

利用pytorch进行深度学习(2)
搭建线性模型,参考视频https://www.bilibili.com/video/BV1Y7411d7Ys?p=2
由于刚开始看书《deep learning with pytorch》只了解了代码部分的一些知识,对于机器学习方面的一些知识还比较陌生,因此专门去B站搜索了这部分的视频来补充知识,现写下博客来帮助日后复习。
(一)数据集
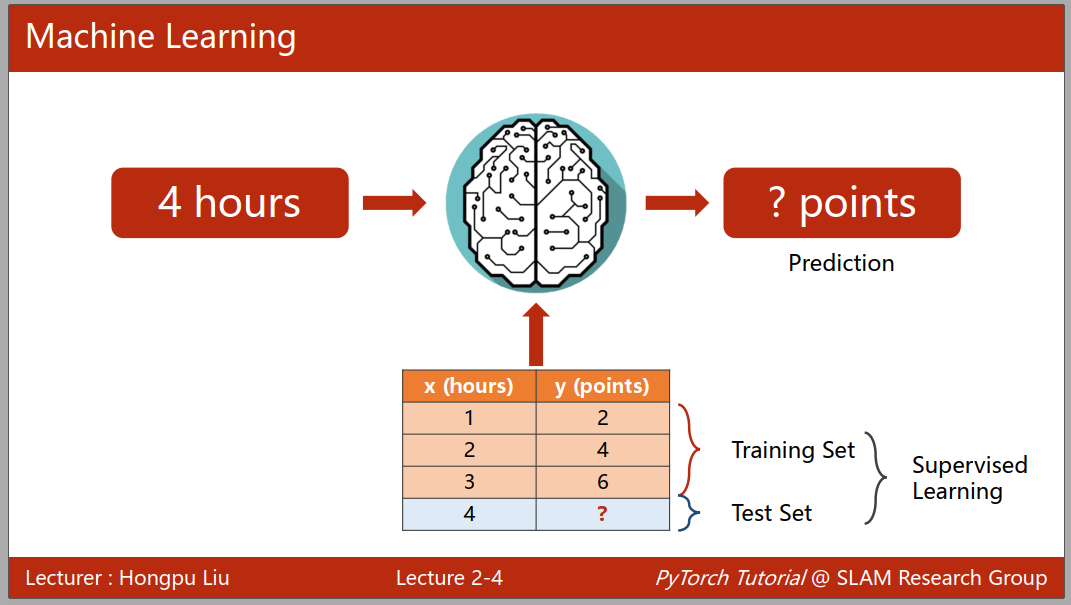
面对问题的时候,我们已知的数据集可以被用来测试,训练模型,然后再利用模型对未知的数据集来进行推理预测,其中在学习的时候我们知道输出的结果,可以通过结果来对模型进行纠正,这种学习过程叫做监督学习。在监督学习的过程中我们可获得的已知的数据集被分为测试集和训练集,其中测试集的数据在训练过程中不能使用,来计算模型的相关指标,并对模型进行纠正。
注意:我们得到的数据集不一定是符合联合分布的,概率论中告诉我们要让模型具有普遍性应该要有足够多的样本才可以实现,所以如果我们的模型在数据集拟合的非常好,可能会导致过拟合的现象,而我们希望我们的模型有比较好的泛化能力,所以我们通常会把我们的训练集分成两部分,一部分叫做训练集,另一部分叫做开发集(Dev)
(二)模型的选择

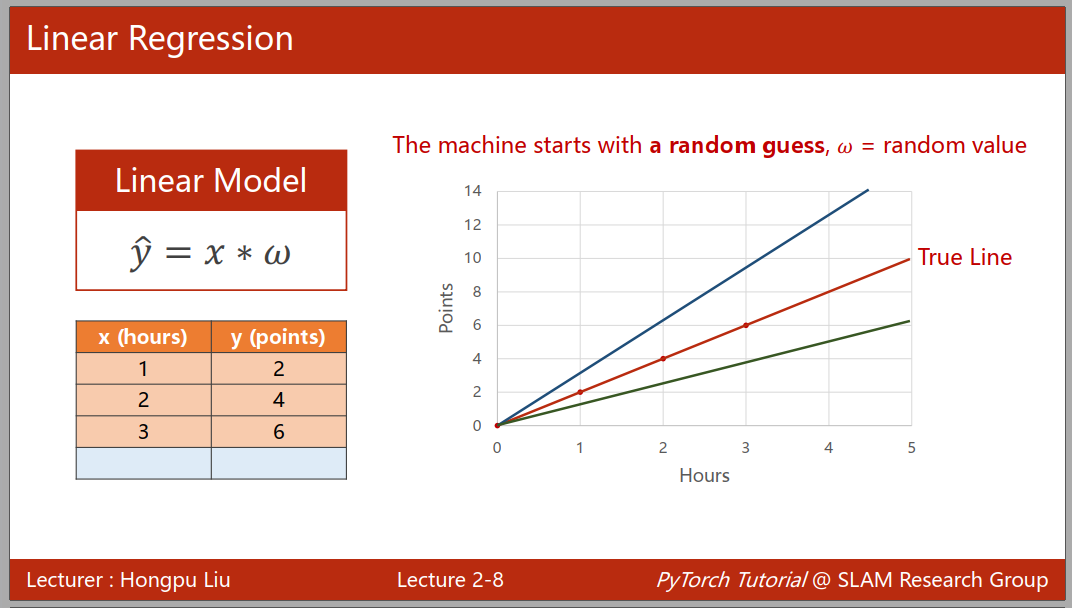
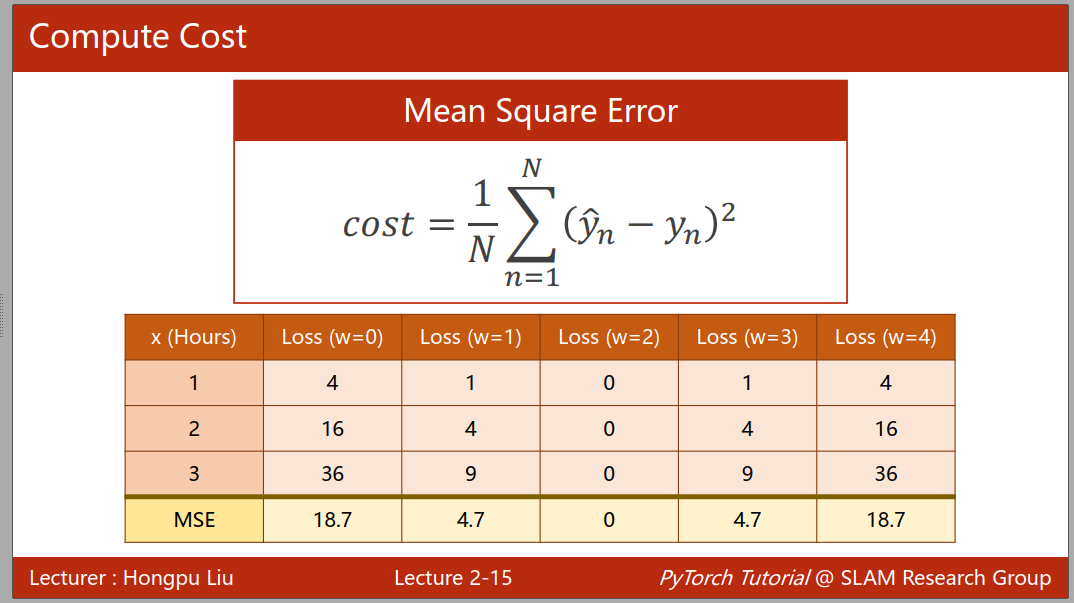
在遇到一个模型时候,我们一般会使用线性模型来测试下,训练的时候我们则考虑 w 和 b 的值来,在机器学习中我们一般使用随机猜测来确定这两个未知量的值,然后通过穷举法来找到最优值,使用损失函数来评估模型的性能,当我们的误差函数值最小的时候,即可以代表最优的性能,通过每个样本的损失函数值,我们可以求得平均平方误差(MSE),来得到样本的综合性能。
(三)代码实例
接下来用代码来表示这个线性拟合的过程:
import numpy as np import matplotlib.pyplot as plt x_data = [1.0,2.0,3.0] y_data = [2.0,4.0,6.0] def forward(x): //定义线性模型y = x*w return x*w def loss(x,y): //定义损失函数 loss=(x*w-y)2 y_pred = forward(x) return (y_pred - y)*(y_pred - y) w_list = [] //用空列表保存权重以及相应权重的损失值 mse_list = [] for w in np.arange(0.0,4.1,0.1): print('w=',w) l_sum = 0 for x_val,y_val in zip(x_data,y_data): //zip函数可用于将可迭代变量中的每个元素转换为对应的元组 y_pred_val = forward(x_val) loss_val = loss(x_val,y_val) l_sum += loss_val print('\t',x_val,y_val,y_pred_val,loss_val) print('MSE=',l_sum/3) w_list.append(w) mse_list.append(l_sum/3)
所得到的图:
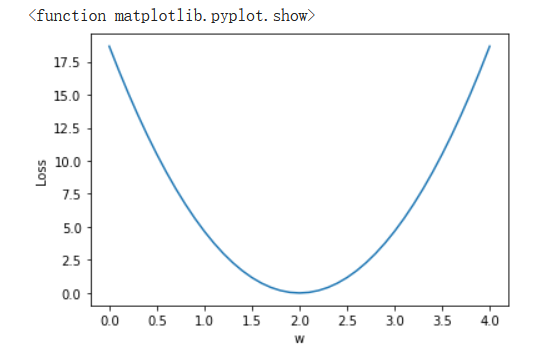
在深度学习中,我们也经常会要绘制这样的图,但是我们一般是拿训练的轮数作为横坐标而不是权重,因为我们在深度学习中我们很难判断什么时候结果会收敛,通常训练数据随着训练轮数增加其损失函数会不断减小最后趋于平缓,而如果此时拿开发集的数据去跑就会发现,开发集的损失函数会先伴随着训练集的减小而减小,而后开始上升,因此我们要找到那个开发集上升前的临界点,这时候我们可以用这个图,即可视化来帮助我们判断。一般我们可以利用visdom来实时依据输出数据来画图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号