Oracle实战笔记(第二天)
导读
今日主要内容:表管理、表操作(增删改查)、表查询(简单查询&复杂查询)、创建数据库。
一、表管理
1、表命名规范
- 必须以字母开头;
- 长度不能超过30个字符;
- 不能使用Oracle保留字;
- 只能使用如下字符 A-Z,a-z,0-9,$,#。
2、Oracle中的数据类型
字符型
- char:定长,最大长度2000字节。如:char(10),表示存储10字节长度的字符串,不足10字节的以空格后补。特点:浪费存储空间,但查询速度快。
- nchar:同char一样,只是nchar是Unicode编码的,支持多国语言。
- varchar2:边长,最大长度4000字节。如char(20),表示可存储最大长度为20字节的字符串。特点:节约存储空间,但查询速度慢。
- nvarchar2:同varchar2一样,只是nvarchar2是Unicode编码的,支持多国语言。
- clob(character large object):字符型大对象 ,最大长度4G。特点:够大。
数字类型
- number:可表示整数和小数,范围在[-10^38,10^38]。
- number(m):表示一个m个有效位数的整数。
- number(m,n):表示一个m个有效位数的小数,其中包含n个小数位。
日期类型
- date:精确到秒。默认格式是“dd-mon-yy”,即“日-月-年”,而我们中国的习惯是“年-月-日”,所以可以使用sql> alter session set nls_date_format = 'yyyy-mm-dd';来修改日期的格式。
- timestamp: 是date的数据类型的扩展,可以精确到小数秒(fractional_seconds_precision)。
二进制大对象类型
- blob(Binary Large Object): 二进制数据, 可以存放图片、声音、视频等,最大长度 4G。ps:一般情况下我们只需要存储大文件路径即可。
3、表的创建
比如我们使用scott来创建一个学生表,包含字段信息:学号、姓名、性别、出生日期和一个班级表,包含信息:班级号、班级名。
所以可以执行sql语句:
1 --学生表 2 create table student ( ---表名 3 sid number(4), --学号 4 sname varchar2(20), --姓名 5 sex char(2), --性别 6 birthday date, --出生日期 7 ); 8 --班级表 9 CREATE TABLE class( 10 cid NUMBER(2), 11 cName VARCHAR2(40) 12 );
4、修改表
有时候我们会对表格进行字段等信息的修改,常见的修改内容有:
添加一个字段
sql> alter table 表名 add (字段名 字段类型);
修改一个字段的长度
sql> alter table 表名 modify (字段名 字段类型);
修改字段名
sql> alter table 表名 rename column 旧字段名 to 新字段名;
修改字段的类型(要求该字段下没有数据)
sql> alter table 表名 modify (字段名 字段类型);
删除一个字段
sql> alter table 表名 drop column 字段名;
修改表的名字
sql>rename 旧表名 to 新表名;
5、删除表
sql> drop table 表名;
二、表的数据处理:增删改查
1、修改日期的默认格式
默认格式是“dd-mon-yy”,即“日-月-年”,而我们中国的习惯是“年-月-日”,所以可以使用sql> alter session set nls_date_format = 'yyyy-mm-dd';来修改日期的格式;也可以使用to_date()函数来传入自定义格式的日期。注意:这只是临时修改,数据库重启后会恢复为默认,如要修改需要修改注册表。
2、插入数据:insert into
SQL> INSERT INTO 表名[(column [, column...])] VALUES(value [, value...]);
所有字段都插入数据
比如我们在学生表中插入一条数据:在插入数据之前,先修改默认的日期格式:sql> alter session set nls_date_format = 'yyyy-mm-dd';然后在执行插入语句:sql> insert into student values('2014015332','fzz','男','1996-11-11');
插入部分字段
sql> INSERT INTO student(column1, column2, column3...) VALUES (value1, value2, value3...);
如在student表中只插入学号和出生日期:sql> insert into student(sid,birthday) values('2014015001','1995-9-22');
插入空值
填写数据的地方用null代替即可。
3、删除数据:delete from...where
delete清空表格
语法:sql> delete table 表名;
说明:删除所有记录,表结构还在,写日志,可以恢复删除的数据,速度慢。
ps:删除前使用savepoint可恢复删除的数据:savepoint a; --创建保存点 ;DELETE FROM student; rollback to a; --恢复到保存点
truncate清空表格
语法:sql >truncate table 表名;
说明:与delete的区别在于:不带where删除,不写日志,删除后不能恢复,但速度快。
删除表格
语法:drop table 表名;
说明:删除表的结构和数据,即表格本身也会被删除。无法恢复。
删除指定记录
语法:sql> delete from student where 删除条件
4、修改数据:update set
语法:sql> update 表名 set column1=value1,column2=value2... [where 修改条件];
三、表查询
表查询是很重要的操作,我们单独拿出来总结。为了方便说明,我们使用scott用户下的emp表和dept表进行查询分析。
1、scott.emp和scott.dept
- emp表是雇员表,是employee的缩写:表结构如下:

- dept表是部门表,是department的缩写:表结构如下:

2、简单查询
- 条件查询:where
语法:select * from 表名 where 查询条件;
1 --查询上级为7788的员工 2 select * from emp where mgr=7788;
- 模糊查询:like
%:表示0到多个字符;
_:表示任意单个字符
1 --显示首字母为S的员工姓名和工资 2 select ename, sal from emp where ename like 'S%'; 3 4 --显示第三个字母为O的员工信息 5 select * from emp where ename like '___O%';
- 统计查询:使用函数查询
常用的聚合函数包括: count(字段)、 sum(字段)、 avg(字段)、 min(字段)、 max(字段)。
1 --查询emp的总记录数 2 select count(*) from emp; 3 4 --查询emp的平均工资 5 select avg(sal) from emp; 6 7 --查询emp的最低工资 8 select min(sal) from emp; 9 10 --查询emp的最高工资 11 select max(sal) from emp;
- 使用算数表达式查询&函数nvl
算数表达式+、-、*、/都可以使用;
函数NVL( string1, replace_with)。它的功能是如果string1为NULL,则NVL函数返回replace_with的值,否则返回string1的值,如果两个参数都为NULL ,则返回NULL。
1 --查询所有员工的年工资 2 select sal * 13 + nvl(comm * 13, 0) "年工资", ename from emp; 3 4 --查询工资高于3000的员工 5 select * from emp where sal > 3000; 6 7 --查询1982年1月1号以后入职的员工 8 select * from emp where hiredate > '1-1月-1982'; 9 10 --显示工资在2000-2500的员工 11 select * from emp where sal > 2000 and sal < 2500; 12 select * from emp where sal between 2001 and 2499;
- 使用逻辑操作符
我们常说的逻辑运算符即:NOT、 AND、 OR,即非、且、或。
--查询工资高于500或者岗位是MANAGER的员工,同时姓名首写字母是大写的J select * from emp where (sal > 500 or job = 'MANAGER') and ename like 'J%';
- 使用操作符is null
isnull是查询值为Null的字段;isnotnull是查询值非空的字段。
1 --显示没有上级的人的员工信息 2 select * from emp where mgr is null;
- 使用操作符in
in(value1,value2...)表示在指定值中查询。
1 --显示empno为123,345,800的员工信息 2 select * from emp where empno = 123 or empno = 345 or empno = 800; 3 select * from emp where empno in (123, 345, 800);
- 排序查询:oder by
asc表示升序(从小到大),默认是asc;desc表示降序(从大到小)。
--按照工资从低到高的顺序显示员工的信息 select * from emp order by sal ASC; --按照工资从高到低的顺序显示员工信息 select * from emp order by sal DESC; --按照部门号升序而员工工资降序排列 select * from emp order by deptno ASC, sal DESC; --按照部门号升序而入职时间降序排列 select * from emp order by deptno ASC, hiredate DESC;
3、复杂查询
分组查询(2种)
- 分组查询之数据分组:使用聚合函数
即我们上面说的统计查询:
1 --显示所有员工中的最高工资和最低工资 2 select max(sal) 最高工资, min(sal) 最低工资 from emp; 3 4 --显示所有员工中的最高工资和最低工资并显示它们的名字 5 select ename,sal from emp where sal = (select max(sal) from emp) or sal = (select min(sal) from emp); 6 7 --显示工资高于平均工资的员工信息 8 select * from emp where sal > (select avg(sal) from emp);
- 分组查询之group by和having
group by语法可以根据指定的字段对查询结果进行分组统计,最终得到一个分组汇总表。
由于where关键字在使用集合函数时不能使用,所以在集合函数中加上了having来起到测试查询结果是否符合条件的作用。
1 --显示每个部门的平均工资和最高工资 2 select deptno, avg(sal) 平均工资, max(sal) 最高工资 from emp group by deptno order by deptno; 3 4 --显示每个部门的每种岗位的平均工资和最高工资 5 select deptno, job, avg(sal) 平均工资, max(sal) 最高工资 from emp group by deptno, job; 6 7 --显示每个部门的每种岗位的平均工资和最高工资,并按部门号升序,平均工资降序排列 8 select deptno, job, avg(sal) 平均工资, max(sal) 最高工资 from emp group by deptno, job order by deptno ASC,avg(sal) DESC; 9 10 --显示平均工资低于2000的部门号和他的平均工资 11 select deptno, avg(sal) from emp group by deptno having avg(sal) < 2000;
分组查询总结
1 分组函数只能出现在选择列表、having、order by子句中(不能出现在where中)
2 如果在select语句中同时包含有group by, having, order by 那么它们的顺序是group by, having, order by
3 在选择列中如果有列、表达式和分组函数,那么这些列和表达式必须有一个出现在group by 子句中,否则就会出错。 如SELECT deptno, AVG(sal), MAX(sal) FROM emp GROUP by deptno HAVING AVG(sal) < 2000; 这里deptno就一定要出现在group by 中。
多表查询(3种)
多表查询分为:交叉连接(笛卡尔积);内连接;外连接(外连接又分为左外和右外)。
交叉连接是两把如果要查询两表的交集或未交的部分,就分别使用内连接查询和外连接查询,如下图所示:
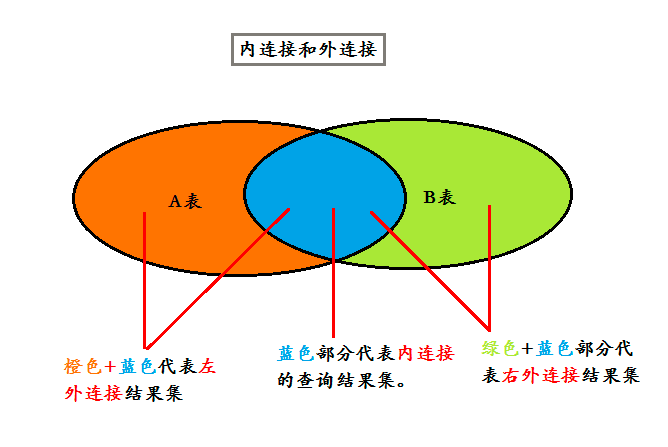
- 多表查询之交叉连接
交叉连接不带WHERE子句,它返回被连接的两个表所有数据行的笛卡尔积,返回结果集合中的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。
1 --交叉连接查询:emp和dept的笛卡尔积 2 select * from emp , dept;
- 多表查询之内连接
典型的联接运算,使用比较运算符进行条件查询。使用表A inner join 表B 表示,可省略。
1 --显示员工名,员工工资以及所在部门名 2 select ename, sal, dname from emp,dept where emp.deptno = dept.deptno; 3 4 --显示部门号为10的部门名、员工名和工资 5 select dname,ename,sal from emp e, dept d where e.deptno = d.deptno and d.deptno = 10;
- 多表查询之外连接
左外连接:表A left [outer] join 表B on;左向外联接的结果集包括指定的左表的所有行,而不仅仅是联接列所匹配的行。如果表A的某行在右表中没有匹配行,则在相关联的结果集行中表B的所有选择列表列均为空值。(如上图)
右外连接:表A right [outer] join 表B on;右向外联接是左向外联接的反向联接。将返回右表的所有行。如果表B的某行在左表中没有匹配行,则将为表A返回空值。
全外连接: 表A full [outer] join 表B on;完整外部联接返回左表A和右表B中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
1 --左外:查询员工姓名和的部门地址 2 select e.ename,d.loc from emp e left join dept d on e.deptno=d.deptno; 3 --右外:查询员工姓名和部门地址 4 select e.ename,d.loc from emp e right join dept d on e.deptno=d.deptno; 5 --全外连接:查询员工姓名和部门地址 6 select e.ename,d.loc from emp e full join dept d on e.deptno=d.deptno;
子查询(5种)
当一个查询是另一个查询的条件时,称之为子查询。
- 子查询之单行子查询:=
1 --显示与SMITH同一部门的所有员工 2 select * from emp where deptno = (select deptno from emp where ename='SMITH') and ename != 'SMITH';
- 子查询之多行子查询:any&all
1 --查询和部门10工作相同的雇员的名字、岗位、工资、部门号 2 select ename,job,sal,deptno from emp where job in(select job from emp where deptno = 10) and deptno != 10; 3 select ename,job,sal,deptno from emp where job = any(select job from emp where deptno = 10) and deptno != 10; 4 5 --显示工资比部门30的所有员工的工资还要高的员工的姓名、工资和部门号 6 select ename,sal,deptno from emp where sal > (select max(sal) from emp where deptno=30); 7 select ename,sal,deptno from emp where sal > all(select sal from emp where deptno=30); 8 9 --显示工资比部门30的任意一个员工的工资还要高的员工的姓名、工资和部门号 10 select ename,sal,deptno from emp where sal > (select min(sal) from emp where deptno=30); 11 select ename,sal,deptno from emp where sal > any(select sal from emp where deptno=30);
补充:带有ANY或ALL谓词的子查询
子查询单列多行值时可以使用ANY或ALL谓词,使用ANY或ALL谓词时则必须同时使用比较运算符,其语义为(总结来说就是all是所有数据、any是任意数据):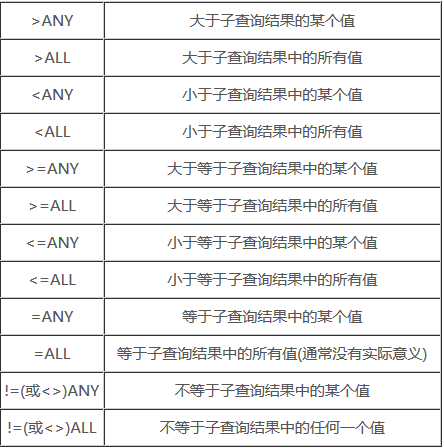
事实上,用聚合函数来实现子查询通常比直接用ANY或ALL查询效率要高,ANY与ALL与聚合函数的对应关系如下所示: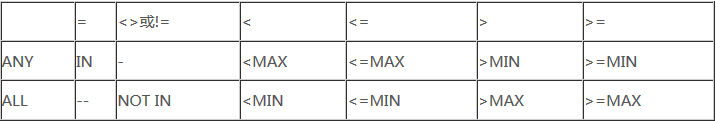
- 多列子查询
1 --查询与SMITH的部门和岗位完全相同的所有员工 2 select e1.* from emp e1,(select deptno,job from emp where ename='SMITH') e2 where e1.deptno = e2.deptno and e1.job = e2.job and ename != 'SMITH';
- 在from子句中使用子查询
在这里需要说明的当在from子句中使用子查询时,该子查询会被作为一个视图来对待,因此叫做内嵌视图,当在from子句中使用子查询时,必须给子查询指定别名,注:子查询的别名不能加as。即给表取别名的时候,不能加as;但是给列取别名,是可以加as的。1 --显示高于自己部门平均工资的员工信息 2 select e1.*,e2.avgsal from emp e1,(select deptno,avg(sal) avgsal from emp group by deptno) e2 where e1.deptno = e2.deptno and e1.sal > e2.avgsal;
- 使用查询结果创建新表
1 --使用查询结果创建新表emp2 2 create table emp2(eid,ename,sal) as select empno,ename,sal from emp;
这样emp的查询结果包括字段、字段类型甚至是数据都会导入到新表emp2中。
分页查询(3种)
- 使用rownum分页
第一步:查询:rownum是Oracle对查询结果进行逻辑排序的序号,比如语句:
--查询emp及rownum信息: select e.*,rownum rn from(select * from emp)e ;
即:select * from emp是子查询,并命名为e,然后rownum就会自动子查询的结果进行排序,这些序号信息就是rownum,并以rn字段显示出来。如图:
第二步:分页:使用where利用rn信息来进行分页,即使用比较符<、>、≥、=、≤或区间表达式between m and n,即区间[m,n]来分页。1 --比较符查询:查询roenum前10条数据 2 select e.*,rownum rn from(select * from emp)e where rownum<=10; 3 --区间查询case1:查询rownum在[5,10]的数据 4 select e.*,rownum rn from(select * from emp)e where rn between 5 and 6; 5 --区间查询case2:查询rownum在[2,6]的数据 6 select * from 7 (select e.*,rownum rn from(select * from emp)e where rownum<=10) 8 where rn>=5;
说明:注意区间查询的两种格式,由于rownum在一个sql语句中只能使用一次,所以不能使用where rownum<=10 and rownum>=5。所以case1中我们使用between and 来表示;而在case2中,相当于两次分页,首先我们查询了rownum<=10的数据,是第一次分页,然后再把这些数据作为第二次分页的子查询,第二次分页我们将rn>=5就最终得到[5,10]之间的分页数据。
ps:区间查询中case1格式简单明了,但查询速度却不及case2的两次分页查询速度。
注意1:我们上面的查询例子是查询所有字段信息即select *查询。例如case2只需要查询部分字段,如只需要查询员工名称ename和员工薪资sal,我们只需要修改最里层的查询即可:1 --查询rownum为[5,10]的员工姓名和工资 2 select * from 3 (select e.*,rownum rn from(select ename,sal from emp)e where rownum<=10) 4 where rn>=5;
注意2:有时候我们需要排序后再分页,这是也只需要修改最里层的查询即可:
1 --查询rownum为[5,10]的员工姓名和薪资,并按照薪资降序排序 2 select * from 3 (select e.*,rownum rn from(select ename,sal from emp order by sal desc)e where rownum<=10) 4 where rn>=5;
ps:其他情况也是如此,修改最里层的查询即可。
- 使用rowid分页
rowid区别与rownum,rownum是逻辑序号,是根据每次的查询结果自动编号的,而rowid是物理序号,oracle每次插入一条记录时都会生成唯一的rowid序号,相当于记录的id。总结来说就是rownum是根据自动生成的,而rowid是读取表中已有的唯一序号。
rowid分页查询比较复杂,但效率很高:
1 --查询表t_xiaoxi按cid降序排序的第9981-9999条记录,表中有70000条记录 2 select * from t_xiaoxi where rowid in( 3 select rid from 4 (select rownum rn,rid from 5 (select rowid rid,cid from t_xiaoxi order by cid desc) 6 where rownum<10000) 7 where rn >9980) order by cid desc;
执行时间:0.03秒。
可以看出rowid是层层嵌套的,比较复杂,一般情况下不推荐使用,除非是查询数据很大,用时较长的情况。 - 使用分析函数row_number()分页
效率很低,不推荐使用。
1 --查询表t_xiaoxi按cid降序排序的第9981-9999条记录,表中有70000条记录 2 select * from 3 (select t.*,row_number() over over(order by cid desc) rk 4 from t_xiaoxi t) where rk<10000 and rk>9980;
执行时间:1.01秒。
分页查询总结
分页查询的三种方式中,同样的分页查询中,rowid查询速度最快(0.03s),但书写很复杂;rownum查询次之(0.1s),书写方便;row_number()函数查询最慢(1.01s)。所以一般我们使用rownum进行分页查询即可。
合并查询(4种)
有时候在实际应用中,为了合并多个select语句的查询结果,可以使用集合操作符号union、union all,intersect、minus来进行合并。
- union查询(并集)
1 --查询薪水大于2500和job为MANAGER的员工 2 select ename,sal,job from emp where sal > 2500 union select ename,sal,job from emp where job='MANAGER';
即,两条查询记录进行合并,重复的记录会自动去掉。
- union all查询(并集)
也是并集查询,与union查询的区别在于重复的记录不会去掉。 - intersect查询(交集)
1 --查询薪水大于2500并且job为MANAGER的员工 2 select ename,sal,job from emp where sal > 2500 intersect select ename,sal,job from emp where job='MANAGER';
- minus查询(差集)
1 --查询薪水大于2500但是job不为MANAGER的员工 2 select ename,sal,job from emp where sal > 2500 minus select ename,sal,job from emp where job='MANAGER';
可以看到,其实有的合并查询可以使用逻辑运算符实现,如并集就是or、交集就是and。那为什么还要使用这些关键字呢?原因在于合并查询的速度是比使用逻辑运算符查询速度要快的,所以合并查询有时候可以对查询进行优化。
四、数据库的创建
1、使用Oracle提供的工具创建(掌握)
使用工具dbca(database configuration assistant:数据库配置助手)。
- 启动dbca
找到dbca的图标,启动即可;或者使用命令行启动:win+r 输入cmd,然后在命令行界面输入dbca即可。 - 然后根据提示操作即可(百度有很多教程,这里就不再描述)
2、手动创建(了解)
手动创建很麻烦,而且容易出错,具体可参考:http://www.linuxidc.com/Linux/2013-04/83260.htm、https://www.cnblogs.com/landiljy/archive/2015/04/28/4464191.html或自行百度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号