
完整教程:小杰深度学习(thirteen)——视觉-经典神经网络——GoogLeNet
1. 网络的根本介绍
GoogLeNet是一种流行的神经网络架构在2014年ImageNet挑战赛中由Google团队首次提出的,并且在那次就是,它通常用于图像分类任务。该网络架构分类比赛中获得了第一名的成绩。
GoogLeNet的主要特点是采用了一种名为“Inception”模块的结构,该模块可以管用地捕捉图像中的多尺度特征。
在Inception模块中,网络结构被分成多个并行的分支,每个分支都用于捕捉不同尺度的特征通过。这样,GoogLeNet网络就能够更有效地学习图像的特征,并且还行减少网络的体积。
GoogLeNet还采用了一种名为“平均池化”的技术,该技术行在不改变图像尺寸的情况下对图像进行降采样。这样,GoogLeNet网络就可以更快地处理图像,并且还允许提高网络的鲁棒性。
GoogLeNet论文名:Going deeper with convolutions。
论文地址:https://arxiv.org/abs/1409.4842
1.1网络结构的表
在paper中给出了网络结构的表,如下图所示:
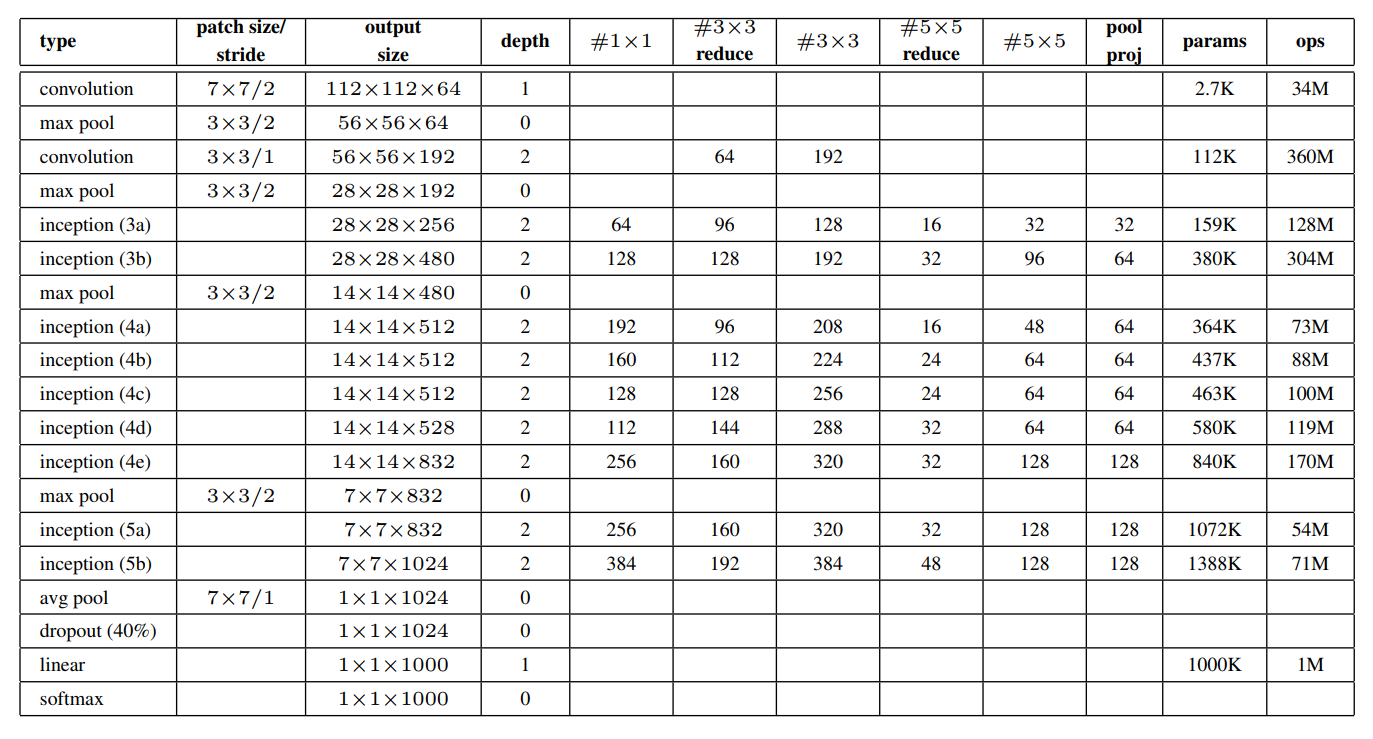
在上图中,type是每一层的结构,patch size/stride是卷积或者池化的核大小/步长,output size是本层的输出尺寸,depth是这一层的卷积深度,就是卷积层数,param是本层的参数量,ops是运算量。
#1×1表示 1×1 卷积核的数量,#3×3表示 3×3 卷积核的数量,#5×5表示 5×5 卷积核的数量,
#3×3 reduce” 和 “#5×5 reduce” 表示在 3×3 和 5×5 卷积之前的降维层中 1×1 滤波器(卷积核 )的数量。
Inception结构中的对应卷积的的参数,行和上面Inception结构对应着看。
GoogLeNet网络的网络结构图如下图所示:
2. 网络的创新
2. 网络的创新
Inception结构的思想和之前的卷积思想不同,之前的模型是将不同的卷积层通过串联连接起来的,不过Inception结构是通过串联+并联的方式将卷积层连接起来的。
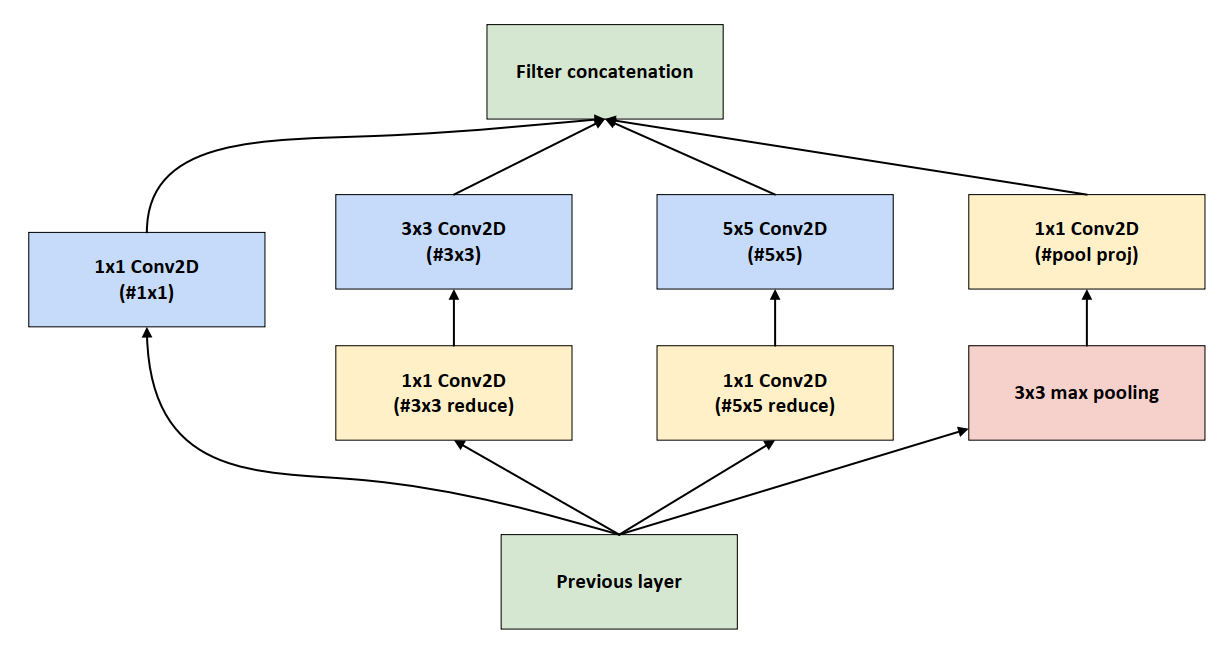
Inception结构是对输入图像并行地执行多个卷积运算或池化执行,并将所有输出结果拼接为一个非常深的特征图,且不同大小卷积核的卷积运算可能得到图像中的不同信息,处理获取到的图像中的不同信息可以得到更好的图像特征,一个Inception结构如下图所示。
Inception结构通常用于图像分类和识别任务,因为它能够有用地捕捉图像中的细节信息。它的主要优势在于能够以高效的方式处理大量的数据,并且模型的参数量相对较少,这使得它能够在不同的设备上运行。
2.2 1x1卷积核进行降维
需要注意的是Inception结构的四个分支中,每个分支所得到的特征矩阵的宽和高相同的,然后再将四个分就是必须支的特征矩阵沿着深度方向进行拼接。
因为1x1的卷积有着就是为什么在其中的三个分支中有1x1的卷积呢,降维的作用,举例说明,例如现在有一个输入特征矩阵为

:
- 直接经过64个5x5的卷积核进行卷积,那么要求5x5x512x64=819200的参数量;
- 经过1x1的卷积再经过64个5x5的卷积,这里1x1的卷积核个数例如是24个,因而需要的参数量为1x1x512x24+5x5x24x64=50688。
可以看到,在经过1x1的卷积降维后,参数量明显减少。
2.3 辅助分类器
辅助分类器通常与主要的分类器结合运用,以帮助模型更好地理解图像中的细节和复杂模式。这种手艺能够提高模型的泛化能力,使其更准确地预测未知的图像,在GoogLeNet中有两个辅助分类器,分别在Inception4a和Inception4d。
GoogLeNet 包含两个辅助分类器,该分类器仅用于训练,解决梯度消失问题。分类器的损失值将乘以 0.3 的权重被加到最终损失中。
它们的结构如下图所示:
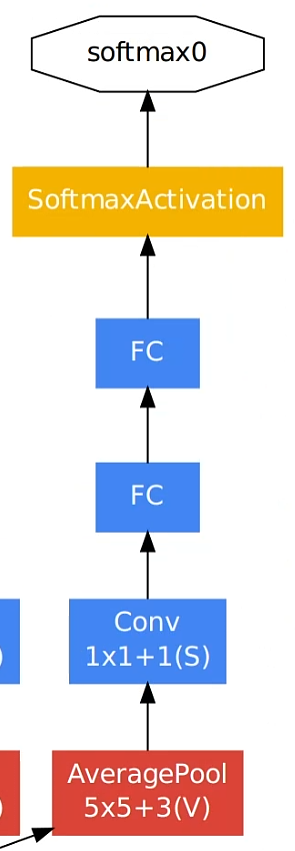
两个辅助分类器的结构式完全一致的:
- 平均池化层,池化核大小为5x5,步长为3。
- 卷积层,128个卷积核大小是1x1,步长为1。
3. 网络的问题
GoogLeNet缺点。
1.由于其启用了Inception模块,网络的计算复杂度较高。这使得GoogLeNet的训练速度较慢,不太适合对实时性要求较高的应用。
2.GoogLeNet的网络结构相对麻烦,不太容易理解,并且由于辅助分类器的存在,这使得在调试和优化网络时较为困难。
总之,GoogLeNet的计算复杂度高、网络结构麻烦是其主要缺点。
4.结构组件介绍
4.1 卷积
输入特征矩阵是(224 x 224 x 3),本层卷积核的宽、高、通道、个数是(7 x 7 x 3 x 64),步长为2,padding方式为SAME,经过计算可知,输出特征矩阵为(112 x 112 x 64)。
本层之后要经过ReLU激活函数,如下图:
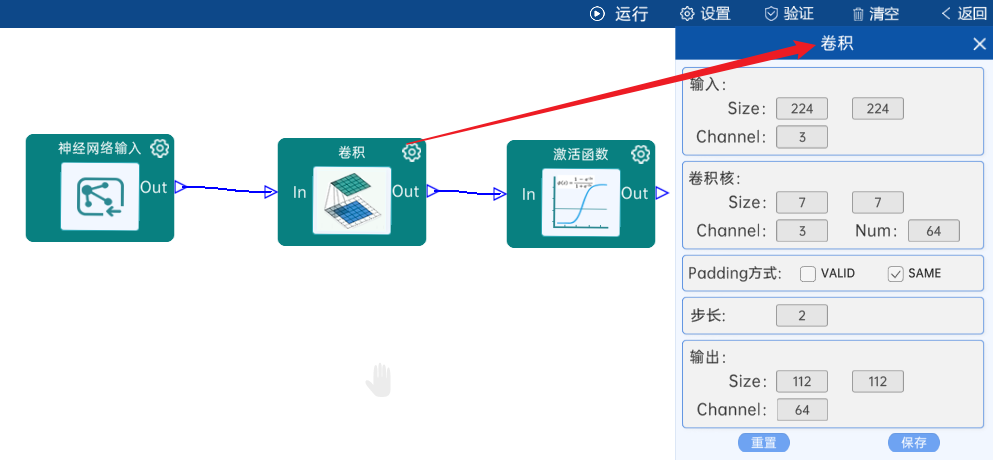
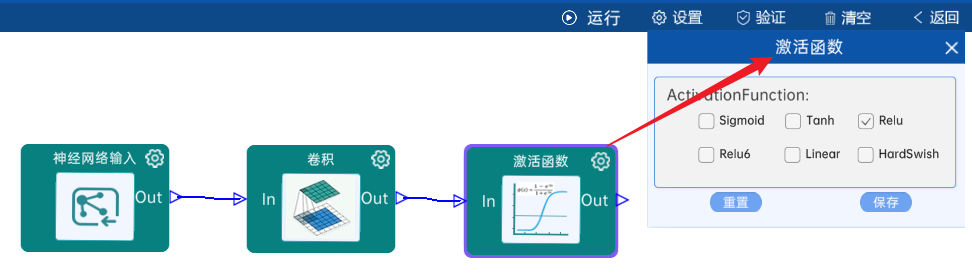
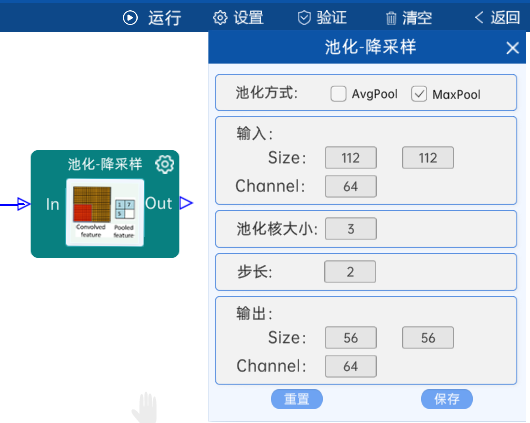
4.2 池化-降采样
池化方式为MaxPool,输入特征矩阵是(112 x 112 x 64),池化核大小为3,步长为2,经过计算可知,输出特征矩阵为(56 x 56 x 64),如下图:
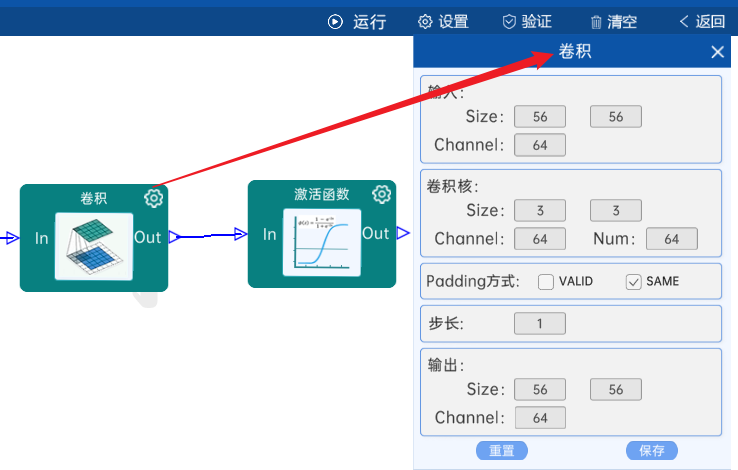
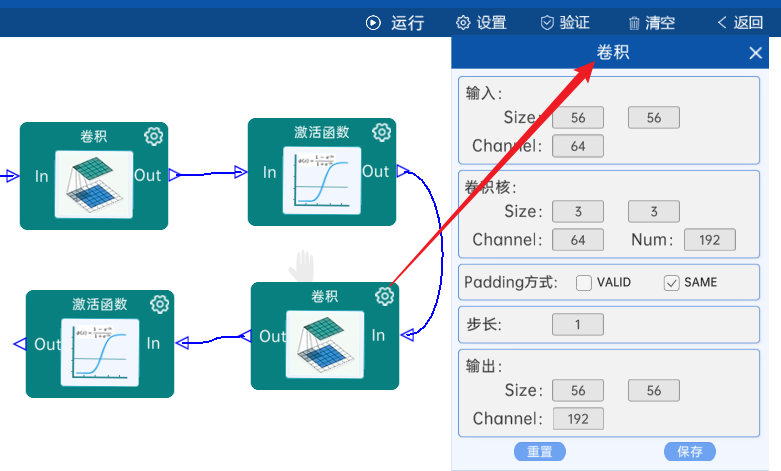
4.3 卷积
输入特征矩阵是(56 x 56 x 64),本层卷积核的宽、高、通道、个数是(3 x 3 x 64 x 64),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(56 x 56 x 64)。
本层之后要经过ReLU激活函数,如下图:
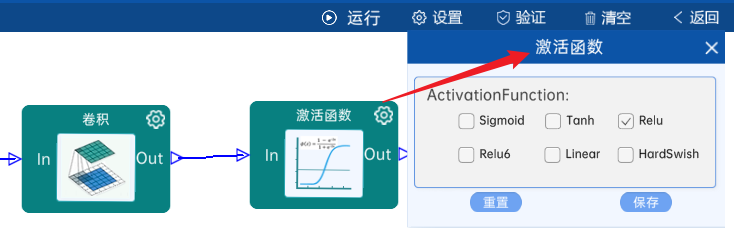
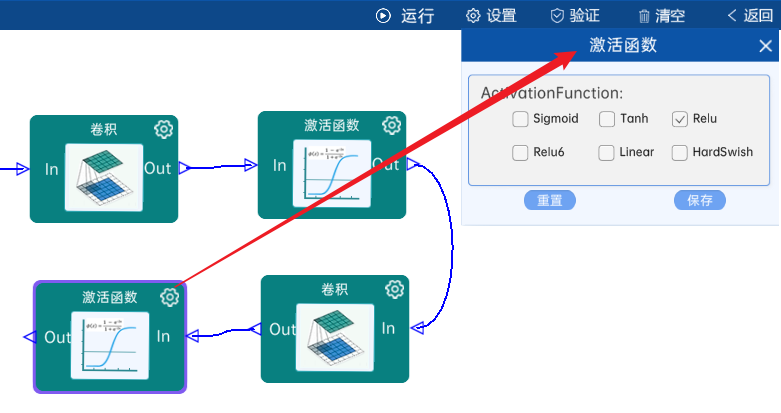
4.4 卷积
输入特征矩阵是(56 x 56 x 64),本层卷积核的宽、高、通道、个数是(3 x 3 x 64 x 192),步长为1,padding方式为SAME,经过计算可知,输出特征矩阵为(56 x 56 x 192)。
本层之后要经过ReLU激活函数,如下图:
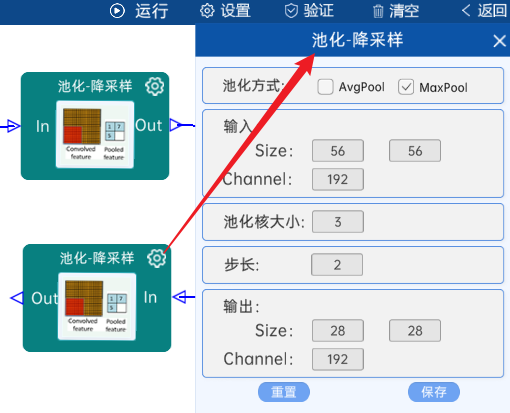
4.5 池化-降采样
池化方式为MaxPool,输入特征矩阵是(56 x 56 x 192),池化核大小为3,步长为2,经过计算可知,输出特征矩阵为(28 x 28 x 192),如下图:
4.6 Inception结构
不具有辅助分类器。(3a)
输入特征矩阵是(28 x 28 x 192),#1x1个数为64,#3x3reduce个数为96,#3x3个数为128,#5x5reduce个数为16,#5x5个数为32,pool proj个数为32,经过计算可知,输出特征矩阵为(28 x 28 x 256),如下图:
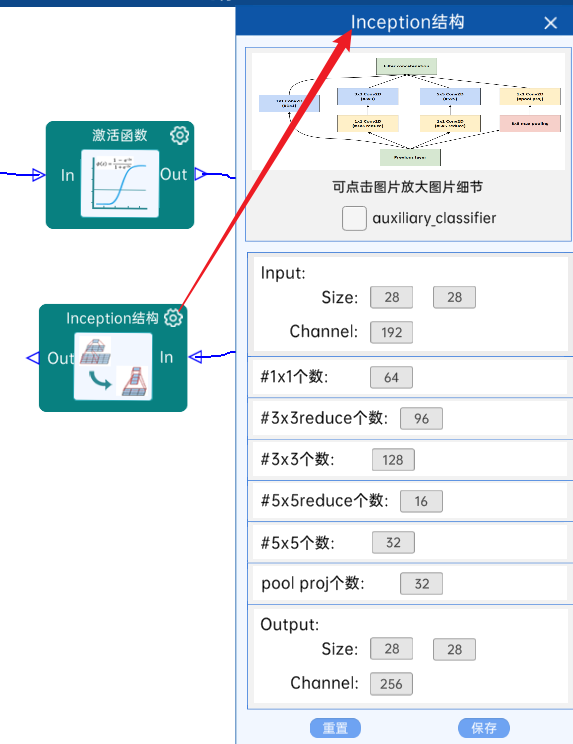
4.7 Inception结构
不具有辅助分类器。(3b)
输入特征矩阵是(28 x 28 x 256),#1x1个数为128,#3x3reduce个数为128,#3x3个数为192,#5x5reduce个数为32,#5x5个数为96,pool proj个数为64,经过计算可知,输出特征矩阵为(28 x 28 x 480),如下图:
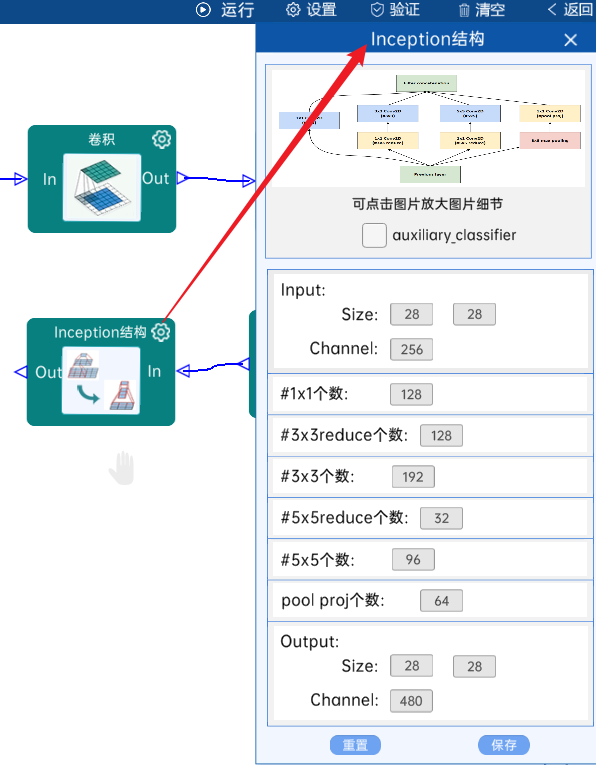
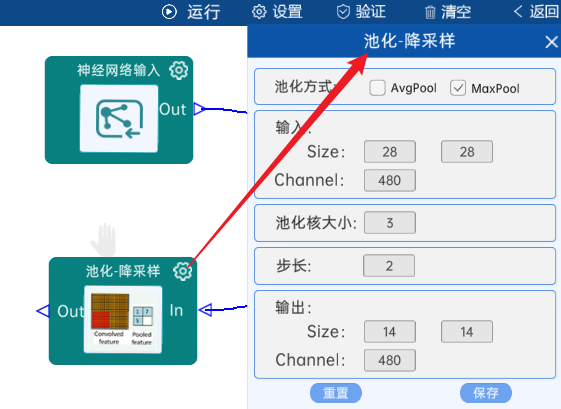
4.8 池化-降采样:
池化方式为MaxPool,输入特征矩阵是(28 x 28 x 480),池化核大小为3,步长为2,经过计算可知,输出特征矩阵为(14 x 14 x 480),如下图:
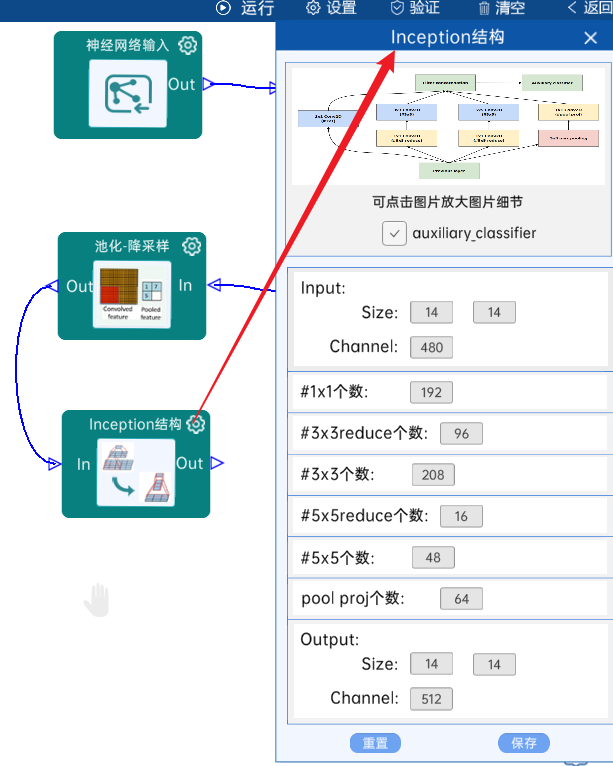
4.9 Inception结构
具有辅助分类器(4a)。
输入特征矩阵是(14 x 14 x 480),#1x1个数为192,#3x3reduce个数为96,#3x3个数为208,#5x5reduce个数为16,#5x5个数为48,pool proj个数为64,经过计算可知,输出特征矩阵为(14 x 14 x 512),如下图:
4.10 Inception结构
不具有辅助分类器。(4b)
(14 x 14 x 512),#1x1个数为160,#3x3reduce个数为112,#3x3个数为224,#5x5reduce个数为24,#5x5个数为64,pool proj个数为64,经过计算可知,输出特征矩阵为(14 x 14 x 512),如下图:就是输入特征矩阵
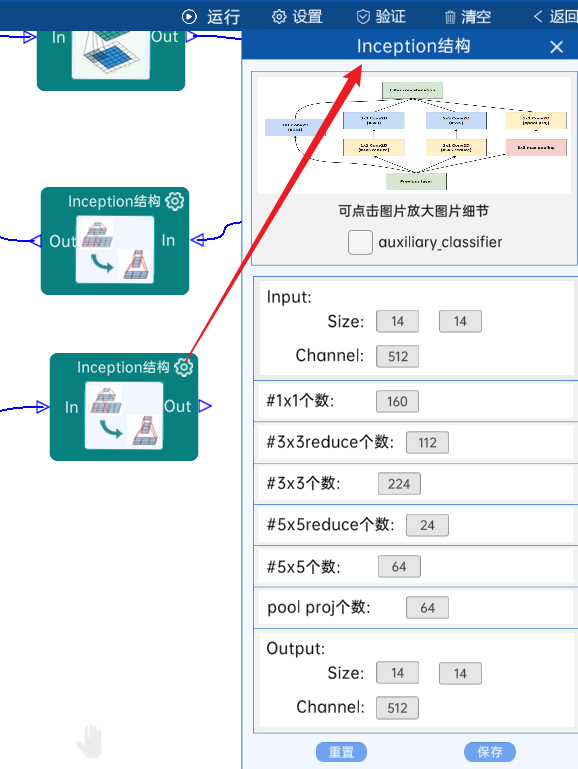
4.11 Inception结构
不具有辅助分类器。(4c)
(14 x 14 x 512),#1x1个数为128,#3x3reduce个数为128,#3x3个数为256,#5x5reduce个数为24,#5x5个数为64,pool proj个数为64,经过计算可知,输出特征矩阵为(14 x 14 x 512),如下图:就是输入特征矩阵
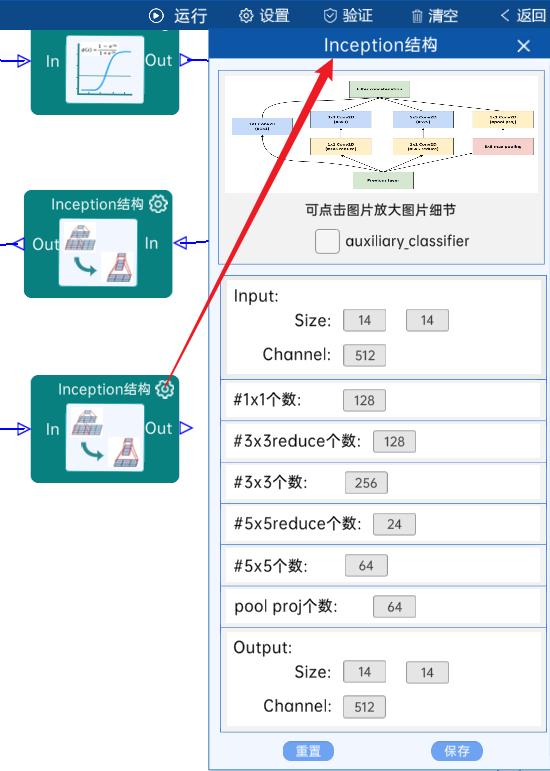
4.12 Inception结构
具有辅助分类器。(4d)
输入特征矩阵是(14 x 14 x 512),#1x1个数为112,#3x3reduce个数为144,#3x3个数为288,#5x5reduce个数为32,#5x5个数为64,pool proj个数为64,经过计算可知,输出特征矩阵为(14 x 14 x 528),如下图:
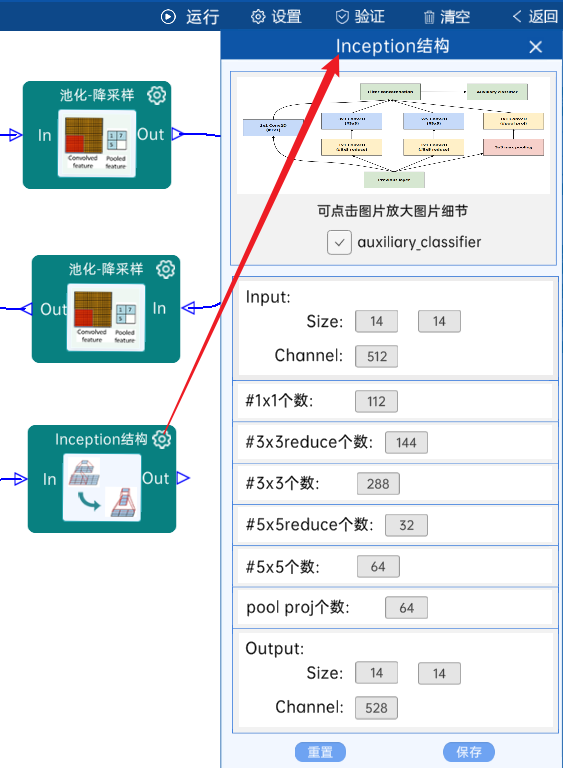
4.13 Inception结构
不具有辅助分类器。(4e)
输入特征矩阵是(14 x 14 x 528),#1x1个数为256,#3x3reduce个数为160,#3x3个数为320,#5x5reduce个数为32,#5x5个数为128,pool proj个数为128,经过计算可知,输出特征矩阵为(14 x 14 x 832),如下图:
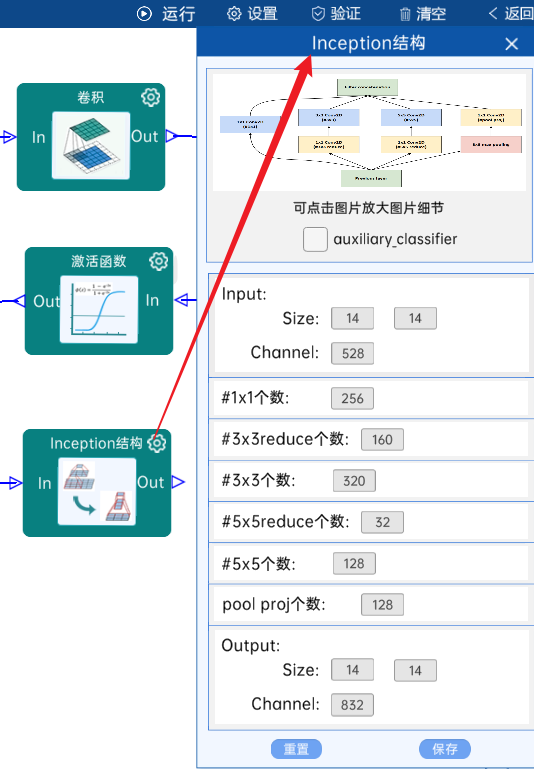
4.14 池化-降采样:
池化方式为MaxPool,输入特征矩阵是(14 x 14 x 832),池化核大小为3,步长为2,经过计算可知,输出特征矩阵为(7 x 7 x 832),如下图:
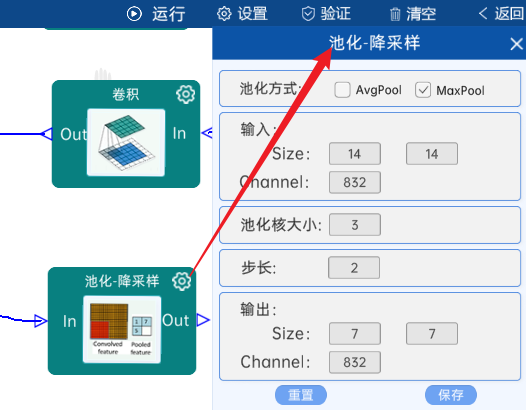
4.15 Inception结构
不具有辅助分类器。(5a)
输入特征矩阵是(7 x 7 x 832),#1x1个数为256,#3x3reduce个数为160,#3x3个数为320,#5x5reduce个数为32,#5x5个数为128,pool proj个数为128,经过计算可知,输出特征矩阵为(7 x 7 x 832),如下图:
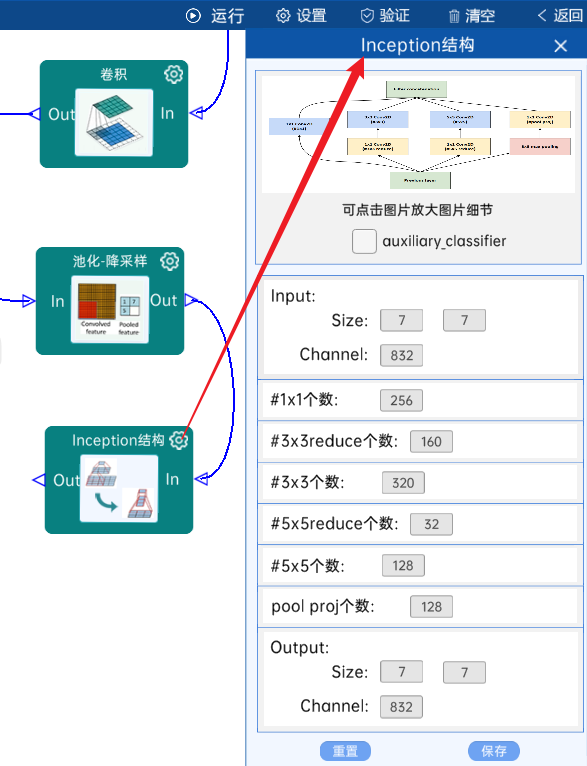
4.16 Inception结构
不具有辅助分类器。(5b)
输入特征矩阵是(7 x 7 x 832),#1x1个数为384,#3x3reduce个数为192,#3x3个数为384,#5x5reduce个数为48,#5x5个数为128,pool proj个数为128,经过计算可知,输出特征矩阵为(7 x 7 x 1024),如下图:
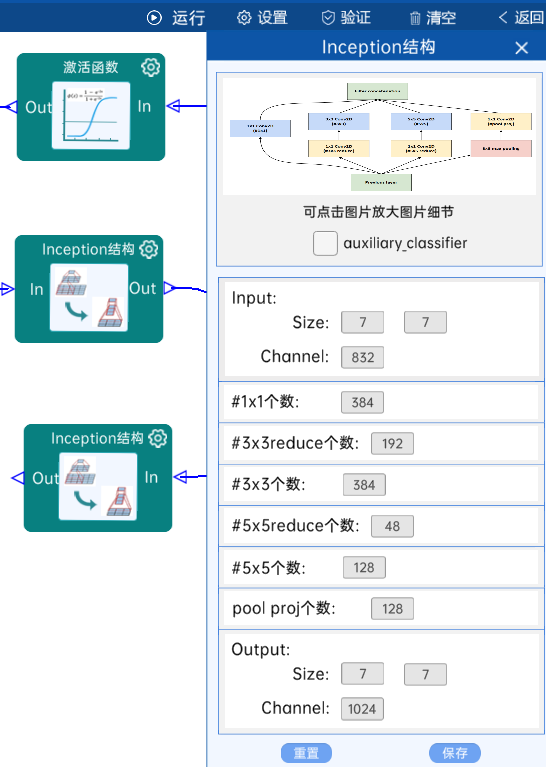
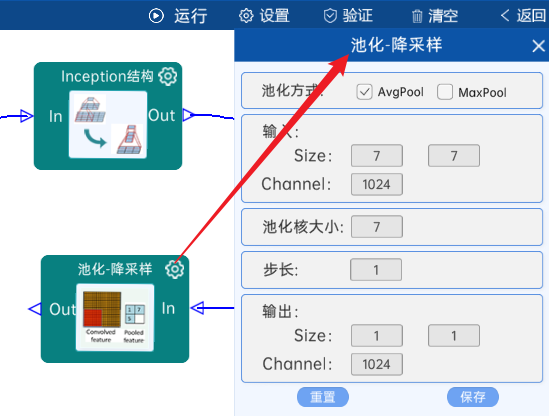
4.17 池化-降采样
池化方式为AvgPool,输入特征矩阵是(7 x 7 x 1024),池化核大小为7,步长为1,经过计算可知,输出特征矩阵为(1 x 1 x 1024),如下图:
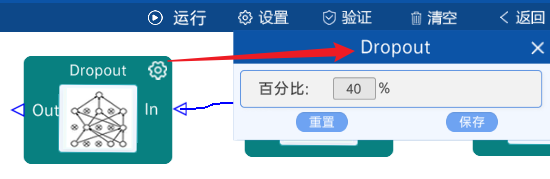
4.18 dropout
保留40%的神经元个数,如下图:
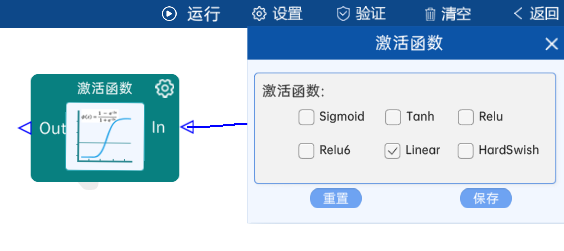
4.19 激活函数
采用Linear激活,如下图:
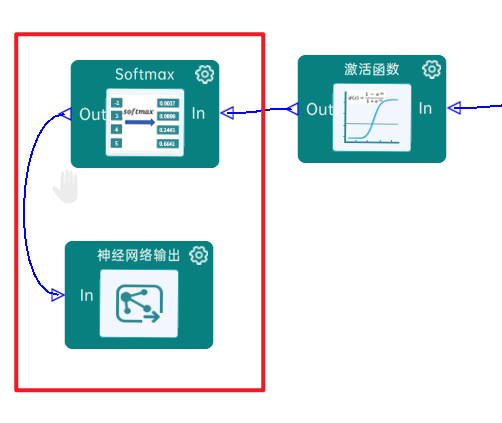
4.20 Softmax
最后通过Softmax实现将多分类的输出值转换为范围在[0, 1]和为1的概率分布,如下图:
4.21实验验证
正确的。就是本实验主要学习GoogLeNet的网络的相关知识,最后需要进行点击“验证”,验证成功即代表网络结构连接
5.代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 定义一个名为Inception的类,该类继承自nn.Module
class Inception(nn.Module):
# 定义类的构造函数,接受以下参数:in_channels(输入通道数)、ch1x1(1x1卷积的输出通道数)、ch3x3red(3x3卷积前的压缩通道数)、
# ch3x3(3x3卷积的输出通道数)、ch5x5red(5x5卷积前的压缩通道数)、ch5x5(5x5卷积的输出通道数)、pool_proj(池化投影后的输出通道数)
def __init__(self,in_channels,ch1x1,ch3x3red,ch3x3,ch5x5red,ch5x5,pool_proj):
super(Inception,self).__init__()
# 定义一个名为branch1的分支,该分支使用一个1x1的卷积层,输入通道数为in_channels,输出通道数为ch1x1
self.branch1=BasicConv2d(in_channels=in_channels,out_channels=ch1x1, kernel_size=1)
# 定义一个名为branch2的分支,该分支先经过一个1x1的卷积层进行通道数的压缩,然后再经过一个3x3的卷积层,保证输出大小等于输入大小
self.branch2=nn.Sequential(
BasicConv2d(in_channels=in_channels,out_channels=ch3x3red,kernel_size=1),
# 保证输出大小等于输入大小
BasicConv2d(in_channels=ch3x3red, out_channels=ch3x3, kernel_size=3, padding=1)
)
# 定义一个名为branch3的分支,该分支先经过一个1x1的卷积层进行通道数的压缩,然后再经过一个5x5的卷积层,保证输出大小等于输入大小。
# 注意,实际上官方的实现中使用的是3x3的卷积
self.branch3 = nn.Sequential(
BasicConv2d(in_channels=in_channels, out_channels=ch5x5red, kernel_size=1),
# 在官方的实现中,其实是3x3的kernel并不是5x5
BasicConv2d(in_channels=ch5x5red, out_channels=ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
# 定义一个名为branch4的分支,该分支先经过一个3x3的池化层,然后再经过一个1x1的卷积层
self.branch4=nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=1,padding=1),
BasicConv2d(in_channels=in_channels, out_channels=pool_proj, kernel_size=1)
)
#定义前向传播
def forward(self,x):
branch1=self.branch1(x)
branch2=self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
# 将四个分支的输出结果放入outputs列表中
outputs=[branch1,branch2,branch3,branch4]
# 使用torch.cat函数将outputs列表中的张量拼接在一起,拼接的维度为1(列方向),并返回拼接后的结果
return torch.cat(outputs, 1)
#,定义辅助分类器 InceptionAux类
class InceptionAux(nn.Module):
# 定义构造函数__init__,输入参数为in_channels(输入通道数)和num_classes(类别数)
def __init__(self, in_channels, num_classes):
# 调用父类的构造函数
super(InceptionAux, self).__init__()
# 定义一个2D平均池化层,池化窗口大小为5x5,步长为3
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
# 定义一个基本的2D卷积层,输入通道数为in_channels,输出通道数为128,卷积窗口大小为1x1
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
# 定义一个全连接层,输入特征数为2048,输出特征数为1024
self.fc1 = nn.Linear(2048, 1024)
# 定义第二个全连接层,输入特征数为1024,输出特征数为num_classes(类别数)
self.fc2 = nn.Linear(1024, num_classes)
# 定义前向传播函数forward,输入参数为x(输入张量)
def forward(self, x):
# 对输入的x进行平均池化
x = self.averagePool(x)
# 对x进行卷积
x = self.conv(x)
# 将x按照第1维进行展平
x = torch.flatten(x, 1)
# 进行dropout操作,丢弃概率为0.5,使用training来表示是否为训练阶段
x = F.dropout(x, 0.5, training=self.training)
# 使用ReLU进行激活
x = F.relu(self.fc1(x))
# 进行dropout操作,丢弃概率为0.5,使用training来表示是否为训练阶段
x = F.dropout(x, 0.5, training=self.training)
# 进行全连接
x = self.fc2(x)
# 返回最后的x
return x
#定义一个名为BasicConv2d的类
class BasicConv2d(nn.Module):
def __init__(self,in_channels, out_channels, **kwargs):
super(BasicConv2d,self).__init__()
#定义一个2d卷积层,输入通道为in_channels,输出通道为out_channels,其他参数通过**kwargs传入
self.conv=nn.Conv2d(in_channels,out_channels,**kwargs)
#定义一个relu激活函数
self.relu=nn.ReLU(inplace=True)
def forward(self,x):
x=self.conv(x)
x=self.relu(x)
return x
#定义GoogleNet类
class GoogleNet(nn.Module):
def __init__(self,num_classes=1000,aux_logits=True):
super(GoogleNet,self).__init__()
#是否使用辅助分类器
self.aux_logits=aux_logits
# 第一层卷积层,使用BasicConv2d模块,输入通道数为3,输出通道数为64,卷积核大小为7,步长为2,填充为3
self.conv1=BasicConv2d(3,64,kernel_size=7,stride=2,padding=3)
# 第一层最大池化层,池化窗口大小为3,步长为2,采用ceil方式计算输出大小
self.maxpool1=nn.MaxPool2d(3,stride=2,ceil_mode=True)
# 第二层卷积层,输入通道数为64,输出通道数为64,卷积核大小为1
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
# 第三层卷积层,输入通道数为64,输出通道数为192,卷积核大小为3,填充为1
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
# 第一层最大池化层,池化窗口大小为3,步长为2,采用ceil方式计算输出大小
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
# 第四层卷积层,使用Inception模块,输入通道数为192,输出通道数分别为64、96、128、16、32、32
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
# 第五层卷积层,使用Inception模块,输入通道数为256,输出通道数分别为128、128、192、32、96、64
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
# 第三层最大池化层,池化窗口大小为3,步长为2,采用ceil方式计算输出大小
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
# 第六层卷积层,使用Inception模块,输入通道数为480,输出通道数分别为192、96、208、16、48、64
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
# 第七层卷积层,使用Inception模块,输入通道数为512,输出通道数分别为160、112、224、24、64、64
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
# 第八层卷积层,使用Inception模块,输入通道数为512,输出通道数分别为128、128、256、24、64、64
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
# 第九层卷积层,使用Inception模块,输入通道数为512,输出通道数分别为112、144、288、32、64、64
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
# 第十层卷积层,使用Inception模块,输入通道数为528,输出通道数分别为256、160、320、32、128、128
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
# 第四层最大池化层,池化窗口大小为3,步长为2,采用ceil方式计算输出大小
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
# 第十一层卷积层,使用Inception模块,输入通道数为832,输出通道数分别为256、160、320、32、128、128
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
# 第十二层卷积层,使用Inception模块,输入通道数为832,输出通道数分别为384、192、384、48、128、128
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
# 如果使用辅助分类器,则添加两个InceptionAux模块,分别输入512和528通道的张量,输出num_classes个结果
if self.aux_logits:
self.aux1=InceptionAux(512,num_classes)
self.aux2=InceptionAux(528,num_classes)
# 使用自适应平均池化层,将输入张量的大小调整为(1, 1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# Dropout层,将输入张量的40%元素设为0
self.dropout = nn.Dropout(0.4)
# 全连接层,输入大小为1024,输出大小为num_classes
self.fc = nn.Linear(1024, num_classes)
def forward(self,x):
x=self.conv1(x)
x=self.maxpool1(x)
x=self.conv2(x)
# 对输入的x进行卷积
x = self.conv3(x)
# 对卷积后的x进行池化
x = self.maxpool2(x)
# 对输入的x进行Inception结构模块,通常用于增加网络的深度和减少参数
x = self.inception3a(x)
# 对Inception后的x再进行Inception结构模块
x = self.inception3b(x)
# 对Inception后的x进行池化操作
x = self.maxpool3(x)
# 对输入的x进行Inception结构模块
x = self.inception4a(x)
if self.training and self.aux_logits:
# 通过辅助分类器得到辅助分类结果aux1
aux1=self.aux1(x)
# 对输入的x进行Inception结构模块
x = self.inception4b(x)
# 对Inception后的x进行Inception结构模块
x = self.inception4c(x)
# 对Inception后的x进行Inception结构模块
x = self.inception4d(x)
# 如果在训练阶段并且使用辅助分类器,则经过辅助分类器模块后的张量通过辅助损失函数计算损失,并赋值给aux2变量
if self.training and self.aux_logits:
# 通过辅助分类器得到辅助分类结果aux2
aux2 = self.aux2(x)
# 对输入的x进行Inception结构模块
x = self.inception4e(x)
# 对输入的x进行池化操作,降低特征图的尺寸
x = self.maxpool4(x)
# 对输入的x进行Inception结构模块
x = self.inception5a(x)
# 对Inception后的x进行Inception结构模块
x = self.inception5b(x)
# N x 1024 x 7 x 7
# 对特征图进行全局平均池化,将其变为一维向量
x = self.avgpool(x)
# 将二维特征图展平为一维向量
x = torch.flatten(x, 1)
# 在向量的维度上添加dropout操作,随机丢弃部分神经元以防止过拟合
x = self.dropout(x)
# 通过全连接层得到最终的输出结果,通常用于分类任务或者回归任务等
x = self.fc(x)
# 判断是否在训练阶段且使用了辅助分类器 ,如果是,则返回输入张量x,经过辅助分类器2的输出aux2,以及经过辅助分类器1的输出aux1
if self.training and self.aux_logits:
return x, aux2, aux1
# 如果不是在训练阶段或者没有使用辅助分类器,则只返回输入张量x
return x
# 实例化模型
model = GoogleNet()
# 打印模型
input_tensor=torch.rand(5,3,224,224)
# 创建模型实例
model.train() # 设置为训练模式
# 前向传播
output, aux_output2, aux_output1 = model(input_tensor)
print(output,aux_output2,aux_output1)
labels = torch.tensor([1, 0, 2, 0, 1])
# 计算损失
criterion = nn.CrossEntropyLoss()
#优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
loss = criterion(output, labels) + 0.3 * criterion(aux_output1, labels) + 0.3 * criterion(aux_output2, labels)
print(loss)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号