特征选择算法学习2
特征选择算法学习笔记2
主要讲一下常见的评价函数
评价函数就是给特征选择后选择的好坏做一个直观额解释。。和智能算法中的评价函数是一样的,总得量化展示的
(一)思维导图
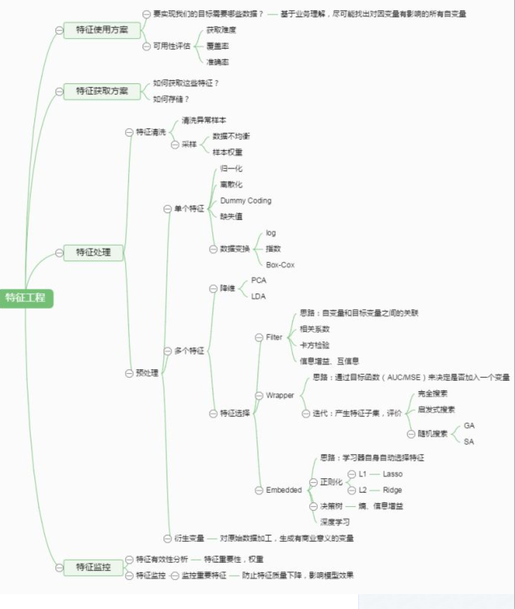
个人感觉这个图交代的挺清楚地儿。。可以概括。。源地址https://www.cnblogs.com/babyfei/p/9674128.html
(二)特征选择中常见的评价函数主要分为三种
- 过滤式 filter
- 包裹式 wrapper
- 嵌入式 embeded
2.2 距离 (Distance Metrics )
运用距离度量进行特征选择是基于这样的假设:好的特征子集应该使得属于同一类的样本距离尽可能小,属于不同类的样本之间的距离尽可能远。
常用的距离度量(相似性度量)包括欧氏距离、标准化欧氏距离、马氏距离等。欧式距离($$\operatorname{dist}(X, Y)=\sqrt{\sum_{i=1}{n}\left(x_{i}-y_{i}\right){2}}$$)偏多。。。
2.3 Chi-squared test(卡方检验)
consistency metrics通常用卡方检验,其思想是找出和预测目标不相关的特征,所以其过程是计算每个特征和预测目标的卡方统计量。
2.4 一致性( Consistency )
若样本1与样本2属于不同的分类,但在特征A、 B上的取值完全一样,那么特征子集{A,B}不应该选作最终的特征集。
2.5 信息增益、信息熵
信息熵:信息熵就是指不确定性,熵越大,不确定性越大
$$H(X)=-\sum_{i=1}^{n} P_{i} \bullet \log {2} P$$
信息增益是针对一个一个的特征而言的,就是看一个特征t,系统有它和没它的时候信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即增益。系统含
有特征t的时候信息量很好计算,就是刚才的式子,它表示的是包含所有特征时系统的信息量。
信息熵有如下特性:若集合Y的元素分布越“纯”,则其信息熵越小;若Y分布越“紊乱”,则其信息熵越大。在极端的情况下:若Y只能取一个值,即P1=1,则H(Y)取最
小值0;反之若各种取值出现的概率都相等,即都是1/m,则H(Y)取最大值log2m(https://blog.csdn.net/weixin_42296976/article/details/81126883
包裹式wrapper
这个目前我看的包裹式论文稍微多一点,主要是与原启发式算法相结合
1.定义:将子集的选择看作是一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较。这样就将子集的选择看作是一个是一个优化问题,这
里有很多的优化算法可以解决,尤其是一些启发式的优化算法,如GA,PSO,DE,ABC,GWO,WOA,FA,FPA,BOA,ALO,ACO。一般的是二进制改进算法居多一些。
2.1分类错误率
使用特定的分类器,用给定的特征子集对样本集进行分类,用分类的精度来衡量特征子集的好坏。
公式:$$\text {error}_{-} \text {rate}=\frac{\sum\{1 | Y i \neq P Y i\}}{\sum\{1 | Y i=Y i\}}$$
一些论文里面这个公式居多:$$\text {Fitness}=\alpha \gamma_{R}(D)+\beta \frac{|R|}{|C|}$$


3常见的分类器
这个写个专门的吧,挺多的,不过论文中常用的KNN和SVM居多
<a>https://www.cnblogs.com/gaowenxingxing/p/11829424.html</a>
嵌入式 embeded
1.定义:
在模型既定的情况下学习出对提高模型准确性最好的属性。这句话并不是很好理解,其实是讲在确定模型的过程中,挑选出那些对模型的训练有重要意义的属
性。嵌入式特征选择是将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了特征选择。
2.给个思维导图吧
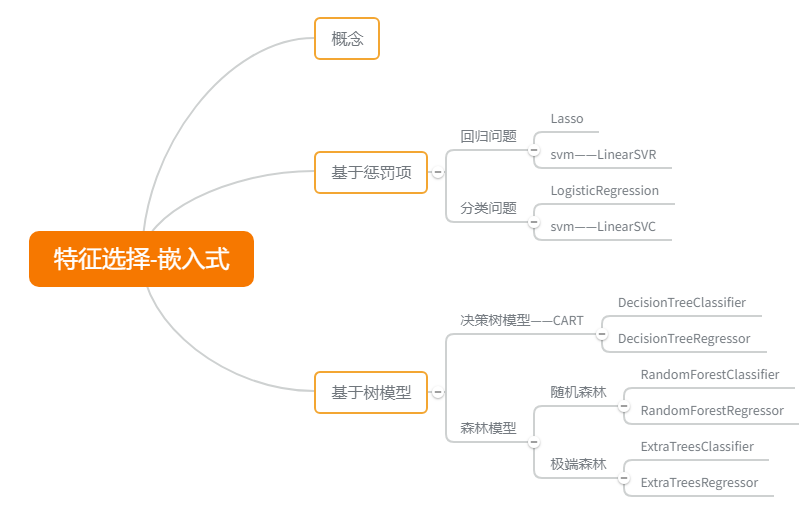
这里有几个分类器,我回头单独写出来,给出代码。
Reference:
1.《机器学习》周志华
2.Binary ant lion approaches for feature selection
3.Binary butterfly optimization approaches for feature selection
4.Whale optimization approaches for wrapper feature selection
5.https://www.cnblogs.com/stevenlk/p/6543628.html#移除低方差的特征-removing-features-with-low-variance
6. M. Dash, H. Liu, Feature Selection for Classification. In:Intelligent Data Analysis 1 (1997) 131–156.
7。Lei Yu,Huan Liu, Feature Selection for High-Dimensional Data:A Fast Correlation-Based Filter Solution
8.Ricardo Gutierrez-Osuna, Introduction to Pattern Analysis ( LECTURE 11: Sequential Feature Selection )
http://courses.cs.tamu.edu/rgutier/cpsc689_f08/l11.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号