kube-proxy三种模式
kubernetes里kube-proxy支持三种模式,在v1.8之前我们使用的是iptables 以及 userspace两种模式,在kubernetes 1.8之后引入了ipvs模式,并且在v1.11中正式使用,其中iptables和ipvs都是内核态也就是基于netfilter,只有userspace模式是用户态。
参考:https://www.cnblogs.com/yrxing/p/15920398.html
一.userspace
起初,kube-proxy进程是一个真实的TCP/UDP代理,当某个pod以clusterIP方式访问某个service的时候,这个流量会被pod所在的本机的iptables转发到本季的kube-proxy进程,然后将请求转发到后端某个pod上。具体过程为:
- kube-proxy为每个service在node上打开一个随机端口作为代理端口
- 建立iptables规则,将clusterip的请求重定向到代理端口(用户空间)
- 到达代理端口的请求再由kubeproxy转发到后端
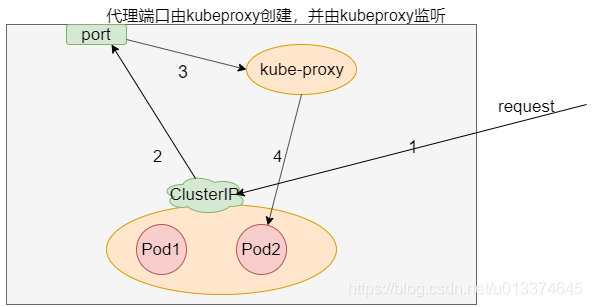
clusterip重定向到kube-proxy服务的过程存在内核态到用户态的切换,开销很大,因此有了iptables模式,而userspace模式也被废弃了。
二.iptables
kubernets从1.2版本开始将iptabels模式作为默认模式,这种模式下kube-proxy不再起到proxy的作用。其核心功能:通过API Server的Watch接口实时跟踪Service和Endpoint的变更信息,并更新对应的iptables规则,Client的请求流量通过iptables的NAT机制“直接路由”到目标Pod。
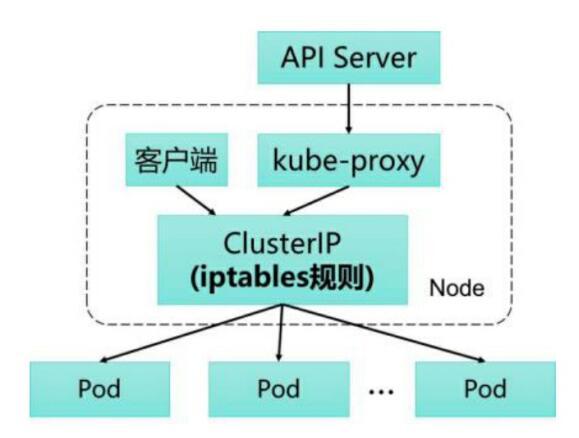
不同于userspace,iptables由kube-proxy动态的管理,kube-proxy不再负责转发,数据包的走向完全由iptables规则决定,这样的过程不存在内核态到用户态的切换,效率明显会高很多。但是随着service的增加,iptables规则会不断增加,导致内核十分繁忙(等于在读一张很大的没建索引的表)。
三.ipvs
从kubernetes 1.8版本开始引入第三代的IPVS模式,它也是基于netfilter实现的,但定位不同:iptables是为防火墙设计的,IPVS则专门用于高性能
负载均衡,并使用高效的数据结构Hash表,允许几乎无限的规模扩张。
一句话说明:ipvs使用ipset存储iptables规则,在查找时类似hash表查找,时间复杂度为O(1),而iptables时间复杂度则为O(n)。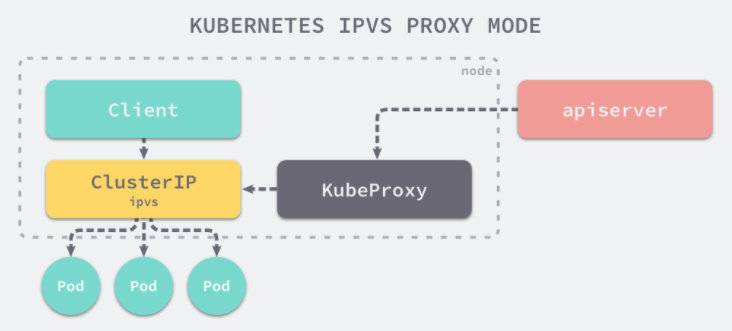
可以将ipset简单理解为ip集合,这个集合的内容可以是IP地址、IP网段、端口等,iptabels可以直接添加规则对这个可变集合进行操作,这样做的好处可以大大减少iptables规则的数量,从而减少性能损耗。
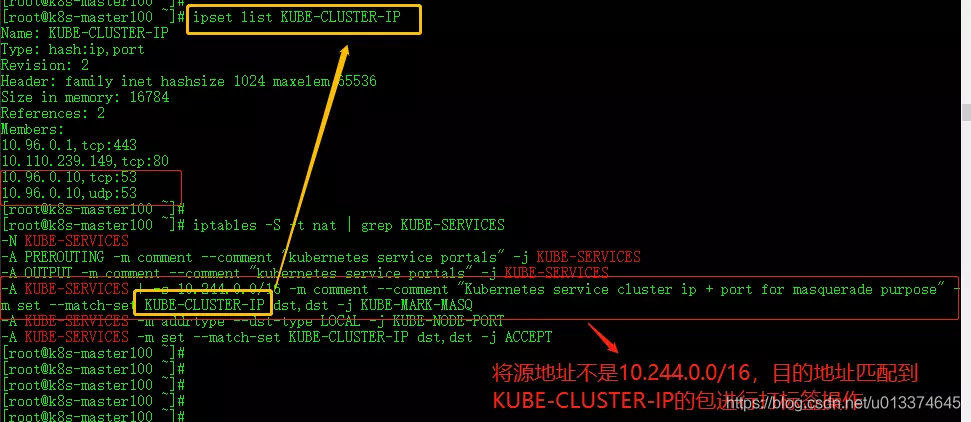
假设要禁止上万个IP访问我们的服务器,如果用iptables的话,就需要一条一条的添加规则,会生成大量的iptabels规则;但是用ipset的话,只需要将相关IP地址加入ipset集合中即可,这样只需要设置少量的iptables规则即可实现目标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号