3.K均值算法
1. 机器学习的步骤
数据,模型选择,训练,测试,预测
2. 安装机器学习库sklearn
pip list 查看版本
python -m pip install --upgrade pip
pip install -U scikit-learn
pip uninstall sklearn
pip uninstall numpy
pip uninstall scipy
pip install scipy
pip install numpy
pip install sklearn
https://scikit-learn.org/stable/install.html
2. 导入sklearn的数据集
from sklearn.datasets import load_iris
iris = load_iris()
iris.keys()
X = iris.data # 获得其特征向量
y = iris.target # 获得样本标签
iris.feature_names # 特征名称
3.K均值算法
K-means是一个反复迭代的过程,算法分为四个步骤:
(x,k,y)
1) 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心;
def initcenter(x, k): kc
2) 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类;
def nearest(kc, x[i]): j
def xclassify(x, y, kc):y[i]=j
3) 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值;
def kcmean(x, y, kc, k):
4) 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)。
while flag:
y = xclassify(x, y, kc)
kc, flag = kcmean(x, y, kc, k)
参考官方文档:
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans
4. 作业:
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
一轮:随机三个数为聚类中心

二轮:按距离最近的准则将它们分到距离它们最近的聚类中心

三轮:

2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
源代码:
#201706120098 冯振威
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
#数据收集、处理
iris = load_iris()
s1 = iris.data[:,1] #花瓣长度特征
X = s1.reshape(-1,1)
#建模
est = KMeans(n_clusters=3) #分三类
est.fit(X) #训练
#预测
est.predict([[3.5]])[0]
y_kmeans = est.predict(X) #预测每个样本的聚类索引
y = iris.target
#可视化:散点图
#一个特征
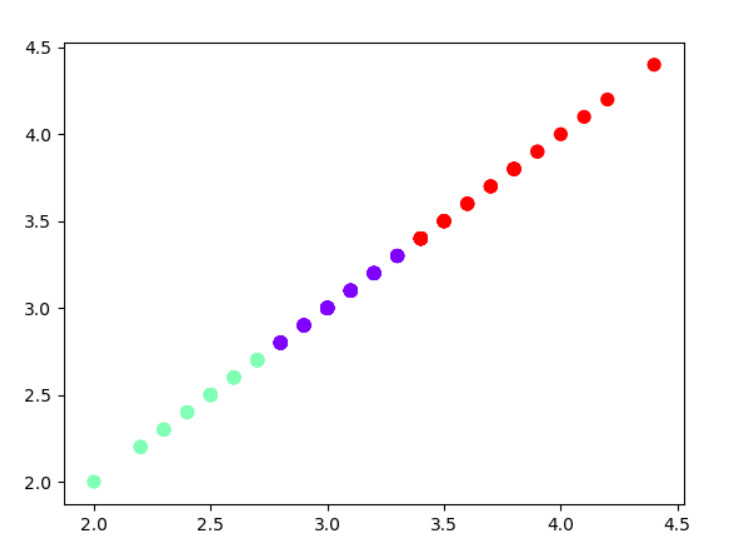
plt.scatter(X[:,0],X[:,0],c=y_kmeans,s = 50,cmap='rainbow')
plt.show()
plt.scatter(X[:,0],y_kmeans,c=y_kmeans,s = 50,cmap='rainbow')
plt.show()
est.cluster_centers_
分类:
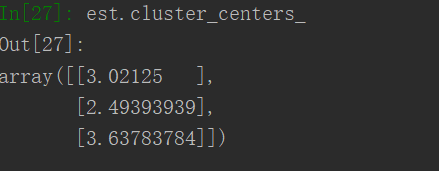
截图:散点图
4). 鸢尾花完整数据做聚类并用散点图显示.
源代码:
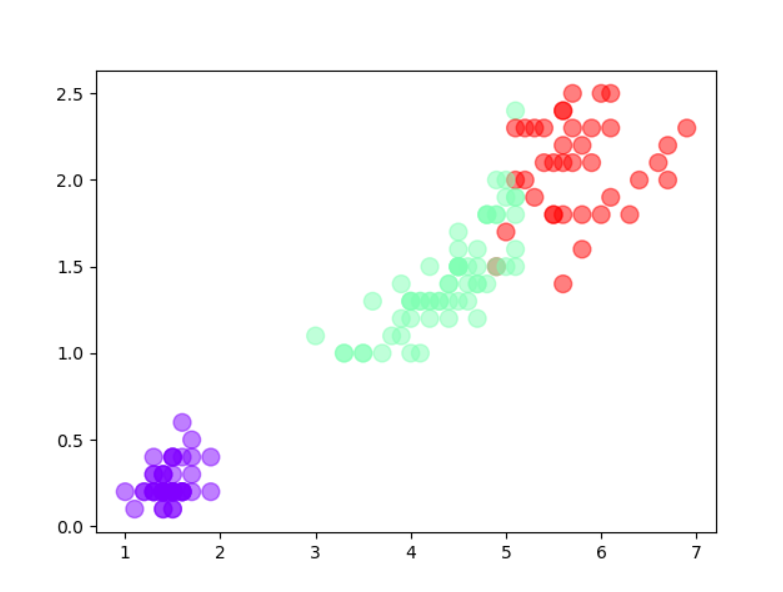
#201706120098 冯振威 import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import load_iris from sklearn.cluster import KMeans #数据收集、处理 iris = load_iris() X1 = iris.data #花瓣四个特征 #建模 est1 = KMeans(n_clusters=3) #分三类 est1.fit(X1) #训练 #预测 y_kmeans1 = est1.predict(X1) #预测每个样本的聚类索引 y = iris.target #可视化:散点图 #一个特征 plt.scatter(X1[:,2],X1[:,3],c=y_kmeans1,s = 100,cmap='rainbow',alpha=0.5) plt.show() est1.cluster_centers_
分类:
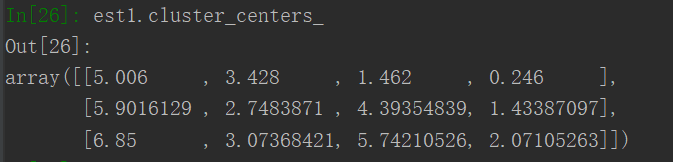
截图:散点图
5).想想k均值算法中以用来做什么?
k均值可以用来对农作物品种分类,筛选出优良品种。还有其他动植物分类等等用处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号