


Python 机器学习入门实战:客户流失预测任务全教程
前言
机器学习作为人工智能的核心分支,已广泛应用于金融、医疗、互联网等多个领域。本教程将经过一个客户流失预测实战项目,带大家从零掌握 Python 机器学习的完整流程。计划采用公开的电信客户数据集,利用信息预处理、特征工程、模型训练与评估等步骤,构建能够预测客户是否会流失的机器学习模型。
教程适合 Python 入门者、机器学习新手,无需深厚的数学基础,只需掌握 Python 基础语法和 Pandas、NumPy 等库的基本运用。全程搭配完整代码、逻辑流程图、可视化图表和 Prompt 示例,帮助大家理解每个环节的核心原理与实操技巧,最终达到 “能复现、能修改、能迁移” 的学习目标。
一、项目整体框架与技术栈
1.1 项目核心目标
基于电信客户的历史数据(如套餐类型、消费金额、使用时长等),构建机器学习模型,预测客户未来是否会停止使用公司服务(即客户流失)。通过该模型,企业可提前识别高流失风险客户,针对性地制定留存策略,降低运营成本。
1.2 技术栈选型
| 工具 / 库 | 核心作用 |
|---|---|
| Python 3.9+ | 方案开发核心编程语言 |
| Pandas | 素材读取、清洗、预处理 |
| NumPy | 数值计算、数组处理 |
| Matplotlib/Seaborn | 内容可视化、特征分布与模型结果展示 |
| Scikit-learn(sklearn) | 特征工程、模型训练、评估与调优 |
| Jupyter Notebook | 代码编写、运行与结果展示(推荐编写环境) |
| Mermaid | 绘制项目流程与模型逻辑流程图 |
1.3 项目完整流程图(Mermaid 格式)
graph TD
A[项目启动] --> B[数据加载与探索性分析EDA]
B --> C[数据预处理]
C --> C1[缺失值处理]
C --> C2[异常值检测与处理]
C --> C3[分类变量编码]
C --> C4[数据归一化/标准化]
C1 --> D[特征工程]
C2 --> D
C3 --> D
C4 --> D
D --> D1[特征筛选]
D --> D2[特征衍生]
D1 --> E[数据集划分]
D2 --> E
E --> F[模型选择与训练]
F --> F1[逻辑回归]
F --> F2[决策树]
F --> F3[随机森林]
F --> F4[XGBoost]
F1 --> G[模型评估]
F2 --> G
F3 --> G
F4 --> G
G --> G1[准确率/精确率/召回率/F1分数]
G --> G2[ROC曲线/AUC值]
G --> G3[混淆矩阵]
G1 --> H[模型调优]
G2 --> H
G3 --> H
H --> H1[网格搜索GridSearchCV]
H --> H2[随机搜索RandomizedSearchCV]
H1 --> I[最优模型部署与预测]
H2 --> I
I --> J[项目总结与优化方向]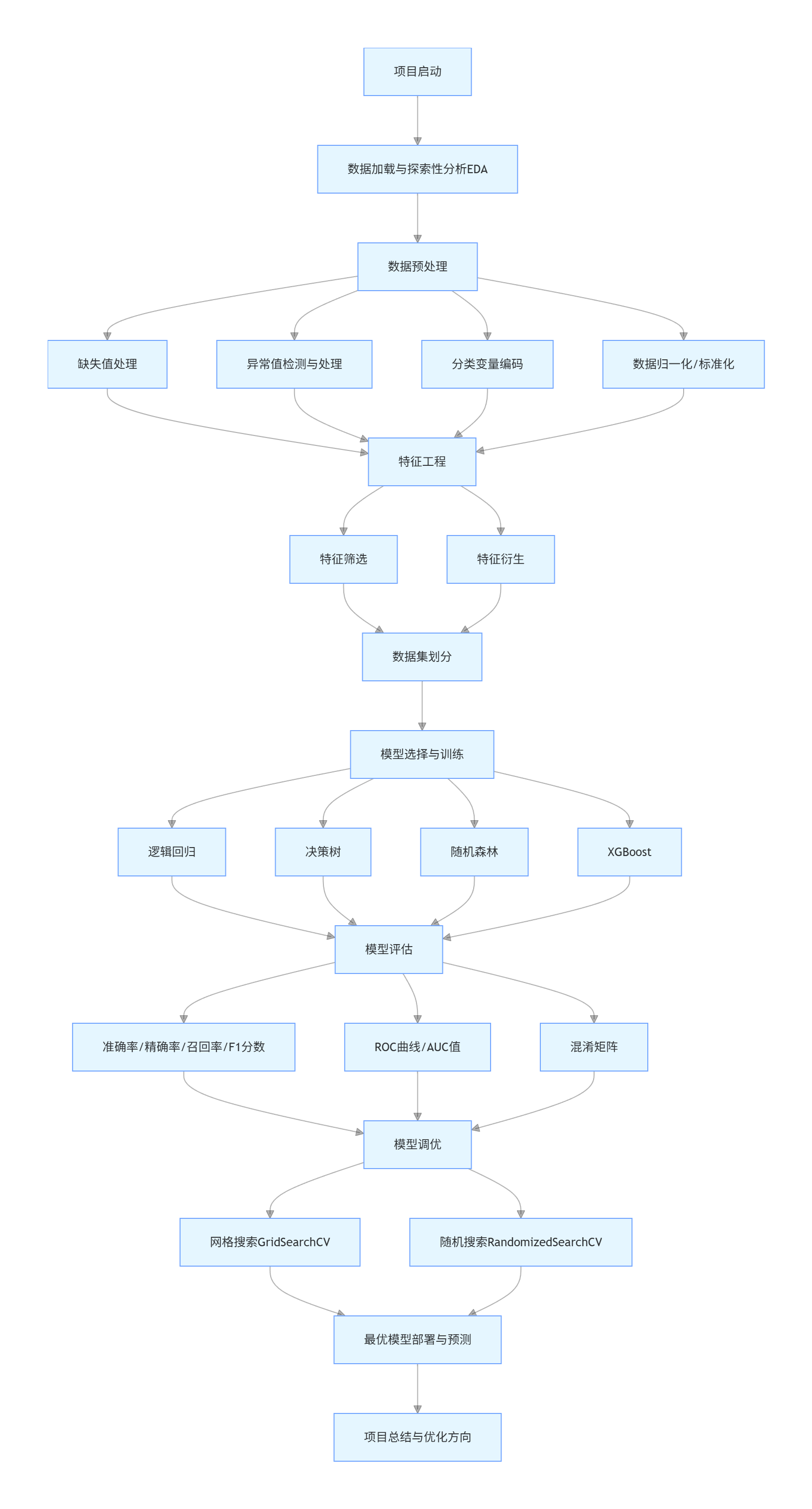

 浙公网安备 33010602011771号
浙公网安备 33010602011771号