Homework1:词频统计程序
2013-09-25 汪仁贵 11061162
一、项目要求:
- 递归遍历目标目录下.txt、.h、.cpp、.c文件,统计里面的单词出现次数,将结果有序输出;
- 单词定义为以四个英文字母开头,由字母加数字组成;
- 排序输出时,按词频输出,词频相同按单词字典序输出;
- 程序在两种模式下运行,简单模式和扩展模式,扩展模式要求将尾部数字不同的单词按相同单词计算词频。
二、程序框架设计
在动手写程序之前,对程序的框架进行了设计。
这个程序要实现的功能有三大块:1.递归遍历目标文件目录,找出要求的四种文件。
2.按规则读取其中的word。
3.将读取的word有序输出。
因为c++库里面封装了排序的函数,所以,3的实现比较简单。于是,我将1,2分别用Reverse()和wordStatistics这两个函数实现,并封装在frequencyCounter类里,由init调用。

最初我乐观估计实现这三个功能只要4小时足矣,结果,结果很惨烈……
三、功能实现:
最终为了实现这些功能,我实际花费时间在20个小时左右(大致估计).
//patten用于匹配符合要求的单词(四个字母打头,有字母数字组成 const regex patten("[a-zA-Z]{4}[a-zA-Z0-9]*"); //pattenOfExtend用于匹配扩展模式下有数字后缀的单词 const regex pattenOfExtend("[a-zA-Z0-9]*[0-9]+");
1 /*init通过调用Reverse(filename)实现递归遍历目录filename里的四种文本文件并统计词频,调用sort(wordlist.begin() ,wordlist.end(),cmp)对结果排序 2 */ 3 void frequencyCounter::init (){ 4 ofstream outFile("futurewrg@gmail.com.txt",ios::out); 5 Reverse(filename); 6 sort(wordlist.begin() ,wordlist.end(),cmp); 7 for(vector<wordF>::iterator iter=wordlist.begin ();iter!=wordlist .end();iter++) 8 outFile<<(*iter).word 9 <<":" 10 <<(*iter).fre 11 <<endl; 12 outFile.close(); 13 }
其它Reverse()函数和wordStatistics()请参见源代码。
四、性能分析。
1、Code Analysis。
第一次只出现了一个问题,就是wordStatistics函数没有写返回值。
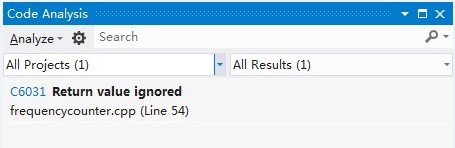
改过之后再分析,再次报错,说_findnext(if,&file);返回值未使用,可是,,可是我没需要用它的返回值啊。。。于是,,我用了一个自我感觉良好的办法,,嘿嘿,都佩服我自己了……
//改进前的代码
void frequencyCounter::Reverse(char* filename){ if((lf=_findfirst(dir.c_str(),&file))!=-1) { _findnext(lf,&file); //这行代码我真心只是想让他将目录下子目录..过滤掉 ………… } ………… }
//改进后的代码
void frequencyCounter::Reverse(char* filename){ if((lf=_findfirst(dir.c_str(),&file))!=-1l&&_findnext(lf,&file)==0)
{ //我把它加到if的判断语句里,嘿嘿,利用上了返回值
……
}
}
2.Performance
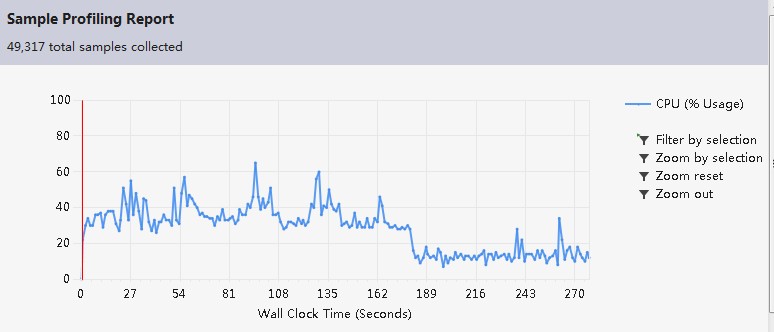


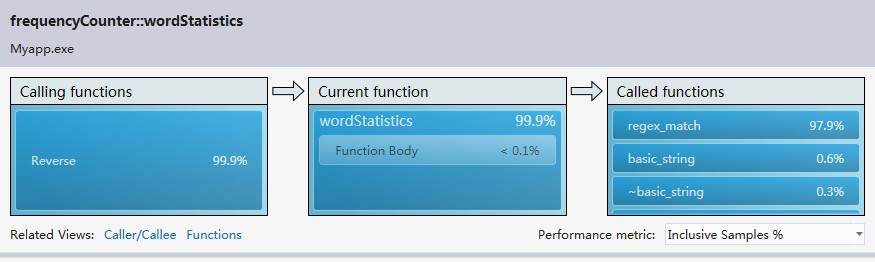
看了这个结果我感觉还是比较正常吧,因为整个程序中最大工作量就在word的处理上,而我使用正则表达式处理word,所以正则函数regex_match()占用最多时间
五、个人总结。
写完这个程序,花了这么多时间,最后写出了124行的程序(不包括头文件),只能说欲哭无泪啊。。。。。(之前没有好好学c++的节奏)
不过这个痛苦的过程也学到了不少技巧,例如功能强大的_finddata_t,_findnext,_findfirst这些文件处理的结构和函数,用起来真心方便,直接38行就完成了递归地从目标目录里筛选出要求文件的功能。还有regex,正则表达式,用起来方便,直接一行就完成了对扩展模式下含数字后缀的word的筛选。
好吧,写完这个程序,我知道,我真心不会c++,真心要好好学c++了,不然,,软工就要一直悲剧下去了……

 浙公网安备 33010602011771号
浙公网安备 33010602011771号