉特征相似性。具体来说,我们使用SigLIP2作为视觉编码器,并直接比较两个相邻帧之间的帧特征差异(余弦距离)。如果差异超过阈值,我们将后一帧视为惊奇帧。我们在所有VSR变体上比较这两种方式。对于每个VSR时长,我们保持实验设置相同,除了惊奇阈值,我们为两种手段都进行了调整。如图11c所示,使用预测误差作为惊奇测量在不同视频时长上始终优于相邻帧相似性。就是我们基于惊奇的记忆系统的核心
预测性感知提供了一种比基于每帧特征的静态相似性度量更原则性的方式来建模视频素材的时空动态。
尽管我们当前的架构采用一个简单的预测头作为初始原型,但未来集成一个更有能力的世界模型可以产生更丰富和更可靠的惊奇信号,最终建立空间超感知的更广泛进展。
4.3. 案例研究 II:用于VSi-SuPeR计数的惊奇驱动连续视频分割
即使VSR侧重于评估MLLMs的长期观察和回忆能力,但对超感知更具挑战性的测试是检验模型解释其感官输入、在不同环境中导航以及执行累积、多跳推理的能力。例如,模型可能需要在一个环境中完成任务,移动到另一个环境,并最终整合所有经验中的信息以达成最终决策。
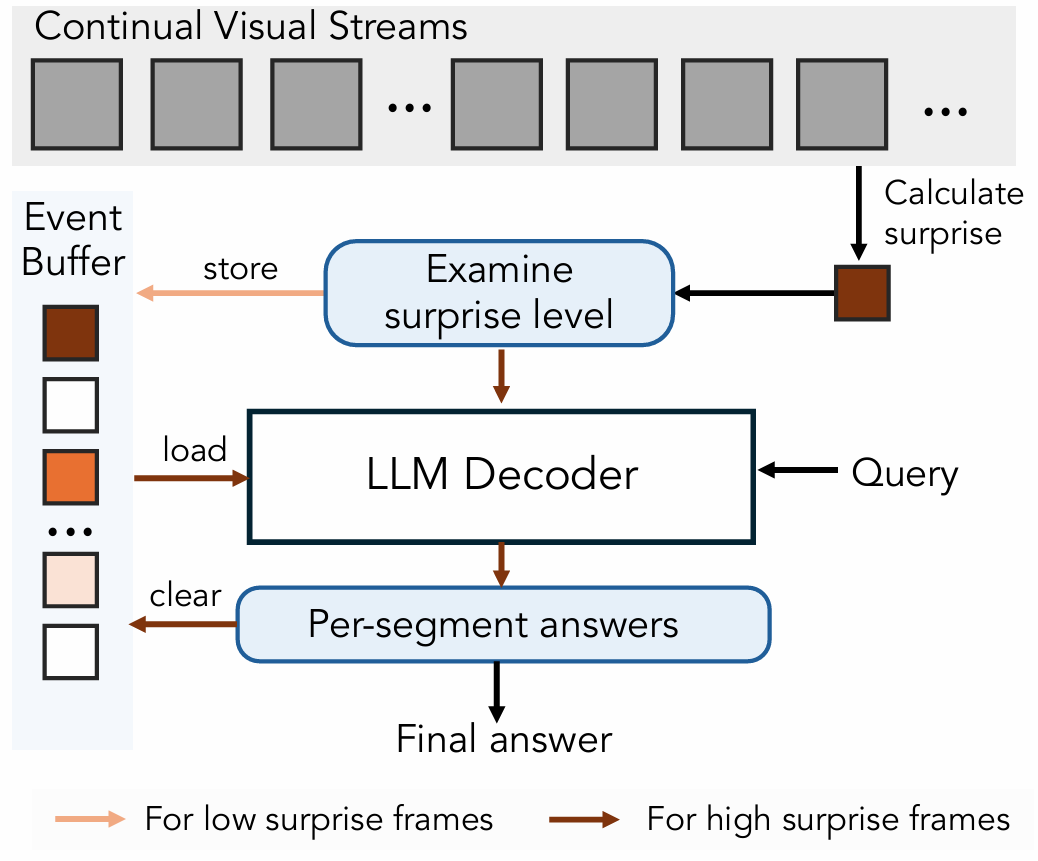
惊奇驱动事件分割。一个事件可能被理解为一个时空连贯的经验片段[64]。在空间超感知的背景下,一个事件对应于位于特定空间内并感知其环境的连续体验。该定义强调,真实的感官体验通常被组织成本地连贯的片段——感知、空间和时间特征保持相对稳定或一致的片段。事件分割,则是基于这种连贯性的变化将连续的感官输入流解析为离散的、有意义的单元的过程。这种分割对于推理和行为是必不可少的[37]:它允许智能体(生物或人工)形成经验的结构化表示,检测发生显著变化的边界,并相应地更新关于环境的预测。最近的研究强调,预测误差和工作记忆/上下文的变化是驱动分割的两个可能机制[98, 118]。
在VSi-SupeR计数(VSC)基准测试中,我们研究了一个简单的设置,其中惊奇用于分割连续视觉输入,将场景变化识别为将视频流划分为空间连贯片段的自然断点。这种方法也类似于人类解决问题的方式:当在一个大区域计数物体时,人们通常一次专注于一个部分,然后再组合结果。这种行为也与"门口效应"[106]有关,其中穿过门口或进入新房间会在记忆中创建一个自然边界。如图12所示,模型在事件缓冲区中持续累积帧特征。当检测到高惊奇帧时,缓冲的特征被总结以产生片段级答案,并且缓冲区被清空以开始新的片段。该循环重复直到视频结束,之后所有片段答案被聚合以形成最终输出。
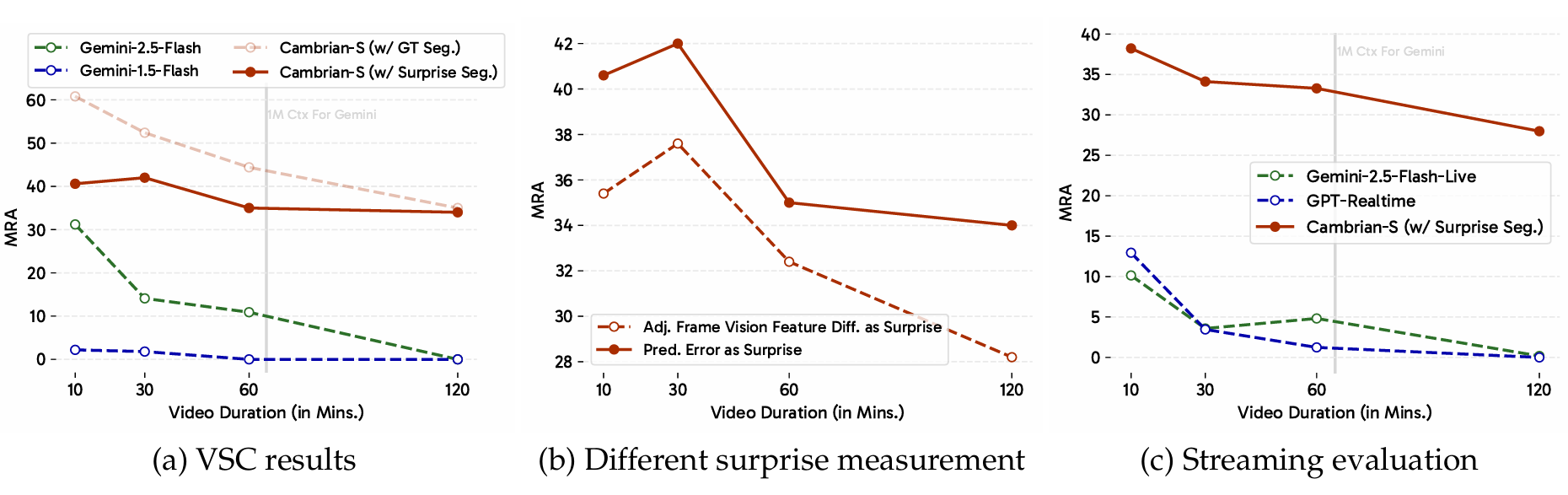
结果。Gemini-1.5-Flash在VSC上达到接近零的性能(图13a),显示了任务的难度。尽管Gemini-2.5-Flash在10分钟视频上产生了更好的结果,但其在更长视频上的性能迅速下降。相比之下,CambrianS使用的惊奇驱动事件分割方法(带惊奇分割)在所有视频长度上实现了更高且更稳定的性能。当启用真实场景转换(即Cambrian-S带真实分割)分割视频时,性能进一步提高,代表了一个近似上限。图14中的更深入分析显示,Gemini-2.5-Flash的预测被限制在一个有限的范围内,并且随着视频中出现更多物体而不成比例增长。相比之下,Cambrian-S(带惊奇分割)产生的计数,虽然尚未完全准确,但与真实物体数量表现出更强的相关性,表明更好的泛化能力。
关于惊奇测量的消融。大家将我们的惊奇驱动技巧与运用相邻帧特征相似性的基线进行比较(图13b)。对于两种方法,我们在超参数调整后报告最佳结果。与我们在VSR中的观察一致,使用预测误差作为惊奇的度量在所有视频时长上始终以显著优势优于外观相似性。
在流式设置中的评估。由于VSC中的正确答案在整个视频中演变,我们创建了一个流式QA设置,在10个不同的时间戳提出相同的问题。最终性能在所有查询上取平均。我们与为实时视觉输入销售的商业MLLMs进行基准测试。如图13c所示,尽管Gemini-Live和GPT-Realtime旨在用于流式场景,但它们在10分钟流上实现了低于15%的MRA,并且它们在120分钟流上的性能下降到接近零。然而,Cambrian-S显示出更强的性能,在10分钟流上达到38%的MRA,并在120分钟时保持在28%左右。
总结。在VSR回忆和VSC计数任务中,借助惊奇驱动记忆和事件分割的预测性感知使Cambrian-S能够克服第3节中描述的固定上下文限制。尽管这仍然是一个早期原型,但它突出了构建不仅能"看见"而且能预测、选择和组织经验的AI平台的潜力。这样的系统超越了帧级问答,朝着构建支持更深层次空间推理、跨越无界时间范围并实现媲美并最终超越人类视觉智能的超感知的隐式世界模型迈进。
5. 相关工作
视频多模态大语言模型预训练LLMs的强大语言理解能力[15, 126, 7, 127],与用作特征提取器的视觉基础模型的表征能力相结合[105,157, 128, 50,39],推动了将这些模型扩展到文本之外以实现视觉内容的语义感知(主要在图像领域)的重大进展[56,78, 65, 8,124, 121, 27,134, 68]。这一势头刺激了对基于视频的MLLMs日益增长的研究[74, 65, 161, 119, 9, 167, 158, 69, 168, 89],这被视为将多模态智能与现实世界应用(如具身智能体[61, 147])连接起来的关键一步。正如本文通篇强调的,创建一个真正有能力的超感知系统需要重新思考几个核心方面,包括如何基准测试进展、什么构成正确的资料、哪些架构设计最有效,以及哪些建模目标最符合系统的目标。
流式视频理解视频是连续的、潜在无限的视觉信号流。虽然人类毫不费力地处理它,但其无界性质挑战了视频MLLMs,因为令牌长度随着持续时间增加,导致计算和存储成本上升。最近的工作探索了几种方法来解决这个问题:高效架构设计。自注意力的二次成本使得处理长视频变得困难。最近的技巧[70, 112]使用更方便、更快的架构[135, 48, 58],减少计算并更好地处理更长的输入。上下文窗口扩展。预训练LLMs中的固定上下文长度限制了它们对长期内容的理解。最近的工作[26, 160, 25]通过精细的系统设计扩展了这个窗口,使模型能够处理和对更长的视频序列进行推理。检索增强的视频理解。为了处理长视频,一些办法仅从更大的集合中检索最相关的片段[63, 101, 136],并将它们用作进一步分析的上下文。视觉令牌减少或压缩。其他方法通过跨帧或帧内减少视觉令牌来缩短输入[117, 73, 57,72, 19],使得处理长视频序列更容易。虽然这些方法提高了性能,但它们很大程度上将连续视频视为标准的序列建模疑问,类似于文本。我们认为未来的MLLMs应该构建内部预测模型来高效处理连续视觉流,就像人类一样。
视觉空间智能从视觉输入理解空间关系对于感知和与物理世界交互至关重要。随着多模态模型变得更加物理接地,对空间智能的兴趣激增,导致了新的基准测试[148, 107, 154, 86, 152, 75, 142, 123]和专注于增强模型空间推理能力的研究[151, 84, 99, 38, 21, 28, 18, 76, 67,166, 110]。在本文中,我们经过视频中的空间超感知概念研究视觉空间智能,并利用改进数据整理、优化训练策略和引入新范式来探索加强MLLMs空间推理的手段。
预测性建模一个学习到的内部预测模型[31, 49]允许智能智能体表示和模拟其环境的各个方面,从而完成更有效的规划和决策。模型预测控制(MPC)[43]在控制理论中应用了类似的原则,利用内部前向模型来预测未来轨迹并在实时中选择最优行动。该概念灵感来源于人类如何形成世界的心理模型[108, 52, 41]以及这些内部表示如何影响行为(例如,无意识推断[130]),作为现实的简化抽象,使得预测和有效行动成为可能。越来越多的工作依据自监督表示学习[5, 6]以及文本或行动条件的视频生成[164, 150, 11, 22, 10, 44]探索了预测建模的思想。在本文中,受到人类如何利用内部世界模型高效有效地处理无界感官输入的启发,我们研究了如何为MLLMs配备类似的预测感知能力。
6. 结论
我们强调并提出了视频中空间超感知能力的重要性及其层次结构,认为构建超级智能需AI系统超越基于文本的知识和语义感知(当前大多数MLLMs的焦点),以发展空间认知和预测性世界模型。为了衡量进展,我们引入了VSi-SUPER,并发现当前的MLLMs在其中表现挣扎。为了测试当前的进展是否受到数据的限制,我们整理了VSI-590K并在其上训练了我们的空间接地MLLM,Cambrian-S。尽管Cambrian-S在标准基准测试上表现良好,但其在VSI-SUPER上的结果揭示了当前MLLM范式的局限性。我们原型化了预测性感知,利用潜在帧预测和惊奇估计来处理无界视觉流。它提高了Cambrian-S在VSi-SupER上的性能,并标志着迈向空间超感知的早期一步。
局限性。大家的目标是提出一个概念框架,鼓励社区重新考虑发展空间超感知的重要性。作为一个长期的研究方向,我们当前的基准测试、数据集和模型设计在质量、规模和泛化性方面仍然有限,并且原型仅作为概念验证。未来的工作应探索更多样化和具身的场景,并与视觉、语言和世界建模的最新进展建立更强的联系。
致谢
我们感谢Cambrian-1 [124]的优秀代码库,它为我们研究的起点。感谢TorchXLA团队就TPU、TorchXLA和JAX分布式训练基础设施进行的有益讨论。我们还感谢Anjali Gupta, Sihyun Yu, Oscar Michel, Boyang Zheng, Xichen Pan, Weiyang Jin, 和 Arijit Ray审阅本手稿并提供建设性反馈。这项工作主要得到Google TPU Research Cloud (TRC)计划和Google Cloud Research Credits计划 (GCP19980904)的支持。E.B.得到DoD NDSEG Fellowship Program的帮助。S.X.感谢MSIT IITP资助 (RS-2024-00457882) 和NSF奖项 IIS-2443404的支持。
附录
本附录供应了全面的达成细节、实验结果和支持主论文的补充分析:
- A 呈现了不同评估设置下视频MLLM基准测试的详细诊断测试结果。
- B 描述了VSi-SuPeR基准测试,包括实现细节、可视化和回忆与计数任务的流式设置。
- C 提供了VSi-590K数据集的全面文档,包括障碍类型分类法、问答对构建流程、消融研究和定性示例。
- D 详细说明了Cambrian-S模型架构、训练数据混合、所有四个阶段的训练方法和基础设施设置。
- E 呈现了额外的实验结果,包括详细评估设置、所有模型规模在图像和视频基准测试上的性能、图像-视频数据贡献的消融以及空间感知与通用视频理解之间权衡的分析。
- F 描述了预测性感知组件,包括潜在帧预测实现细节、用于VSi-SuPeR回忆的记忆框架设计、用于VSi-SuPeR计数的智能体框架设计以及与现有长视频方法的比较。
A. 基准诊断测试结果
我们在表8中给予了图2的详细结果。
B. VSI-SUPER基准测试
B.1. VSI-SUPER回忆
实现细节。为了构建这个基准测试,我们从VSi-Bench集合[148]的视频开始。标注者选择视频,并使用Gemini-2.0-Flash从精选池中手动将一个不寻常的物体插入到四个不同的帧中,专注于将物体放置在合理的位置。对于每次插入,标注者记录物体的位置及其出现顺序。然后,我们将这些编辑后的片段与随机采样的未编辑视频组合,以产生长度为10、30、60、120和240分钟的最终视频。对于每个时长,我们创建60个视频,每个视频有一个对应的障碍。我们将视频下采样到每秒1帧,以确保模型在推理过程中始终能看到编辑过的帧。
可视化。我们在图18中展示了我们VSR视频数据集编辑帧的定性示例。插入的物体在其位置看起来视觉上合理,这是我们高质量标注的直接结果。
B.2. VSI-SUPER计数
实现细节。为了构建VSI-SuPER计数,我们连接来自VSI-Bench [148]的视频并将它们的物体计数相加以创建新的真实值。这个过程需要两个额外的归一化步骤。首先,我们统一来自不同源数据集(即ScanNet [33]、ScanNet++ [153]和ARKitScenes [12])的物体类别标签。其次,我们通过重新平衡问答对来解决数据偏向小物体数量的障碍,以创建更均匀的计数分布。最终基准测试包括长度为10、30、60和120分钟的视频,每个视频附带50个相应的问题。与VSR不同,VSC中的所有视频都下采样到24 FPS。
流式设置。对于流式设置,我们在10个不同的时间戳重复查询视频中的物体总数。为了在这些查询时间戳构建真实值,我们需要确定视频中每个独特物体的首次出现时间。为了找到这些出现时间,我们使用了VSI-Bench [148]提出的方法。这允许直接计算任何给定时间戳的真实物体计数。
C. VSI-590K数据集
在本节中,我们献出关于VSi-590K数据集的更多细节,包括问题类型定义、问答对构建流程以及每个数据源的一些示例。
C.1. 挑战类型定义详情
分类法。在整理视觉空间智能监督微调数据集时,一个重要的视角是如何定义障碍类型。受VSI-Bench [148]的启发,大家以更系统的方式扩展了其任务定义。如表9所示,我们从四个角度区分这些困难类型:
时空属性:我们将问题分为五种不同的时空属性类型:尺寸(比较或测量物体/空间尺寸)、方向(空间中的朝向)、计数(物体的枚举)、距离(物体之间的接近度)和出现顺序(物体在视频中出现的时间顺序)。
相对与绝对:多少米?”),被分类为绝对问题。这种区分适用于大多数属性类型。就是当问题涉及多个物体之间的比较时(例如,“哪个更大?”),被分类为相对问题;当需要特定测量值或数量时(例如,“高度
视角采取:右边?”),也可以从场景中特定物体的视角提出(例如,“从物体2面对物体1…”)。就是这个维度捕捉了评估空间关系时所采用的视角。问题可能从相机的视角提出(例如,“从相机的视角看,物体在左边还
模态:问题根据它们是仅能使用静态图像回答,还是应该动态视频信息来分类。一些属性类型,如出现顺序,仅适用于视频,而其他如尺寸则可以在任一模态中提问。
此外,遵循VSi-Bench,大家还根据其不同的时空特征将我们的疑问类型分类为三个不同的组(即配备、度量或时空)。
C.2. 详细的问答对构建流程
我们在这里介绍用于整理VSI-590K的具体流程。
3D标注的真实视频。对于3D标注的真实视频,我们遵循Thinking in Space [148]建立的做法。我们首先研究所有包含3D实例级标注以及视频或全景图像的公开可用数据集。从这些数据集中,我们提取关键信息,包括物体计数、物体边界框和房间尺寸测量值,然后将它们标准化为统一格式。之后,将这些结构化信息纳入增强的问题模板中,以创建配对的问答集。
3D标注的模拟视频和图像。对于模拟数据,其本身包含丰富的标注,我们遵循了与处理3D标注真实视频类似的程序。对于ProcTHOR [36],我们的主要努力是生成带有随机放置智能体的3D场景来渲染遍历视频。对于Hypersim [113],它提供图像级而非场景级的3D标注,我们利用具有相应3D标注的单个图像。在这两种情况下,我们提取必要的信息,将其转换为我们设计的统一格式,并将其纳入增强的问题模板中,遵循与处理3D标注真实视频相同的方法。
未标注的网络爬取真实视频。对于未标注的网络爬取真实视频,如算法1所示,大家实现了一个多阶段处理流程。我们首先以固定间隔采样帧并过滤掉模糊图像。对于每个高效帧,我们使用带有预定义感兴趣类别的开放词汇物体检测器Grounding-DINO [80]。当一帧包含足够多的有效物体时,我们使用SAM2 [109]提取实例级的语义掩码。此外,为了将2D图像内容转换为3D表示,我们使用VGGT [133]为每张图像提取3D点集,并将其与先前生成的实例掩码集成。值得注意的是,我们应用腐蚀算法来细化实例掩码,这减轻了物体边界处不准确的点云估计。该流程使我们能够从YouTube和机器人学习数据集的大约19,000个房间导览视频中创建伪标注,在各种房间类型和布局中产生多样化的空间问答对,而无需手动3D标注。经过处理单个帧而不是完整的视频,我们的流程确保了更高质量的语义提取和更可靠的重建结果,避免了将重建和语义提取技术应用于整个视频序列时通常遇到的噪声和不一致障碍。
C.3. 额外消融研究
| VSI-Bench | |||||||
| 物体计数 平均 | 绝对距离 | 物体尺寸 | 房间尺寸 | 相对距离 | 相对方向 | 路线规划 | |
| VSI-590K 混合 全部 | 63.2 73.5 | 49.4 | 71.4 | 70.1 | 66.9 | 61.5 | 出现顺序 36.6 76.4 |
| 无 配置 | 51.9 46.2 | 43.0 | 70.4 | 66.0 | 48.0 | 36.8 27.3 | 77.3 |
| 无 度量 | 49.7 74.5 | 19.1 | 31.1 | 38.5 | 63.9 | 55.6 35.1 | 79.5 |
| 无 时空 | 58.1 73.7 | 47.7 | 70.9 | 65.2 | 68.3 | 58.9 32.5 | 47.6 |
表10展示了一项关于不同任务组如何影响模型空间感知能力的消融研究。我们的结果表明,所有三个任务组——配置、度量和时空——都是不可或缺的,因为移除其中任何一个都会降低性能。我们进一步使用保留的路线规划子任务评估空间推理,发现配置组是最有影响力的,而度量组是最不具影响力的。我们将此结果归因于路线规划需要整体理解空间布局,这由设置问答对比度量和时空任务更明确地提供。
C.4. VSI-590K示例
为了更好地说明VSI-590K,我们在图19至25中提供了定性可视化结果。这些可视化表明VSI-590K为空间问答监督微调供应了巨大的多样性和质量。
D. Cambrian-S实现细节
在本节中,我们给予Cambrian-S模型的整体训练细节。
D.1. 模型架构
遵循原始Cambrian-1 [124]和大多数MLLMs的常见实践[78, 65],我们的模型(包括我们升级的Cambrian-1和Cambrian-S)集成了一个预训练的视觉编码器、一个预训练的语言模型作为解码器以及一个连接这两种模态的视觉语言连接器。具体来说,我们采用SigLIP2-So400M [128]作为视觉编码器。该编码器运用组合损失进行训练:文本下一令牌预测(LocCa [131])、图像-文本对比(或sigmoid [105, 157])和掩码自预测(SILC [96]/TiPS [88])。对于语言模型,我们利用指令微调的Qwen2.5 LLMs [145]。与使用SVA进行更深层次视觉语言融合的Cambrian-1不同,我们采用一个更简单的GELU激活[35]的两层MLP作为视觉语言连接器,以在性能和效率之间保持平衡。
D.2. 训练数据混合
如第3.4节所述,我们的Cambrian-S模型使用四个训练阶段进行训练(见图8)。对于前两个阶段(即视觉语言对齐阶段和图像指令微调阶段),我们请读者参考Cambrian-1 [124]了解详细的训练数据混合。在第三阶段,我们在精选的CambrianS-3M视频数据和从Cambrian-7M中采样的图像指令数据的混合上对模型进行视频指令微调。如先前阶段一样,视觉编码器保持冻结,其余模块进行微调。对于图像数据,我们重用第2阶段的采样策略。对于视频资料,我们对每个视频均匀采样64帧,将其调整为384×384384\times384384×384,并将其特征图进一步下采样到8×88\times88×8,即每帧64个令牌。
在第4阶段,大家通过在CambrianS-3M中采样590K视频样本和从Cambrian-7M中采样120K图像样本的混合语料库上进行微调,以保留通用视频和图像理解能力。训练设置大多与第3阶段一致,除了两个关键变化:(1)我们将每视频帧数增加到128,(2)我们将序列长度扩展到16,384,两者都是为了拥护更丰富的时间建模。第3和第4阶段的详细配置列于表12中。
D.3. 训练方法
阶段1:视觉语言对齐。我们冻结模型的大部分参数,仅使用Cambrian-Alignment-2.5M数据集[124]训练视觉语言连接器。输入图像填充到固定的384×384384 \times 384384×384分辨率,最大序列长度设置为2048。
阶段2:图像指令微调。我们解冻视觉语言连接器和LLM解码器,同时保持视觉编码器冻结。然后运用Cambrian-7M图像指令微调数据集对模型进行微调。与Cambrian-1 [14]相比,我们采用AnyRes策略[77]来增强模型的图像理解能力。具体来说,输入图像在保持纵横比的同时调整大小,然后分成多个384×384384\times 384384×384的子图像。这使得模型能够处理具有更高和更灵活分辨率的图像。为了适应AnyRes策略引入的视觉令牌数量的增加,大家将序列长度扩展到8192。第1和第2阶段的详细训练配置在表11中提供。
阶段3:通用视频指令微调。为了使模型具备通用视频理解能力,大家在精选的CambrianS-3M视频数据和从Cambrian-7M采样的图像指令素材的混合上进行视频指令微调。与先前阶段一样,视觉编码器保持冻结,其余模块进行微调。对于图像数据,我们重用第2阶段的采样策略。对于视频数据,我们对每个视频均匀采样64帧,将其调整为384×384384\times384384×384,并将其特征图进一步下采样到8×88\times88×8,即每帧64个令牌。
阶段4:空间视频指令微调。末了阶段侧重于通过在我们提出的VSi-590K上进行微调来增强模型的空间推理能力。为了保留通用视频和图像理解能力,我们混合了来自CambrianS-3M的590K视频样本和来自Cambrian-7M的120K图像样本。训练设置大多与第3阶段一致,除了两个关键变化:(1)我们将每视频帧数增加到128,(2)我们将序列长度扩展到16,384,两者都是为了帮助更丰富的时间建模。第3和第4阶段的详细配置列于表12中。
D.4. 基础设施
本文中的所有模型均使用TPU v4 Pods和TorchXLA框架进行训练。为了帮助大规模视频指令微调——其中长序列长度带来了高昂的计算和内存成本——我们利用了GSPMD [143]和Pallas实现的FlashAttention [34]。
GSPMD是一个为灵活和用户友好的大规模分布式训练设计的自动并行化系统。它允许用户像为单个设备一样编写训练代码,之后只需最少的更改即可轻松扩展到数百个设备。大家的训练框架基于TorchXLA和GSPMD,将数据、模型参数、激活和优化器状态分片到多个设备上。这降低了峰值内存使用量并提高了训练吞吐量。
为了适应长序列,我们集成了由Pallas支持的FlashAttention,这在长上下文输入下显著减少了TPU HBM(V-Mem)使用量。这使得我们能够在TPU v4-512 Pod上为7B模型将输入序列长度扩展到16,384个令牌。
E. Cambrian-S额外结果
E.1. 详细评估设置
通过我们描述了用于大多数图像和视频基准测试的评估设置,不包括VSi-SuPER。对于图像输入,遵循我们训练流程中采用的任意分辨率设计,每个图像在保持其纵横比的同时调整大小,并且其分辨率被最大化,以便能够划分为最多九个384×384384\times384384×384的子图像。对于视频输入,我们应用固定帧数的均匀帧采样。具体来说,第1阶段和第2阶段的检查点使用32个均匀采样的帧进行评估,而第3阶段和第4阶段的检查点分别使用64和128帧。
E.2. 在图像和视频基准测试上的详细性能
表13和表14详细说明了我们所有检查点(从第1阶段到第4阶段,从0.5B到7B)在基于图像和基于视频的MLLM基准测试上的性能。对于图像基准测试,我们报告了在MME [155]、MMBench [81]、SeedBench [66]、GQA [55]、ScienceQA [114]、MMMU [156]、MathVista [83]、AI2D [59]、ChartQA [91]、OCRBench[82]、TextVQA [165]、DocVQA [92]、MMVP [125]、RealworldQA [141]和CVBench [124]上的结果,遵循Cambrian-1的分组策略。
E.3. 基于图像和基于视频的指令微调的贡献
为了阐述基于图像和基于视频的指令微调对模型最终视频理解能力的各自贡献,我们进行了一系列实验。这些实验在微调阶段采用了不同比例的图像和视频数据,我们观察了在不同视频基准测试上产生的性能趋势。
更具体地说,对于初始的图像MLLM训练,我们从Cambrian-7M中随机采样1M、4M和7M图像问答(QA)对来训练不同的模型。随后,对于视频特定的微调,我们从LLaVA-Video-178K(总共约1.6M数据样本)中随机采样25%、50%、75%和100%的视频QA对,在每个预训练的图像MLLM上执行仅视频微调。图像指令微调和视频微调的超参数保持如表11和表12所述。实验结果呈现在表15中,得出以下观察结果:
在没有微调的情况下,在视频基准测试上评估时,使用更多图像数据训练的模型并不固有地优于使用较少数据训练的模型。如表所示,直接评估视频基准测试显示,三个模型(最初分别在1M、4M和7M图像信息集上训练)的性能相当。
在更大的图像信息集上预训练的模型进行视频数据微调通常是有益的,但并非普遍如此。当所有模型在100%视频数据上微调时,最初在7M图像上训练的模型在9个视频基准测试中的5个上(具体是HourVideo、VideoMME、EgoSchema、LongVideoBench和Perception Test)优于其他两个。
将视频数据纳入训练过程始终有利于所有视频基准测试的性能。我们观察到,即使用一小部分视频数据(如25%)对基于图像的MLLM进行微调,也能提高其在所有评估的视频基准测试上的性能。
增加用于微调的视频数据量并不能保证在所有基准测试上获得一致的性能改进。即使视频微调通常是有利的,但一些基准测试(例如,VideoMME、VSI-Bench、Tomato)并未显示更多视频数据带来的进一步增益。例如,在VideoMME基准测试上,使用100%视频材料微调的模型与仅使用25%视频数据微调的模型表现相当。只有EgoSchema、MVBench和Perception Test显示出从增加视频数据中持续获益,我们假设这种现象与训练视频的底层视频分布有关。
E.4. 关于空间感知与通用视频理解之间的权衡

在第3.3节中,我们比较了仅在VSi-590K上微调与在VSi-590K和通用视频材料混合上微调的模型性能。我们观察到,仅在VSi-590K上微调始终在空间感知任务上产生更高的性能,而混合数据微调在空间感知和通用视频理解之间提供了更好的平衡。为了进一步探索跨模型规模的此种权衡,我们在第3阶段之后,使用仅VSi-590K或混合数据集,在四种不同的模型大小(0.5B、1B、3B和7B参数)下进行微调。然后我们在通用视频理解和空间感知基准测试上评估这些模型,如图17所示。
结果证实了先前的结论在所有规模上都成立:仅VSi-590K微调在空间感知方面表现出色,而混合数据微调提供了更好的整体平衡。然而,值得注意的是,随着模型大小的增加,在VSi-Bench上的性能差距缩小。我们将此归因于更大模型学习和保留多样化能力的更大容量。这种趋势表明,扩展到更大的模型可能会进一步减轻通常在混合数据微调时观察到的空间感知性能下降。
F. 预测性感知
F.1. 潜在帧预测搭建细节
潜在帧预测头。如算法2所示,我们的下一帧预测头是一个简单的两层MLP,带有GELU激活[51],与MLLM的原始语言模型头并行运行。输出维度设置为1152,与我们的视觉编码器(即siglip2-so400m-patch14-384)的输出维度匹配。
算法2:潜在帧预测(LFP)头架构(PyTorch风格)。
LFPHead(
Sequential(
(0):Linear(in_features=3584,out_features=3584,bias=True)
(1):GELU(approximate=none)
(2):Linear(in_features=3584,out_features=1152,bias=True)
)
)
关于LFP和指令微调损失之间的平衡。如第4.1节所述,为了构建模型的内部世界模型,我们略微修改了我们的第4阶段,引入了两个辅助损失(即余弦距离和均方误差)来优化下一帧预测目标。应用一个系数来平衡LFP损失与指令微调损失,我们在表16中对此进行了消融。
| LFP 损失系数 | VSI-Bench | VideoMME | EgoSchema | Perception Test |
| 0.0 (即 无 LFP 损失) | 67.5 | 63.4 | 76.8 | 69.9 |
| 0.1 | 66.1 | 63.9 | 76.9 | 69.7 |
| 0.5 | 60.8 | 63.6 | 77.2 | 66.4 |
| 1.0 | 56.6 | 61.0 | 72.9 | 65.1 |
F.2. 用于VSI-SuPER回忆的记忆框架设计
如主论文中介绍(并在算法3中表现),大家的预测性记忆机制包括三个不同的记忆级别(Ms,Ml,Mw)\left(M_{s},M_{l},M_{w}\right)(Ms,Ml,Mw)和四个控制它们交互的关键转换函数:感官流、记忆压缩、记忆巩固和检索。本节详细说明这些函数的实现。
基本记忆单元。对于大家的实现,我们利用来自每个大语言模型(LLM)层的编码键值对作为基本记忆单元。这个选择,而不是运用来自视觉编码器或视觉语言连接器的输出潜在特征,允许我们充分利用LLM的内部能力进行记忆构建,而无需外部模块。这个设计决策将在后续章节中详细说明。
流式感知。每个传入的帧最初由视觉编码器和视觉语言连接器以窗口大小W独立处理。随后,它由LLM进一步编码,参考选定的先前帧。这些先前帧的键值对,缓存在感官记忆缓冲区(Ms)中,为此编码步骤供应了必要的上下文。
基于惊奇的记忆压缩。在编码单个帧的同时,我们评估其"惊奇"水平。这是通过计算模型对当前帧的预测与实际观测到的真实值(均在潜在特征空间中)之间的差异来实现的。当时间戳t的帧从感官记忆缓冲区MsM_{s}Ms移动到长期记忆MlM_{l}Ml时,如果它被认为是不令人惊奇的(即,其惊奇分数低于预定义阈值TsT_{s}Ts),我们将其’键值对沿空间(H×W)\left(H\times W\right)(H×W)+ 维度进行2倍下采样。这种基于惊奇的压缩减轻了存储在MlM_{l}Ml中的信息的冗余性。
基于惊奇的记忆巩固。长期记忆 Mı 初始化为预定义的预算大小BlongB_{l o n g}Blong(例如,32,768个令牌)。当记忆令牌量超过此预算时,我们对 M 应用基于惊奇的巩固函数以确保其保持在分配的限制内。我们的巩固函数容易而有用:我们识别与MlM_{l}Ml中每个帧相关联的惊奇分数。然后,移除(或"遗忘")具有最低惊奇分数的帧。然后,我们根据它们的惊奇分数合并或丢弃其中一些帧(我们在这里尝试了三种不同的策略:1. 遗忘最旧的记忆,2. 遗忘最不惊奇的记忆,以及3. 遗忘最不惊奇的记忆,同时合并任何相邻的惊奇记忆(如果存在任何相邻的惊奇记忆)。该过程迭代进行,直到 M 的总大小低于预算。
检索。在接收到用户查询 q 时,我们开始从长期记忆 (M) 中检索最相关的帧以构建工作记忆(Mw)\left(M_{w}\right)(Mw)1。然后,这个MwM_{w}Mw作为回答用户查询的上下文。为了高效地执行此检索而不诉诸外部模块,我们利用了LLM注意力机制固有的相似性测量能力。具体来说,对于每个Transformer层,用户查询 q 被转换为注意力机制的查询特征空间。然后,我们计算此查询特征与存储在MlM_{l}Ml中的每个帧的关键特征之间的相似性。相似性运用余弦距离测量,为简单起见,多头特征被视为单个特征。具有最高相似性得分的 k 个帧,其键值对被选中并被注意力机制用来进一步编码用户查询。
算法3:用于VSI-SuPER回忆的记忆框架设计。
输入:帧 {1, . . .,}, 用户查询
输入:编码器 E, 解码器 D, 惊奇估计器 S, 惊奇阈值 τ
输入:压缩函数 C, 巩固函数 G, 检索函数 R
输入:感官记忆 Ms ← ∅ 预算为 B, 长期记忆 M ← ∅ 预算为 B, 工作记忆 Mw ←0
1 for t ← 1 to T do
2Zt ← E(ft, Ms);
3Ms←MsU{zt};// 流式感知
4St ← S(ft, Ms) ;// 惊奇估计
5while |Ms| > Bs do
6Dequeue zold from Ms;
7m ← 1[s ≥ ] ·Zold + 1[ < ] · C(zold) ;// 选择性压缩
8M{←MlU{m};
9if |M| > B[ then
10Ml← G(Ml) ;// 记忆巩固
11 Mω ← R(q, M{) ;// 检索工作记忆
12 â← D(q, Mω) ;// 使用 Mw 回答查询
13 return a
F.3. 用于VSi-SUPER计数的智能体框架设计
算法4呈现了我们用于VSi-SuPeR计数任务的智能体框架。类似于算法3中的记忆设计,我们使用窗口大小为WsW_{s}Ws的滑动窗口方法对感官帧进行编码。潜在帧预测模块持续估计预期的下一帧并计算预测误差以量化实际下一帧的"惊奇"程度。当新帧到达时,超过感官记忆窗口的最旧帧被移出队列并存储在长期记忆中。如果一个出队的帧被认为是"令人惊奇的"(即,其预测误差超过预定义阈值 τ),这可能表明一个场景或空间边界,大家使用累积的长期记忆触发查询响应,并在之后重置它。生成的响应然后存储在答案记忆库中。最终答案计算为该库中所有中间答案的聚合。
算法4:用于VSi-SuPeR计数任务的智能体框架设计。
输入:帧 {f1,⋯ ,fT}\left\{f_{1},\cdots,f_{T}\right\}{f1,⋯,fT}, 用户查询 q
输入:编码器 E, 解码器 D, 惊奇估计器 S, 阈值 τ
输入:感官记忆 Ms ← ∅ 预算为 B
输入:长期记忆Ml←∅,\mathcal{M}_{l}\gets\emptyset,Ml←∅,, 答案记忆库MAns←∅\mathcal{M}_{\mathrm{A n s}}\leftarrow\emptysetMAns←∅
1fort ←1 to T do
2Zt ← E(ft, Ms);
3Ms←Ms∪{zt};// 流式感知
4st←S(ft,Ms)s_{t}\gets\mathcal{S}(f_{t},\mathcal{M}_{s})st←S(ft,Ms);// 惊奇估计
5if ∣Ms∣>Bs|\mathcal{M}_{s}|>B_{s}∣Ms∣>Bs then
6Remove oldest zold fromMs;\mathcal{M}_{s};Ms;
7Ml←Ml∪{zold} ;\mathcal{M}_{l}\leftarrow\mathcal{M}_{l}\cup\{z_{\mathrm{o l d}}\}\;;Ml←Ml∪{zold};// 存储到长期记忆
8if st ≥ τ then
9← D(q, M) ;// 使用长期记忆回答查询
10MAns← MAns ∪ {a};
11M{←0;// 重置长期记忆
12 return Sum(MAns)
F.4. 与现有长视频方法的比较
采用我们经过LFP微调的Cambrian-S-7B进行的,采用不同的策略来处理不断扩展的视觉感官输入。对于MovieChat,我们遵循[119]中的官方实现,维持一个固定大小的长期记忆库,并将长期和短期记忆预算分别设置为64和就是我们在表17中将我们的办法(包括惊奇驱动记忆和智能体框架)与为长视频理解设计的现有手段进行比较。具体来说,这里的所有实验都16,16,16,。对于Flash-VStream [159],由于其抽象记忆模块引入了额外的参数并且需要专门的训练过程,大家仅建立了其余三个记忆组件(即空间记忆、时间记忆和检索记忆),并保持所有其他超参数与默认设置一致。
| 评估设置 | VSR (时长 分钟.) | VSC (时长 分钟.) | |||||
| 10 | 30 09 | 120 240 | 10 | 30 | 09 | 120 | |
| MovieChat | 18.3 | 21.7 16.7 | 26.7 25.6 | 0.0 | 0.0 | 0.0 | 0.0 |
| Flash-VStream | 28.3 | 33.3 23.3 | 28.3 | 31.7 | 0.0 0.0 | 0.0 | 0.0 |
| 我们的方法 | 45.0 | 41.7 40.0 | 40.0 | 40.0 | 40.6 42.0 | 35.0 | 34.0 |

以下哪项正确表示了史迪奇在视频中出现的顺序?
A. 炉子, 垃圾桶, 冰箱, 柜台 B. 垃圾桶, 冰箱, 柜台, 炉子 C. 炉子, 柜台, 冰箱, 垃圾桶 D. 垃圾桶, 炉子, 柜台, 冰箱

以下哪项正确表示了Hello Kitty在视频中出现的顺序?
A. 床头柜, 床, 婴儿床, 蓝色长凳 B. 蓝色长凳, 婴儿床, 床头柜, 床 C. 床, 床头柜, 蓝色长凳, 婴儿床 D. 蓝色长凳, 床, 婴儿床, 床头柜

以下哪项正确表示了金毛寻回犬在视频中出现的顺序?
A. 床, 桌子, 抽屉柜, 地板 B. 桌子, 抽屉柜, 床, 地板 C. 抽屉柜, 地板, 桌子, 床 D. 地板, 床, 抽屉柜, 桌子

以下哪项正确表示了白色布偶猫在视频中出现的顺序?
A. 地面, 垃圾桶, 长凳, 桌子 B. 桌子, 长凳, 地面, 垃圾桶 C. 地面, 垃圾桶, 桌子, 长凳 D. 垃圾桶, 长凳, 桌子, 地面






物体计数(相对)
如果计数的话,椅子的数量是比桌子少、多还是相等?
A. 少
B. 多
C. 相等
相对方向(相机视角)
通过相机镜头,水槽是位于场景的左侧还是右侧部分?
A. 右
B. 左

物体计数(绝对)
如果你数一下所有的椅子,数量会是多少?
答案: 6
相对距离(相机视角)
沙发?就是就与相机的接近程度而言,哪个更近:桌子还
A. 桌子
B. 沙发

 浙公网安备 33010602011771号
浙公网安备 33010602011771号