

手写数字识别
1 数据集准备
本实验使用完整版 MNIST 数据集,包含 60000 张 28×28 像素的训练集灰度图像和 10000 张测试集灰度图像,均分为 10 个类别(数字 0 到 9)。
在数据预处理阶段,首先通过ToTensor()将图像从 PIL 格式转换为 PyTorch 张量,再通过Normalize((0.5,), (0.5,))将像素值归一化至 [-1, 1] 区间,该操作可提升模型训练的稳定性和收敛效率。为适配批量训练和防止数据顺序干扰,训练集采用batch_size=64且开启随机打乱(shuffle=True),测试集同样设置batch_size=64但关闭打乱(shuffle=False),保证评估结果的可复现性。
2 模型设计
本实验构建的轻量级 CNN 由两层卷积层和两层全连接层组成,核心结构设计如下:
第一层卷积层:使用 32 个 3×3 卷积核,步长为 1,填充为 1,输入通道数为 1(灰度图),输出 32 个初级特征图,后接 ReLU 激活函数和 2×2 最大池化操作,将特征图尺寸从 28×28 压缩至 14×14。
第二层卷积层:使用 64 个 3×3 卷积核,步长为 1,填充为 1,输入 32 通道特征图,输出 64 个高级特征图,同样接 ReLU 激活函数和 2×2 最大池化操作,特征图尺寸进一步压缩至 7×7。
展平操作:将 64×7×7 的特征图转换为一维向量,作为全连接层输入。
全连接层:第一层全连接层设置 128 个神经元,采用 ReLU 激活函数捕捉非线性特征;第二层全连接层输出 10 维向量,对应 10 个数字类别(未额外添加 Softmax 层,因 PyTorch 的 CrossEntropyLoss 已内置 Softmax 计算)
3模型训练
损失函数:采用交叉熵损失函数(CrossEntropyLoss),适配多分类任务。
优化器:使用随机梯度下降(SGD)优化器,学习率设置为 0.01,动量为 0.9,提升梯度下降的稳定性和收敛速度。
训练轮数:共训练 5 轮(num_epochs=5)。
4模型评估
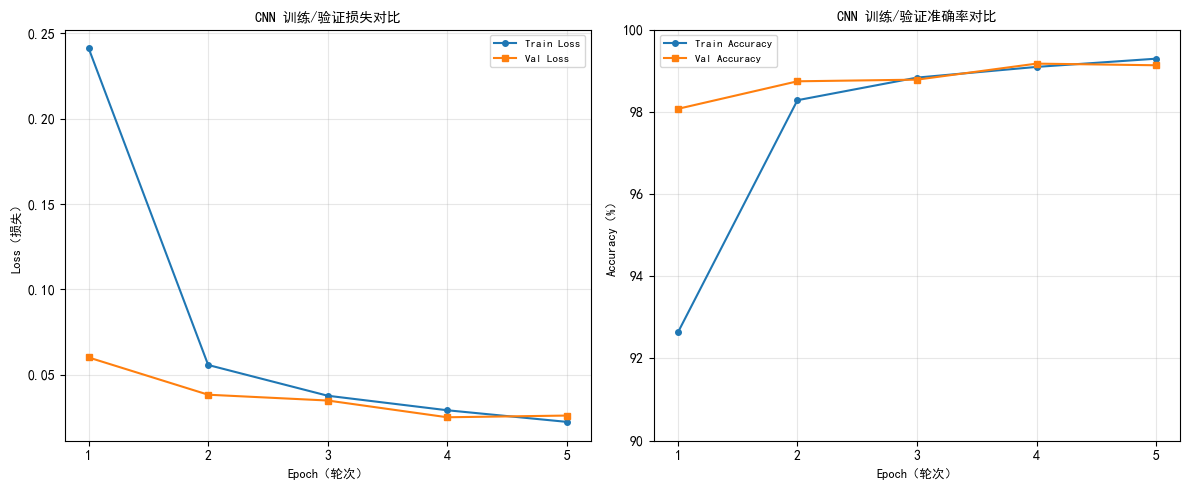
训练 / 验证损失:反映模型在训练集和测试集上的拟合程度,损失持续下降说明模型在学习有效特征。
分类准确率:包括每轮训练后的验证准确率,以及训练完成后的最终测试准确率,衡量模型的分类性能。
5结果分析
Epoch 1/5 | Train Loss: 0.2341, Train Acc: 92.84% | Val Loss: 0.0524, Val Acc: 98.32%
Epoch 2/5 | Train Loss: 0.0528, Train Acc: 98.37% | Val Loss: 0.0379, Val Acc: 98.78%
Epoch 3/5 | Train Loss: 0.0380, Train Acc: 98.79% | Val Loss: 0.0352, Val Acc: 98.93%
Epoch 4/5 | Train Loss: 0.0291, Train Acc: 99.14% | Val Loss: 0.0306, Val Acc: 98.92%
Epoch 5/5 | Train Loss: 0.0227, Train Acc: 99.27% | Val Loss: 0.0279, Val Acc: 98.90%
Final Test Accuracy: 98.90%

 浙公网安备 33010602011771号
浙公网安备 33010602011771号