
计蒜客信息学 8 月普及组模拟赛 赛后总结
比赛地址:这里
T1:

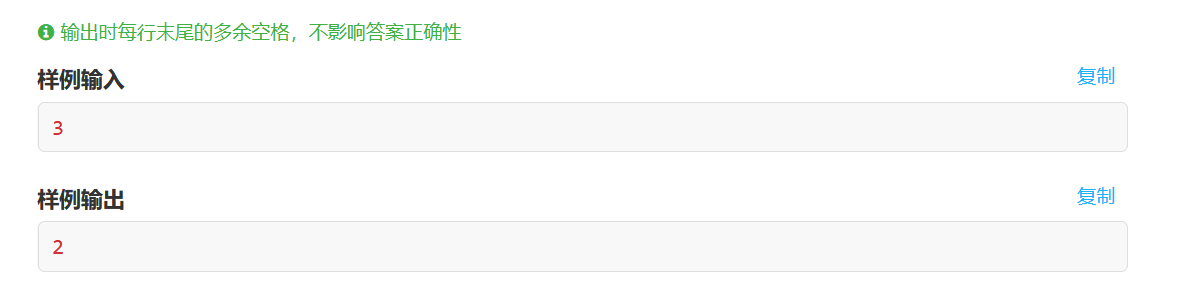 T1好水啊!标准的签到题,都用不着考虑思路,暴力即可。
T1好水啊!标准的签到题,都用不着考虑思路,暴力即可。
代码:
#include <bits/stdc++.h> using namespace std; template < typename T > void read(T &x) { int f = 1;x = 0;char c = getchar(); for (;!isdigit(c);c = getchar()) if (c == '-') f = -f; for (; isdigit(c);c = getchar()) x = x * 10 + c - '0'; x *= f; } int Count(int n) { int count = 0; int i; for (i = 1; i * i < n; i++) { if (n % i == 0) count+=2; } if (i * i == n) count++; return count; } int main() { //freopen(".in", "r", stdin); //freopen(".out", "w", stdout); int n, ans = 0; read(n); for(int i = 1;i <= n;i++) if(Count(i) % 2 == 0) ans++; cout << ans << endl; return 0; }
T2:



T2反而比较难,我们可以先对向左射的人的起始点和终点对终点进行排序,然后暴力枚举,再加上火车头神奇的优化效果,这道题就被我水过去了。
下面贴上代码(由于我的做法不是正解,代码只是做参考用!):
#include <bits/stdc++.h> #pragma GCC optimize(3) #pragma GCC target("avx") #pragma GCC optimize("Ofast") #pragma GCC optimize("inline") #pragma GCC optimize("-fgcse") #pragma GCC optimize("-fgcse-lm") #pragma GCC optimize("-fipa-sra") #pragma GCC optimize("-ftree-pre") #pragma GCC optimize("-ftree-vrp") #pragma GCC optimize("-fpeephole2") #pragma GCC optimize("-ffast-math") #pragma GCC optimize("-fsched-spec") #pragma GCC optimize("unroll-loops") #pragma GCC optimize("-falign-jumps") #pragma GCC optimize("-falign-loops") #pragma GCC optimize("-falign-labels") #pragma GCC optimize("-fdevirtualize") #pragma GCC optimize("-fcaller-saves") #pragma GCC optimize("-fcrossjumping") #pragma GCC optimize("-fthread-jumps") #pragma GCC optimize("-funroll-loops") #pragma GCC optimize("-fwhole-program") #pragma GCC optimize("-freorder-blocks") #pragma GCC optimize("-fschedule-insns") #pragma GCC optimize("inline-functions") #pragma GCC optimize("-ftree-tail-merge") #pragma GCC optimize("-fschedule-insns2") #pragma GCC optimize("-fstrict-aliasing") #pragma GCC optimize("-fstrict-overflow") #pragma GCC optimize("-falign-functions") #pragma GCC optimize("-fcse-skip-blocks") #pragma GCC optimize("-fcse-follow-jumps") #pragma GCC optimize("-fsched-interblock") #pragma GCC optimize("-fpartial-inlining") #pragma GCC optimize("no-stack-protector") #pragma GCC optimize("-freorder-functions") #pragma GCC optimize("-findirect-inlining") #pragma GCC optimize("-fhoist-adjacent-loads") #pragma GCC optimize("-frerun-cse-after-loop") #pragma GCC optimize("inline-small-functions") #pragma GCC optimize("-finline-small-functions") #pragma GCC optimize("-ftree-switch-conversion") #pragma GCC optimize("-foptimize-sibling-calls") #pragma GCC optimize("-fexpensive-optimizations") #pragma GCC optimize("-funsafe-loop-optimizations") #pragma GCC optimize("inline-functions-called-once") #pragma GCC optimize("-fdelete-null-pointer-checks") #pragma GCC optimize(2) using namespace std; template < typename T > void read(T &x) { int f = 1;x = 0;char c = getchar(); for (;!isdigit(c);c = getchar()) if (c == '-') f = -f; for (; isdigit(c);c = getchar()) x = x * 10 + c - '0'; x *= f; } struct node { int start, end; }; node lft[100005];//向右 node rgh[100005];//向左 int dir[100005]; int cnt1, cnt2; bool cmp(node x, node y) { return x.start < y.start; } int main() { //freopen(".in", "r", stdin); //freopen(".out", "w", stdout); int n; read(n); for(int i = 1;i <= n;i++) read(dir[i]); for(int i = 1;i <= n;i++) { int a, b; read(a); read(b); if(dir[i]) { cnt1++; lft[cnt1].start = a; lft[cnt1].end = b; } else { cnt2++; if(a > b) swap(a, b); rgh[cnt2].start = a; rgh[cnt2].end = b; } } sort(rgh + 1, rgh + cnt2 + 1, cmp); int ans = 0; for(int i = 1;i <= cnt1;i++) for(int j = 1;j <= cnt2;j++) { if(lft[i].end >= rgh[j].start) { if(rgh[j].end >= lft[i].start) ans++; } else break; } cout << ans << endl; return 0; }
T3:


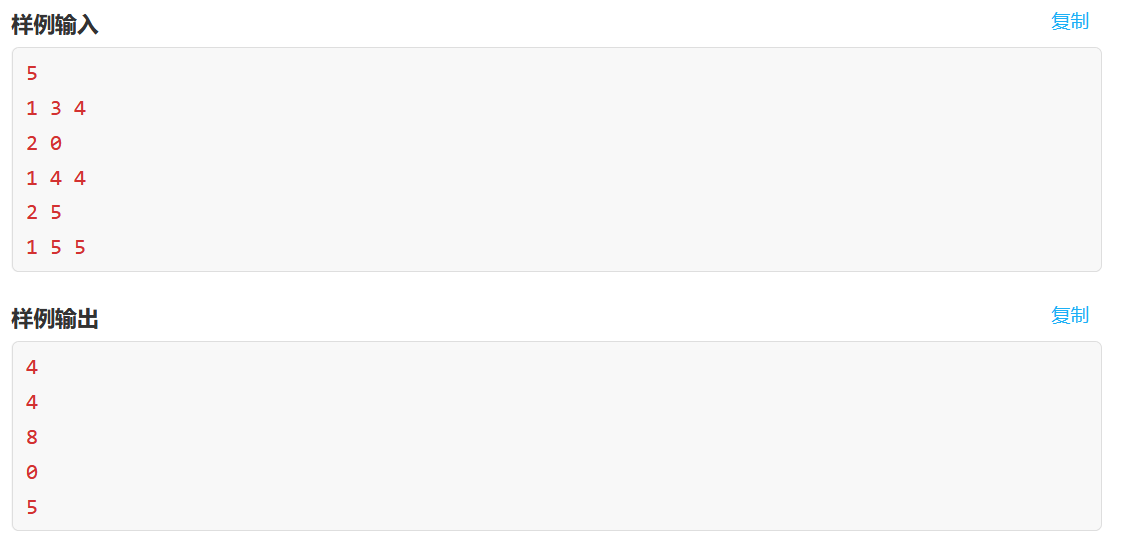
T3主观上认为比T2还简单一些,只需要记录每次1号操作结束后目前的状态,并存入一个数组,在2号操作时从后往前找,找到符合要求的即可跳转。
此外,我还要提醒大家一点:用不着开long long的一定不要乱开!乱开long long容易导致时间超限。
最后贴上代码:
#include <bits/stdc++.h> using namespace std; template < typename T > void read(T &x) { int f = 1;x = 0;char c = getchar(); for (;!isdigit(c);c = getchar()) if (c == '-') f = -f; for (; isdigit(c);c = getchar()) x = x * 10 + c - '0'; x *= f; } struct node { int t; long long sum; int cnt; }a[500005]; int main() { //freopen(".in", "r", stdin); //freopen(".out", "w", stdout); int n; read(n); int now = 0, cnt = 0; long long ans = 0; for(int i = 1;i <= n;i++) { int q; read(q); if(q == 1) { int t, w; read(t); read(w); now += t; ans += w; cnt++; a[cnt].t = now; a[cnt].sum = ans; a[cnt].cnt = cnt; printf("%lld\n", ans); } if(q == 2) { int p; bool flag = 1; read(p); for(int j = cnt;j >= 1;j--) if(a[j].t <= now - p) { now = a[j].t; ans = a[j].sum; cnt = a[j].cnt; flag = 0; break; } if(flag) { now = 0; ans = 0; cnt = 0; } printf("%lld\n", ans); } } return 0; }
T4:
T4由于长时间做不出,果断弃坑。
题解上说用dp, 可是我没有实现。
待填坑。
总结:
这场比赛总的来说不算很难,但依然需要选手细心应对。
此外,这场比赛也说明了题目不一定按难度排序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号