

记一次elasticsearch的技术分享记录
Elasticsearch技术分享
一 Es背景
今天我们要讲的es既然是个搜索引擎,那肯定是跟数据有关系的。我们知道对于一般的办公司来讲,初期是没有那么多数据的,所以很多公司比较倾向于传统的数据库例如mysql,比如我们要查一个关键字,会直接使用select语句。但是随着业务的发展,数据会不断膨胀,这样问题就来了,mysql的单表查询能力即使经过优化,极限大概也就在400W条左右,而且还会出现一些其他的问题。
所以为了解决这些问题,开始对数据库进行横向或纵向的扩容或者拆分,但是即使是这样的操作也会出现很多的问题,比如说
- 对数据库进行分库分表的话,如果出现单点故障的问题,基于主从复制的关系,运维成本会大大增加
- 其次就是,即使做了大量的维护,但对于大数据量的检索,像日志基本上都是亿级别的数据量,查询速度仍然很慢。
在这种情况下,肯定会催生新技术的诞生,首先就是luence全文检索工具,但是luence对外提供的接口过于复杂,对开发人员来说使用不是很友好,后来在luence的基础上有了solr高性能分布式检索服务框架,但是solr有一个致命缺点,在建立索引的过程中,solr的搜索能力会下降。这在一定程度上造成了solr在实时索引上效率不高。在这两款搜索引擎的教训基础上,同样是基于luence的elasticsearch应运而生。Es的特点主要是:
- 基于restful web接口进行开发,开发人员操作起来很方便
- Es扩展节点方便,用于存储和检索海量数据
- 自定发现节点,同时分片,副片机制保障数据不丢失。
二 基础概念介绍
2.1 集群,分片,节点概念介绍
在介绍es的原理之前,先来认识一下几个概念。
集群:字面意思,就是多台es服务器的结合就是es集群
节点:集群的一个服务器就是一个节点,作为集群的一部分,用来存储数据,参与集群的索引和搜索功能。
分片:将数据切分,分布的放在每个分片上,分片又被放到集群的节点上,每个分片都是独立的luence,也就是独立的索引,这样即使某个分片坏了,也不影响其他分片的查询。
大致结构看起来就是 集群--->节点---->分片
2.2 索引,类型,文档概念介绍
索引:一个索引就是一个拥有几份相似特征的文档的集合,跟我们熟悉的关系型数据库比较的话 一个索引就相当于一个数据库。
类型:在一个索引中,可以定义一种或者是多种类型,一个类型就是索引上的一个逻辑上的分区。相当于数据库中的一张表。
文档:是一个可以被索引的基础信息单元。相当于数据库表中的一条数据。
2.3数据写入索引过程
Es在写入索引的需要先写主分片,再写副分片,副分片就是在设置的主分片的时候同时设置副分片。
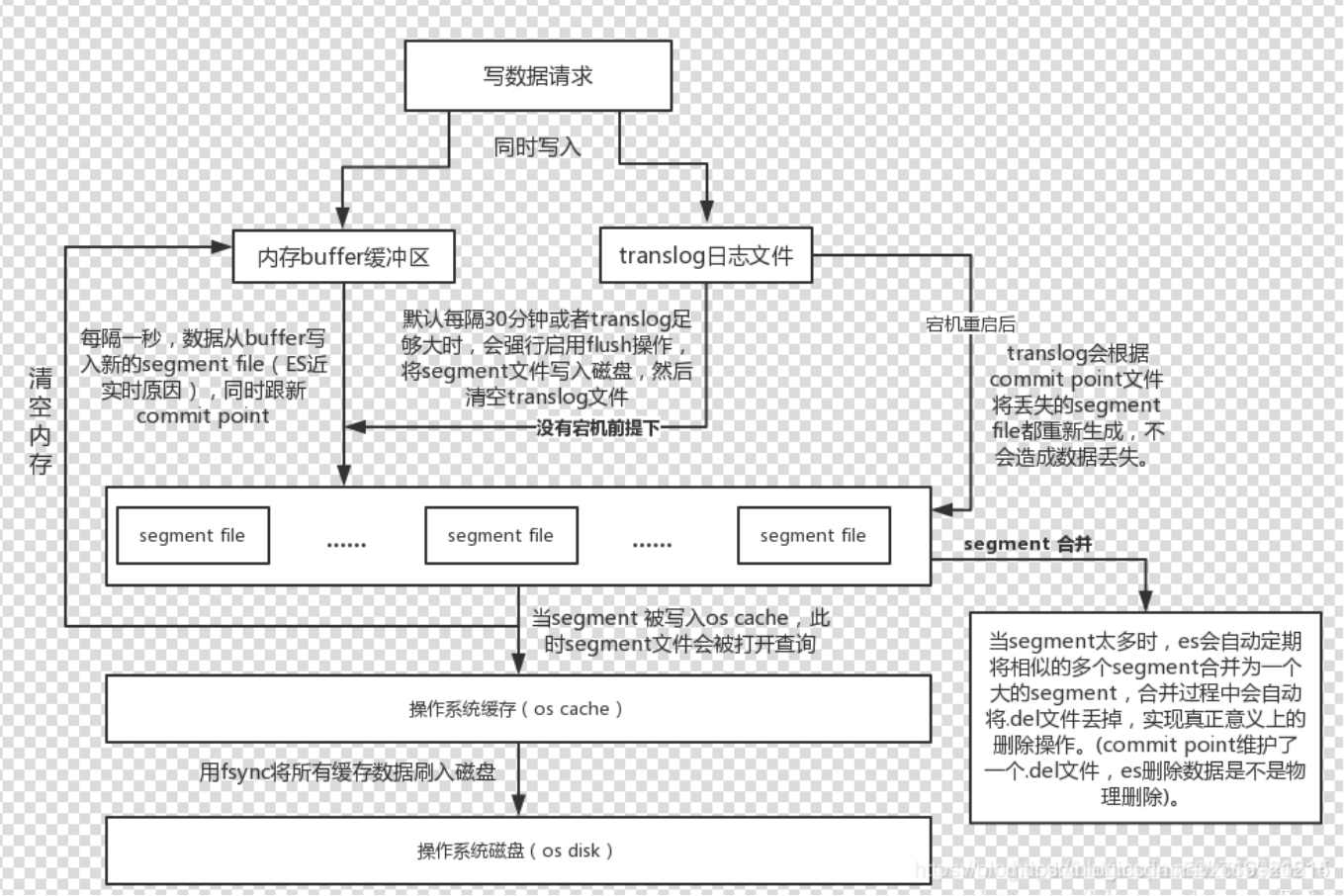
- es接受到数据源发送写数据请求时会同时将数据写入内存buffer缓存区和translog日志文件。
- 每隔1s,数据从buffer写入进的segment file中,s同时更新commit point ,segment file就是我们说的索引,被分成了很多个。
- 这些segment会被写入缓存,同时清空buffer缓冲区。
- 最后利用fsync将所有缓存数据写入磁盘。
2.3 分布式查询
我们前面说过,es的特点分片,副片机制保证数据不丢失,写入的过程也是要同时写进主副分片中,所以有可能面临这种情况,我们要检索某个东西,会发现它在好几个分片上都存在,要取得这些分片上的数据。因此Es的分布式检索查询分为两个阶段:查询阶段和取回阶段。
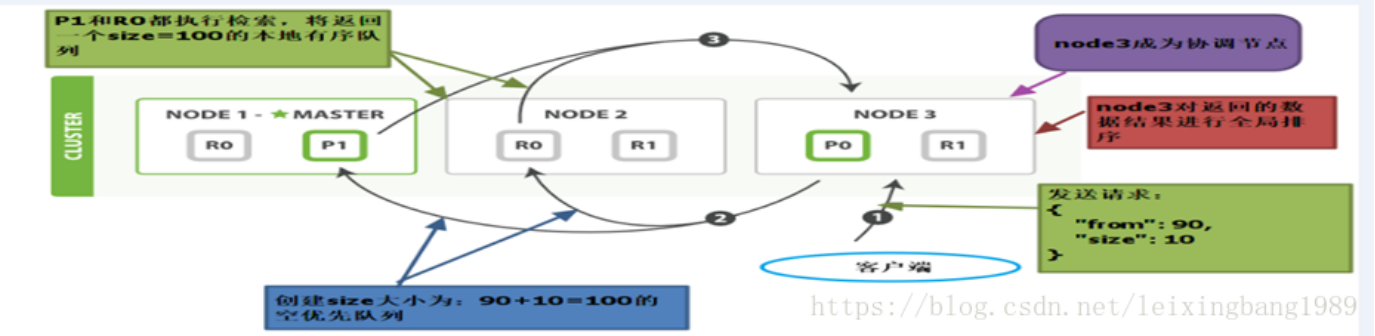
- 客户端像任意节点发送请求,比如像node3节点(node3节点成为了协调节点),协调节点并不是主节点,只作为接收请求,转发请求到其他节点,汇总各个节点返回数据的功能。
- Node3会对document进行路由,将请求转发到相应的node,比如node1和node2,node1和node2会执行查询请求,返回数据给node3
- Node3将数据排序处理返回给客户端。
三 底层实现原理
3.1 文档索引化的过程
在上面我们简单的说了es的索引检索过程,那么索引到底是怎么来的。说是索引化的过程,其实也是分词的过程。原文本到索引词的过程大概需要这么几步。
原文本要经过字符过滤器去过滤掉一部分无意义词汇,然后经过分词器拆解成词元,在经过词元过滤器变成索引词。可以看一个经过ik分词器分解后的例子。
3.2 底层数据结构(FST,倒排索引,bitmap)
3.2.1 倒排索引
|
文档编号 |
文档内容 |
|
1 |
James Ennis |
|
2 |
James Harden |
|
3 |
Justin James |
|
4 |
LeBron James |
|
5 |
James John |
经过文档索引化后:
|
索引 |
文档频率 |
倒排列表 |
|
James |
5 |
(1;1;<1>),(2;1;<1>),(3;1;<2>),(4;1;<2>) (5;1;<1>) |
|
Ennis |
1 |
|
|
Harden |
1 |
|
|
LeBron |
1 |
|
|
John |
1 |
|
不仅会记录每个分词出现的次数,还会记录这些分词在doc中的一系列信息。(1;1;<1>) 就是 在文档id为1的时候出现,出现次数为1,在第一个位置。
3.2.2 FST
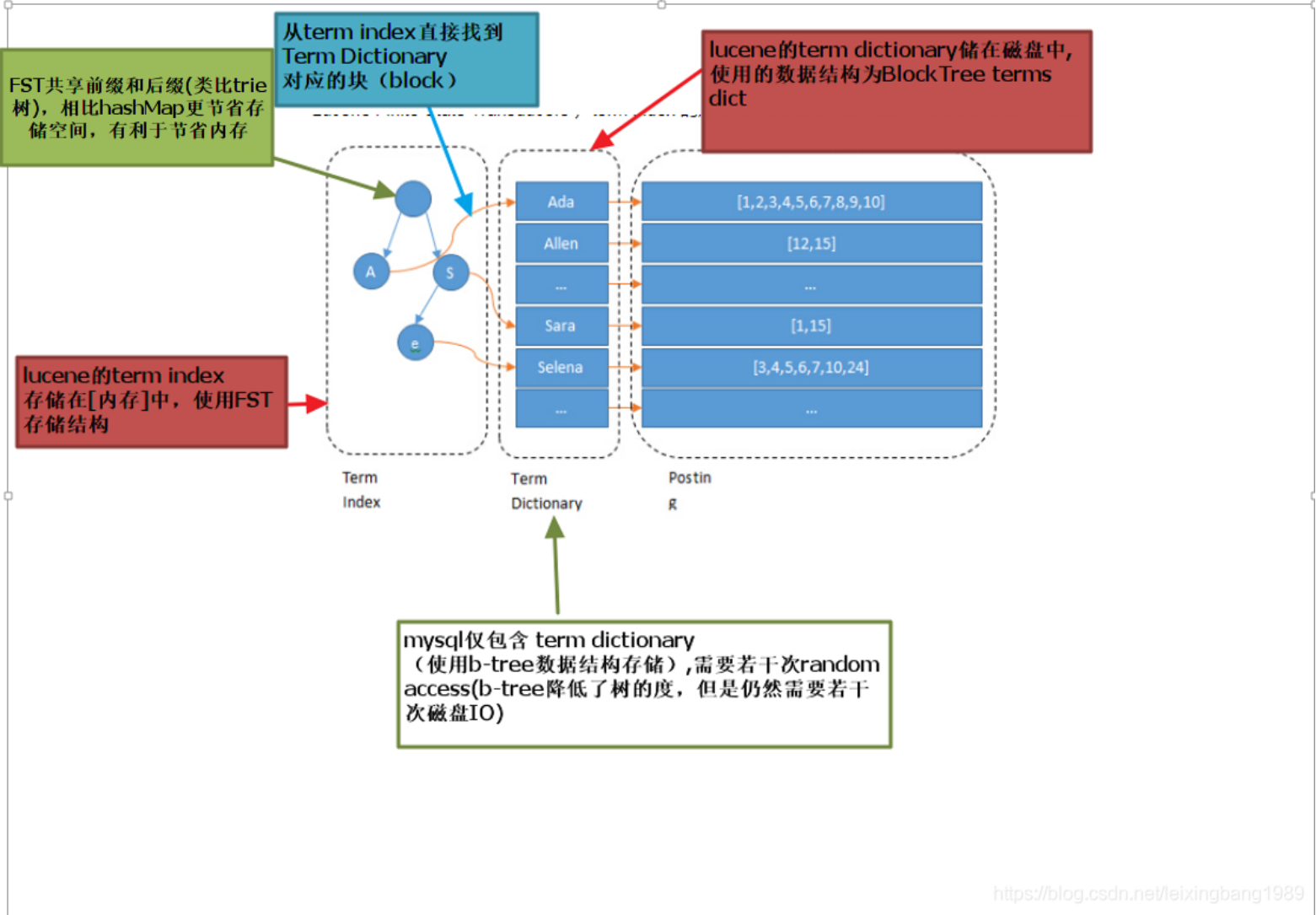
当索引建好如果没有经过处理,就这样无序排列的话,如果我们要找到Harden,可能要将索引都遍历一遍,如果索引很多的话,这样很耗时间。所以要保证索引是有序的,有序之后就可以通过快速查找的方法来找到目标。现在回想一下,前面说的将索引写入到了哪里,磁盘中,我们都知道磁盘是非常宝贵的资源,在系统中应该尽可能的减少磁盘的io的次数,所以要把一些数据放到缓存中,索引量很大的话,将索引全部放到缓存中的也不现实,需要将其压缩,压缩所用到的结构就是FST(有穷状态转换器),其实就是一个有向无环图。功能类似于字典树,通过输入字符串构建最小的有向无环图。通过这个图可能映射到索引之间的关系。经过FST压缩后的索引可能只有原来的几十分之一,这样就可以保存到内存中去了。通过图去找索引,其实也是增加了命中率,减少了查询的次数。总体的流程可以看一下图:
3.2.3 增量编码压缩
上面我们说的压缩是对索引进行压缩,有没有想过这样一种情况。如果现在es要对性别进行搜索,数据量很大的话,那么postlist里面的文档id就有几百万条。Es对postlist也有相应的压缩方案。其中一个就是增量压缩。解释起来就是大数变为小数,最后按字节存储。看一下图,假如现在有一个有序id序列,77,300,302,332,343,增量编码,将大数字变成小数字,规律就是存储增量值,然后将数据拆分成块,取块中最大的数字,然后按最低bit数字打包存储。比如说第一块最多8位。第二块最多5位,这些数据最多只需要7byte就可以存储下。
除了这种压缩方式,还有基于bitmap的压缩方式,这里由于时间的原因就不细说了,有兴趣的可以自己了解一下。
四 与mysql存储方式比较
刚才简单的了解es的一些概念和原理,我们可以比较一个es和其他存储方式的区别,常用的关系型数据库像MySQL。
Mysql我们都知道常用的存储引擎有两种,一种是myisam和innnodb,走的都是以B树为存储结构的索引。直接通过索引去找到对应的数据或者是数据的地址。其实从这样我们就可以发现es和mysql的一个区别,也是es为什么会比mysql快的原因,前面说过,es将索引通过FTS压缩成一棵树的结构,也就是term index,通过term index去找term dictionary,增加了命中率减少了磁盘的io次数,但是mysql只有这一层。
其次就是适用的场景,我们要注意一点es是一个搜索引擎,并不是一个数据库,他只适合海量数据和更新频率较低的数据,es也不支持事务。一些比较复杂的关系数据还是需要传统的关系型数据库来处理。
五 es的使用优化
在使用es的时候,我们会经常使用默认配置,es的默认配置是综合了数据可靠性,写入速度,搜索实时性等因素。有时候我们也可以根据需要进行偏向化的优化。从这几个方面:
5.1 写优化
- 批量提交。Es提供了bulk api支持批量操纵,当有大量写任务的时候,可以用bulk进行大量写入。
- 合理使用合并,前面说过当有新数据写入索引时,luence会创建一个信息segment段,segment过多的时候,es会定期合并相似的segment。合并会消耗I/O
5.2 读优化
1.避免大结果集和深翻。前面说去es的读取数据的过程,如果查询从grom到size的数据,需要在每个分片上查询排名from+size 的数据,再汇总,去最后的from+size条数据。如果from或者size很大时,需要查询的数据量很多。所以es提供了scroll的方式
例如,我们需要查询 1~100 页的数据,每页 100 条数据。
如果使用 Search 查询:每次都需要在每个分片上查询得分最高的 from+100 条数据,然后协同节点把收集到的 n×(from+100)条数据聚合起来再进行一次排序。
每次返回 from+1 开始的 100 条数据,并且要重复执行 100 次。
如果使用 Scroll 查询:在各个分片上查询 10000 条数据,协同节点聚合 n×10000 条数据进行合并、排序,并将排名前 10000 的结果快照起来。这样做的好处是减少了查询和排序的次数。
2.在查询时选择合适的路由。这个路由不是网络的路由,是来决定对哪个分片查询的,所以选择合适的路由会事半功倍。
(文中图片均来自网络,如有侵权,可以删除)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号