Self-Tuning, GPU-Accelerated Kernel Density Models for Multidimensional Selectivity Estimation
Histogram和KDE的分别
参考,https://www.jianshu.com/p/428ae3658f85
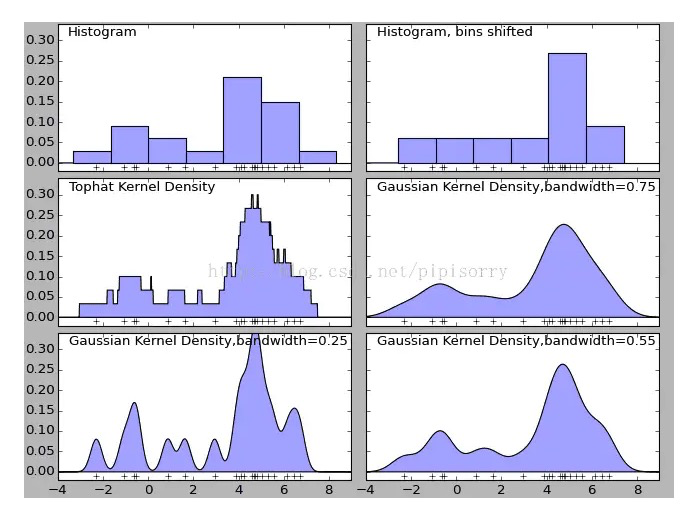
Histogram的问题比较明显,首先不平滑,再者分布和区间大小和偏移有很大关系,比如底下两个分布图差别非常大
所以Histogram误差是比较大的
KDE的基本思想比较简单
首先KDE是非参数估计,好处不对分布有先验知识,但非参数估计,估计的代价比较大,因为要scan整个sample集合
如果是参数估计,你首先要假设是线性,指数,高斯分布,然后用sample点去拟合参数,参数估计的好处是一旦得到参数,估计的代价比较小;但是如果你的先验假设是错的,那么误差就会比较大
KDE,核密度估计,不会像Histogram一样分bucket,对于所有的sample点,点就是kernel,离kernel的距离越近密度越大
所以很直觉,如果要算一个点的密度,只需要衡量它和所有sample kernel的距离的均值即可
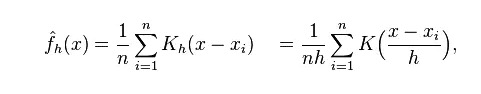
第一个公式,就表示x点到所有kernel的距离的平均值
K是核函数,表示距离和密度之间的关系,虽然知道距离越近密度越大,但需要量化,不同的核函数量化关系不同
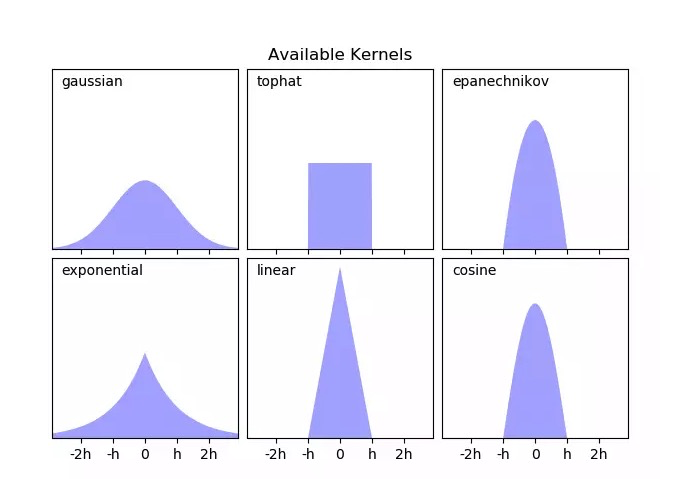
第二个公式中加入一个h,bandwidth
这个对于KDE是最重要的参数
bandwidth如果很大,看上面的公式,那么无论哪个点和各个kernel的距离都很小,underfitting,分布就会很平滑,因为没有学到足够的信息
反之,如果很小,那么该点到大部分kernel的距离都很大,密度趋向于0,只能学习到很近的kernel,overfitting,分布会很波动
The Bandwidth
Selecting a good bandwidth matrix H 2 Rdd is much more important than choosing the kernel function [1, 23].
The bandwidth controls the spread of the local distributions, i.e., the larger its magnitude is, the further will sample points distribute probability mass into their neighborhood.
Figure 2 illustrates the eect of choosing different bandwidth parameters for the estimator from Figure 1:
If the bandwidth is chosen too small (Figure 2(a)), the estimator isn't smooth enough, resulting in a very spiky distribution that overts the sample.
On the other hand, if the bandwidth is chosen too large (Figure 2(b)), the estimator is smoothed too strongly, losing much of the local information and under-fitting the distribution.

这里有个问题,既然Histogram误差那么大,为什么大部分数据库还是在用Histogram,而不用KDE?
因为KDE是非参数的,每次做估计的时候计算代价太大,没法用,有个优化是,做估计的时候没必要遍历所有sample点,只需要计算附近的点即可,这个需要事先做索引
还有KDE对于连续型的数据支持比较好,对于离散型的数据支持也不太好
再来看这篇paper,
只需要注意以下几个问题,
计算代价的问题怎么解决?
GPU,用GPU加速后会快很多
Bandwidth怎么选?
这个就是个优化问题,选怎样的bandwidth,可以让误差尽量小

这个问题之所以难,是因为true distribution一般而言是不知道的
通用的做法是用高斯分布来拟合true distribution,这样可以推导出一个公式来算出合理的bandwidth
但是对于数据的selectivity,因为数据集是确定的,所以true distribution是可以知道的,那么这个问题就变成一个最优化问题来求解即可
如果应对数据变化?
数据表的数据是在不断变化的,有insert, update,delete
这里数据变化对两个东西有影响,一个是bandwidth,一个sample集合
对于bandwidth本身是个最优化问题,所以如果数据发生变化,只需要持续的梯度下降求导就可以,文中使用的是stochastic gradient descent (SGD)
对于sample集合,有可以分成两种情况
insert比较简单,定期把新的数据加入到集合中即可
但是对于update和delete就比较复杂,因为原先的集合中会有些数据已经失效了
这里定义了karma score来量化集合中每个point对于estimation quality的影响,需要把产生负影响的点从集合中去掉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号