

Linux搭建数据质量监控 Griffin
官方源码: https://gitee.com/apache/griffin/tree/master 下载到本地
一、启动前需要先安装以下环境
- Jdk(1.8 or later versions)
- Postgresql or Mysql(用于存储Measure、job等元数据信息)
- npm(version 6.0.0+,用于编译ui模块)
- Hadoop(2.6.0 or later,需要HDFS存储)
- Spark(version 2.2.1,用于数据质量的各种计算)
- Hive(version 2.2.0,实际上低版本也支持,需要自行测试,如果需要用到其中的数据源则需要,否则也可以不用)
- Livy(用来通过Http的方式提交Spark作业)
- ElasticSearch (5.0 or later,用于存储质量检测后生成的时序数据)
二、安装细节
以下我是统一安装到 /usr/local/src/ 目录下
Hadoop 安装
1. wget http://archive.apache.org/dist/hadoop/core/hadoop-2.7.1/hadoop-2.7.1.tar.gz
2. tar -xvf hadoop-2.7.1.tar.gz
3. 需要修改配置文件 进入 :cd /usr/local/src/hadoop-2.7.1/etc/hadoop/
1. vim core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/src/hadoop-2.7.1/tmp</value> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
HDFS的元数据存储在这个/usr/local/src/hadoop-2.7.1/tmp目录下,如果操作系统重启了,系统会清空/tmp目录下的东西,导致NameNode元数据丢失,应该修改这个路径,所以在要创建tmp目录
2. vim hadoop-env.sh 和 vim yarn-env.sh
配置JDK路径: export JAVA_HOME=/usr/local/src/jdk1.8.0_131
3. 把mapred-site.xml.templte 修改成 mapred-site.xml
4. vim mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
5.vim hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>
6.vim yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>masteractive</value> </property> </configuration>
7. vim /etc/profile 配置环境变量
export HADOOP_HOME=/usr/local/src/hadoop-2.7.1
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin
----------------------------以上就完成了hadoop的配置---------------------------------------
启动Hadoop
1.格式化hdfs文件系统,启动hadoop。
[root@localhost ~]# cd /usr/local/src/hadoop-2.6.0/bin
[root@localhost bin]# ./hadoop namenode -format
[root@localhost bin]# ./sbin/start-all.sh
启动过程需要输入好几次的linux当前用户的密码,启动完成验证是否成功,输入 jps
[root@localhost bin]# jps
输入 hadoop -version 出现版本号,那么恭喜你,启动成功
Spark 安装
1.wget https://www.apache.org/dyn/closer.lua/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
2. tar -xvf spark-3.1.1-bin-hadoop2.7.tgz
3.vim /etc/profile 配置环境变量
#spark
export SPARK_HOME=/usr/local/src/spark-3.1.1-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
4.直接启动 输入 spark-shell 命令即可
[root@localhost /]# spark-shell
Hive 安装
1.wget https://downloads.apache.org/incubator/livy/0.7.1-incubating/apache-livy-0.7.1-incubating-bin.zip
2. unzip apache-livy-0.7.1-incubating-bin.zip
3. 进入hive下的conf修改配置文件
[root@localhost /]# cd /usr/local/src/apache-hive-2.3.8-bin/conf/
1.vim hive-site.xml
把下面这一段复制进去,修改对应的数据用户名密码即可
<?xml version="1.0"?> <configuration> <property> <name>hive.metastore.uris</name> <value>thrift://localhost:9083</value> </property> <property> <name>hive.server2.authentication</name> <value>CUSTOM</value> </property> <!-- Hive jdbc usernmae and pwd--> <property> <name>hive.jdbc_passwd.auth.zhangsan</name> <value>123456789</value> <description/> </property> <property> <name>hive.server2.custom.authentication.class</name> <value>org.apache.hadoop.hive.contrib.auth.CustomPasswdAuthenticator</value> </property> <!-- Hive产生的元数据存放位置--> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <!--- 使用本地服务连接Hive,默认为true--> <property> <name>hive.metastore.local</name> <value>true</value> </property> <!-- 数据库连接JDBC的URL地址--> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive2?createDatabaseIfNotExist=true</value> </property> <!-- 数据库连接driver,即MySQL驱动--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <!-- MySQL数据库用户名--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!-- MySQL数据库密码--> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>12345678</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>datanucleus.schema.autoCreateAll</name> <value>true</value> </property> <property> <name>hive.exec.local.scratchdir</name> <value>/tmp</value> <description>Local scratch space for Hive jobs</description> </property> <property> <name>hive.downloaded.resources.dir</name> <value>/tmp</value> <description>Temporary local directory for added resources in the remote file system.</description> </property> <property> <name>hive.server2.logging.operation.log.location</name> <value>/tmp/operation_logs</value> <description>Top level directory where operation logs are stored if logging functionality is enabled</description> </property> <property> <name>hive.metastore.port</name> <value>9083</value> <description>Hive metastore listener port</description> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> <description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description> </property> </configuration>
2.vim hive-env.sh
直接文件底部插入以下配置
export JAVA_HOME=/usr/local/src/jdk1.8.0_131
export HADOOP_HOME=/usr/local/src/hadoop-2.7.1
export HIVE_HOME=/usr/local/src/apache-hive-2.3.8-bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HIVE_AUX_JARS_PATH=$HIVE_HOME/lib
3. 下载jdbc的驱动包 mysql-connector-java-5.1.47.jar (自行下载)放入 /usr/local/src/apache-hive-2.3.8-bin/lib 文件夹中
4.mysql并配置hive数据库及权限
1. create table hive; 2.update user set host='%' where user='root';
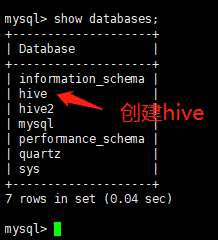

3. flush privileges;
----------------------------以上就完成了hive的配置---------------------------------------
启动测试hive
1.执行以下命令,创建hive数据表,可以登陆mysql 查看hive表
[root@localhost bin]# cd /usr/local/src/apache-hive-2.3.8-bin/bin
[root@localhost bin]# schematool -initSchema -dbType mysql
2.完成数据库初始化后,执行以下两条命令启动,
[root@localhost bin]# ./hive --service metastore &
[root@localhost bin]# ./hive
3.使用hive 创建表
CREATE EXTERNAL TABLE test(
id int,
name string,
age int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs:///griffin/persist/test';
Livy 安装
1.wget https://downloads.apache.org/incubator/livy/0.7.1-incubating/apache-livy-0.7.1-incubating-bin.zip
2. unzip apache-livy-0.7.1-incubating-bin.zip
3.vim /etc/profile 配置环境变量
#livy
export LIVY_HOME=/usr/local/src/apache-livy-0.7.1
export HADOOP_CONF_DIR=/usr/local/src/hadoop-2.6.0/etc/hadoop
4. 配置很少,直接启动
[root@localhost /]# cd /usr/local/src/apache-livy-0.7.1/bin/
[root@localhost bin]# ./livy-server
Elasticsearch 安装
1. wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.0.tar.gz
2. tar -vxf elasticsearch-6.0.0.tar.gz
3. 配置 elasticsearch.yml
[root@localhost config]# cd /usr/local/src/elasticsearch-6.0.0/config
[root@localhost config]# vim elasticsearch.yml
再底部增加
network.host: 0.0.0.0
http.port: 9200
path.data: /home/elasticserach/elasticsearch-1/data
path.logs: /home/elasticserach/elasticsearch-1/logs
4.启动服务:需要注意的是ES在linux上的话默认是不支持root用户进行启动,所以我们需要切换其它用户来进行启动,并且需要设置访问权限
需要设置以下两个文件权限
[root@localhost /]#chown -R admin /usr/local/src/elasticsearch-6.0.0
[root@localhost /]#chown -R admin /home/elasticserach/
5. vim /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360
最后记得执行:
sysctl -p
6.切换用户登陆,进行启动
[root@localhost bin]# cd /usr/local/src/elasticsearch-6.0.0/bin
[root@localhost bin]# ./elasticsearch
****************************************************以上完成了所有的griffin 需要的依赖配置****************************************************
接下来配置griffin
griffin 安装配置请查看 https://www.cnblogs.com/qiu-hua/p/13947941.html
griffin ui操作请查看 https://cloud.tencent.com/developer/article/1780013

启动 griffin 命令:nohup java -jar griffin-service.jar --httpPort=8085 >a.log 2>&1 &

 浙公网安备 33010602011771号
浙公网安备 33010602011771号