


实用指南:Day49 | J.U.C集合-CopyOnWriteArrayList详解
CopyOnWriteArrayList是JDK1.5引入的,核心设计思想写时复制一直都没变化。
读操作不需要加锁,直接访问底层数组。
写操作会先获取锁,创建底层数组的副本,在副本上进行修改操作,修改完成后再把指向原数组的引用替换成指向新数组的引用。
之前我们在集合章节讲过ArrayList,知道他不是线程安全的。而CopyOnWriteArrayList可以作为ArrayList的线程安全替代品。
本文将从核心特性、实现原理、源码分析到应用场景,全面拆解CopyOnWriteArrayList。
一、ArrayList的线程不安全
来看一段简单的代码:
package com.lazy.snail.day49;
import java.util.ArrayList;
import java.util.List;
/**
* @ClassName ArrayListDemo
* @Description TODO
* @Author lazysnail
* @Date 2025/9/23 15:43
* @Version 1.0
*/
public class ArrayListDemo {
public static void main(String[] args) {
List list = new ArrayList<>(List.of(1, 2, 3));
new Thread(() -> {
try { Thread.sleep(50); } catch (InterruptedException ignored) {}
list.add(99);
}).start();
try {
for (Integer x : list) {
Thread.sleep(30);
System.out.println(x);
}
} catch (Exception e) {
e.printStackTrace();
}
}
} 当运行这个demo的时候,大概率会抛出ConcurrentModificationException。
抛出这个异常的本质就是主线程在遍历集合,手动创建的线程又改变了集合的结构,迭代器检查到了不一致的状态。
如果我们把ArrayList换成CopyOnWriteArrayList,就不会再抛出ConcurrentModificationException异常了。
但是要注意的是,list.add(99)加进去的元素,在迭代的时候,是遍历不出来的。
因为迭代器一开始拿到的就是原数组的引用。
二、CopyOnWriteArrayList的结构
2.1继承关系
CopyOnWriteArrayList类的类图如下:
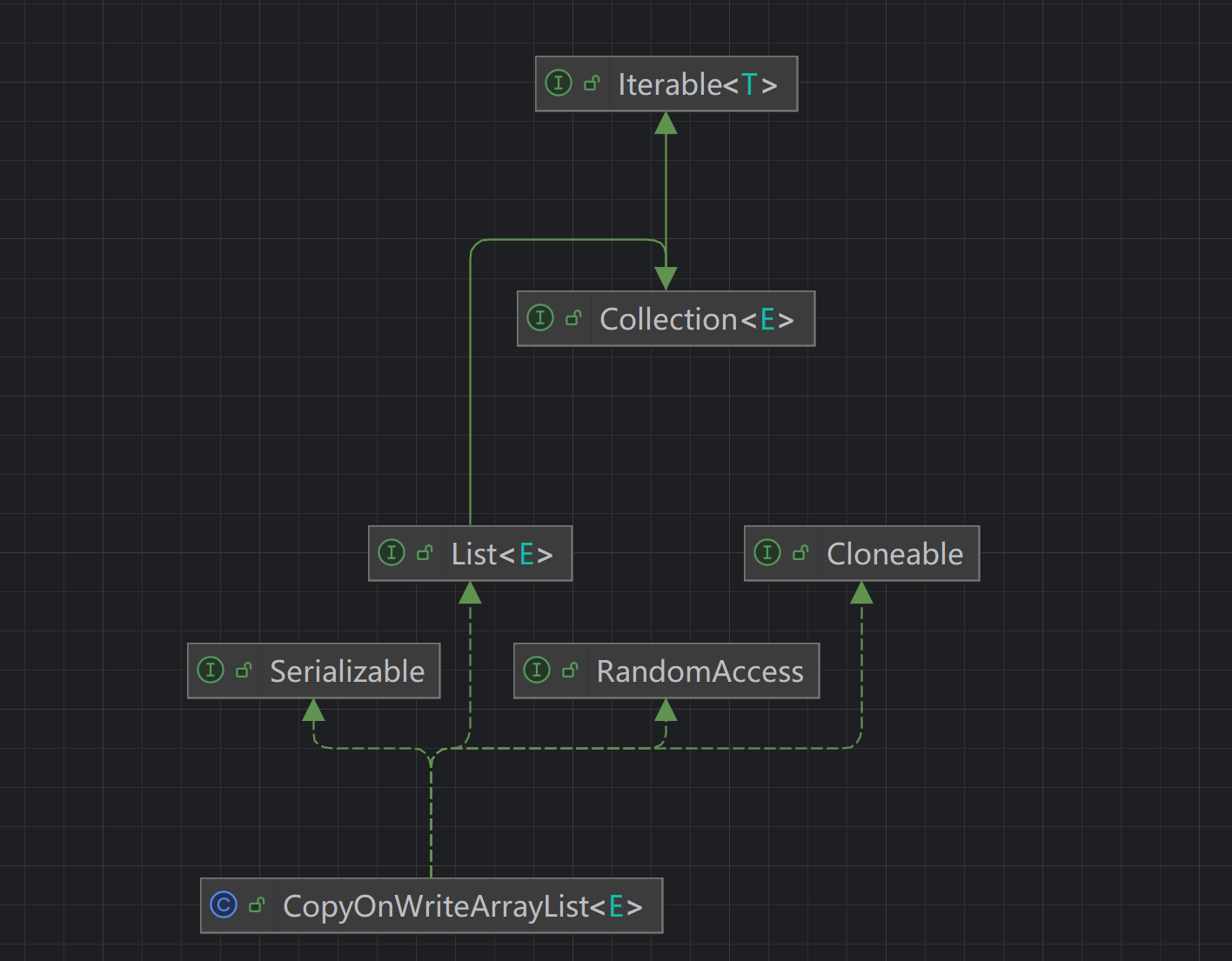
类图跟ArrayList其实非常相似,具备列表的基本特性。
支持迭代操作。支持序列化。支持随机访问。支持克隆。
2.2内部类
CopyOnWriteArrayList里有三个内部类:

COWIterator是一个自定义的迭代器, 通过持有原数组的快照(snapshot)和游标(cursor)来实现迭代,保证迭代过程不受后续修改影响。

COWSubList用来支持子列表操作,内部封装了对原列表的部分视图。

COWSubListIterator是COWSubList对应的迭代器,基于子列表的范围和偏移量实现迭代逻辑。

这些内部类属于框架级的实现细节,在业务开发中直接接触的场景并不多,作为了解。
2.3核心属性
/**
* The lock protecting all mutators. (We have a mild preference
* for builtin monitors over ReentrantLock when either will do.)
*/
final transient Object lock = new Object();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;lock是用来保证修改操作,比如add、remove等的原子性,所有的修改操作都会在这个锁的保护下执行。
array是存储集合元素的底层数组,也就是CopyOnWriteArrayList的核心数据容器。
2.4构造函数
/**
* Creates an empty list.
*/
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
public CopyOnWriteArrayList(Collection c) {
Object[] es;
if (c.getClass() == CopyOnWriteArrayList.class)
es = ((CopyOnWriteArrayList)c).getArray();
else {
es = c.toArray();
if (c.getClass() != java.util.ArrayList.class)
es = Arrays.copyOf(es, es.length, Object[].class);
}
setArray(es);
}
public CopyOnWriteArrayList(E[] toCopyIn) {
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}第一个是一个无参构造,初始化的时候array会创建一个空数组new Object[0]。
第二个构造接收一个集合,把接收到的集合转换成数组(有必要的话),然后把数组复制到底层数组array里。
第三个构造接收一个数组,同样是把数组复制到底层数组中。
三、核心方法解析
先来看读操作方法:
public E get(int index) {
return elementAt(getArray(), index);
}
public int size() {
return getArray().length;
}
public boolean isEmpty() {
return size() == 0;
}
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
Object[] es = getArray();
return indexOfRange(o, es, 0, es.length);
}
public int indexOf(E e, int index) {
Object[] es = getArray();
return indexOfRange(e, es, index, es.length);
}这些读操作都是基于底层的array数组,这个array是volatile修饰的不可变数组(修改操作的时候会创建新数组)。
读操作代码中没有任何的锁,也是由于没有锁的开销,读操作的性能非常高,但是有可能读到旧数据。
再来看看写操作,以add为例:
public boolean add(E e) {
synchronized (lock) {
Object[] es = getArray();
int len = es.length;
es = Arrays.copyOf(es, len + 1);
es[len] = e;
setArray(es);
return true;
}
}add方法中出现了synchronized关键字,表示在add过程中,只有一个线程会进来操作。
先拿到原来的底层数组,然后通过Arrays.copyOf复制一份,长度加一。然后把要添加的元素放到最后索引处。
最后通过setArray用新数组替换旧数组。
往指定的位置(索引)放元素要稍微复杂点。
public void add(int index, E element) {
synchronized (lock) {
Object[] es = getArray();
int len = es.length;
if (index > len || index < 0)
throw new IndexOutOfBoundsException(outOfBounds(index, len));
Object[] newElements;
int numMoved = len - index;
if (numMoved == 0)
newElements = Arrays.copyOf(es, len + 1);
else {
newElements = new Object[len + 1];
System.arraycopy(es, 0, newElements, 0, index);
System.arraycopy(es, index, newElements, index + 1,
numMoved);
}
newElements[index] = element;
setArray(newElements);
}
}加锁之后,先检查下索引是不是合法的。
如果是正好是要加在末尾,就直接复制旧数组(Arrays.copyOf)。
如果是添加到数组的中间位置,就要分两段复制旧数组(System.arraycopy)。
然后在指定的位置放上元素。
最后还是通过setArray替换旧数组。
我们从这两个操作来看,就知道每次add都要复制整个旧数组,如果数组规模很大的时候,内存消耗和GC回收肯定都是问题。
如果再叠加写操作很频繁的话,复制数组的操作加上锁的影像,直接就变成串行了。
再有一个add操作经历了一系列的操作,虽然是不影响读操作的,最后才把旧数组替换成了新的,这期间肯定会造成写后立即读却未读到新元素的情况。
再看一下remove方法:
public E remove(int index) {
synchronized (lock) {
Object[] es = getArray();
int len = es.length;
E oldValue = elementAt(es, index);
int numMoved = len - index - 1;
Object[] newElements;
if (numMoved == 0)
newElements = Arrays.copyOf(es, len - 1);
else {
newElements = new Object[len - 1];
System.arraycopy(es, 0, newElements, 0, index);
System.arraycopy(es, index + 1, newElements, index,
numMoved);
}
setArray(newElements);
return oldValue;
}
}移除指定位置上的元素。
同样上来就加锁,先拿到旧数组这个位置上的元素(最后会返回)。
如果移除的正好是末尾元素,最省事儿,直接Arrays.copyOf创建一个小1的数组把旧数组复制过去。
如果要移除的是中间位置元素,就先创建一个小1的数组,然后根据索引分段复制。
最后把新数组赋值给旧数组。
其实逻辑跟add(int index,E element)差不多。
四、应用场景
从上面的分析解读来看,CopyOnWriteArrayList的读操作是完全优于写操作的。
所以必然他的应用场景是读多写少的场景。
配置缓存、静态数据列表、日志记录这些场景场景,一般情况下都是进行频繁的查询,很少会去修改。
这种无锁读的优势能显著提升性能。
但是还是要考虑数据量的大小,如果数据量很多,一个数组长度百万级的数据,就算是极少的写操作。
由于CopyOnWriteArrayList的写时复制特性,成本(时间,空间)还是非常高。
再有一个就是不适合实时要求高的场景,因为CopyOnWriteArrayList只保证最终一致性而不是实时一致性。
写操作完成之后新数组才会被读操作可见。
结语
感觉没什么好总结的了,甩一张ArrayList和CopyOnWriteArrayList的对比吧。
特性 | ArrayList | CopyOnWriteArrayList |
|---|---|---|
线程安全性 | 非线程安全(并发修改会抛ConcurrentModificationException) | 线程安全(基于写时复制机制) |
锁机制 | 无锁 | 写操作加锁,读操作无锁 |
数据一致性 | 弱一致性(迭代器遍历过程中修改会触发快速失败) | 最终一致性(迭代器基于快照遍历,不抛并发异常) |
性能侧重 | 单线程或低并发场景(读写均无锁开销) | 高并发读场景(读操作无阻塞,写操作有复制开销) |
下一篇预告
Day50 | J.U.C集合-ConcurrentLinkedQueue详解
如果你觉得这系列文章对你有帮助,欢迎关注专栏,我们一起坚持下去!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号