scrapy-中间件
https://www.jianshu.com/nb/16039443
https://www.cnblogs.com/xieqiankun/p/know_middleware_of_scrapy_1.html
scrapy 中间件
Scrapy中有两种中间件:下载器中间件(Downloader Middleware)和爬虫中间件(Spider Middleware)
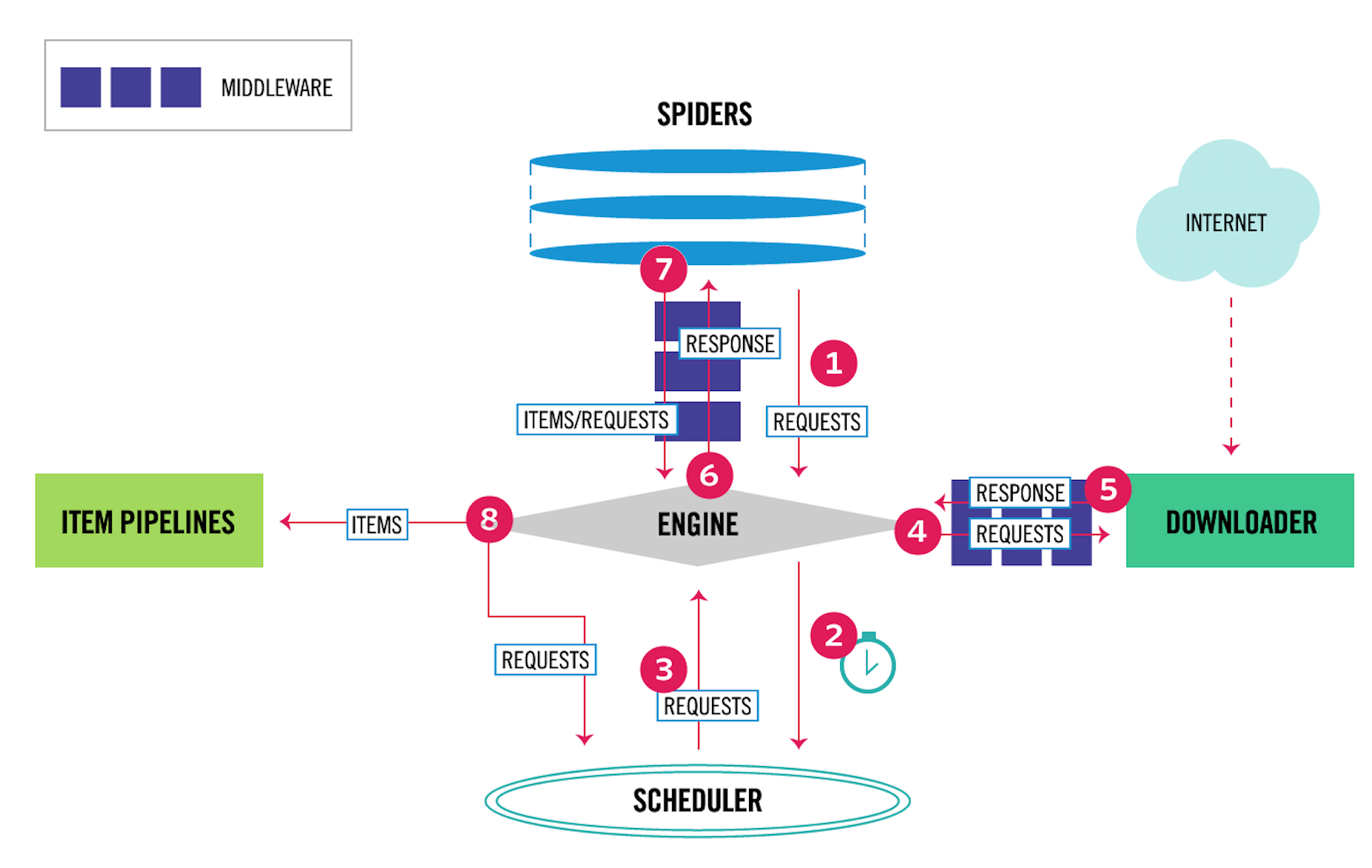
其中,4、5表示下载器中间件,6、7表示爬虫中间件。爬虫中间件会在以下几种情况被调用。
- 当运行到
yield scrapy.Request()或者yield item的时候,爬虫中间件的process_spider_output()方法被调用。 - 当爬虫本身的代码出现了
Exception的时候,爬虫中间件的process_spider_exception()方法被调用。 - 当爬虫里面的某一个回调函数
parse_xxx()被调用之前,爬虫中间件的process_spider_input()方法被调用。 - 当运行到
start_requests()的时候,爬虫中间件的process_start_requests()方法被调用。
下载器中间件
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量、底层的系统。
中间件的一般作用是: 更换代理IP,更换Cookies,更换User-Agent,自动重试
没有中间件:
有了中间件
下载器中间件的class
class Scrapy.downloadermiddleares.DownloaderMiddleware
该类的方法:process_request(request, spider)
当每个Request对象经过下载中间件时会被调用,优先级越高的中间件,越先调用;该方法应该返回以下对象:None/Response对象/Request对象/抛出IgnoreRequest异常;
- 返回
None:scrapy会继续处理request,执行其他中间件相应的方法; - 返回
Response对象:scrapy不会再调用其他中间件的process_request方法,也不会去发起下载,而是直接返回该Response对象;已安装的中间件的 process_response() 方法则会在每个response返回时被调用 - 返回
Request对象:scrapy不会再调用其他中间件的process_request()方法,而是将其返回的Request放置调度器待调度下载; - 抛出
IgnoreRequest异常:如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)
参数:
request(Request 对象)–处理的request
spider(Spider 对象)–该request对应的spider
process_response(request, response, spider)
当每个Response经过下载中间件会被调用,优先级越高的中间件,越晚被调用,与process_request()相反;该方法返回以下对象:Response对象/Request对象/抛出IgnoreRequest异常。
- 返回
Response对象:如果其返回一个 Response (可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理 - 返回
Request对象:如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样 - 抛出
IgnoreRequest异常:`如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)
参数:
request (Request 对象) – response所对应的request
response (Response 对象) – 被处理的response
spider (Spider 对象) – response所对应的spider
process_exception(request, exception, spider)
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常(包括IgnoreRequest异常)时,Scrapy调用 process_exception() ,应该返回以下对象:None/Response对象/Request对象;
- 如果返回
None:如果其返回 None ,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的 process_exception() 方法,直到所有中间件都被调用完毕,则调用默认的异常处理 - 如果返回
Response对象:如果其返回一个 Response 对象,则已安装的中间件链的 process_response() 方法被调用。Scrapy将不会调用任何其他中间件的 process_exception() 方法 - 如果返回
Request对象:如果其返回一个 Request 对象, 则返回的request将会被重新调用下载。这将停止中间件的 process_exception() 方法执行,就如返回一个response的那样。
参数:
request (是 Request 对象) – 产生异常的request
exception (Exception 对象) – 抛出的异常
spider (Spider 对象) – request对应的spider
from_crawler(cls, crawler)
如果存在该函数,from_crawler会被调用使用crawler来创建中间器对象,必须返回一个中间器对象,通过这种方式,可以访问到crawler的所有核心部件,如settings、signals等
下载中间件的开发:
1, 代理
代理设置来源于setting.py
middlewares.py
import random
from scrapy.conf import settings
class ProxyMiddleware(object):
def process_request(self, request, spider):
proxy = random.choice(settings['PROXIES'])
request.meta['proxy'] = proxy #设置中间代理的方法
setting.py 里配置:
PROXIES = ['https://114.217.243.25:8118',
'https://125.37.175.233:8118',
'http://1.85.116.218:8118']
激活, settings.py 配置
DOWNLOADER_MIDDLEWARES = {
'AdvanceSpider.middlewares.ProxyMiddleware': 543,
}
关于启用的优先级:
启用是字典模式,字典的Key就是用点分隔的中间件路径,后面的数字表示这种中间件的顺序.
由于中间件是按顺序运行的,因此如果遇到后一个中间件依赖前一个中间件的情况,中间件的顺序就至关重要
最后数字的确认:
最简单的办法就是从543开始,逐渐加一,这样一般不会出现什么大问题。如果想把中间件做得更专业一点,那就需要知道Scrapy自带中间件的顺序
默认的下载中间件顺序:
# scrapy/settings/default_settings.py
DOWNLOADER_MIDDLEWARES_BASE = {
# Engine side
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
# Downloader side
}
数字越小的中间件越先执行,例如Scrapy自带的第1个中间件RobotsTxtMiddleware,它的作用是首先查看settings.py中ROBOTSTXT_OBEY这一项的配置是True还是False。如果是True,表示要遵守Robots.txt协议,它就会检查将要访问的网址能不能被运行访问,如果不被允许访问,那么直接就取消这一次请求,接下来的和这次请求有关的各种操作全部都不需要继续了
开发者自定义的中间件,会被按顺序插入到Scrapy自带的中间件中。爬虫会按照从100~900的顺序依次运行所有的中间件。直到所有中间件全部运行完成,或者遇到某一个中间件而取消了这次请求
代理IP 写入数据库直接获取他
2, UA设置
中间件代码
class UAMiddleware(object):
def process_request(self, request, spider):
ua = random.choice(settings['USER_AGENT_LIST'])
request.headers['User-Agent'] = ua
settings.py 里配置ua
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Dalvik/1.6.0 (Linux; U; Android 4.2.1; 2013022 MIUI/JHACNBL30.0)",
"Mozilla/5.0 (Linux; U; Android 4.4.2; zh-cn; HUAWEI MT7-TL00 Build/HuaweiMT7-TL00) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"AndroidDownloadManager",
"Apache-HttpClient/UNAVAILABLE (java 1.4)",
"Dalvik/1.6.0 (Linux; U; Android 4.3; SM-N7508V Build/JLS36C)",
"Android50-AndroidPhone-8000-76-0-Statistics-wifi",
"Dalvik/1.6.0 (Linux; U; Android 4.4.4; MI 3 MIUI/V7.2.1.0.KXCCNDA)",
"Dalvik/1.6.0 (Linux; U; Android 4.4.2; Lenovo A3800-d Build/LenovoA3800-d)",
"Lite 1.0 ( http://litesuits.com )",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/5.0 (Linux; U; Android 4.1.1; zh-cn; HTC T528t Build/JRO03H) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30; 360browser(securitypay,securityinstalled); 360(android,uppayplugin); 360 Aphone Browser (2.0.4)",
]
## 启用
DOWNLOADER_MIDDLEWARES = {
'AdvanceSpider.middlewares.ProxyMiddleware': 543,
'AdvanceSpider.middlewares.UAMiddleware': 544,
}
随机用户代理和ip 代理
#middlewares.py
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
from scrapy.exceptions import NotConfigured
from collections import defaultdict
from urllib.parse import urlparse
from faker import Faker #引入Faker,pip install faker下载
import random
class RandomHttpProxyMiddleware(HttpProxyMiddleware):
def __init__(self, auth_encoding='latin-1', proxy_list = None):
if not proxy_list:
raise NotConfigured
self.proxies = defaultdict(list)
for proxy in proxy_list:
parse = urlparse(proxy)
self.proxies[parse.scheme].append(proxy) #生成dict,键为协议,值为代理ip列表
@classmethod
def from_crawler(cls, crawler):
if not crawler.settings.get('HTTP_PROXY_LIST'):
raise NotConfigured
http_proxy_list = crawler.settings.get('HTTP_PROXY_LIST') #从配置文件中读取
auth_encoding = crawler.settings.get('HTTPPROXY_AUTH_ENCODING', 'latin-1')
return cls(auth_encoding, http_proxy_list)
def _set_proxy(self, request, scheme):
proxy = random.choice(self.proxies[scheme]) #随机抽取选中协议的IP
request.meta['proxy'] = proxy
class RandomUserAgentMiddleware(object):
def __init__(self):
self.faker = Faker(local='zh_CN')
self.user_agent = ''
@classmethod
def from_crawler(cls, crawler):
o = cls()
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o
def spider_opened(self, spider):
self.user_agent = getattr(spider, 'user_agent',self.user_agent)
def process_request(self, request, spider):
self.user_agent = self.faker.user_agent() #获得随机user_agent
request.headers.setdefault(b'User-Agent', self.user_agent)
# 启用
#settings.py
#...
DOWNLOADER_MIDDLEWARES = {
'newproject.middlewares.RandomHttpProxyMiddleware': 543,
'newproject.middlewares.RandomUserAgentMiddleware': 550,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware':None,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':None,
}
HTTP_PROXY_LIST = [
'http://193.112.216.55:1234',
'http://118.24.172.34:1234',
]
#...
## 测试spider
#anything.py
# -*- coding: utf-8 -*-
import scrapy
import json
import pprint
class AnythingSpider(scrapy.Spider):
name = 'anything'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/anything']
def parse(self, response):
ret = json.loads(response.text)
pprint.pprint(ret)
内置的中间件
- CookiesMiddleware
该中间件使得爬取需要cookie(例如使用session)的网站成为了可能。 其追踪了web server发送的cookie,并在之后的request中发送回去, 就如浏览器所做的那样。
以下设置可以用来配置cookie中间件:
COOKIES_ENABLED默认为True
COOKIES_DEBUG默认为False
- DefaultHeadersMiddleware
该中间件设置 DEFAULT_REQUEST_HEADERS 指定的默认request header。
- DownloadTimeoutMiddleware
该中间件设置 DOWNLOAD_TIMEOUT 指定的request下载超时时间.
- HttpAuthMiddleware
该中间件完成某些使用 Basic access authentication (或者叫HTTP认证)的spider生成的请求的认证过程。
- HttpCacheMiddleware
该中间件为所有HTTP request及response提供了底层(low-level)缓存支持。 其由cache存储后端及cache策略组成。
- HttpCompressionMiddleware
该中间件提供了对压缩(gzip, deflate)数据的支持
- ChunkedTransferMiddleware
该中间件添加了对 chunked transfer encoding 的支持。
- HttpProxyMiddleware
该中间件提供了对request设置HTTP代理的支持。您可以通过在 Request 对象中设置 proxy 元数据来开启代理。
- RedirectMiddleware
该中间件根据response的状态处理重定向的request。通过该中间件的(被重定向的)request的url可以通过 Request.meta 的 redirect_urls 键找到。
- MetaRefreshMiddleware
该中间件根据meta-refresh html标签处理request重定向。
- RetryMiddleware
该中间件将重试可能由于临时的问题,例如连接超时或者HTTP 500错误导致失败的页面。
爬取进程会收集失败的页面并在最后,spider爬取完所有正常(不失败)的页面后重新调度。 一旦没有更多需要重试的失败页面,该中间件将会发送一个信号(retry_complete), 其他插件可以监听该信号。
- RobotsTxtMiddleware
该中间件过滤所有robots.txt eclusion standard中禁止的request。
确认该中间件及 ROBOTSTXT_OBEY 设置被启用以确保Scrapy尊重robots.txt。
- UserAgentMiddleware
用于覆盖spider的默认user agent的中间件。
要使得spider能覆盖默认的user agent,其 user_agent 属性必须被设置。
- AjaxCrawlMiddleware
根据meta-fragment html标签查找 ‘AJAX可爬取’ 页面的中间件。
spider爬虫中间件
SPIDER_MIDDLEWARES_BASE = {
# Engine side
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500,
'scrapy.spidermiddlewares.referer.RefererMiddleware': 700,
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800,
'scrapy.spidermiddlewares.depth.DepthMiddleware': 900,
# Spider side
}
Python爬虫开发从入门到实战(微课版) https://blog.csdn.net/xiang12835/article/details/89083620
item pipline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理
item pipline 的典型应用:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库或者文件中
编写
每个item pipeline组件是一个独立的Python类,同时必须实现以下方法
process_item(self, item, spider)
- item (Item 对象或者一个dict) – 被爬取的item
- spider (Spider 对象) – 爬取该item的spider
open_spider(self, spider)
- spider (Spider 对象) – 被开启的spider
close_spider(self, spider)
- spider (Spider 对象) – 被关闭的spider
from_crawler(cls, crawler) , 如果给出,这个类方法将会被调用从Crawler创建一个pipeline实例,它必须返回一个pipeline的新的实例,Crawler对象提供了调用scrapy所有的核心组件的权限,比如你可以调用settings里面的设置项。事实上,在后面的学习中,你会发现,这是非常常用的一个方法,你会经常用到
pipline去重
一个用于去重的过滤器,丢弃那些已经被处理过的item。假设我们的item有一个唯一的id,但是我们spider返回的多个item中包含有相同的id,我们就可以使用集合来去重
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
# 生效
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,
'myproject.pipelines.JsonWriterPipeline': 800,
}
保存到文件或数据库
保存到mongodb
import pymongo #别忘了导入这个模块
class FilePipeline(object):
'''
实现保存到txt文件的类,类名这个地方为了区分,做了修改,
当然这个类名是什么并不重要,你只要能区分就可以,
请注意,这个类名待会是要写到settings.py文件里面的。
'''
def process_item(self, item, spider):
with open('cnblog.txt', 'w', encoding='utf-8') as f:
titles = item['title']
links = item['link']
for i,j in zip(titles, links):
f.wrire(i + ':' + j + '\n')
return item
class MongoPipeline(object):
'''
实现保存到mongo数据库的类,
'''
collection = 'cnblog' #mongo数据库的collection名字,随便
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
'''
scrapy为我们访问settings提供了这样的一个方法,这里,
我们需要从settings.py文件中,取得数据库的URI和数据库名称
'''
return cls(
mongo_uri = crawler.settings.get('MONGO_URI'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider): #爬虫一旦开启,就会实现这个方法,连接到数据库
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider): #爬虫一旦关闭,就会实现这个方法,关闭数据库连接
self.client.close()
def process_item(self, item, spider):
'''
每个实现保存的类里面必须都要有这个方法,且名字固定,用来具体实现怎么保存
'''
titles = item['title']
links = item['link']
table = self.db[self.collection]
for i, j in zip(titles, links):
data = {}
data['文章:链接'] = i + ':' + j
table.insert_one(data)
return item
## 修改配置生效
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
#新修改
ITEM_PIPELINES = {
'cnblog.pipelines.FilePipeline': 300, #实现保存到txt文件
'cnblog.pipelines.MongoPipeline': 400, #实现保存到mongo数据库
}
#新添加数据库的URI和DB
MONGO_URI = 'mongodb://localhost:27017' D
MONGO_DB = "cnblog"
文件与图片下载
crapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的 item pipelines . 这些pipeline有些共同的方法和结构(称之为media pipeline)
FilesPipeline和Images Pipeline来保存文件和图片,他们有以下的一些特点:Files Pipeline
- 避免重新下载最近已经下载过的数据
- 指定存储路径
FilesPipeline的典型工作流程如下:
- 在一个爬虫里,你抓取一个项目,把其中图片的URL放入 file_urls 组内。
- 项目从爬虫内返回,进入项目管道。
- 当项目进入 FilesPipeline,file_urls 组内的URLs将被Scrapy的调度器和下载器(这意味着调度器和下载器的中间件可以复用)安排下载,当优先级更高,会在其他页面被抓取前处理。项目会在这个特定的管道阶段保持“locker”的状态,直到完成文件的下载(或者由于某些原因未完成下载)。
- 当文件下载完后,另一个字段(files)将被更新到结构中。这个组将包含一个字典列表,其中包括下载文件的信息,比如下载路径、源抓取地址(从 file_urls 组获得)和图片的校验码(checksum)。 files 列表中的文件顺序将和源 file_urls 组保持一致。如果某个图片下载失败,将会记录下错误信息,图片也不会出现在 files 组中。
Images Pipeline
- 避免重新下载最近已经下载过的数据
- 指定存储路径
- 将所有下载的图片转换成通用的格式(JPG)和模式(RGB)
- 缩略图生成
- 检测图像的宽/高,确保它们满足最小限制
和FilesPipeline类似,除了默认的字段名不同,image_urls保存图片URL地址,images保存下载后的图片信息
启用Media Pipline
# 同时启用图片和文件管道
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
'scrapy.pipelines.files.FilesPipeline': 2,
}
FILES_STORE = 'D:' # 文件存储路径
IMAGES_STORE = 'D' # 图片存储路径
# 避免下载最近90天已经下载过的文件内容
FILES_EXPIRES = 90
# 避免下载最近90天已经下载过的图像内容
IMAGES_EXPIRES = 30
# 设置图片缩略图
IMAGES_THUMBS = {
'small': (50, 50),
'big': (250, 250),
}
# 图片过滤器,最小高度和宽度,低于此尺寸不下载
IMAGES_MIN_HEIGHT = 110
IMAGES_MIN_WIDTH = 110
当你启用media pipeline以后,
它的默认命名方式是这样的,文件以它们URL的 SHA1 hash 作为文件名。
例如,
对下面的图片URL:http://www.example.com/image.jpg,
其SHA1 hash 值为:3afec3b4765f8f0a07b78f98c07b83f013567a0a
将被下载并存为下面的文件:<IMAGES_STORE>/full/3afec3b4765f8f0a07b78f98c07b83f013567a0a.jpg
其中,<IMAGES_STORE> 是定义在 IMAGES_STORE 设置里的文件夹,我们设置的是D盘,full 是用来区分图片和缩略图(如果使用的话)的一个子文件夹,这个文件夹scrapy会自动生成
扩展Media Pipline
以ImagesPipeline为例来自定义ImagesPipeline,需要重写以下两个方法
-
get_media_requests(item, info)
在工作流程中可以看到,管道会得到图片的URL并从项目中下载。为了这么做,你需要重写 get_media_requests() 方法,并对各个图片URL返回一个Request:def get_media_requests(self, item, info): for image_url in item['image_urls']: yield scrapy.Request(image_url)这些请求将被管道处理,当它们完成下载后,结果将以2元素的元组列表形式传送到 item_completed() 方法: 每个元组包含 (success, file_info_or_error):
-
success 是一个布尔值,当图片成功下载时为 True ,因为某个原因下载失败为False
-
file_info_or_error 是一个包含下列关键字的字典(如果成功为 True )或者出问题时为 Twisted Failure 。
url - 文件下载的url。这是从 get_media_requests() 方法返回请求的url。
path - 图片存储的路径(类似 IMAGES_STORE)
checksum - 图片内容的 MD5 hash
item_completed() 接收的元组列表需要保证与 get_media_requests() 方法返回请求的顺序相一致。下面是 results 参数的一个典型值[(True, {'checksum': '2b00042f7481c7b056c4b410d28f33cf', 'path': 'full/0a79c461a4062ac383dc4fade7bc09f1384a3910.jpg', 'url': 'http://www.example.com/files/product1.jpg'}), (False, Failure(...))]该方法 必须返回每一个图片的URL
-
-
item_completed(results, items, info)
当一个单独项目中的所有图片请求完成时,例如,item里面一共有10个URL,那么当这10个URL全部下载完成以后,ImagesPipeline.item_completed() 方法将被调用。默认情况下, item_completed() 方法返回item。
使用ImagesPipeline下载图片
创建一个项目
-
item
import scrapy class JiandanItem(scrapy.Item): image_urls = scrapy.Field()#图片的链接 images = scrapy.Field() -
jiandan_spider.py 提取每一个图片url
import scrapy from jiandan.items import JiandanItem class jiandanSpider(scrapy.Spider): name = 'jiandan' start_urls = ["http://jandan.net/ooxx"] def parse(self, response): item = JiandanItem() item['image_urls'] = response.xpath('//img//@src').extract() #提取图片链接 yield item -
settings.py
BOT_NAME = 'jiandan' SPIDER_MODULES = ['jiandan.spiders'] NEWSPIDER_MODULE = 'jiandan.spiders' DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36", } ITEM_PIPELINES = { 'jiandan.pipelines.JiandanPipeline':1, } IMAGES_STORE='H:\\jiandan' IMAGES_THUMBS = { 'small': (50, 50), 'big': (200, 200), } -
pipelinse.py
import scrapy from scrapy.exceptions import DropItem from scrapy.pipelines.images import ImagesPipeline #内置的图片管道 class JiandanPipeline(ImagesPipeline):#继承ImagesPipeline这个类 def get_media_requests(self, item, info): for image_url in item['image_urls']: image_url = "http://" + image_url yield scrapy.Request(image_url) def item_completed(self, results, item, info): image_paths = [x['path'] for ok, x in results if ok] if not image_paths: raise DropItem("Item contains no images") return item

 浙公网安备 33010602011771号
浙公网安备 33010602011771号