字符编码
文本编辑器存取文件的原理
1.打开编辑器就启动了一个进程,是在内存中的,所以用编辑器编写的内容也都是存放在内存中的,断电后数据丢失。
2.要想永久保存,需要点击保存按钮,编辑器把内存的数据存到了硬盘上。
3.在我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
python解释器与文件本编辑的异同
相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样。
不同点:文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法,而python解释器将文件内容读入内存后,会识别(语法)和执行python代码。
字符编码
最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系,最多只能用8位来表示(一个字节),即2**8=256,所以ASCII码最多只能表示256个符号。
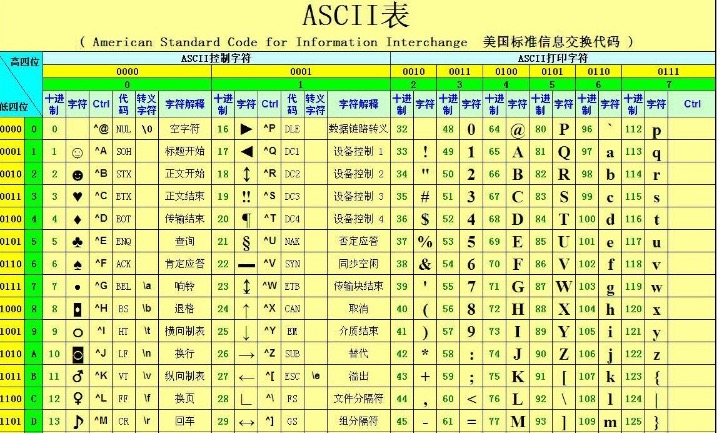

我们国家规定了自己的标准gb2312编码,规定了包含中文在内的字符与数字的对应关系。日本人规定了自己的Shift_JIS编码,韩国人规定了自己的Euc_kr编码,各个国家都有自己的编码,那这时候就必须统一编码了,于是Unicode应运而生。
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 01001110 00101101 |
Unicode编码包含了所有国家的编码,而UTF-8是Unicode编码的延申,是为了节省内存空间。
乱码分析
首先明确概念:
- 文件从内存到硬盘的操作简称存文件
- 文件从硬盘到内存的操作简称读文件
乱码的两种情况:
1.存文件时就已经乱码
存文件时,由于文件内有各个国家的文字,我们单以shift_js编码去存,本质上其他国家的文字由于在shift_js中没有找到对应关系而导致存储失败。当我们硬要存的时候,编辑并不会报错,但毫无疑问,不能存而硬存,肯定是乱存了,即存文件阶段就已经发生乱码,当我们用shift_js打开文件时,日文可以正常显示,而中文则乱码了。
2.存文件时不乱码而读文件时乱码
存文件时用utf-8编码,保证兼容万国,不会乱码,而读文件时选择了错误的解码方式,比如gbk,则在读阶段发生乱码,读阶段发生乱码是可以解决的,选择正确的解码方式就好了。
总结:
1.保证不乱码的核心法则就是,字符按照什么标准编码的,就要按照什么标准解码,此处的标准是指字符编码。
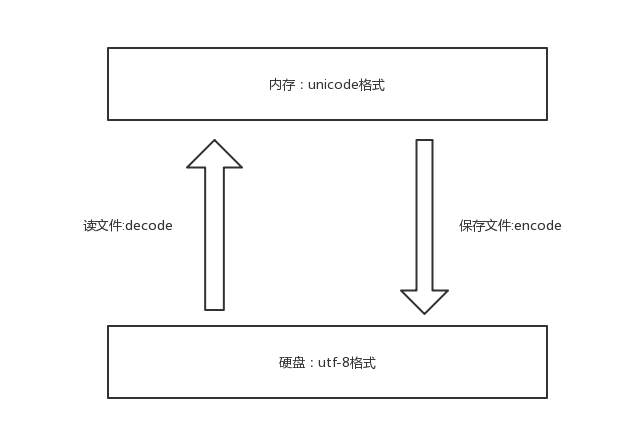
2.在内存中写的所有字符,一视同仁,都是Unicode编码,比如我们打开编辑器,输入一个“你”,我们不能说“你”就是一个汉字,此时它仅仅只是一个符号,该符号可能有很多国家都在使用,根据我们使用的输入法不同这个字的样式可能也不太一样。只有在我们往硬盘保存或者基于网络传输时,才能确定“你”到底是一个汉字,还是一个日本字,这就是Unicode转换成其他编码格式的过程了。简而言之,就是内存中固定使用的就是Unicode编码,我们唯一能改变的就是储存到硬盘时使用的编码。
- Unicode---->encode(编码)---->gbk
- Unicode---->decode(解码)<----gbk

 浙公网安备 33010602011771号
浙公网安备 33010602011771号