利用pytorch进行深度学习(6)—— 逻辑斯蒂回归
(一)分类问题
在前述的案例中,我们要进行的计算都是在一个连续空间里面,但是在很多任务中我们要进行的是分类,在分类任务中会出现输入特征比较相似但是输出值比较远的情况,这个时候我们利用连续空间的函数模型就不太适合了,因为我们模型输出的数值并不是要表示大小的含义,我们是要做类别的比较,所以在分类问题中我们核心的问题是根据输入的x,它输出为各个分类的概率是多少,根据概率值大小找出他应该是在哪个类别,在pytorch中,我们可以利用torchvision的MINIST包来下载相应的分类数据集,还提供CIFAR的数据集,里面是一堆彩色的图像,每个数据集大概有50000个样本,对应的测试集有10000个样本。


如果我们的分类只有两个,例如true或者是false,那么我们就成这样的分类任务为二分类问题,在二分类中,我们知道了一种分类的概率就可以得知另一种分类的概率,如果在分类中没有十足的把握,即两种情况都是近似的,比如在0.4-0.6之间,那么我们就可能会输出无法分类,也可能直接把分类的概率输出。
(二)logistic函数
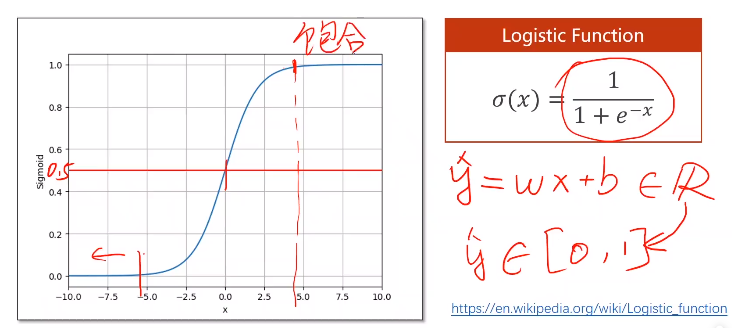
对于分类任务,我们有一些函数可以把实数集合映射成为[0,1]之间的概率分布,这样的函数被称为激活函数(Sigmoid function),其中比较经典的就是logistic函数,在该函数的两端导数值趋近于0,含有这样区间的函数成为饱和函数,事实上,logistic函数是由于自然界正态分布的存在而产生的一种函数。但记住不是logistic函数可以计算概率,而是我们要计算概率,就要保证输出值在[0,1]之间。由于logistic函数太过于出名,所以我们在pytorch中指sigmoid函数就是指logistic函数,logistic函数一般写作 σ(x)
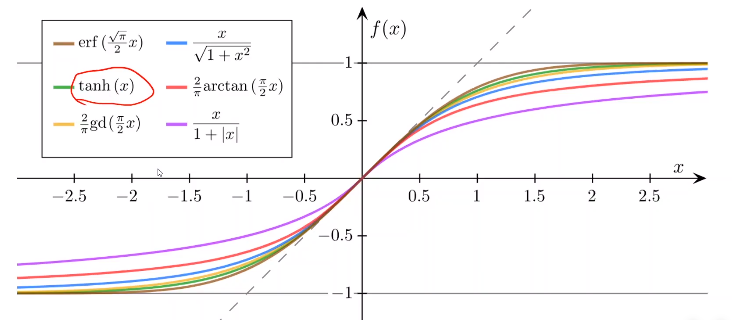
还有很多其他的激活函数如下图,作为激活函数需要满足一下几个条件:
(1)都是单调增函数
(2)他们的值都有极限
(3)都是饱和函数
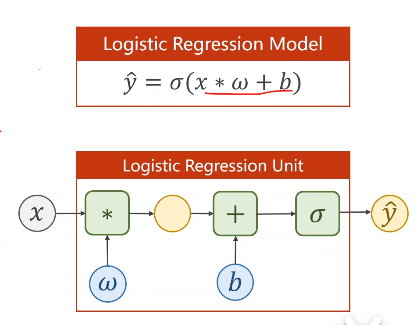
(三)logistic回归模型
对于logistic回归模型,我们只需对前面的线性模型进行调用一个σ(x)函数即可,当然我们需要注意,我们在求导的时候还要对σ(x)函数求导。虽然σ(x)函数要求的是输入为[0, +∞],但我们大部分时候的输入都是符合这个值的,即使不行,那我们也可以换成反正切函数等等也可以。
模型变了,损失函数也要进行改变,原来的损失函数求得是每个数之间的距离,但现在输出的不再是个数值而是个分布,所以现在想求的是两个分布之间的差异,求分布差异的方法可以有:KL散度,我们这里用的是交叉熵(Cross Entropy),我们希望所得 交叉熵越小越好,所以在公式中加了个负号,我们将这种二分类的损失函数称为BCE

对于BCE,我们希望y越接近1,y_hat就越接近1,y越接近0,y_hat也越接近0,越接近BCE就会越小,对于Mini-Batch,我们就直接加和求均值。

(四)代码解析
整个代码可以分为四个模块:数据集准备,设计模型类,构造损失函数和优化器,迭代训练。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号