

Python数据分析之pandas统计分析基础1
**pandas** (Python Data Analysis Library )是基于numpy
的一种工具,该工具是为了解决数据分析任务而创建的。pandas
纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
* * *
### 1. 数据库数据的读写
#### 1.1 数据库数据读取
pandas提供了读取与存储关系型数据库数据的函数与方法。除了pandas库外,还需要使用SQLAlchemy库建立对应的数据库连接。SQLAlchemy配合相应数据库的Python连接工具(例如MySQL数据库需要安装mysqlclient或者pymysql库),
使用create_engine函数 ,建立一个数据库连接。
creat_engine中填入的是一个连接字符串。在使用Python的SQLAlchemy时,MySQL和Oracle数据库连接字符串的格式如下:
数据库产品名+连接工具名://用户名:密码@数据库IP地址:数据库端口号/数据库名称?charset = 数据库数据编码
```code
import pandas as pd
from sqlalchemy import create_engine
engin = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data = pd.read_sql_table('meal_order_detail1', con=engin)
```
read_sql_table只能够读取数据库的某一个表格,不能实现查询的操作。
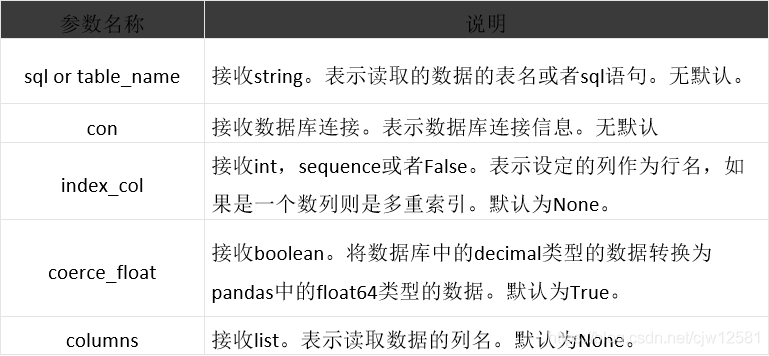
pandas.read_sql_table(table_name, con, schema=None, index_col=None,
coerce_float=True, columns=None)
read_sql_query则只能实现查询操作,不能直接读取数据库中的某个表。
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True)
read_sql 是两者的综合,既能够读取数据库中的某一个表,也能够实现查询操作。
pandas.read_sql(sql, con, index_col=None, coerce_float=True, columns=None)
pandas三个数据库数据读取函数的参数几乎完全一致,唯一的区别在于传入的是语句还是表名。
#### 1.2 数据库数据存储
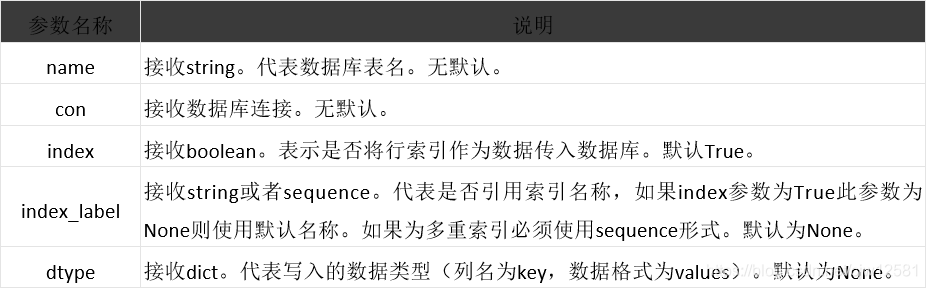
数据库数据读取有三个函数,但数据存储则 只有一个to_sql方法 。
DataFrame.to_sql(name, con, schema=None, if_exists=’fail’, index=True,
index_label=None, dtype=None)
### 2. 读写文本文件
#### 2.1 文本文件读取
文本文件是一种由若干行字符构成的计算机文件,它是一种典型的顺序文件。
csv是一种逗号分隔的文件格式,因为其分隔符不一定是逗号,又被称为字符分隔文件,文件以纯文本形式存储表格数据(数字和文本)。
使用read_table来读取文本文件。
pandas.read_table(filepath_or_buffer, sep=’\t’, header=’infer’, names=None,
index_col=None, dtype=None, engine=None, nrows=None)
使用read_csv函数来读取csv文件。
pandas.read_csv(filepath_or_buffer, sep=’,’, header=’infer’, names=None,
index_col=None, dtype=None, engine=None, nrows=None)
read_table和read_csv常用参数及其说明:
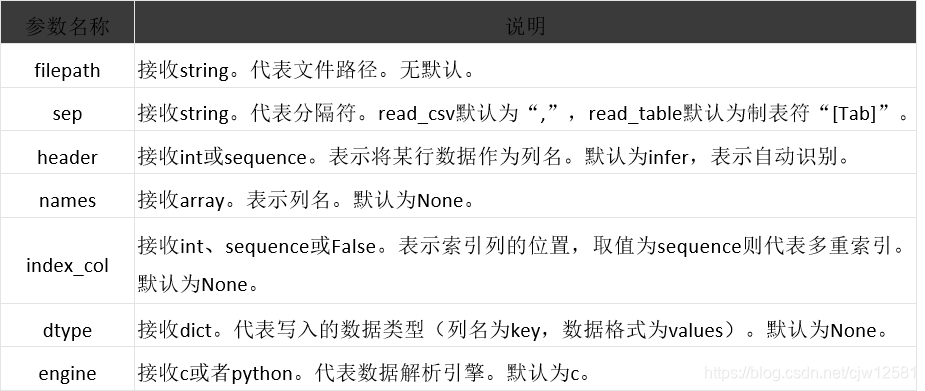
read_table和read_csv函数中的sep参数是指定文本的分隔符的,如果分隔符指定错误,在读取数据的时候,每一行数据将连成一片。
header参数是用来指定列名的,如果是None则会添加一个默认的列名。
encoding代表文件的编码格式,常用的编码有 utf-8 、utf-16、 gbk
、gb2312、gb18030等。如果编码指定错误数据将无法读取,IPython解释器会报解析错误。
#### 2.2 文本文件储存
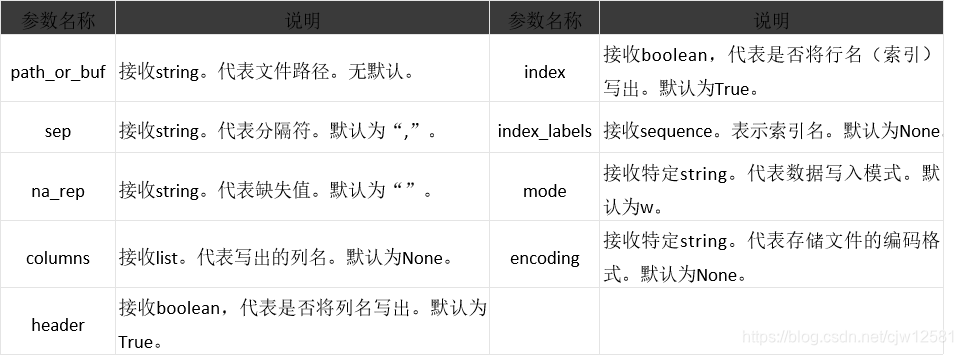
文本文件的存储和读取类似,结构化数据可以通过pandas中的to_csv函数实现以csv文件格式存储文件。
DataFrame.to_csv(path_or_buf=None, sep=’,’, na_rep=”, columns=None,
header=True, index=True,index_label=None,mode=’w’,encoding=None)
### 3. 读写Excel文件
#### 3.1 Excel文件读取
pandas提供了read_excel函数来读取“xls”“xlsx”两种Excel文件。
pandas.read_excel(io, sheetname=0, header=0, index_col=None,
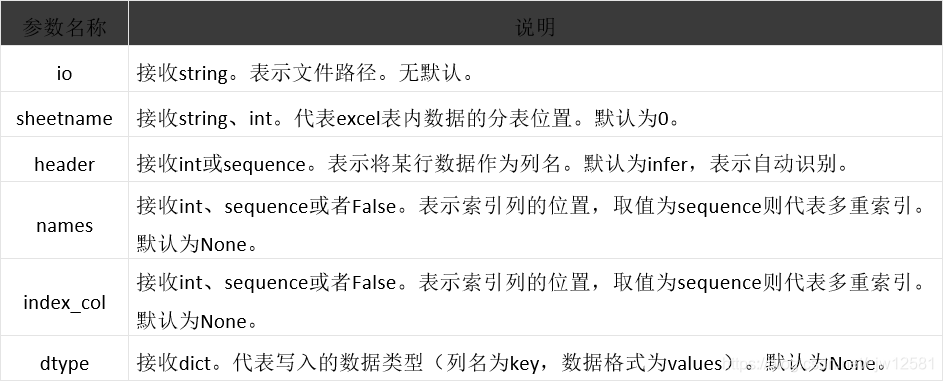
#### 3.2 Excel文件储存
将文件存储为Excel文件,可以使用to_excel方法。其语法格式如下:
DataFrame.to_excel(excel_writer=None, sheetname=None’, na_rep=”, header=True,
index=True, index_label=None, mode=’w’, encoding=None)
to_csv方法的常用参数基本一致,区别之处在于:指定存储文件的文件路径参数名称为excel_writer,并且没有sep参数,增加了一个sheetnames参数用来指定存储的Excel
sheet的名称,默认为sheet1。
```code
with pd.ExcelWriter('./tmp/temp.xlsx') as w:
data.to_excel(w, sheet_name='a')
data.to_excel(w, sheet_name='b')
```
* * *


 浙公网安备 33010602011771号
浙公网安备 33010602011771号