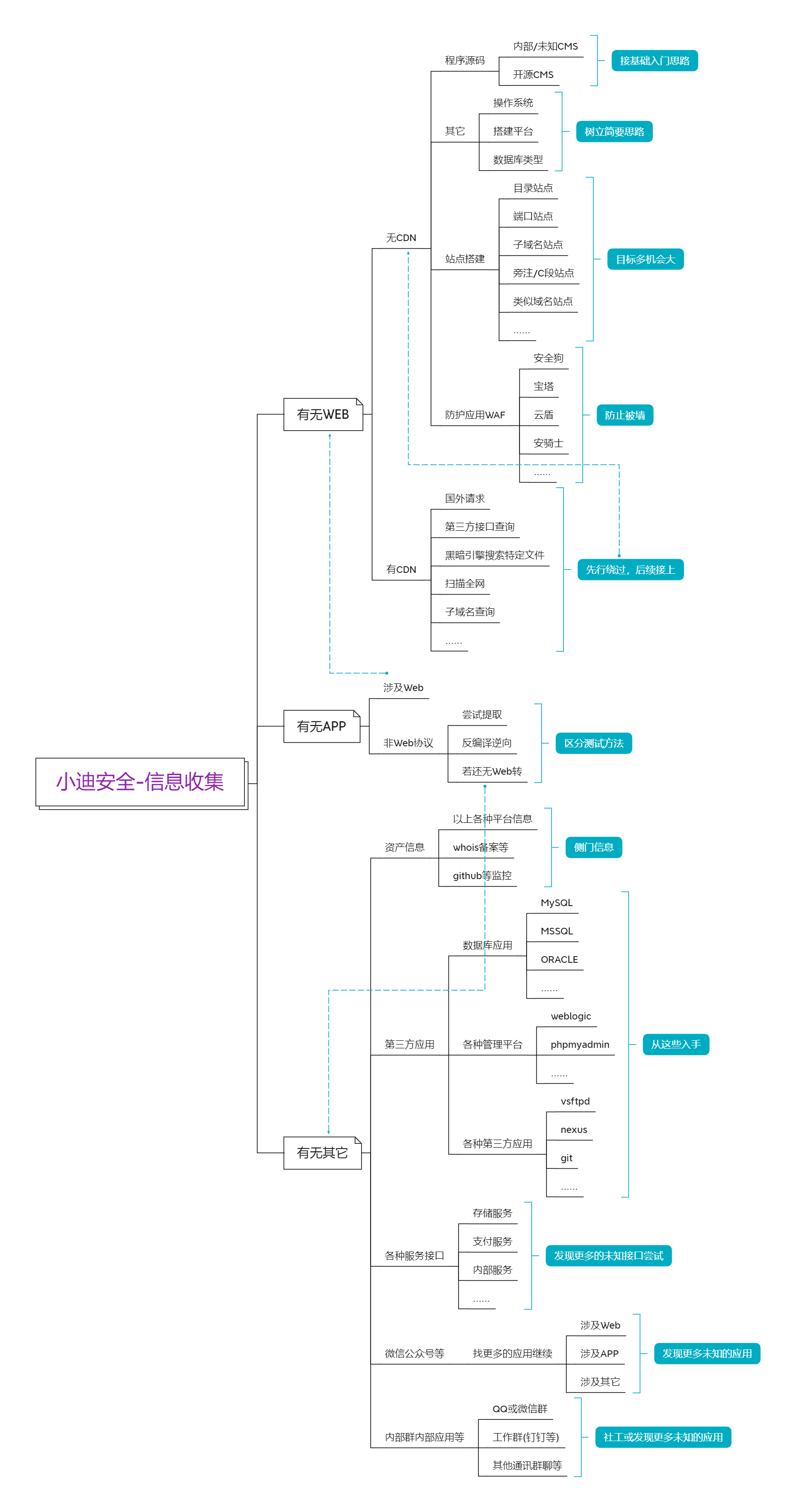
Web安全-信息收集
信息收集
前言:在渗透测试过程中,信息收集是非常重要的一个环节,此环节的信息将影响到后续成功几率,掌握信息的多少将决定发现漏洞的机会的大小,换言之决定着是否能完成目标的测试任务。也就是说:渗透测试的思路就是从信息收集开始,你与大牛的差距也是这里开始的。
Part1:whois信息收集
whois是网站管理者进行域名注册时留下的信息,收集whois信息可以帮助我们找到更多的域名,我们还可以查到邮箱,进而找到更多的东西。
查询网站:
http://whois.chinaz.com/(站长之家)
https://www.whois.com/(国外网站)
Part2:子域名查询
安全的高度取决于最短的那块板子,很多时候主站的防护比较强,所以我们可以搜集其子域名去进行安全测试。而且子域名可以扩大攻击范围,子域名一定是有关联的,很多时候基本上都同属一个公司

搜集方法:
① 谷歌语法
site: 指定域名
② 通过在线平台
• ip反查域名
https://dns.aizhan.com/
https://reverseip.domaintools.com/
• 站长工具
http://tool.chinaz.com/subdomain/
• 潮汐指纹
http://finger.tidesec.com/
③ 使用工具爆破DNS服务器
• subDomainsBrute
https://github.com/lijiejie/subDomainsBrute
• Layer子域名挖掘机
• teemo
https://github.com/bit4woo/teemo
Part3:端口探测
有些危险端口开放了我们就可以尝试入侵,例如 445|3306|22|1433|6379 可以尝试爆破或者是使用某些端口存在漏洞的服务。而且有可能一台服务器上面不同端口代表着不同的Web网站~
常见端口与服务对应关系
445-局域网文件共享服务【永恒之蓝】
3389-远程桌面
80-web搭建默认端口
3306-MySQL默认端口
21-Ftp
22-SSH服务
1433-SQL Server默认端口
6379-Redis数据库默认端口
8888-宝塔默认端口
1521-Oracle数据库默认端口
nmap的使用:
nmap+ip #最简单的使用方法
nmap+ip/24 #C段探测
nmap -p [port1,port2,...] [ip] #探测指定端口
nmap -p 1-65535 [ip] #全端口扫描
nmap -v [ip] #执行命令的同时显示每一步具体做了什么
nmap -Pn [ip] #目标禁ping时可以使用
nmap -h #查看所有命令
nmap -O [ip] #探测主机是什么操作系统
nmap -A [ip] #最强指令,把所有的扫描|探测方法都用上
端口扫描状态
Opened 端口开放
Closed 端口关闭
Filtered 端口被过滤
Part4:目录扫描
用途:
1.可以下载备份文件(数据库、源码、上传的内容)
2.寻找到网站的后台
御剑目录扫描工具
https://github.com/foryujian/yjdirscan
https://github.com/7kbstorm/7kbscan-WebPathBrute
网站状态码对应信息:
200-网站正常访问
302-重定向
404-页面不存在
403-权限不足,但是页面存在
502-服务器内部错误
Part5:CMS指纹识别
查询到网站是CMS之后,我们可以百度这个CMS爆出过哪些漏洞,快速的有针对性地进行测试。
https://s.threatbook.cn/
http://finger.tidesec.com/ 潮汐指纹【推荐】
Part6:旁站查询
旁站指同IP站点,旁站与主站一定有关联关系,它们要么位于同一台主机,要么处于同一内网
在线工具:
http://stool.chinaz.com/same
https://www.webscan.cc/
Part7:CDN相关
首先,我们需要确定目标用户是否使用了CDN
可以通过如下方法:
方法1:多节点ping
http://ping.chinaz.com/
http://ping.aizhan.com/
https://www.17ce.com/
https://www.boce.com/ping/
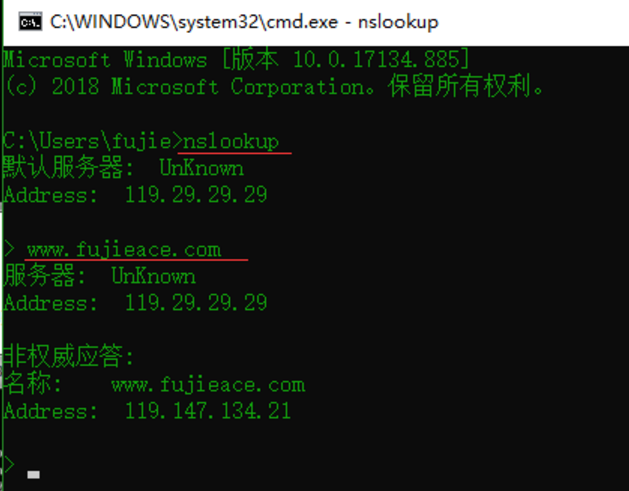
方法2:通过nslookup检测
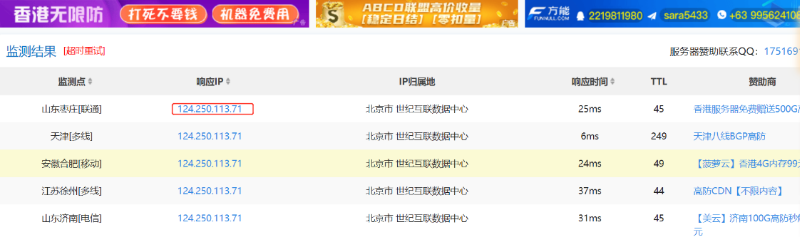
使用 nslookup 进行检测,原理同上,如果返回域名解析对应多个 IP 地址多半是使用了 CDN。
有 CDN 的示例,如下图:
方法3:直接连接查询
在线工具:
https://www.cdnplanet.com/tools/cdnfinder/
https://www.ipip.net/ip.html
CDN绕过
(1) 利用子域名请求
原理:由于经济等其他原因,子域名往往与主站在同一个服务器或网段
工具:在线子域名挖掘&Layer子域名挖掘机
http://z.zcjun.com/
https://phpinfo.me/domain
https://dnsdb.io/zh-cn/
Google 搜索;例如:用语法"site:baidu.com -www"就能查看除www外的子域名。
(2) 利用第三方查询
在线查询:
https://get-site-ip.com/
https://x.threatbook.cn/
https://tools.ipip.net/cdn.php
本方法效果一般,但是无成本
(3) 手机站点查询
原理:手机站点有的时候也可以绕过CDN,它只是根据你的UA头展示了贴近手机显示的页面
例:http://m.sp910.com其实和http://www.sp910.com访问的是同一个页面
(4) 国外地址请求
原理:目标对于国外用户没有做CDN,直接ping可以得到真实IP
在线工具:
https://check-host.net/check-ping?
http://port.ping.pe/
评价:本方法效果不是很好,但是成本低
案例:看到大量国外的服务器去Ping,得到IP都一样,极大概率是真实IP
(5) 利用邮件服务器接口获取真实IP
利用网站中有用到邮件的位置,例如注册发邮件、找回密码发邮件等等,查看邮件原文寻找真实IP。
案例:墨者学院注册邮件
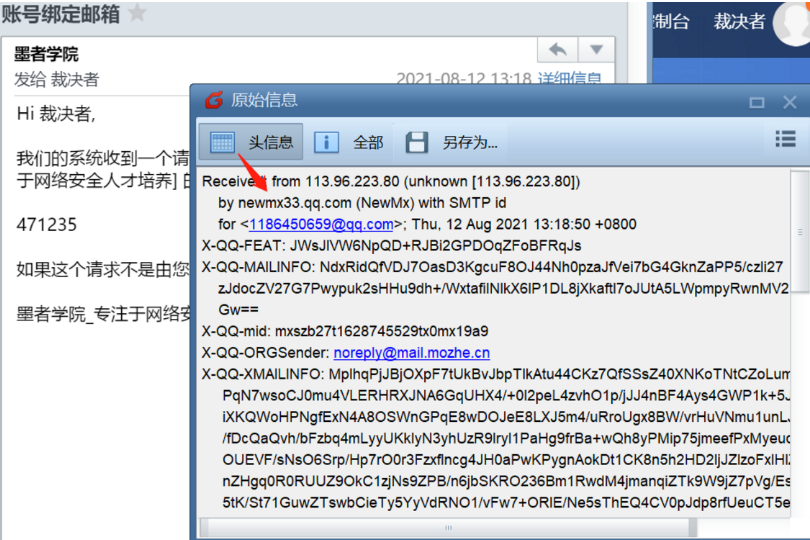
我们注意到上面这个是来自于腾讯的中转邮件,应该不是真实的;那么我们再往下找
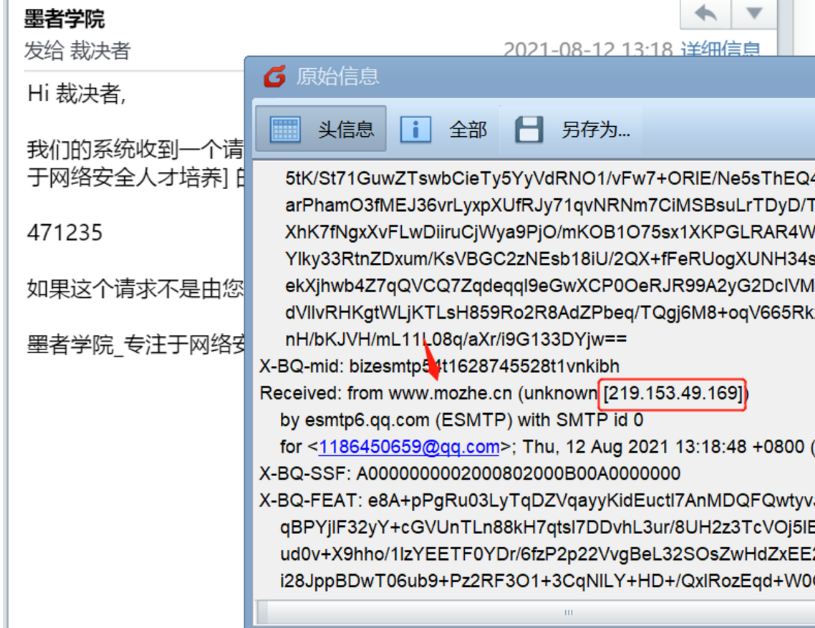
然后我们就发现了带有mozhe标志的邮箱,不出意外这个应该就是真实IP地址
我们接下来去百度查询一下,我们发现这个IP所在地在重庆
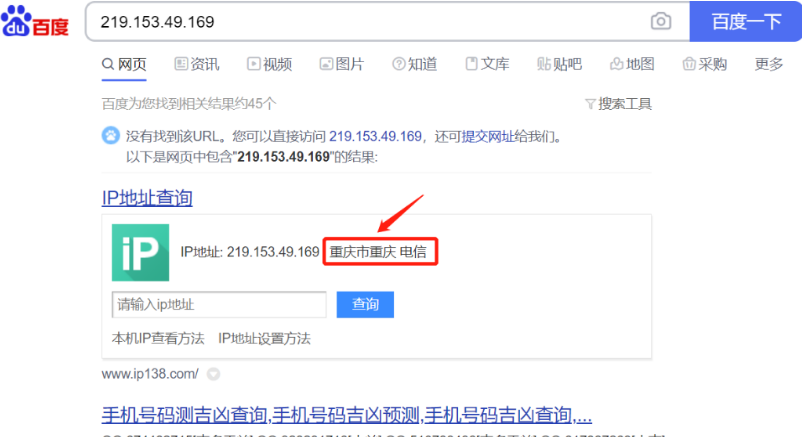
接下来我们怎么确定他就是这个IP呢?
方法:人情味【查备案地址、备案号】
我们在墨者学院官网下面发现
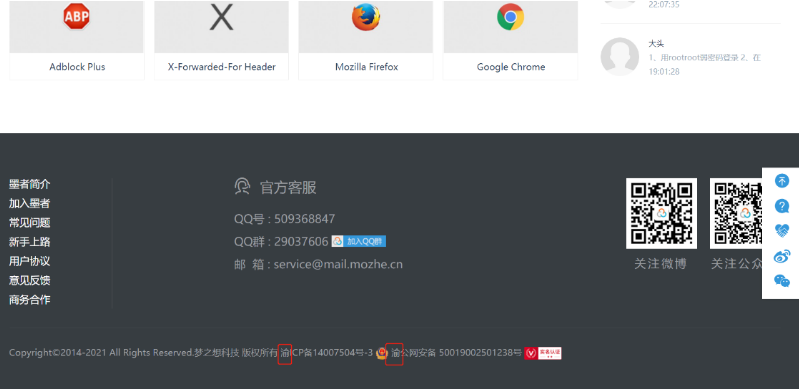
它的备案地址有渝,那么基本就可以确定它就是这个重庆的IP
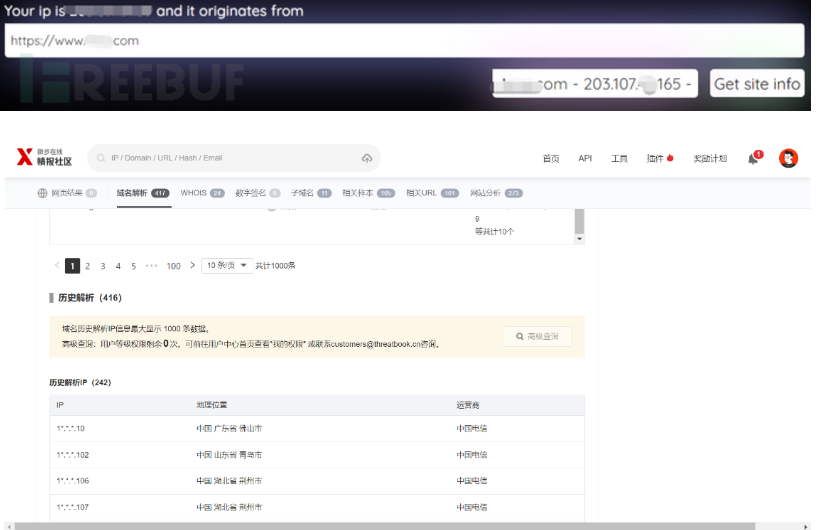
(6) 历史DNS解析记录
在线工具:
https://viewdns.info/iphistory/?domain=
http://www.jsons.cn/nslookup/
https://dnsdumpster.com/
https://securitytrails.com/domain/baidu.com/history/a
https://securitytrails.com/domain
https://sitereport.netcraft.com/?url=
https://x.threatbook.cn/
https://dnsdb.io/zh-cn/
评价:本方法效果好,但是需要花时间去找
需要注意的是:除了过去的DNS记录,当前的记录也有可能泄露原始服务器IP。例如,MX记录是一种常见的查找IP的方式。如果网站在与web相同的服务器和IP上托管自己的邮件服务器,那么原始服务器IP将在MX记录中。
历史DNS查询演示:

(7) 去掉WWW大法
评价:本方法效果较好,并且无成本
直接ping带WWW的网址
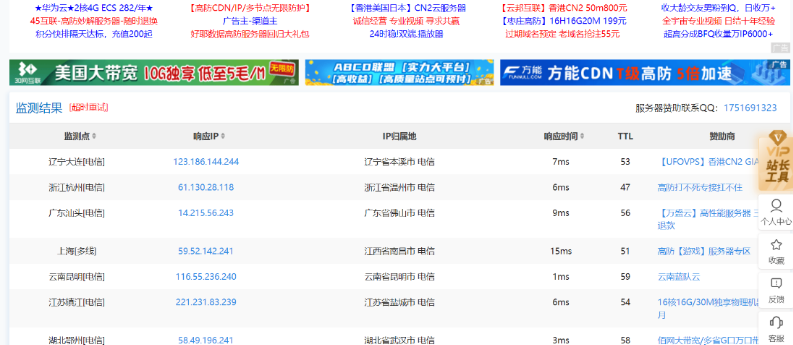
去掉WWW后再ping,查询到真实IP
(8) 利用黑暗引擎搜索ICO图标的hash值
原理:图片有一串唯一哈希,网络空间测绘引擎会收集全网IP的信息进行排序收录,
那么这些图标的信息,也自然会采集在测绘解析的目标中。
工具:fofa
评价:本方法效果好
步骤:
1、找到网站的ICO路径

2、Fofa 可以直接输入URL,也可以上传ico图片,将自动转化icon_hash

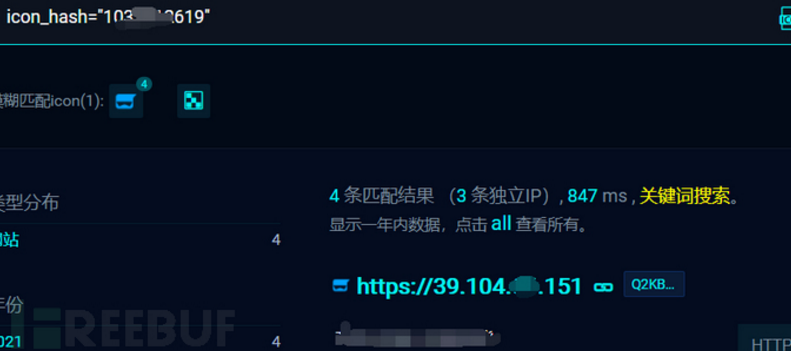
这里演示一下用shodan怎么做:
操作流程:
1、首先访问获取ico地址
2、然后利用python2获取其ico地址的hash信息
3、再利用黑暗引擎shodan进行全网追踪
4、最后通过结果访问探针真实地址

第一步,直接查看网页源代码获取完整ico地址

第二步,通过python2脚本获取hash值(需要提前安装好mmh3库)
import mmh3
import requests
response = requests.get('http://www.xiaodi8.com/img/favicon.ico')
favicon = response.content.encode('base64')
hash = mmh3.hash(favicon)
print hash
#安装mmh3失败记得先安装下这个
#Microsoft Visual C++ 14.0的百度云下载地址为:
#https://pan.baidu.com/s/12TcFkZ6KFLhofCT-osJOSg 提取码:wkgv

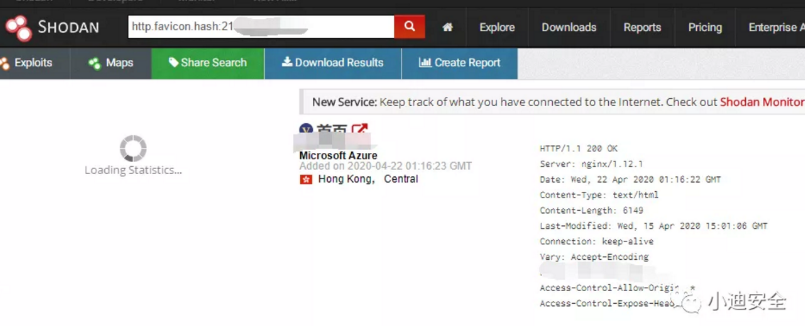
第三步,直接访问shodan,通过特定语法搜索
xxxx是icon_hash
搜索语法:http.favicon.hash:xxxx
(9) 通过APP端
通过抓包工具来抓取APP的请求包,寻找真实IP。
(10) 通过网站证书
案例演示:
1、需要站点是HTTPS的
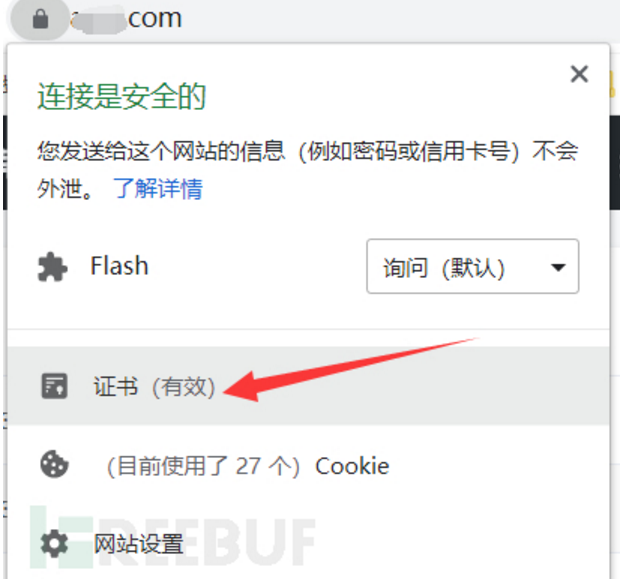
2、复制序列号
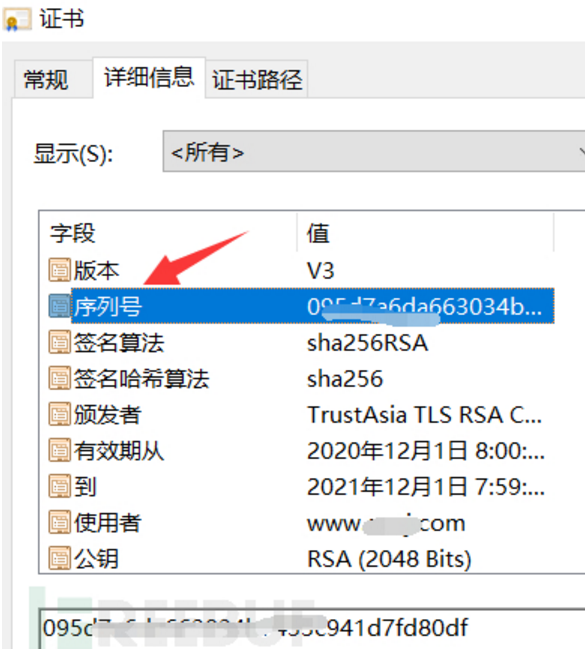
3、序列号是16进制,需要转化为10进制
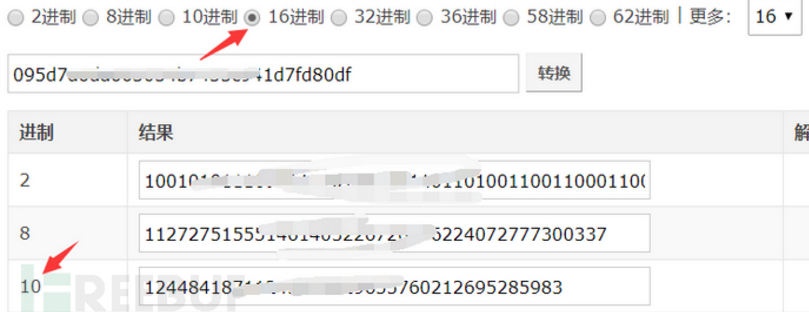
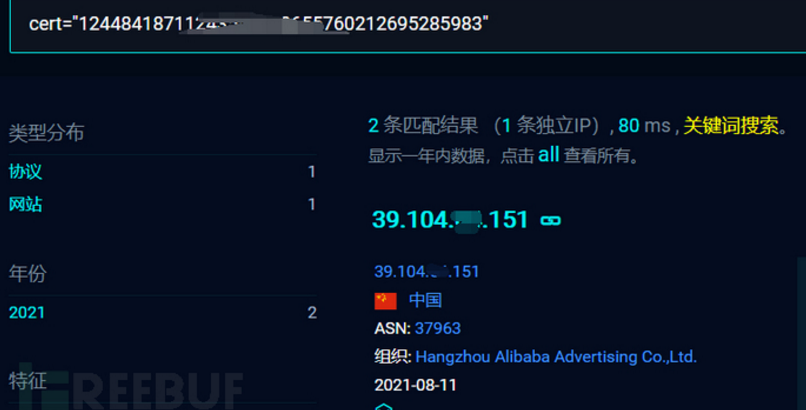
4、搜索语法:cert="xxxx"
(11) SSL证书查询
工具:https://censys.io/certificates?q=
评价:该方法准确度高
案例演示:域名www.xxx.com
1、输入语法: parsed.names: www.xxx.com and tags.raw: trusted
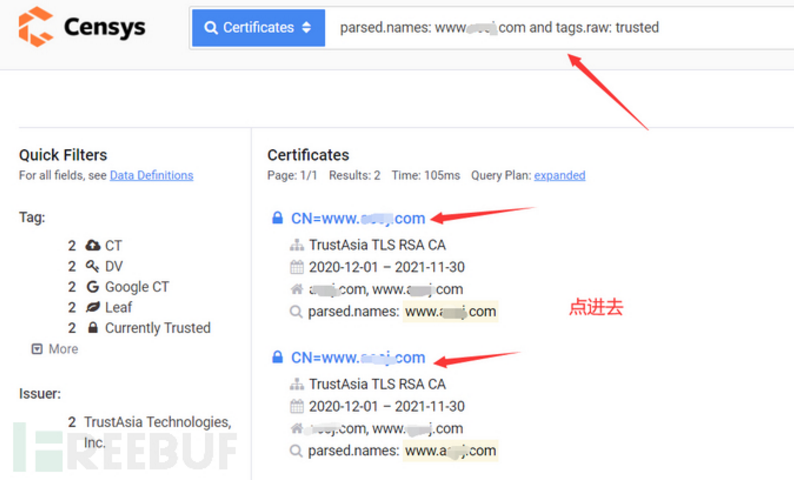
2、找到IPv4 Hosts,点进去
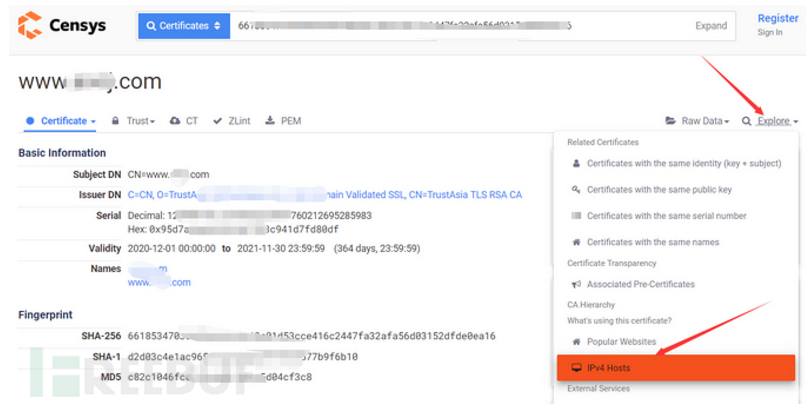
3、可以看见第一个就是了
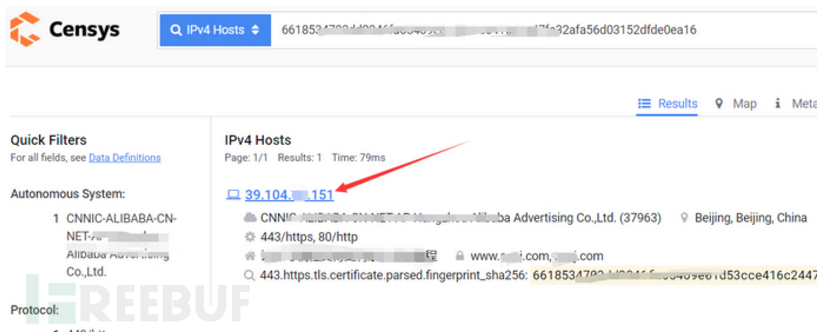
(12) 利用历史遗留文件
比如,phpinfo()、phpinfo.php等会暴露一些真实IP信息
(13) 利用全网扫描
扫描全网开放特定端口的IP,然后获取他们的特定页面的HTML源代码,用这些源代码和目标网站的特定页面的HTML源代码做对比,如果匹配上来了,就很可能是目标网站的真实P,工具匹配会匹配出来很多,最后还是要人工筛选。
全网扫描工具:zmap、w8fuckcdn、fuckcdn
https://github.com/Tai7sy/fuckcdn fuckcdn
https://github.com/boy-hack/w8fuckcdn w8fuckcdn
通过zmap扫描
(14) 以量打量【DDOS将CDN流量打没】
(15) 利用网络空间搜索引擎
最常见的网络空间搜索引擎有钟馗之眼、shodan、fofa搜索。
1、钟馗之眼:https://www.zoomeye.org/
2、Shodan:https://www.shodan.io/
3、FOFA:https://fofa.so/
这里主要是利用网站返回的内容寻找真实原始IP,如果原始服务器IP也返回了网站的内容,那么可以在网上搜索大量的相关数据。
我们只需要浏览网页源代码,寻找独特的代码片段。在JavaScript中使用具有访问或标识符参数的第三方服务(例如Google Analytics、reCAPTCHA、Analytics)是攻击者经常使用的方法。或者说用title,毕竟竟每个网站的title基本上都是独一无二的。 以fofa为例:可以直接以 title=""来搜索。
再配合最常见的网络空间搜索引擎就可以轻而易举的找到网站的真实的IP
Part8:C段扫描
某些有钱的公司,为了方便公司管理以及价格优惠,会买整个段
同一个C段有很大的概率处于同一个机房
信息收集-补充知识
谷歌hacking语法:
filetype:指定文件类型
inurl:指定url包含内容
site:指定域名
intitle:指定title包含内容
intext:指定内容
inurl:/admin/index #这种很容易找到别人的后台
inurl:/admin.php #这种就很容易找到admin.php的内容
site:edu.cn inurl:.php?id=123 #找SQL注入站点时可以这么找
君子协议
/robots.txt => 防止蜘蛛爬虫的协议
告诉搜索引擎哪些不要爬取,但是因为这是个君子协议,所以搜索引擎可以不遵守
WAF检测
工具:
https://github.com/EnableSecurity/wafw00f wafw00f
APP及其他资产获取
1、APP一键提取反编译【工具:漏了个大洞】
2、APP 抓数据包进行工具配合【模拟器+Burp】
利用Burp历史抓取更多URL
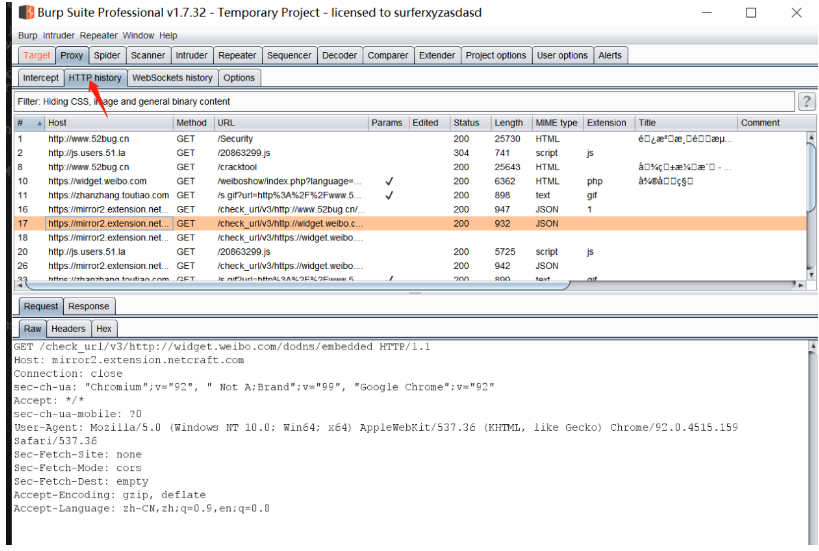
其它方法
同一个域名的不同后缀有可能属于同一个网站(.cn|.com|.net)
知识学习库
https://websec.readthedocs.io/zh/latest/ Web安全学习笔记
Github监控
Github监控最新的EXP发布及其它
# Title: wechat push CVE-2020
# Date: 2020-5-9
# Exploit Author: weixiao9188
# Version: 4.0
# Tested on: Linux,windows
# coding:UTF-8
import requests
import json
import time
import urllib3
import os
import pandas as pd
time_sleep = 20 # 每隔20秒爬取一次
while(True):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"}
# 判断文件是否存在
datas = []
response1 = None
response2 = None
if os.path.exists("olddata.csv"):
# 如果文件存在则每次爬取10个
df = pd.read_csv("olddata.csv", header=None)
datas = df.where(df.notnull(),None).values.tolist()# 将提取出来的数据中的nan转化为None
requests.packages.urllib3.disable_warnings()
response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2021&sort=updated&per_page=10",
headers=headers,verify=False)
response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&per_page=10",
headers=headers,verify=False)
else:
# 不存在爬取全部
datas = []
requests.packages.urllib3.disable_warnings()
response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2021&sort=updated&order=desc",headers=headers,verify=False)
response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&order=desc",headers=headers,verify=False)
data1 = json.loads(response1.text)
data2 = json.loads(response2.text)
for j in [data1["items"],data2["items"]]:
for i in j:
s = {"name":i['name'],"html":i['html_url'],"description":i['description']}
s1 =[i['name'],i['html_url'],i['description']]
if s1 not in datas:
#print(s1)
#print(datas)
params = {
"text":s["name"],
"desp":" 链接:"+str(s["html"])+"\n简介"+str(s["description"])
}
print("当前推送为"+str(s)+"\n")
print(params)
requests.packages.urllib3.disable_warnings()
requests.get("https://sctapi.ftqq.com/SCT68513T20RxXKZZlL1mtwHtu8UtTyPQ.send",params=params,timeout=10,verify=False)
#time.sleep(1)#以防推送太猛
print("推送完成!")
datas.append(s1)
else:
pass
#print("数据已存在!")
pd.DataFrame(datas).to_csv("olddata.csv",header=None,index=None)
time.sleep(time_sleep)
实战案例演示:
群友 WEB 授权测试下的服务测试【https://www.caredaily.com/】
网站表面上看起来存在漏洞的可能性不高,功能都比较简单
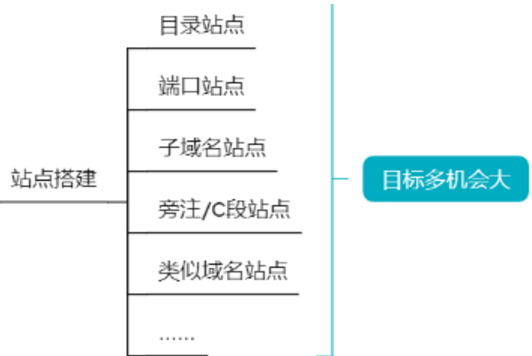
接下来直接从以下5方面开始
我们直接去fofa、shodan、zoomeye进行域名搜索
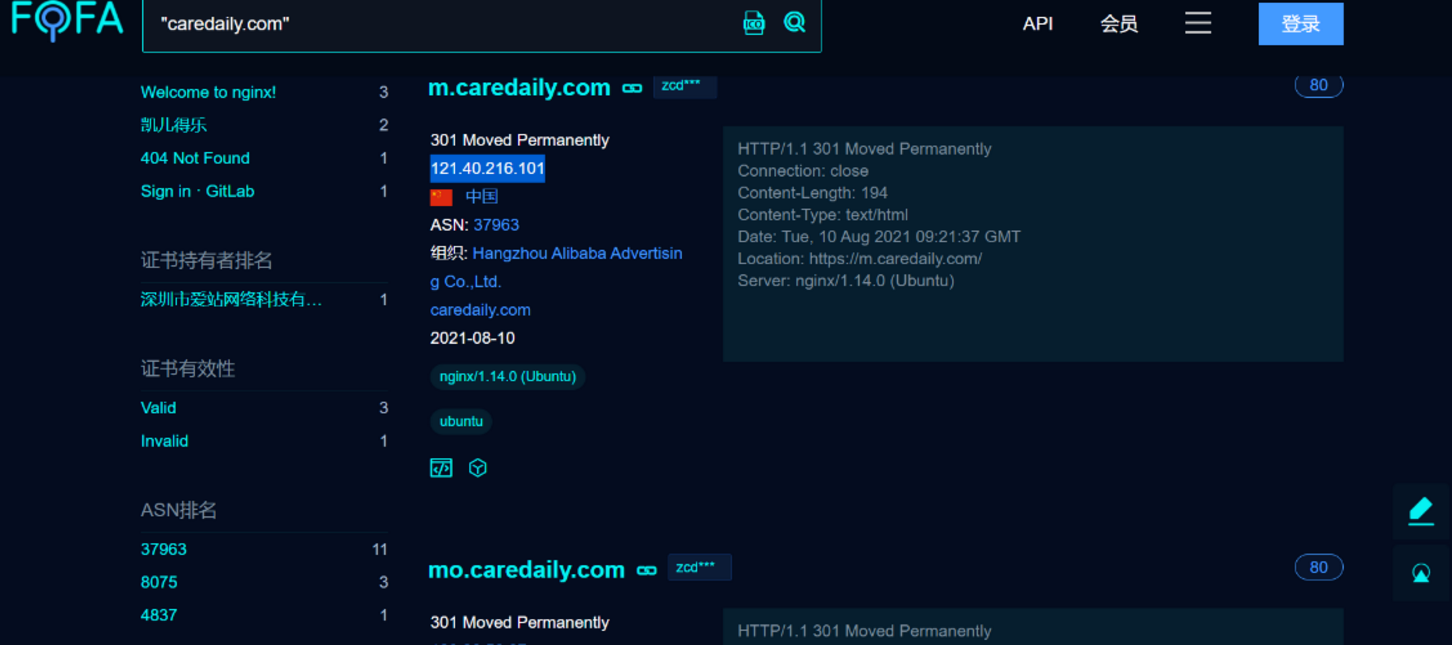
查看特定IP开放的端口服务可以通过
https://fofa.so/hosts/121.40.216.101 -> 替换成想要查询的IP
我们注意到这里8000端口出现了OpenSSH服务,我们就可以去搜对应版本存在的漏洞,去验证

我们又注意到他这27017开了MongoDB,那么就可能存在MongoDB数据库相关的漏洞,我们也可以去进行尝试
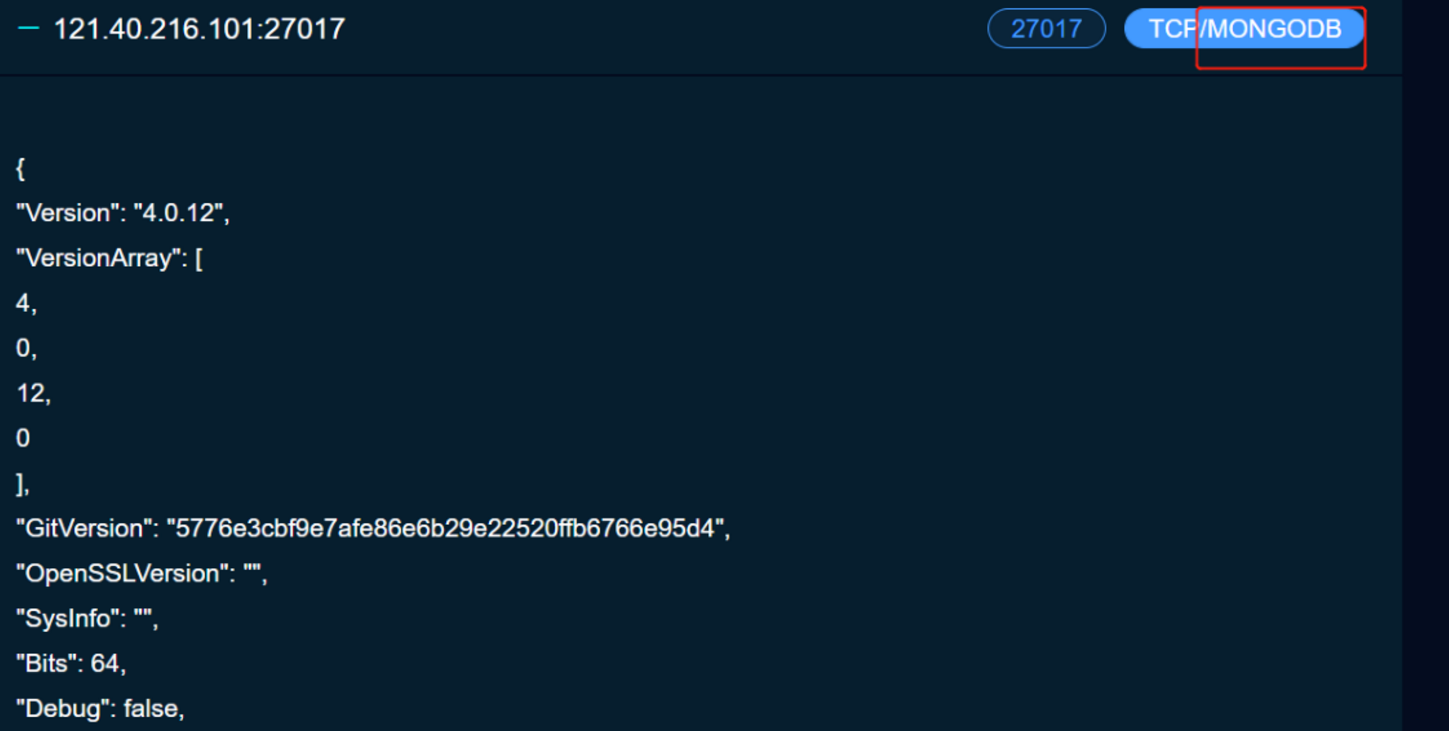
这个地方又可以成为一个攻击点
其他端口也类似,端口代表着服务,有服务就代表可能存在相应的服务的漏洞
我们就可以先记录下来,然后最后统一对各个点进行攻击。
我们还可以搜索它的目录站点、子域名站点、旁注/C段站点进一步扩大我们的攻击面【利用工具:7kbScan御剑扫描、Layer子域名挖掘机、同IP站点查询】
最后讲一下类似域名怎么找?
利用接口查,第一步就是查备案信息【需要VIP】
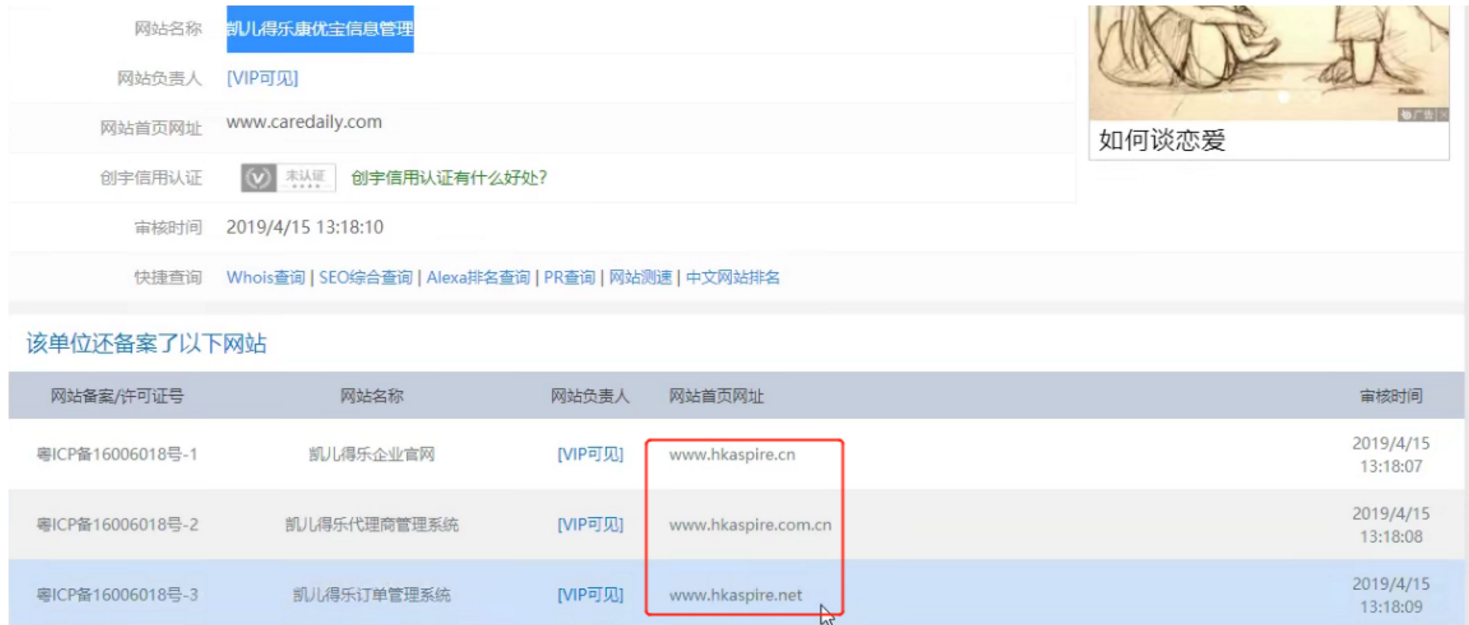
然后我们就新获得了几个域名
http://hkaspire.net/ 和 https://hkaspire.cn/
在 http://hkaspire.net/ 这个网站我们发现这里可以点击,点击之后跳转到一个新的页面 http://hkaspire.net:8080/login
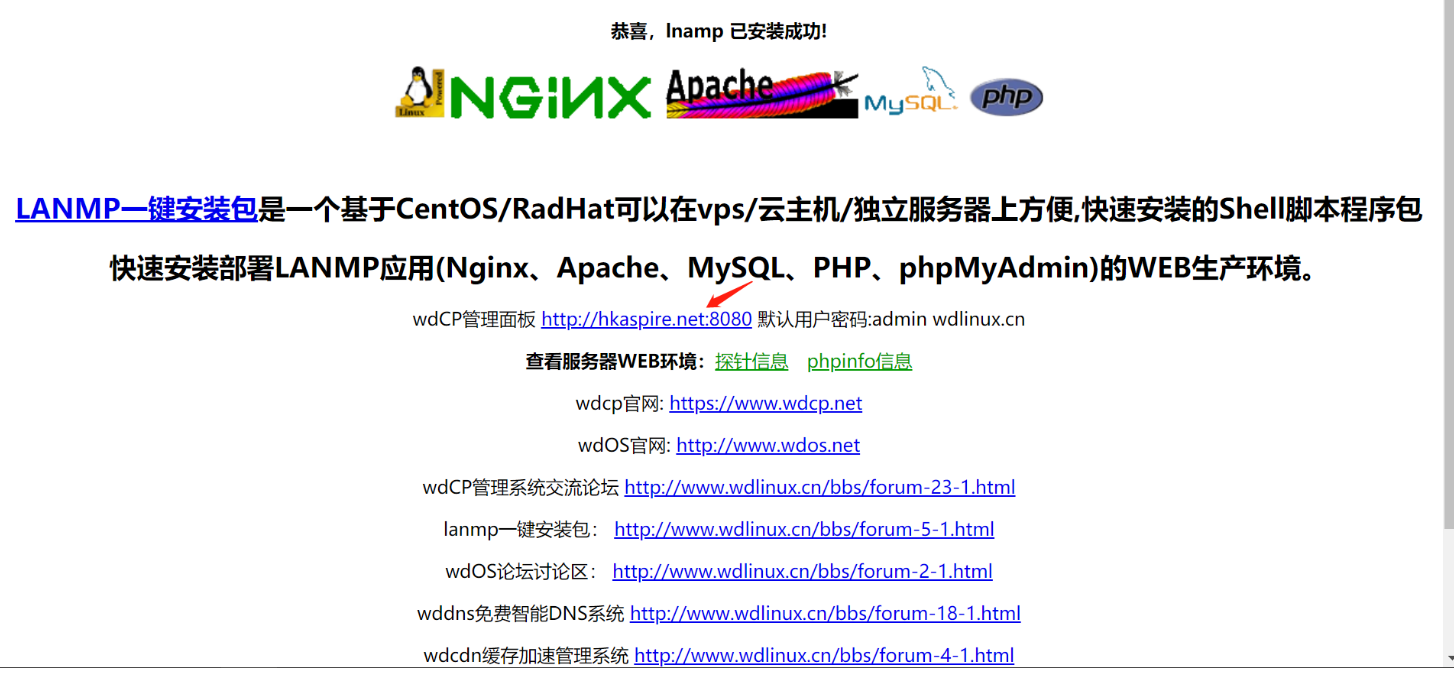
这其实也是可以成为一个攻击面的
他这里其实还暴露了很多,类似于探针信息,phpinfo信息
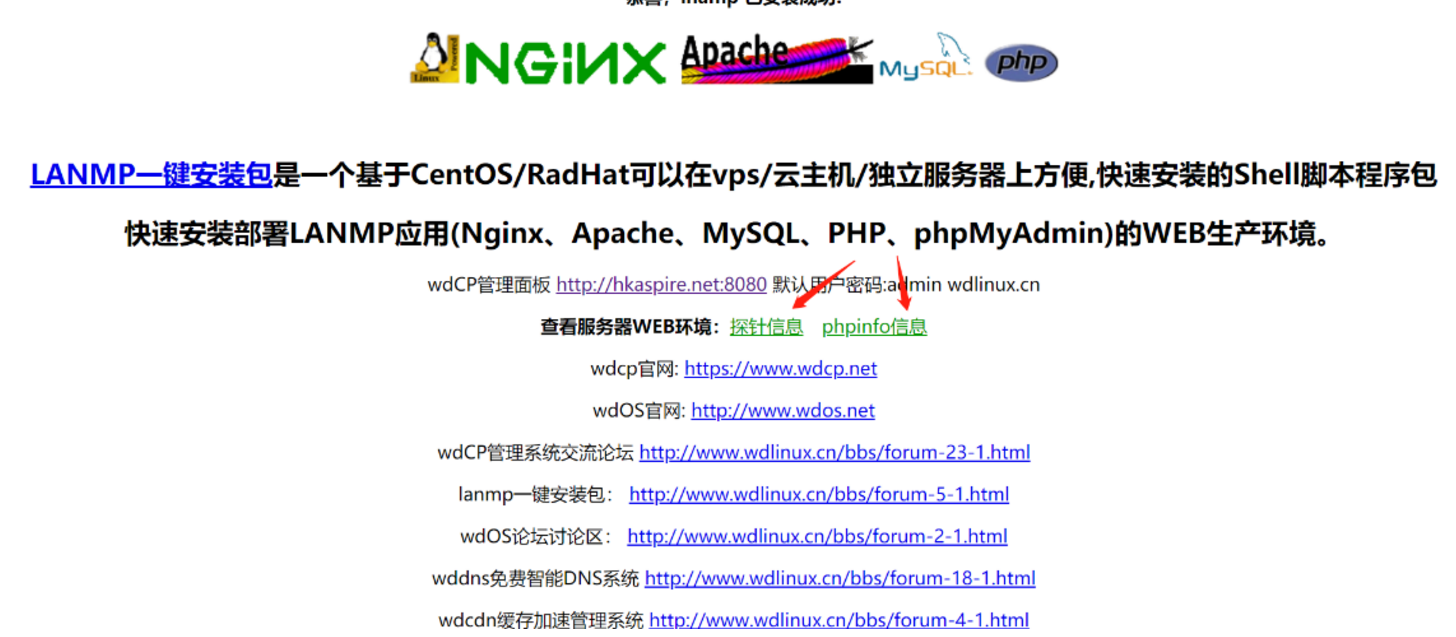
针对这个WDCP登陆系统,我们也可以直接在网上搜漏洞,进行漏洞测试
针对这个 https://hkaspire.cn/ 网站,这也是个系统,我们也可以进行漏洞测试

与此同时,这个域名https://hkaspire.cn/也涉及到新的IP地址,我们也可以针对这个IP地址进行测试【进行fofa的搜索】
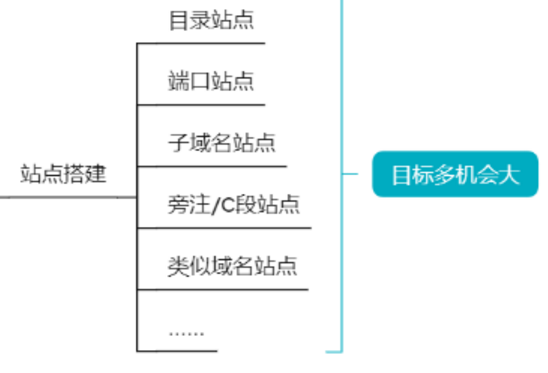
所以能做的事情是很多的
这样还没完,我们可以拿这种网站的标题去百度|谷歌搜索
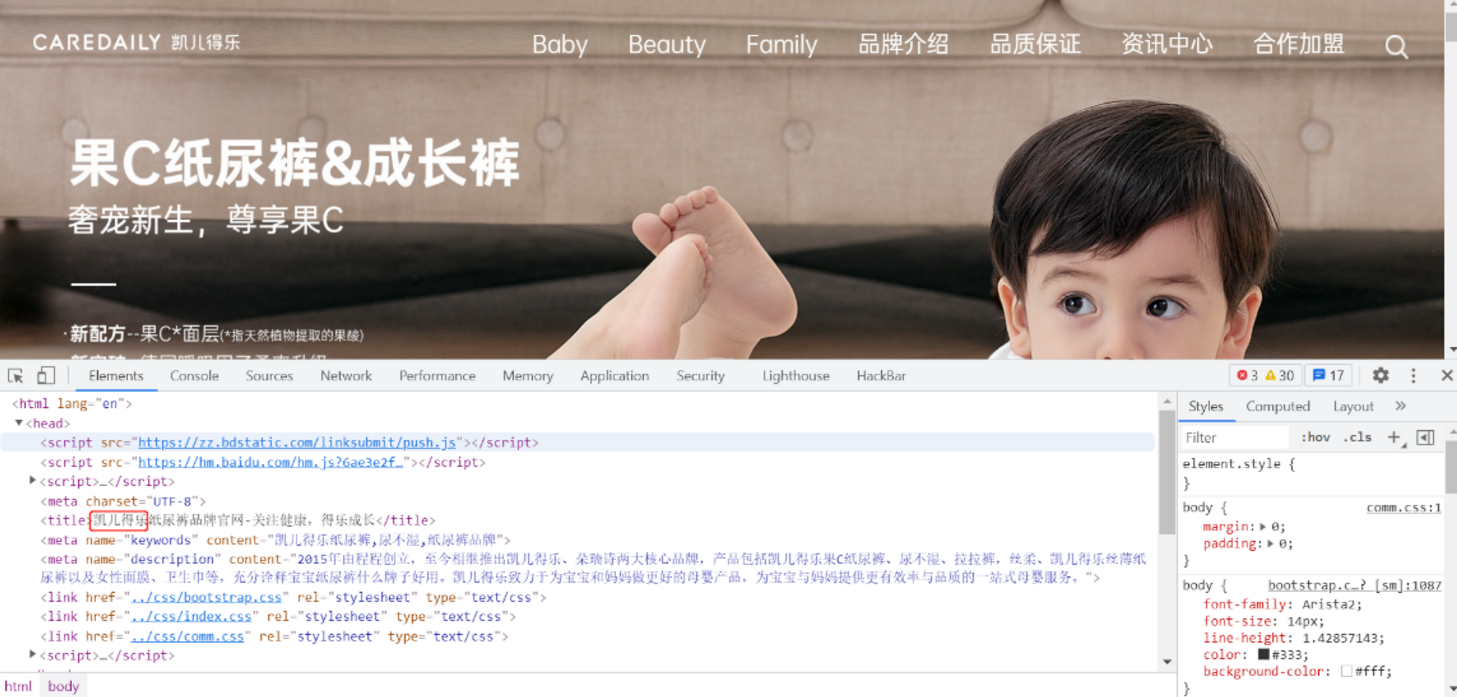
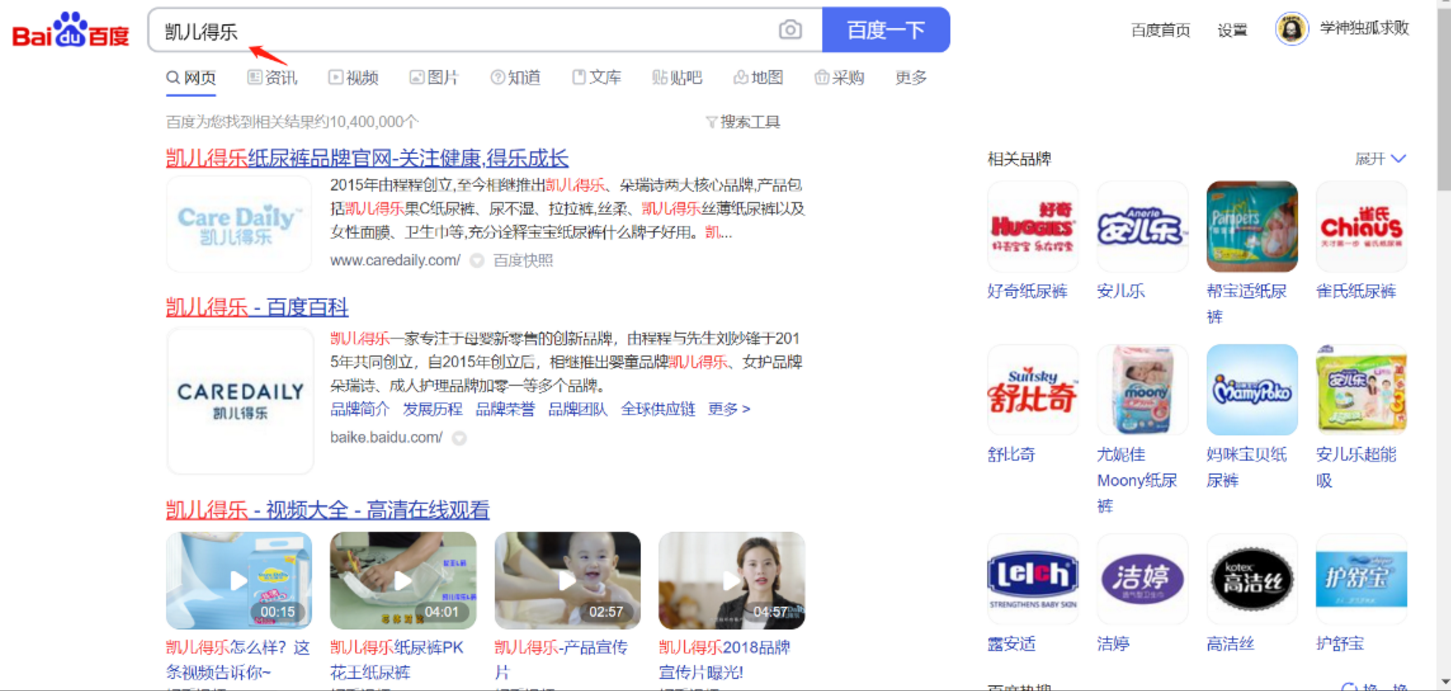
像是域名差不多的都可以进行测试
我们还可以去搜索域名的关键字【尽量用Google去搜索】
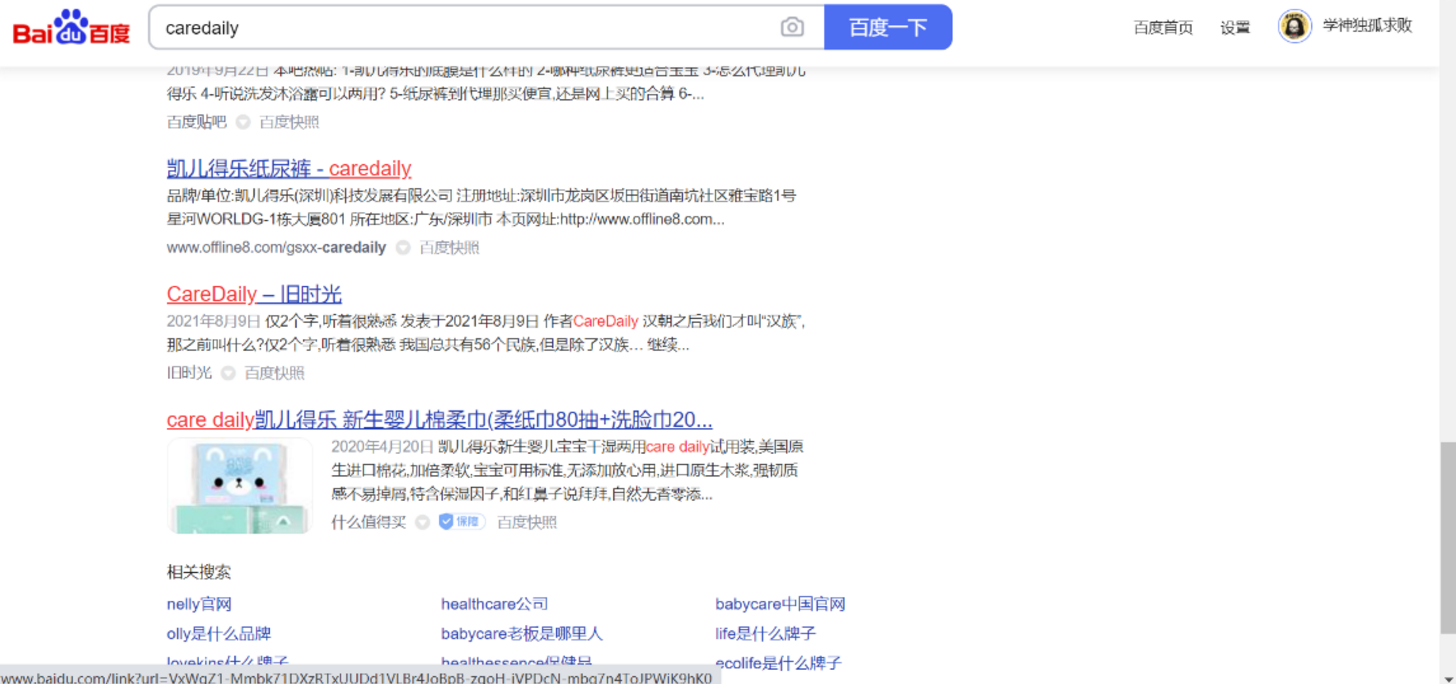
这个是我们通过谷歌搜到的 http://caredaily.xyz/

我们查看其robots.txt可以查到其一些路径
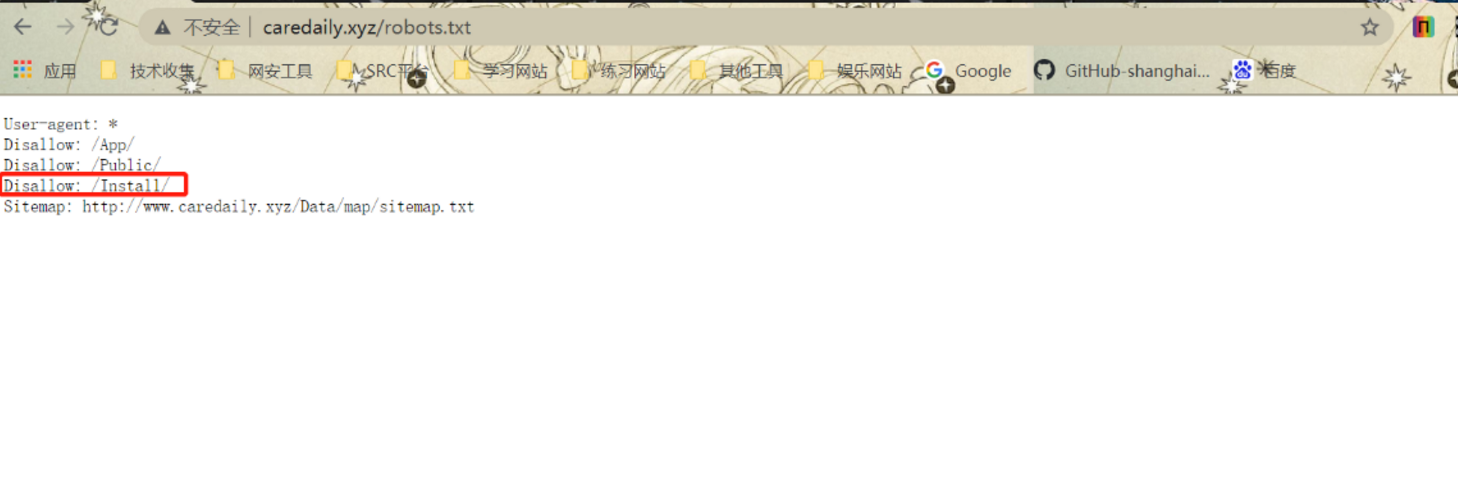
我们进这个Install看看
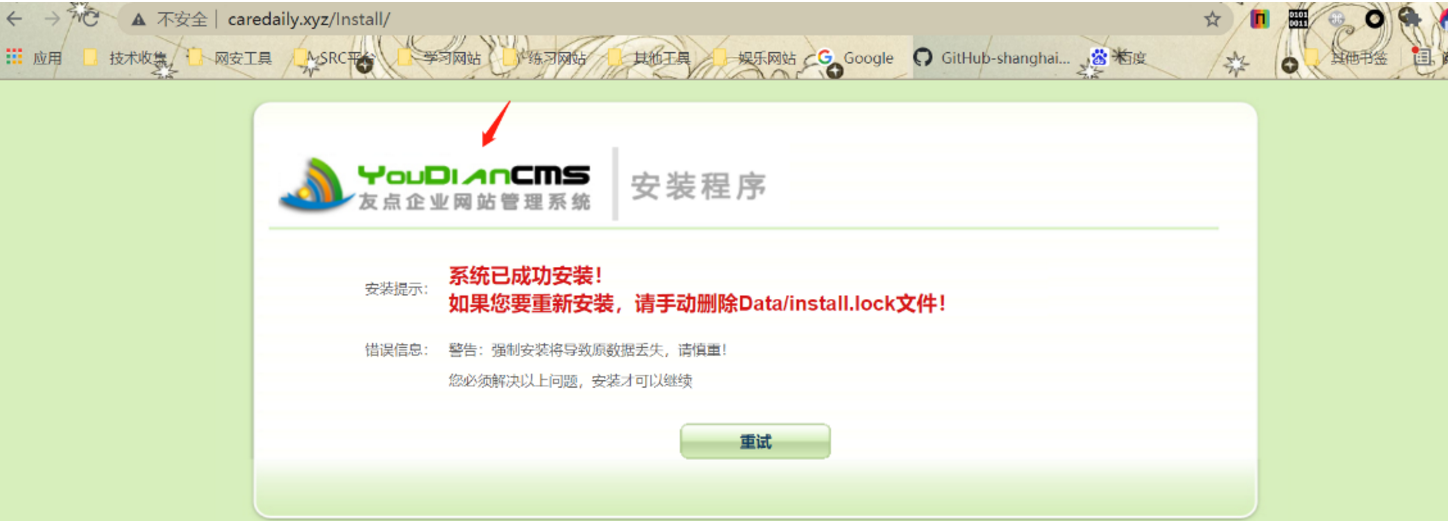
然后我们就又可以去百度搜索youdiancms漏洞
这搜到的信息已经足够多了,而且我们每个得到的域名对应的每个IP,每个端口都要扫,我们会拿到相当多信息,足够我们进行渗透测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号