Kafka学习笔记
Kafka学习笔记
一、Kafka快速入门
1、安装部署
1.1集群规划
| 服务器1 | 服务器2 | 服务器3 |
|---|---|---|
| Zookeeper | Zookeeper | Zookeeper |
| kafka | kafka | kafka |
1.2集群部署
1)解压安装包
[gaocl@hadoop102 software]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module/
2)修改解压后的文件名称
[gaocl@hadoop102 module]$ mv kafka_2.11-0.11.0.0/ kafka
3)在/opt/module/kafka目录下创建logs文件夹
[gaocl@hadoop102 kafka]$ mkdir logs
4)修改配置文件
[gaocl@hadoop102 kafka]$ cd config/
[gaocl@hadoop102 config]$ vi server.properties
输入以下内容:
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
5)配置环境变量
[gaocl@hadoop102 module]$ sudo vi /etc/profile
\#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[gaocl@hadoop102 module]$ source /etc/profile
6)分发安装包
[gaocl@hadoop102 module]$ xsync kafka/
注意:分发之后记得配置其他机器的环境变量
分发脚本
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径 –P指向实际物理地址,防止软连接
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=102; host<105; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
7)分别在hadoop103和hadoop104上修改配置文件/opt/module/kafka/config/server.properties中的broker.id=1、broker.id=2
注:broker.id不得重复
8)启动集群
依次在hadoop102、hadoop103、hadoop104节点上启动kafka
[gaocl@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[gaocl@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[gaocl@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
9)关闭集群
[gaocl@hadoop102 kafka]$ bin/kafka-server-stop.sh
[gaocl@hadoop103 kafka]$ bin/kafka-server-stop.sh
[gaocl@hadoop104 kafka]$ bin/kafka-server-stop.sh
10)kafka群起脚本
for i in `cat /opt/module/hadoop-2.7.2/etc/hadoop/slaves`
do
echo "========== $i =========="
ssh $i 'source /etc/profile&&/opt/module/kafka_2.11-0.11.0.2/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-0.11.0.2/config/server.properties'
echo $?
done
2、Kafka 命令行操作
2.1、对 Topic 操作
1)查看当前服务器中的所有Topic
bin/kafka-topics.sh --zookeeper hadoop102:2181 --list
2)创建topic
bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 3 --partitions 1 --topic test_first
选项说明:
--topic 定义topic名
--replication-factor 定义副本数
--partitions 定义分区数

3)删除topic
bin/kafka-topics.sh --zookeeper hadoop102:2181 --delete --topic test_first

注意:需要server.properties中设置delete.topic.enable=true否则只是标记删除。
4)查看某个Topic的详情
bin/kafka-topics.sh --zookeeper hadoop102:2181 --describe --topic test_first

5)修改分区数
bin/kafka-topics.sh --zookeeper hadoop102:2181 --alter --topic test_first --partitions 6

2.2、consumer对topic的操作
1)发送数据
bin/kafka-console-producer.sh \
> --broker-list hadoop102:9092\
> --topic test_first
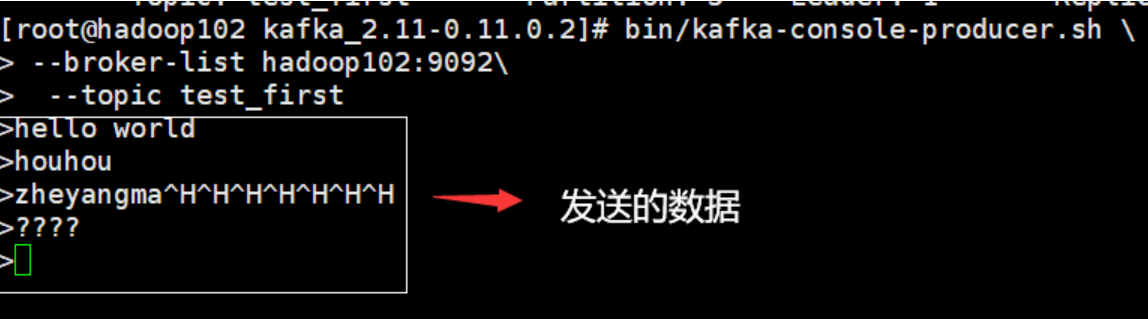
2)消费数据
bin/kafka-console-consumer.sh \
> --bootstrap-server hadoop102:9092 --from-beginning --topic test_first
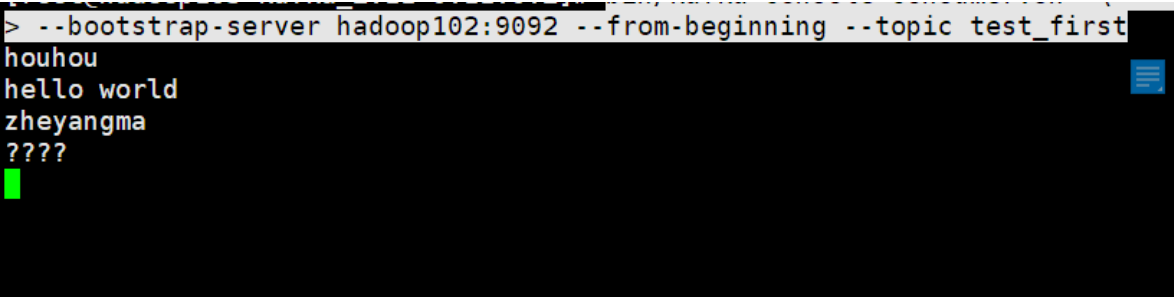
--from-beginning:会把 Topic 中以往所有的数据都读取主来。
3、Kafka Api 练习
3.1、Producer API
消息发送流程:
Kafka的Producer发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程——main线程和Sender线程,以及一个线程共享变量——RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka broker。
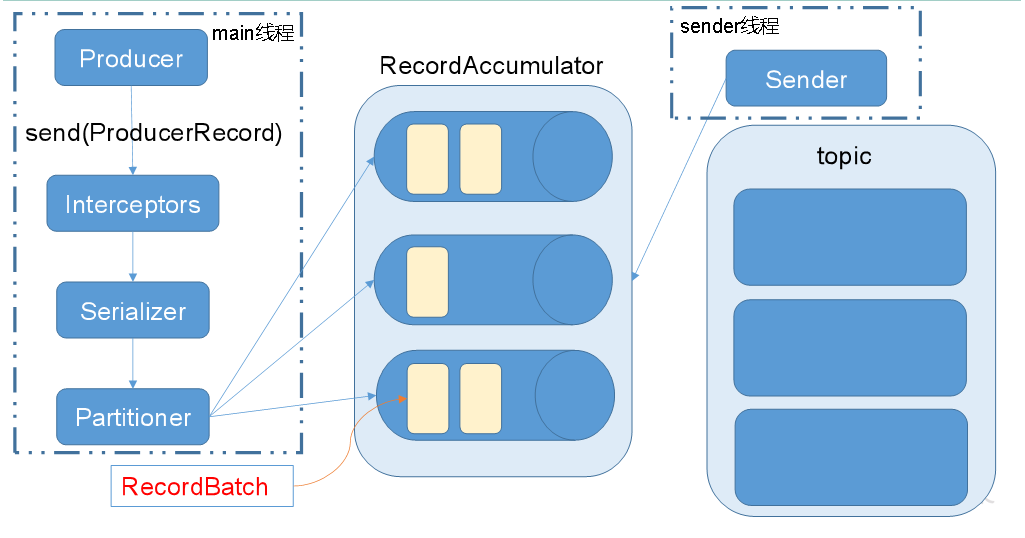
相关参数:
batch.size:只有数据积累到batch.size之后,sender才会发送数据。
linger.ms:如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。
1)异步发送Api
① 导入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
② 我系统因为总是默认选择jdk 10,所以在xml中锁定版本(没有这种情况的忽略即可)
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build>
③ 编写代码
需要用到的类:
KafkaProducer:需要创建一个生产者对象,用来发送数据
ProducerConfig:获取所需的一系列配置参数
ProducerRecord:每条数据都要封装成一个ProducerRecord对象
不带回调函数的API
public class KafkaProducter {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers","hadoop102:9092"); //kafka集群,broker-list
properties.put("acks", "all");
properties.put("retries", 1); //重试次数
properties.put("batch.size", 16384); //批次大小
properties.put("linger.ms", 1); //等待时间
properties.put("buffer.memory", 33554432); //RecordAccumulator 缓冲区大小
properties.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("test_first",
Integer.toString(i), Integer.toString(i)));
}
producer.close();
}
}
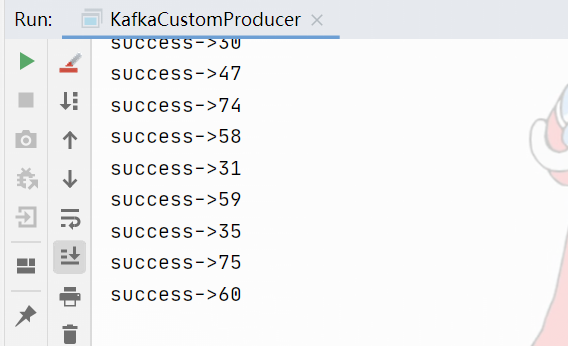
带回调函数的API
public class KafkaCustomProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers","hadoop102:9092"); //kafka集群,broker-list
properties.put("acks", "all");
properties.put("retries", 1); //重试次数
properties.put("batch.size", 16384); //批次大小
properties.put("linger.ms", 1); //等待时间
properties.put("buffer.memory", 33554432); //RecordAccumulator 缓冲区大小
properties.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("test_first",
Integer.toString(i), Integer.toString(i)), new Callback() {
// 回调函数,该方法会在Producer收到ack时调用,为异步调用
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
System.out.println("success->" + recordMetadata.offset());
} else {
e.printStackTrace();
}
}
});
}
producer.close();
}
}
2)同步发送API
同步发送的意思就是,一条消息发送之后,会阻塞当前线程,直至返回ack。
由于send方法返回的是一个Future对象,根据Futrue对象的特点,我们也可以实现同步发送的效果,只需在调用Future对象的get方发即可。
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<>("test_first", Integer.toString(i), Integer.toString(i))).get();
}
3.2、Consumer API
Consumer消费数据时的可靠性是很容易保证的,因为数据在Kafka中是持久化的,故不用担心数据丢失问题。
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
所以offset的维护是Consumer消费数据是必须考虑的问题。
1)自动提交offset
① 导入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
② 编写代码
需要用到的类:
KafkaConsumer:需要创建一个消费者对象,用来消费数据
ConsumerConfig:获取所需的一系列配置参数
ConsuemrRecord:每条数据都要封装成一个ConsumerRecord对象
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。
自动提交offset的相关参数:
enable.auto.commit:是否开启自动提交offset功能
auto.commit.interval.ms:自动提交offset的时间间隔
public class KafkaCustomConsumer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
properties.put("bootstrap.servers","hadoop102:9092"); //kafka集群,broker-list
properties.put("group.id", "test"); //消费者组,只要group.id相同,就属于同一个消费者组
properties.put("enable.auto.commit", "true");
properties.put("auto.commit.interval.ms", "1000");
properties.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Arrays.asList("test_first")); //消费者订阅主题
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100); //消费者拉取数据
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
}
2)手动提交offset
虽然自动提交offset十分简介便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka还提供了手动提交offset的API。
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次poll的一批数据最高的偏移量提交;不同点是,commitSync阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而commitAsync则没有失败重试机制,故有可能提交失败。
① 同步提交offset
由于同步提交offset有失败重试机制,故更加可靠,以下为同步提交offset的示例。
props.put("enable.auto.commit", "false");//关闭自动提交offset
...
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
consumer.commitSync(); //同步提交,当前线程会阻塞知道offset提交成功
}
② 异步提交offset
虽然同步提交offset更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此吞吐量会收到很大的影响。因此更多的情况下,会选用异步提交offset的方式。
props.put("enable.auto.commit", "false");//关闭自动提交offset
...
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception != null) {
System.err.println("Commit failed for" + offsets);
}
}
});//异步提交
}
3)数据漏消费和重复消费分析
无论是同步提交还是异步提交offset,都有可能会造成数据的漏消费或者重复消费。先提交offset后消费,有可能造成数据的漏消费;而先消费后提交offset,有可能会造成数据的重复消费。

二、Kafka理解
1、offset的概念
topic数据存储过程图
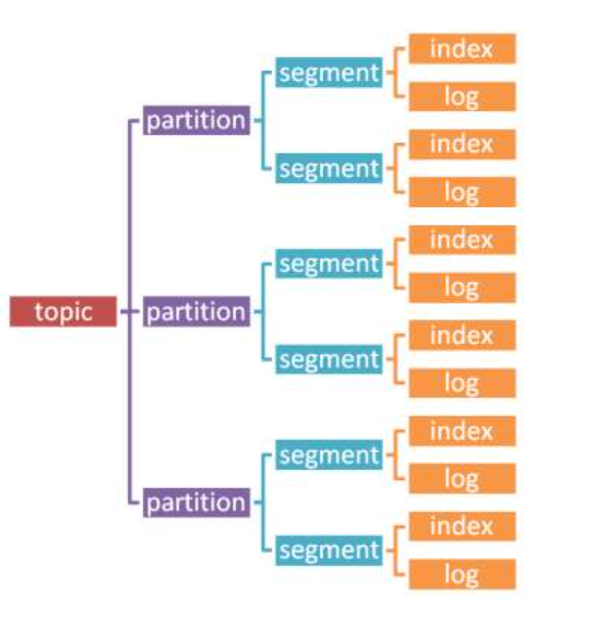
segment下.log文件(个人理解)
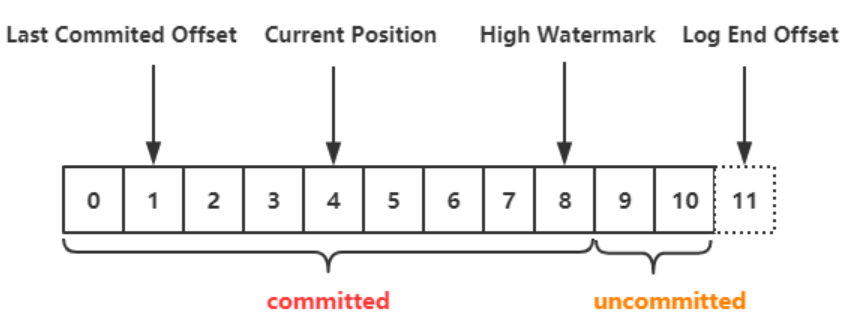
- Last Committed Offset:consumer group 最新一次 commit 的 offset,表示这个 group 已经把 Last Committed Offset 之前的数据都消费成功了。
- Current Position:consumer group 当前消费数据的 offset,也就是说,Last Committed Offset 到 Current Position 之间的数据已经拉取成功,可能正在处理,但是还未 commit。
- Log End Offset(LEO):记录底层日志 (log) 中的下一条消息的 offset。, 对 producer 来说,就是即将插入下一条消息的 offset。
- High Watermark(HW):已经成功备份到其他 replicas 中的最新一条数据的 offset,也就是说 Log End Offset 与 High Watermark 之间的数据已经写入到该 partition 的 leader 中,但是还未完全备份到其他的 replicas 中,consumer 是无法消费这部分消息 (未提交消息)。
2、Consumer和ConsumerGroup
2.1、两种常用的消息模型
队列模型(queuing)和发布订阅模型(publish-subscribe)。
队列的处理方式是一组消费者从服务器读取消息,一条消息只由其中的一个消费者来处理。
发布-订阅模型中,消息被广播给所有的消费者,接收到消息的消费者都可以处理此消息。
2.2、Kafka的消费者和消费者组
Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组 (consumer group)。 消费者用一个消费者组名标记自己。 一个发布在Topic上消息被分发给此消费者组中的一个消费者。 假如所有的消费者都在一个组中,那么这就变成了队列模型。 假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。 一个消费者组中消费者订阅同一个Topic,每个消费者接受Topic的一部分分区的消息,从而实现对消费者的横向扩展,对消息进行分流。
注意:当单个消费者无法跟上数据生成的速度,就可以增加更多的消费者分担负载,每个消费者只处理部分partition的消息,从而实现单个应用程序的横向伸缩。但是不要让消费者的数量多于partition的数量,此时多余的消费者会空闲。此外,Kafka还允许多个应用程序从同一个Topic读取所有的消息,此时只要保证每个应用程序有自己的消费者组即可。
消费者组的概念就是:当有多个应用程序都需要从Kafka获取消息时,让每个app对应一个消费者组,从而使每个应用程序都能获取一个或多个Topic的全部消息;在每个消费者组中,往消费者组中添加消费者来伸缩读取能力和处理能力,消费者组中的每个消费者只处理每个Topic的一部分的消息,每个消费者对应一个线程。

2.3、Producer发送消息如何存储到partition
我们创建消息的时候,必须要提供主题和消息的内容,而消息的key是可选的,当不指定key时默认为null。消息的key有两个重要的作用:1)提供描述消息的额外信息;2)用来决定消息写入到哪个分区,所有具有相同key的消息会分配到同一个分区中。
如果key为null,那么生产者会使用默认的分配器,该分配器使用轮询(round-robin)算法来将消息均衡到所有分区。
如果key不为null而且使用的是默认的分配器,那么生产者会对key进行哈希并根据结果将消息分配到特定的分区。注意的是,在计算消息与分区的映射关系时,使用的是全部的分区数而不仅仅是可用的分区数。这也意味着,如果某个分区不可用(虽然使用复制方案的话这极少发生),而消息刚好被分配到该分区,那么将会写入失败。另外,如果需要增加额外的分区,那么消息与分区的映射关系将会发生改变,因此尽量避免这种情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号