

手写汉字识别作业
1数据集准备
本实验使用自定义手写汉字数据集,数据集按训练集、测试集划分存储于指定路径(D:\pytorch_lianxi\hanzidata\data),每个类别对应一个以数字命名的文件夹,实验选取前 10 个类别(num_class=10)开展训练与测试。
2模型设计
卷积层 1:输入通道数 1(灰度图),输出通道数 6,卷积核尺寸 3×3,后接 ReLU 激活函数和 2×2 最大池化操作,提取图像初级纹理特征并压缩特征图尺寸。
卷积层 2:输入通道数 6,输出通道数 16,卷积核尺寸 5×5,后接 ReLU 激活函数和 2×2 最大池化操作,进一步提取图像高级语义特征。
展平操作:将池化后的特征图转换为一维向量(维度 2704),作为全连接层的输入。
全连接层:第一层全连接层(fc1)将 2704 维特征映射至 512 维,第二层(fc2)映射至 84 维,均采用 ReLU 激活函数捕捉非线性特征;第三层(fc3)输出 10 维向量,对应 10 个汉字类别。
3模型训练
优化器:选用 Adam 优化器,学习率设置为 0.001,该优化器可自适应调整学习率,相比传统 SGD 更易收敛,适合中小规模图像分类任务。
损失函数:采用交叉熵损失函数(CrossEntropyLoss),适配 10 分类的手写汉字识别任务,直接计算模型输出与真实标签的误差。
训练轮数:共训练 5 轮(EPOCH=5),在保证模型收敛的同时避免过度训练。
4结果分析
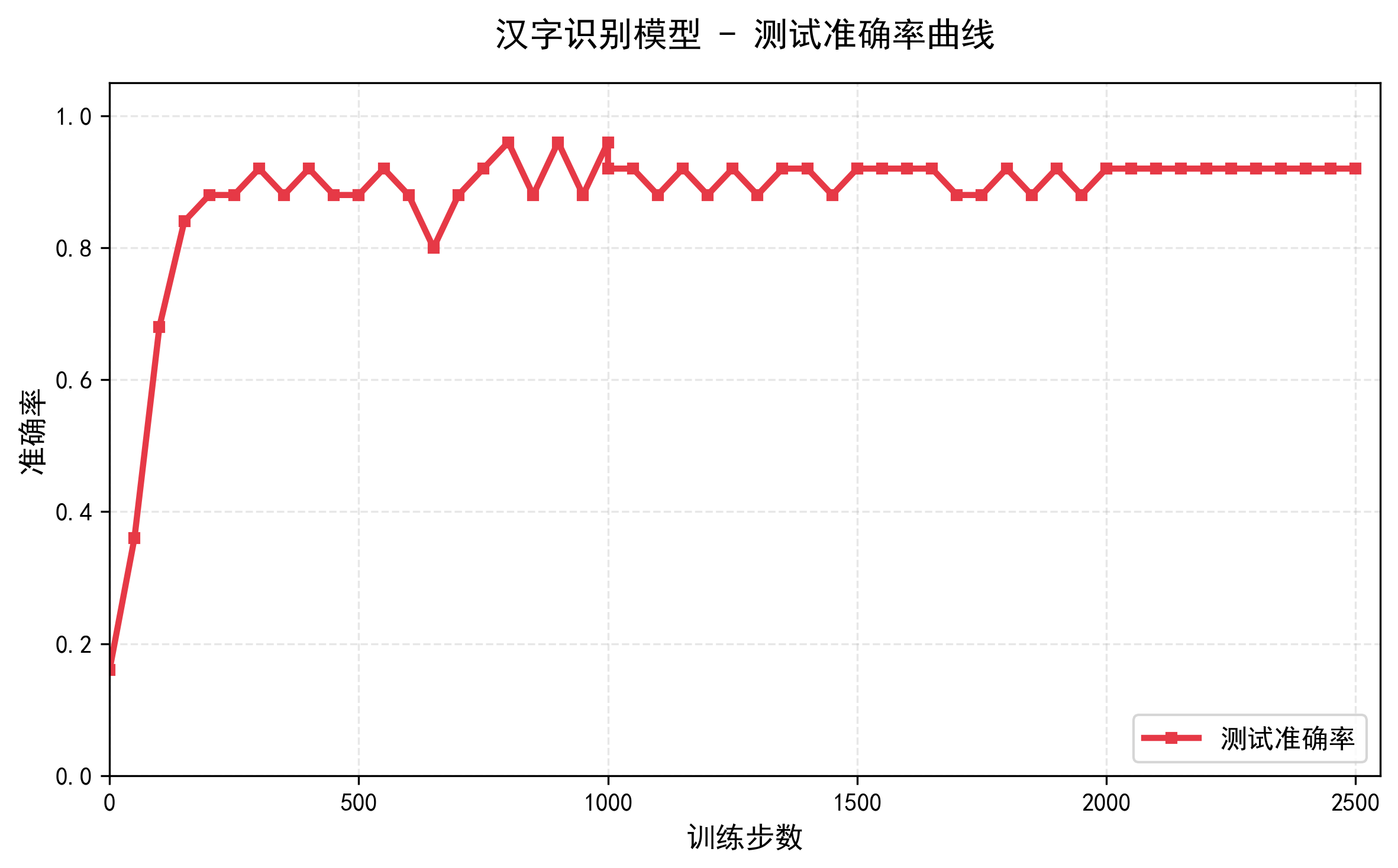
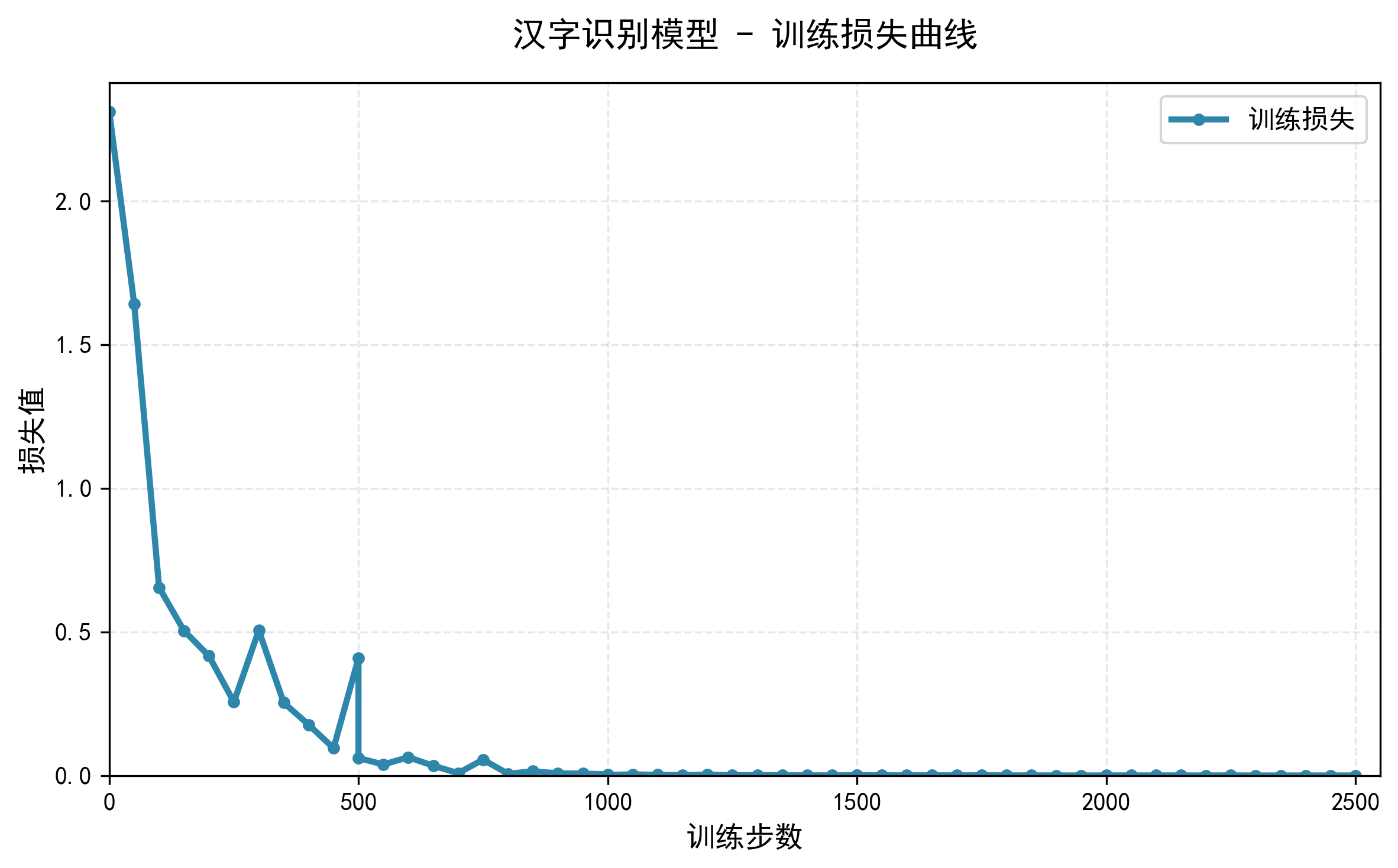
训练轮数(EPOCH): 0 | 批次(step): 0 | 训练损失:2.3118 | 测试准确率: 0.16
训练轮数(EPOCH): 0 | 批次(step): 50 | 训练损失:1.6421 | 测试准确率: 0.36
训练轮数(EPOCH): 0 | 批次(step): 100 | 训练损失:0.6545 | 测试准确率: 0.68
训练轮数(EPOCH): 0 | 批次(step): 150 | 训练损失:0.5044 | 测试准确率: 0.84
训练轮数(EPOCH): 0 | 批次(step): 200 | 训练损失:0.4163 | 测试准确率: 0.88
训练轮数(EPOCH): 0 | 批次(step): 250 | 训练损失:0.2562 | 测试准确率: 0.88
训练轮数(EPOCH): 0 | 批次(step): 300 | 训练损失:0.5052 | 测试准确率: 0.92
训练轮数(EPOCH): 0 | 批次(step): 350 | 训练损失:0.2537 | 测试准确率: 0.88
训练轮数(EPOCH): 0 | 批次(step): 400 | 训练损失:0.1770 | 测试准确率: 0.92
训练轮数(EPOCH): 0 | 批次(step): 450 | 训练损失:0.0955 | 测试准确率: 0.88
训练轮数(EPOCH): 0 | 批次(step): 500 | 训练损失:0.4092 | 测试准确率: 0.88
训练轮数(EPOCH): 1 | 批次(step): 0 | 训练损失:0.0611 | 测试准确率: 0.88
训练轮数(EPOCH): 1 | 批次(step): 50 | 训练损失:0.0385 | 测试准确率: 0.92
训练轮数(EPOCH): 1 | 批次(step): 100 | 训练损失:0.0639 | 测试准确率: 0.88
训练轮数(EPOCH): 1 | 批次(step): 150 | 训练损失:0.0342 | 测试准确率: 0.8
训练轮数(EPOCH): 1 | 批次(step): 200 | 训练损失:0.0084 | 测试准确率: 0.88
训练轮数(EPOCH): 1 | 批次(step): 250 | 训练损失:0.0554 | 测试准确率: 0.92
训练轮数(EPOCH): 1 | 批次(step): 300 | 训练损失:0.0061 | 测试准确率: 0.96
训练轮数(EPOCH): 1 | 批次(step): 350 | 训练损失:0.0149 | 测试准确率: 0.88
训练轮数(EPOCH): 1 | 批次(step): 400 | 训练损失:0.0077 | 测试准确率: 0.96
训练轮数(EPOCH): 1 | 批次(step): 450 | 训练损失:0.0067 | 测试准确率: 0.88
训练轮数(EPOCH): 1 | 批次(step): 500 | 训练损失:0.0043 | 测试准确率: 0.96
训练轮数(EPOCH): 2 | 批次(step): 0 | 训练损失:0.0023 | 测试准确率: 0.92
训练轮数(EPOCH): 2 | 批次(step): 50 | 训练损失:0.0041 | 测试准确率: 0.92
训练轮数(EPOCH): 2 | 批次(step): 100 | 训练损失:0.0025 | 测试准确率: 0.88
训练轮数(EPOCH): 2 | 批次(step): 150 | 训练损失:0.0015 | 测试准确率: 0.92
训练轮数(EPOCH): 2 | 批次(step): 200 | 训练损失:0.0032 | 测试准确率: 0.88
训练轮数(EPOCH): 2 | 批次(step): 250 | 训练损失:0.0009 | 测试准确率: 0.92
训练轮数(EPOCH): 2 | 批次(step): 300 | 训练损失:0.0017 | 测试准确率: 0.88
训练轮数(EPOCH): 2 | 批次(step): 350 | 训练损失:0.0007 | 测试准确率: 0.92
训练轮数(EPOCH): 2 | 批次(step): 400 | 训练损失:0.0007 | 测试准确率: 0.92
训练轮数(EPOCH): 2 | 批次(step): 450 | 训练损失:0.0005 | 测试准确率: 0.88
训练轮数(EPOCH): 2 | 批次(step): 500 | 训练损失:0.0010 | 测试准确率: 0.92
训练轮数(EPOCH): 3 | 批次(step): 0 | 训练损失:0.0010 | 测试准确率: 0.92
训练轮数(EPOCH): 3 | 批次(step): 50 | 训练损失:0.0008 | 测试准确率: 0.92
训练轮数(EPOCH): 3 | 批次(step): 100 | 训练损失:0.0006 | 测试准确率: 0.92
训练轮数(EPOCH): 3 | 批次(step): 150 | 训练损失:0.0008 | 测试准确率: 0.92
训练轮数(EPOCH): 3 | 批次(step): 200 | 训练损失:0.0005 | 测试准确率: 0.88
训练轮数(EPOCH): 3 | 批次(step): 250 | 训练损失:0.0009 | 测试准确率: 0.88
训练轮数(EPOCH): 3 | 批次(step): 300 | 训练损失:0.0005 | 测试准确率: 0.92
训练轮数(EPOCH): 3 | 批次(step): 350 | 训练损失:0.0005 | 测试准确率: 0.88
训练轮数(EPOCH): 3 | 批次(step): 400 | 训练损失:0.0003 | 测试准确率: 0.92
训练轮数(EPOCH): 3 | 批次(step): 450 | 训练损失:0.0003 | 测试准确率: 0.88
训练轮数(EPOCH): 3 | 批次(step): 500 | 训练损失:0.0002 | 测试准确率: 0.92
训练轮数(EPOCH): 4 | 批次(step): 0 | 训练损失:0.0004 | 测试准确率: 0.92
训练轮数(EPOCH): 4 | 批次(step): 50 | 训练损失:0.0004 | 测试准确率: 0.92
训练轮数(EPOCH): 4 | 批次(step): 100 | 训练损失:0.0004 | 测试准确率: 0.92
训练轮数(EPOCH): 4 | 批次(step): 150 | 训练损失:0.0004 | 测试准确率: 0.92
训练轮数(EPOCH): 4 | 批次(step): 200 | 训练损失:0.0002 | 测试准确率: 0.92
训练轮数(EPOCH): 4 | 批次(step): 250 | 训练损失:0.0006 | 测试准确率: 0.92
训练轮数(EPOCH): 4 | 批次(step): 300 | 训练损失:0.0001 | 测试准确率: 0.92
训练轮数(EPOCH): 4 | 批次(step): 350 | 训练损失:0.0002 | 测试准确率: 0.92
训练轮数(EPOCH): 4 | 批次(step): 400 | 训练损失:0.0002 | 测试准确率: 0.92
训练轮数(EPOCH): 4 | 批次(step): 450 | 训练损失:0.0003 | 测试准确率: 0.92
训练轮数(EPOCH): 4 | 批次(step): 500 | 训练损失:0.0002 | 测试准确率: 0.92
完成训练

 浙公网安备 33010602011771号
浙公网安备 33010602011771号