


2017-2018-1 20155229 《信息安全系统设计基础》第十三周学习总结
2017-2018-1 20155229 《信息安全系统设计基础》第十三周学习总结
对“第二章 信息的表示和处理”的深入学习
- 这周的任务是选一章认为最重要的进行学习,我选择了第二章。当今的计算机存储和处理信息基本上是由二进制(位)组成,二进制能够很容易的被表示、存储和传输。当把位组合在一起,再加上某种解释,即给不同的可能位模式赋予含义,我们就能表示任何有限集合的元素。而正因为信息表示和处理是计算机最基础的东西,我认为弄懂基础是很有必要的。
第二章主要是研究计算机上如何表示数字和其他形式数据的基本属性,以及计算机对这些数据执行操作的属性,计算机系统规定了三种重要的编码方式:无符号编码、补码编码、浮点数编码。
无符号编码:基于传统的二进制表示法,表示大于或等于0的数字。
补码编码:表述有符号整数的常见方式,正或负的数字。
浮点数编码:表示实数的科学计数法的以二进制为技术的版本。
将本章分为三个模块
一、信息存储
二、整数表示及运算
三、浮点数
一、信息存储
大端小端
大端模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
小端模式,是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中。
1.为什么会有大小端之分
在计算机系统中,是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式.但是,大端小端没有谁优谁劣,各自优势便是对方劣势
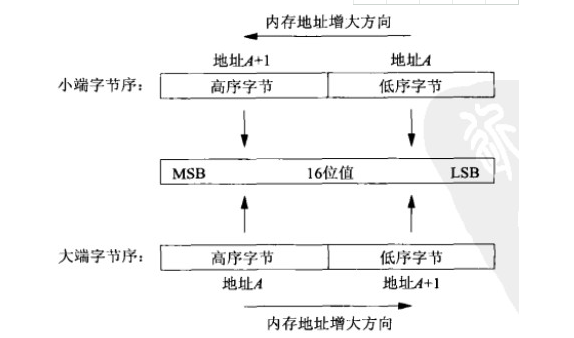
eg.一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。而对于小端模式,恰好相反
2.判断机器的大小端
#include <stdio.h>
/*联合*/
union node
{
int num;
char ch;
}
int main()
{
union node p;
//方法一
p.num = 0x12345678;
if (p.ch == 0x78)
{
printf("Little endian\n");
}
else
{
printf("Big endian\n");
}
return 0;
}

- 所以Linux是小端的
3.如何进行转换
对于字数据(16位)
#define BigtoLittle16(A) (( ((uint16)(A) & 0xff00) >> 8) | \
(( (uint16)(A) & 0x00ff) << 8))
对于双子数据(32位)
#define BigtoLittle32(A) ((( (uint32)(A) & 0xff000000) >> 24) | \
(( (uint32)(A) & 0x00ff0000) >> 8) | \
(( (uint32)(A) & 0x0000ff00) << 8) | \
(( (uint32)(A) & 0x000000ff) << 24))
判断CPU的大小端
int a = 1;
if ((char)a == 1) //取最低地址的一个字节
cout << "小端序" << endl;
else
cout << "大端序" << endl;
数据类型
- 数据类型在数据结构中的定义是一个值的集合以及定义在这个值集上的一组操作。
- 数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以充分利用内存。
- 数据类型的具体实现由计算机的体系结构决定。
![]()

typedef命名数据类型
- 用typedef可以声明各种类型名,但不能用来定义变量,用typedef可以声明数组类型、字符串类型、使用比较方便。
- typedef与#define有相似之处,但事实上二者是不同的,#define是在 预编译 时处理,它只能做简单的字符串替换,而typedef是在 编译时 处理的。
- 用typedef只是对已经存在的类型增加一个类型名,而没有创造新的类型。
位操作和逻辑运算
模数运算
- 模:是运算结果超出实际数据表示范围的溢出量,它等于数的最大值加1.
- 计算机只能进行非负的模数加法。
eg.
50+80=(1)30。
因为字长限制,运算结果自动舍去溢出量,只保留小于模的部分,这种受模限制的运算叫模数运算。
c的位级运算
- | 就是OR(或),&就是AND(与),~就是NOT(取反),而^就是EXCLUSIVE-OR(异或)
- 可用于任何整型数据:unsigned,long long int ,long,int short ,char
c逻辑运算
- 逻辑运算符:&&、||、!
- 总是返回0或1,是整数的布尔运算,返回0表示“假”,返回1表示“真”。
1、逻辑短路与运算
#include <stdio.h>
int main()
{
int a=5,b=6,c=7,d=8,m=2,n=2;
(m=a>b)&&(n=c>d);
printf("%d\t%d",m,n);
return 0;
}
输出的结果为0,2。因为a>b为0,m=0,整个“与”逻辑判断就为“假”,所以后面的“c>d”就被短路掉了,所以n还是等于原先的2。

2.逻辑运算或运算
#include <stdio.h>
int main()
{
int a=5,b=6,c=7,d=8,m=2,n=2;
(m=a<b)||(n=c>d);
printf("%d\t%d",m,n);
return 0;
}
输出的结果为1,2。因为a<b,m=1,这个“或”逻辑就被“短路”掉了,后面的语句就没被执行,所以n还是等于原先的2

c移位操作
左移:x<<y
- 向量x向左移y个位置,丢弃左边额外的位,右边用0填充
右移:x>>y
- 向量x向右移动y个位置,丢弃右边额外的为,左边用0填充(逻辑右移),复制最高位用于整数的补码表示(算术右移)
c和java对右移的规定
-
c语标准并没有明确定义应该使用哪种类型的右移。对于无符号数据,右移必须是逻辑的,对于有符号数据,算术的或者逻辑的右移都可以,实际上,几乎所有的编译器/机器组合都对有符号数据使用算术右移。
-
Java有明确的右移定义。表达式x>>k会将x算术右移K个位置,而x>>>k会对x做逻辑右移。
-
当移动位数k大于等于字长w,实际上位移量就是通过计算k mod w 得到的。
返回分类
二、整数表示及运算
整数是现实世界中使用最多的数,在计算机系统中,为整数定义了很多数据类型。
无符号和补码编码
数字编码
数字信息的编码方式:将数字x经过某种数学变换之后得到的另一个数字x1作为其编码,这个数字x1常常写成位向量形式。
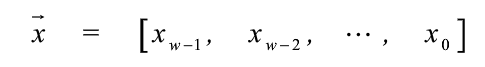
- 实际的应用常需要无符号数的编码或有符号数的编码,前者称为无符号编码,后者称为二进制补码编码。
- 有符号编码变换如下:
![]()
C库
C库中的头文件
<limits.h>定义了一组宏,来限定编译器运行的机器的不同整型和字符型的取值范围。如它定义常量INT_MAX、INT_MIN和UINT_MAX来描述有符号和无符号整数的范围。
<float.h>指定浮点型范围和精度
<stdins.h>定义了一组形如intN_t和uintN_t的数据类型,其中N可为8、16、32、64.
eg.1
#include <stdio.h>
#include <limits.h>
int main(int argc,char* argv[]) {
printf("INT_MAX=%d\n",INT_MAX);
printf("INT_MIN=%d\n",INT_MIN);
printf("UINT_MAX=%u\n",UINT_MAX);
return 0;
}

eg.2
#include <stdio.h>
#include <limits.h>
#if INT_MAX>=3000000000
typedef int Quantity;
#else
typedef long long Quantity;
#endif
int main(int argc,char* argv[]) {
printf("int=%d\n",sizeof(int));
printf("long long=%d\n",sizeof(long long));
printf("quantity=%d\n",sizeof(Quantity));
return 0;
}

有符号数和无符号数之间的转换
C允许无符号数和有符号数之间的转换,原则是位表示保持不变。这些转换可以是显示的或隐式的。
eg
int tx,ty
unsigned ux,uy;
tx = (int)ux;
uy = (unsigned)ty;//显示
tx = ux;
uy = ty;//隐式
- 当用printf输出一个整数时,按照整数的编码根据不同的指示符分别输出int类型(%d)、unsigned类型(%u)或十六进制格式(%x)
int x = -1;
unsigned u = 2147483648;
printf("x = %u = %d = %x\n",x,x,x);
printf("u = %u = %d = %x\n",u,u,u);
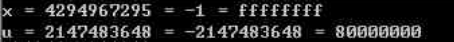
对于大多数C语言实现,处理同样位长的有符号数(补码)和无符号数间转换规则是:位模式不变,改变解释这些位的方式
数字的扩展和截断
- 当对一个无符号数转换为一个更大的数据类型,只需要简单地在其位表示开头的扩展字节添加0,称为零扩展。
- 要将一个有符号数(补码)转换为一个更大的数据类型,需要在其位表示开头的扩展字节添加最高有效位的值,称为符号扩展。
什么时候使用无符号类型
- 尽量不要在代码中使用无符号数类型,以免增加不必要的复杂性。
- 仅当需要对二进制位进行操作的时候,才使用无符号数。
- 在表示内存地址、实现模运算和多精度运算的数学包时,也可使用无符号数。
整数加法
无符号加法
①操作数:w bits → w+1 bits
②精确值:w+1 bits
③截断值:w bits
运算法则:为了不丢失精度,x、y的编码应零扩展为w+1位无符号数编码
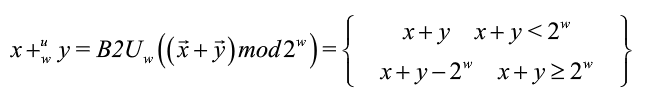
无符号减法
-
通过模数加法来实现
![]()
-
在无符号减法中,减去一个无符号数,相当于加上它的加法逆元。无符号数的加法逆元都为正数。
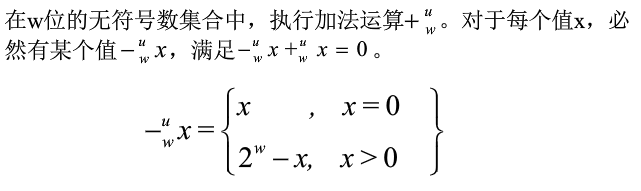
有符号数加法
①操作数:w bits → w+1 bits
②精确值:w+1 bits
③截断值:w bits
运算法则:为了不丢失精度,x、y的编码应符号扩展为w+1位二进制编码
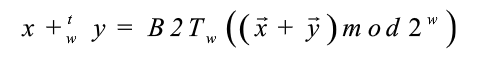
有符号减法
-
通常转换为有符号加法来实现
![]()
-
在有符号减法中,减去一个有符号数,相当于加上它的加法逆元。有符号数的加法逆元是它的相反数。

整数乘法
- 计算w位数字x、y的实际乘积
返回分类
三、浮点数
浮点数是属于有理数中某特定子集的数的数字表示,在计算机中用以近似表示任意某个实数。具体的说,这个实数由一个整数或定点数(即尾数)乘以某个基数(计算机中通常是2)的整数次幂得到,这种表示方法类似于基数为10的科学计数法。
IEEE浮点标准
浮点的引入
- 使用整数的编码可以表示以0为中心的一定范围内的正负整数,但缺陷为:
①无法表示那些绝对值“很大的”数值
②除了整数以外,在很多场合还需使用绝对值“极小的”小数,由于小数的某些特点,不能使用表示整数的方式去表示小数。
浮点数和IEEE754
科学记数法表示二进制数:
-1^s*2^E*M
s是符号位;2是基数,E是指数,
2^E
构成一个幂,表示数量级范围;M是有效数字部分(尾数),主要表示数值精度。M的位数越多,有效数字越多,数值精度越高。
IEEE754浮点标准
- IEEE754中,指定长度的浮点实数格式只有两种:float(单精度浮点实数)和double(双精度浮点实数),float的长度固定为4字节,double的长度固定为8字节。
V = -1^s*2^E*M = -1^s*2^(e-bias)*M
s=0或1,表示正或负值,用1bit编码S
E=e-bias。
M=1+f或f,0≤f<1。M应取哪个值依赖于e是否等于0.
规格化值:当exp编码不全为0,不全为1,可得到浮点数编码的规格化值
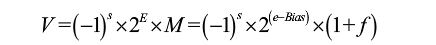
非规格化值:exp编码全为0时,可得到浮点数编码的非规格化值
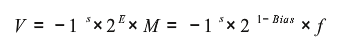
特殊值:exp编码全为1,可得到浮点数编码的特殊值
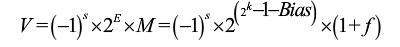
eg.
1.采用IEEE单精度格式,试求出32位浮点编码0xAC710000的值。
解:1,01011000,11100010000000000000000
s=[1],为负数
exp=[01011000],E=88-127=-39
frac=[1110001]
M=1+(0.1110001)b=1+141/16+21/256=1+0.875+0.0078125=1.8828125
2.试写出数0.8125的IEEE单精度浮点数编码
解:
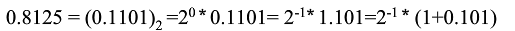
该数为正,s=0;E=-1=126-127,exp=126=[01111110]
尾数frac=[10100000000000000000000]
+
浮点编码:[0 01111110 10100000000000000000000]=0x3F500000
舍入
- 由于浮点表示方法只是离散地表示了实数,所以相应的浮点运算只能是近似的实数运算。
- 对于值x,我们一般想有一种系统的方法,能够找到“最接近的”,用x’的浮点形式来表示x,这就是舍入的任务。
浮点运算
C浮点类型
-
C提供了2种浮点类型:float和double。
-
int、float、double之间的强制类型转换。
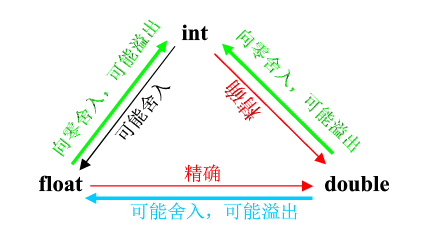
- 为什么int到float,为什么可能被舍入
float有23位用来表示有效数字,对于整数来说,超过223之后,很多数字都没法精确表示了,比如223+1。
如果把223+1这个int转化位float,就只能转换成最接近的223。
返回分类
习题
2.60
#include <stdio.h>
#include <assert.h>
unsigned replace_byte(unsigned x, int i, unsigned char b) {
if (i < 0) {
printf("error: i is negetive\n");
return x;
}
if (i > sizeof(unsigned)-1) {
printf("error: too big i");
return x;
}
unsigned mask = ((unsigned) 0xFF) << (i << 3);
unsigned pos_byte = ((unsigned) b) << (i << 3);
return (x & ~mask) | pos_byte;
}
int main(int argc, char *argv[]) {
unsigned rep_0 = replace_byte(0x12345678, 0, 0xAB);
unsigned rep_3 = replace_byte(0x12345678, 3, 0xAB);
assert(rep_0 == 0x123456AB);
assert(rep_3 == 0xAB345678);
return 0;
}
代码托管
上周考试错题总结
1.给定32位虚给定32位虚拟地址空间和24位的物理地址,页面大小为8K,下面说法正确的是()
A .
VPN=13
B .
VPN=19
C .
PPO=13
D .
VPO=11
E .
PPN=11
正确答案: B C E
结对及互评
点评模板:
- 博客中值得学习的或问题:
-
- 代码中值得学习的或问题:
-
本周结对学习情况
- [20155225](http://www.cnblogs.com/clever-universe/p/8052696.html)
- 结对照片
- 结对学习内容
- 相互讲解第二章和第五章的内容
其他(感悟、思考等,可选)
在此学习第二章,相比于开学那一次学习有更多的收获与见解。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 15篇 | 400小时 | |
| 第一周 | 20/20 | 1/ | 12/12 | |
| 第二周 | 42/62 | 1/2 | 8/20 | |
| 第三周 | 62/124 | 1/3 | 14/34 | |
| 第四周 | 61/185 | 1/4 | 10/44 | |
| 第五周 | / | 2/6 | 13/57 | |
| 第六周 | / | 2/8 | 17/74 | |
| 第七周 | / | 2/10 | 15/89 | |
| 第八周 | / | 2/12 | 12/101 | |
| 第九周 | / | 2/14 | 10/111 | |
| 第十一周 | / | 1/16 | 12/123 | |
| 第十三周 | / | 2/18 | 17/140 | 学习认为最重要的一章 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:18小时
-
实际学习时间:18小时
-
改进情况:本周是学习认为最重要的一章,虽然是重新学一遍,有了第一遍的基础,但还是在一些问题上更深的去探讨了
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号