


集合框架和泛型 - 实践
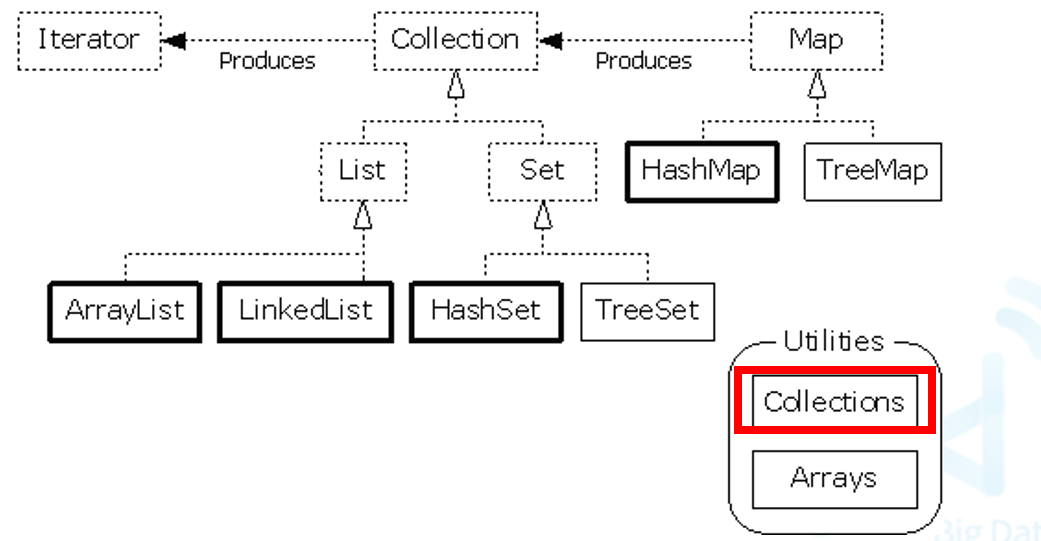
一、集合框架概述
1. 集合框架体系结构
Java集合框架主要分为两大类:
Collection接口:单列集合,存储一组对象(不唯一)
List:有序、可重复
Set:无序、不可重复
Queue:队列,先进先出
Map接口:双列集合,存储键值对(key-value)
2. 集合框架核心接口
Collection
├── List
│ ├── ArrayList
│ ├── LinkedList
│ └── Vector
├── Set
│ ├── HashSet
│ ├── LinkedHashSet
│ └── TreeSet
└── Queue
├── PriorityQueue
└── Deque
└── ArrayDeque
Map
├── HashMap
├── LinkedHashMap
├── TreeMap
└── Hashtable3. ArrayList的基本操作
// 创建一个空的ArrayList
ArrayList arrayList = new ArrayList<>();
// 创建具有初始容量的ArrayList
ArrayList numbers = new ArrayList<>(20);
// 从其他集合创建ArrayList
List existingList = Arrays.asList("A", "B", "C");
ArrayList fromExisting = new ArrayList<>(existingList); arrayList.add("Java"); // 添加到末尾
arrayList.add(0, "Python"); // 添加到指定位置
arrayList.addAll(List.of("C++", "JavaScript")); // 添加集合String first = arrayList.get(0); // 获取第一个元素
String last = arrayList.get(arrayList.size() - 1); // 获取最后一个元素
// 遍历ArrayList
for (String language : arrayList) {
System.out.println(language);
}
// 使用索引遍历
for (int i = 0; i < arrayList.size(); i++) {
System.out.println(arrayList.get(i));
}arrayList.set(1, "Go"); // 将索引1的元素改为"Go"arrayList.remove(0); // 按索引删除
arrayList.remove("Java"); // 按元素值删除
arrayList.removeAll(List.of("C++", "Python")); // 删除多个元素
arrayList.clear(); // 清空所有元素int size = arrayList.size(); // 获取元素数量
boolean isEmpty = arrayList.isEmpty(); // 判断是否为空
boolean contains = arrayList.contains("Java"); // 是否包含某元素
int index = arrayList.indexOf("Java"); // 获取元素索引ArrayList常用方法
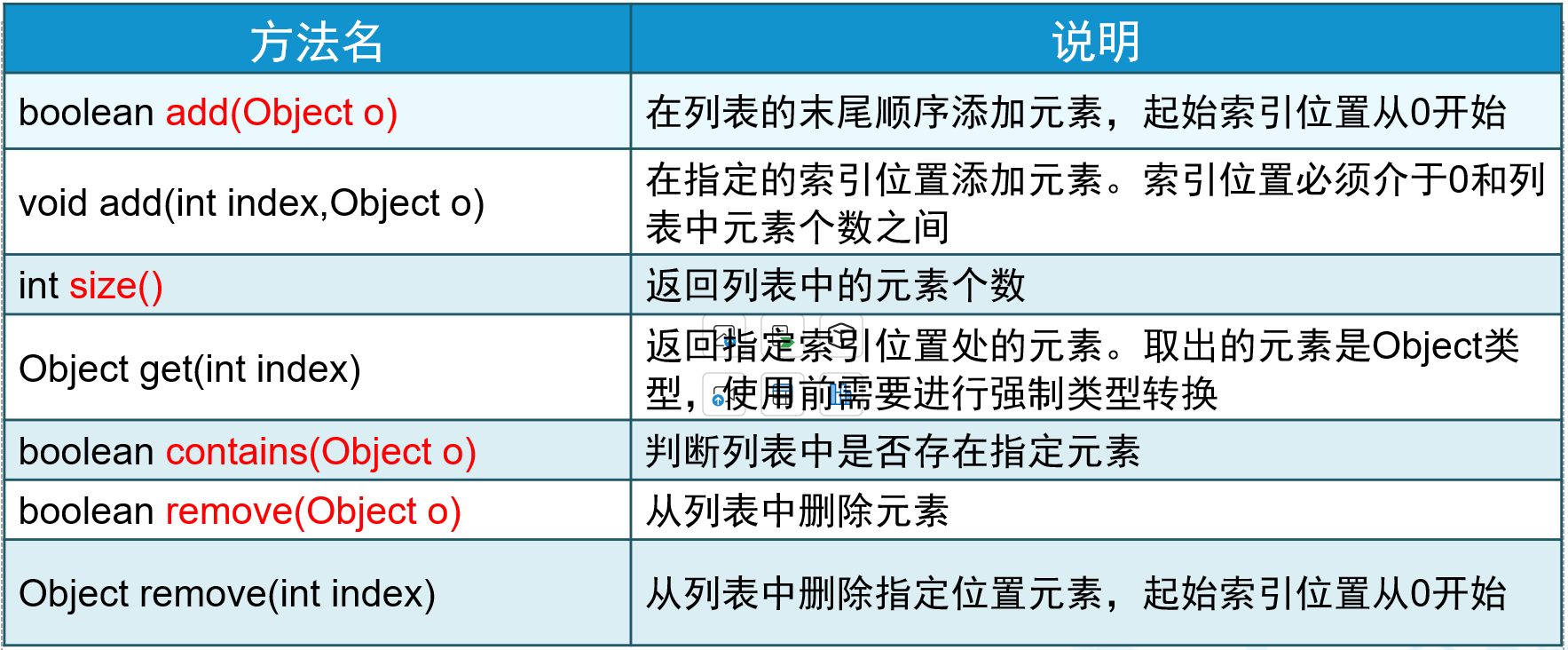
4.LinkedList的基本操作
LinkedList linkedList = new LinkedList<>();
// 从其他集合创建
LinkedList fromList = new LinkedList<>(Arrays.asList("A", "B", "C")); linkedList.add("Apple"); // 添加到末尾
linkedList.addFirst("Banana"); // 添加到开头
linkedList.addLast("Orange"); // 添加到末尾(同add)
linkedList.add(1, "Grape"); // 添加到指定位置String first = linkedList.getFirst(); // 获取第一个元素
String last = linkedList.getLast(); // 获取最后一个元素
String elem = linkedList.get(2); // 获取指定位置元素
// 遍历LinkedList
for (String fruit : linkedList) {
System.out.println(fruit);
}
// 使用ListIterator可以双向遍历
ListIterator iterator = linkedList.listIterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
} linkedList.set(1, "Mango"); // 修改指定位置元素linkedList.remove(); // 删除第一个元素
linkedList.removeFirst(); // 删除第一个元素
linkedList.removeLast(); // 删除最后一个元素
linkedList.remove("Apple"); // 删除指定元素
linkedList.remove(2); // 删除指定位置元素// 作为队列使用(FIFO)
linkedList.offer("Pear"); // 添加到队尾
String head = linkedList.poll(); // 移除并返回队头
// 作为栈使用(LIFO)
linkedList.push("Cherry"); // 压栈
String top = linkedList.pop(); // 弹栈LinkedList常用方法
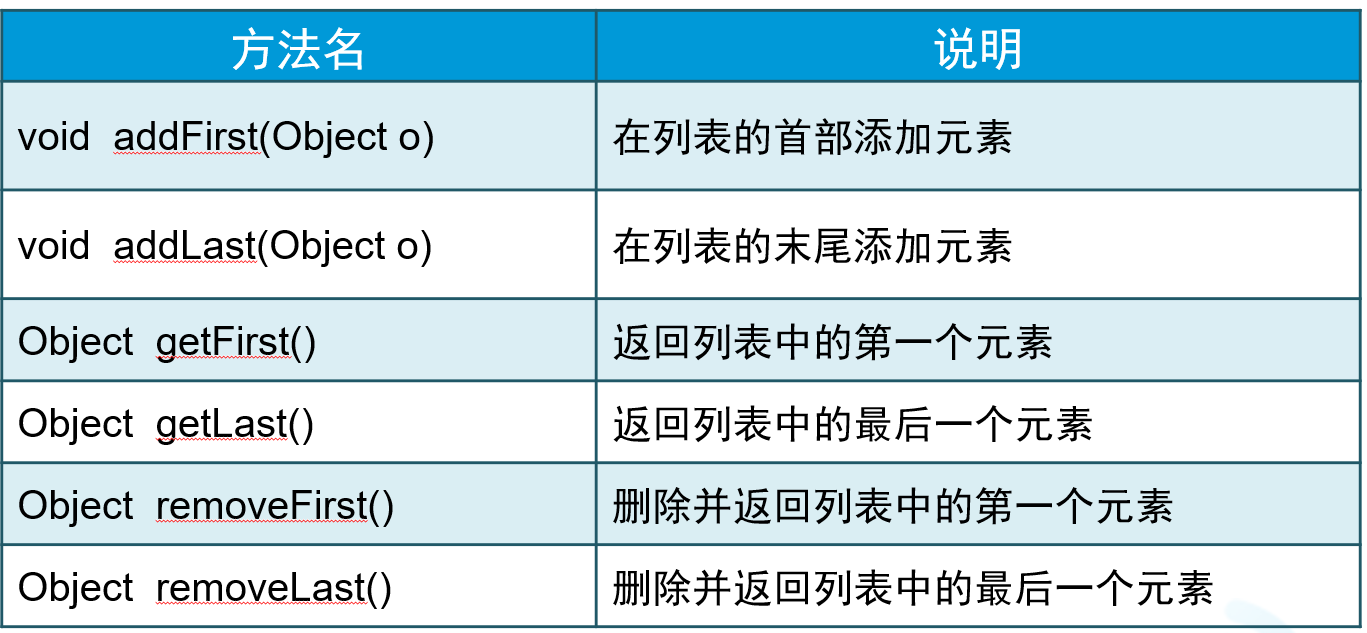
5.ArrayList与LinkedList的区别
1. 底层数据结构

2. 时间复杂度比较

3.使用场景对比

4.内存占用分析

6.Set接口
Set接口存储一组唯一,无序的对象
HashSet是Set接口常用的实现类
遍历操作
// 迭代器遍历
Iterator it = set.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
// for-each循环
for (String s : set) {
System.out.println(s);
} 二、Map接口
1. Map接口特点
键值对存储:存储的是key-value映射关系
key唯一性:不允许重复key(重复put会覆盖value)
value可重复:不同key可以对应相同value
key和value都允许为null(TreeMap的key不允许为null)
最常用的实现类是HashMap
HashMap 允许一个 null 键和多个 null 值。
HashMap 使用 hashCode() 定位存储位置,并用 equals() 判断键是否重复。
2. Map接口继承关系
Map
├── HashMap
│ └── LinkedHashMap
├── Hashtable
└── SortedMap
└── TreeMap3.Map接口常用方法
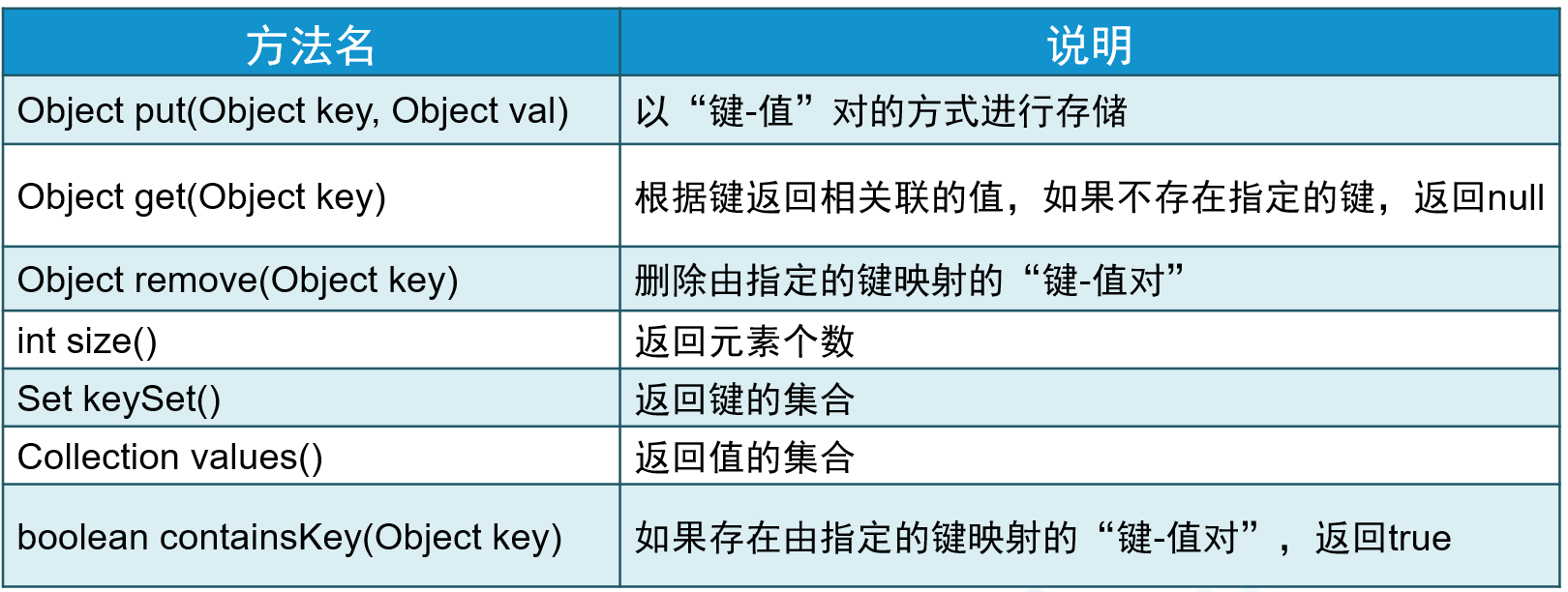
4.遍历Map集合
方法1:通过迭代器Iterator实现遍历
方法2:增强型for循环
方法3:键值对
三、最佳实践
1.选择合适集合:
随机访问多:ArrayList
插入删除多:LinkedList
去重:HashSet
排序:TreeSet/TreeMap
2.初始化时指定容量:
避免频繁扩容
3.使用泛型保证类型安全:
避免运行时类型转换错误
4.遍历集合
for-each循环
Iterator迭代器
JDK8+ Stream API
5.线程安全考虑
单线程:HashMap、ArrayList
多线程:ConcurrentHashMap、CopyOnWriteArrayList
或使用Collections.synchronizedXxx()包装
四、泛型
将对象的类型作为参数,指定到其他类或者方法上,从而保证类型转换的安全性和稳定性
本质是参数化类型
1.泛型基础
// 泛型类
class Box {
private T t;
public void set(T t) { this.t = t; }
public T get() { return t; }
}
// 泛型方法
public static void printArray(T[] array) {
for (T element : array) {
System.out.println(element);
}
} 2.泛型通配符
<?>:无界通配符
<? extends T>:上界通配符(T及其子类)
<? super T>:下界通配符(T及其父类)
当只需要从集合中获取元素(生产者)时,使用<? extends T>
当只需要向集合中添加元素(消费者)时,使用<? super T>
当既需要获取又需要添加时,不要使用通配符
3.类型擦除
编译时检查类型安全
运行时擦除类型信息
桥方法保持多态性
五、Collections算法类
Collections类定义了一系列用于操作集合的静态方法
Collections和Collection不同,前者是集合的操作类,后者是集合接口
Collections提供的常用静态方法
1.Collections类常用方法
sort(List<T> list)
根据元素的自然顺序对指定列表进行升序排序
示例:Collections.sort(list);
max(Collection<? extends T> coll)
根据元素的自然顺序返回集合中的最大元素
示例:String max = Collections.max(list);
min(Collection<? extends T> coll)
根据元素的自然顺序返回集合中的最小元素
示例:String min = Collections.min(list);
2.Collections排序
Collections类可以对集合进行排序、查找和替换操作
实现一个类的对象之间比较大小,该类要实现Comparable接口
重写compareTo()方法
HashMap
- HashMap允许一个null键和多个null值,这是正确的。
- HashMap使用键的hashCode()方法确定存储位置,并通过equals()方法确保键的唯一性,这是正确的。
- 初始容量和负载因子确实会影响HashMap的性能。初始容量过小会导致频繁扩容,负载因子过高会增加哈希冲突的可能性,这是正确的。
泛型通配符 <?>(无界通配符)表示可以接受任意类型的泛型参数,但它的主要限制是:
- 可以读取元素(因为所有类型都继承自 Object,可以用 Object 接收)。
- 不能添加元素(除了 null),因为编译器无法确定具体类型,无法进行类型安全检查

Arrays.asList()
- Arrays.asList() 方法返回的是一个 固定大小(fixed-size)的列表,由原始数组支持。
- 不能增加或删除元素(会抛出 UnsupportedOperationException),但可以修改已有元素(如 set())。
HashMap 的特性:
- 键唯一:如果插入相同的键("A"),新值会覆盖旧值。
- 允许 null 键和值。
- 无序存储(遍历顺序不固定)。
TreeSet 不依赖 equals() 判断元素唯一性,而是通过 compareTo() 或 Comparator.compare() 返回 0 来判断是否重复

 浙公网安备 33010602011771号
浙公网安备 33010602011771号