


完整教程:swin-transformer架构解析和源码解析
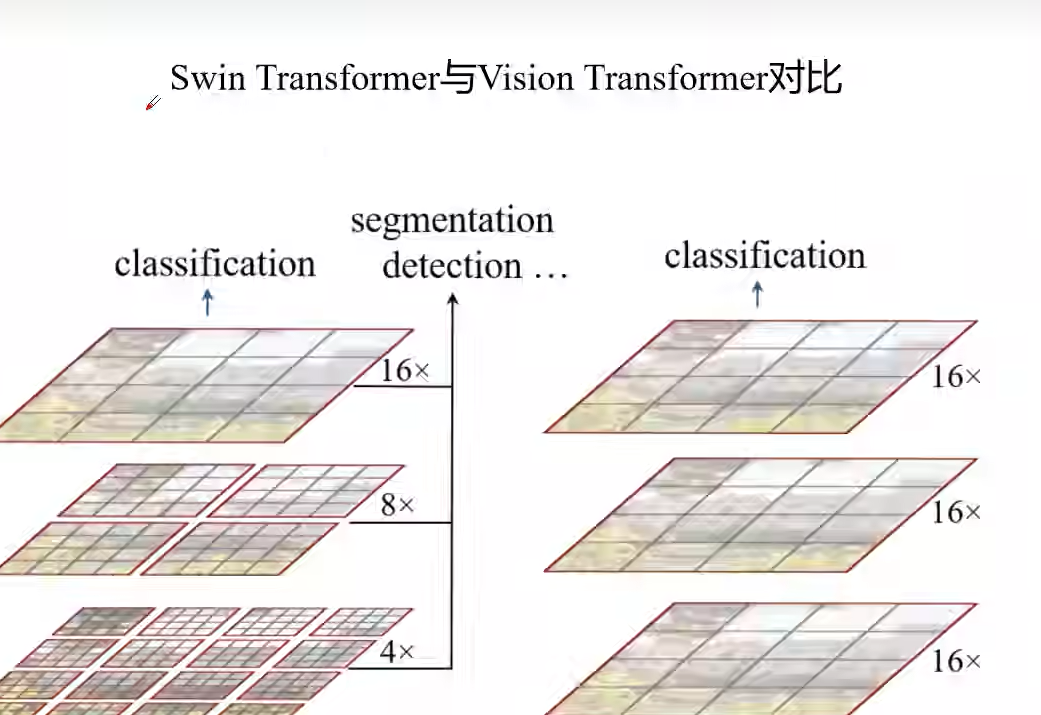
swin-transformer和vit-transformer的区别是它采用了多个窗口收集信息然后进行注意力机制,然后在经过移动窗口结合信息
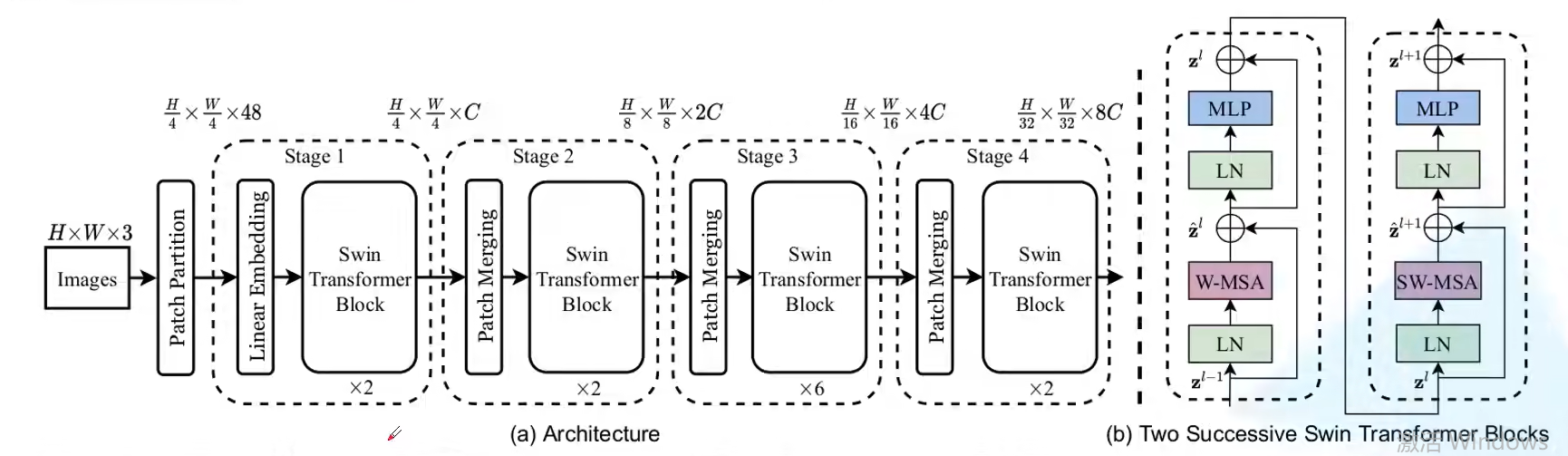
swin-transformer结构
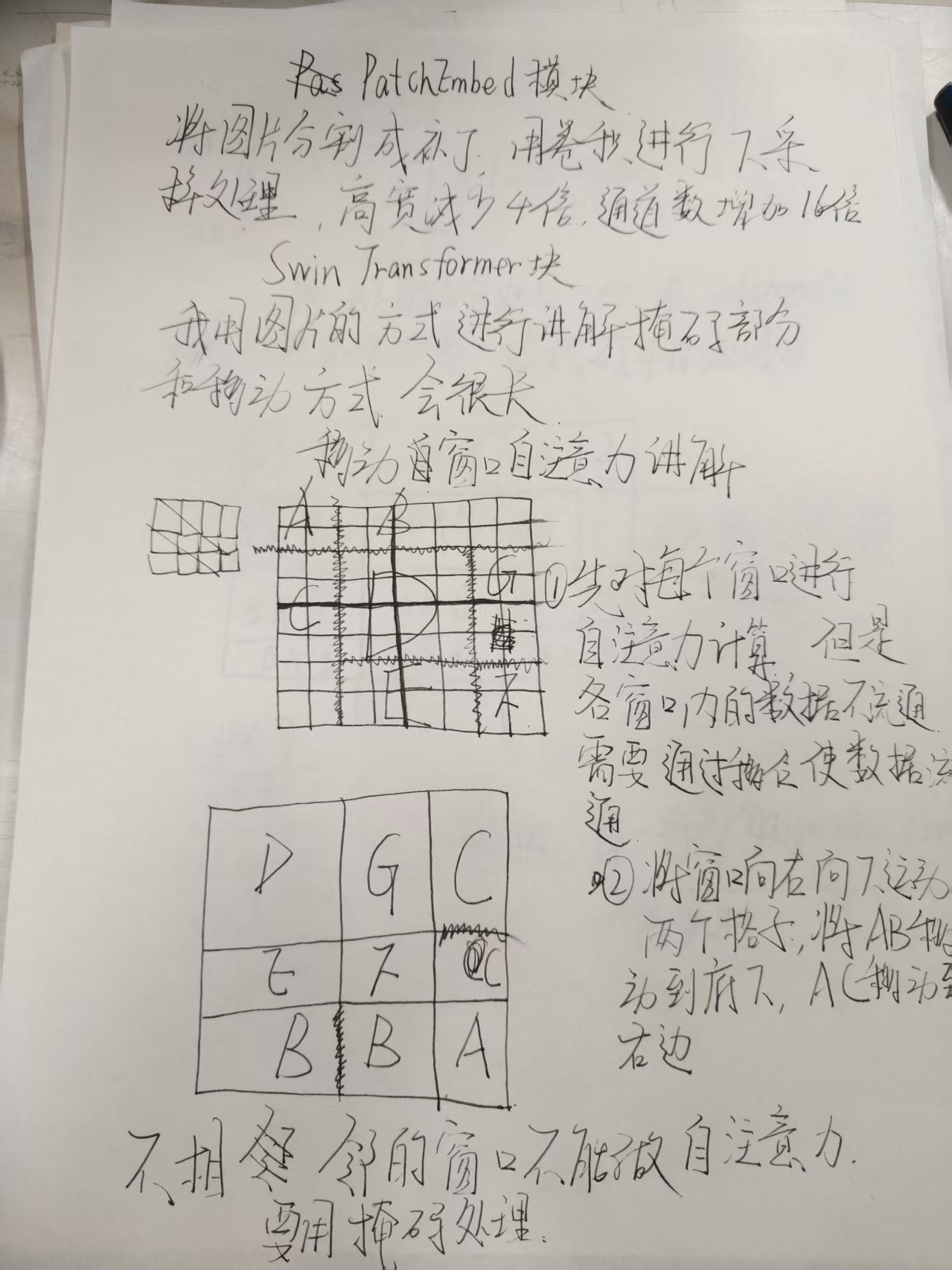
swin模块和其中掩码的讲解就是Patch Partition的主导目的是将原来的大模块分成小补丁,这点和VIT类似,下面
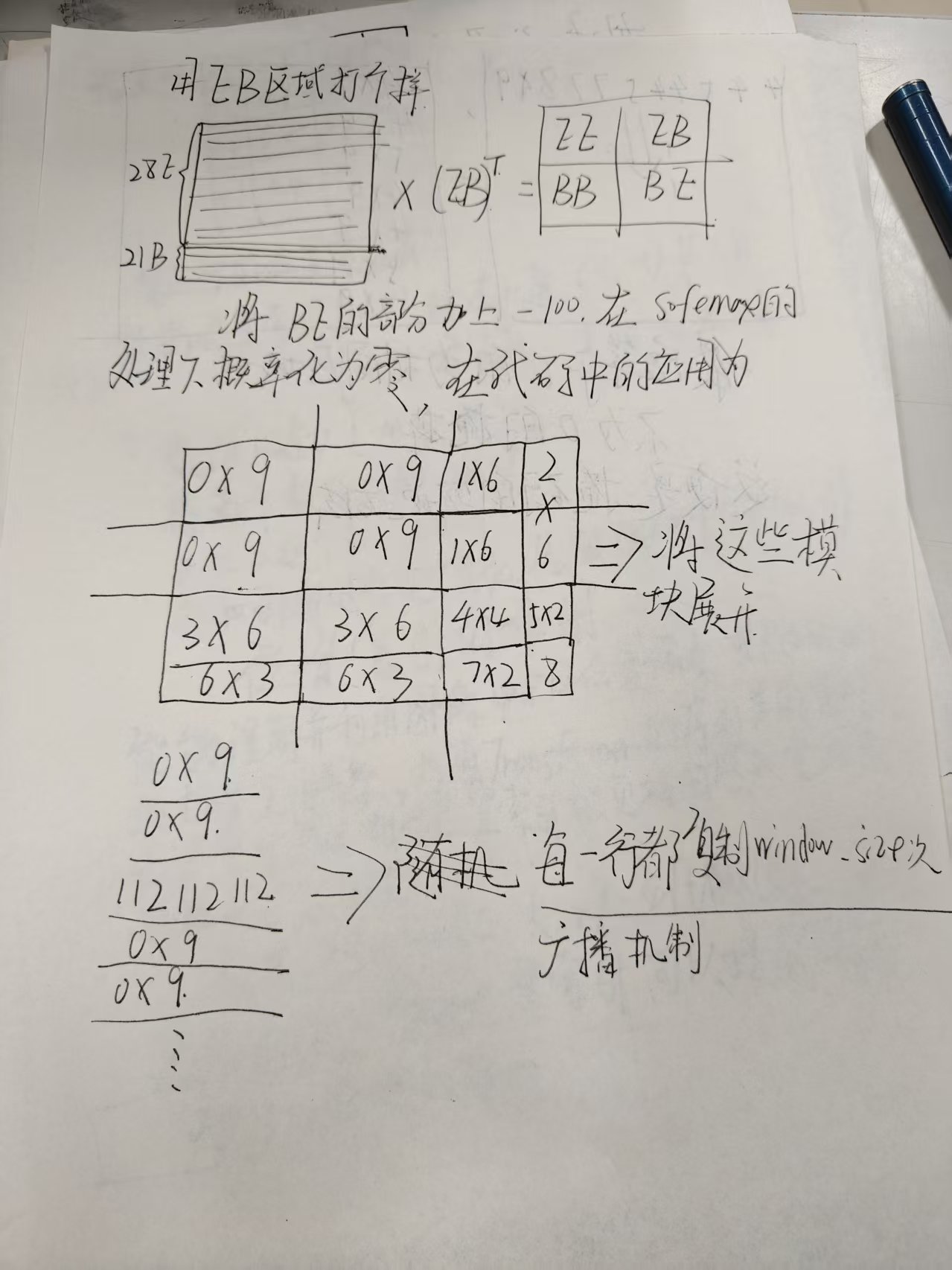

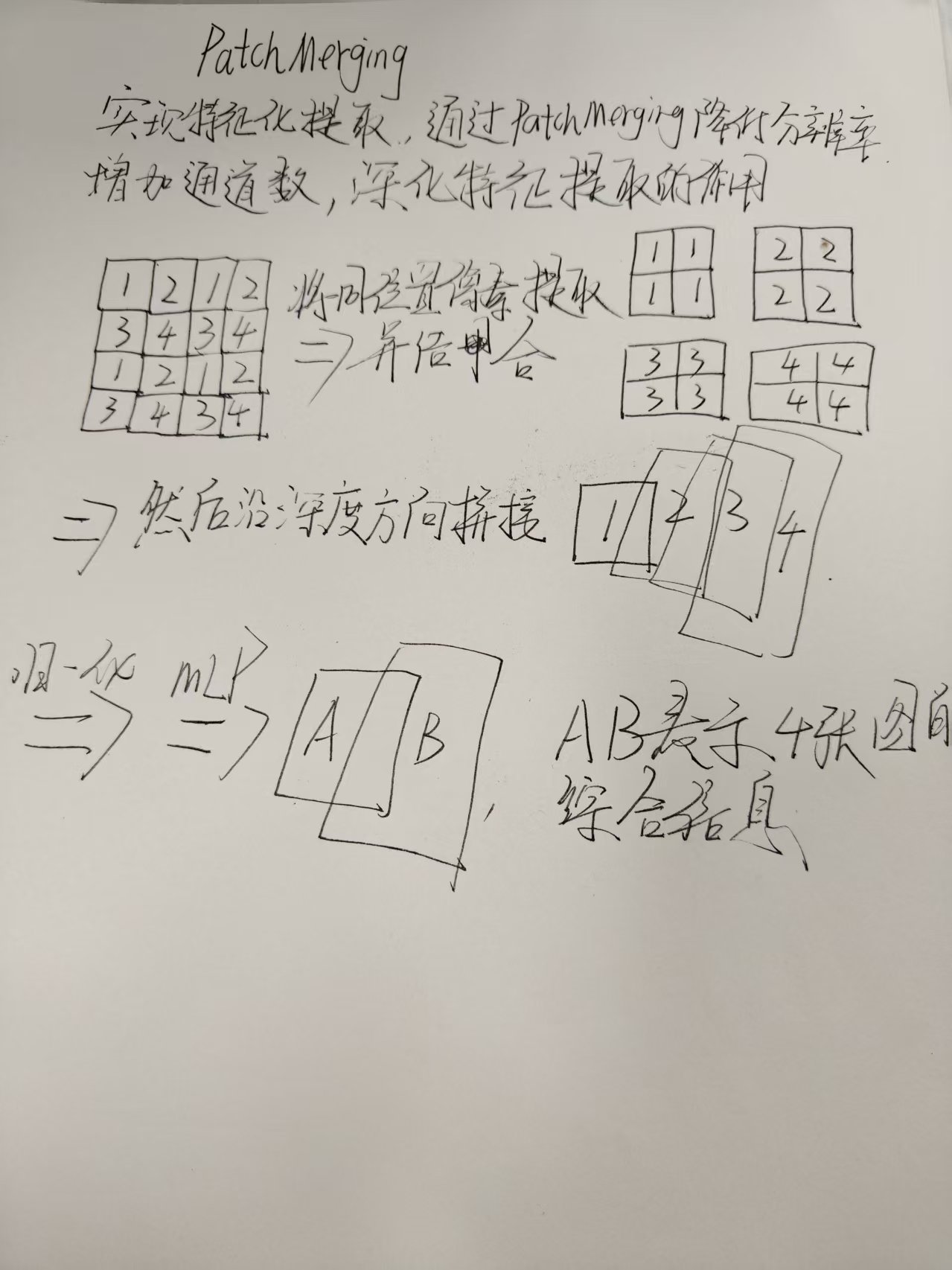
Patch Merging讲解
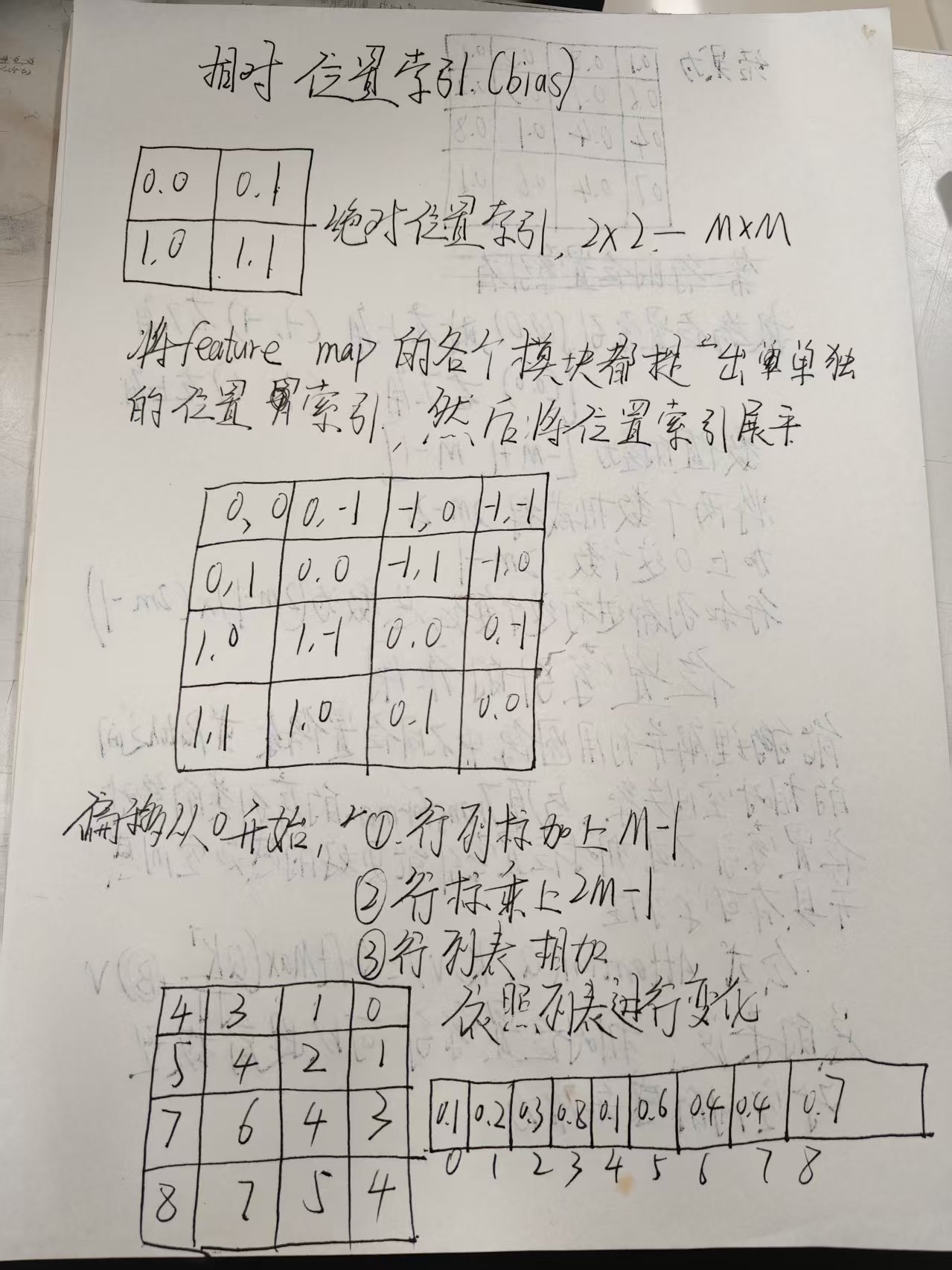
位置索引(bias)讲解

模块讲解完毕,MLP在代码解析中讲解,代码太长了(600多行)我就没有像以前一样逐行讲解
# --------------------------------------------------------
# Swin Transformer
# 版权 (c) 2021 Microsoft
# 根据 MIT 许可证授权 [详见 LICENSE]
# 作者 Ze Liu
# --------------------------------------------------------
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
try:
import os, sys
kernel_path = os.path.abspath(os.path.join('..'))
sys.path.append(kernel_path)
#计算绝对路径防止出错
from kernels.window_process.window_process import WindowProcess, WindowProcessReverse
except:
WindowProcess = None
WindowProcessReverse = None
print("[Warning] Fused window process have not been installed. Please refer to get_started.md for installation.")
#特殊处理,用try-except,如果try部分出错则切换到except部分
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
#真值保持不变,假值则赋予or后面的值
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
#ffn层,进行非线性变化,收集更多信息
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
#数据运行流程
def window_partition(x, window_size):
"""
参数:
x: (B, H, W, C)
window_size (int): 窗口大小
返回:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
#主要目的是将b和window结合,将h/window_size 得到高方面的窗口数,然后用w/window_size得到宽方面的窗口数
#将2,3维度调换,然后用contiguous()保证了数据连续性
#用view方法将前三个维度结合到一起,得到批次数乘以总的窗口数
#将窗口拆开,有利于在窗口内部进行自注意力
#反回总的窗口数
def window_reverse(windows, window_size, H, W):
"""
参数:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): 窗口大小
H (int): 图像高度
W (int): 图像宽度
返回:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
#将拆分的窗口复原,合并信息
#重新回到x;(B,H,W,C)
class WindowAttention(nn.Module):
r""" 基于窗口的多头自注意力 (W-MSA) 模块,带有相对位置偏置。
它支持移位和非移位窗口。
#对单个窗口进行多头注意力,可以看看我的上一期讲解
参数:
dim (int): 输入通道数。
window_size (tuple[int]): 窗口的高度和宽度。
num_heads (int): 注意力头数。
qkv_bias (bool, optional): 如果为 True,为 query、key、value 添加可学习偏置。默认: True
qk_scale (float | None, optional): 如果设置,覆盖默认的 head_dim ** -0.5 的 qk 缩放
attn_drop (float, optional): 注意力权重的 dropout 比率。默认: 0.0
proj_drop (float, optional): 输出的 dropout 比率。默认: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5#定义缩放因子
#简单的实例化
# 定义相对位置偏置的参数表
self.relative_position_bias_table = nn.Parameter(
#nn.Parameter,将位置偏置变成可学习的参数
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)
#设置0起点方便进行学习,总共有(2m-1)*(2m-1)个可能,所以设置这些个0矩阵,创造空间
# 2*Wh-1 * 2*Ww-1, nH
#看我的文章,我会细讲这一部分
# 为窗口内每个标记获取成对相对位置索引
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
#将位置索引的高宽表示出来
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
#生成一个包含所有可能的 (h, w) 组合的网格坐标,
# 将 h 和 w 这两个 (Wh, Ww) 形状的张量堆叠在一起,沿着一个新的维度。
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
#将 coords 张量的第1个维度开始的部分展平
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
#None,在所在维度上多加一个维度
#将 Δh 和 Δw 放在一个张量的不同切片
#广播机制,所有行减所有列
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
#调换维度并进行连续化处理
relative_coords[:, :, 0] += self.window_size[0] - 1 # 移位以从 0 开始
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
#我在文章写的一系列变化
self.register_buffer("relative_position_index", relative_position_index)
#把编号作为模型参数的一部分
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
#通过线性变化得到Q,K,V
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
#融合信息
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
#用截断正态分布生成随机数来填充你的参数
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
参数:
x: 输入特征,形状为 (num_windows*B, N, C)
mask: (0/-inf) 掩码,形状为 (num_windows, Wh*Ww, Wh*Ww) 或 None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
#拆分获取Q,K,V
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
#Q*K的装置,计算注意力分数
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
#将index用table表示,然后回复原来的的状态
# Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
#对应公式中的+b
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
#进行转换,使两者处于相同维度
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
#softmax处理
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
#对应公式中的*v
x = self.proj(x)
x = self.proj_drop(x)
return x
#拼接并进性线性变化
def extra_repr(self) -> str:
return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
def flops(self, N):
# 计算 1 个窗口中标记长度为 N 的 flops
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
return flops
#计算浮点数的,不重要
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer 块。
参数:
dim (int): 输入通道数。
input_resolution (tuple[int]): 输入分辨率。
num_heads (int): 注意力头数。
window_size (int): 窗口大小。
shift_size (int): SW-MSA 的移位大小。
mlp_ratio (float): mlp 隐藏维度与嵌入维度的比率。
qkv_bias (bool, optional): 如果为 True,为 query、key、value 添加可学习偏置。默认: True
qk_scale (float | None, optional): 如果设置,覆盖默认的 head_dim ** -0.5 的 qk 缩放。
drop (float, optional): Dropout 率。默认: 0.0
attn_drop (float, optional): 注意力 dropout 率。默认: 0.0
drop_path (float, optional): 随机深度率。默认: 0.0
act_layer (nn.Module, optional): 激活层。默认: nn.GELU
norm_layer (nn.Module, optional): 归一化层。默认: nn.LayerNorm
fused_window_process (bool, optional): 如果为 True,使用一个内核融合窗口移位和窗口分区以加速,逆过程类似。默认: False
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
fused_window_process=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
#实例化
if min(self.input_resolution) <= self.window_size:
# 如果窗口大小大于输入分辨率,则不分区窗口
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size 必须在 0-window_size 之间"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
#ffn同理
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
if self.shift_size > 0:
# 计算 SW-MSA 的注意力掩码
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
#切割图片
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
#给切割后的图片标号,相同的数字是相邻模块
mask_windows = window_partition(img_mask, self.window_size)
#上文的window_partition切割图片
# nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
#nw,window_size*window_size
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
#掩码处理
self.register_buffer("attn_mask", attn_mask)
self.fused_window_process = fused_window_process
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "输入特征大小错误"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# 循环移位
if self.shift_size > 0:
if not self.fused_window_process:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
# 分区窗口
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
else:
x_windows = WindowProcess.apply(x, B, H, W, C, -self.shift_size, self.window_size)
else:
shifted_x = x
# 分区窗口
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# 合并窗口
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
# 逆循环移位
if self.shift_size > 0:
if not self.fused_window_process:
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = WindowProcessReverse.apply(attn_windows, B, H, W, C, self.shift_size, self.window_size)
else:
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = shifted_x
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
# FFN
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# W-MSA/SW-MSA
nW = H * W / self.window_size / self.window_size
flops += nW * self.attn.flops(self.window_size * self.window_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops
class PatchMerging(nn.Module):
r""" 补丁合并层。
参数:
input_resolution (tuple[int]): 输入特征的分辨率。
dim (int): 输入通道数。
norm_layer (nn.Module, optional): 归一化层。默认: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "输入特征大小错误"
assert H % 2 == 0 and W % 2 == 0, f"x 大小 ({H}*{W}) 不是偶数。"
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
#在我的文章里面讲了
x = self.norm(x)
x = self.reduction(x)
return x
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
return flops
class BasicLayer(nn.Module):
""" Swin Transformer 的一个基本层,用于一个阶段。
参数:
dim (int): 输入通道数。
input_resolution (tuple[int]): 输入分辨率。
depth (int): 块的数量。
num_heads (int): 注意力头数。
window_size (int): 局部窗口大小。
mlp_ratio (float): mlp 隐藏维度与嵌入维度的比率。
qkv_bias (bool, optional): 如果为 True,为 query、key、value 添加可学习偏置。默认: True
qk_scale (float | None, optional): 如果设置,覆盖默认的 head_dim ** -0.5 的 qk 缩放。
drop (float, optional): Dropout 率。默认: 0.0
attn_drop (float, optional): 注意力 dropout 率。默认: 0.0
drop_path (float | tuple[float], optional): 随机深度率。默认: 0.0
norm_layer (nn.Module, optional): 归一化层。默认: nn.LayerNorm
downsample (nn.Module | None, optional): 层末端的下采样层。默认: None
use_checkpoint (bool): 是否使用检查点以节省内存。默认: False
fused_window_process (bool, optional): 如果为 True,使用一个内核融合窗口移位和窗口分区以加速,逆过程类似。默认: False
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,
fused_window_process=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# 构建块
self.blocks = nn.ModuleList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer,
fused_window_process=fused_window_process)
for i in range(depth)])
# 补丁合并层
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
def flops(self):
flops = 0
for blk in self.blocks:
flops += blk.flops()
if self.downsample is not None:
flops += self.downsample.flops()
return flops
class PatchEmbed(nn.Module):
r""" 图像到补丁嵌入
参数:
img_size (int): 图像大小。默认: 224。
patch_size (int): 补丁标记大小。默认: 4。
in_chans (int): 输入图像通道数。默认: 3。
embed_dim (int): 线性投影输出通道数。默认: 96。
norm_layer (nn.Module, optional): 归一化层。默认: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
#输入转换为一个包含两个元素的元组
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
#长宽方向的补丁数目
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
#patches_resolution 用于跟踪特征图的分辨率
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
#进行下采样
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME 考虑放宽大小约束
assert H == self.img_size[0] and W == self.img_size[1], \
f"输入图像大小 ({H}*{W}) 与模型不匹配 ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
#若想进行多尺度训练,则用pading处理
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
class SwinTransformer(nn.Module):
r""" Swin Transformer
PyTorch 实现:`Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
参数:
img_size (int | tuple(int)): 输入图像大小。默认 224
patch_size (int | tuple(int)): 补丁大小。默认: 4
in_chans (int): 输入图像通道数。默认: 3
num_classes (int): 分类头的类别数。默认: 1000
embed_dim (int): 补丁嵌入维度。默认: 96
depths (tuple(int)): 每个 Swin Transformer 层的深度。
num_heads (tuple(int)): 不同层中的注意力头数。
window_size (int): 窗口大小。默认: 7
mlp_ratio (float): mlp 隐藏维度与嵌入维度的比率。默认: 4
qkv_bias (bool): 如果为 True,为 query、key、value 添加可学习偏置。默认: True
qk_scale (float): 如果设置,覆盖默认的 head_dim ** -0.5 的 qk 缩放。默认: None
drop_rate (float): Dropout 率。默认: 0
attn_drop_rate (float): 注意力 dropout 率。默认: 0
drop_path_rate (float): 随机深度率。默认: 0.1
norm_layer (nn.Module): 归一化层。默认: nn.LayerNorm。
ape (bool): 如果为 True,向补丁嵌入添加绝对位置嵌入。默认: False
patch_norm (bool): 如果为 True,在补丁嵌入后添加归一化。默认: True
use_checkpoint (bool): 是否使用检查点以节省内存。默认: False
fused_window_process (bool, optional): 如果为 True,使用一个内核融合窗口移位和窗口分区以加速,逆过程类似。默认: False
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, fused_window_process=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# 将图像分割成非重叠补丁
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# 绝对位置嵌入
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# 随机深度
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # 随机深度衰减规则
# 构建层
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint,
fused_window_process=fused_window_process)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def flops(self):
flops = 0
flops += self.patch_embed.flops()
for i, layer in enumerate(self.layers):
flops += layer.flops()
flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
return flops希望大家喜欢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号