Evaluating EndtoEnd Optimization for Data Analytics Applications in Weld
需要解决的问题,
当前数据分析应用,会用到很多libraries,比如Numpy,Pandas,TensorFlow,Spark等
这些libraries的接口和数据结构都是不一样的,所以如果要提升应用的性能,你只能one by one的去提升每个libaries的性能,但是这样是很难优化的
缺乏一个end to end的优化方式,
Weld就是要做这个,当然Weld只考虑在单机的内存中的执行优化

大体思路,Weld 提供一组IR,每个库需要根据这套IR把算子重写,然后在执行的时候是lazy的,只有真正需要的时候才会真正执行
每个库里面不会真正去执行,而是把IR给返回出来,Weld有个RunTime,会收集所有库的IR,形成Combined IR,这样就和那些库没关系了
Weld有个优化器,会对Combined IR进行End to End的优化,最后生成机器代码
这个想法是不错,
但是前提是,每个库都要porting到Weld上才行,这个应该很难实现
Weld IR
IR的设计很关键,就像是关系数据库中的relational algebra,是整体的基石

IR基本元素包含,
Datatype

Computation
算子,这里叫builder

这里有的叫builder,有的叫merger,没有本质区别
所有builder都支持,3个接口

merge,往builder里面加数据
result,得到builder的结果,一旦调用了result,builder被destroy了,只能调用一次
for,用于parallel
可以看到这套IR还是真的很简单,
看个例子,就是这样的,


Weld IR的好处,就是能够表达前面提到的那些库的算子,这里提到fuse,因为把loop和builder分离开了,所以更容易fuse
看个例子,
对于上面的map本身就包含loop,所以调用两个map,就需要loop两次
但是用Weld IR,一个for就行,只需要loop一次

Weld Runtime
强调是lazy,每个libraries都会把要执行的IR,通过Runtime API提交出来

下面列出,RuntimeAPI,和一个使用的例子
只有在调用Evaluate的时候才会真正执行


Weld Optimizer
可以看到优化器和数据库优化器比较像
也是分成rule-based和adaptive
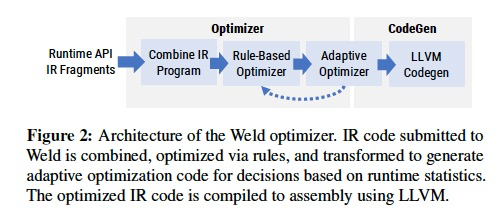
Rule-based 优化
最主要的是Fusion,执行优化中最常见的词

fusion有两种,其中之一是pipelining,可以看到pipelining后就不需要产生v1
还有一种是,水平fusion,相同输入,不同输出

还有个比较关键的优化,是向量化

Adaptive优化,有点类似CBO,但是其实这里拿不到太多数据来做判断
这里有提到,adaptive predication and adaptive data structures

 浙公网安备 33010602011771号
浙公网安备 33010602011771号