

Zookeeper详解
ZooKeeper是一个开源的分布式协调服务,由雅虎创建,是Google Chubby的开源实现。分布式应用程序可以基于ZooKeeper实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能
一、概念
-
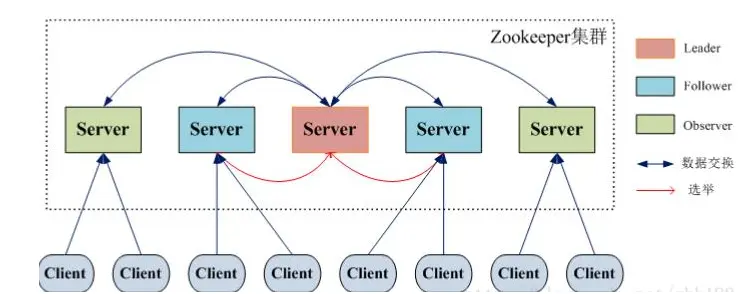
集群组成
- 领导者(Leader Server):接受folloer的请求,进行投票的发起和决议,更新系统状态。
- 学习者(Learner Server):
- 跟随者(Follower Server):
- 用于接受客户端请求,向Leader发起投票请求,获取结果修改数据,并向客户端返回结果
- 选主过程中参与投票。
- 观察者(ObServer Server):Observer可以接受客户端连接,将写请求转发给leader。但Observer不参加投票,只同步leader的状态。Observer的目的是位了扩展系统,提高读取速度。
- 跟随者(Follower Server):
- 客户端(Client):请求发送方。
![]()
-
接点数:奇数
- 由于Leader选举算法采用Paxos(ZAB:Zookeeper Atomic Brodcast)协议:当多数Server同意,则任务成功
-
原子广播(ZAB协议:一种Paxos变种):
- 恢复模式(选主):
- 广播模式(同步):
-
ZAB协议中的Server状态:
- LOOKING:系统刚启动时或者Leader崩溃后正处于选举状态
- LEADING:当前Server即位选出来的leader
- FLOOWING:leader已经选出来,当前Server与之同步。
-
Follower的消息循环处理
- PING:心跳处理
- PROPOSAL:Leader发起的提案,要求Folloer投票
- COMMIT:服务器最新一次提案信息。
- UPTODATE:表明同步完成
- REVALIDATE:根据Leader的REVALIDATE结果、关闭revalidate的session还是允许其接受消息。
- SYNC:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新。
二、恢复模式和广播模式
- 配置文件
"配置"
server.1=192.168.211.1:2888:3888
server.2=192.168.211.2:2888:3888
"格式"
server.serverid=serverhost:leader_listent_port:quorum_port
"serverid": 在配置中的myid中
-
恢复模式:
- 阶段一:Leader选举(fastpaxos:完整的paxos流程)
- 情景一:集群初始化
- 情景二:集群的Leader失去连接,需要重新选举一个新的Leader。
- 逻辑:
- 读取自己的配置 (集群初始化)
- 将服务器 {ID(myid文件中),ZXID } 作为leader推荐发送给给集群服务器,包括自己(推荐自己)。({ID,ZXID }:相当于paxos中的选举值)
- 接受其它集群Server的推荐询问,排除自己的询问,将 {id,zxid} 存放到列表中。
- 更新逻辑时钟:(逻辑时钟:相当于paxos中的选举号)
- 如果当前节点的逻辑时钟 > 消息节点的逻辑时钟 ,说明消息节点还处在一个比较老的选举周期里,则只需将当前节点的信息发送给消息节点
- 如果当前节点的逻辑时钟 <= 消息节点的逻辑时钟,说明当前节点处在一个比较老的选举周期。
- 更新逻辑时钟,并将列表中的信息清空。
- 先比较zxid,如果相同,则比较节点id的大小。选出最大,并发广播给其它节点
- 阶段二:恢复选择(所有ZNODE数据同步):
- 逻辑
- leader创建learnerhandler线程等待server连接。
- Leader将最大的zxid同步给该follower,同步完成后,通知follower进入UPTODATE状态。
- follower状态修改成UPTODATE后,开始接受client的请求
- 逻辑
- 阶段一:Leader选举(fastpaxos:完整的paxos流程)
-
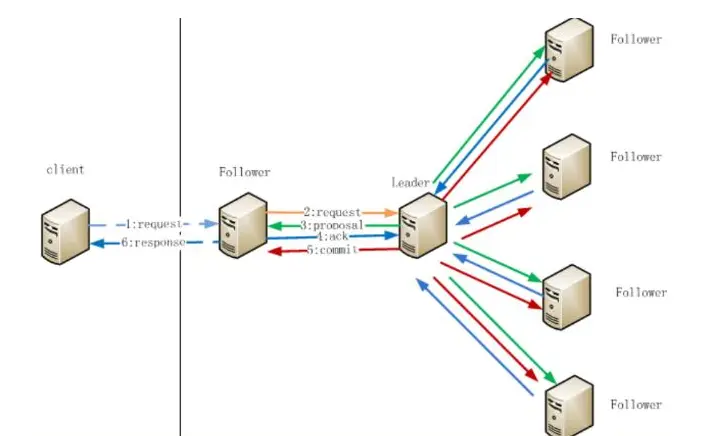
广播模式:由于所有的写入操作都是leader发起,不用在经历完整的paxos流程,只需要统计选举值修改步骤(两段提交)
- follower接受client的请求,并将请求转交给leader
- leader给每个请求 (单个ZNODE修改) 提起一个Proposal提案,发送给所有的follower修改
- follower修改完后给leader一个ack
- leader根据接受到的ack数量,判断有半数成功了,则代表成功。发送给所有follower一个commit命令。
- followercommit后,直接给client返回结果。
三、数据结构与ACL
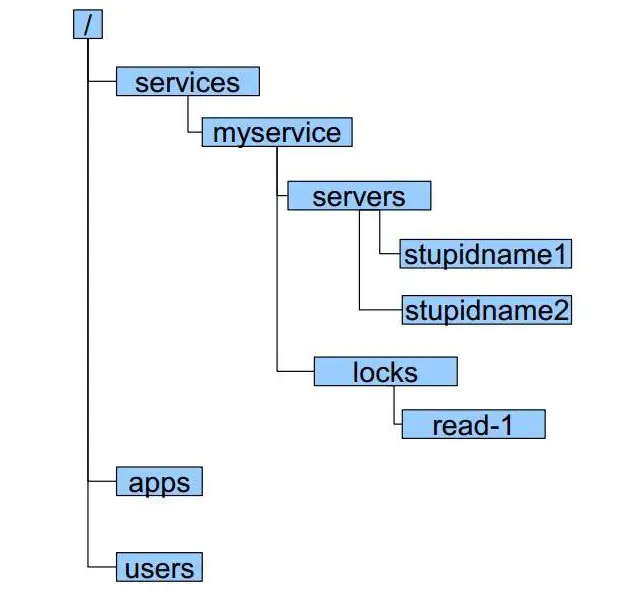
- ZNote结点(文件系统)
- 每个znode结点都有唯一的路径
- 可以在一个znode下添加、删除子znode
- znode用来直接存放数据
- znode类型:
- PERSISTENT(持久化目录结点):客户端与zookeeper断开后,该节点依旧存在
- PERSISTENT_SEQUENETIAL(持久化顺序编号目录结点):客户端与zookeeper断开后,该节点依旧存在。只是zookeeper给该节点名次进行顺序编号
- EPHEMERAL(临时结点):客户端与zookeeper断开后,被删除
- EPHEMERAL_SEQUENTIAL(临时顺序编号目录节点):客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
"ZNODE的信息"
[zk: 127.0.0.1:2181(CONNECTED) 2] get /zk
cZxid = 0x512bf "创建时的zxid"
ctime = Wed Dec 20 09:41:59 CST 2017
mZxid = 0x512bf "修改时的zxid"
mtime = Wed Dec 20 09:41:59 CST 2017
pZxid = 0x512c0 "提案(proposal)的zxid"
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
- ACL
- CREATE:创建子节点的权限
- READ: 获取节点数据和子节点列表的权限。
- WRITE:更新节点数据的权限。
- DELETE: 删除子节点的权限。
- ADMIN: 设置节点ACL的权限。
四、功能逻辑
| 名称 | 功能 | 作用 |
|---|---|---|
| 命名服务 | 在zookeeper的文件系统里创建一个目录,即有唯一的path | 通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息 |
| 配置管理 | 放在一个Znode中,client都来监听Znode信息变化 | 客户端对这个Znode坚挺,一旦配置信息发生变化,每个Client都会收到Zookeeper通知,从Zookeeper获取新的配置信息 |
| 集群管理 | 在zookeeper的文件系统里创建临时目录节点,客户端监听临时结点的子节点变化 | 所有机器都在该临时结点下,创建临时子节点,并将信息放在子结点上,然后监听该节点。 |
| 分布式锁 | 通过创建临时Znode的形式,获取一个锁。用完断开连接 | 排他锁(Exclusive Locks)和共享锁(Shared Locks) |
| 分布式队列 | 监听目标结点的子节点数是够达到个数 | 如合并计算结果等 |
五、应用
- 集群搭建
- 需要在 dataDir 目录中创建创建myid
- 关闭 selinux 、iptables 和 firewalld
- 配置
"配置"
# 每次心跳之间的毫秒数
tickTime=2000
# zk能接受,客户端多久(initLimit*tickTime)时常的客户端失链次数
initLimit=10
# Leader与Follower之之间请求和发送消息,不能超过的时常(syncLimit*tickTime)
syncLimit=5
# 数据快照存放地点
dataDir=/tmp/zookeeper
# 客户端连接接口
clientPort=2181
# 集群
server.1=192.168.214.128:2888:3888
server.2=192.168.214.129:2888:3888
server.3=192.168.214.130:2888:3888
"查看状态"
"192.168.214.128"
[fxl@localhost zookeeper-3.4.11]$ ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper-3.4.11/bin/../conf/zoo.cfg
Mode: follower
"192.168.214.129"
[fxl@localhost zookeeper-3.4.11]$ ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper-3.4.11/bin/../conf/zoo.cfg
Mode: leader
"192.168.214.130"
[fxl@localhost zookeeper-3.4.11]$ ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper-3.4.11/bin/../conf/zoo.cfg
Mode: follower
- zkclient:
- 监听数据结点
- 监听数据变化*
- 监听数据状态变化*
public static void main(String[] args) {
"监听数据结点"
zkClient.subscribeChildChanges("/"+ROOTPAHT, new IZkChildListener() {
@Override
public void handleChildChange(String arg0, List<String> arg1) throws Exception {
System.out.println("子节点的变化");
System.out.println("子节点的变化:arg0"+arg0);
for (int i = 0; i < arg1.size(); i++) {
System.out.println("子节点的变化:i"+i+" arg1:"+arg1.get(i));
}
}
});
"监听数据变化"
zkClient.subscribeDataChanges("/"+ROOTPAHT, new IZkDataListener() {
@Override
public void handleDataDeleted(String arg0) throws Exception {
System.out.println("数据被删除");
System.out.println("数据被删除 arg0:"+arg0);
}
@Override
public void handleDataChange(String arg0, Object arg1) throws Exception {
System.out.println("数据被更改");
System.out.println("数据被更改 arg0:"+arg0);
System.out.println("数据被更改 arg1"+arg1);
}
});
"监听数据状态变化"
zkClient.subscribeStateChanges(new IZkStateListener() {
@Override
public void handleStateChanged(KeeperState arg0) throws Exception {
System.out.println("数据状态改变");
System.out.println("数据状态改变 arg0");
}
@Override
public void handleNewSession() throws Exception {
System.out.println("当session expire异常重新连接时,由于原来的所有的watcher和EPHEMERAL节点都已失效,可以在这里进行相应的容错处理");
}
@Override
public void handleSessionEstablishmentError(Throwable arg0) throws Exception {
System.out.println(arg0);
}
});
try {
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号