datax开启hana支持以及dolphinscheduler开启datax任务
datax开启hana支持以及dolphinscheduler开启datax任务
前面(@,@)
前段时间因为要做异构数据导入导出,所以搜了下,发现这类工具收费的居多,使用起来未必趁手~
于是我找了下相关开源工具,目前,对于非开源的,我找到的大概有三种方式:
- 1.
springboot+mybatis写代码做导入导出->固定表可以这样做,换张表结构不一样又要重新开发 - 2.使用
kattle...一开始同事用的这款工具,不过它太重了,启动卡半天、操作个字段也卡半天,换个表还要重新建任务,屎一样的操作体验... - 3.使用
datax,需要配置环境(java、python) ,以及写任务文件(json) 似乎也不是很高效快捷,真难为我了
直到最近我发现了一款工具可以配合着dolphinscheduler使用,那体验简直了..:爽歪歪😎,这次我就讲讲如何操作~
一.准备
- 1.
java环境(默认您已经安装) - 2.
python环境(默认您已经安装),我这边使用linux自带的2.7版本 - 3.
dolphinschedule(默认您已经安装) - 4.下载并解压
datax安装版(我使用的是2022年3月份左右的版本)https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/20220530/datax.tar.gz - 5.测试表及数据:
-- postgresql(pg)
CREATE TABLE TMPP (
ID int8 primary key,
NUM int4,
NAME VARCHAR(20) ,
EXT1 date ,
EXT2 timestamp ,
EXT3 timestamp ,
EXT4 DECIMAL(20, 4) ,
EXT5 text ,
EXT6 CHAR(1) ,
EXT7 float4
);
INSERT INTO TMPP (ID,NUM,NAME,EXT1,EXT2,EXT3,EXT4,EXT5,EXT6,EXT7) VALUES (-3,33,'这是名称',NULL,NULL,NULL,830.9123,NULL,NULL,NULL);
INSERT INTO TMPP (ID,NUM,NAME,EXT1,EXT2,EXT3,EXT4,EXT5,EXT6,EXT7) VALUES (-2,22,'n_22','2021-10-28','2021-10-27 11:46:25.000','2021-10-29 11:46:33.000',999.1230,'hello youth!','2',19.8799991607666);
INSERT INTO TMPP (ID,NUM,NAME,EXT1,EXT2,EXT3,EXT4,EXT5,EXT6,EXT7) VALUES (-1,11,'n_11',NULL,NULL,NULL,NULL,NULL,NULL,NULL);
INSERT INTO TMPP (ID,NUM,NAME,EXT1,EXT2,EXT3,EXT4,EXT5,EXT6,EXT7) VALUES (0,1000,'NAME_1000',NULL,'2021-10-28 16:23:30.000',NULL,NULL,NULL,NULL,NULL);
INSERT INTO TMPP (ID,NUM,NAME,EXT1,EXT2,EXT3,EXT4,EXT5,EXT6,EXT7) VALUES (1,1001,'NAME_1001','2021-10-28',NULL,'2021-10-28 16:22:41.000',177.3330,'你好啊~','0',NULL);
INSERT INTO TMPP (ID,NUM,NAME,EXT1,EXT2,EXT3,EXT4,EXT5,EXT6,EXT7) VALUES (-99,99,'hello hana','2021-11-02','2021-11-02 14:56:45.758','2021-11-02 14:56:45.758',99.9900,'HELLO TEXT','9',22.329999923706055);
-- hana(sap db)
CREATE ROW TABLE "TMPP" ( "ID" INT CS_INT NOT NULL, "NUM" INT CS_INT, "NAME" NVARCHAR(20) CS_STRING, "EXT1" DAYDATE CS_DAYDATE, "EXT2" LONGDATE CS_LONGDATE, "EXT3" LONGDATE CS_LONGDATE, "EXT4" DECIMAL(20, 4) CS_FIXED, "EXT5" CLOB MEMORY THRESHOLD 1000 , "EXT6" CHAR(1) CS_FIXEDSTRING, "EXT7" DOUBLE CS_DOUBLE );
INSERT INTO TMPP (ID,NUM,NAME,EXT1,EXT2,EXT3,EXT4,EXT5,EXT6,EXT7) VALUES (-3,33,'这是名称',NULL,NULL,NULL,830.9123,NULL,NULL,NULL);
INSERT INTO TMPP (ID,NUM,NAME,EXT1,EXT2,EXT3,EXT4,EXT5,EXT6,EXT7) VALUES (-2,22,'n_22','2021-10-28','2021-10-27 11:46:25.000','2021-10-29 11:46:33.000',999.1230,NULL,'2',19.8799991607666);
INSERT INTO TMPP (ID,NUM,NAME,EXT1,EXT2,EXT3,EXT4,EXT5,EXT6,EXT7) VALUES (-1,11,'n_11',NULL,NULL,NULL,NULL,NULL,NULL,NULL);
INSERT INTO TMPP (ID,NUM,NAME,EXT1,EXT2,EXT3,EXT4,EXT5,EXT6,EXT7) VALUES (0,1000,'NAME_1000',NULL,'2021-10-28 16:23:30.000',NULL,NULL,NULL,NULL,NULL);
INSERT INTO TMPP (ID,NUM,NAME,EXT1,EXT2,EXT3,EXT4,EXT5,EXT6,EXT7) VALUES (1,1001,'NAME_1001','2021-10-28',NULL,'2021-10-28 16:22:41.000',177.3330,NULL,'0',NULL);
INSERT INTO TMPP (ID,NUM,NAME,EXT1,EXT2,EXT3,EXT4,EXT5,EXT6,EXT7) VALUES (-99,99,'hello postgres','2021-11-02','2021-11-02 14:56:45.758','2021-11-02 14:56:45.758',99.9900,NULL,'9',22.329999923706055);
二.datax(通用rdbms方式)开启hana支持
首先,要说明的是一般datax支持hana有两种方式:
- 1.二次开发,写
hana专属的writer以及reader插件->配置jdbc->编译上线 - 2.直接使用
datax提供的rdbmswriter以及rdbmsreader插件->添加jdbc->配置对应的plugin.json中的driver路径即可
这里我使用的是第二种方式,当然下面也会讲到这中间碰到的坑哈🤣
2.1 datax的基本结构
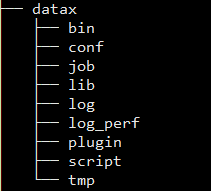
上图为datax解压后的主目录.
bin:启动脚本,主要是python脚本,启动一个任务实例时会用到conf: 一些基本的配置文件,很少用到job: 任务配置文件(json格式),这个目录是可选的,一般手写任务配置文件会放到这个目录lib: 通用及基本的jar包依赖log: 任务日志目录,这个目录也是可选的,一般是启动任务时指定log_perf: 也是任务执行统计日志文件,一般是空的plugin: 里面包含具体的writer以及reader插件及插件配置script: 脚本目录,这也是可选的,一般脚本文件是统一采用git等版本管理tmp: 临时目录,个人建的哈😁😁
2.2 添加jdbc驱动文件(jar)
一般这个jdbc需要到包管理网站或者对应数据库厂商官网下载,这里下hana的driver:https://mvnrepository.com/artifact/com.sap.cloud.db.jdbc/ngdbc
这里的主要操作是将下载好的jar包放到lib目录内,这里需要特别说明的是:网上有博客写的是放入的plugin目录,可能我的版本较新或者和他们的集成方式不同吧,对我来说这个jar放入到plugin目录肯定是不行的!!!
以下是我的lib目录:
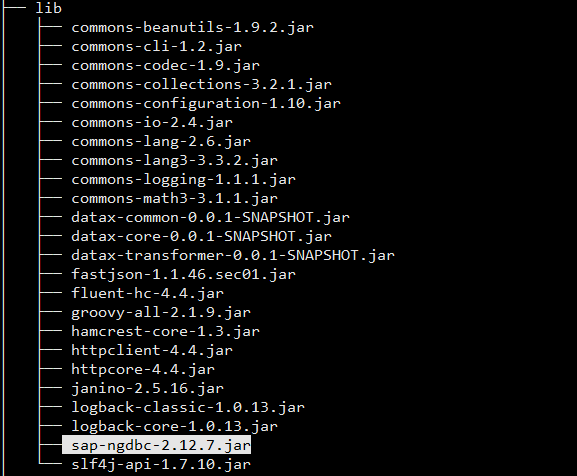
2.3 给通用rdbms添加hana支持
这个操作在plugin目录下,对应其中的plugin/writer/rdbmswriter 以及 plugin/reader/rdbmsreader目录下的plugin.json文件 ,修改drivers这一项,这个一定不能错!!!
下图为我添加的 hana driver :


到这里,datax的hana配置已经ok了,下面是dolphinscheduler内的datax相关配置~
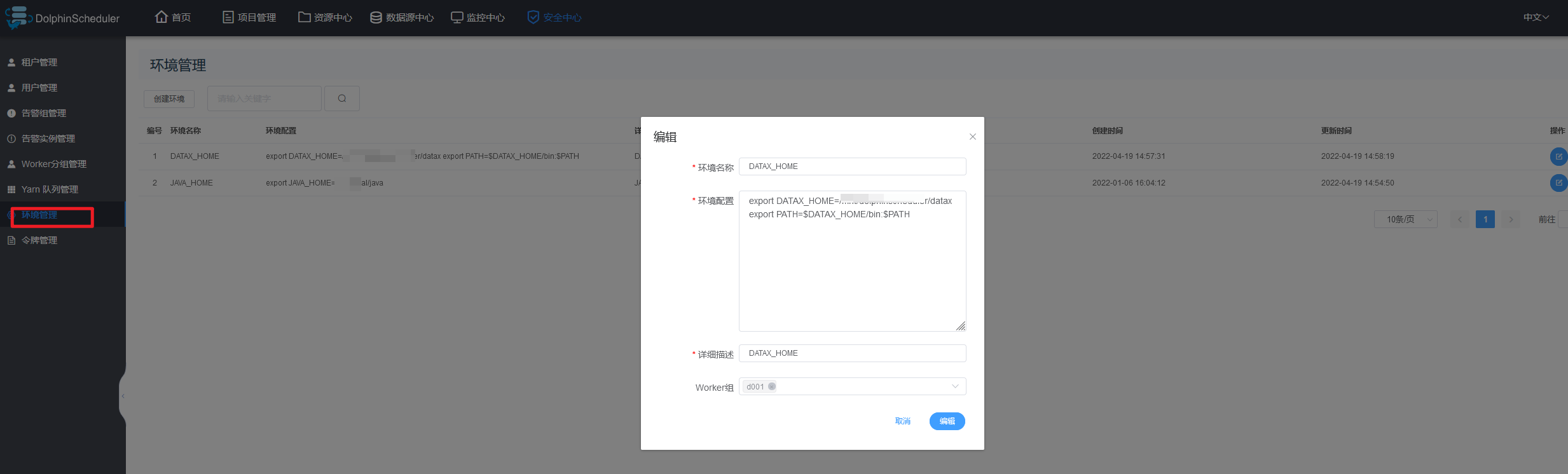
三.dolphinscheduler中配置datax环境变量
其实这一步很简单,主要是在dolphinscheduler的->安全中心->环境管理 菜单下配置datax的位置,这步操作一定要在管理员账号 (admin)下操作,一般普通用户是没有权限的,这个很重要!!!
如果您是多机集群部署,建议将datax放在相同的目录位置,不然统一的环境变量找不到,同时JAVA_HOME这个环境变量也建议配置下,不然会有些莫名其妙的问题发生就不好了😂😂
以下是我的配置:
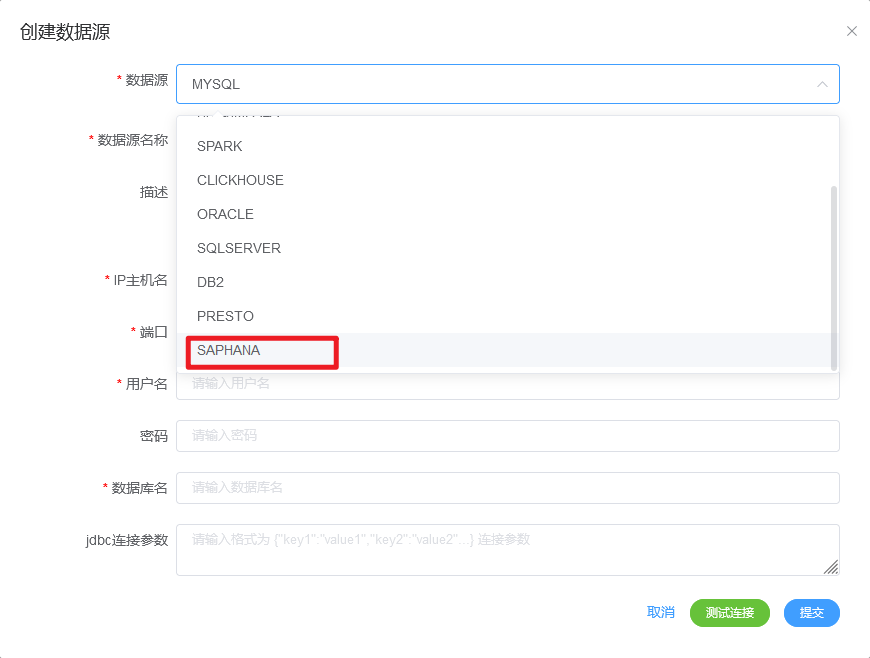
oh,我忘记了,dolphinscheduler默认是没有hana的数据源支持的,需要的可以找我哦(后面会有博客聊到的,关注哟~)😎
四.小测一下😂
我的测试的是postgresql内的数据抽取到hana 以及 hana的数据抽取到postgresql 两个任务,由于dolphinscheduler的基本使用上一篇博客已经讲过了(具体看这个:https://www.cnblogs.com/funnyzpc/p/16395094.html ),这里我只给出具体的任务节点配置哈🤗
(dolphinscheduler任务具体配置,表sql脚本上文有)
- postgresql to hana
![]()
- hana to postgresql
![]()
- 执行结果:
![]()

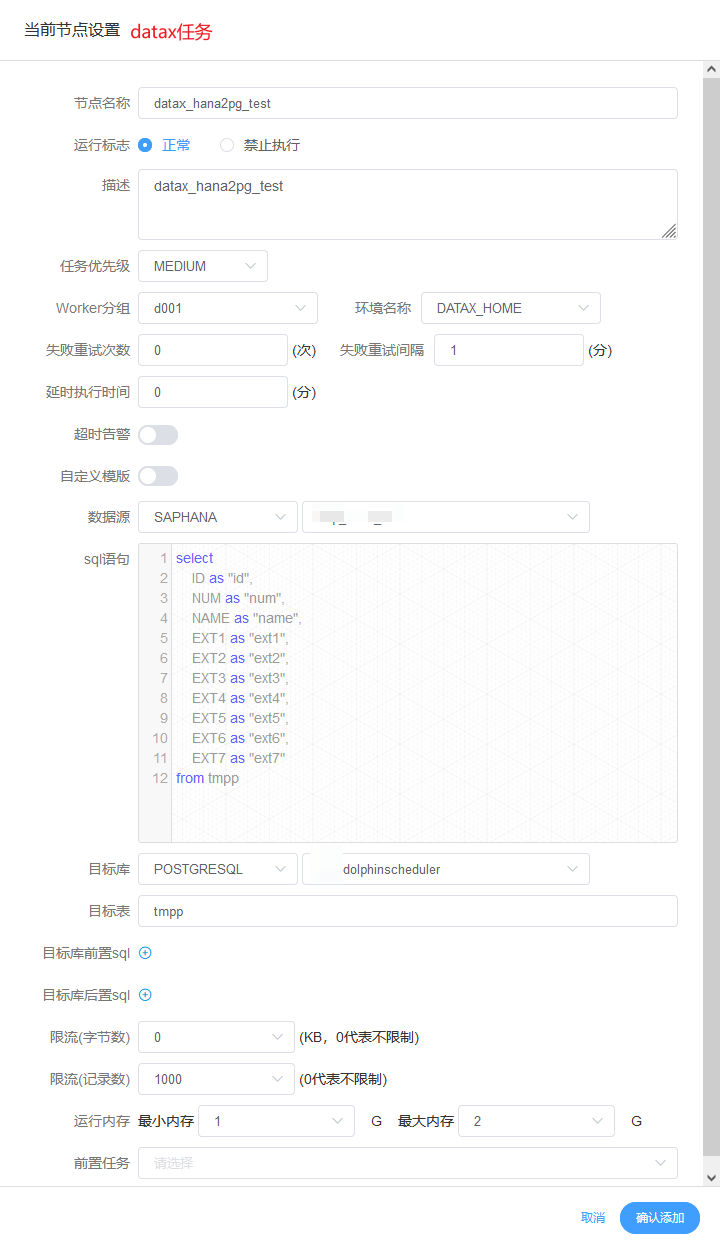

还有几个小的注意事项是:
dolphinscheduler的datax任务下查询sql需要将字段显式的写出,不可以用*号代替- 查询的字段要注意不同的数据库下会有大小写区分,比如否用 ` 以及 " 装饰字段别名
dolphinscheduler下配置datax任务时环境名称(配置的datax环境变量) 这一项为必选,不然任务抛错我不负责哟😛

 浙公网安备 33010602011771号
浙公网安备 33010602011771号