stacking思想
一开始stacking和bagging傻fufu分不清
stacking
一张经典的图
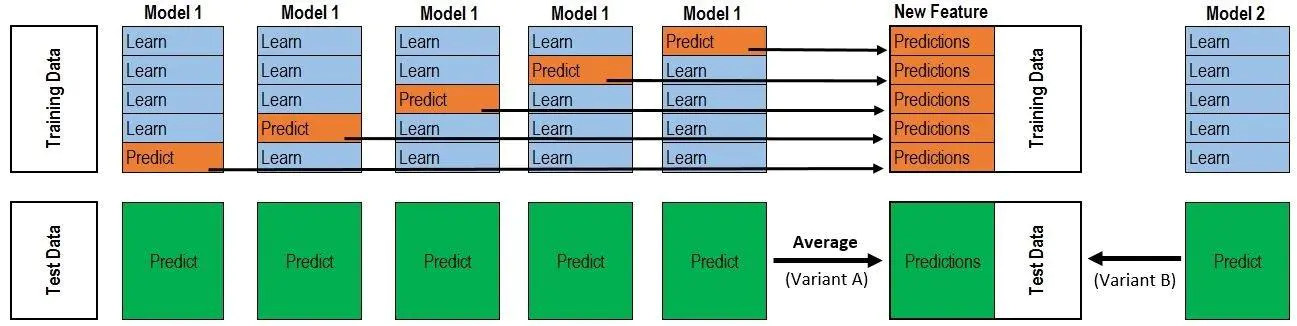
假设训练数据:train.csv有1000行;测试数据:test.csv有250行。然后按照上图所示训练:
假设model1是一个基模型xgboost,进行5折交叉验证
第一次,model1,拿train.csv的800行做训练集,200行做验证集,然后预测出200行的数据a1。
第二次,model1,拿train.csv的800行做训练集,200行做验证集,然后预测出200行的数据a2。
第三次,model1,拿train.csv的800行做训练集,200行做验证集,然后预测出200行的数据a3。
第四次,model1,拿train.csv的800行做训练集,200行做验证集,然后预测出200行的数据a4。
第五次,model1,拿train.csv的800行做训练集,200行做验证集,然后预测出200行的数据a5。
然后将a1到a5拼接起来,得到一列,共1000行的数据。
针对测试集test.csv有两种方法,一种是全部训练完成后,一次性预测输出250行数据;另一种是model1每次做完训练就拿test.csv中的数据做预测,一种得到5次250行的数据,然后做平均,得到一列250行的数据。
如果有10个基模型,那么根据train.csv会得到10列数据,作为x,原来train.csv中的label作为y(很多文章都没说这点,导致初学者有很多误解),然后再放到一个模型中做训练。而根据test.csv会得到10列250行的数据,作为测试数据。
最后,将训练好的模型预测10列200行的数据,得到的最终结果就是最后需要的数据。这仅仅只是2层stacking,多的可以搞很多层。放开那个BUG
这篇讲的更清楚一些

 浙公网安备 33010602011771号
浙公网安备 33010602011771号