
第八次作业
WordCount程序任务:
|
程序 |
WordCount |
|
输入 |
一个包含大量单词的文本文件 |
|
输出 |
文件中每个单词及其出现次数(频数), 并按照单词字母顺序排序, 每个单词和其频数占一行,单词和频数之间有间隔 |
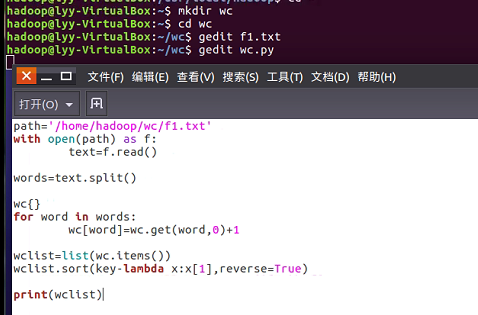
1.用你最熟悉的编程环境,编写非分布式的词频统计程序。
- 读文件
- 分词(text.split列表)
- 按单词统计(字典,key单词,value次数)
- 排序(list.sort列表)
- 输出
# 正则表达式库
import collections # 词频统计库
import numpy as np # numpy数据处理库
import jieba # 结巴分词
import wordcloud # 词云展示库
from PIL import Image # 图像处理库
import matplotlib.pyplot as plt # 图像展示库
jieba.setLogLevel(jieba.logging.INFO)
# 读取文件
fn = open('魈.txt',encoding='UTF-8') # 打开文件
string_data = fn.read() # 读出整个文件
fn.close() # 关闭文件
# 文本预处理
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"') # 定义正则表达式匹配模式
string_data = re.sub(pattern, '', string_data) # 将符合模式的字符去除
# 文本分词
seg_list_exact = jieba.cut(string_data, cut_all = False) # 精确模式分词
object_list = []
remove_words = [u'的', u',',u'和', u'是', u'随着', u'对于', u'对',u'等',u'能',u'都',u'。',u' ',u'、',u'中',u'在',u'了',
u'通常',u'如果',u'我们',u'需要',u'就',u'比起','像','说','觉得',u'一对','因为',u'此后',u'因此',u'不',u'再',
u'相处',u'出',u'力',u']',u'[',u'1',u'2',u'3',u'4',u'角色',u'《',u'》',u'被',u'要',u'着',u'这',u'有',
u'明白',u'”',u'“',u'可以',u'「',u'」',u'?',u'他',u'与',u'过'] # 自定义去除词库
for word in seg_list_exact: # 循环读出每个分词
if word not in remove_words: # 如果不在去除词库中
object_list.append(word) # 分词追加到列表
# 词频统计
word_counts = collections.Counter(object_list) # 对分词做词频统计
word_counts_top10 = word_counts.most_common(10) # 获取前10最高频的词
print (word_counts_top10) # 输出检查
# 词频展示
mask = np.array(Image.open('魈.jpg')) # 定义词频背景
wc = wordcloud.WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf', # 设置字体格式
mask=mask, # 设置背景图
max_words=300, # 最多显示词数
max_font_size=200# 字体最大值
)
wc.generate_from_frequencies(word_counts) # 从字典生成词云
image_colors = wordcloud.ImageColorGenerator(mask) # 从背景图建立颜色方案
wc.recolor(color_func=image_colors) # 将词云颜色设置为背景图方案
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像

在Ubuntu中实现运行。
- 准备txt文件
- 编写py文件
2.用MapReduce实现词频统计
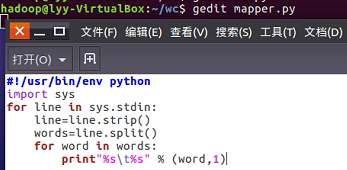
2.1编写Map函数
- 编写mapper.py
![]()
- 授予可运行权限
- 本地测试mapper.py
![]()
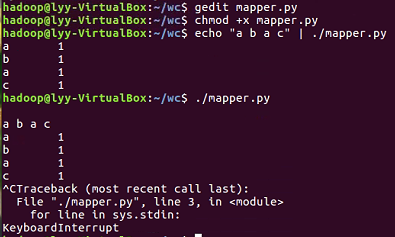
python mapper.py

使用第一行的解释器运行,ctrl+d结束输入
2.2编写Reduce函数
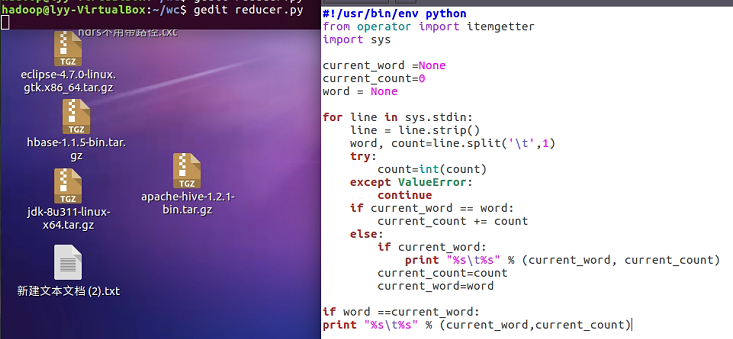
- 编写reducer.py
![]()
- 授予可运行权限
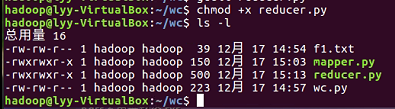
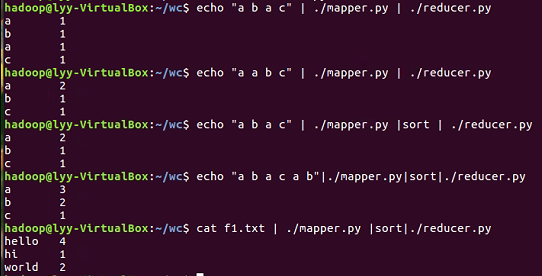
2.3分布式运行自带词频统计示例
- 启动HDFS与YARN
-
![]()
- 准备待处理文件,上传到HDFS上
![]()
![]()
- 运行实例hadoop-mapreduce-examples-2.7.1.jar
![]()
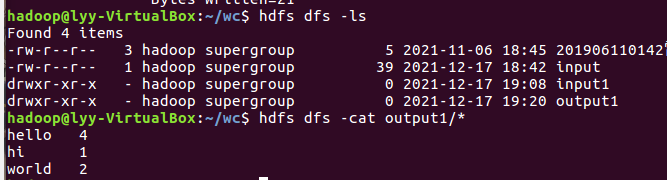
- 查看结果
![]()

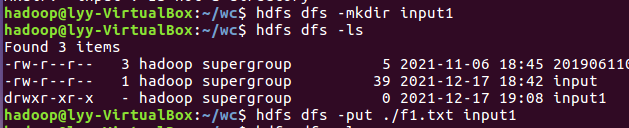

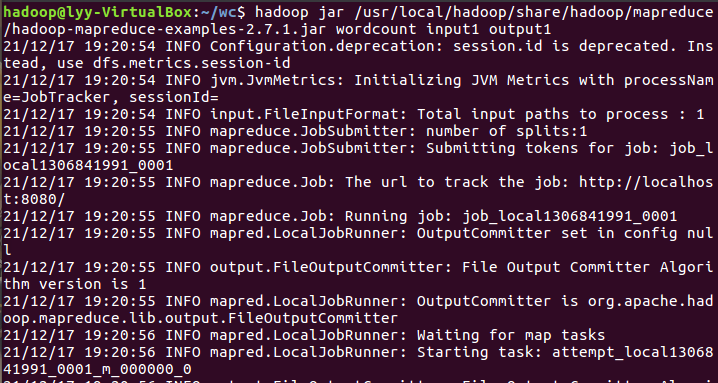
2.4 分布式运行自写的词频统计
- 用Streaming提交MapReduce任务:
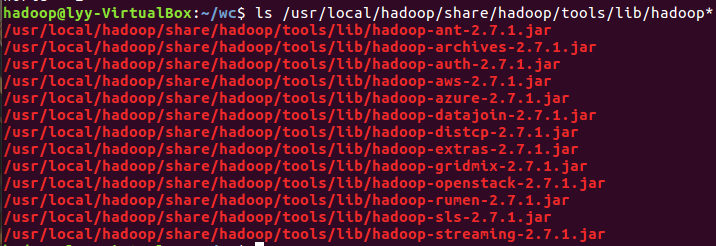
- 查看hadoop-streaming的jar文件置:/usr/local/hadoop/share/hadoop/tools/lib/
![]()
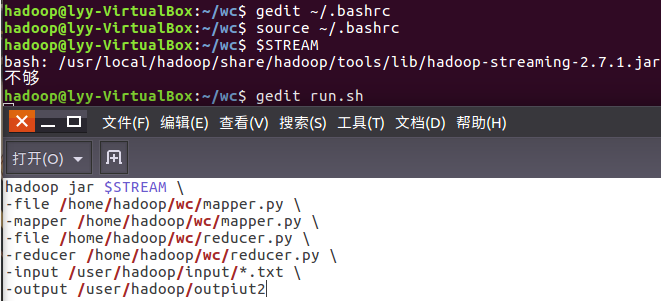
- 配置stream环境变量
![]()
- 编写运行文件run.sh
- 运行run.sh运行
![]()
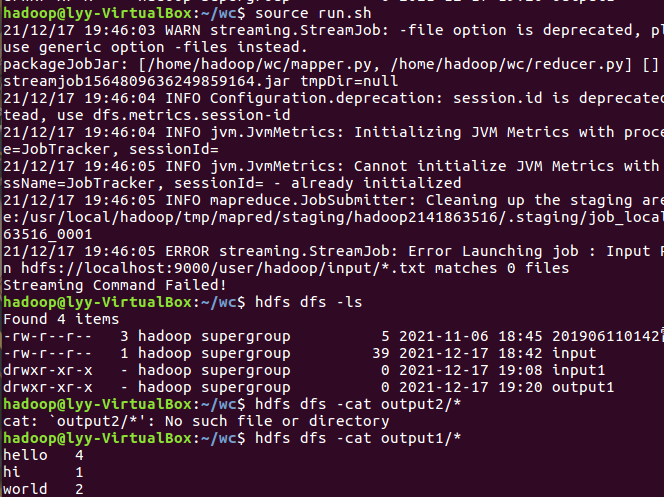
- 查看运行结果
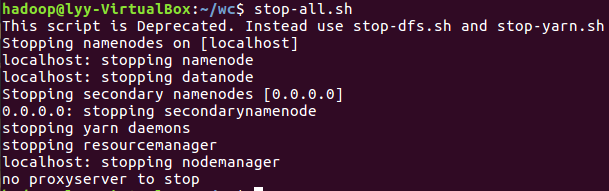
- 停止HDFS与YARN
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号