
Python之路【第一篇】:python简介与杂乱知识汇总
本节内容:
Python发展历史
HOW TO RETURN words document:
PUT {} IN collection
FOR line IN document:
FOR word IN split line:
IF word not.in collection:
INSERT word IN collection
RETURN collection
HOW TO用于定义一个函数。一个Python程序员应该很容易理解这段程序。ABC语言使用冒号和缩进来表示程序块。行尾没有分号。for和if结构中也没有括号() 。赋值采用的是PUT,而不是更常见的等号。这些改动让ABC程序读起来像一段文字。尽管已经具备了良好的可读性和易用性,ABC语言最终没有流行起来。在当时,ABC语言编译器需要比较高配置的电脑才能运行。而这些电脑的使用者通常精通计算机,他们更多考虑程序的效率,而非它的学习难度。除了硬件上的困难外,ABC语言的设计也存在一些致命的问题: 可拓展性差。ABC语言不是模块化语言。如果想在ABC语言中增加功能,比如对图形化的支持,就必须改动很多地方。不能直接进行IO。ABC语言不能直接操作文件系统。尽管你可以通过诸如文本流的方式导入数据,但ABC无法直接读写文件。输入输出的困难对于计算机语言来说是致命的。你能想像一个打不开车门的跑车么?过度革新。ABC用自然语言的方式来表达程序的意义,比如上面程序中的HOW TO 。然而对于程序员来说,他们更习惯用function或者define来定义一个函数。同样,程序员更习惯用等号来分配变量。尽管ABC语言很特别,但学习难度也很大。传播困难。ABC编译器很大,必须被保存在磁带上。当时Guido在访问的时候,就必须有一个大磁带来给别人安装ABC编译器。这样,ABC语言就很难快速传播。1989年,为了打发圣诞节假期,Guido开始写Python语言的编译器。Python这个名字,来自Guido所挚爱的电视剧Monty Python's Flying Circus。他希望这个新的叫做Python的语言,能符合他的理想:创造一种C和shell之间,功能全面,易学易用,可拓展的语言。Guido作为一个语言设计爱好者,已经有过设计语言的尝试。这一次,也不过是一次纯粹的hacking行为。
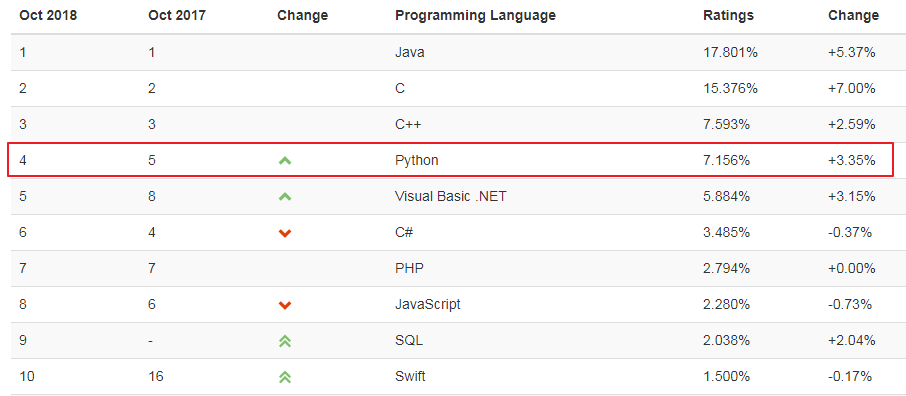
TIOBE Index for October 2018
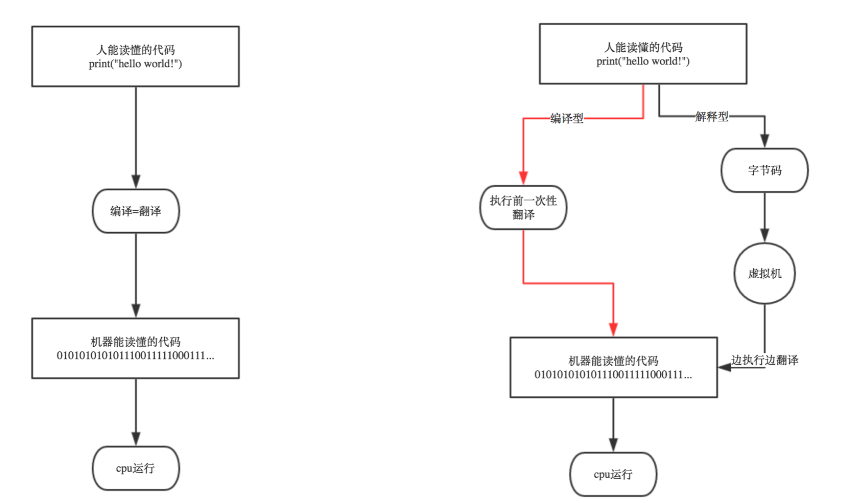
pyc 文件:
执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
内容编码
python2解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
- ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
python3解释器的默认编码为unicode,显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
- Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
- UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
#!/usr/bin/env python print "你好,世界"
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
print "你好,世界"
执行脚本传入参数与注释
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
- Python内部提供的模块
- 业内开源的模块
- 程序员自己开发的模块
Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数
#!/usr/bin/env python # -*- coding: utf-8 -*- import sys print sys.argv
单行注视:# 被注释内容
多行注释:""" 被注释内容 """
流程控制
if... elif... elif ...... else
while(break/continue) else 当跳出循环后执行else语句
for(break/continue) else 当跳出循环后执行else语句
变量
为了更充分的利用内存空间以及更有效率的管理内存,变量是有不同的类型的,如下所示:
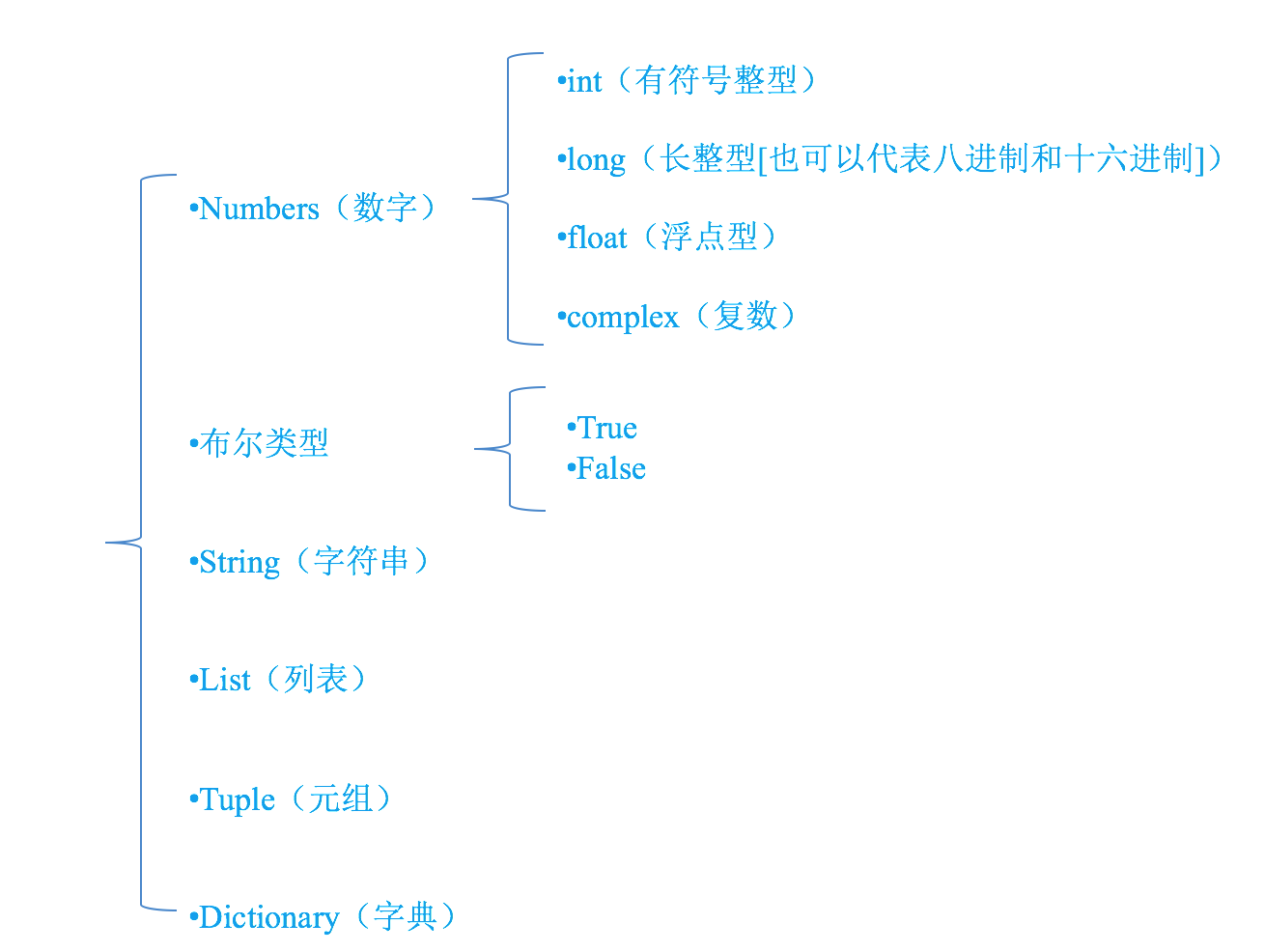
怎样知道一个变量的类型呢?
- 在python中,只要定义了一个变量,而且它有数据,那么它的类型就已经确定了,不需要咱们开发者主动的去说明它的类型,系统会自动辨别
- 可以使用 type(变量的名字),来查看变量的类型
变量名:由字母、下划线和数字组成,且数字不能开头
三元运算
result = 值1 if 条件 else 值2
如果条件为真:result = 值1
如果条件为假:result = 值2
万恶的字符串拼接
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内存中重新开辟一块空间。
python一切皆对象
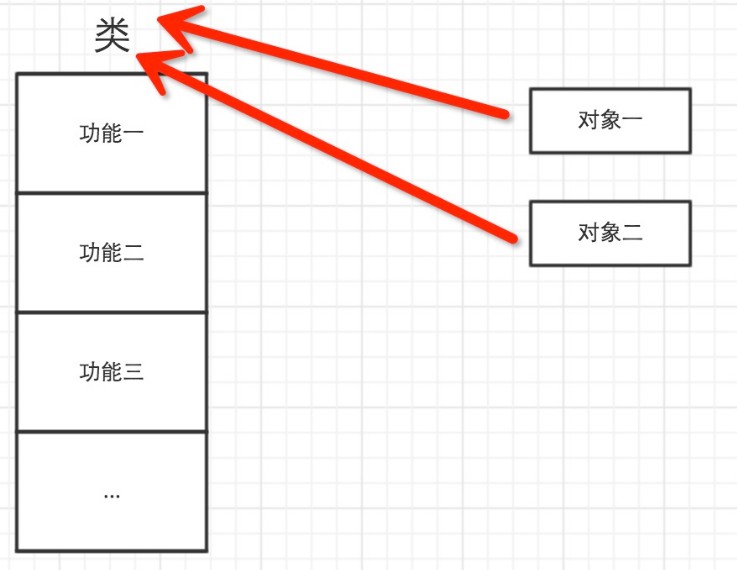
比如:常用的字符串、数字、列表、字典、元组都是来自于其对应的内置类,对应为字符串类str、数字类int、列表类list、字典类dict、元组类tuple...
python2与3的某些区别
- python3的 print() 函数;python2为 print
- python3字符编码默认为unicode;python2为ascii 码
- 某些库改名了:
|
python2 |
python3 |
|
_winreg |
winreg |
|
ConfigParser |
configparser |
|
copy_reg |
copyreg |
|
Queue |
queue |
|
SocketServer |
socketserver |
|
markupbase |
_markupbase |
|
repr |
reprlib |
|
test.test_support |
test.support |
输出
字符串的格式化输出:
下面是完整的,它可以与%符号使用列表:
| 格式符号 | 转换 |
|---|---|
| %c | 字符 |
| %s | 通过str() 字符串转换来格式化 |
| %i | 有符号十进制整数 |
| %d | 有符号十进制整数 |
| %u | 无符号十进制整数 |
| %o | 八进制整数 |
| %x | 十六进制整数(小写字母) |
| %X | 十六进制整数(大写字母) |
| %e | 索引符号(小写'e') |
| %E | 索引符号(大写“E”) |
| %f | 浮点实数 |
| %g | %f和%e 的简写 |
| %G | %f和%E的简写 |
age = 18 name = "qinglong"
# 几种格式化输出的方式 print("名字是 %s, 年龄是 %d" % (name, age)) print("名字是 {n}, 年龄是 {a}".format(n=name, a=age)) # 可以使用format()函数进行格式化输出 print("名字是 {0}, 年龄是 {1}".format(name, age)) print("名字是 {n}, 年龄是 {a}".format_map({"n": name, "a": age})) # format_map()函数传入的参数是一个字典
输入
python2中raw_input()
- raw_input()的小括号中放入的是,提示信息,用来在获取数据之前给用户的一个简单提示
- raw_input()在从键盘获取了数据以后,会存放到等号右边的变量中
- raw_input()会把用户输入的任何值都作为字符串来对待
python3版本中,没有raw_input()函数,只有input(),并且python3中的input()与python2中的raw_input()功能一样
#!/usr/bin/env python # -*- coding: utf-8 -*- # 将用户输入的内容赋值给 name 变量
#name = raw_input("请输入用户名:") # python2 name = input("请输入用户名:") # python3 # 打印输入的内容 print(name)
输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法,即:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import getpass
# 将用户输入的内容赋值给 name 变量
pwd = getpass.getpass("请输入密码:")
# 打印输入的内容
print(pwd)
运算符
python支持以下几种运算符
1.算术运算符
下面以a=10, b=20为例进行计算
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 两个对象相加a + b 输出结果30 |
| - | 减 | 得到负数或是一个数减去另一个数a - b 输出结果-10 |
| * | 乘 | 两个数相乘或是返回一个被重复若干次的字符串a * b 输出结果200 |
| / | 除 | x除以yb / a 输出结果 2 |
| // | 取整除 | 返回商的整数部分9//2 输出结果4 , 9.0//2.0 输出结果4.0 |
| % | 取余 | 返回除法的余数b % a 输出结果 0 |
| ** | 幂 | 返回x的y次幂a**b 为10的20次方, 输出结果100000000000000000000 |
>>> 9/2.0 4.5 >>> 9//2.0 4.0
2.赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 赋值运算符 | 把=号右边的结果给左边的变量num=1+2*3 结果num的值为7 |
>>> a, b = 1, 2 >>> a 1 >>> b 2
3.复合赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| += | 加法赋值运算符 | c += a 等效于c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于c = c // a |
4.常用的数据类型转换
| 函数 | 说明 |
|---|---|
| int(x [,base ]) | 将x转换为一个整数 |
| long(x [,base ]) | 将x转换为一个长整数 |
| float(x ) | 将x转换到一个浮点数 |
| complex(real [,imag ]) | 创建一个复数 |
| str(x ) | 将对象x 转换为字符串 |
| repr(x ) | 将对象x 转换为表达式字符串 |
| eval(str ) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s ) | 将序列s 转换为一个元组 |
| list(s ) | 将序列s 转换为一个列表 |
| chr(x ) | 将一个整数转换为一个字符 |
| unichr(x ) | 将一个整数转换为Unicode字符 |
| ord(x ) | 将一个字符转换为它的整数值 |
| hex(x ) | 将一个整数转换为一个十六进制字符串 |
| oct(x ) | 将一个整数转换为一个八进制字符串 |
a = '100' # 此时a的类型是一个字符串,里面存放了100这3个字符
b = int(a) # 此时b的类型是整型,里面存放的是数字100
print("a=%d" % b)
5.比较(即关系)运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
| == | 检查两个操作数的值是否相等,如果是则条件变为真。 | 如a=3,b=3则(a == b) 为true. |
| != | 检查两个操作数的值是否相等,如果值不相等,则条件变为真。 | 如a=1,b=3则(a != b) 为true. |
| <> | 检查两个操作数的值是否相等,如果值不相等,则条件变为真。 | 如a=1,b=3则(a <> b) 为true。这个类似于!= 运算符 |
| > | 检查左操作数的值是否大于右操作数的值,如果是,则条件成立。 | 如a=7,b=3则(a > b) 为true. |
| < | 检查左操作数的值是否小于右操作数的值,如果是,则条件成立。 | 如a=7,b=3则(a < b) 为false. |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是,则条件成立。 | 如a=3,b=3则(a >= b) 为true. |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是,则条件成立。 | 如a=3,b=3则(a <= b) 为true. |
6.逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果x 为False,x and y 返回False,否则它返回y 的计算值。 | (a and b) 返回20。 |
| or | x or y | 布尔"或" - 如果x 是True,它返回True,否则它返回y 的计算值。 | (a or b) 返回10。 |
| not | not x | 布尔"非" - 如果x 为True,返回False 。如果x 为False,它返回True。 | not(a and b) 返回False |
文件操作
- 打开文件,或者新建立一个文件
- 读/写数据
- 关闭文件
1.打开文件
在python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件
open(文件名,访问模式)
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
2.关闭文件
close( )
示例如下:
f = open('test.txt', 'w') # 新建一个文件,文件名为:test.txt
f.close() # 关闭这个文件
3.文件的读写
<1>写数据(write)
使用write()可以完成向文件写入数据
示例如下:
f = open('test.txt', 'w') # 打开文件
f.write('hello world, i am here!') # 写入数据
f.close() # 关闭文件
注意:
如果文件不存在那么创建,如果存在那么就先清空,然后写入数据
<2>读数据(read)
使用read(num)可以从文件中读取数据,num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
示例如下:
f = open('test.txt', 'r') # 以只读方式打开文件
content = f.read(5) # 读取5个字符
print(content)
print("-" * 30)
content = f.read() # 读取剩下的所有
print(content)
f.close()
注意:
如果open是打开一个文件,那么可以不用写打开的模式,即只写 open('test.txt'),默认以只读方式打开
如果读了多次,那么后面读取的数据是从上次读完后的位置开始的
<3>读数据(readlines)
就像read没有参数时一样,readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素
# -*- coding:utf-8 -*-
f = open('test.txt', 'r')
contents = f.readlines()
print(type(content)) # 是一个列表,每一个元素为一行
i=1
for line in contents:
print("%d:%s" % (i, line))
i += 1
f.close()
<4>读数据(readline)
# -*- coding:utf-8 -*-
f = open('test.txt', 'r')
content = f.readline()
print("1:%s" % content)
content = f.readline()
print("2:%s"%content)
f.close()
想一想:
如果一个文件很大,比如5G,试想应该怎样把文件的数据读取到内存然后进行处理呢?
制作文件的备份
1 # -*-coding:utf-8 -*- 2 3 oldFileName = input("请输入要拷贝的文件名字:") 4 5 oldFile = open(oldFileName,'r') 6 7 # 如果打开文件 8 if oldFile: 9 10 # 提取文件的后缀 11 fileFlagNum = oldFileName.rfind('.') 12 if fileFlagNum > 0: 13 fileFlag = oldFileName[fileFlagNum:] 14 15 # 组织新的文件名字 16 newFileName = oldFileName[:fileFlagNum] + '[复件]' + fileFlag 17 18 # 创建新文件 19 newFile = open(newFileName, 'w') 20 21 # 把旧文件中的数据,一行一行的进行复制到新文件中 22 for lineContent in oldFile.readlines(): 23 newFile.write(lineContent) 24 25 # 关闭文件 26 oldFile.close() 27 newFile.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号