
数据采集与融合技术作业1
- 作业①:
- 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
- 输出信息:
|
排名 |
学校名称 |
省市 |
学校类型 |
总分 |
|
1 |
清华大学 |
北京 |
综合 |
852.5 |
|
2...... |
代码如下:
import urllib.request import bs4 from bs4 import BeautifulSoup def getHTMLText(url): url = "http://www.shanghairanking.cn/rankings/bcur/2020" try: req = urllib.request.Request(url)#访问url网址 data = urllib.request.urlopen(req)#读取数据 data = data.read().decode() return data except Exception as err: print(err) def fillUnivList(list, html): soup = BeautifulSoup(html, "html.parser") for tr in soup.find('tbody').children: if isinstance(tr,bs4.element.Tag): a = tr('a')#定义一个列表a存放学校名称 tds = tr('td')#定义列表存放学校信息 list.append([tds[0].text.strip(), a[0].string.strip(), tds[2].text.strip(), tds[3].text.strip(), tds[4].text.strip()]) #打印输出结果 def printUnivList(list1, num): tplt = "{0: ^10}\t{1: ^10}\t{2: ^12}{3: ^10}\t{4: ^10}" print(tplt.format("排名","学校名称","省份","学校类型","总分")) for i in range(num): u = list1[i] print(tplt.format(u[0], u[1], u[2], u[3], u[4])) print() print("以上共有记录" + str(num) + "条。") #主函数main def main(): list = [] url = "https: // www.shanghairanking.cn / rankings / bcur / 2020" html = getHTMLText(url) fillUnivList(list, html) printUnivList(list, 22) main()
输出结果截图如下:
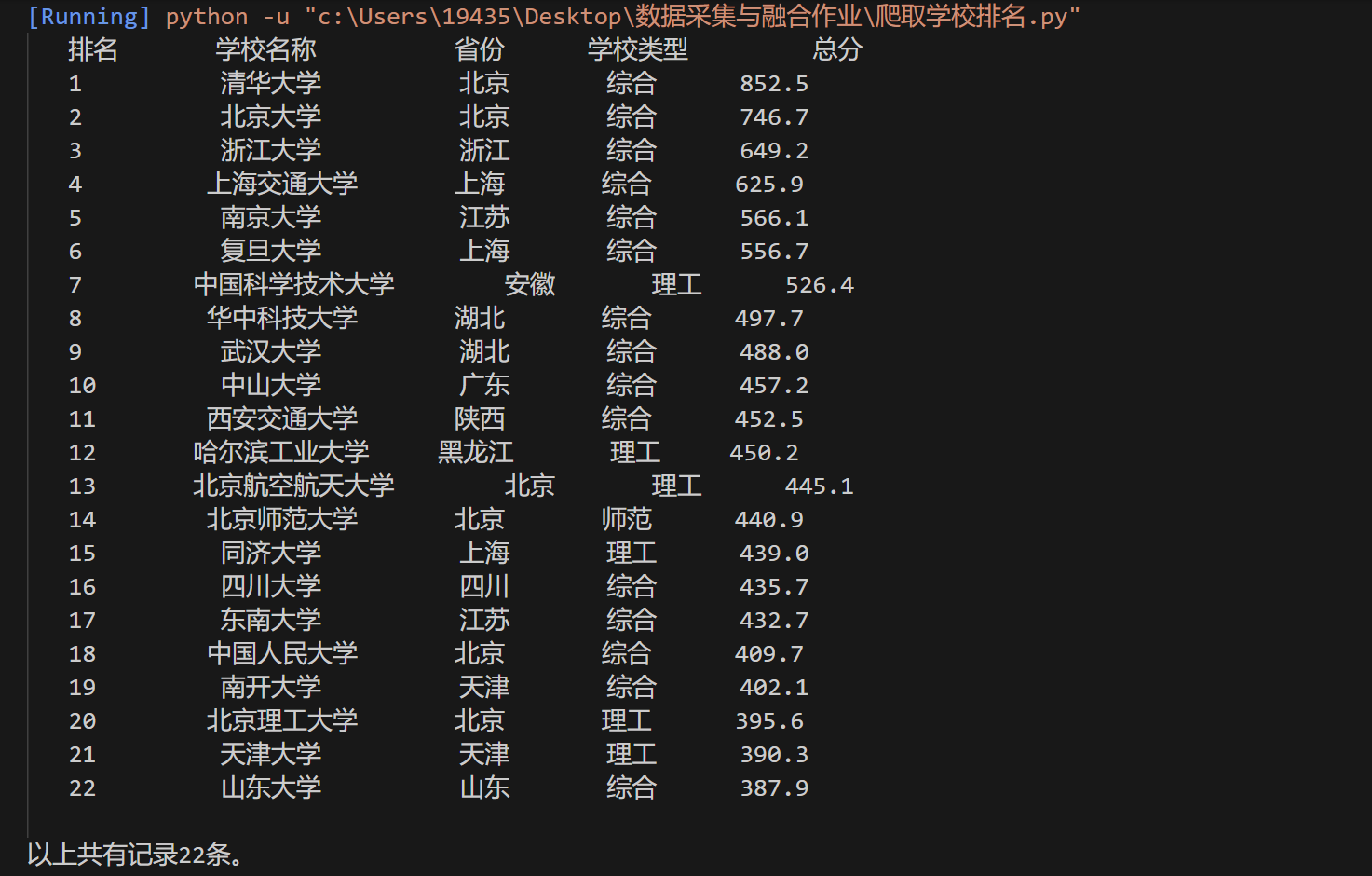
心得:
因为是重新使用vscode完成python,导致中文输出乱码,查找了好多办法都没用,将文件改成gbk格式又会出现新的报错,后来参考了 https://blog.csdn.net/didi_ya/article/details/107883798 的方法一才得以解决。
这份代码本来是从网上查找得到的,后来在几次作业之后才慢慢理解了。
- 作业②:
- 要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
- 输出信息:
代码如下:
import requests from bs4 import BeautifulSoup from pprint import pprint import io import sys import urllib.request sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码 url="http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input" headers={ "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.36" } resp=requests.get(url,headers=headers).text soup=BeautifulSoup(resp,'lxml') data_list=soup.select('ul[class="bigimg cloth_shoplist"] li') data=[] for li in data_list: name=li.a.attrs['title'] price=li.select('p[class="price"] span')[0].text data.append((name,price)) pprint(data)
输出结果如下(后面还有很长一串):
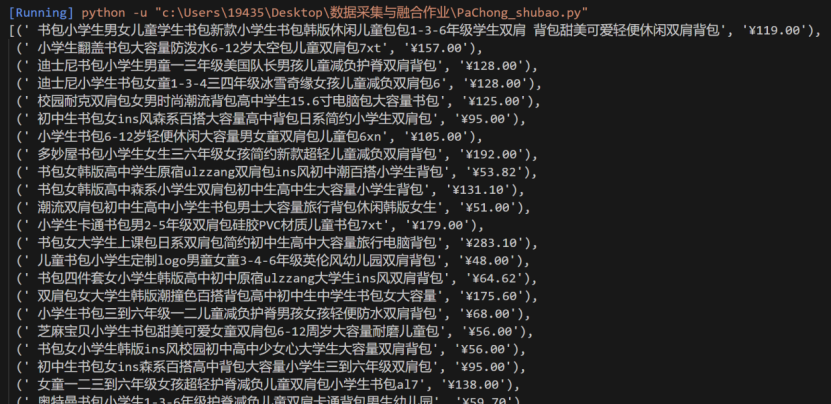
心得:
在这次写代码的过程中遇到了很多问题。首先是老师教会了我用headers规避反爬。然后在同学的帮助下查看网页的信息,找到需要爬取页面所在的相似之处,来完成代码的构造。
代码在完成的过程中也出现了很多问题,因为pycharm用不了了,只能在vscode上运行,导致需要重新下载python库。
然后紧接着又出现了一下问题:

查询了csdn发现是print的格式可能出现了问题,后来在代码头加入了以下代码才解决:
import io import sys import urllib.request sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
- 作业③:
- 要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm )或者自选网页的所有JPEG和JPG格式文件
- 输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
代码如下:
import requests from bs4 import BeautifulSoup from fake_useragent import UserAgent url = "https://xcb.fzu.edu.cn/info/1071/4481.htm" headers = { 'User-Agent':UserAgent().chrome } response = requests.get(url,headers) # print(response) soup = BeautifulSoup(response.text,'lxml') imgs = soup.find_all('img',attrs={'width':'600'}) # print(imgs) img_address = [] for img in imgs: picture_address = "https://xcb.fzu.edu.cn"+img['src'] img_address.append(picture_address) # print(img_address) for i in range(len(img_address)): res = requests.get(img_address[i],headers) with open(f".\picture{i+1}.jpg","wb") as f: f.write(res.content) print(f"第{i+1}副图片下载完毕")
输出结果如下:

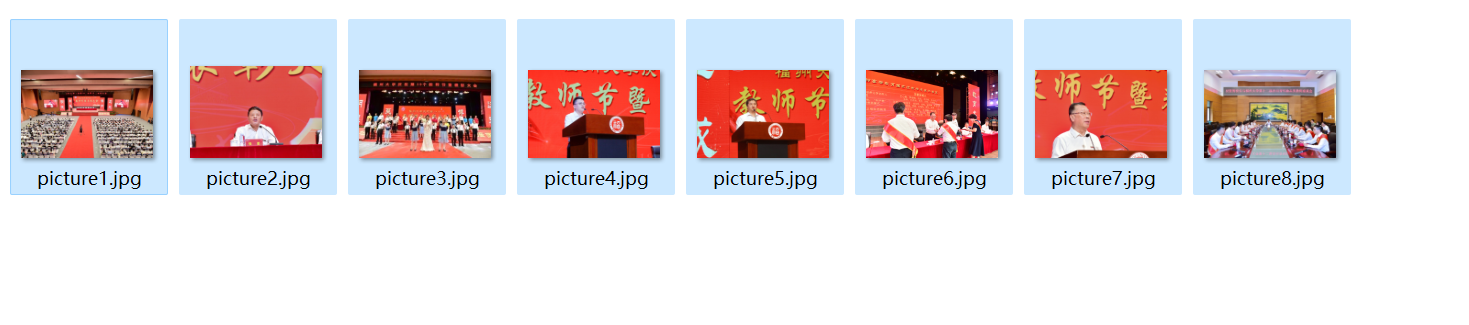
心得:
在这份代码中,我学会了如何查看土拍你所在地址,并会打开图片查看需要在前面加的头地址(因为在f12中的图片rul和网页中的不同),也学会了如何循环打开并输出图片。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号