swin-transformer 基于pytorch&tensorflow2实现
swin-transformer
- 论文名称:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- 原论文地址: https://arxiv.org/abs/2103.14030
- 官方开源代码地址:https://github.com/microsoft/Swin-Transformer
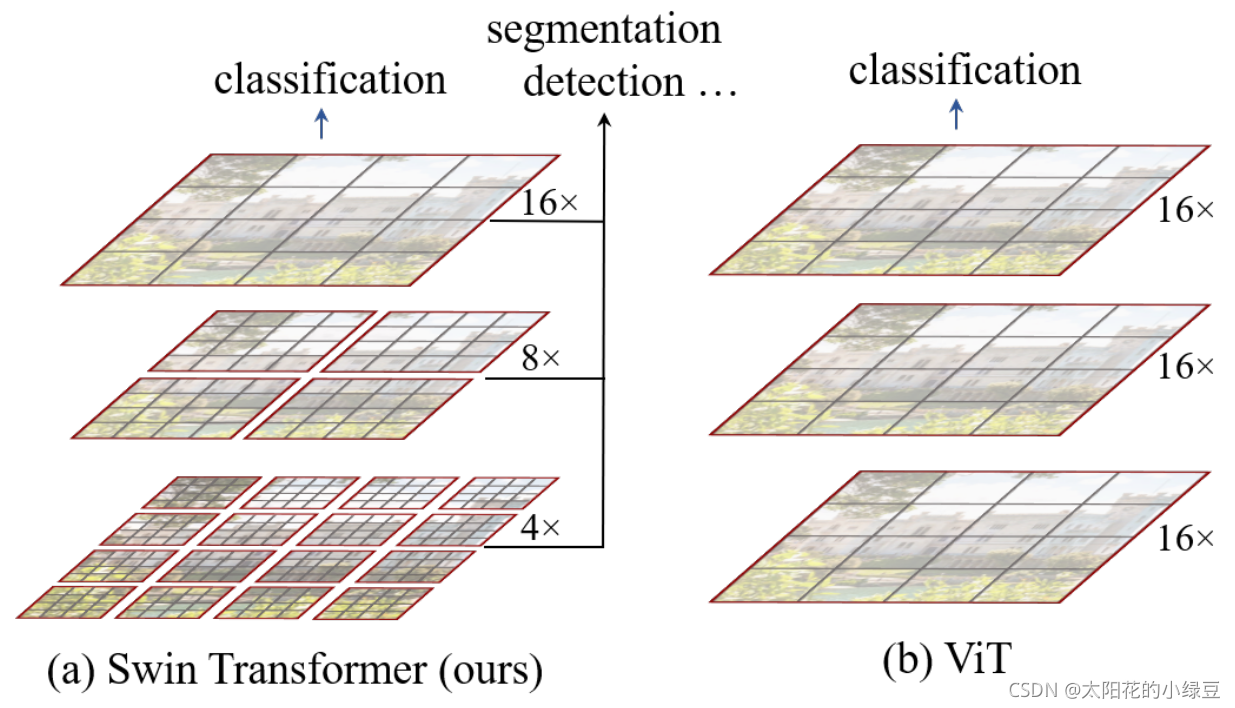
在正文开始之前,先来简单对比下Swin Transformer和之前的Vision Transformer。通过对比上图至少可以看出两点不同:
- Swin Transformer使用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变。
- 在Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA)的概念,比如上图中的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域(Window),并且Multi-Head Self-Attention只在每个窗口(Window)内进行。相对于Vision Transformer中直接对整个(Global)特征图进行Multi-Head Self-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以在论文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递。
网络结构
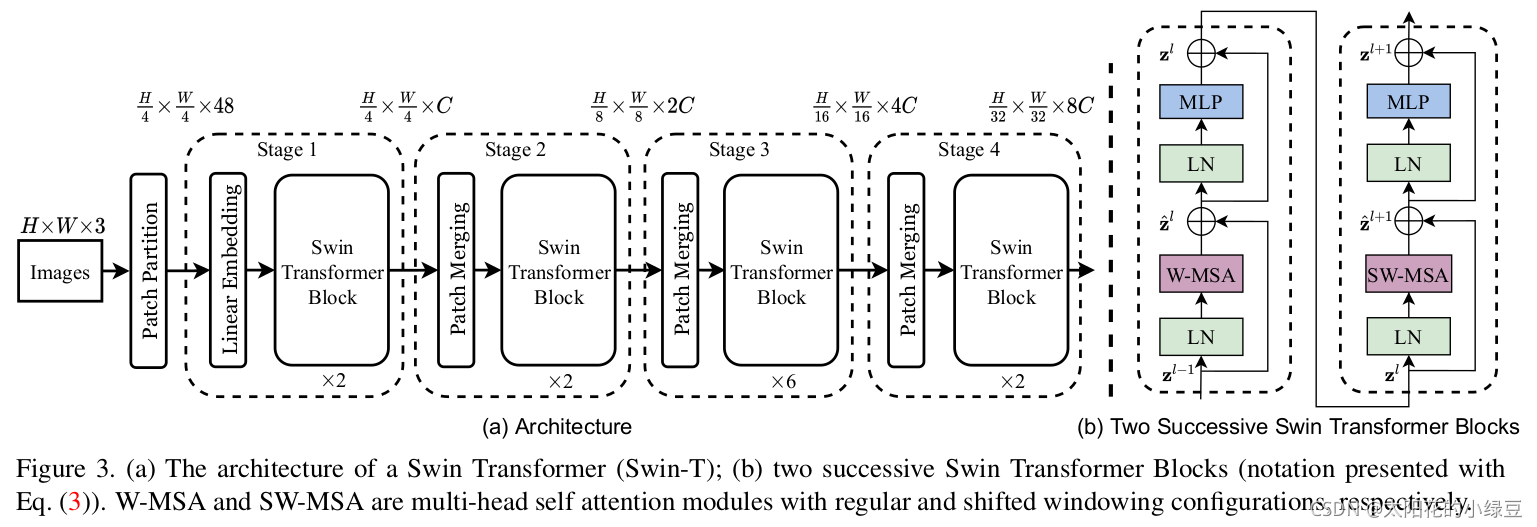
-
首先将图片输入到Patch Partition模块中进行分块,即每\(4\times 4\)相邻的像素为一个Patch,然后在channel方向展平(flatten)。假设输入的是RGB三通道图片,那么每个patch就有\(4\times 4=16\)个像素,然后每个像素有R、G、B三个值所以展平后是\(16\times 3=48\),所以通过Patch Partition后图像shape由 \([H, W, 3]\)变成了 \([H/4, W/4, 48]\)。然后在通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由 \([H/4, W/4, 48]\)变成了$ [H/4, W/4, C]$。其实在源码中Patch Partition和Linear Embeding就是直接通过一个卷积层实现的,和之前Vision Transformer中讲的 Embedding层结构一模一样。
-
然后就是通过四个Stage构建不同大小的特征图,除了Stage1中先通过一个Linear Embeding层外,剩下三个stage都是先通过一个Patch Merging层进行下采样(后面会细讲)。然后都是重复堆叠Swin Transformer Block注意这里的Block其实有两种结构,如图(b)中所示,这两种结构的不同之处仅在于一个使用了W-MSA结构,一个使用了SW-MSA结构。而且这两个结构是成对使用的,先使用一个W-MSA结构再使用一个SW-MSA结构。所以你会发现堆叠Swin Transformer Block的次数都是偶数(因为成对使用)。
-
最后对于分类网络,后面还会接上一个Layer Norm层、全局池化层以及全连接层得到最终输出。图中没有画,但源码中是这样做的。
pytorch实现
model.py
""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows`
- https://arxiv.org/pdf/2103.14030
Code/weights from https://github.com/microsoft/Swin-Transformer
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import numpy as np
from typing import Optional
def drop_path_f(x, drop_prob: float = 0., training: bool = False):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path_f(x, self.drop_prob, self.training)
def window_partition(x, window_size: int):
"""
将feature map按照window_size划分成一个个没有重叠的window
Args:
x: (B, H, W, C)
window_size (int): window size(M)
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
# permute: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H//Mh, W//Mh, Mw, Mw, C]
# view: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B*num_windows, Mh, Mw, C]
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size: int, H: int, W: int):
"""
将一个个window还原成一个feature map
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size(M)
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
# view: [B*num_windows, Mh, Mw, C] -> [B, H//Mh, W//Mw, Mh, Mw, C]
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
# permute: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B, H//Mh, Mh, W//Mw, Mw, C]
# view: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H, W, C]
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class PatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
def __init__(self, patch_size=4, in_c=3, embed_dim=96, norm_layer=None):
super().__init__()
patch_size = (patch_size, patch_size)
self.patch_size = patch_size
self.in_chans = in_c
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
_, _, H, W = x.shape
# padding
# 如果输入图片的H,W不是patch_size的整数倍,需要进行padding
pad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)
if pad_input:
# to pad the last 3 dimensions,
# (W_left, W_right, H_top,H_bottom, C_front, C_back)
x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],
0, self.patch_size[0] - H % self.patch_size[0],
0, 0))
# 下采样patch_size倍
x = self.proj(x)
_, _, H, W = x.shape
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x, H, W):
"""
x: B, H*W, C
"""
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
x = x.view(B, H, W, C)
# padding
# 如果输入feature map的H,W不是2的整数倍,需要进行padding
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
# to pad the last 3 dimensions, starting from the last dimension and moving forward.
# (C_front, C_back, W_left, W_right, H_top, H_bottom)
# 注意这里的Tensor通道是[B, H, W, C],所以会和官方文档有些不同
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C]
x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C]
x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C]
x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C]
x = torch.cat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]
x = x.view(B, -1, 4 * C) # [B, H/2*W/2, 4*C]
x = self.norm(x)
x = self.reduction(x) # [B, H/2*W/2, 2*C]
return x
class Mlp(nn.Module):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop)
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # [Mh, Mw]
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # [2*Mh-1 * 2*Mw-1, nH]
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing="ij")) # [2, Mh, Mw]
coords_flatten = torch.flatten(coords, 1) # [2, Mh*Mw]
# [2, Mh*Mw, 1] - [2, 1, Mh*Mw]
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # [2, Mh*Mw, Mh*Mw]
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # [Mh*Mw, Mh*Mw, 2]
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # [Mh*Mw, Mh*Mw]
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask: Optional[torch.Tensor] = None):
"""
Args:
x: input features with shape of (num_windows*B, Mh*Mw, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
# [batch_size*num_windows, Mh*Mw, total_embed_dim]
B_, N, C = x.shape
# qkv(): -> [batch_size*num_windows, Mh*Mw, 3 * total_embed_dim]
# reshape: -> [batch_size*num_windows, Mh*Mw, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
# transpose: -> [batch_size*num_windows, num_heads, embed_dim_per_head, Mh*Mw]
# @: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, Mh*Mw]
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
# relative_position_bias_table.view: [Mh*Mw*Mh*Mw,nH] -> [Mh*Mw,Mh*Mw,nH]
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # [nH, Mh*Mw, Mh*Mw]
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
# mask: [nW, Mh*Mw, Mh*Mw]
nW = mask.shape[0] # num_windows
# attn.view: [batch_size, num_windows, num_heads, Mh*Mw, Mh*Mw]
# mask.unsqueeze: [1, nW, 1, Mh*Mw, Mh*Mw]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# @: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
# transpose: -> [batch_size*num_windows, Mh*Mw, num_heads, embed_dim_per_head]
# reshape: -> [batch_size*num_windows, Mh*Mw, total_embed_dim]
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads, qkv_bias=qkv_bias,
attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, attn_mask):
H, W = self.H, self.W
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# pad feature maps to multiples of window size
# 把feature map给pad到window size的整数倍
pad_l = pad_t = 0
pad_r = (self.window_size - W % self.window_size) % self.window_size
pad_b = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
attn_mask = None
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # [nW*B, Mh, Mw, C]
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [nW*B, Mh*Mw, C]
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # [nW*B, Mh*Mw, C]
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [nW*B, Mh, Mw, C]
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # [B, H', W', C]
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
if pad_r > 0 or pad_b > 0:
# 把前面pad的数据移除掉
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class BasicLayer(nn.Module):
"""
A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
super().__init__()
self.dim = dim
self.depth = depth
self.window_size = window_size
self.use_checkpoint = use_checkpoint
self.shift_size = window_size // 2
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock(
dim=dim,
num_heads=num_heads,
window_size=window_size,
shift_size=0 if (i % 2 == 0) else self.shift_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def create_mask(self, x, H, W):
# calculate attention mask for SW-MSA
# 保证Hp和Wp是window_size的整数倍
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
# 拥有和feature map一样的通道排列顺序,方便后续window_partition
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # [1, Hp, Wp, 1]
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # [nW, Mh, Mw, 1]
mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # [nW, Mh*Mw]
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # [nW, 1, Mh*Mw] - [nW, Mh*Mw, 1]
# [nW, Mh*Mw, Mh*Mw]
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x, H, W):
attn_mask = self.create_mask(x, H, W) # [nW, Mh*Mw, Mh*Mw]
for blk in self.blocks:
blk.H, blk.W = H, W
if not torch.jit.is_scripting() and self.use_checkpoint:
x = checkpoint.checkpoint(blk, x, attn_mask)
else:
x = blk(x, attn_mask)
if self.downsample is not None:
x = self.downsample(x, H, W)
H, W = (H + 1) // 2, (W + 1) // 2
return x, H, W
class SwinTransformer(nn.Module):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24),
window_size=7, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.patch_norm = patch_norm
# stage4输出特征矩阵的channels
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
patch_size=patch_size, in_c=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
# 注意这里构建的stage和论文图中有些差异
# 这里的stage不包含该stage的patch_merging层,包含的是下个stage的
layers = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layers)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
# x: [B, L, C]
x, H, W = self.patch_embed(x)
x = self.pos_drop(x)
for layer in self.layers:
x, H, W = layer(x, H, W)
x = self.norm(x) # [B, L, C]
x = self.avgpool(x.transpose(1, 2)) # [B, C, 1]
x = torch.flatten(x, 1)
x = self.head(x)
return x
def swin_tiny_patch4_window7_224(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=96,
depths=(2, 2, 6, 2),
num_heads=(3, 6, 12, 24),
num_classes=num_classes,
**kwargs)
return model
def swin_small_patch4_window7_224(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=96,
depths=(2, 2, 18, 2),
num_heads=(3, 6, 12, 24),
num_classes=num_classes,
**kwargs)
return model
def swin_base_patch4_window7_224(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
**kwargs)
return model
def swin_base_patch4_window12_384(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=12,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
**kwargs)
return model
def swin_base_patch4_window7_224_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
**kwargs)
return model
def swin_base_patch4_window12_384_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22k.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=12,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
**kwargs)
return model
def swin_large_patch4_window7_224_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window7_224_22k.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=192,
depths=(2, 2, 18, 2),
num_heads=(6, 12, 24, 48),
num_classes=num_classes,
**kwargs)
return model
def swin_large_patch4_window12_384_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22k.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=12,
embed_dim=192,
depths=(2, 2, 18, 2),
num_heads=(6, 12, 24, 48),
num_classes=num_classes,
**kwargs)
return model
pytorch函数用法
torch.Tensor.view()
Tensor.view(*shape) → Tensor
Returns a new tensor with the same data as the self tensor but of a different shape.
相当于重构纬度
>>> x = torch.randn(4, 4)
>>> x.size()
torch.Size([4, 4])
>>> y = x.view(16)
>>> y.size()
torch.Size([16])
>>> z = x.view(-1, 8) # the size -1 is inferred from other dimensions
>>> z.size()
torch.Size([2, 8])
torch.jit.is_scripting()
首先要知道 JIT 是一种概念,全称是 Just In Time Compilation,中文译为「即时编译」,是一种程序优化的方法,一种常见的使用场景是「正则表达式」。例如,在 Python 中使用正则表达式:
prog = re.compile(pattern)
result = prog.match(string)
或
result = re.match(pattern, string)
两种写法从结果上来说是「等价」的。但注意第一种写法种,会先对正则表达式进行 compile,然后再进行使用。如果继续阅读 Python 的文档,可以找到下面这段话:
using re.compile() and saving the resulting regular expression object for reuse is more efficient when the expression will be used several times in a single program.
也就是说,如果多次使用到某一个正则表达式,则建议先对其进行 compile,然后再通过 compile 之后得到的对象来做正则匹配。而这个 compile 的过程,就可以理解为 JIT(即时编译)。
在深度学习中 JIT 的思想更是随处可见,最明显的例子就是 Keras 框架的 model.compile,TensorFlow 中的 Graph 也是一种 JIT,虽然他没有显示调用编译方法。
那 PyTorch 呢?PyTorch 从面世以来一直以「易用性」著称,最贴合原生 Python 的开发方式,这得益于 PyTorch 的「动态图」结构。我们可以在 PyTorch 的模型前向中加任何 Python 的流程控制语句,甚至是下断点单步跟进都不会有任何问题,但是如果是 TensorFlow,则需要使用 tf.cond 等 TensorFlow 自己开发的流程控制,谁更简单一目了然。那么为什么 PyTorch 还需要引入 JIT 呢?
TorchScript
动态图模型通过牺牲一些高级特性来换取易用性,那到底 JIT 有哪些特性,在什么情况下不得不用到 JIT 呢?下面主要通过介绍 TorchScript(PyTorch 的 JIT 实现)来分析 JIT 到底带来了哪些好处。
- 模型部署
PyTorch 的 1.0 版本发布的最核心的两个新特性就是 JIT 和 C++ API,这两个特性一起发布不是没有道理的,JIT 是 Python 和 C++ 的桥梁,我们可以使用 Python 训练模型,然后通过 JIT 将模型转为语言无关的模块,从而让 C++ 可以非常方便得调用,从此「使用 Python 训练模型,使用 C++ 将模型部署到生产环境」对 PyTorch 来说成为了一件很容易的事。而因为使用了 C++,我们现在几乎可以把 PyTorch 模型部署到任意平台和设备上:树莓派、iOS、Android 等等…
- 性能提升
既然是为部署生产所提供的特性,那免不了在性能上面做了极大的优化,如果推断的场景对性能要求高,则可以考虑将模型(torch.nn.Module)转换为 TorchScript Module,再进行推断。
- 模型可视化
TensorFlow 或 Keras 对模型可视化工具(TensorBoard等)非常友好,因为本身就是静态图的编程模型,在模型定义好后整个模型的结构和正向逻辑就已经清楚了;但 PyTorch 本身是不支持的,所以 PyTorch 模型在可视化上一直表现得不好,但 JIT 改善了这一情况。现在可以使用 JIT 的 trace 功能来得到 PyTorch 模型针对某一输入的正向逻辑,通过正向逻辑可以得到模型大致的结构,但如果在 forward 方法中有很多条件控制语句,这依然不是一个好的方法,所以 PyTorch JIT 还提供了 Scripting 的方式,这两种方式在下文中将详细介绍。
TorchScript Module 的两种生成方式
1. 编码(Scripting)
可以直接使用 TorchScript Language 来定义一个 PyTorch JIT Module,然后用 torch.jit.script 来将他转换成 TorchScript Module 并保存成文件。而 TorchScript Language 本身也是 Python 代码,所以可以直接写在 Python 文件中。
使用 TorchScript Language 就如同使用 TensorFlow 一样,需要前定义好完整的图。对于 TensorFlow 我们知道不能直接使用 Python 中的 if 等语句来做条件控制,而是需要用 tf.cond,但对于 TorchScript 我们依然能够直接使用 if 和 for 等条件控制语句,所以即使是在静态图上,PyTorch 依然秉承了「易用」的特性。TorchScript Language 是静态类型的 Python 子集,静态类型也是用了 Python 3 的 typing 模块来实现,所以写 TorchScript Language 的体验也跟 Python 一模一样,只是某些 Python 特性无法使用(因为是子集),可以通过 TorchScript Language Reference 来查看和原生 Python 的异同。
理论上,使用 Scripting 的方式定义的 TorchScript Module 对模型可视化工具非常友好,因为已经提前定义了整个图结构。
2. 追踪(Tracing)
使用 TorchScript Module 的更简单的办法是使用 Tracing,Tracing 可以直接将 PyTorch 模型(torch.nn.Module)转换成 TorchScript Module。「追踪」顾名思义,就是需要提供一个「输入」来让模型 forward 一遍,以通过该输入的流转路径,获得图的结构。这种方式对于 forward 逻辑简单的模型来说非常实用,但如果 forward 里面本身夹杂了很多流程控制语句,则可能会有问题,因为同一个输入不可能遍历到所有的逻辑分枝。
此外,还可以混合使用上面两种方式。
class SwinTransformer(nn.module)
class SwinTransformer(nn.Module):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
patch_size (int | tuple(int)): Patch size.
Default: 4 下采样倍数
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.每一个Swin Transformer模块中重复Swin Transformer Block的次数
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
最好为7的整数倍
wmsa&Swmas中采用的window大小
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
MLP中第一个全连接层翻多少倍
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
mutil-head self attention中是否使用偏置
drop_rate (float): Dropout rate. Default: 0
除了在pos_drop中使用到,还在mlp以及其他地方使用
attn_drop_rate (float): Attention dropout rate. Default: 0
mutil-head self attention过程当中使用的drop rate
drop_path_rate (float): Stochastic depth rate. Default: 0.1
每一个swin transformer模块当中使用的drop rate
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
使用checkpoint可以节省内存
"""
def __init__(self, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24),
window_size=7, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.patch_norm = patch_norm
# stage4输出特征矩阵的channels
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
# 看 patch_embed 部分的解析
self.patch_embed = PatchEmbed(
patch_size=patch_size, in_c=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth 随机深度网络
# drop_path_rate 从0开始一直增长到drop_path_rate
# sum(depths)为步数
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
# 注意这里构建的stage和论文图中有些差异
# 这里的stage不包含该stage的patch_merging层,包含的是下个stage的
layers = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
# downsample即patch_merging
# 前n-1个stage都有downsample,之后最后一个没有
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layers)
self.norm = norm_layer(self.num_features)
# 自适应的全局平均池化,池化完之后高和宽都变为1
self.avgpool = nn.AdaptiveAvgPool1d(1)
# 创造一个全连接层进行输出
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
# 调用一个权重初始化
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
# 传播过程
def forward(self, x):
# x: [B, L, C]
# 使用patch_embed方法对图像进行下采样四倍
x, H, W = self.patch_embed(x)
x = self.pos_drop(x)
# 遍历之前定义的模型
for layer in self.layers:
x, H, W = layer(x, H, W)
x = self.norm(x) # [B, L, C]
# transpose 对 L,C 进行调换
# 再进行一个自适应全局池化 L变为1
x = self.avgpool(x.transpose(1, 2)) # [B, C, 1]
# 从C的方向进行展平输出[B,C]
x = torch.flatten(x, 1)
# 通过一个全连接层得到输出
x = self.head(x)
return x
#各个版本的网络结构
def swin_tiny_patch4_window7_224(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# 官方的预训练权重https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=96,
depths=(2, 2, 6, 2),
num_heads=(3, 6, 12, 24),
num_classes=num_classes,
**kwargs)
return model
def swin_small_patch4_window7_224(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=96,
depths=(2, 2, 18, 2),
num_heads=(3, 6, 12, 24),
num_classes=num_classes,
**kwargs)
return model
def swin_base_patch4_window7_224(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
**kwargs)
return model
def swin_base_patch4_window12_384(num_classes: int = 1000, **kwargs):
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=12,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
**kwargs)
return model
def swin_base_patch4_window7_224_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
**kwargs)
return model
def swin_base_patch4_window12_384_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22k.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=12,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
**kwargs)
return model
def swin_large_patch4_window7_224_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window7_224_22k.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=192,
depths=(2, 2, 18, 2),
num_heads=(6, 12, 24, 48),
num_classes=num_classes,
**kwargs)
return model
def swin_large_patch4_window12_384_in22k(num_classes: int = 21841, **kwargs):
# trained ImageNet-22K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22k.pth
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=12,
embed_dim=192,
depths=(2, 2, 18, 2),
num_heads=(6, 12, 24, 48),
num_classes=num_classes,
**kwargs)
return model
模型详细配置参数
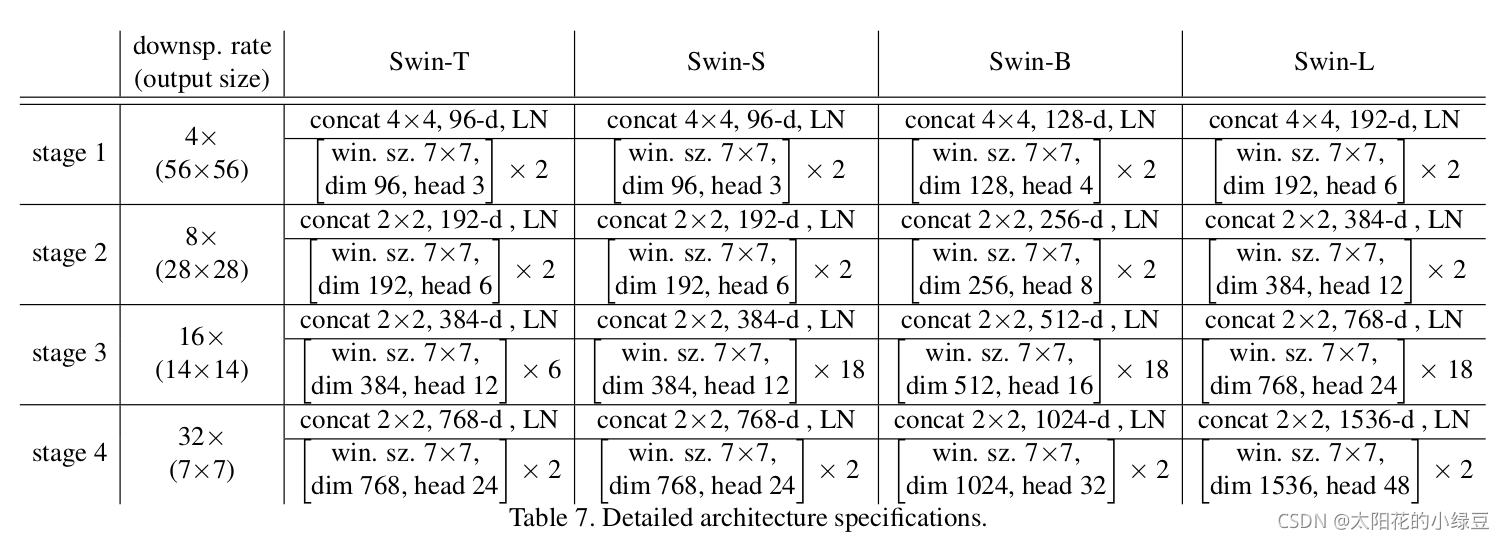
首先回忆下Swin Transformer的网络架构:
下图(表7)是原论文中给出的不同Swin Transformer的配置,T(Tiny),S(Small),B(Base),L(Large),其中:
- \(\text{win.sz.}7\times7\)表示使用的窗口(Windows)的大小
- \(\text{dim}\)表示feature map的channel深度(或者说token的向量长度)
- \(\text{head}\)表示多头注意力模块中head的个数
class PatchEmbed(nn.module)
# 把图片划分成没有重叠的patches
class PatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
# in_c 下采样深度
# embed_dim output的指定深度
def __init__(self, patch_size=4, in_c=3, embed_dim=96, norm_layer=None):
super().__init__()
patch_size = (patch_size, patch_size)
self.patch_size = patch_size
self.in_chans = in_c
self.embed_dim = embed_dim
# 通过一个卷积层映射 输入in_c 输出embed_dim 卷积核尺寸patch_size 步长 patch_size
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
# 如果在初始化时设置norm_layer,则做归一化,没有则做线性映射
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
_, _, H, W = x.shape
# padding
# 如果输入图片的H,W不是patch_size的整数倍,需要进行padding
pad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)
# 判断语句 返回true or false
if pad_input:
# to pad the last 3 dimensions,
# (W_left, W_right, H_top,H_bottom, C_front, C_back)
x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],
0, self.patch_size[0] - H % self.patch_size[0],
0, 0))
# 此处是在宽度的最右侧和高度的最下侧padding
# 下采样patch_size倍
x = self.proj(x)
# 下采样后记录一下新的高度和宽度
_, _, H, W = x.shape
# 然后进行展平
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
class PatchMerging(nn.Module)
在每个Stage中首先要通过一个Patch Merging层进行下采样(Stage1除外)。如下图所示,假设输入Patch Merging的是一个\(4\times4\)大小的单通道特征图(feature map),Patch Merging会将每个\(2\times2\)的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map。接着将这四个feature map在深度方向进行concat拼接,然后在通过一个LayerNorm层。最后通过一个全连接层在feature map的深度方向做线性变化,将feature map的深度由\(C\)变成\(C/2\)。
通过这个简单的例子可以看出,通过Patch Merging层后,feature map的高和宽会减半,深度会翻倍。
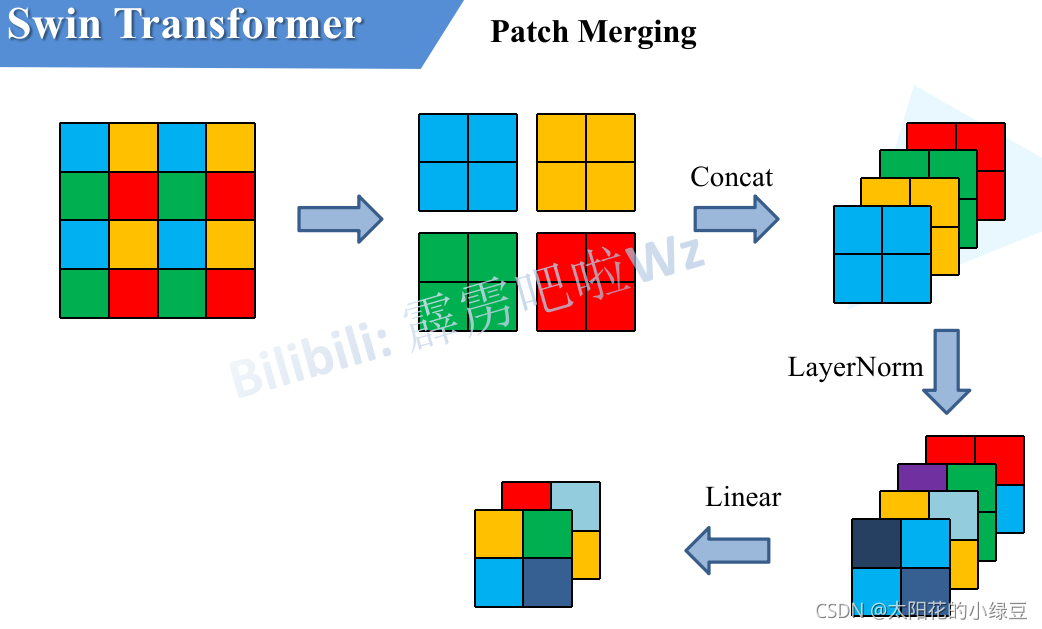
简单来说
- 每\(2*2\)窗口进行分割\(\longrightarrow 4*dim\)
- 将分割结果的每个相同位置上的元素进行拼接
- 然后在channel方向上进行concat
- LayerNorm进行处理
- 通过全连接层做一个线性映射\(\longrightarrow 2*dim\)
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
# 全连接层做线性映射 输入4*dim 输出2*dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x, H, W):
"""
x: B, H*W, C
"""
B, L, C = x.shape
# 判断如果长度不等于高度乘以宽度就报错
assert L == H * W, "input feature has wrong size"
x = x.view(B, H, W, C)
# padding
# 因为我们最终的输出其实是对Input下采样两倍的
# 如果输入feature map的H,W不是2的整数倍,需要进行padding
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
# to pad the last 3 dimensions, starting from the last dimension and moving forward.
# (C_front, C_back, W_left, W_right, H_top, H_bottom)
# 注意这里的Tensor通道是[B, H, W, C],所以会和官方文档有些不同
# 参数是从最后一个纬度向前设置的!!!
# 即(C,W,H) 在宽度右侧padding一列0,在高度上侧padding一行0
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
# 分成四份之后将相对应位置的内容拼接起来
x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C] 高度为0宽度为0
x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C] 高度为1宽度为0
x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C] 高度为0宽度为1
x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C] 高度为1宽度为1
x = torch.cat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]
# 在channel方向上进行展平
x = x.view(B, -1, 4 * C) # [B, H/2*W/2, 4*C]
# layernorm进行norm处理
x = self.norm(x)
# 全连接层将4*c映射为2*c
x = self.reduction(x) # [B, H/2*W/2, 2*C]
return x
class SwinTransformerBlock(nn.Module)
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
# WindowAttention就是w-msa or sw-msa
# 根据传入的shift_size进行判断
self.attn = WindowAttention(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads, qkv_bias=qkv_bias,
attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, attn_mask):
H, W = self.H, self.W
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# pad feature maps to multiples of window size
# 把feature map给pad到window size的整数倍
# 因为padding只会对高度下侧和宽度右侧操作,所以将左侧和上侧的标记设置为0
pad_l = pad_t = 0
pad_r = (self.window_size - W % self.window_size) % self.window_size
pad_b = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
# shift_window中的对调操作
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
attn_mask = None
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # [nW*B, Mh, Mw, C]
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [nW*B, Mh*Mw, C]
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # [nW*B, Mh*Mw, C]
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [nW*B, Mh, Mw, C]
# 将window_partition处理后的窗口转换回去
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # [B, H', W', C]
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
if pad_r > 0 or pad_b > 0:
# 把前面pad的数据移除掉,并变成内存连续
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
# FFN
# 残差
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class Mlp(nn.Module)
class Mlp(nn.Module):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
# 全连接层 hidden_features_channel = 4*in_features_channel
self.fc1 = nn.Linear(in_features, hidden_features)
# GELU
self.act = act_layer()
# dropout
self.drop1 = nn.Dropout(drop)
# 全连接层 out_features_channel=1/4 * hidden_features_channel=in_features_channel
# 还原回输入的channel
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class WindowAttention(nn.Module)
引入Windows Multi-head Self-Attention(W-MSA)模块是为了减少计算量。如下图所示,左侧使用的是普通的Multi-head Self-Attention(MSA)模块,对于feature map中的每个像素(或称作token,patch)在Self-Attention计算过程中需要和所有的像素去计算。但在图右侧,在使用Windows Multi-head Self-Attention(W-MSA)模块时,首先将feature map按照MxM(例子中的M=2)大小划分成一个个Windows,然后单独对每个Windows内部进行Self-Attention。

两者的计算量具体差多少呢?原论文中有给出下面两个公式,这里忽略了Softmax的计算复杂度。:
-
\(h \rightarrow \text{height of feature map}\)
-
\(w \rightarrow \text{width of feature map}\)
-
\(C \rightarrow \text{channel of feature map}\)
-
\(M \rightarrow \text{size of window}\)
那么这个公式怎么来的?
首先先回忆一下单头Self-Attention的公式:
MSA模块计算量
对于feature map中的每个像素(或称作token,patch),都要通过\(W_q, W_k, W_v\) 生成对应的query(q),key(k)以及value(v)。这里假设q, k, v的向量长度与feature map的深度C保持一致。那么对应所有像素生成Q的过程如下式:
- \(A^{hw\times C}\text{为将所有像素(token)拼接在一起得到的矩阵(一共有hw个像素,每个像素的深度为C)}\)
- \(W^{C\times C}_q为生成query的变换矩阵\)
- \(Q^{hw\times C}为所有像素通过W^{C\times C}_q得到的query拼接后的矩阵\)
根据矩阵运算的计算量公式可以得到生成Q的计算量为\(hw\times C\times C\),生成\(K\)和\(V\)同理都是\(hwC^2\),那么总共是\(3hwC^2\)。接下来\(Q\)和\(K^T\)相乘,对应计算量为\((hw)^2C\)
接下来忽略除以\(\sqrt{d}\)以及softmax的计算量,假设得到\(\Lambda^{hw\times hw}\),最后还要乘以\(V\),对应计算量为\((hw)^2C\)
那么对应单头的Self-Attention模块,总共需要\(3hwC^2+(hw)^2C+(hw)^2C=3hwC^2+2(hw)^2C\)。而在实际使用过程中,使用的是多头的Multi-head Self-Attention模块,在之前的文章中有进行过实验对比,多头注意力模块相比单头注意力模块的计算量仅多了最后一个融合矩阵\(W_o\)的计算量\(hwC^2\)
所以总共加起来是:
W-MSA模块计算量
对于W-MSA模块首先要将feature map划分到一个个窗口(Windows)中,假设每个窗口的宽高都是M,那么总共会得到\(\frac {h} {M} \times \frac {w} {M}\)个窗口,然后对每个窗口内使用多头注意力模块。刚刚计算高为\(h\),宽为\(w\),深度为C的feature map的计算量为$4hwC^2 + 2(hw)^2C \(,这里每个窗口的高为\)M\(宽为\)M$,带入公式得:
又因为有\(\frac {h} {M} \times \frac {w} {M}\)个窗口,则:
故使用W-MSA模块的计算量为:
假设feature map的\(h=112,w=112,M=7,C=128\),采用W-MSA模块相比MSA模块能够节省约\(40124743680 \text{FLOPs}\):
SW-MSA详解
采用W-MSA模块时,只会在每个窗口内进行自注意力计算,所以窗口与窗口之间是无法进行信息传递的。
为了解决这个问题,作者引入了Shifted Windows Multi-Head Self-Attention(SW-MSA)模块,即进行偏移的W-MSA。
如下图所示,左侧使用的是刚刚讲的W-MSA(假设是第L层),那么根据之前介绍的W-MSA和SW-MSA是成对使用的,那么第\(L+1\)层使用的就是SW-MSA(右侧图)。根据左右两幅图对比能够发现窗口(Windows)发生了偏移(可以理解成窗口从左上角分别向右侧和下方各偏移了$ \left \lfloor \frac {M} {2} \right \rfloor $个像素)。
看下偏移后的窗口(右侧图),比如对于第一行第2列的\(2\times4\)的窗口,它能够使第\(L\)层的第一排的两个窗口信息进行交流。再比如,第二行第二列的\(4\times 4\)的窗口,他能够使第\(L\)层的四个窗口信息进行交流,其他的同理。那么这就解决了不同窗口之间无法进行信息交流的问题。
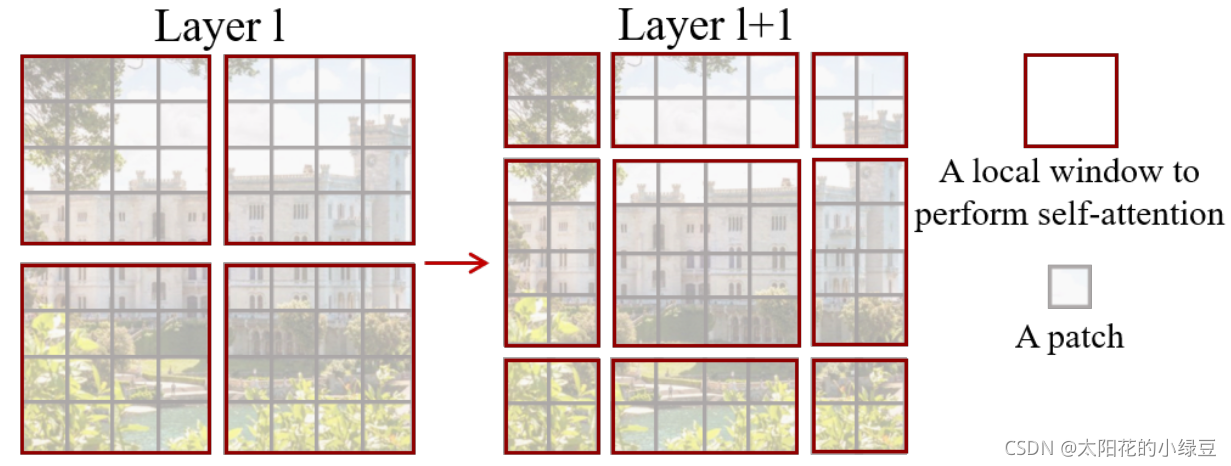
根据上图,可以发现通过将窗口进行偏移后,由原来的4个窗口变成9个窗口了。后面又要对每个窗口内部进行MSA,这样做感觉又变麻烦了。为了解决这个麻烦,作者又提出而了Efficient batch computation for shifted configuration,一种更加高效的计算方法。下面是原论文给的示意图。
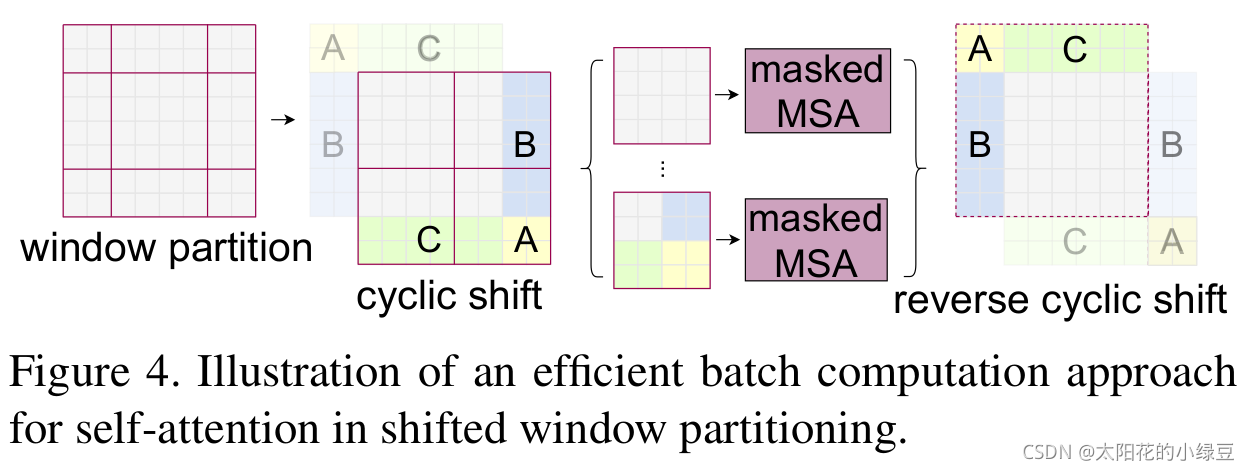
下图左侧是刚刚通过偏移窗口后得到的新窗口,右侧是为了方便大家理解,对每个窗口加上了一个标识。然后0对应的窗口标记为区域A,3和6对应的窗口标记为区域B,1和2对应的窗口标记为区域C。
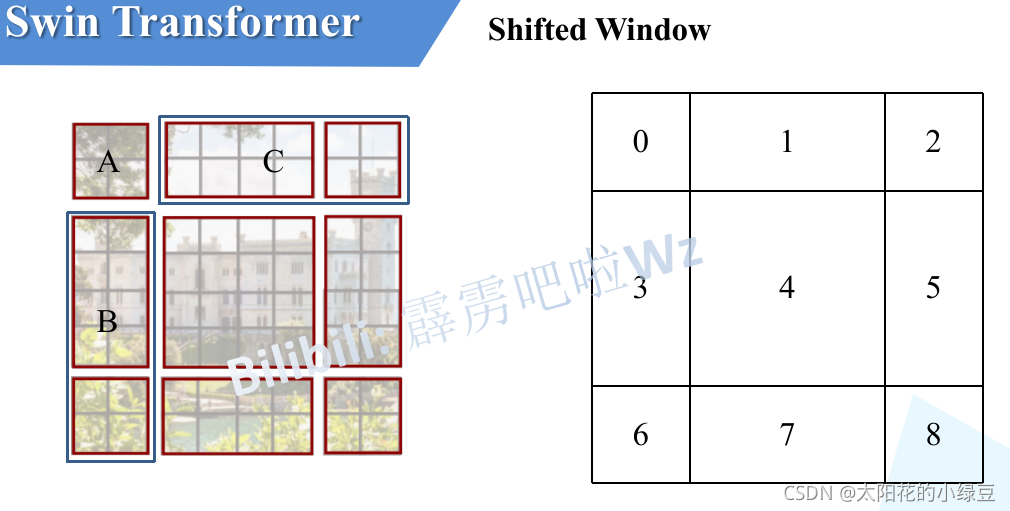
然后先将区域A和C移到最下方
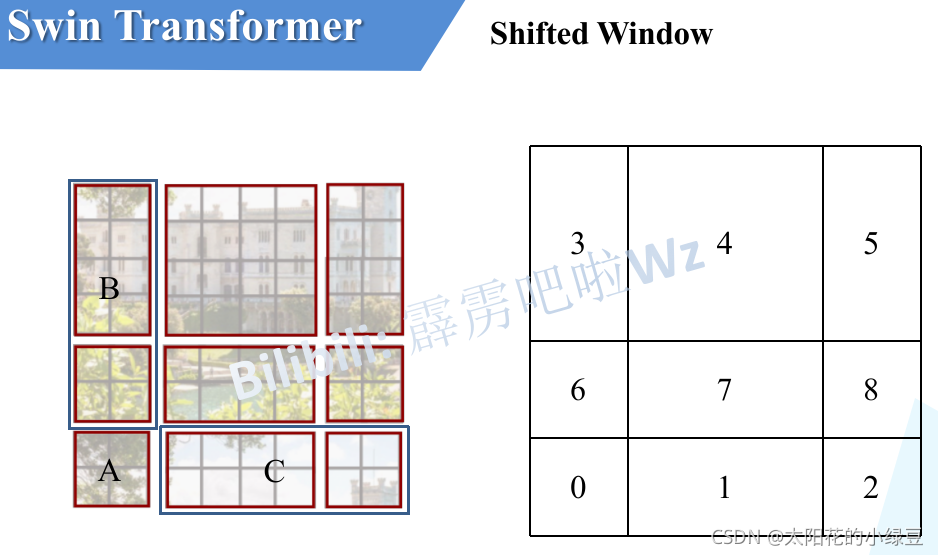
接着,再将区域A和B移至最右侧

移动完后
- 4是一个单独的窗口
- 将5和3合并成一个窗口
- 7和1合并成一个窗口
- 8、6、2和0合并成一个窗口
这样又和原来一样是4个\(4\times 4\)的窗口了,所以能够保证计算量是一样的。
但是把不同的区域合并在一起(比如5和3)进行MSA,这信息不就乱窜了吗?
为了防止这个问题,在实际计算中使用的是masked MSA即带蒙版mask的MSA,这样就能够通过设置蒙版来隔绝不同区域的信息了。
关于mask如何使用,下图是以上面的区域5和区域3为例。
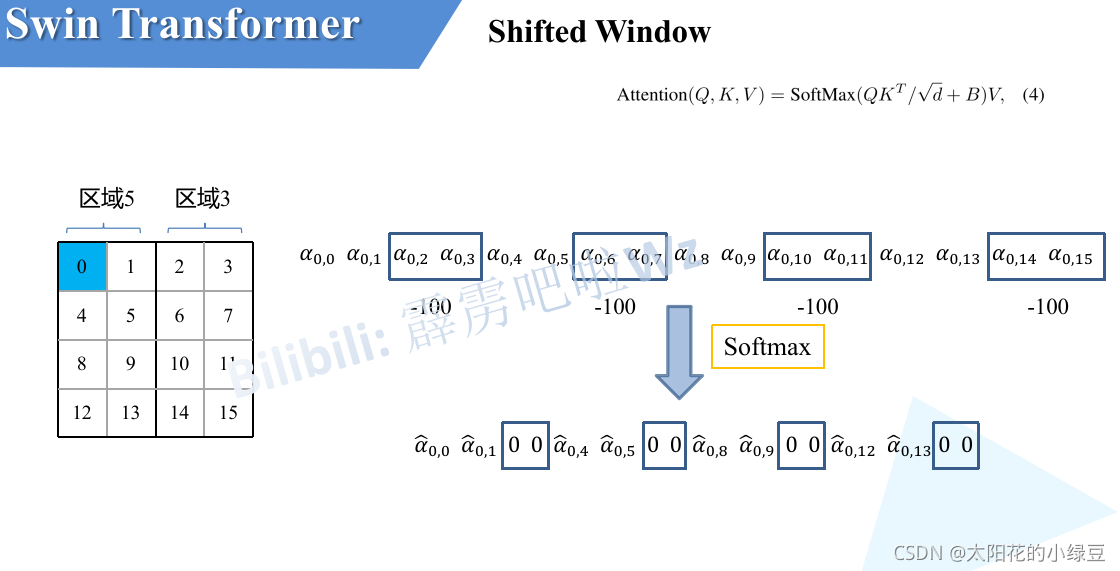
对于该窗口内的每一个像素(或称token,patch)在进行MSA计算时,都要先生成对应的query(q),key(k),value(v)。
假设对于上图的像素0而言,得到\(q^0\)后要与每一个像素的k进行匹配(match),假设\(\alpha _{0,0}\)代表\(q^0\)与像素0对应的\(k^0\)进行匹配的结果,那么同理可以得到\(\alpha _{0,0}\)至$ \alpha _{0,15}$。
按照普通的MSA计算,接下来就是SoftMax操作了。但对于这里的masked MSA,像素0是属于区域5的,我们只想让它和区域5内的像素进行匹配。那么我们可以将像素0与区域3中的所有像素匹配结果都减去100(例如$ \alpha _{0,2}, \alpha _{0,3}, \alpha _{0,6}, \alpha _{0,7}\(等等),由于\)\alpha$的值都很小,一般都是零点几的数,将其中一些数减去100后在通过SoftMax得到对应的权重都等于0了。所以对于像素0而言实际上还是只和区域5内的像素进行了MSA。那么对于其他像素也是同理,具体代码是怎么实现的,请看create_mask部分。
注意,在计算完后还要把数据给挪回到原来的位置上(例如上述的A,B,C区域)。
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # [Mh, Mw]
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # [2*Mh-1 * 2*Mw-1, nH]
# get pair-wise relative position index for each token inside the window
# 生成relative position index
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing="ij")) # [2, Mh, Mw]
# 绝对位置索引
coords_flatten = torch.flatten(coords, 1) # [2, Mh*Mw]
# [2, Mh*Mw, 1] - [2, 1, Mh*Mw]
# coords_flatten最后一列新加了一个纬度-coords_flatten中间一列新加一个纬度 利用广播机制
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # [2, Mh*Mw, Mh*Mw]
# contiguous()使内存连续
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # [Mh*Mw, Mh*Mw, 2]
# 行标+window_size[0] - 1
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
# 列标+window_size[0] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # [Mh*Mw, Mh*Mw]
# register_buffer将relative_position_index放入模型缓存中,因为relative_position_index是固定值
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
# 对多头输出进行融合的过程
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask: Optional[torch.Tensor] = None):
"""
Args:
x: input features with shape of (num_windows*B, Mh*Mw, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
# [batch_size*num_windows, Mh*Mw, total_embed_dim]
B_, N, C = x.shape
# qkv(): -> [batch_size*num_windows, Mh*Mw, 3 * total_embed_dim]
# reshape: -> [batch_size*num_windows, Mh*Mw, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
# transpose: -> [batch_size*num_windows, num_heads, embed_dim_per_head, Mh*Mw]
# @: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, Mh*Mw]
# scale就是attention公式里的放缩量
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
# relative_position_bias_table.view: [Mh*Mw*Mh*Mw,nH] -> [Mh*Mw,Mh*Mw,nH]
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # [nH, Mh*Mw, Mh*Mw]
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
# mask: [nW, Mh*Mw, Mh*Mw]
nW = mask.shape[0] # num_windows
# attn.view: [batch_size, num_windows, num_heads, Mh*Mw, Mh*Mw]
# mask.unsqueeze: [1, nW, 1, Mh*Mw, Mh*Mw]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
# 将不相关的位置加上-100,softmax之后就会变成0
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# @: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
# transpose: -> [batch_size*num_windows, Mh*Mw, num_heads, embed_dim_per_head]
# reshape: -> [batch_size*num_windows, Mh*Mw, total_embed_dim]
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
Relative Position Bias
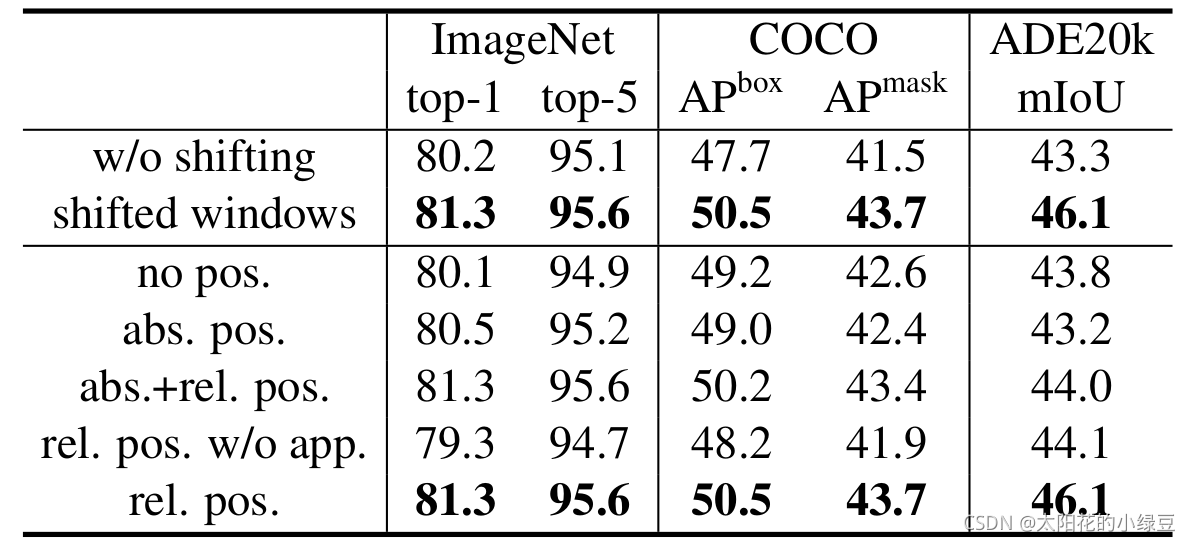
关于相对位置偏执,论文里也没有细讲,就说了参考的哪些论文,然后说使用了相对位置偏执后给够带来明显的提升。根据原论文中的表4可以看出,在Imagenet数据集上如果不使用任何位置偏执,top-1为80.1,但使用了相对位置偏执(rel. pos.)后top-1为83.3,提升还是很明显的。
那这个相对位置偏执是加在哪的呢,根据论文中提供的公式可知是在\(Q\)和\(K\)进行匹配并除以\(\sqrt{d}\)后加上了相对位置偏执\(B\)。
如下图,假设输入的feature map高宽都为2,那么首先我们可以构建出每个像素的绝对位置(左下方的矩阵),对于每个像素的绝对位置是使用行号和列号表示的。
比如蓝色的像素对应的是第\(0\)行第\(0\)列所以绝对位置索引是\((0,0)\),接下来再看看相对位置索引。
首先看下蓝色的像素,在蓝色像素使用\(q\)与所有像素\(k\)进行匹配过程中,是以蓝色像素为参考点。
然后用蓝色像素的绝对位置索引与其他位置索引进行相减,就得到其他位置相对蓝色像素的相对位置索引。
例如黄色像素的绝对位置索引是\((0,1)\),则它相对蓝色像素的相对位置索引为\((0, 0) - (0, 1)=(0, -1)\),这里是严格按照源码中来讲的,请不要杠。
那么同理可以得到其他位置相对蓝色像素的相对位置索引矩阵。同样,也能得到相对黄色,红色以及绿色像素的相对位置索引矩阵。接下来将每个相对位置索引矩阵按行展平,并拼接在一起可以得到下面的\(4\times 4\)矩阵 。

请注意,我这里描述的一直是相对位置索引,并不是相对位置偏执参数。因为后面我们会根据相对位置索引去取对应的参数。
比如说黄色像素是在蓝色像素的右边,所以相对蓝色像素的相对位置索引为\((0, -1)\)。绿色像素是在红色像素的右边,所以相对红色像素的相对位置索引为\((0, -1)\)。可以发现这两者的相对位置索引都是\((0, -1)\),所以他们使用的相对位置偏执参数都是一样的。
其实讲到这基本已经讲完了,但在源码中作者为了方便把二维索引给转成了一维索引。具体这么转的呢,有人肯定想到,简单啊直接把行、列索引相加不就变一维了吗?比如上面的相对位置索引中有\((0, -1)\)和\((-1,0)\)在二维的相对位置索引中明显是代表不同的位置,但如果简单相加都等于-1那不就出问题了吗?
接下来我们看看源码中是怎么做的。首先在原始的相对位置索引上加上M-1(M为窗口的大小,在本示例中M=2),加上之后索引中就不会有负数了。

接着将所有的行标都乘上2M-1。
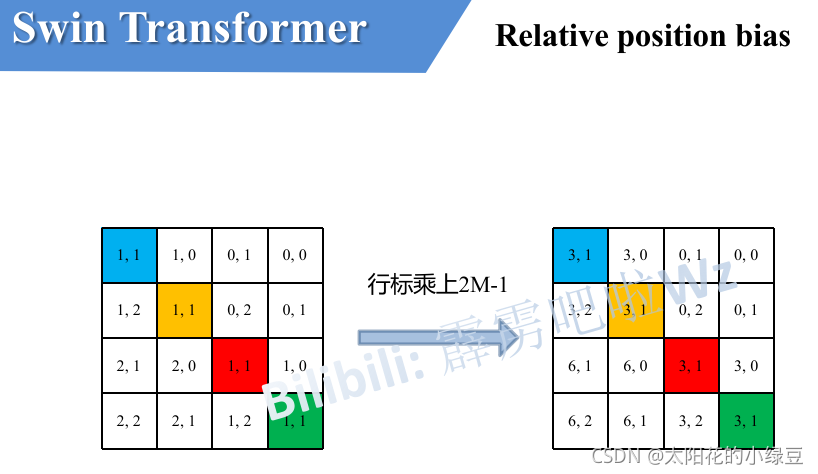
最后将行标和列标进行相加。这样即保证了相对位置关系,而且不会出现上述\(0+(-1)=(-1)+0\)的问题了,是不是很神奇。
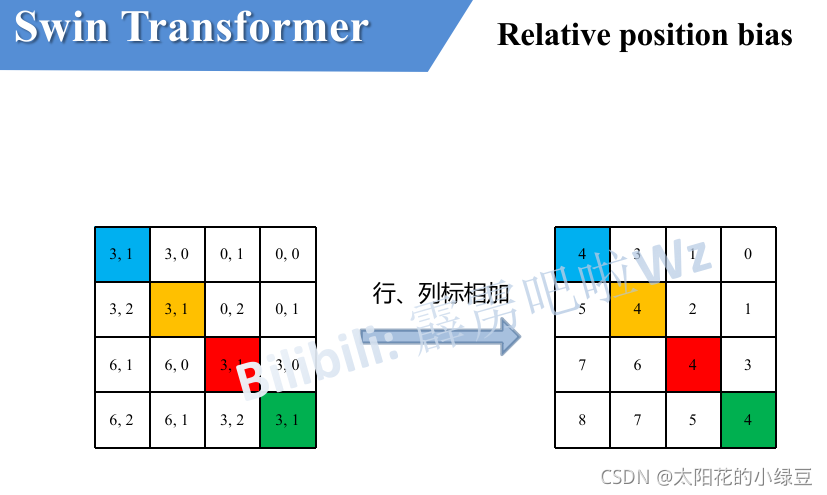
刚刚上面也说了,之前计算的是相对位置索引,并不是相对位置偏执参数。真正使用到的可训练参数\(\hat{B}\)是保存在relative position bias table表里的,这个表的长度是等于\((2M-1) \times (2M-1)\))的。那么上述公式中的相对位置偏执参数\(B\)是根据上面的相对位置索引表根据查relative position bias table表得到的,如下图所示。
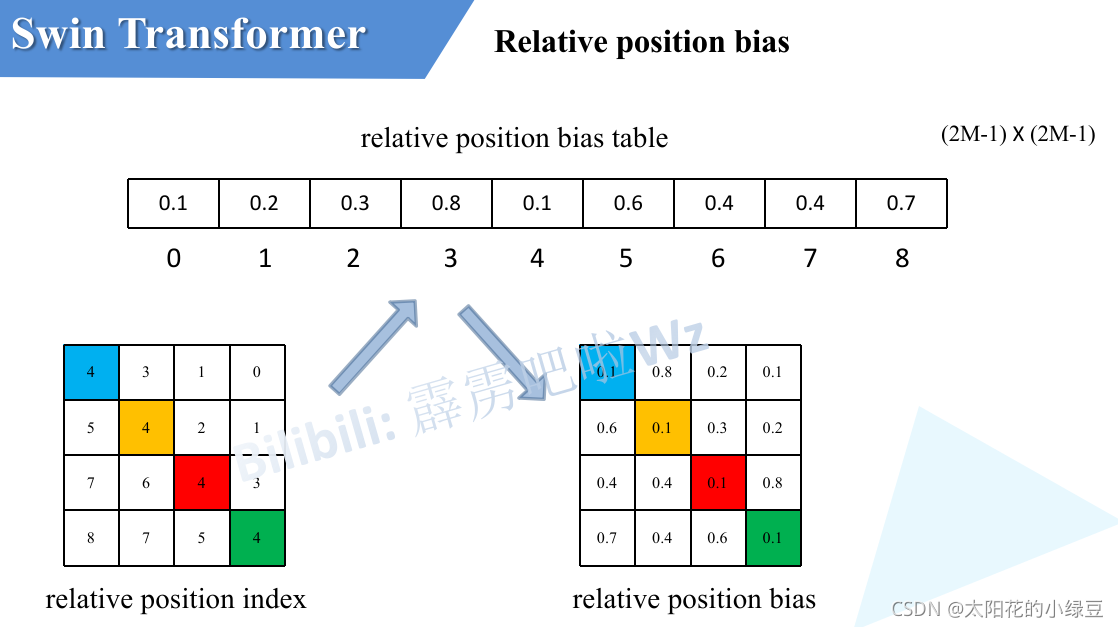
class BasicLayer(nn.Module)
class BasicLayer(nn.Module):
"""
A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
super().__init__()
self.dim = dim
self.depth = depth
self.window_size = window_size
self.use_checkpoint = use_checkpoint
# sw-msa时需要向右向下偏移多少个像素,除以2向下取整
self.shift_size = window_size // 2
# build swin-transformer blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock(
dim=dim,
num_heads=num_heads,
window_size=window_size,
# 在每个block中w-msa 和 sw-msa是依次成对使用的
# 之后会根据shift_size值得大小来选择使用w-msa 和 sw-msa
shift_size=0 if (i % 2 == 0) else self.shift_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
# 如果设置需要降采样,则实例化对象
if downsample is not None:
self.downsample = downsample(dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
# 使用s-msa时引入的蒙版
def create_mask(self, x, H, W):
# calculate attention mask for SW-MSA
# 保证Hp和Wp是window_size的整数倍
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
# 拥有和feature map一样的通道排列顺序,方便后续window_partition
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # [1, Hp, Wp, 1]
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # [nW, Mh, Mw, 1]
mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # [nW, Mh*Mw]
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # [nW, 1, Mh*Mw] - [nW, Mh*Mw, 1]
# [nW, Mh*Mw, Mh*Mw]
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
# 传播过程
def forward(self, x, H, W):
# 放在此处可以解决多尺度问题
attn_mask = self.create_mask(x, H, W) # [nW, Mh*Mw, Mh*Mw]
for blk in self.blocks:
blk.H, blk.W = H, W
if not torch.jit.is_scripting() and self.use_checkpoint:
x = checkpoint.checkpoint(blk, x, attn_mask)
else:
x = blk(x, attn_mask)
if self.downsample is not None:
x = self.downsample(x, H, W)
# 防止padding 如果是奇数,+1之后除2为整数,如果为偶数,除2取整后还是原来的一半
H, W = (H + 1) // 2, (W + 1) // 2
return x, H, W
create_mask
# 使用s-msa时引入的蒙版
def create_mask(self, x, H, W):
# calculate attention mask for SW-MSA
# 保证Hp和Wp是window_size的整数倍
# 为了支持多尺度
# 除以window_size然后向上取整,再乘以window_size,得到新的Hp,Wp
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
# 拥有和feature map一样的通道排列顺序,方便后续window_partition
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # [1, Hp, Wp, 1]
# 对应Shifted Window切片
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
# 遍历高度方向的第二个切片和第三个切片
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
# 通过window_partition这个方法将整个图片划分为不同窗口
mask_windows = window_partition(img_mask, self.window_size) # [nW, Mh, Mw, 1] 按行展平
mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # [nW, Mh*Mw]
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # [nW, 1, Mh*Mw] - [nW, Mh*Mw, 1] 涉及广播机制
# [nW, Mh*Mw, Mh*Mw]
# 对于!=0的区域填入-100
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
window_partition
def window_partition(x, window_size: int):
"""
将feature map按照window_size划分成一个个没有重叠的window
Args:
x: (B, H, W, C)
window_size (int): window size(M)
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
# permute: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H//Mh, W//Mh, Mw, Mw, C]
# view: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B*num_windows, Mh, Mw, C]
# permute方法调换3,2两行数据
# contiguous()将调换后的数据内存变为连续的
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
window_reverse
def window_reverse(windows, window_size: int, H: int, W: int):
"""
将一个个window还原成一个feature map
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size(M)
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
# view: [B*num_windows, Mh, Mw, C] -> [B, H//Mh, W//Mw, Mh, Mw, C]
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
# permute: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B, H//Mh, Mh, W//Mw, Mw, C]
# view: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H, W, C]
# window_partition的逆操作
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
# 导入对应模型
from model import swin_tiny_patch4_window7_224 as create_model
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img_size = 224
data_transform = transforms.Compose(
[transforms.Resize(int(img_size * 1.14)),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = create_model(num_classes=5).to(device)
# load model weights
model_weight_path = "./weights/model-9.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
print(print_res)
plt.show()
if __name__ == '__main__':
main()
train.py
import os
import argparse
import torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from my_dataset import MyDataSet
# 设置模型参数
from model import swin_tiny_patch4_window7_224 as create_model
from utils import read_split_data, train_one_epoch, evaluate
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
if os.path.exists("./weights") is False:
os.makedirs("./weights")
tb_writer = SummaryWriter()
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)
# 输入图片尺寸,最好是7的倍数
img_size = 224
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(img_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(int(img_size * 1.143)),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)
model = create_model(num_classes=args.num_classes).to(device)
# 载入预训练权重部分
if args.weights != "":
assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights)
weights_dict = torch.load(args.weights, map_location=device)["model"]
# 删除有关分类类别的权重
for k in list(weights_dict.keys()):
if "head" in k:
del weights_dict[k]
print(model.load_state_dict(weights_dict, strict=False))
if args.freeze_layers:
for name, para in model.named_parameters():
# 除head外,其他权重全部冻结
if "head" not in name:
para.requires_grad_(False)
else:
print("training {}".format(name))
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.AdamW(pg, lr=args.lr, weight_decay=5E-2)
for epoch in range(args.epochs):
# train
train_loss, train_acc = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
# validate
val_loss, val_acc = evaluate(model=model,
data_loader=val_loader,
device=device,
epoch=epoch)
tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]
tb_writer.add_scalar(tags[0], train_loss, epoch)
tb_writer.add_scalar(tags[1], train_acc, epoch)
tb_writer.add_scalar(tags[2], val_loss, epoch)
tb_writer.add_scalar(tags[3], val_acc, epoch)
tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)
torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--batch-size', type=int, default=8)
parser.add_argument('--lr', type=float, default=0.0001)
# 数据集所在根目录
# http://download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path', type=str,
default="/data/flower_photos")
# 预训练权重路径,如果不想载入就设置为空字符
parser.add_argument('--weights', type=str, default='./swin_tiny_patch4_window7_224.pth',
help='initial weights path')
# 是否冻结权重
parser.add_argument('--freeze-layers', type=bool, default=False)
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
main(opt)
utils.py
import os
import sys
import json
import pickle
import random
import torch
from tqdm import tqdm
import matplotlib.pyplot as plt
def read_split_data(root: str, val_rate: float = 0.2):
random.seed(0) # 保证随机结果可复现
assert os.path.exists(root), "dataset root: {} does not exist.".format(root)
# 遍历文件夹,一个文件夹对应一个类别
flower_class = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root, cla))]
# 排序,保证顺序一致
flower_class.sort()
# 生成类别名称以及对应的数字索引
class_indices = dict((k, v) for v, k in enumerate(flower_class))
json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
train_images_path = [] # 存储训练集的所有图片路径
train_images_label = [] # 存储训练集图片对应索引信息
val_images_path = [] # 存储验证集的所有图片路径
val_images_label = [] # 存储验证集图片对应索引信息
every_class_num = [] # 存储每个类别的样本总数
supported = [".jpg", ".JPG", ".png", ".PNG"] # 支持的文件后缀类型
# 遍历每个文件夹下的文件
for cla in flower_class:
cla_path = os.path.join(root, cla)
# 遍历获取supported支持的所有文件路径
images = [os.path.join(root, cla, i) for i in os.listdir(cla_path)
if os.path.splitext(i)[-1] in supported]
# 获取该类别对应的索引
image_class = class_indices[cla]
# 记录该类别的样本数量
every_class_num.append(len(images))
# 按比例随机采样验证样本
val_path = random.sample(images, k=int(len(images) * val_rate))
for img_path in images:
if img_path in val_path: # 如果该路径在采样的验证集样本中则存入验证集
val_images_path.append(img_path)
val_images_label.append(image_class)
else: # 否则存入训练集
train_images_path.append(img_path)
train_images_label.append(image_class)
print("{} images were found in the dataset.".format(sum(every_class_num)))
print("{} images for training.".format(len(train_images_path)))
print("{} images for validation.".format(len(val_images_path)))
plot_image = False
if plot_image:
# 绘制每种类别个数柱状图
plt.bar(range(len(flower_class)), every_class_num, align='center')
# 将横坐标0,1,2,3,4替换为相应的类别名称
plt.xticks(range(len(flower_class)), flower_class)
# 在柱状图上添加数值标签
for i, v in enumerate(every_class_num):
plt.text(x=i, y=v + 5, s=str(v), ha='center')
# 设置x坐标
plt.xlabel('image class')
# 设置y坐标
plt.ylabel('number of images')
# 设置柱状图的标题
plt.title('flower class distribution')
plt.show()
return train_images_path, train_images_label, val_images_path, val_images_label
def plot_data_loader_image(data_loader):
batch_size = data_loader.batch_size
plot_num = min(batch_size, 4)
json_path = './class_indices.json'
assert os.path.exists(json_path), json_path + " does not exist."
json_file = open(json_path, 'r')
class_indices = json.load(json_file)
for data in data_loader:
images, labels = data
for i in range(plot_num):
# [C, H, W] -> [H, W, C]
img = images[i].numpy().transpose(1, 2, 0)
# 反Normalize操作
img = (img * [0.229, 0.224, 0.225] + [0.485, 0.456, 0.406]) * 255
label = labels[i].item()
plt.subplot(1, plot_num, i+1)
plt.xlabel(class_indices[str(label)])
plt.xticks([]) # 去掉x轴的刻度
plt.yticks([]) # 去掉y轴的刻度
plt.imshow(img.astype('uint8'))
plt.show()
def write_pickle(list_info: list, file_name: str):
with open(file_name, 'wb') as f:
pickle.dump(list_info, f)
def read_pickle(file_name: str) -> list:
with open(file_name, 'rb') as f:
info_list = pickle.load(f)
return info_list
def train_one_epoch(model, optimizer, data_loader, device, epoch):
model.train()
loss_function = torch.nn.CrossEntropyLoss()
accu_loss = torch.zeros(1).to(device) # 累计损失
accu_num = torch.zeros(1).to(device) # 累计预测正确的样本数
optimizer.zero_grad()
sample_num = 0
data_loader = tqdm(data_loader)
for step, data in enumerate(data_loader):
images, labels = data
sample_num += images.shape[0]
pred = model(images.to(device))
pred_classes = torch.max(pred, dim=1)[1]
accu_num += torch.eq(pred_classes, labels.to(device)).sum()
loss = loss_function(pred, labels.to(device))
loss.backward()
accu_loss += loss.detach()
data_loader.desc = "[train epoch {}] loss: {:.3f}, acc: {:.3f}".format(epoch,
accu_loss.item() / (step + 1),
accu_num.item() / sample_num)
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss)
sys.exit(1)
optimizer.step()
optimizer.zero_grad()
return accu_loss.item() / (step + 1), accu_num.item() / sample_num
@torch.no_grad()
def evaluate(model, data_loader, device, epoch):
loss_function = torch.nn.CrossEntropyLoss()
model.eval()
accu_num = torch.zeros(1).to(device) # 累计预测正确的样本数
accu_loss = torch.zeros(1).to(device) # 累计损失
sample_num = 0
data_loader = tqdm(data_loader)
for step, data in enumerate(data_loader):
images, labels = data
sample_num += images.shape[0]
pred = model(images.to(device))
pred_classes = torch.max(pred, dim=1)[1]
accu_num += torch.eq(pred_classes, labels.to(device)).sum()
loss = loss_function(pred, labels.to(device))
accu_loss += loss
data_loader.desc = "[valid epoch {}] loss: {:.3f}, acc: {:.3f}".format(epoch,
accu_loss.item() / (step + 1),
accu_num.item() / sample_num)
return accu_loss.item() / (step + 1), accu_num.item() / sample_num
my_dataset.py
from PIL import Image
import torch
from torch.utils.data import Dataset
class MyDataSet(Dataset):
"""自定义数据集"""
def __init__(self, images_path: list, images_class: list, transform=None):
self.images_path = images_path
self.images_class = images_class
self.transform = transform
def __len__(self):
return len(self.images_path)
def __getitem__(self, item):
img = Image.open(self.images_path[item])
# RGB为彩色图片,L为灰度图片
if img.mode != 'RGB':
raise ValueError("image: {} isn't RGB mode.".format(self.images_path[item]))
label = self.images_class[item]
if self.transform is not None:
img = self.transform(img)
return img, label
@staticmethod
def collate_fn(batch):
# 官方实现的default_collate可以参考
# https://github.com/pytorch/pytorch/blob/67b7e751e6b5931a9f45274653f4f653a4e6cdf6/torch/utils/data/_utils/collate.py
images, labels = tuple(zip(*batch))
images = torch.stack(images, dim=0)
labels = torch.as_tensor(labels)
return images, labels
tensorflow2_keras实现
model.py
import tensorflow as tf
from tensorflow.keras import Model, layers, initializers
import numpy as np
class PatchEmbed(layers.Layer):
"""
2D Image to Patch Embedding
"""
def __init__(self, patch_size=4, embed_dim=96, norm_layer=None):
super(PatchEmbed, self).__init__()
self.embed_dim = embed_dim
self.patch_size = (patch_size, patch_size)
self.norm = norm_layer(epsilon=1e-6, name="norm") if norm_layer else layers.Activation('linear')
self.proj = layers.Conv2D(filters=embed_dim, kernel_size=patch_size,
strides=patch_size, padding='SAME',
kernel_initializer=initializers.LecunNormal(),
bias_initializer=initializers.Zeros(),
name="proj")
def call(self, x, **kwargs):
_, H, W, _ = x.shape
# padding
# 支持多尺度
# 如果输入图片的H,W不是patch_size的整数倍,需要进行padding
pad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)
if pad_input:
paddings = tf.constant([[0, 0],
[0, self.patch_size[0] - H % self.patch_size[0]],
[0, self.patch_size[1] - W % self.patch_size[1]]])
x = tf.pad(x, paddings)
# 下采样patch_size倍
x = self.proj(x)
B, H, W, C = x.shape
# [B, H, W, C] -> [B, H*W, C]
x = tf.reshape(x, [B, -1, C])
x = self.norm(x)
return x, H, W
def window_partition(x, window_size: int):
"""
将feature map按照window_size划分成一个个没有重叠的window
Args:
x: (B, H, W, C)
window_size (int): window size(M)
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = tf.reshape(x, [B, H // window_size, window_size, W // window_size, window_size, C])
# transpose: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H//Mh, W//Mh, Mw, Mw, C]
# reshape: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B*num_windows, Mh, Mw, C]
x = tf.transpose(x, [0, 1, 3, 2, 4, 5])
windows = tf.reshape(x, [-1, window_size, window_size, C])
return windows
def window_reverse(windows, window_size: int, H: int, W: int):
"""
将一个个window还原成一个feature map
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size(M)
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
# reshape: [B*num_windows, Mh, Mw, C] -> [B, H//Mh, W//Mw, Mh, Mw, C]
x = tf.reshape(windows, [B, H // window_size, W // window_size, window_size, window_size, -1])
# permute: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B, H//Mh, Mh, W//Mw, Mw, C]
# reshape: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H, W, C]
x = tf.transpose(x, [0, 1, 3, 2, 4, 5])
x = tf.reshape(x, [B, H, W, -1])
return x
class PatchMerging(layers.Layer):
def __init__(self, dim: int, norm_layer=layers.LayerNormalization, name=None):
super(PatchMerging, self).__init__(name=name)
self.dim = dim
self.reduction = layers.Dense(2*dim,
use_bias=False,
kernel_initializer=initializers.TruncatedNormal(stddev=0.02),
name="reduction")
self.norm = norm_layer(epsilon=1e-6, name="norm")
def call(self, x, H, W):
"""
x: [B, H*W, C]
"""
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
x = tf.reshape(x, [B, H, W, C])
# padding
# 如果输入feature map的H,W不是2的整数倍,需要进行padding
pad_input = (H % 2 != 0) or (W % 2 != 0)
if pad_input:
paddings = tf.constant([[0, 0],
[0, 1],
[0, 1],
[0, 0]])
x = tf.pad(x, paddings)
x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C]
x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C]
x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C]
x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C]
x = tf.concat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]
x = tf.reshape(x, [B, -1, 4*C]) # [B, H/2*W/2, 4*C]
x = self.norm(x)
x = self.reduction(x) # [B, H/2*W/2, 2*C]
return x
class MLP(layers.Layer):
"""
MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
k_ini = initializers.TruncatedNormal(stddev=0.02)
b_ini = initializers.Zeros()
def __init__(self, in_features, mlp_ratio=4.0, drop=0., name=None):
super(MLP, self).__init__(name=name)
self.fc1 = layers.Dense(int(in_features * mlp_ratio), name="fc1",
kernel_initializer=self.k_ini, bias_initializer=self.b_ini)
self.act = layers.Activation("gelu")
self.fc2 = layers.Dense(in_features, name="fc2",
kernel_initializer=self.k_ini, bias_initializer=self.b_ini)
self.drop = layers.Dropout(drop)
def call(self, x, training=None):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x, training=training)
x = self.fc2(x)
x = self.drop(x, training=training)
return x
class WindowAttention(layers.Layer):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
attn_drop_ratio (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop_ratio (float, optional): Dropout ratio of output. Default: 0.0
"""
k_ini = initializers.GlorotUniform()
b_ini = initializers.Zeros()
def __init__(self,
dim,
window_size,
num_heads=8,
qkv_bias=False,
attn_drop_ratio=0.,
proj_drop_ratio=0.,
name=None):
super(WindowAttention, self).__init__(name=name)
self.dim = dim
self.window_size = window_size # [Mh, Mw]
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = layers.Dense(dim * 3, use_bias=qkv_bias, name="qkv",
kernel_initializer=self.k_ini, bias_initializer=self.b_ini)
self.attn_drop = layers.Dropout(attn_drop_ratio)
self.proj = layers.Dense(dim, name="proj",
kernel_initializer=self.k_ini, bias_initializer=self.b_ini)
self.proj_drop = layers.Dropout(proj_drop_ratio)
def build(self, input_shape):
# define a parameter table of relative position bias
# [2*Mh-1 * 2*Mw-1, nH]
self.relative_position_bias_table = self.add_weight(
shape=[(2 * self.window_size[0] - 1) * (2 * self.window_size[1] - 1), self.num_heads],
initializer=initializers.TruncatedNormal(stddev=0.02),
trainable=True,
dtype=tf.float32,
name="relative_position_bias_table"
)
coords_h = np.arange(self.window_size[0])
coords_w = np.arange(self.window_size[1])
coords = np.stack(np.meshgrid(coords_h, coords_w, indexing="ij")) # [2, Mh, Mw]
coords_flatten = np.reshape(coords, [2, -1]) # [2, Mh*Mw]
# [2, Mh*Mw, 1] - [2, 1, Mh*Mw]
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # [2, Mh*Mw, Mh*Mw]
relative_coords = np.transpose(relative_coords, [1, 2, 0]) # [Mh*Mw, Mh*Mw, 2]
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # [Mh*Mw, Mh*Mw]
self.relative_position_index = tf.Variable(tf.convert_to_tensor(relative_position_index),
trainable=False,
dtype=tf.int64,
name="relative_position_index")
def call(self, x, mask=None, training=None):
"""
Args:
x: input features with shape of (num_windows*B, Mh*Mw, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
training: whether training mode
"""
# [batch_size*num_windows, Mh*Mw, total_embed_dim]
B_, N, C = x.shape
# qkv(): -> [batch_size*num_windows, Mh*Mw, 3 * total_embed_dim]
qkv = self.qkv(x)
# reshape: -> [batch_size*num_windows, Mh*Mw, 3, num_heads, embed_dim_per_head]
qkv = tf.reshape(qkv, [B_, N, 3, self.num_heads, C // self.num_heads])
# transpose: -> [3, batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
qkv = tf.transpose(qkv, [2, 0, 3, 1, 4])
# [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
q, k, v = qkv[0], qkv[1], qkv[2]
# transpose: -> [batch_size*num_windows, num_heads, embed_dim_per_head, Mh*Mw]
# multiply -> [batch_size*num_windows, num_heads, Mh*Mw, Mh*Mw]
attn = tf.matmul(a=q, b=k, transpose_b=True) * self.scale
# relative_position_bias(reshape): [Mh*Mw*Mh*Mw,nH] -> [Mh*Mw,Mh*Mw,nH]
relative_position_bias = tf.gather(self.relative_position_bias_table,
tf.reshape(self.relative_position_index, [-1]))
relative_position_bias = tf.reshape(relative_position_bias,
[self.window_size[0] * self.window_size[1],
self.window_size[0] * self.window_size[1],
-1])
relative_position_bias = tf.transpose(relative_position_bias, [2, 0, 1]) # [nH, Mh*Mw, Mh*Mw]
attn = attn + tf.expand_dims(relative_position_bias, 0)
if mask is not None:
# mask: [nW, Mh*Mw, Mh*Mw]
nW = mask.shape[0] # num_windows
# attn(reshape): [batch_size, num_windows, num_heads, Mh*Mw, Mh*Mw]
# mask(expand_dim): [1, nW, 1, Mh*Mw, Mh*Mw]
attn = tf.reshape(attn, [B_ // nW, nW, self.num_heads, N, N]) + tf.expand_dims(tf.expand_dims(mask, 1), 0)
attn = tf.reshape(attn, [-1, self.num_heads, N, N])
attn = tf.nn.softmax(attn, axis=-1)
attn = self.attn_drop(attn, training=training)
# multiply -> [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
x = tf.matmul(attn, v)
# transpose: -> [batch_size*num_windows, Mh*Mw, num_heads, embed_dim_per_head]
x = tf.transpose(x, [0, 2, 1, 3])
# reshape: -> [batch_size*num_windows, Mh*Mw, total_embed_dim]
x = tf.reshape(x, [B_, N, C])
x = self.proj(x)
x = self.proj_drop(x, training=training)
return x
class SwinTransformerBlock(layers.Layer):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
"""
def __init__(self, dim, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0., name=None):
super().__init__(name=name)
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = layers.LayerNormalization(epsilon=1e-6, name="norm1")
self.attn = WindowAttention(dim,
window_size=(window_size, window_size),
num_heads=num_heads,
qkv_bias=qkv_bias,
attn_drop_ratio=attn_drop,
proj_drop_ratio=drop,
name="attn")
self.drop_path = layers.Dropout(rate=drop_path, noise_shape=(None, 1, 1)) if drop_path > 0. \
else layers.Activation("linear")
self.norm2 = layers.LayerNormalization(epsilon=1e-6, name="norm2")
self.mlp = MLP(dim, drop=drop, name="mlp")
def call(self, x, attn_mask, training=None):
H, W = self.H, self.W
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = tf.reshape(x, [B, H, W, C])
# pad feature maps to multiples of window size
# 把feature map给pad到window size的整数倍
pad_r = (self.window_size - W % self.window_size) % self.window_size
pad_b = (self.window_size - H % self.window_size) % self.window_size
if pad_r > 0 or pad_b > 0:
paddings = tf.constant([[0, 0],
[0, pad_r],
[0, pad_b],
[0, 0]])
x = tf.pad(x, paddings)
_, Hp, Wp, _ = x.shape
# cyclic shift
if self.shift_size > 0:
shifted_x = tf.roll(x, shift=(-self.shift_size, -self.shift_size), axis=(1, 2))
else:
shifted_x = x
attn_mask = None
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # [nW*B, Mh, Mw, C]
x_windows = tf.reshape(x_windows, [-1, self.window_size * self.window_size, C]) # [nW*B, Mh*Mw, C]
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask, training=training) # [nW*B, Mh*Mw, C]
# merge windows
attn_windows = tf.reshape(attn_windows,
[-1, self.window_size, self.window_size, C]) # [nW*B, Mh, Mw, C]
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # [B, H', W', C]
# reverse cyclic shift
if self.shift_size > 0:
x = tf.roll(shifted_x, shift=(self.shift_size, self.shift_size), axis=(1, 2))
else:
x = shifted_x
if pad_r > 0 or pad_b > 0:
# 把前面pad的数据移除掉
x = tf.slice(x, begin=[0, 0, 0, 0], size=[B, H, W, C])
x = tf.reshape(x, [B, H * W, C])
# FFN
x = shortcut + self.drop_path(x, training=training)
x = x + self.drop_path(self.mlp(self.norm2(x)), training=training)
return x
class BasicLayer(layers.Layer):
"""
A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
downsample (layer.Layer | None, optional): Downsample layer at the end of the layer. Default: None
"""
def __init__(self, dim, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.,
drop_path=0., downsample=None, name=None):
super().__init__(name=name)
self.dim = dim
self.depth = depth
self.window_size = window_size
self.shift_size = window_size // 2
# build blocks
self.blocks = [
SwinTransformerBlock(dim=dim,
num_heads=num_heads,
window_size=window_size,
shift_size=0 if (i % 2 == 0) else self.shift_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
name=f"block{i}")
for i in range(depth)
]
# patch merging layer
if downsample is not None:
self.downsample = downsample(dim=dim, name="downsample")
else:
self.downsample = None
def create_mask(self, H, W):
# calculate attention mask for SW-MSA
# 保证Hp和Wp是window_size的整数倍
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
# 拥有和feature map一样的通道排列顺序,方便后续window_partition
img_mask = np.zeros([1, Hp, Wp, 1]) # [1, Hp, Wp, 1]
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
img_mask = tf.convert_to_tensor(img_mask, dtype=tf.float32)
mask_windows = window_partition(img_mask, self.window_size) # [nW, Mh, Mw, 1]
mask_windows = tf.reshape(mask_windows, [-1, self.window_size * self.window_size]) # [nW, Mh*Mw]
# [nW, 1, Mh*Mw] - [nW, Mh*Mw, 1]
attn_mask = tf.expand_dims(mask_windows, 1) - tf.expand_dims(mask_windows, 2)
attn_mask = tf.where(attn_mask != 0, -100.0, attn_mask)
attn_mask = tf.where(attn_mask == 0, 0.0, attn_mask)
return attn_mask
def call(self, x, H, W, training=None):
attn_mask = self.create_mask(H, W) # [nW, Mh*Mw, Mh*Mw]
for blk in self.blocks:
blk.H, blk.W = H, W
x = blk(x, attn_mask, training=training)
if self.downsample is not None:
x = self.downsample(x, H, W)
H, W = (H + 1) // 2, (W + 1) // 2
return x, H, W
class SwinTransformer(Model):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
patch_size (int | tuple(int)): Patch size. Default: 4
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, patch_size=4, num_classes=1000,
embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24),
window_size=7, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=layers.LayerNormalization, name=None, **kwargs):
super().__init__(name=name)
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(patch_size=patch_size,
embed_dim=embed_dim,
norm_layer=norm_layer)
self.pos_drop = layers.Dropout(drop_rate)
# stochastic depth decay rule
dpr = [x for x in np.linspace(0, drop_path_rate, sum(depths))]
# build layers
self.stage_layers = []
for i_layer in range(self.num_layers):
# 注意这里构建的stage和论文图中有些差异
# 这里的stage不包含该stage的patch_merging层,包含的是下个stage的
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
name=f"layer{i_layer}")
self.stage_layers.append(layer)
self.norm = norm_layer(epsilon=1e-6, name="norm")
self.head = layers.Dense(num_classes,
kernel_initializepythonr=initializers.TruncatedNormal(stddev=0.02),
bias_initializer=initializers.Zeros(),
name="head")
# 对应forward
def call(self, x, training=None):
x, H, W = self.patch_embed(x) # x: [B, L, C]
x = self.pos_drop(x, training=training)
for layer in self.stage_layers:
x, H, W = layer(x, H, W, training=training)
x = self.norm(x) # [B, L, C]
x = tf.reduce_mean(x, axis=1)
x = self.head(x)
return x
def swin_tiny_patch4_window7_224(num_classes: int = 1000, **kwargs):
model = SwinTransformer(patch_size=4,
window_size=7,
embed_dim=96,
depths=(2, 2, 6, 2),
num_heads=(3, 6, 12, 24),
num_classes=num_classes,
name="swin_tiny_patch4_window7",
**kwargs)
return model
def swin_small_patch4_window7_224(num_classes: int = 1000, **kwargs):
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=96,
depths=(2, 2, 18, 2),
num_heads=(3, 6, 12, 24),
num_classes=num_classes,
name="swin_small_patch4_window7",
**kwargs)
return model
def swin_base_patch4_window7_224(num_classes: int = 1000, **kwargs):
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
name="swin_base_patch4_window7",
**kwargs)
return model
def swin_base_patch4_window12_384(num_classes: int = 1000, **kwargs):
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=12,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
name="swin_base_patch4_window12",
**kwargs)
return model
def swin_base_patch4_window7_224_in22k(num_classes: int = 21841, **kwargs):
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
name="swin_base_patch4_window7",
**kwargs)
return model
def swin_base_patch4_window12_384_in22k(num_classes: int = 21841, **kwargs):
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=12,
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
num_classes=num_classes,
name="swin_base_patch4_window12",
**kwargs)
return model
def swin_large_patch4_window7_224_in22k(num_classes: int = 21841, **kwargs):
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=7,
embed_dim=192,
depths=(2, 2, 18, 2),
num_heads=(6, 12, 24, 48),
num_classes=num_classes,
name="swin_large_patch4_window7",
**kwargs)
return model
def swin_large_patch4_window12_384_in22k(num_classes: int = 21841, **kwargs):
model = SwinTransformer(in_chans=3,
patch_size=4,
window_size=12,
embed_dim=192,
depths=(2, 2, 18, 2),
num_heads=(6, 12, 24, 48),
num_classes=num_classes,
name="swin_large_patch4_window12",
**kwargs)
return model
predict.py
import os
import json
import glob
import numpy as np
from PIL import Image
import tensorflow as tf
import matplotlib.pyplot as plt
from model import swin_tiny_patch4_window7_224 as create_model
def main():
num_classes = 5
im_height = im_width = 224
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
# resize image
img = img.resize((im_width, im_height))
plt.imshow(img)
# read image
img = np.array(img).astype(np.float32)
# preprocess
img = (img / 255. - [0.485, 0.456, 0.406]) / [0.229, 0.224, 0.225]
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img, 0))
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = create_model(num_classes=num_classes)
model.build([1, im_height, im_width, 3])
weights_path = './save_weights/model.ckpt'
assert len(glob.glob(weights_path+"*")), "cannot find {}".format(weights_path)
model.load_weights(weights_path)
result = np.squeeze(model.predict(img, batch_size=1))
result = tf.keras.layers.Softmax()(result)
predict_class = np.argmax(result)
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_class)],
result[predict_class])
plt.title(print_res)
print(print_res)
plt.show()
if __name__ == '__main__':
main()
train.py
import os
import re
import datetime
import tensorflow as tf
from tqdm import tqdm
from model import swin_tiny_patch4_window7_224 as create_model
from utils import generate_ds
assert tf.version.VERSION >= "2.4.0", "version of tf must greater/equal than 2.4.0"
def main():
data_root = "/data/flower_photos" # get data root path
if not os.path.exists("./save_weights"):
os.makedirs("./save_weights")
img_size = 224
batch_size = 8
epochs = 10
num_classes = 5
freeze_layers = False
initial_lr = 0.0001
weight_decay = 1e-5
log_dir = "./logs/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_writer = tf.summary.create_file_writer(os.path.join(log_dir, "train"))
val_writer = tf.summary.create_file_writer(os.path.join(log_dir, "val"))
# data generator with data augmentation
train_ds, val_ds = generate_ds(data_root,
train_im_width=img_size,
train_im_height=img_size,
batch_size=batch_size,
val_rate=0.2)
# create model
model = create_model(num_classes=num_classes)
model.build((1, img_size, img_size, 3))
# 下载我提前转好的预训练权重
# 链接: https://pan.baidu.com/s/1cHVwia2i3wD7-0Ueh2WmrQ 密码: sq8c
# load weights
pre_weights_path = './swin_tiny_patch4_window7_224.h5'
assert os.path.exists(pre_weights_path), "cannot find {}".format(pre_weights_path)
model.load_weights(pre_weights_path, by_name=True, skip_mismatch=True)
# freeze bottom layers
if freeze_layers:
for layer in model.layers:
if "head" not in layer.name:
layer.trainable = False
else:
print("training {}".format(layer.name))
model.summary()
# using keras low level api for training
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.Adam(learning_rate=initial_lr)
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
val_loss = tf.keras.metrics.Mean(name='val_loss')
val_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='val_accuracy')
@tf.function
def train_step(train_images, train_labels):
with tf.GradientTape() as tape:
output = model(train_images, training=True)
# cross entropy loss
ce_loss = loss_object(train_labels, output)
# l2 loss
matcher = re.compile(".*(bias|gamma|beta).*")
l2loss = weight_decay * tf.add_n([
tf.nn.l2_loss(v)
for v in model.trainable_variables
if not matcher.match(v.name)
])
loss = ce_loss + l2loss
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(ce_loss)
train_accuracy(train_labels, output)
@tf.function
def val_step(val_images, val_labels):
output = model(val_images, training=False)
loss = loss_object(val_labels, output)
val_loss(loss)
val_accuracy(val_labels, output)
best_val_acc = 0.
for epoch in range(epochs):
train_loss.reset_states() # clear history info
train_accuracy.reset_states() # clear history info
val_loss.reset_states() # clear history info
val_accuracy.reset_states() # clear history info
# train
train_bar = tqdm(train_ds)
for images, labels in train_bar:
train_step(images, labels)
# print train process
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}, acc:{:.3f}".format(epoch + 1,
epochs,
train_loss.result(),
train_accuracy.result())
# validate
val_bar = tqdm(val_ds)
for images, labels in val_bar:
val_step(images, labels)
# print val process
val_bar.desc = "valid epoch[{}/{}] loss:{:.3f}, acc:{:.3f}".format(epoch + 1,
epochs,
val_loss.result(),
val_accuracy.result())
# writing training loss and acc
with train_writer.as_default():
tf.summary.scalar("loss", train_loss.result(), epoch)
tf.summary.scalar("accuracy", train_accuracy.result(), epoch)
# writing validation loss and acc
with val_writer.as_default():
tf.summary.scalar("loss", val_loss.result(), epoch)
tf.summary.scalar("accuracy", val_accuracy.result(), epoch)
# only save best weights
if val_accuracy.result() > best_val_acc:
best_val_acc = val_accuracy.result()
save_name = "./save_weights/model.ckpt"
model.save_weights(save_name, save_format="tf")
if __name__ == '__main__':
main()
trans_weights.py
import torch
from model import *
def main(weights_path: str,
model_name: str,
model: tf.keras.Model):
var_dict = {v.name.split(':')[0]: v for v in model.weights}
weights_dict = torch.load(weights_path, map_location="cpu")["model"]
w_dict = {}
for k, v in weights_dict.items():
if "patch_embed" in k:
k = k.replace(".", "/")
if "proj" in k:
k = k.replace("proj/weight", "proj/kernel")
if len(v.shape) > 1:
# conv weights
v = np.transpose(v.numpy(), (2, 3, 1, 0)).astype(np.float32)
w_dict[k] = v
else:
# bias
w_dict[k] = v
elif "norm" in k:
k = k.replace("weight", "gamma").replace("bias", "beta")
w_dict[k] = v
elif "layers" in k:
k = k.replace("layers", "layer")
split_k = k.split(".")
layer_id = split_k[0] + split_k[1]
if "block" in k:
split_k[2] = "block"
black_id = split_k[2] + split_k[3]
k = "/".join([layer_id, black_id, *split_k[4:]])
if "attn" in k or "mlp" in k:
k = k.replace("weight", "kernel")
if "kernel" in k:
v = np.transpose(v.numpy(), (1, 0)).astype(np.float32)
elif "norm" in k:
k = k.replace("weight", "gamma").replace("bias", "beta")
w_dict[k] = v
elif "downsample" in k:
k = "/".join([layer_id, *split_k[2:]])
if "reduction" in k:
k = k.replace("weight", "kernel")
if "kernel" in k:
v = np.transpose(v.numpy(), (1, 0)).astype(np.float32)
elif "norm" in k:
k = k.replace("weight", "gamma").replace("bias", "beta")
w_dict[k] = v
elif "norm" in k:
k = k.replace(".", "/").replace("weight", "gamma").replace("bias", "beta")
w_dict[k] = v
elif "head" in k:
k = k.replace(".", "/")
k = k.replace("weight", "kernel")
if "kernel" in k:
v = np.transpose(v.numpy(), (1, 0)).astype(np.float32)
w_dict[k] = v
for key, var in var_dict.items():
if key in w_dict:
if w_dict[key].shape != var.shape:
msg = "shape mismatch: {}".format(key)
print(msg)
else:
var.assign(w_dict[key], read_value=False)
else:
msg = "Not found {} in {}".format(key, weights_path)
print(msg)
model.save_weights("./{}.h5".format(model_name))
if __name__ == '__main__':
model = swin_tiny_patch4_window7_224()
model.build((1, 224, 224, 3))
# trained ImageNet-1K
# https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth
main(weights_path="./swin_tiny_patch4_window7_224.pth",
model_name="swin_tiny_patch4_window7_224",
model=model)
# model = swin_small_patch4_window7_224()
# model.build((1, 224, 224, 3))
# # trained ImageNet-1K
# # https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth
# main(weights_path="./swin_small_patch4_window7_224.pth",
# model_name="swin_small_patch4_window7_224",
# model=model)
# model = swin_base_patch4_window7_224()
# model.build((1, 224, 224, 3))
# # trained ImageNet-1K
# # https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224.pth
# main(weights_path="./swin_base_patch4_window7_224.pth",
# model_name="swin_base_patch4_window7_224",
# model=model)
# model = swin_base_patch4_window12_384()
# model.build((1, 384, 384, 3))
# # trained ImageNet-1K
# # https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384.pth
# main(weights_path="./swin_base_patch4_window12_384.pth",
# model_name="swin_base_patch4_window12_384",
# model=model)
# model = swin_base_patch4_window7_224_in22k()
# model.build((1, 224, 224, 3))
# # trained ImageNet-22K
# # https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth
# main(weights_path="./swin_base_patch4_window7_224_22k.pth",
# model_name="swin_base_patch4_window7_224_22k",
# model=model)
# model = swin_base_patch4_window12_384_in22k()
# model.build((1, 384, 384, 3))
# # trained ImageNet-22K
# # https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22k.pth
# main(weights_path="./swin_base_patch4_window12_384_22k.pth",
# model_name="swin_base_patch4_window12_384_22k",
# model=model)
# model = swin_large_patch4_window7_224_in22k()
# model.build((1, 224, 224, 3))
# # trained ImageNet-22K
# # https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window7_224_22k.pth
# main(weights_path="./swin_large_patch4_window7_224_22k.pth",
# model_name="swin_large_patch4_window7_224_22k",
# model=model)
# model = swin_large_patch4_window12_384_in22k()
# model.build((1, 384, 384, 3))
# # trained ImageNet-22K
# # https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22k.pth
# main(weights_path="./swin_large_patch4_window12_384_22k.pth",
# model_name="swin_large_patch4_window12_384_22k",
# model=model)
utils.py
import os
import json
import random
import tensorflow as tf
import matplotlib.pyplot as plt
def read_split_data(root: str, val_rate: float = 0.2):
random.seed(0) # 保证随机划分结果一致
assert os.path.exists(root), "dataset root: {} does not exist.".format(root)
# 遍历文件夹,一个文件夹对应一个类别
flower_class = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root, cla))]
# 排序,保证顺序一致
flower_class.sort()
# 生成类别名称以及对应的数字索引
class_indices = dict((k, v) for v, k in enumerate(flower_class))
json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
train_images_path = [] # 存储训练集的所有图片路径
train_images_label = [] # 存储训练集图片对应索引信息
val_images_path = [] # 存储验证集的所有图片路径
val_images_label = [] # 存储验证集图片对应索引信息
every_class_num = [] # 存储每个类别的样本总数
supported = [".jpg", ".JPG", ".jpeg", ".JPEG"] # 支持的文件后缀类型
# 遍历每个文件夹下的文件
for cla in flower_class:
cla_path = os.path.join(root, cla)
# 遍历获取supported支持的所有文件路径
images = [os.path.join(root, cla, i) for i in os.listdir(cla_path)
if os.path.splitext(i)[-1] in supported]
# 获取该类别对应的索引
image_class = class_indices[cla]
# 记录该类别的样本数量
every_class_num.append(len(images))
# 按比例随机采样验证样本
val_path = random.sample(images, k=int(len(images) * val_rate))
for img_path in images:
if img_path in val_path: # 如果该路径在采样的验证集样本中则存入验证集
val_images_path.append(img_path)
val_images_label.append(image_class)
else: # 否则存入训练集
train_images_path.append(img_path)
train_images_label.append(image_class)
print("{} images were found in the dataset.\n{} for training, {} for validation".format(sum(every_class_num),
len(train_images_path),
len(val_images_path)
))
plot_image = False
if plot_image:
# 绘制每种类别个数柱状图
plt.bar(range(len(flower_class)), every_class_num, align='center')
# 将横坐标0,1,2,3,4替换为相应的类别名称
plt.xticks(range(len(flower_class)), flower_class)
# 在柱状图上添加数值标签
for i, v in enumerate(every_class_num):
plt.text(x=i, y=v + 5, s=str(v), ha='center')
# 设置x坐标
plt.xlabel('image class')
# 设置y坐标
plt.ylabel('number of images')
# 设置柱状图的标题
plt.title('flower class distribution')
plt.show()
return train_images_path, train_images_label, val_images_path, val_images_label
def generate_ds(data_root: str,
train_im_height: int = 224,
train_im_width: int = 224,
val_im_height: int = None,
val_im_width: int = None,
batch_size: int = 8,
val_rate: float = 0.1,
cache_data: bool = False):
"""
读取划分数据集,并生成训练集和验证集的迭代器
:param data_root: 数据根目录
:param train_im_height: 训练输入网络图像的高度
:param train_im_width: 训练输入网络图像的宽度
:param val_im_height: 验证输入网络图像的高度
:param val_im_width: 验证输入网络图像的宽度
:param batch_size: 训练使用的batch size
:param val_rate: 将数据按给定比例划分到验证集
:param cache_data: 是否缓存数据
:return:
"""
assert train_im_height is not None
assert train_im_width is not None
if val_im_width is None:
val_im_width = train_im_width
if val_im_height is None:
val_im_height = train_im_height
train_img_path, train_img_label, val_img_path, val_img_label = read_split_data(data_root, val_rate=val_rate)
AUTOTUNE = tf.data.experimental.AUTOTUNE
def process_train_info(img_path, label):
image = tf.io.read_file(img_path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.cast(image, tf.float32)
image = tf.image.resize_with_crop_or_pad(image, train_im_height, train_im_width)
image = tf.image.random_flip_left_right(image)
image = (image / 255. - [0.485, 0.456, 0.406]) / [0.229, 0.224, 0.225]
return image, label
def process_val_info(img_path, label):
image = tf.io.read_file(img_path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.cast(image, tf.float32)
image = tf.image.resize_with_crop_or_pad(image, val_im_height, val_im_width)
image = (image / 255. - [0.485, 0.456, 0.406]) / [0.229, 0.224, 0.225]
return image, label
# Configure dataset for performance
def configure_for_performance(ds,
shuffle_size: int,
shuffle: bool = False,
cache: bool = False):
if cache:
ds = ds.cache() # 读取数据后缓存至内存
if shuffle:
ds = ds.shuffle(buffer_size=shuffle_size) # 打乱数据顺序
ds = ds.batch(batch_size) # 指定batch size
ds = ds.prefetch(buffer_size=AUTOTUNE) # 在训练的同时提前准备下一个step的数据
return ds
train_ds = tf.data.Dataset.from_tensor_slices((tf.constant(train_img_path),
tf.constant(train_img_label)))
total_train = len(train_img_path)
# Use Dataset.map to create a dataset of image, label pairs
train_ds = train_ds.map(process_train_info, num_parallel_calls=AUTOTUNE)
train_ds = configure_for_performance(train_ds, total_train, shuffle=True, cache=cache_data)
val_ds = tf.data.Dataset.from_tensor_slices((tf.constant(val_img_path),
tf.constant(val_img_label)))
total_val = len(val_img_path)
# Use Dataset.map to create a dataset of image, label pairs
val_ds = val_ds.map(process_val_info, num_parallel_calls=AUTOTUNE)
val_ds = configure_for_performance(val_ds, total_val, cache=False)
return train_ds, val_ds
本文来自博客园,作者:甫生,转载请注明原文链接:https://www.cnblogs.com/fusheng-rextimmy/p/15570094.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号