Zookeeper分布式服务协调组件
Zookeeper是一个分布式服务协调组件,是Hadoop、Hbase、Kafka重要的依赖组件,为分布式应用提供一致性服务的组件。
Zookeeper是Hadoop、HBase、Kafka的重要依赖组件。
Zookeeper主要包含文件系统以及通知机制两个部分。
2.模型
2.1 Zookeeper的文件系统

Zookeeper维护了一个类似文件系统的数据结构,有根目录和若干个子目录 (树形结构 , 与Linux类似 )
每个目录都称为一个znode,每个znode都包含自身节点的数据,同时每个znode下可以包含多个子znode。
在创建znode时必须指定znode的数据,可以为null。
znode保存的数据存在版本号,当进行更新操作时版本号会+1。
删除znode时,若该znode包含子znode,那么必须先删除所有的子znode,否则无法删除。
当使用JAVA进行更新和删除操作时,需要传递数据的版本号,其内部进行CAS判断,当且仅当传递的版本号与当前节点的版本号相同时,才进行操作。
ZNode类型
持久化节点:无论客户端的连接是否断开,节点以及节点中的数据都会被保留。 持久化节点并顺序编号:在持久化节点的基础上,对节点进行顺序编号(编号最大为Integer.MAX_SIZE,创建/p持久化节点并顺序编号时,Zookeeper将把节点命名为/p1,当再次创建/p节点时,自动命名为/p2) 临时节点:当客户端的连接断开,节点以及节点中的数据将会被删除。 临时节点并顺序编号:在临时节点的基础上,对节点进行顺序编号。
2.2 Zookeeper的通知机制
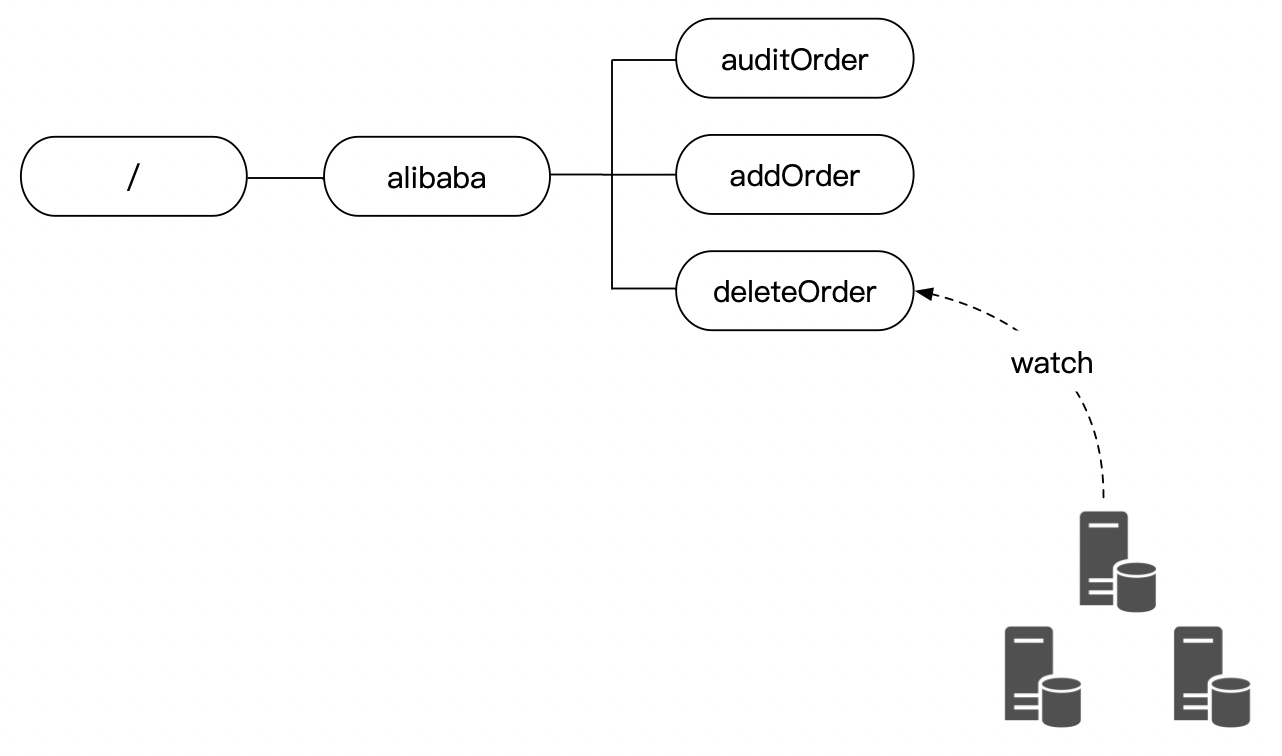
客户端可以监听它所关注的节点,当节点的状态发生变化时(比如数据的版本号发生改变、节点被删除、节点添加子节点或者删除子节点),Zookeeper将会通知客户端。
Zookeeper并不是根据节点的值发生改变而触发通知的,而是根据节点中数据的版本号,所以修改后的内容相同那么一样会进行通知。
2.3 Zookeeper集群

当搭建了一个Zookeeper集群后,Zookeeper会根据选举算法,从多个ZK Server中选取一个作为Leader,剩余的作为Follower,Leader会与各个Follower之间建立一个有效的长连接,以保证各个节点的通信正常。
当某个节点收到修改操作时,首先会把请求转发给Leader,有Leader负责数据的读写操作然后再把修改同步给所有的Follower节点,一旦Leader节点挂了,那么会从剩余的Follower节点中选举一个新的Leader节点(重新选取的时间很短,大概200ms)
2.4 关于Zookeeper集群的脑裂
Zookeeper集群中存在一个Leader,多个Follower,Leader与Follower之间将会通过心跳机制来确保其还存活着(Leader会定期向所有的Follower发送心跳)
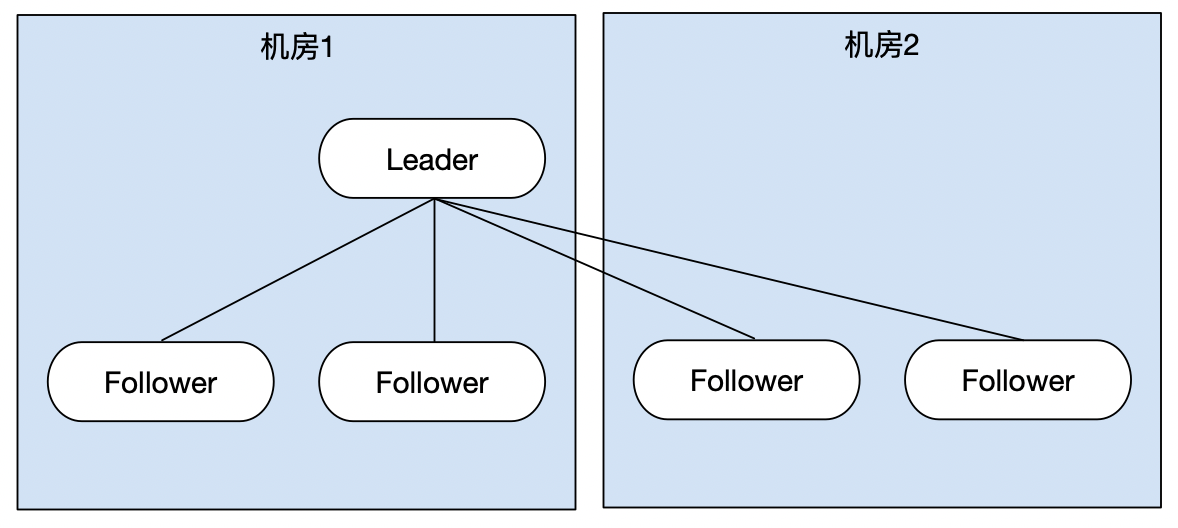
如果集群中有部分的Follower由于网络等问题无法与Leader进行通讯,那么它将收不到Leader的心跳,将会认为Leader已经死亡,但是它们之间是可以互相进行访问的,此时它们将会组成一个新的集群,选举出一个新的Leader,那么此时将会有两个ZK集群,每个集群中都有一个Leader节点。
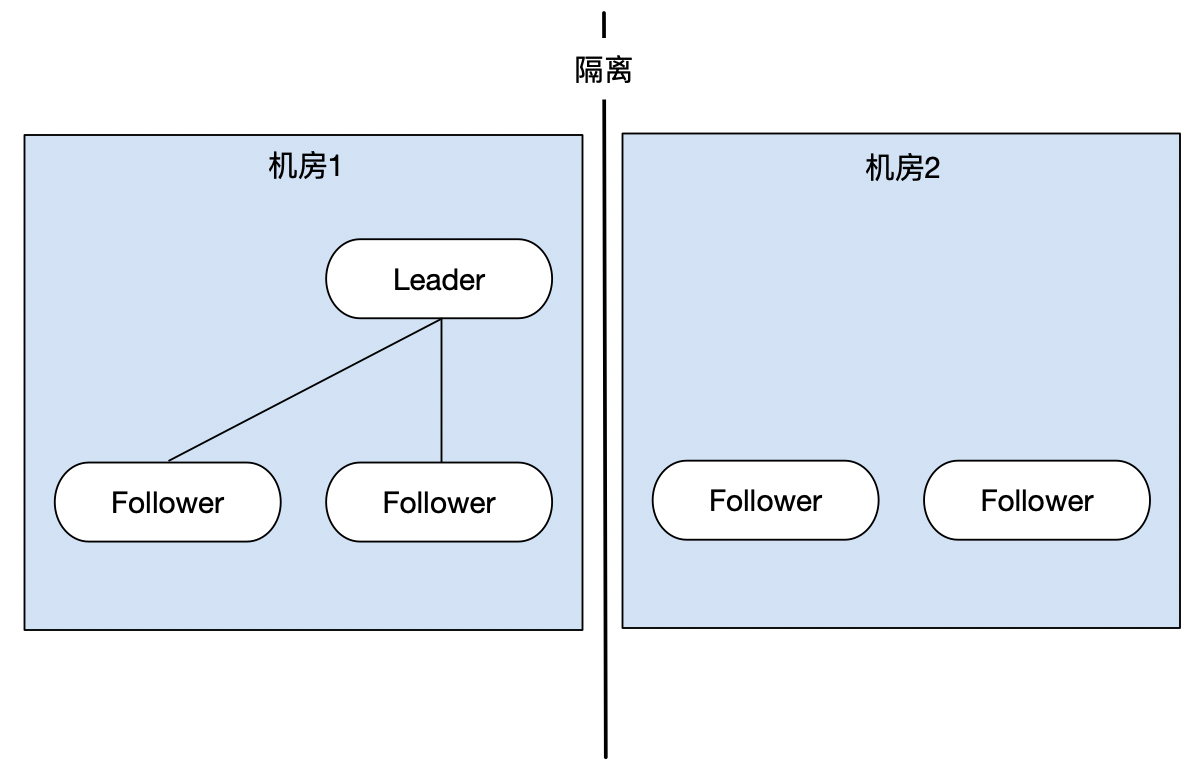
Zookeeper实际上是不会发生脑裂现象的,由于ZK内部有一个过半机制,也就是说集群至少要有超过一半的节点存活时才能够对外提供服务。
假设Zookeeper集群中存在5个节点(一个Leader,四个Follower),那么集群中至少要有3个节点存活时才能够对外提供服务,如果此时有2个Follower或者3个Follower无法与Leader进行通讯,由于存在过半机制,最终也只会保留一个ZK集群,另一个集群将会由于不满足过半机制而无法建立。
Zookeeper提供的过半机制就是用来解决集群脑裂问题的。
为什么搭建集群时一定要遵循2n+1个节点?
如果存在5个节点的集群,挂了2个,集群仍然能够运行。
如果存在6个节点的集群,挂了2个,集群仍然能够运行。
如果存在5个节点的集群,不管有多少个Follower节点与Leader节点的网络被隔离,集群都能够正常运行。
如果存在6个节点的集群,如果有3个Follower节点与Leader节点的网络被隔离,那么集群将不可用(极端情况)
3.Zookeeper的应用场景
3.1 使用Zookeeper作为配置中心
可以将一些重要的,可以动态配置的信息放在ZK当中,然后各个应用都监听这些节点,当配置更新时,将会通过通知机制去通知各个应用,然后再把节点的值更新到本地的静态变量当中。 1.自定义注解。 2.使用自定义的BeanPostProcesser,在Bean的初始化后调用指定的方法。 3.通过反射,获取Bean的类信息,判断类中的属性和方法是否有被自定义的注解所标注。 4.如果有则获取注解,然后根据注解中的Key属性监听节点,当节点的值发生改变时,设置Field或者调用Method,更新到本地的静态变量当中。 5.如果节点不存在则创建节点(触发通知)
3.2 使用Zookeeper作为注册中心
1.Provider和Consumer在启动时会连接ZK,建立一个有效的长连接。 2.Provicer会把服务注册到ZK当中,并且在/dubbo对应API下的Provider节点下创建临时节点。 3.Consumer会从ZK中获取服务列表,然后缓存到本地,并且在/dubbo对应API下的Consumer节点下创建临时节点。 4.当服务列表发生改变时,也就是新增或减少节点时,能够通过通知机制去通知Consumer,更新服务列表。 5.当ZK挂了,Consumer仍然可以访问Provider,走本地,只不过当服务列表发生改变时,无法再通过通知机制去通知Consumer,因此可能会访问一个已经下线的节点。
3.3 使用Zookeeper作为本地缓存的新增和更新策略(广播)
应用程序都是以集群的方式进行部署的,每个应用都有本地缓存,当信息新增和更新时需要更新本地缓存的值,此时可以利用ZK。
各个应用都监听ZK上的一个节点,当信息新增或更新时,更新节点的值,值为记录的id,那么各个应用都会收到通知,然后根据这个id从数据库中进行查询,更新本地缓存。
*如果应用挂了,当它重启后无法获取到在它挂了的这段时间内所有已经发生的通知(首次监听节点会触发一次节点数据发生改变的事件)
*如果ZK由于自身的原因没有进行通知,那么对于被通知者来说是没有感知的。
3.4 使用Zookeeper作为分布式锁
分布式锁有两种类型,分别是保持独占和控制时序。
保持独占,即当有多个线程同时申请获取锁时,只有一个线程能够获取成功,其他线程直接返回(通过Redis中的一个Key或者Zookeeper中的一个节点进行控制)
控制时序,即所有申请获取锁的线程最终都能够获取到锁然后执行指定的逻辑(利用Zookeeper的通知机制)
Zookeeper可以实现保持独占和控制时序两种类型的分布式锁
保持独占(通过Zookeeper中的一个临时节点)
1.当线程要获取锁时,创建一个临时节点,如果创建失败,则表示锁已经被其他线程所持有。
2.如果创建成功则表示获取了锁,然后进行业务处理,当处理完毕后释放锁,删除该节点。
控制时序(利用通知机制)
首先创建一个locker持久化节点。 1.当线程要获取锁时,需要在locker持久化节点下创建顺序编号的临时节点。 2.然后获取locker节点下的所有子节点,判断刚创建的临时节点的编号在locker的子节点中是否是最小的。 3.如果是最小的,则表示获取锁成功,那么进行业务处理,当处理完毕后删除该节点。 4.如果不是最小的,则找到它的前一个节点,然后对它进行监听,建立Watch。 5.当节点被删除时将会通知正在监听它的节点,此时其他线程就获取到锁。
*可以直接使用Curator提供的acquire()和release()方法来使用ZK的分布式锁。
使用Redis作为分布式锁与使用ZK作为分布式锁有什么区别?
1.Redis只能实现保持独占的分布式锁,而Zookeeper可以实现保持独占和控制时序两种类型的分布式锁。
2.从性能上来说,Redis的加锁、解锁的效率以及抗并发的能力都要比Zookeeper的高。
3.从实现上来说,Redis要做很多特殊的处理,比如如何保证获取锁的同步性、当应用宕机时如何保证锁能够被释放、如何保证释放的锁是自己的,ZK没有这些问题(当应用宕机时临时节点将会被删除)
4.搭建Zookeeper
1.安装
由于Zookeeper是由java语言编写的,因此在安装Zookeeper之前需要安装好JDK,并且配置环境变量JAVA_HOME


从Zookeeper官网下载zk并进行解压

bin目录

zkEnv.sh:用于配置zk服务启动时的环境变量 (包括加载配置文件的路径等)
zkServer.sh:用于启动zk服务,默认监听2181端口。
zkCli.sh:用于启动zk客户端。
zookeeper.out:用于存放zk运行时的日志。
conf目录

log4j.properties文件:日志配置文件,默认日志信息都将打印到bin目录下的zookeeper.out文件 (当使用Zookeeper遇到异常时应该查看此文件下的内容)
zoo_sample.conf文件:zk server的配置文件,zk服务启动时默认会加载conf目录下的zoo.cfg配置文件
2.修改配置文件
Zookeeper启动时会默认加载conf目录下的zoo.cfg配置文件,因此将conf目录下的zoo_sample.conf配置文件更名为zoo.cfg。
#initLimit、syncLimit的单位,值是毫秒 tickTime=2000 #集群搭建前所允许的初始化时间 initLimit=10 #Leader发送心跳给Follower,Follower向Leader回复心跳这一过程所允许的最大时长 (rtt,往返时间),一旦超过了这个时间,Leader则认为该Follower宕机。 syncLimit=5 #快照日志的存放目录 dataDir=/usr/Zookeeper/Zookeeper-3.4.6/zkdata #事务日志的存放目录 dataLogDir=/usr/Zookeeper/Zookeeper-3.4.6/zklog #zookeeper服务的监听端口,默认为2181 clientPort=2181
当其中一台zk节点启动后,剩余的zk节点必须在initLimit规定的时间内全都启动,否则zk在进行集群的搭建时会认为未启动的zk节点已经失效。
如果不配置dataLogDir,那么事务日志将写入到dataDir目录下 (会严重影响zk的性能)
3.启动Zookeeper
使用zkServer.sh命令启动Zookeeper服务。
zkServer.sh start
使用jps命令查询zk进程是否启动成功,当出现QuorumPeerMain表示zk启动成功。

4.Zookeeper的基本命令
#连接zk server,默认本机,使用-server选项指定远程zk服务 zkcli.sh -server 192.168.1.80:2181 #创建ZNode,默认为持久化节点,使用-e选项表示临时节点,使用-s选项表示顺序编号 create -e -s path data #查看ZNode下的子ZNode ls path #获取ZNode保存的数据 get path #设置ZNode保存的数据 set path data #删除ZNode(不能递归删除) delete path #退出客户端 quit
5.搭建Zookeeper集群
1.修改配置文件
在conf文件中添加集群的配置,使用server.num配置集群信息(num必须为整数)
#基础配置 tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/Zookeeper/Zookeeper-3.4.6/zkdata dataLogDir=/usr/Zookeeper/Zookeeper-3.4.6/zklog clientPort=2181 #集群配置 server.1=192.168.1.119:2888:3888 server.2=192.168.1.122:2888:3888 server.3=192.168.1.125:2888:3888
server.本机节点标识 = host:leader和follower之间的通讯端口:leader的选举端口
server.其他节点标识 = host:leader和follower之间的通讯端口:leader的选举端口
在同一个集群中,节点的标识不能够重复。
Leader和Follower之间的通讯端口默认为2888,Leader的选举端口默认为3888。
2.创建myid文件
在快照日志目录下创建myid文件,文件中的值是本机zk节点的唯一标识(必须为整数)
#将1输入到myid文件中
echo "1" > myid
每个节点都需要这么配置。
3.启动各个Zookeeper节点
zkServer.sh start
必须要在 initLimit * tickTime 的时间内启动集群中的所有节点,否则集群有可能搭建失败。
4.查询集群中各个节点的状态
zkServer.sh status


5.注意事项
1.搭建Zookeeper集群时需要遵循2n+1个节点,因为Zookeeper内部有过半机制,当集群中超过一半的节点存活时,那么Zookeeper就能够对外提供服务。
2.搭建Zookeeper集群时需要关闭防火墙或者开放对应的端口,否则集群中节点之间无法进行通讯。
3.Zookeeper集群在高负荷的工作时会产生大量的事务日志,如果日志长期不进行清理容易将分区中的空间占满导致服务无法运行,因此需要定期清理zk产生的事务日志(可以借助Linux的crontab命令定期删除ZK产生的事务日志)
6.Zookeeper可视化工具
ZK UI是一个Zookeeper的可视化平台
1.下载源码(Maven项目),直接导入idea,然后使用mvn install进行打包,最终得到一个jar包。
https://github.com/DeemOpen/zkui
2.修改config.cfg配置文件
#zuui端口 serverPort=9090 #zk服务地址,多个使用逗号分隔 zkServer=localhost:2181
3.启动jar包
java -jar zkui-2.0-SNAPSHOT-jar-with-dependencies.jar
4.访问ZK UI,http://localhost:9090,用户名/密码默认为 admin/manager
7.JAVA中操作Zookeeper
可以使用apache提供的zookeeper客户端或者curator framework来操作ZK。
1.导入Maven依赖
<dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.13</version> <type>pom</type> </dependency>
2.建立连接
ZooKeeper(StringconnectString, intsessionTimeout, Watcherwatcher) throwsIOException
connectString:ZK服务地址,多个使用逗号分隔。
sessionTimeout:连接Zookeeper的超时时间。
watcher:事件回调接口。
*ZooKeeper实例是通过异步的方式来建立连接的,当连接建立后会调用Watcher的process方法,因此程序为了保证同步建立连接,可以使用CountDownLatch进行控制。
3.调用Zookeeper提供的API
//创建ZNode,指定节点的路径、数据、ZNode类型 publicStringcreate(finalStringpath, bytedata[], List<ACL>acl,CreateModecreateMode) //获取ZNode下的子ZNode publicList<String>getChildren(finalStringpath, booleanwatch) //判断ZNode是否存在 publicStatexists(Stringpath, booleanwatch) //获取ZNode保存的数据 publicbyte[] getData(Stringpath, booleanwatch, Statstat) //设置ZNode的数据 publicStatsetData(finalStringpath, bytedata[], intversion) //删除ZNode publicvoiddelete(finalStringpath, intversion)
节点类型
CreateMode.PERSISTENT:持久化节点
CreateMode.PERSISTENT_SEQUENTIAL:持久化节点并顺序编号
CreateMode.EPHEMERAL:临时节点
CreateMode.EPHEMERAL_SEQUENTIAL:临时节点并顺序编号
*当进行更新和删除操作时,需要传递数据的版本号,其内部会进行CAS判断,当且仅当传递的版本号与当前节点的版本号相同时,才进行操作。
*Apache Zookeeper API中有很多方法都支持Watcher参数,Watcher用于监听节点的状态,当节点的状态发生改变时将会调用Watcher的process方法进行处理。
完整示例
/** * @Auther: ZHUANGHAOTANG * @Date: 2018/11/12 14:55 * @Description: */ publicclassZKUtils{ /** * 日志输出 */ privatestaticLoggerlogger=LoggerFactory.getLogger(ZKUtils.class); /** * ZK服务列表 */ privatestaticfinalStringURLS="192.168.1.80:2181,192.168.1.81:2181,192.168.1.83:2181"; /** * 连接Zookeeper的超时时长(单位:毫秒) */ privatestaticfinalintSESSION_TIMEOUT=3000; /** * Zookeeper连接对象 */ privatestaticZooKeeperzk=null; static{ try{ CountDownLatchcountDownLatch=newCountDownLatch(1); zk=newZooKeeper(URLS, SESSION_TIMEOUT, newWatcher() { @Override publicvoidprocess(WatchedEventevent) { if(Event.KeeperState.SyncConnected==event.getState()) { countDownLatch.countDown();//倒数器-1 } } }); countDownLatch.await(); } catch(Exceptione) { logger.info("Zookeeper获取连接失败,{}", e); } } /** * 创建节点 * * @param path * @param data * @param createMode * @throws Exception */ publicstaticvoidcreatePath(Stringpath, Stringdata, CreateModecreateMode) throwsException{ if(StringUtils.isBlank(path)) { thrownewException("path is null"); } if(!exists(path)) { zk.create(path, data.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, createMode); } } /** * 获取子节点 * * @param path * @return * @throws Exception */ publicstaticList<String>getSubNode(Stringpath) throwsException{ if(StringUtils.isBlank(path)) { thrownewException("path is null"); } returnzk.getChildren(path, false); } /** * 判断节点是否存在 * * @param path * @return * @throws Exception */ publicstaticbooleanexists(Stringpath) throwsException{ if(StringUtils.isBlank(path)) { thrownewException("path is null"); } if(zk.exists(path, false) !=null) { returntrue; } returnfalse; } /** * 获取节点中的数据 * * @param path * @return * @throws Exception */ publicstaticStringgetData(Stringpath) throwsException{ if(StringUtils.isBlank(path)) { thrownewException("path is null"); } returnnewString(zk.getData(path, false, null)); } /** * 更新节点中的数据 * * @param path * @param data * @throws Exception */ publicstaticvoidsetData(Stringpath, Stringdata) throwsException{ if(StringUtils.isBlank(path)) { thrownewException("path is null"); } zk.setData(path, data.getBytes(), -1); } /** * 删除节点 * * @param path * @throws Exception */ publicstaticvoiddeletePath(Stringpath) throwsException{ if(StringUtils.isBlank(path)) { thrownewException("path is null"); } zk.delete(path, -1); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号