

std::string的find挺慢的
搞了个比较极端的测试: 64KB长的字符串里找不到:
#include <stdio.h> #include <time.h> // MinGW does not build against glibc, it builds against msvcrt. As such, it uses libmsvcrtXX.a instead. // gcc and glibc are two separate products. So still no memmem(). #define _GNU_SOURCE #include <string.h> #include <string> using namespace std; int main() { enum { N = 1 << 16 }; char* p = new char[N + 1]; for (int i = 0; i < N; i++) p[i] = (i & 15) + 'a'; p[N] = 0; string s = p; enum { M = 1 << 20 }; int n = 0; #if 0 const char NEEDLE[] = "abcde"; #else const char NEEDLE[] = "0123456789"; #endif time_t start = time(0); for (int i = 0; i < M; i++) #if 0 //n += (int)memmem(p, N, NEEDLE, 10); n += (int)strstr(p, NEEDLE); #else n += s.find(NEEDLE); #endif printf("%d\n", n); printf("%d\n", time(0) - start); }
tdm-gcc-10.3.0.exe (mingw32), -O3, 比strstr慢太多了。
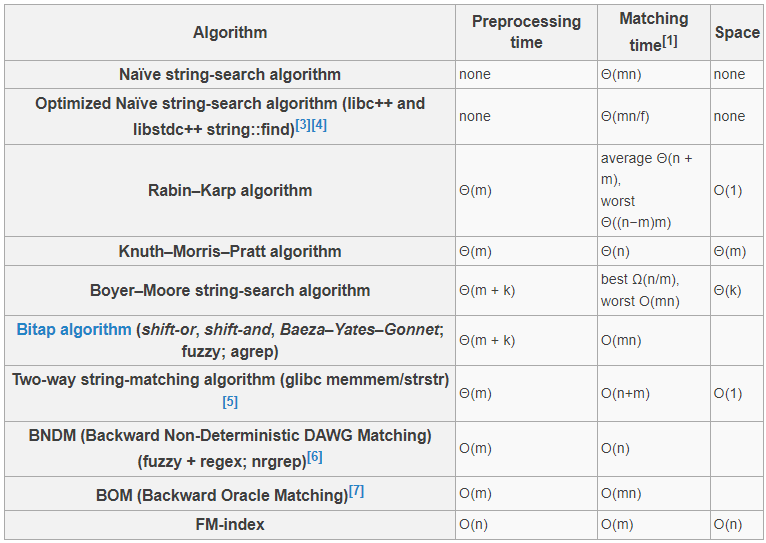
Big O describes the upper bound of an algorithm. Big Omega describes the lower bound of an algorithm. Big Theta describes the tight bound of an algorithm. What’s the Difference Between Big O, Big Omega, and Big Theta? | jarednielsen.com
草堆里找针。n是草堆的长度,m是针的长度,k是字母表里字符的个数。自动机如果每个状态都有个State* next[256],太占地方了,完整的UNICODE 32位,16位不能表示所有字符。好像是把state + char和起来做key. f is a constant introduced by SIMD (单指令多数据) operations. C++又走上邪路了。:-) 我的意思是:要么别优化,因为不常用;要么换算法。还是检查m*n个字符,只是每次利用SIMD指令检查多个,不能说不好,但不够标准库的水准啊。
python有个ply包,里面的lex是完全python写的,不是去调用C的lex,但用了数次re.compile,核心代码几百行的样子:
self.lexre = None # Master regular expression. This is a list of # tuples (re, findex) where re is a compiled # regular expression and findex is a list # mapping regex group numbers to rules self.lexretext = None # Current regular expression strings self.lexstatere = {} # Dictionary mapping lexer states to master regexs self.lexstateretext = {} # Dictionary mapping lexer states to regex strings self.lexstaterenames = {} # Dictionary mapping lexer states to symbol names self.lexstate = 'INITIAL' # Current lexer state self.lexstatestack = [] # Stack of lexer states self.lexstateinfo = None # State information self.lexstateignore = {} # Dictionary of ignored characters for each state self.lexstateerrorf = {} # Dictionary of error functions for each state self.lexstateeoff = {} # Dictionary of eof functions for each state self.lexreflags = 0 # Optional re compile flags self.lexdata = None # Actual input data (as a string) self.lexpos = 0 # Current position in input text self.lexlen = 0 # Length of the input text self.lexerrorf = None # Error rule (if any) self.lexeoff = None # EOF rule (if any) self.lextokens = None # List of valid tokens self.lexignore = '' # Ignored characters self.lexliterals = '' # Literal characters that can be passed through self.lexmodule = None # Module self.lineno = 1 # Current line number self.lexoptimize = False # Optimized mode

 浙公网安备 33010602011771号
浙公网安备 33010602011771号