

使用kube-prometheus快速部署监控系统
使用kube-prometheus快速部署监控系统
简介
根据官方的描述kube-prometheus集kubernetes资源清单、Grafana仪表盘、Prometheus规则文件以及文档和脚本于一身,通过使用prometheus operator提供易于操作的端到端Kubernetes集群监控。 包含以下组件:
- Prometheus Operator
- 高可用Prometheus
- 高可用AlertManager
- Prometheus node-exporter
- Prometheus Adapter for Kubernetes Metrics APIS
- kube-state-metrics
- Grafana 更多信息可以前往github进行查看:
前提
- 需要有Kubernetes集群环境
kubectl get nodes
NAME STATUS ROLES AGE VERSION
test-node0 Ready <none> 15d v1.18.2
test-node1 Ready <none> 15d v1.18.2
- 兼容性
| kube-prometheus stack | Kubernetes 1.16 | Kubernetes 1.17 | Kubernetes 1.18 | Kubernetes 1.19 | Kubernetes 1.20 |
|---|---|---|---|---|---|
| release-0.4 | ✔ (v1.16.5+) | ✔ | ✗ | ✗ | ✗ |
| release-0.5 | ✗ | ✗ | ✔ | ✗ | ✗ |
| release-0.6 | ✗ | ✗ | ✔ | ✔ | ✗ |
| release-0.7 | ✗ | ✗ | ✗ | ✔ | ✔ |
| HEAD | ✗ | ✗ | ✗ | ✔ | ✔ |
当前版本1.18.2可以使用release-0.6版本进行部署。
安装
下载代码
wget https://github.com/prometheus-operator/kube-prometheus/archive/v0.6.0.tar.gz
tar xf v0.6.0.tar.gz
cd kube-prometheus-0.6.0
ls
DCO README.md examples jsonnet scripts
LICENSE build.sh experimental jsonnetfile.json sync-to-internal-registry.jsonnet
Makefile code-of-conduct.md go.mod jsonnetfile.lock.json test.sh
NOTICE docs go.sum kustomization.yaml tests
OWNERS example.jsonnet hack manifests
快速安装
默认情况下所有资源创建在monitoring名称空间下
kubectl create -f manifests/setup
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl create -f manifests/
国内由于某些原因部分源下载比较慢,可能导致镜像拉取失败。检查pod运行状态
kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 103m
alertmanager-main-1 2/2 Running 0 103m
alertmanager-main-2 2/2 Running 0 103m
grafana-67dfc5f687-w27mv 1/1 Running 0 118m
kube-state-metrics-69d4c7c69d-q5j8p 3/3 Running 0 118m
node-exporter-mbt65 2/2 Running 0 118m
node-exporter-stjfh 2/2 Running 0 118m
prometheus-adapter-66b855f564-xf98f 1/1 Running 0 118m
prometheus-k8s-0 3/3 Running 1 103m
prometheus-k8s-1 3/3 Running 0 103m
prometheus-operator-57859b8b59-xc6z7 2/2 Running 0 118m
检查服务
kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.96.200.17 <none> 9093/TCP 120m
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 105m
grafana ClusterIP 10.96.185.117 <none> 3000/TCP 120m
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 120m
node-exporter ClusterIP None <none> 9100/TCP 120m
prometheus-adapter ClusterIP 10.96.154.67 <none> 443/TCP 120m
prometheus-k8s ClusterIP 10.96.211.235 <none> 9090/TCP 120m
prometheus-operated ClusterIP None <none> 9090/TCP 105m
prometheus-operator ClusterIP None <none> 8443/TCP 120m
部署nginx
kubectl create deploy nginx --image=nginx:1.6.1-alpine
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-f4c7fc54d-5qmpq 1/1 Running 0 23s
配置nginx-exporter
要启用nginx-exporter需要开始nginx stub页面统计功能,并将nginx配置以configmap挂载进去
cat nginx_stub.conf
server {
listen 8888;
server_name _;
location /stub_status {
stub_status on;
access_log off;
}
}
kubectl create configmap nginx-stub --from-file=nginx_stub.conf
挂载配置文件
nginx.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1-alpine
volumeMounts:
- mountPath: /etc/nginx/conf.d/nginx_stub.conf
subPath: nginx_stub.conf
name: nginx-conf
volumes:
- name: nginx-conf
configMap:
name: nginx-stub
---
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
selector:
app: nginx
ports:
- port: 80
targetPort: 80
name: http
- port: 8888
targetPort: 8888
name: nginx-stub应用
kubectl apply -f nginx.yaml
创建exporter
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-exporter
labels:
app: nginx-exporter
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
selector:
matchLabels:
app: nginx-exporter
template:
metadata:
labels:
app: nginx-exporter
spec:
containers:
- image: nginx/nginx-prometheus-exporter:0.8.0
name: nginx-exporter
imagePullPolicy: Always
args:
- "-nginx.scrape-uri=http://nginx:8888/stub_status" # 需要和前面配置的stub页面保持一致
resources:
requests:
cpu: 50m
memory: 64Mi
limits:
cpu: 50m
memory: 64Mi
ports:
- containerPort: 9113
name: http-metrics
volumeMounts:
- mountPath: /etc/localtime
name: timezone
volumes:
- name: timezone
hostPath:
path: /etc/localtime
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: nginx-exporter
labels:
app: nginx-exporter
spec:
selector:
app: nginx-exporter
ports:
- port: 9113
targetPort: 9113
name: metrics
创建serviceMonitor
nginx-serviceMonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: nginx-exporter
spec:
endpoints:
- interval: 15s
port: metrics # 需要和service的port名称保持一致
selector:
matchLabels:
app: nginx-exporter创建
kubectl apply -f nginx-serviceMonitor.yaml
使用
对外暴露端口
默认安装后prometheus和grafana都是使用ClusterIP的形式,可以采用LoadBalancer或者ingress等形式对外提供服务。这里我们简单的使用NodePort进行暴露。
kubectl -n monitoring patch svc grafana -p '{"spec":{"type": "NodePort"}}'
kubectl -n monitoring patch svc prometheus-k8s -p '{"spec":{"type": "NodePort"}}'
kubectl get svc -n monitoring | grep -E "grafana|prometheus-k8s"
grafana NodePort 10.96.185.117 <none> 3000:32072/TCP 127m
prometheus-k8s NodePort 10.96.211.235 <none> 9090:30787/TCP 127m
查看Prometheus
打开浏览器访问node节点的30787端口进行访问。
查看target
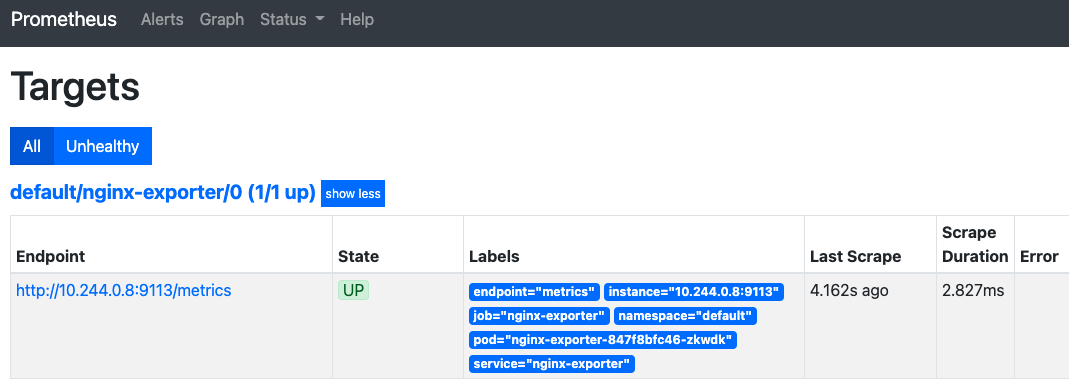
可以看到我们创建的nginx的target已经采集到了。
配置grafana
打开浏览器,访问node的32072
默认用户名admin,密码admin
首次登录提示修改密码。
查看Dashboard

默认内置的部分dashboards
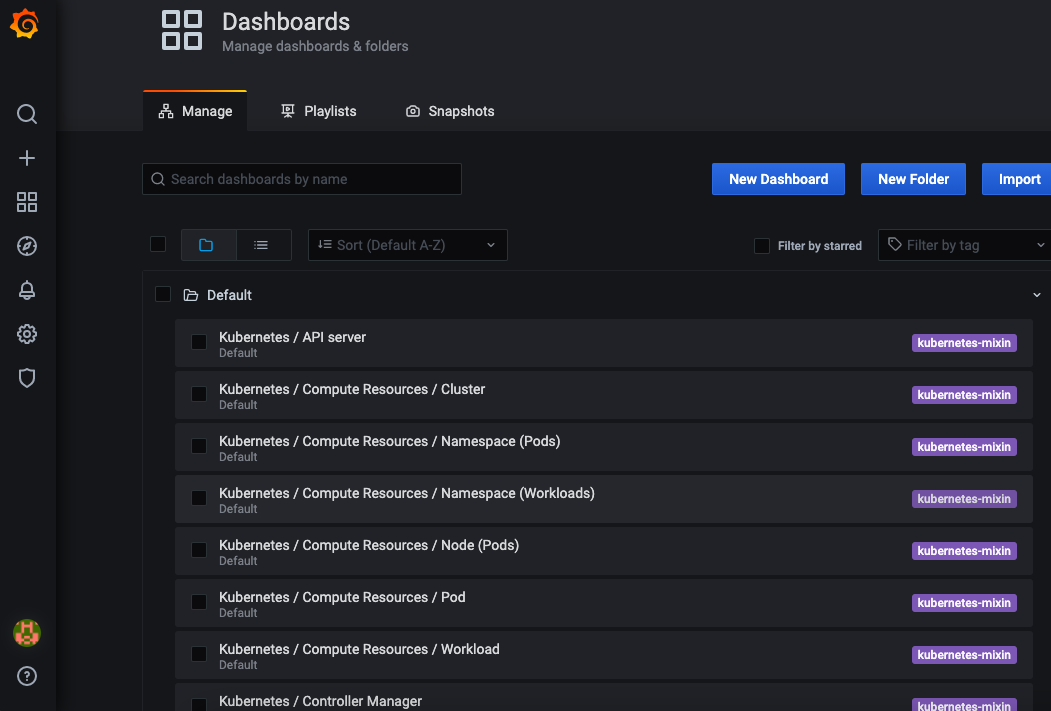
用户可以从Grafana的官网下载相应的Dashboard,也可以自己创建Dashboard。
导入Dashboard

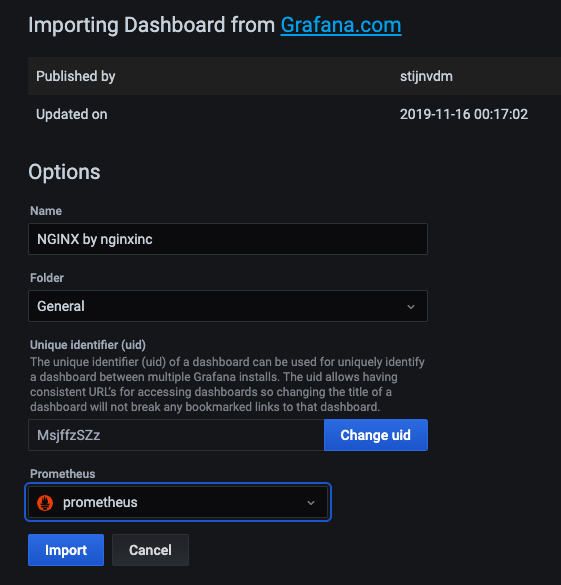
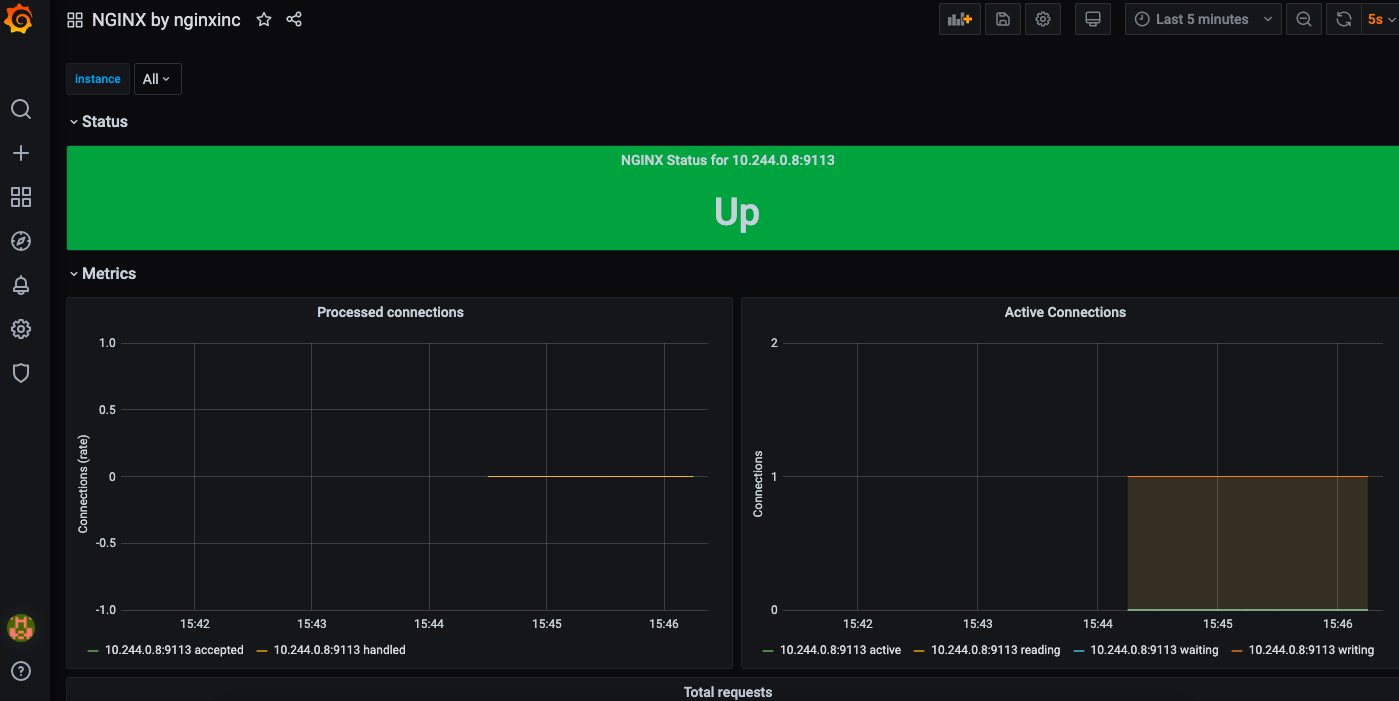
可以看到nginx的运行状况,活跃连接数,请求数等信息。
配置告警
默认情况下kube-prometheus已经内置了一系列的告警规则在里面,但是收不到告警信息的。
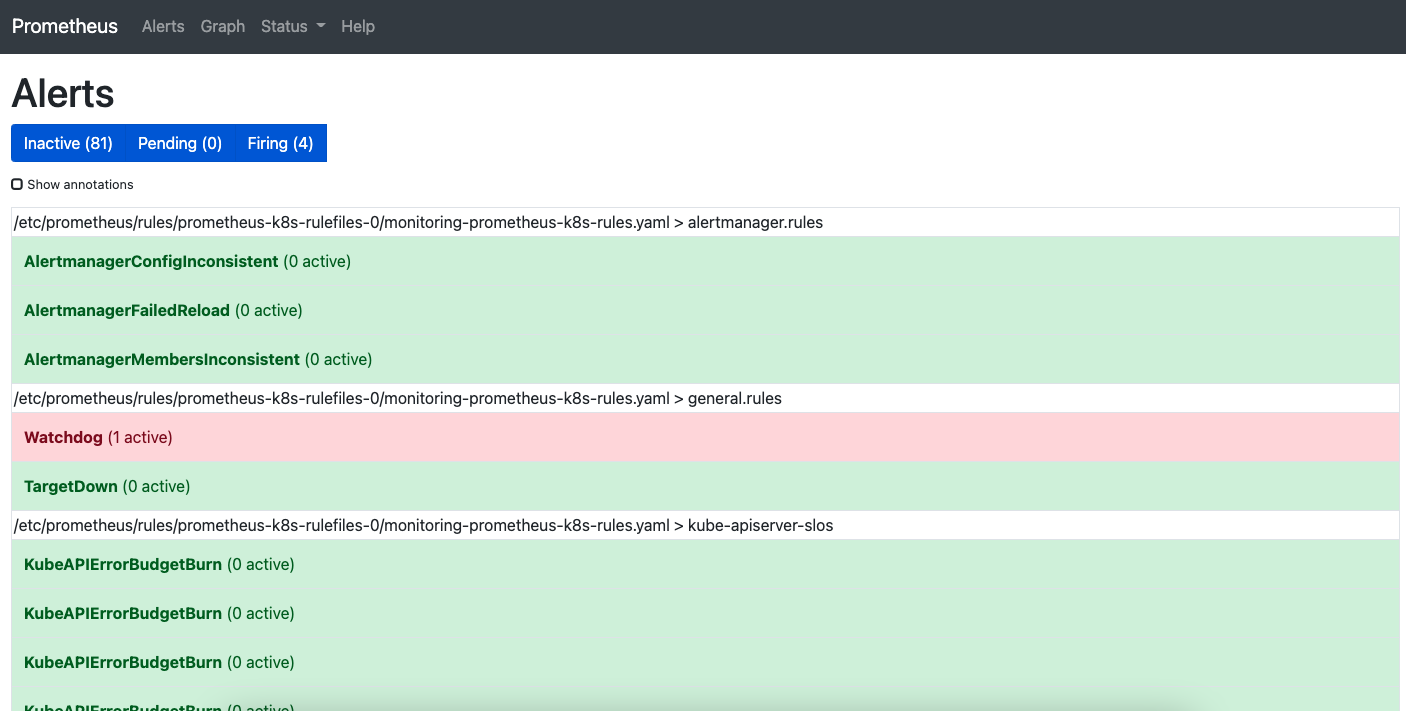
alertmanager-secret.yaml
apiVersion: v1
data: {}
kind: Secret
metadata:
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_match":
"severity": "critical"
"target_match_re":
"severity": "warning|info"
- "equal":
- "namespace"
- "alertname"
"source_match":
"severity": "warning"
"target_match_re":
"severity": "info"
"receivers":
- "name": "Default"
- "name": "Watchdog"
- "name": "Critical"
"route":
"group_by":
- "namespace"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "match":
"alertname": "Watchdog"
"receiver": "Watchdog"
- "match":
"severity": "critical"
"receiver": "Critical"
type: Opaque默认情况下时没有配置邮件或者其他告警渠道的。
通过获取官方文档找到相应的配置信息。https://prometheus.io/docs/alerting/latest/configuration/
以163邮箱为例,先登录邮箱,开启SMTP功能。
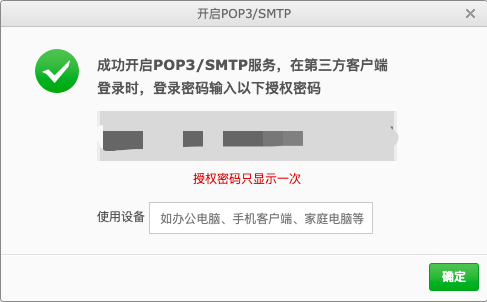
修改配置信息如下
apiVersion: v1
data: {}
kind: Secret
metadata:
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
"global":
# 163SMTP邮件服务器
"smtp_smarthost": "smtp.163.com:25"
# 发邮件的邮箱
"smtp_from": "XXXXXXXX@163.com"
# 发邮件的邮箱用户名,也就是你的邮箱
"smtp_auth_username": "XXXXXX@163.com"
# 前面获取的授权密码,记住不是邮箱密码
"smtp_auth_password": "XXXXXXXXXXXXXXXX"
"resolve_timeout": "5m"
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_match":
"severity": "critical"
"target_match_re":
"severity": "warning|info"
- "equal":
- "namespace"
- "alertname"
"source_match":
"severity": "warning"
"target_match_re":
"severity": "info"
"receivers":
- "name": "Email"
"email_configs":
# 接收邮件的邮箱,多个邮箱中间用空格隔开,也可以写多个to;尽量不要和发件一样,否则可能会遇到各种问题
- "to": "hzde@qq.com"
"route":
"group_by":
- "namespace"
- "alertname"
"group_interval": "5m"
"group_wait": "30s"
# 接收器
"receiver": "Email"
# 收敛时间,告警未恢复再次告警时间间隔
"repeat_interval": "1h"
"routes":
- "match":
"severity": "critical"
"receiver": "Email"
type: Opaque修改了配置文件,需要等待alertmanager重新加载。可以把alertmanager的service也改成NodePort进行查看。
邮件告警配置生效后就能收到邮件告警了。

以下为具体的告警内容:
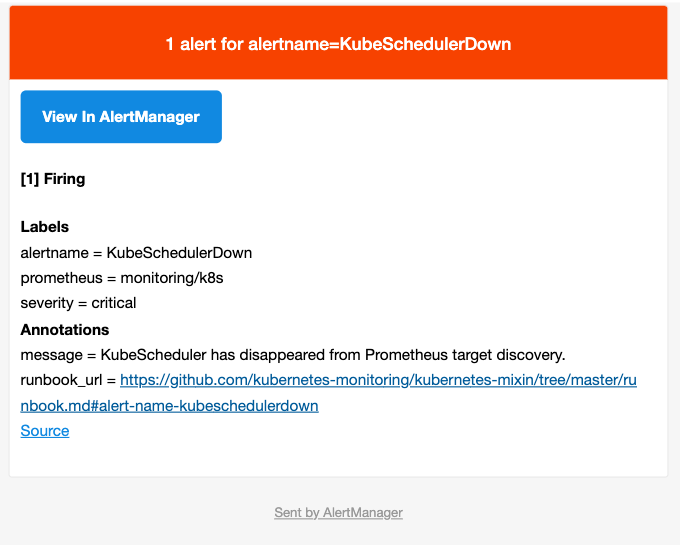
自定义告警规则
https://awesome-prometheus-alerts.grep.to/rules提供了许多规则,可以根据自己的实际需求参考配置,将自定义的规则放到一个单独的configmap里面,再进行挂载。
高级功能
数据持久化
alertmanager、prometheus、grafana属于有状态的服务,数据应该采用持久化存储,后端可以是glusterfs、ceph等等。
前提
需要已经安装了存储类
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
ceph-rbd (default) ceph.com/rbd Retain Immediate false 3h
prometheus数据持久化
修改prometheus-prometheus.yaml文件,在末尾加上
# 这部分为持久化配置
storage:
volumeClaimTemplate:
spec:
storageClassName: ceph-rbd # 存储类的名称
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 100Gi然后重新创建
kubectl apply -f prometheus-prometheus.yaml
Grafana数据持久化
先为grafana创建pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc
namespace: monitoring
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: ceph-rbd # 对应存储类的名称修改grafana-deployment.yaml文件,挂载pv
volumes: 找到grafana-storage段,将之前的emptyDir修改为pvc
#- emptyDir: {}
# name: grafana-storage
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc # 与上面创建的pvc名称保持一致修改prometheus默认保存时长
promentheus默认保留15天的数据,可以根据自己的需要进行调整。例如将prometheus数据保存为30天。
修改setup/prometheus-operator-deployment.yaml文件
- args:
- --kubelet-service=kube-system/kubelet
- --logtostderr=true
- --config-reloader-image=jimmidyson/configmap-reload:v0.3.0
- --prometheus-config-reloader=quay.io/coreos/prometheus-config-reloader:v0.40.0
- --storage.tsdb.retention.time=30d # 在这添加time参数参数说明
--storage.tsdb.retention.time=STORAGE.TSDB.RETENTION.TIME
How long to retain samples in storage. When this flag is set it overrides "storage.tsdb.retention". If neither this flag nor "storage.tsdb.retention" nor "storage.tsdb.retention.size" is set, the retention time defaults to 15d. Units Supported: y, w, d, h, m, s, ms.
服务自动发现
前面配置了一个nginx-exporter示例,是通过serviceMonitor的方式获取到target的。我们可以使用prometheus提供的kubernetes_sd_config能力,对service或者pod进行自动发现。
Kubernetes_sd_config支持的服务发现级别有
- node
- service
- pod
- endpoints
- ingress
这里介绍一下endpoints的自动发现功能。其它发现方式可以参考官方文档kubernetes_sd_config章节。
创建一个prometheus-additional.yaml文件
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name将文件创建为secret
kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
修改prometheus-prometheus.yaml文件,将该secret挂载上
# 在spec下面填写如下内容
additionalScrapeConfigs:
name: additional-configs
key: prometheus-additional.yaml然后重新应用,实现挂载
kubectl apply -f prometheus-prometheus.yaml
然后可以查看service discovery中的kubernetes-service-endpoints,前面创建的nginx-exporter的serviceMonitor也可以删除了。
- 原文作者:黄忠德
- 原文链接:https://huangzhongde.cn/post/Kubernetes/Using_kube-prometheus_deploy_monitor_system/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号