网络爬虫综合作业
眼看这门课程的学*已*尾声,这也是最后一次实践作业,这里记录一下实验结果与过程感受。
本次作业以三个具体案例综合了前几次作业的主要内容:爬取豆瓣电影Top250、爬取软科中国大学排名、爬取中国mooc网账户已学课程信息。
作业①:
1)爬取豆瓣电影Top250实验
-
作业①
-
要求:
- 用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
- 每部电影的图片,采用多线程的方法爬取,图片名字为电影名。
- 了解正则的使用方法。
-
候选网站:豆瓣电影:https://movie.douban.com/top250
-
输出信息:
排名 电影名称 导演 主演 上映时间 国家 电影类型 评分 评价人数 引用 文件路径 1 肖申克的救赎 弗兰克·德拉邦特 蒂姆·罗宾斯 1994 美国 犯罪 剧情 9.7 2192734 希望让人自由。 肖申克的救赎.jpg 2......
-
分析:
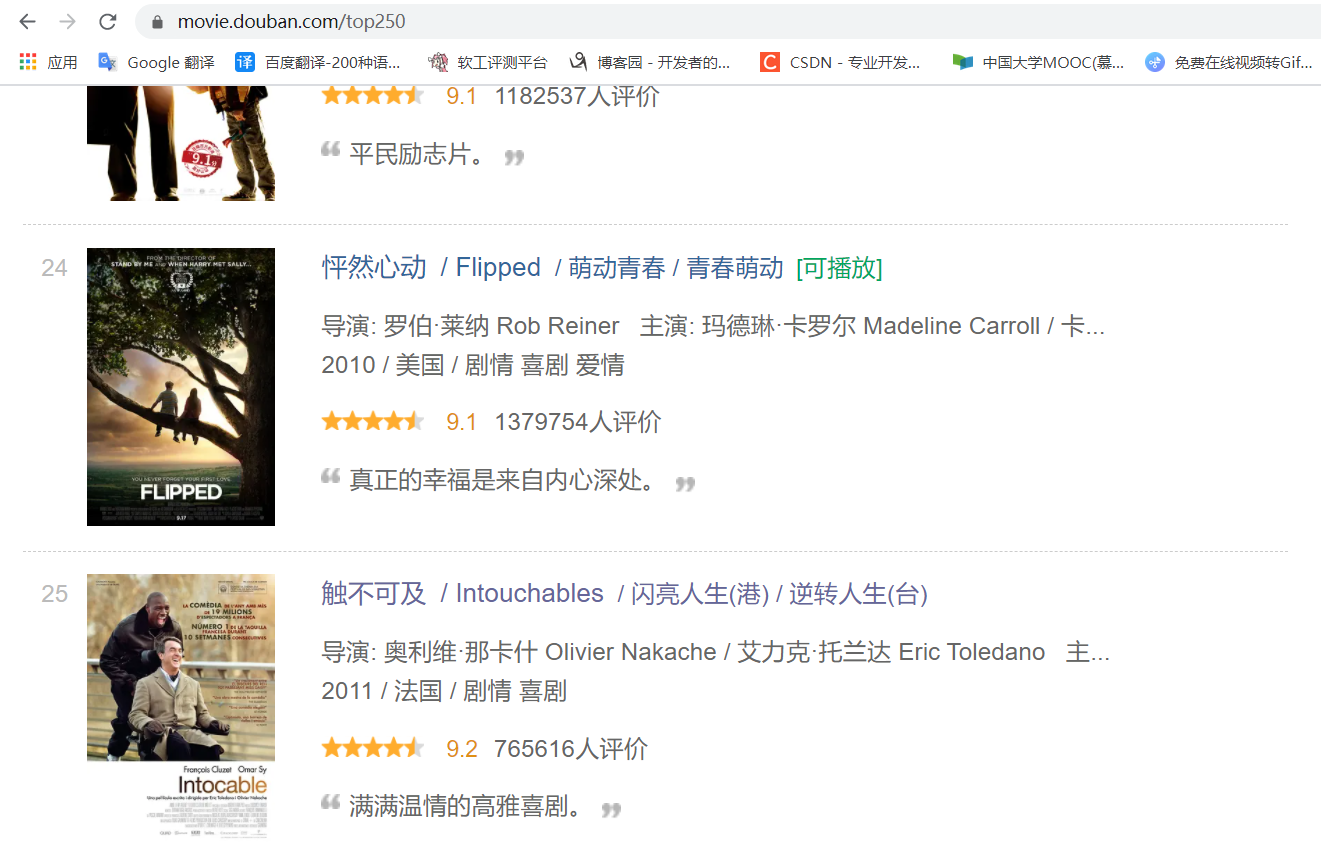
可以看出,所需的提取信息在该网页上都有展示,所以只要利用requests发出Get请求获取网页源代码,然后利用BeautifulSoup和re库设计好信息的解析规则即可以完成,但仔细观察你会发现,这个页面上显示的信息严格上说也并不完全,比如第25条《触不可及》的主演信息在该页面上就没有显示出来,而通过点击电影名称位置进入影片详情页面,会发现里面其实是有完整的主演信息的。(在我进行爬取的时候有11条主演信息在表层页面上没有显示)
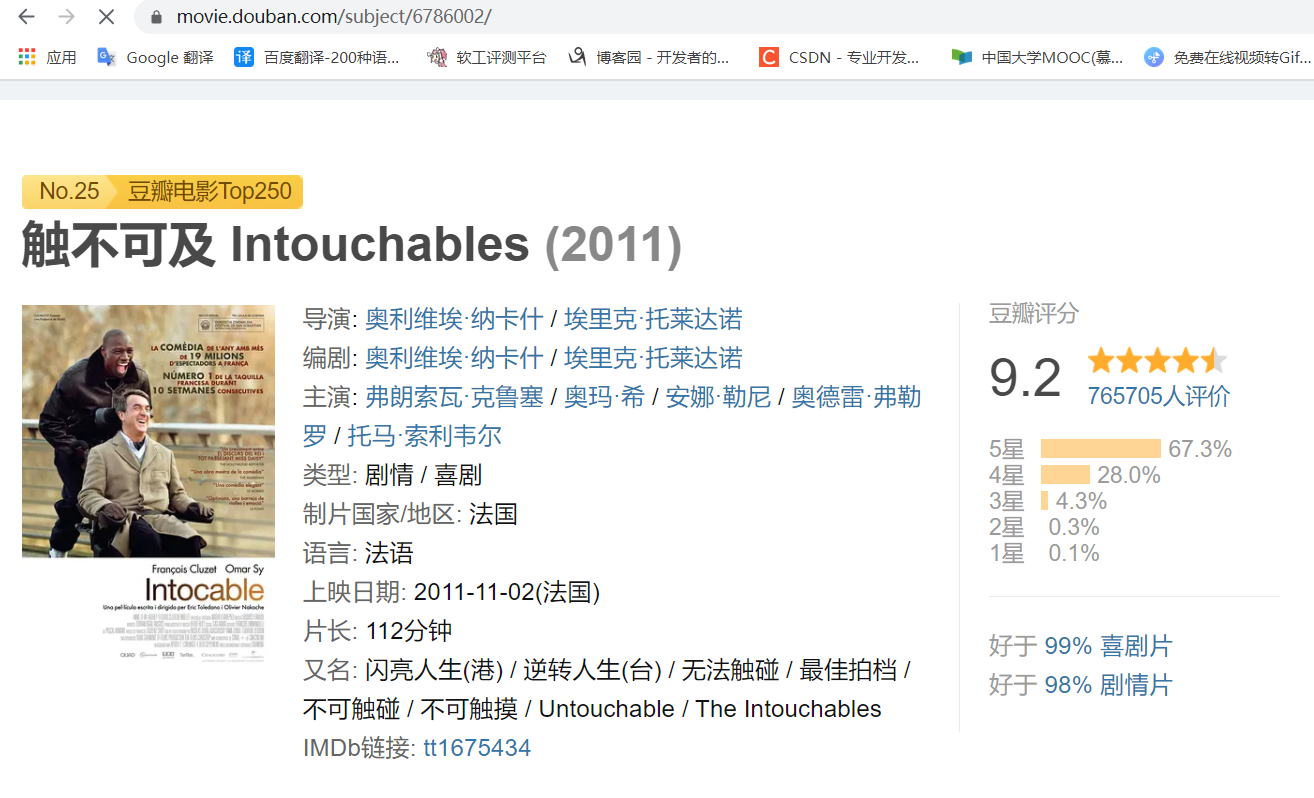
于是我就面临着两个选择:放弃(当解析不到主演信息的时候用空字符或者其他字符代替) or 执着(更改原先设计好的爬取规则,使其进入详情页面爬取信息)
作为一个有些时候莫名执着的少年,我选择了后者。
那是不是说所需的所有信息都可以在详情页面找到呢?
其实也不是,至少我在详情页面中就找不到“引用”。所以要获得相对完整的所需信息就要结合表层页面和深层页面进行爬取。可以对每一条电影信息都去发出Get请求,但其实可以通过设计使其只在表层页面没显示主演信息的时候才去发出深层页面的Get请求,这样可以减少程序发出Get请求的数量,节约系统资源。
这里我通过在load_html方法中引入布尔类型的信息变量deep_search,以及在表层网页解析主演信息的时候使用异常处理try-except,做到了这一点。
def load_html(self,url='',deep_search=False):
'''装载网页'''
url = url if url else self.start_url
response = requests.get(url=url, headers=self.header, timeout=30)
# response.encoding = response.apparent_encoding # 分析编码,比较耗时
response.encoding = 'utf-8' # 手动设置编码(可通过打印response.apparent_encoding)
if not deep_search:
self.soup = BeautifulSoup(response.text, "html.parser")
else:
return BeautifulSoup(response.text, "html.parser")
try:
self.item["starring"] = re.findall('主演: (.*?)\s',p_text)[0]
except:
print("No starring information can be found on this page")
print("Use deep search")
deep_url = div.select("div[class='hd'] a")[0]['href']
soup = self.load_html(deep_url,deep_search=True)
self.item["starring"] = soup.select("span[class='attrs'] a")[0].text
到此,我就找到了相对完善的提取所需信息的方案,至于实际爬取的时候仍然有6条电影的“引用”没有获取到,这是因为本身网站就没有提供该电影的“引用”,这就不是我的过错了,嘿嘿。
由于要爬取的电影Top250信息并不都在同一页(实际上有10页),所以还要设计好翻页的方法。
根据我的实践经验,翻页方法通常有以下几种:
1、通过人工比对不同页码的url,通过控制变量法找出引起页码变化的url字段及其规律。
2、定位页码或者翻页按钮,提取其中存储的url信息。
3、利用开发者工具进行翻页过程中的抓包,再通过人工分析不同页码的url。
4、利用selenium模拟用户进行翻页操作。
这里我采用了第二种方法:定位翻页按钮,提取其中存储的url信息。
def turn_page(self):
'''实现翻页'''
try:
next_page = self.soup.select("span[class='next'] a")[0]['href']
new_url = urljoin(self.start_url,next_page)
except:
print("Crawled to the last page")
new_url = ''
return new_url
提取页面信息方案以及翻页方法设计好之后,可以开始着手设计数据存储与展示了。
数据存储与展示通常有3个方向:
1、存储到本地文件(通常是excel)
2、存储到数据库(通常使用MySQL)
3、控制台输出(format、prettytable、wcwidth库等)
这次不想再耗费精力在美化控制台输出上了,数据库存储方面接下来的两题会有应用,所以这里练*一下存储到本地excel文件。
通常有两种实现方案:openpyxl、pandas
这里选择了数据分析处理中更经常用到的pandas。
初始化dataframe如下:
self.df = pd.DataFrame(
columns=["排名","电影名称","导演","主演","上映时间","国家","电影类型","评分","评价人数","引用","文件路径"]
)
添加一行行数据到dataframe如下:
def save_excel(self,item):
self.df.loc[len(self.df)] = [
item["rank"],item["movie_title"],item["director"],item["starring"],
item["release_time"],item["country"],item["movie_type"],item["score"],
item["evaluator"],item["quote"],item["img_name"]
]
将dataframe写入excel如下:
save_name = 'douban_top250.xlsx'
try:
self.df.to_excel(save_name,index=False)
print("{} 存储成功".format(os.getcwd()+'\\'+save_name))
except Exception as err:
print(err)
print("{} 存储失败".format(save_name))
完整代码:
import requests
from bs4 import BeautifulSoup
import re
from urllib.parse import urljoin
from urllib.request import urlretrieve
import os
import threading
import time
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
class DoubanSpider(object):
def __init__(self):
'''初始化共同属性'''
self.start_url = "https://movie.douban.com/top250"
self.header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, divke Gecko) Chrome/87.0.4280.66 Safari/537.36"
}
self.item = dict() # 初始化数据字典
self.df = pd.DataFrame(
columns=["排名","电影名称","导演","主演","上映时间","国家","电影类型","评分","评价人数","引用","文件路径"]
)
def load_html(self,url='',deep_search=False):
'''装载网页'''
url = url if url else self.start_url
response = requests.get(url=url, headers=self.header, timeout=30)
# response.encoding = response.apparent_encoding # 分析编码,比较耗时
response.encoding = 'utf-8' # 手动设置编码(可通过打印response.apparent_encoding)
if not deep_search:
self.soup = BeautifulSoup(response.text, "html.parser")
else:
return BeautifulSoup(response.text, "html.parser")
def turn_page(self):
'''实现翻页'''
try:
next_page = self.soup.select("span[class='next'] a")[0]['href']
new_url = urljoin(self.start_url,next_page)
except:
print("Crawled to the last page")
new_url = ''
return new_url
def parse_data(self):
'''解析每页数据'''
# 每条电影信息存储在div标签对中
self.item.setdefault("missing_starring",0)
self.item.setdefault("missing_quote",0)
div_list = self.soup.select("li > div[class='item']")
for div in div_list: # 每个元素是一个bs4.element.Tag对象
try:
# 排名
self.item["rank"] = div.select("div[class='pic'] > em")[0].text
# 电影名称
self.item["movie_title"] = div.select("div[class='hd'] span")[0].text
# 导演、主演、上映时间、国家、电影类型
p_text = div.select("div[class='bd'] > p")[0].text
self.item["director"] = re.findall('导演: (.*?)\s',p_text)[0]
try:
self.item["starring"] = re.findall('主演: (.*?)\s',p_text)[0]
except:
print("No starring information can be found on this page")
print("Use deep search")
deep_url = div.select("div[class='hd'] a")[0]['href']
soup = self.load_html(deep_url,deep_search=True)
self.item["starring"] = soup.select("span[class='attrs'] a")[0].text
self.item["missing_starring"] += 1
self.item["release_time"] = re.findall('\d+',p_text)[0]
nbsp_list = p_text.split("/")
self.item["country"] = nbsp_list[-2].strip()
self.item["movie_type"] = nbsp_list[-1].strip()
# 评分、评价人数
span_list = div.select("div[class='star'] span")
self.item["score"] = span_list[1].text
self.item["evaluator"] = re.search('\d+',span_list[-1].text).group()
# 引用
try:
self.item["quote"] = div.select("p[class='quote'] span")[0].text
except IndexError: # 找不到引用的置其值为空
self.item["quote"] = ''
self.item["missing_quote"] += 1
# 图片名称、url
self.item["img_name"] = self.item["movie_title"] + '.jpg'
self.item["img_url"] = div.select("div[class='pic'] img[src]")[0]['src']
# print(self.item)
except Exception as err:
print(err)
continue
yield self.item
def threads_download(self, img_url, img_name):
'''为图片下载引入多线程'''
try:
T = threading.Thread(target=self.download, args=(img_url, img_name)) # 创建线程对象
T.setDaemon(False) # True则为守护线程,若设置守护线程,一旦主线程执行完毕,子线程都得结束
T.start() # 启动线程
self.threads.append(T)
except Exception as err:
print(err)
def download(self, img_url, img_name):
'''下载指定img_url的图片到预设文件夹,并命名为指定img_name'''
dirname = "images" # 存储图片的文件夹
try:
if not os.path.exists(dirname):
os.makedirs(dirname)
print("{}文件夹创建在{}".format(dirname, os.getcwd()))
except:
pass
save_path = dirname + "\\" + img_name
try:
urlretrieve(img_url, save_path)
print("download " + img_name)
except Exception as err:
print(err)
print("download failed")
def save_excel(self,item):
self.df.loc[len(self.df)] = [
item["rank"],item["movie_title"],item["director"],item["starring"],
item["release_time"],item["country"],item["movie_type"],item["score"],
item["evaluator"],item["quote"],item["img_name"]
]
def execute_spider(self):
'''执行爬虫'''
print("Start the crawler")
# 初始化线程对象列表
print("Initializing")
self.threads = []
# 装载网页
self.load_html()
# 处理指定多页商品数据
print("Processing data")
page = 1
while True:
print("{:-^60}.".format(page))
data_generator = self.parse_data() # 返回generator对象
for item in data_generator:
# 多线程下载图片
self.threads_download(item["img_url"], item["img_name"])
# 数据保存到excel
self.save_excel(item)
new_url = self.turn_page()
if not new_url:
break
else:
self.load_html(new_url)
page += 1
save_name = 'douban_top250.xlsx'
try:
self.df.to_excel(save_name,index=False)
print("{} 存储成功".format(os.getcwd()+'\\'+save_name))
except Exception as err:
print(err)
print("{} 存储失败".format(save_name))
print("missing_starring:{}".format(self.item["missing_starring"]))
print("missing_quote:{}".format(self.item["missing_quote"]))
# 主线程中等待所有子线程退出
for t in self.threads:
t.join()
print("Finished")
if __name__ == "__main__":
start = time.clock()
spider = DoubanSpider()
spider.execute_spider()
end = time.clock()
print('Running time: {} Seconds'.format(end - start))
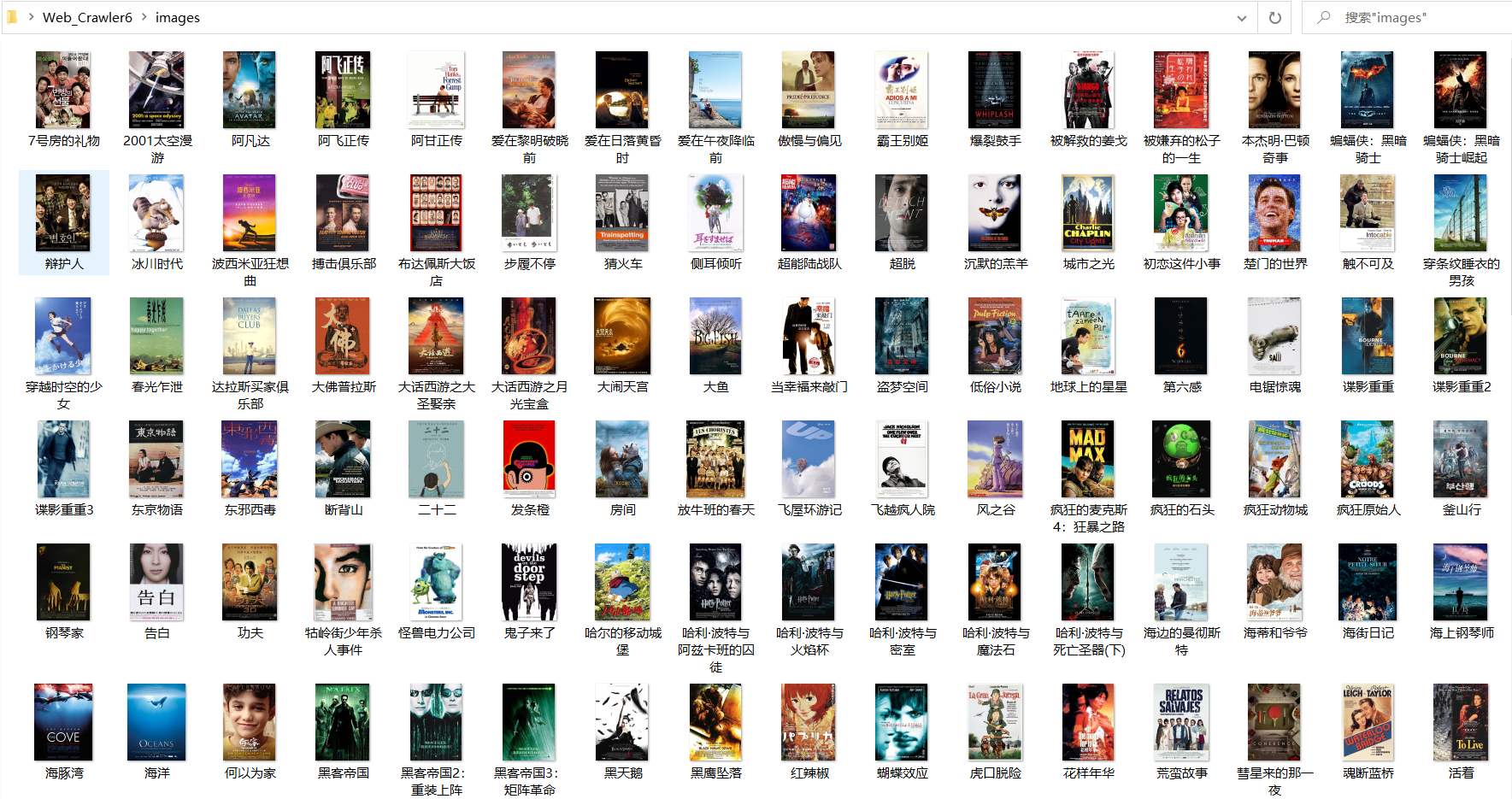
运行结果部分截图:
控制台输出



excel存储
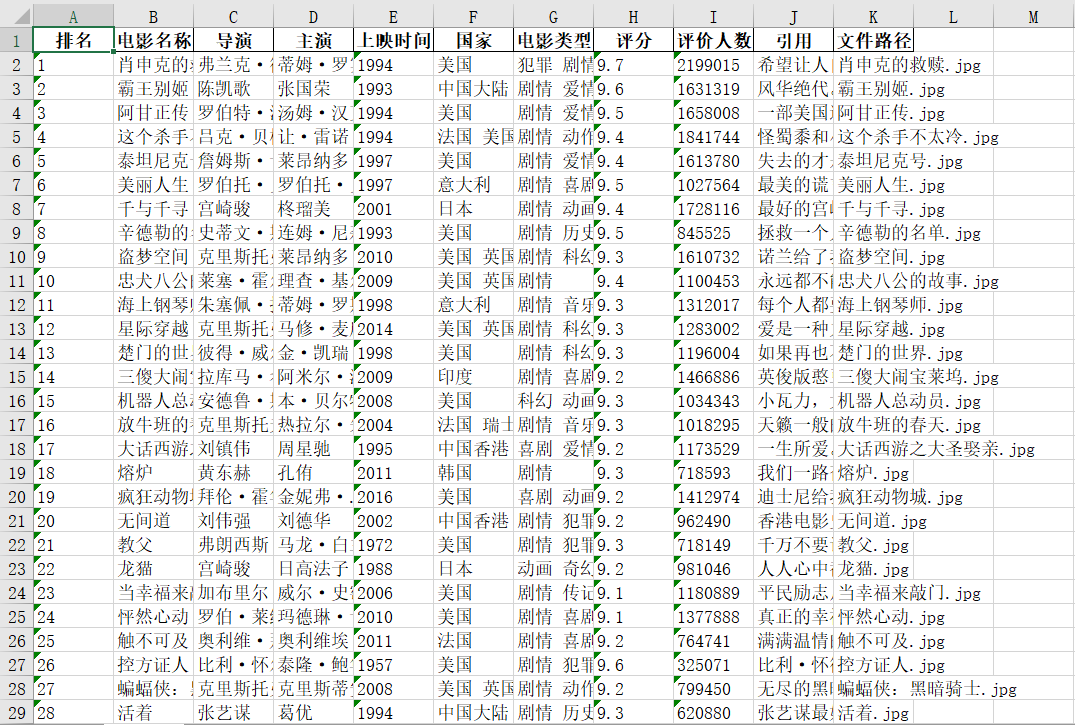
本地图片存储
2)心得体会:
这次实验温*了requests+BeautifulSoup+re+threading,requests是Python实现的简单易用的HTTP库,在urllib的基础上进行了进一步的封装,通常用来爬取相对轻量静态的网站或网页,BeautifulSoup库用来解析html标签,同Xpath一样是一种文档解析手段,而re使Python语言拥有全部的正则表达式功能,功能强应用广,博大精深。至于threading,是Python实现多线程所需借助的一个模块。在IO密集型任务上可以很大程度上地提高程序运行效率。
作业②:
1)爬取软科中国大学排名实验
-
作业②
-
要求:
- 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息。
- 爬取软科学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
-
输出信息:MYSQL的输出信息如下:
sNo schoolName city officalUrl info mFile 1 清华大学 北京 www.tsinghua.edu.cn 清华大学,学校前身清华学堂始建于1911年,1928年更名为国立清华大学。抗战爆发后南迁,与北京大学、南开大学组建国立西南联合大学,1946年迁回清华园。1952年全国高等学校院系调整后,清华大学成为一所多科性工业大学,先后恢复或新建了理科、经济、管理和文科类学科,并入中央工艺美术学院、原中国人民银行研究生部等。清华大学现为教育部直属高校,是教育部与北京市人民政府、国家国防科技工业局、水利部、国家海洋局、国家卫生健康委员会共建的全国重点大学。 1.jpg
-
分析:
跟第一题类似,进入网站查看页面提供的信息:
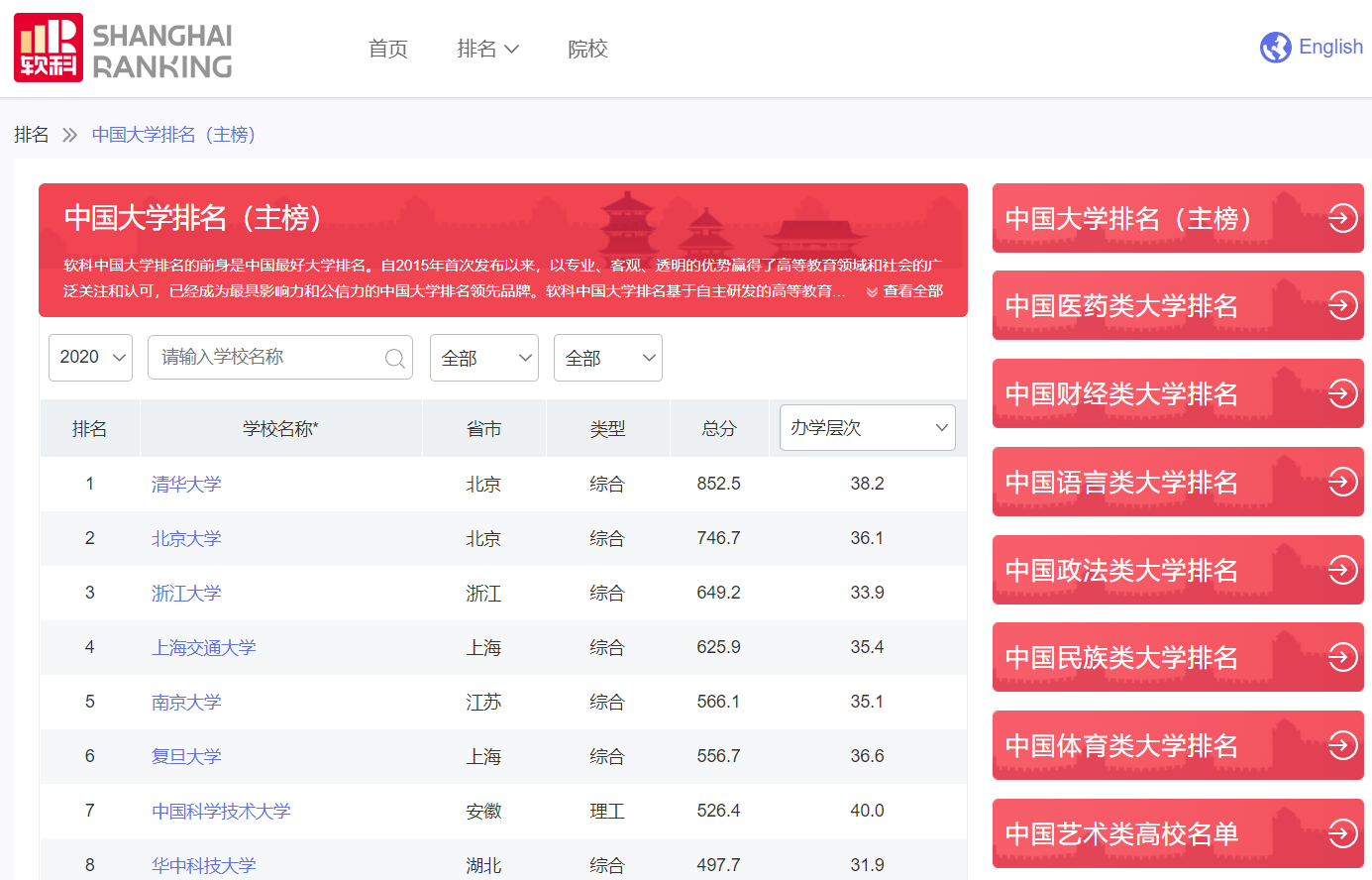
其中所需的学校排名、学校名称以及所在城市在该页面已有显示,但学校官网、学校简介以及logo信息并不在该页面中(在点击学校名称后到达的详情页面)。
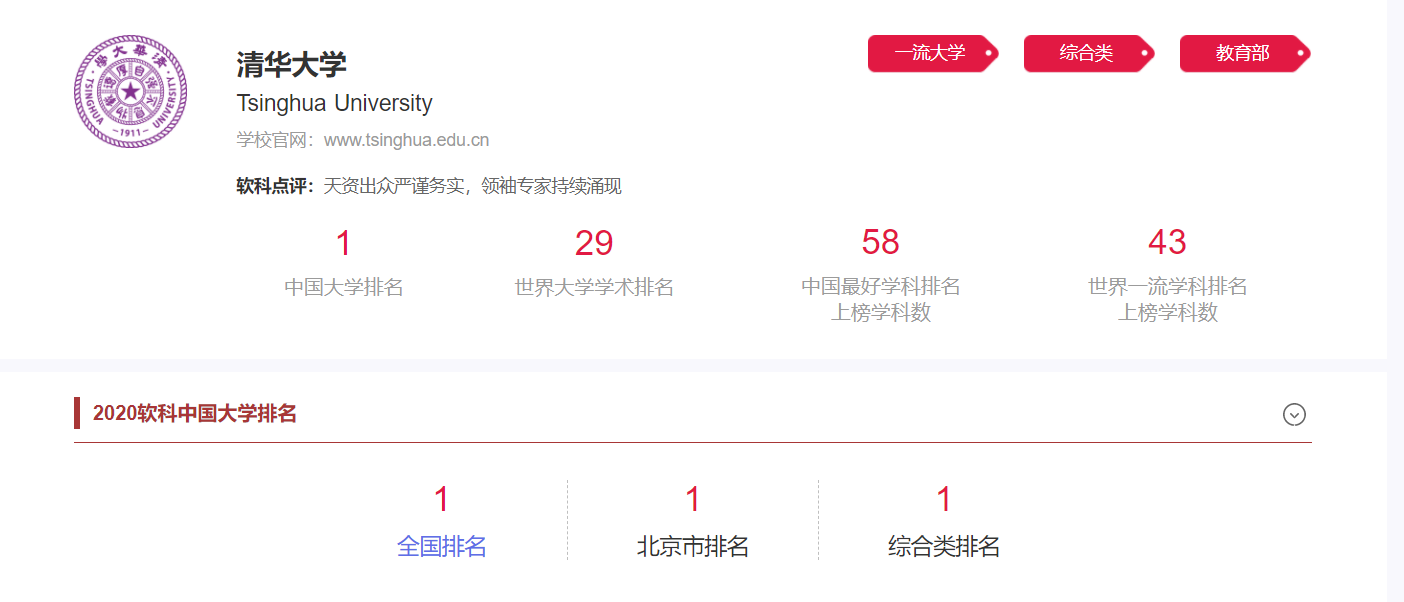

这样的话,在发出起始url的第一个Get请求后,还要通过获取一个个学校详情页面的url持续发起Get请求,且在数据解析方面,虽然可以结合正则表达式在学校详情页面中获取所有需要的信息,但方便起见,还是结合表层页面和深层页面提取信息为妙。
如此就要考虑在数据解析方法parse中进行多参数(response、item)接收,因为在表层页面提取到的item部分字段信息需要推送到parse进一步提取剩余字段信息。
在爬虫程序中设计如下:
1、start_requests函数发出起始请求并回调continue_requests函数。
def start_requests(self):
'''程序入口函数'''
yield scrapy.Request(url=self.start_url,callback=self.continue_requests)
2、continue_requests函数根据start_requests推送的response对象,提取出其中每个学校详情页面的url进行持续请求,并获取item(数据项目)部分字段,回调parse函数:
def continue_requests(self,response):
'''为每一条学校记录持续request请求'''
try:
html = response.body.decode() # 网页字符内容
selector = Selector(text=html) # 装载文档
schools = selector.xpath("//tbody//tr")
urls = schools.xpath(".//a/@href").extract()
school_numbers = schools.xpath("./td[position()=1]/text()").extract()
school_names = schools.xpath("./td[position()=2]/a/text()").extract()
citys = schools.xpath("./td[position()=3]/text()").extract()
print("A total of {} schools were recorded".format(len(schools)))
for index in range(len(schools)):
item = UniversityItem()
url = response.urljoin(urls[index])
item["school_number"] = school_numbers[index].strip()
item["school_name"] = school_names[index].strip()
item["city"] = citys[index].strip()
yield scrapy.Request(url=url,callback=lambda response, item=item: self.parse(response,item))
except Exception as err:
print(err)
其中回调函数的多参数传递有两种实现方式,一种是使用meta进行参数传递。另一种是使用lambda进行参数传递。
这里使用的是lambda进行参数传递的方法。
python Scrapy的spider中回调函数的多个参数传递方法
在每一个详情页面的数据解析方面,使用xpath进行解析,其中要留意的是缺失值的处理(有不少学校的简介都为空)。
def parse(self,response,item=None):
'''解析函数/回调函数'''
try:
html = response.body.decode() # 网页字符内容
selector = Selector(text=html) # 装载文档
item["offical_url"] = selector.xpath("//tbody//div[@class='univ-website']/a/@href").extract_first()
item["school_info"] = selector.xpath("//div[@class='univ-introduce']/p/text()").extract_first()
# item["school_info"] = item["school_info"] if item["school_info"] else ''
item["file"] = "{}.jpg".format(item["school_name"])
item["image_url"] = selector.xpath("//tbody//td[@class='univ-logo']/img/@src").extract_first()
yield item
except Exception as err:
print(err)
在处理推送过来的item的pipelines.py模块中,存储到数据库的操作详见完整代码,值得一提的是多线程下载图片在其中的使用。
由于scrapy框架是异步执行的,通常不容易确定pipelines.py模块中程序的开始和结束,而这为多线程的引入造成了不小的困扰。
但好在其提供了两个特殊的方法:open_spider、close_spider。
open_spider:当爬虫开始工作的时候执行一次,即爬虫执行开始的时候回调open_spider。
close_spider:爬虫程序结束的时候执行一次,即当爬虫程序执行结束的时候回调close_spider。
这样程序执行的头尾就非常明确了,这为初始化变量以及确定主线程等待子线程的位置提供了很大的便利。
def open_spider(self, spider):
print("opened")
try:
self.init_db()
self.create_db()
self.build_table()
self.create_folder()
self.threads = []
self.opened = True
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit() # 用于将事务所做的修改保存到数据库
self.con.close() # 断开数据库连接
self.opened = False
print("closed")
for t in self.threads: # 主线程中等待所有子线程退出
t.join()
print("Finished")
多线程的引入大大提速了图片的下载,具体实现详见完整代码。
在设计好各个模块之后,还要注意的是settings.py中的配置以及终端命令的调用使scrapy框架程序运行。
这里settings.py一方面要注意配置item pipelines,一方面要注意ROBOTSTXT_OBEY的True or False(这里True不影响程序执行结果)。
终端命令的调用一方面可以直接使用“命令提示符”一方面可以创建一个.py程序调用终端命令,这里创建了run.py程序。
创建scrapy框架项目:

scrapy框架目录结构:
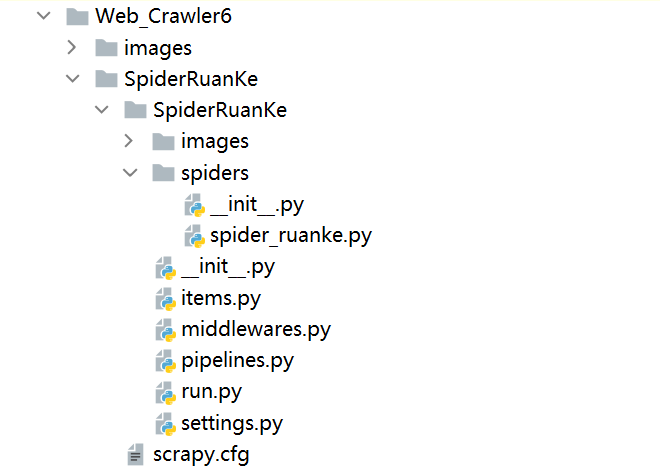
完整代码:
- items.py(设计数据项目模块)
import scrapy
class UniversityItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
school_number = scrapy.Field()
school_name = scrapy.Field()
city = scrapy.Field()
offical_url = scrapy.Field()
school_info = scrapy.Field()
file = scrapy.Field()
image_url = scrapy.Field()
pass
- spider_ruanke.py(爬取数据项目模块)
import scrapy
from scrapy.selector import Selector
import sys
sys.path.append("..") # 添加上级目录到sys.path
from items import UniversityItem
class RuankeSpider(scrapy.Spider):
name = "ruankespider" # 爬虫程序名称
start_url = "https://www.shanghairanking.cn/rankings/bcur/2020" # 软科学校排名主榜
def start_requests(self):
'''程序入口函数'''
yield scrapy.Request(url=self.start_url,callback=self.continue_requests)
def continue_requests(self,response):
'''为每一条学校记录持续request请求'''
try:
html = response.body.decode() # 网页字符内容
selector = Selector(text=html) # 装载文档
schools = selector.xpath("//tbody//tr")
urls = schools.xpath(".//a/@href").extract()
school_numbers = schools.xpath("./td[position()=1]/text()").extract()
school_names = schools.xpath("./td[position()=2]/a/text()").extract()
citys = schools.xpath("./td[position()=3]/text()").extract()
print("A total of {} schools were recorded".format(len(schools)))
for index in range(len(schools)):
item = UniversityItem()
url = response.urljoin(urls[index])
item["school_number"] = school_numbers[index].strip()
item["school_name"] = school_names[index].strip()
item["city"] = citys[index].strip()
yield scrapy.Request(url=url,callback=lambda response, item=item: self.parse(response,item))
except Exception as err:
print(err)
def parse(self,response,item=None):
'''解析函数/回调函数'''
try:
html = response.body.decode() # 网页字符内容
selector = Selector(text=html) # 装载文档
item["offical_url"] = selector.xpath("//tbody//div[@class='univ-website']/a/@href").extract_first()
item["school_info"] = selector.xpath("//div[@class='univ-introduce']/p/text()").extract_first()
# item["school_info"] = item["school_info"] if item["school_info"] else ''
item["file"] = "{}.jpg".format(item["school_name"])
item["image_url"] = selector.xpath("//tbody//td[@class='univ-logo']/img/@src").extract_first()
yield item
except Exception as err:
print(err)
- pipelines.py(数据管道处理模块)
from itemadapter import ItemAdapter
import pymysql
from urllib.request import urlretrieve
import os
import threading
class UniversityPipeline(object):
# 当爬虫开始工作的时候执行一次,即爬虫执行开始的时候回调open_spider
def open_spider(self, spider):
print("opened")
try:
self.init_db()
self.create_db()
self.build_table()
self.create_folder()
self.threads = []
self.opened = True
except Exception as err:
print(err)
self.opened = False
# 处理item
def process_item(self, item, spider):
try:
if self.opened:
self.insert_table(item["school_number"],item["school_name"],item["city"],
item["offical_url"],item["school_info"],item["file"])
self.threads_download(item["image_url"],item["file"])
except Exception as err:
print(err)
return item
# 爬虫程序结束的时候执行一次,即当爬虫程序执行结束的时候回调close_spider
def close_spider(self, spider):
if self.opened:
self.con.commit() # 用于将事务所做的修改保存到数据库
self.con.close() # 断开数据库连接
self.opened = False
print("closed")
for t in self.threads: # 主线程中等待所有子线程退出
t.join()
print("Finished")
# 创建存储图片的文件夹
def create_folder(self):
self.dirname = "images"
if not os.path.exists(self.dirname):
os.makedirs(self.dirname)
print("{} Folder created in {}".format(self.dirname, os.getcwd()))
# 多线程下载
def threads_download(self, image_url, image_name):
try:
T = threading.Thread(target=self.download, args=(image_url, image_name)) # 创建线程对象
T.setDaemon(False) # True则为守护线程,若设置守护线程,一旦主线程执行完毕,子线程都得结束
T.start() # 启动线程
self.threads.append(T)
except Exception as err:
print(err)
# 下载image_url到指定文件夹,根据预设名称命名
def download(self,image_url,image_name):
save_path = self.dirname + "\\" + image_name
try:
urlretrieve(image_url, save_path)
print("download " + image_name)
except Exception as err:
print(err)
print("download failed")
# 初始化数据库相关信息
def init_db(self):
self.host = '127.0.0.1' # MYSQL服务器地址
self.port = 3306 # MYSQL服务器端口号
self.user = 'root' # 用户名
self.passwd = "passwd" # 密码
self.db = 'spider_db' # 数据库名称
self.charset = 'utf8' # 连接编码
self.table = 'school_rank' # 表名
# 如果数据库不存在则创建
def create_db(self):
try:
conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
charset=self.charset)
cursor = conn.cursor()
sql_crdb = "create database if not exists {}".format(self.db)
cursor.execute(sql_crdb)
print("Database {} has been created".format(self.db))
except Exception as err:
print(err)
# 构建表结构
def build_table(self):
try:
self.con = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
db=self.db,
charset=self.charset)
self.cursor = self.con.cursor() # 使用连接对象获得cursor对象
# 如果表存在则删除
sql_drop = 'drop table if exists {}'.format(self.table)
self.cursor.execute(sql_drop)
# 如果表不存在则创建,由于之前进行删表操作,所以这里会创建新表
sql_create = 'create table if not exists {}('.format(self.table) + \
"sNo int not null auto_increment," \
"schoolName varchar(256)," \
"city varchar(64)," \
"officalUrl varchar(512)," \
"school_info varchar(1024)," \
"mFile varchar(64)," \
"primary key (sNo,schoolName))" # 联合主键
self.cursor.execute(sql_create)
except Exception as err:
print(err)
# 按特定格式向表中插入数据
def insert_table(self, sNo, schoolName, city, officalUrl, school_info, mFile):
try:
sql_insert = "insert into {} (sNo, schoolName, city, officalUrl, school_info, mFile)" \
" values (%s,%s,%s,%s,%s,%s)".format(self.table)
self.cursor.execute(sql_insert, (sNo, schoolName, city, officalUrl, school_info, mFile))
except Exception as err:
print(err)
- settings.py(配置模块)
BOT_NAME = 'SpiderRuanKe'
SPIDER_MODULES = ['SpiderRuanKe.spiders']
NEWSPIDER_MODULE = 'SpiderRuanKe.spiders'
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
'SpiderRuanKe.pipelines.UniversityPipeline': 300,
}
- run.py(执行模块)
from scrapy import cmdline
command = "scrapy crawl ruankespider -s LOG_ENABLED=False"
cmdline.execute(command.split())
实验过程中其实有点坎坷,遇到了多个学校同一排名,造成以学校排名作为主键和图片名称所造成的数据丢失:
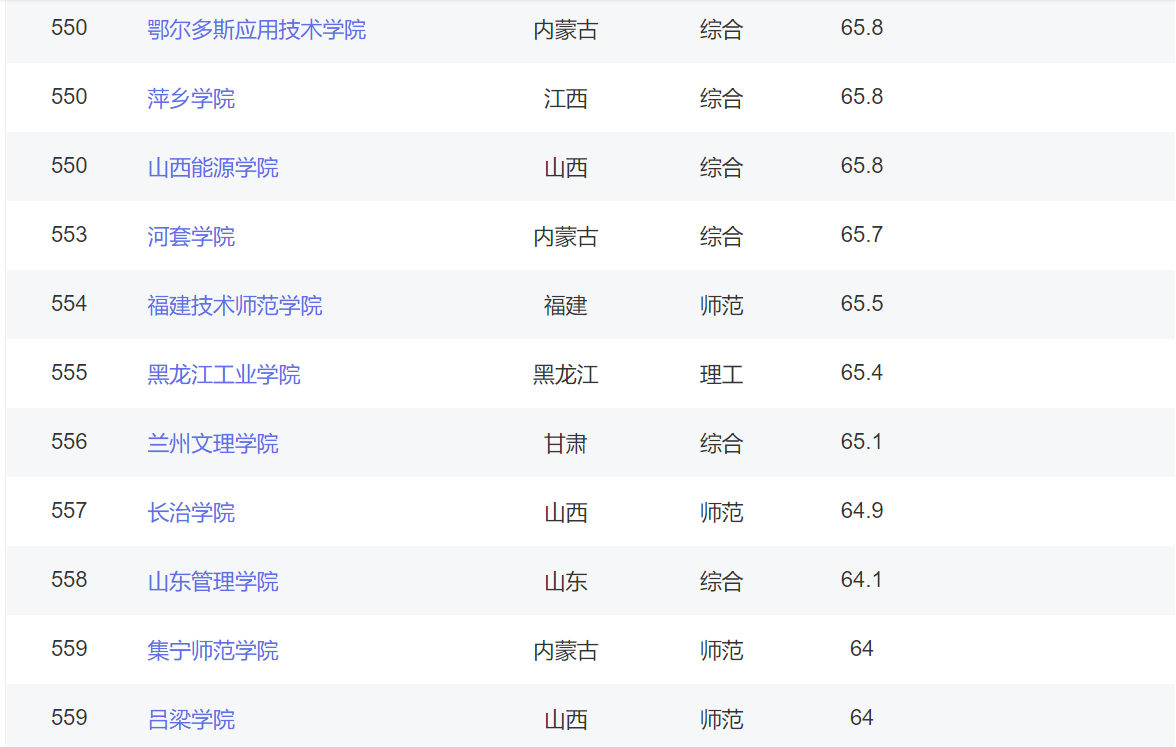
还有的学校没有简介信息:
后来通过将学校名称作为图片名称,以及以学校排名和学校名称作为联合主键等方式解决问题。
运行结果部分截图:
控制台输出
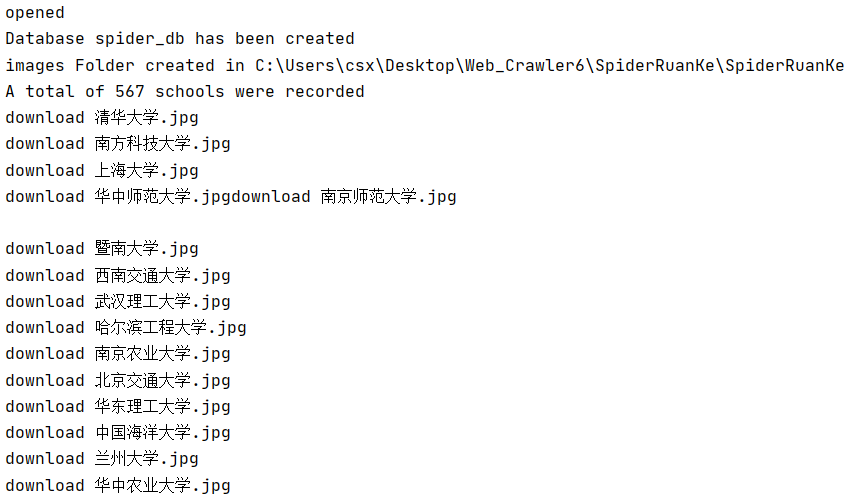

数据库存储

本地图片存储

2)心得体会:
这次实验主要温*了Scrapy+Xpath+MySQL,Scrapy是一个快速、功能强大的爬虫框架,而非函数功能库。框架中的各个模块分工明确,条理清晰,进行设计时需要有模块化设计的思想,通常用于相对大量静态的网站或网页爬取。而MySQL是最流行的关系型数据库管理系统,在数据存储技术方面扮演着重要的角色。
作业③
1)爬取mooc账户已学课程信息实验
-
作业③
-
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
- 使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
- 其中模拟登录账号环节需要录制gif图。
-
候选网站:中国mooc网:https://www.icourse163.org
-
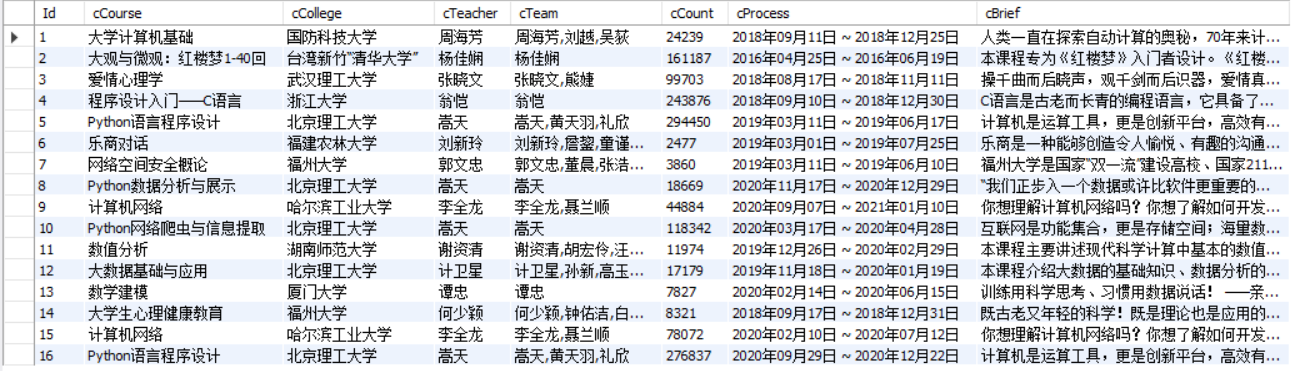
输出信息:MYSQL的输出信息如下:
Id cCourse cCollege cTeacher cTeam cCount cProcess cBrief 1 Python数据分析与展示 北京理工大学 嵩天 嵩天 18766 2020年11月17日 ~ 2020年12月29日 “我们正步入一个数据或许比软件更重要的新时代。——Tim O'Reilly” 运用数据是精准刻画事物、呈现发展规律的主要手段,分析数据展示规律,把思想变得更精细! ——“弹指之间·享受创新”,通过8周学*,你将掌握利用Python语言表示、清洗、统计和展示数据的能力。 2......
-
分析:
这个作业的重点在于利用selenium模仿用户操作浏览器。
模拟用户登录是首先要解决的问题。
通过元素定位和模拟点击可以进入到需要账号密码的登录窗口:这里提供三种登录方式。

在上一次实验中,我已经实现了默认的邮箱登录方式,这次再拓展一个手机登录方式。
没想到的是在切换到手机登录方式的过程中,我遇到了一些坎坷,程序报错信息提示定位不到元素,打印page_sourse后发现果然找不到元素信息。
怎么会呢?难道是我的定位和等待出现了问题吗?
原来是切换iframe的时机错了,上一次实验切换iframe一切顺利,所以我没有认真去研究iframe内包含哪些元素,想当然地以为整个弹窗在一个iframe中了,其实并非如此。
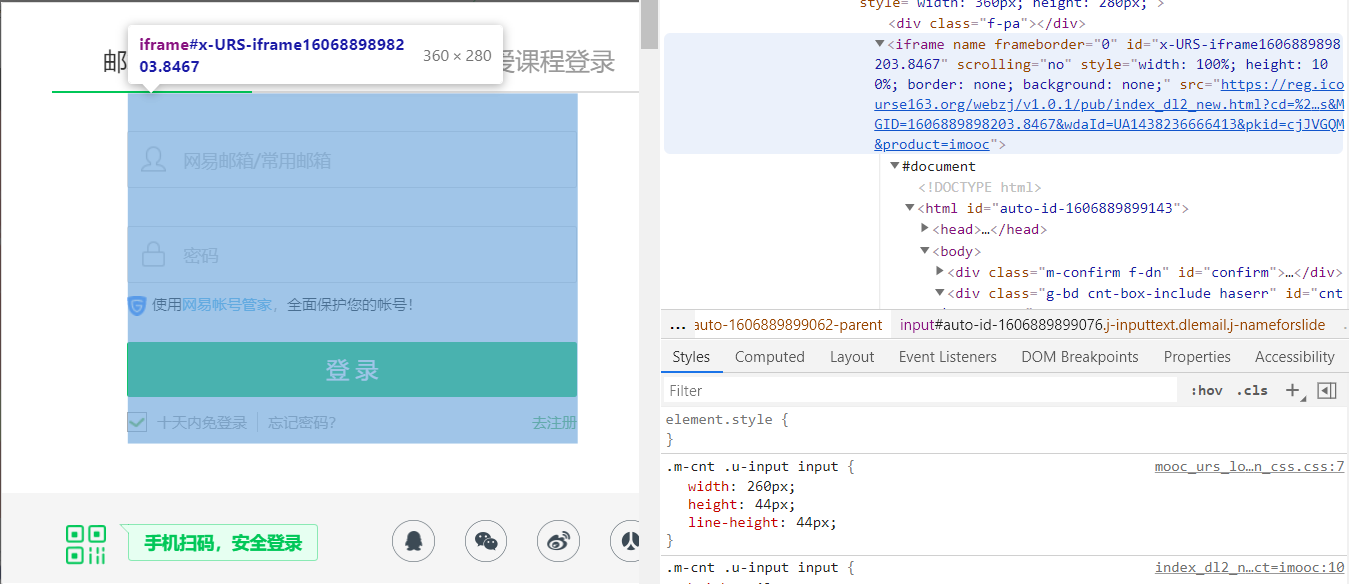
显然可以看出,上方的登录方式选择栏是不在账号密码输入框所在的iframe中的。
既然如此,只要在切换iframe之前完成定位点击,切换到手机号登录方式就好了。
切换后输入账号密码的方法和邮箱登录方式中的一致,这里为了程序的精简选择了一种可以兼容两种登录方式的定位方法。
由于没有使用过爱课程登录,而且找不到一种可以同时兼容三种登录方式的元素定位方法(否则增加工作量且代码更加冗长),所以这里没有去实现爱课程登录,不过方法是一致的。
def log_in(self):
'''模拟用户登录'''
self.get_login_interface()
choice = self.choose_login_method()
if choice == '1': # 默认邮箱登录
iframe = self.browser.find_element_by_tag_name("iframe")
self.browser.switch_to.frame(iframe)
else: # 手机号登录
phone_method = self.browser.find_element_by_xpath("//li[text()='手机号登录']")
phone_method.click()
self.short_wait()
iframe = self.browser.find_element_by_xpath("//div[@id='j-ursContainer-1']/iframe")
self.browser.switch_to.frame(iframe)
account = self.browser.find_element_by_xpath("//input[@tabindex='1']")
password = self.browser.find_element_by_xpath("//input[@tabindex='2']")
account.send_keys(input('please input your account number:\n'))
self.simulate_human()
password.send_keys(input('please input your password:\n'))
self.simulate_human()
# 模拟使用回车键进行登录
password.send_keys(Keys.ENTER)
# 释放iframe,重新回到主页面上操作
self.browser.switch_to.default_content()
self.long_wait()
登录成功之后,接下来就是定位“我的课程”按钮,模拟点击,去遍历已学课程信息了。
理想中是这样的:
可现实却是这样的:

这也就是一开始直接定位并点击失败的原因吧,虽然在页面定位的到该元素,但是点击对应位置没法实现页面跳转。
如果是真实用户的话点击关闭就好了,当然selenium也可以这么做,不过还有一种更强大的解决方式:
def enter_mycourse(self):
'''进入我的课程'''
mycourse = self.browser.find_element_by_xpath("//div[text()='我的课程']")
# mycourse.click()
# 直接点击不可见元素
self.browser.execute_script("arguments[0].click();", mycourse)
self.long_wait()
接下来进入已学课程页面
做好元素定位和模拟点击(课程框、翻页按钮)就可以实现对每个课程的遍历了(想过去并不难,虽然实现的过程有点小插曲)
点击其中一个课程框之后进入以下页面:
显然这个页面并不包含大部分所需提取的字段信息,还要继续点击上方的课程标题按钮:
直至进入到这个页面,就可以提取到所需的所有字段信息了。
由于前后操作产生了新的视窗window,所以要注意用selenium进行切换视窗以及关闭视窗返回到源视窗操作:
切换至第一个视窗:
def switch_new_window(self):
'''切换至最新视窗'''
new_window = self.browser.window_handles[-1] # 返回最新句柄(所有句柄的最后一个)
# 切换到当前最新打开的窗口
self.browser.switch_to.window(new_window)
self.long_wait()
返回至源视窗:
def switch_first_window(self):
'''切换至源视窗'''
while len(self.browser.window_handles) > 1:
self.browser.close() # 关闭当前视窗
last_window = self.browser.window_handles[-1]
self.browser.switch_to.window(last_window)
其中返回至源视窗的过程中将不需要的其他视窗全部关闭,节省系统资源。
其余数据解析以及存储等操作详见完整代码。
至此,整个获取中国mooc网账户已学课程信息的流程基本完成。
实现的过程中还有两个小插曲:
1、定位课程框莫名其妙的失败
经过了不知多少次的元素定位操作,感觉自己元素定位是一定一个准,于是在定位课程框的时候信心满满的写下了以下代码:
course_boxs = self.browser.find_elements_by_xpath("//div[class='course-card-wrapper']/div[class='box']")
还算顺利的是程序并没有报错,但是怎么定位到的元素个数是0?
我想这应该是等待的时间不够吧,睡眠不足我让他多睡一会。可惜并没有用。
那应该是我定位出现问题了吧,于是我前前后后设计了三次元素定位方法,都以失败告终。
于是我疑惑满满的在定位元素之前打印出page_sourse,仔细查看之后发现按理说应该是要定位到的。。
难道是find_elements_by_xpath本身出问题了?想至此我甚至有点脊背发凉...
冷静一想,一定是元素定位出现了问题,查看了一下xpath语法,无语了,自己做完作业1这下子把select语法混进来了。。
course_boxs = self.browser.find_elements_by_xpath("//div[@class='course-card-wrapper']/div[@class='box']")
加了一个“@”,搞定。
这整个过程就像准备出门的时候发现口袋里没有手机,于是在家里各个角落找了一番,最后发现原来手机就在手上的这种感觉。。。
2、爬取过程中莫名其妙的评价弹窗
在伸着懒腰看着程序自动爬取每一条课程信息的时候,一个评价弹窗猝不及防的跳出了:
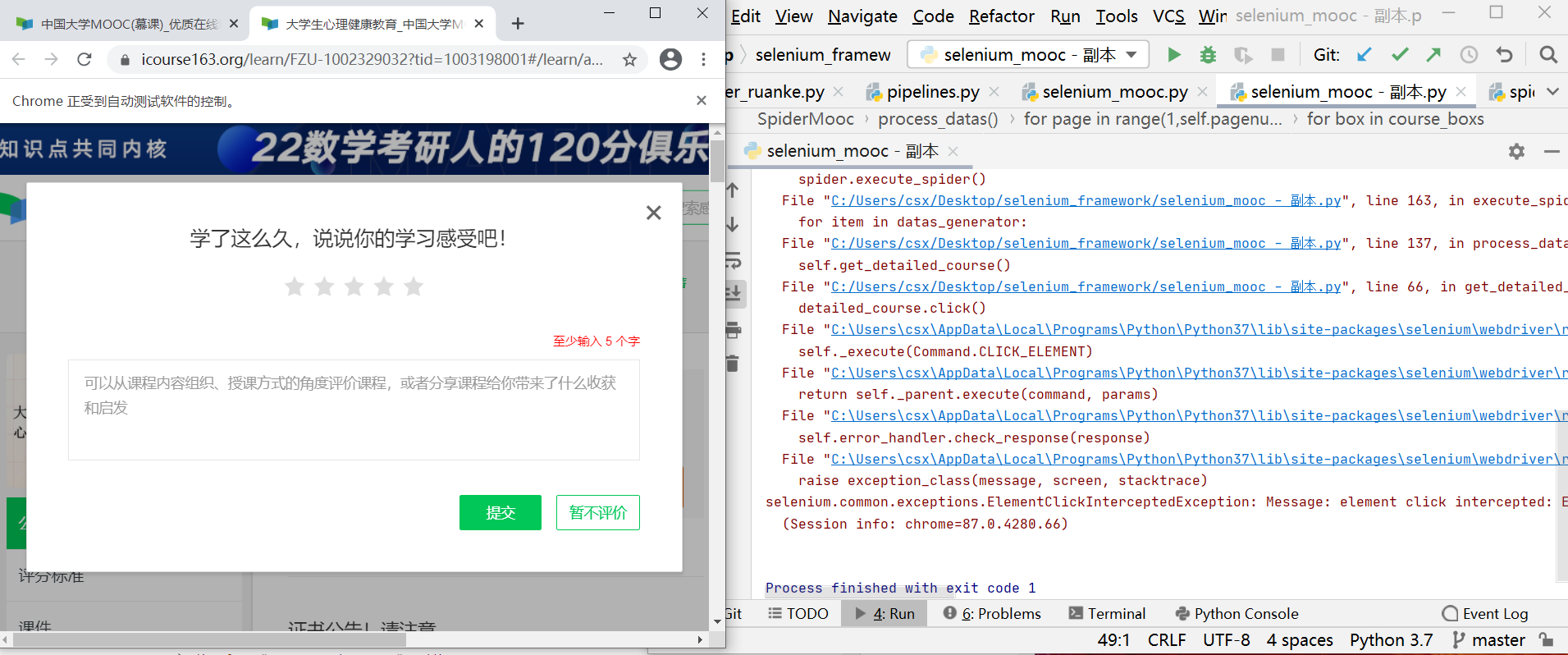
啊这,“不讲武德”?
我可以选择用try-except语句在发生异常的时候返回源窗口来逃避这个问题,不过作为一个有时候莫名执着的少年,我要直面这个问题。
当然这个问题的解决并不是太难,在发生异常的时候我去定位暂不评价按钮并点击就可以了:
def get_detailed_course(self):
'''得到课程详细信息页面'''
while True:
try:
detailed_course = self.browser.find_element_by_xpath("//h4[@class='f-fc3 courseTxt']")
# self.browser.execute_script("arguments[0].click();", detailed_course)
detailed_course.click()
break
# 如果出现评价弹窗,点击暂不评价
except Exception as err:
print(err)
back_main = self.browser.find_element_by_xpath("//span[contains(@class,'hollow-button')]")
back_main.click()
self.short_wait()
之前selenium框架都是使用Firefox驱动,这次使用的是Chrome驱动。
完整代码:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
import time
import random
import pymysql
import re
import warnings
warnings.filterwarnings('ignore')
class SpiderMooc(object):
def __init__(self):
# option = webdriver.ChromeOptions()
# option.add_argument('--headless') # 静默模式
# self.browser = webdriver.Chrome(options=option) # 创建浏览器对象
self.browser = webdriver.Chrome() # 创建浏览器对象
self.start_url = "https://www.icourse163.org" # 起始网址
self.pagenum = 2 # 设置爬取页数
self.long_time = 5 # 长等待时间
self.short_time = 1 # 短等待时间
def log_in(self):
'''模拟用户登录'''
self.get_login_interface()
choice = self.choose_login_method()
if choice == '1': # 默认邮箱登录
iframe = self.browser.find_element_by_tag_name("iframe")
self.browser.switch_to.frame(iframe)
else: # 手机号登录
phone_method = self.browser.find_element_by_xpath("//li[text()='手机号登录']")
phone_method.click()
self.short_wait()
iframe = self.browser.find_element_by_xpath("//div[@id='j-ursContainer-1']/iframe")
self.browser.switch_to.frame(iframe)
account = self.browser.find_element_by_xpath("//input[@tabindex='1']")
password = self.browser.find_element_by_xpath("//input[@tabindex='2']")
account.send_keys(input('please input your account number:\n'))
self.simulate_human()
password.send_keys(input('please input your password:\n'))
self.simulate_human()
# 模拟使用回车键进行登录
password.send_keys(Keys.ENTER)
# 释放iframe,重新回到主页面上操作
self.browser.switch_to.default_content()
self.long_wait()
def get_login_interface(self):
'''到达登录界面'''
while True: # 直到定位到登录按钮
try:
login_button = self.browser.find_element_by_xpath('//div[@class="unlogin"]/a')
break
except:
print("The login button cannot be located, please try to wait")
self.short_wait()
login_button.click()
locator = (By.XPATH, '//span[@class="ux-login-set-scan-code_ft_back"]')
WebDriverWait(driver=self.browser, timeout=10, poll_frequency=0.5) \
.until(EC.presence_of_all_elements_located(locator)) # 直到返回值为True
other_methods = self.browser.find_element_by_xpath('//span[@class="ux-login-set-scan-code_ft_back"]')
other_methods.click()
self.long_wait()
def choose_login_method(self):
'''登录方式选择'''
optional = ('1','2')
while True:
print("please choose:\n1、Login with email\n2、login by phone")
try:
choice = input()
if choice not in optional:
raise ValueError("Please follow the prompts")
break
except Exception as err:
print(err)
return choice
def enter_mycourse(self):
'''进入我的课程'''
mycourse = self.browser.find_element_by_xpath("//div[text()='我的课程']")
# mycourse.click()
# 直接点击不可见元素
self.browser.execute_script("arguments[0].click();", mycourse)
self.long_wait()
def get_detailed_course(self):
'''得到课程详细信息页面'''
while True:
try:
detailed_course = self.browser.find_element_by_xpath("//h4[@class='f-fc3 courseTxt']")
# self.browser.execute_script("arguments[0].click();", detailed_course)
detailed_course.click()
break
# 如果出现评价弹窗,点击暂不评价
except Exception as err:
print(err)
back_main = self.browser.find_element_by_xpath("//span[contains(@class,'hollow-button')]")
back_main.click()
self.short_wait()
def long_wait(self):
'''长等待'''
time.sleep(self.long_time)
def short_wait(self):
'''短等待'''
time.sleep(self.short_time)
def simulate_human(self):
'''模拟人工操作'''
simulation_time = random.uniform(0.2, 1) # 模拟人工操作的时间
time.sleep(simulation_time)
def switch_new_window(self):
'''切换至最新视窗'''
new_window = self.browser.window_handles[-1] # 返回最新句柄(所有句柄的最后一个)
# 切换到当前最新打开的窗口
self.browser.switch_to.window(new_window)
self.long_wait()
def switch_first_window(self):
'''切换至源视窗'''
while len(self.browser.window_handles) > 1:
self.browser.close() # 关闭当前视窗
last_window = self.browser.window_handles[-1]
self.browser.switch_to.window(last_window)
def turn_page(self):
'''执行翻页操作'''
try:
next_page = self.browser.find_element_by_xpath("//li[contains(@class,'next')]/a[@class='th-bk-main-gh']") # 定位
next_page.click() # 点击
self.long_wait() # 等待
except NoSuchElementException: # 如果定位不到翻页按钮元素
print("The last page has been reached, no more pages can be turned")
except Exception as err:
print(err)
def parse(self,item):
'''解析一条课程信息'''
# Id
item["id"] += 1
# cCourse
item["course"] = self.browser.find_element_by_xpath("//span[starts-with(@class,'course-title')]").text
# cCollege
item["college"] = self.browser.find_element_by_xpath("//img[@class='u-img']").get_attribute('alt')
# cTeacher and cTeam
teacher_title = self.browser.find_element_by_xpath("//div[@class='m-teachers_teacher-list']/div").text
teacher_num = int(re.findall('\d+', teacher_title)[0]) # 正则表达式提取数字
h3_list = self.browser.find_elements_by_xpath("//div[@data-cate]//h3")
item["teacher"] = h3_list[0].text # cTeacher
item["team"] = ','.join([h3.text for h3 in h3_list]) if len(h3_list) == teacher_num \
else ','.join([h3.text for h3 in h3_list]) + '...' # cTeam
# cCount
count_text = self.browser.find_element_by_xpath("//span[contains(@class,'enroll-count')]").text
item["count"] = re.findall('\d+', count_text)[0] # 正则表达式提取数字
# cProcess
item["process"] = self.browser.find_element_by_xpath("//div[contains(@class,'term-time')]/span[last()]").text
# cBrief
item["brief"] = self.browser.find_element_by_id("j-rectxt2").text
return item
def process_datas(self):
'''处理多页多课程数据'''
# 初始化
item = dict() # 数据项目字典
item["id"] = 0 # Id
# 遍历指定多页
for page in range(1,self.pagenum+1):
course_boxs = self.browser.find_elements_by_xpath("//div[@class='course-card-wrapper']/div[@class='box']")
for box in course_boxs:
box.click()
self.switch_new_window()
self.get_detailed_course()
self.switch_new_window()
item = self.parse(item)
self.switch_first_window()
yield item
print(item)
print("Article {} Course information crawling completed".format(item["id"]))
if page < self.pagenum: # 最后一页无需翻页
self.turn_page()
def execute_spider(self):
'''执行爬虫'''
print("Start the crawler")
# 初始化数据库
print("Initializing")
self.db_init()
self.create_db()
self.build_table()
# 打开预设网址
self.browser.get(self.start_url)
print("Open preset url")
self.log_in()
self.enter_mycourse()
# 处理多页多课程数据
print("Processing data")
try:
datas_generator = self.process_datas() # 返回generator对象
for item in datas_generator:
# 插入数据到数据库
self.insert_table(item)
except Exception as err:
print(self.browser.page_source)
print(err)
# 关闭数据库连接以及浏览器驱动
print("Closing")
self.close()
print("Finished")
def db_init(self):
'''初始化数据库参数'''
self.host = '127.0.0.1' # MYSQL服务器地址
self.port = 3306 # MYSQL服务器端口号
self.user = 'root' # 用户名
self.passwd = "passwd" # 密码
self.db = 'spider_db' # 数据库名称
self.charset = 'utf8' # 连接编码
self.table = 'mooc' # 设置表名
def create_db(self):
'''建立数据库'''
try:
conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
charset=self.charset)
cursor = conn.cursor()
sql_crdb = "create database if not exists {}".format(self.db)
cursor.execute(sql_crdb)
print("Database {} created".format(self.db))
except Exception as err:
print(err)
def build_table(self):
'''构建表结构'''
try:
self.con = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
db=self.db,
charset=self.charset)
self.cursor = self.con.cursor() # 使用连接对象获得cursor对象
# 如果表存在则删除
sql_drop = 'drop table if exists {}'.format(self.table)
self.cursor.execute(sql_drop)
# 如果表不存在则创建,由于之前进行删表操作,所以这里会创建新表
sql_create = 'create table if not exists {}('.format(self.table) + \
"Id int," + \
"cCourse varchar(256)," + \
"cCollege varchar(32)," + \
"cTeacher varchar(32)," + \
"cTeam varchar(256)," + \
"cCount varchar(32)," + \
"cProcess varchar(256)," + \
"cBrief varchar(1024))"
self.cursor.execute(sql_create)
except Exception as err:
print(err)
def insert_table(self,item):
'''按特定格式向表中插入数据'''
try:
sql_insert = "insert into {} (Id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief) " \
"values(%s,%s,%s,%s,%s,%s,%s,%s)".format(self.table)
self.cursor.execute(sql_insert,(item["id"], item['course'], item['college'], item['teacher'],
item['team'], item['count'], item['process'], item["brief"]))
except Exception as err:
print(err)
def close(self):
'''关闭数据库及浏览器驱动'''
try:
self.con.commit() # 用于将事务所做的修改保存到数据库
self.con.close() # 断开数据库连接
self.browser.quit() # 退出浏览器
except Exception as err:
print(err)
if __name__ == "__main__":
start = time.clock()
spider = SpiderMooc()
spider.execute_spider()
end = time.clock()
print('Running time: {} Seconds'.format(end - start))
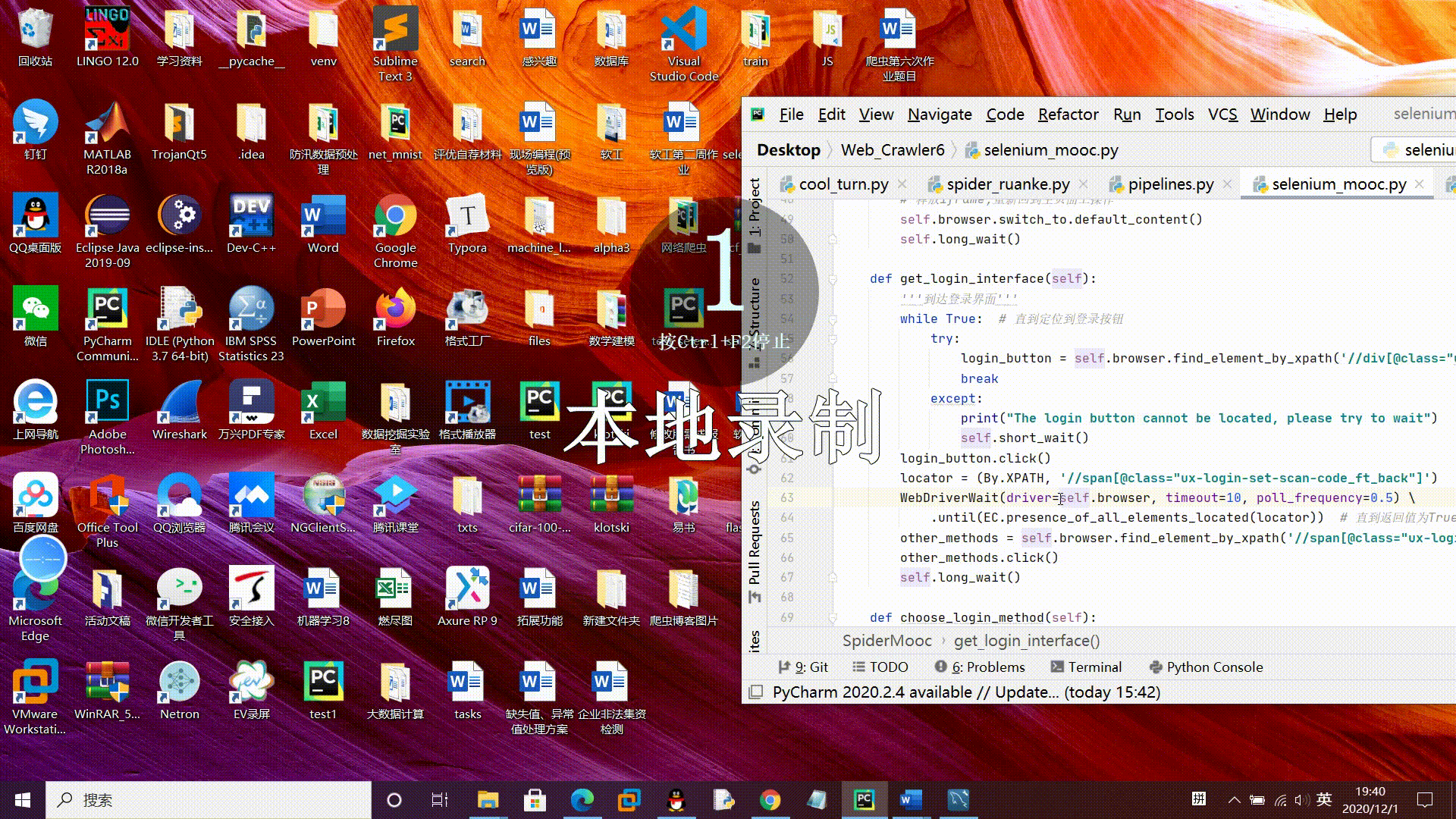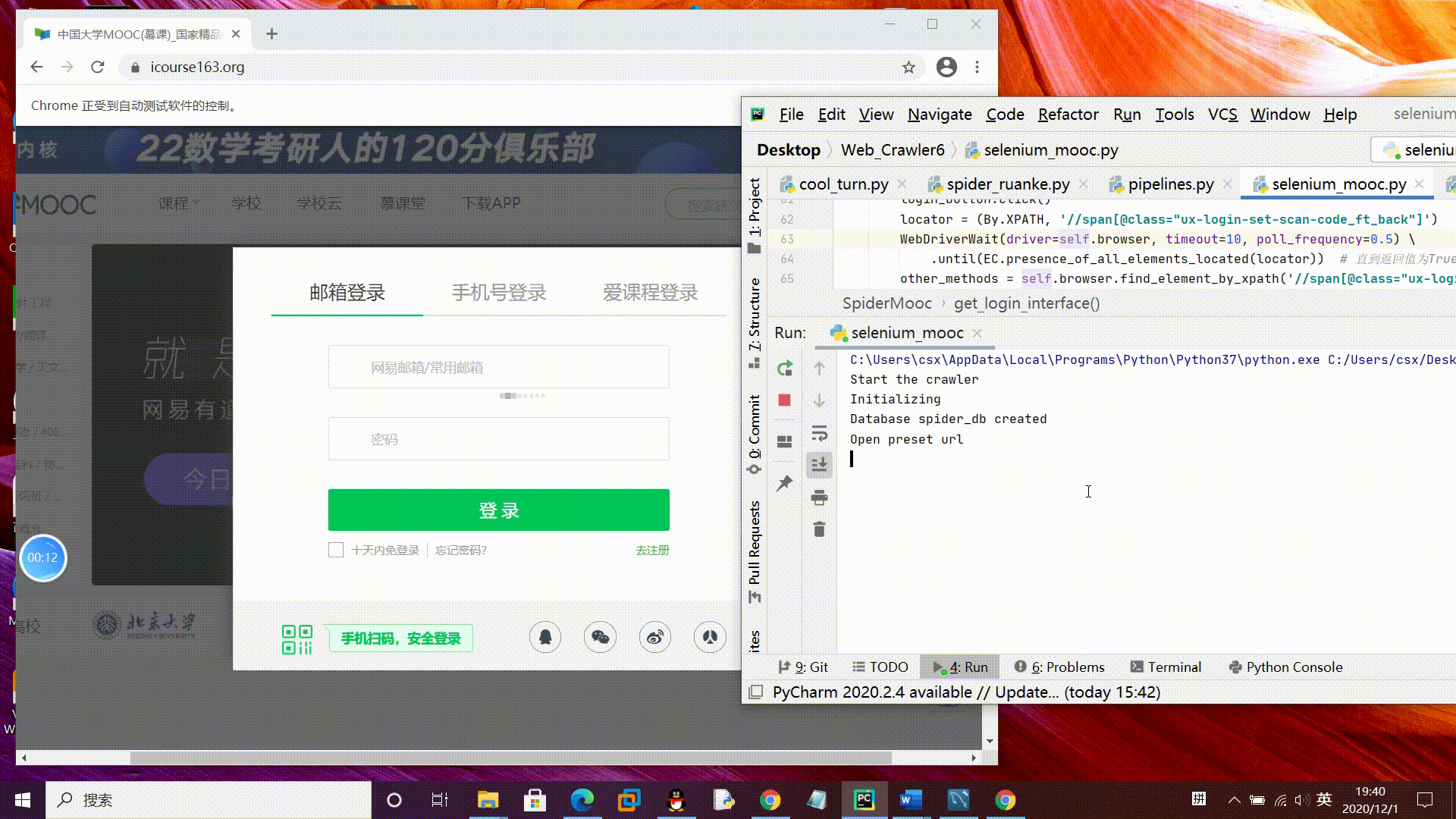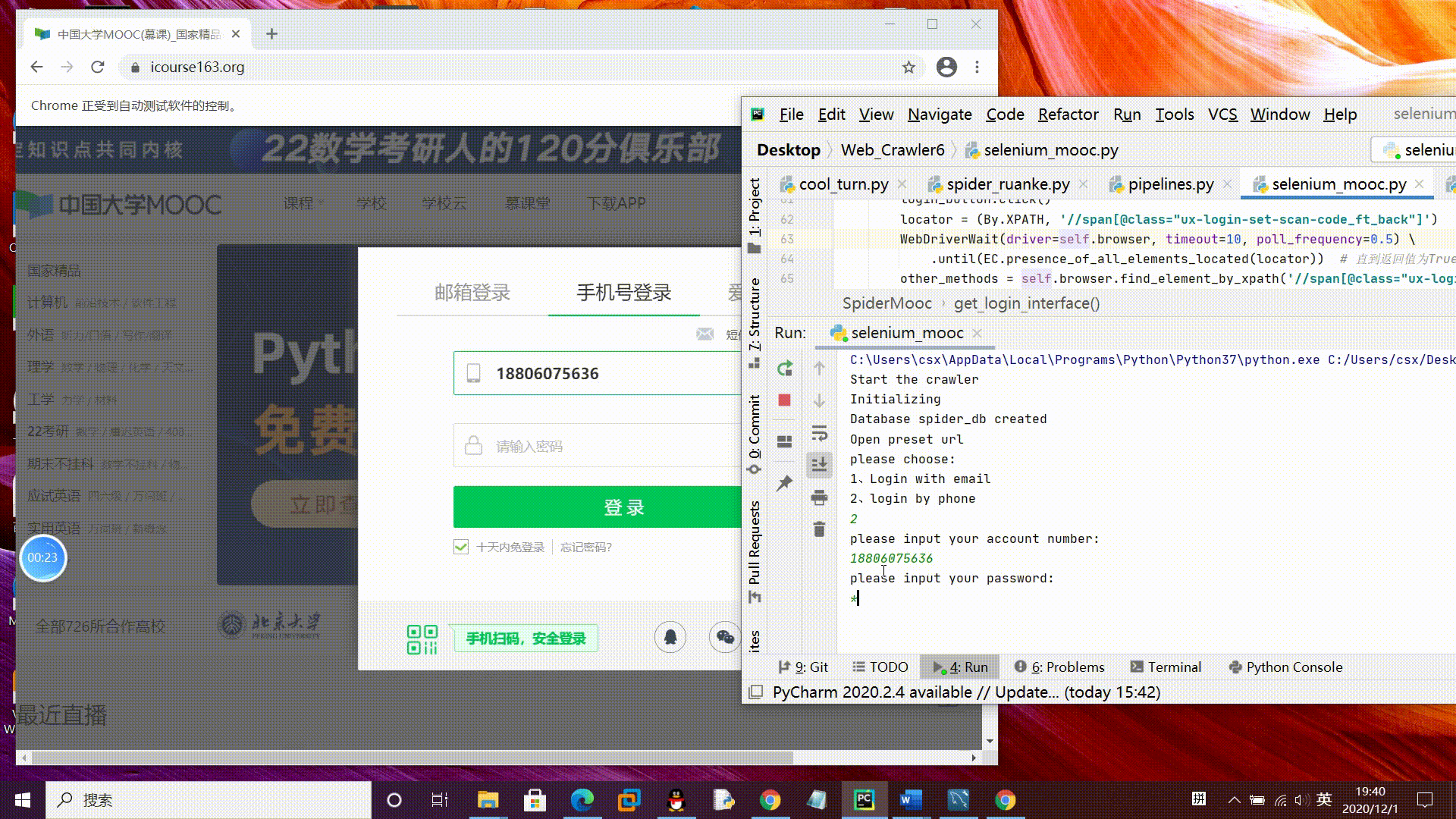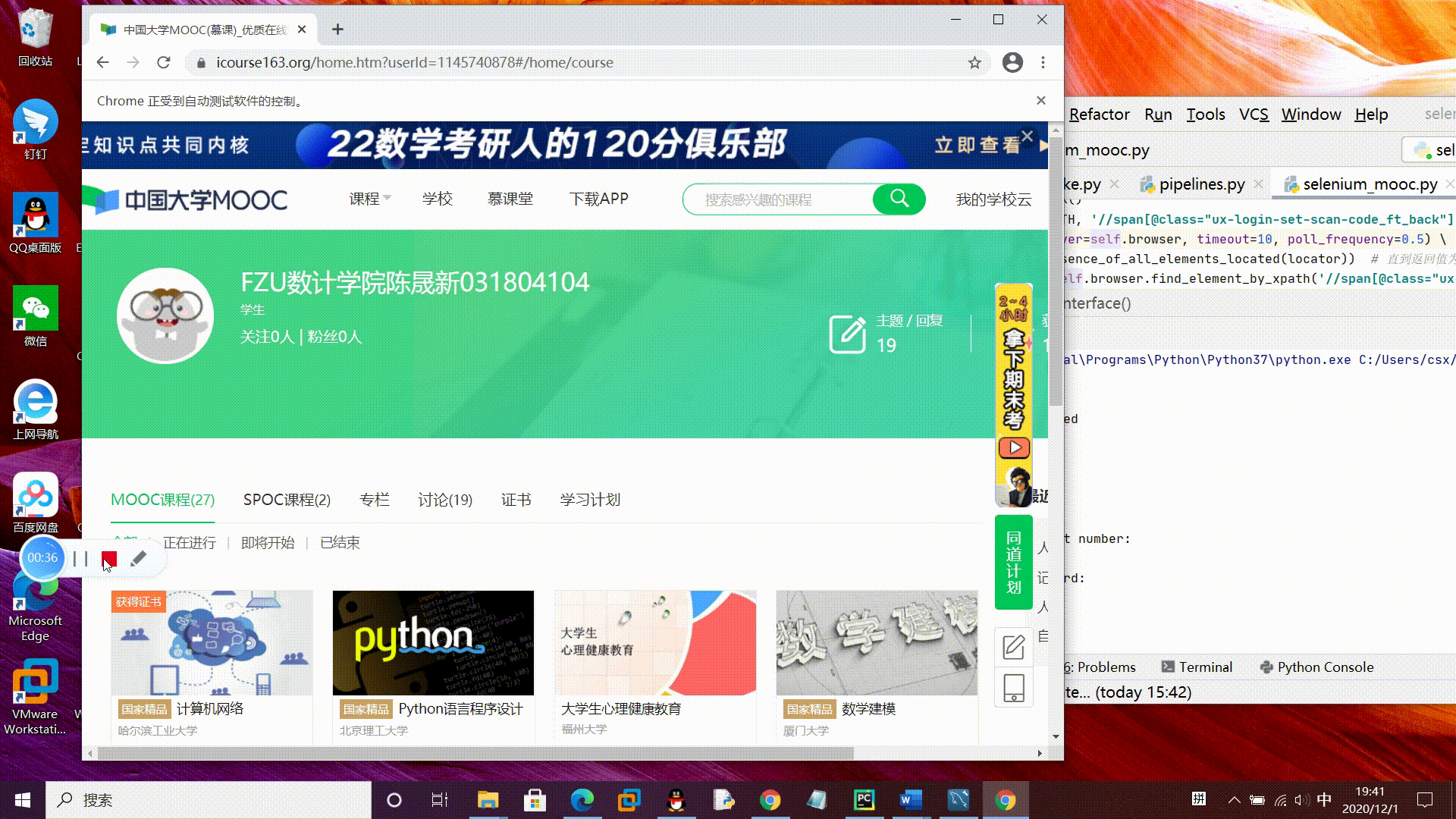
模拟登录账号gif演示:
tips:为演示模拟登录过程临时更改了一下密码,如果需要运行要在控制台输入自己的账户密码哦。
1、邮箱登录:

2、手机登录:
。
运行结果部分截图:
控制台输出


数据库存储
2)心得体会:
无疑,这次实验充分的展现了selenium模仿用户操作浏览器的魅力。selenium的功能之强大可以在处理动态网页数据的时候毫无惧色,毕竟其可以很好的模拟一个真实的用户操作浏览器,至今我仍未探明selenium的模仿用户操作的能力边界。这也是我到目前掌握的最强大的一个爬虫工具吧。
实验过程方面,也许完整代码看起来平平淡淡波澜不惊,但是实践过程可谓一波三折,常常是20%的代码却付出了80%的努力。
一次次的实践还是让自己有所收获,代码风格和爬虫技能都在这个过程中得到了成长。
网络爬虫第一次作业——结合三次小作业
网络爬虫第二次作业——天气、股票
网络爬虫第三次作业——多线程、scrapy框架
网络爬虫第四次作业——Scrapy+Xpath+MySQL
网络爬虫第五次作业——Selenium
希望能将一些自己在学*这门课程的过程中领略的风景以及收获传达给大家。
最后,课程的学*终将告一段落,但我对数据采集与融合技术的追求与探索仍在路上...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号