
Python 爬虫入门实例(爬取小米应用商店的top应用apk)
一,爬虫是什么?
爬虫就是获取网络上各种资源,数据的一种工具。具体的可以自行百度。
二,如何写简单爬虫
1,获取网页内容
可以通过 Python(3.x) 自带的 urllib,来实现网页内容的下载。实现起来很简单
import urllib.request url="http://www.baidu.com" response=urllib.request.urlopen(url) html_content=response.read()
还可以使用三方库 requests ,实现起来也非常方便,在使用之前当然你需要先安装这个库:pip install requests 即可(Python 3以后的pip非常好使)
import requests html_content=requests.get(url).text
2, 解析网页内容
获取的网页内容html_content,其实就是html代码,我们需要对其进行解析,获取我们所需要的内容。
解析网页的方法有很多,这里我介绍的是BeautifullSoup,由于这是一个三方库,在使用前 还是要先安装 :pip install bs4
form bs4 imort BeautifullSoup soup= BeautifullSoup(html_content, "html.parser")
更多使用方法请参考官方文档:http://beautifulsoup.readthedocs.io/zh_CN/latest/
三,实例分析
弄懂爬虫原理的最好办法,就是多分析一些实例,爬虫千变万化,万变不离其宗。废话少说上干货。
===================================我是分割线===================================================
需求:爬取小米应用商店的TOP n 应用
通过浏览器打开小米应用商店排行棒页面,F12审查元素
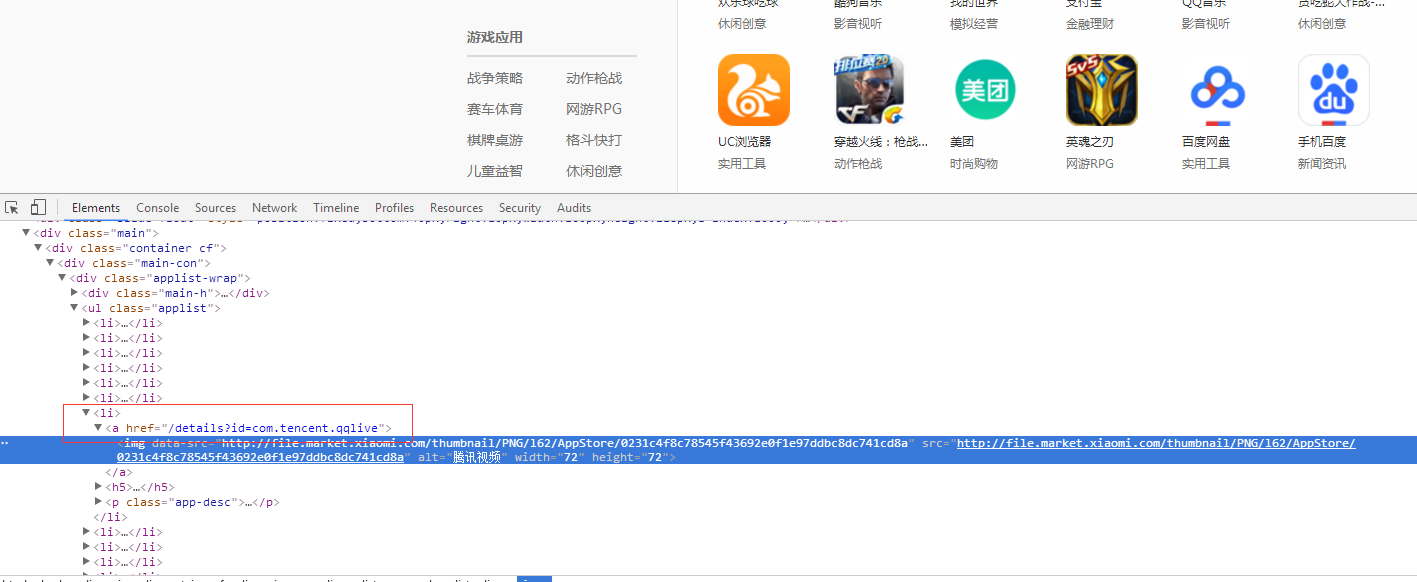
#coding=utf-8 import requests
import re from bs4 import BeautifullSoup def parser_apks(self, count=0): '''小米应用市场''' _root_url="http://app.mi.com" #应用市场主页网址 res_parser={} page_num=1 #设置爬取的页面,从第一页开始爬取,第一页爬完爬取第二页,以此类推 while count:
#获取排行榜页面的网页内容 wbdata = requests.get("http://app.mi.com/topList?page="+str(page_num)).text print("开始爬取第"+str(page_num)+"页")
#解析页面内容获取 应用下载的 界面连接 soup=BeautifulSoup(wbdata,"html.parser") links=soup.body.contents[3].find_all("a",href=re.compile("/details?"), class_ ="", alt="") #BeautifullSoup的具体用法请百度一下吧。。。 for link in links: detail_link=urllib.parse.urljoin(_root_url, str(link["href"])) package_name=detail_link.split("=")[1]
#在下载页面中获取 apk下载的地址 download_page=requests.get(detail_link).text soup1=BeautifulSoup(download_page,"html.parser") download_link=soup1.find(class_="download")["href"] download_url=urllib.parse.urljoin(_root_url, str(download_link))
#解析后会有重复的结果,下面通过判断去重 if download_url not in res_parser.values(): res_parser[package_name]=download_url count=count-1 if count==0: break if count >0: page_num=page_num+1 print("爬取apk数量为: "+str(len(res_parser))) return res_parser
def craw_apks(self, count=1, save_path="d:\\apk\\"): res_dic=parser_apks(count) for apk in res_dic.keys(): print("正在下载应用: "+apk) urllib.request.urlretrieve(res_dic[apk],save_path+apk+".apk") print("下载完成")
if __name__=="__main__":
craw_apks(10)
运行结果:
开始爬取第1页 爬取apk数量为: 10 正在下载应用: com.tencent.tmgp.sgame
下载完成
.
.
.
以上就是简单爬虫的内容,其实爬虫的实现还是很复杂的,不同的网页有不同的解析方式,还需要深入学习。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号