day22-热点资讯抓取存储
RSS简介
什么是 RSS?
你可以把 RSS 想象成“网站的广播频道”。
很多网站——比如新闻站(如 BBC)、博客(如知乎专栏)、播客、甚至 YouTube 频道——都会提供一个叫 RSS 订阅链接 的东西。
这个链接就像一个“实时更新通知器”:只要网站发布了新内容,RSS 就会自动生成一条包含标题、摘要、发布时间和原文链接的信息。
✅ 举个生活化的例子:
你关注了 5 个科技博主,以前你要每天挨个打开他们的主页看有没有更新;
现在,你只要把他们的 RSS 链接“订阅”到一个阅读器里,所有新文章就会自动汇总到一个地方,像收邮件一样方便!
在 n8n 中,RSS 插件是干什么的?
n8n 的 RSS 节点,就是一个“自动监听器”。
小贴士:不是所有网站都直接显示 RSS 链接,但很多博客、新闻站、YouTube 频道都支持。
RSSHub Radar简介
RSSHub Radar 是 RSSHub 的衍生项目,是一款浏览器扩展,简化了查找并订阅RSS和RSSHub的过程。
- 轻松发现并订阅当前页面关联的RSS源。
- 快速探索并订阅当前页面支持的RSSHub服务。
- 快速识别网站支持的RSSHub服务。
Chrome 安装扩展
打开 chrome://extensions/ 开启右上角的「开发者模式」 左上角点击「加载已解压的扩展程序」 选择解压缩后的 dist 目录
社区节点
在 n8n 中,“社区节点”(Community Nodes) 是指由 n8n 官方以外的开发者或用户创建并共享的自定义节点,用于扩展 n8n 原生不支持的功能或服务。
社区节点不是 n8n 默认安装的,但你可以手动安装它们,让你的工作流支持更多国内或小众服务。
社区节点的特点:
| 特点 | 说明 |
|---|---|
| 来源 | GitHub 上由个人或组织开发,非 n8n 官方维护 |
| 用途 | 支持官方未覆盖的服务(如:飞书、钉钉、微信、百度智能云、用友ERP等) |
| 安装方式 | 通过 npm 命令安装到 n8n 实例中(需有服务器/容器访问权限) |
| 风险提示 | 质量和安全性取决于作者,建议选择 Star 多、更新频繁、文档清晰的项目 |
如何查找社区节点?
- 官方社区节点列表(部分):https://n8n.io/integrations/
- GitHub 搜索关键词:
n8n community node 飞书、n8n custom node dingtalk - 中文社区推荐:Gitee 上搜索
n8n-node-xxx
多平台热点自动抓取
一、添加一个定时节点
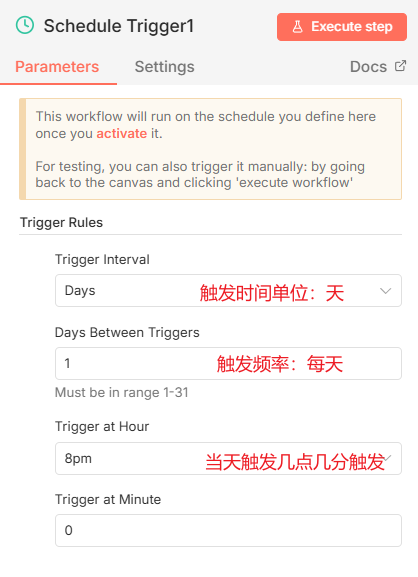
我们需要使用的触发节点是,定时触发节点,点添加节点,搜索schedule,然后找到这个节点添加,这个节点主要作用是可以进行定时执行,我们现在是测试,可以随便选个时间。
设置触发时间:
二、添加Rss节点
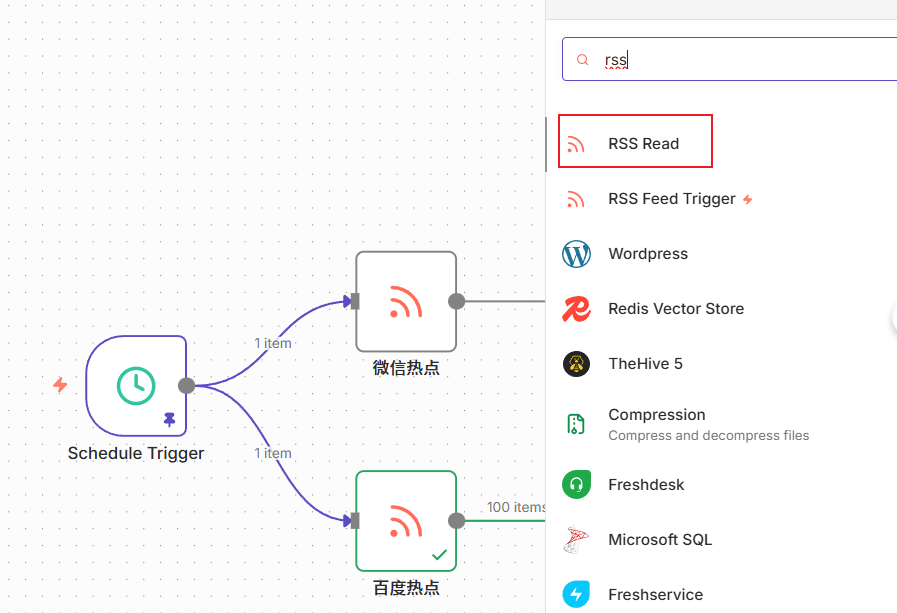
接下来,我们添加Rss节点,这个节点可以直接订阅支持Rss的网站。
一个开源的rss地址库:https://github.com/weekend-project-space/top-rss-list
因为是演示,我这里就先添加两个节点
节点配置:
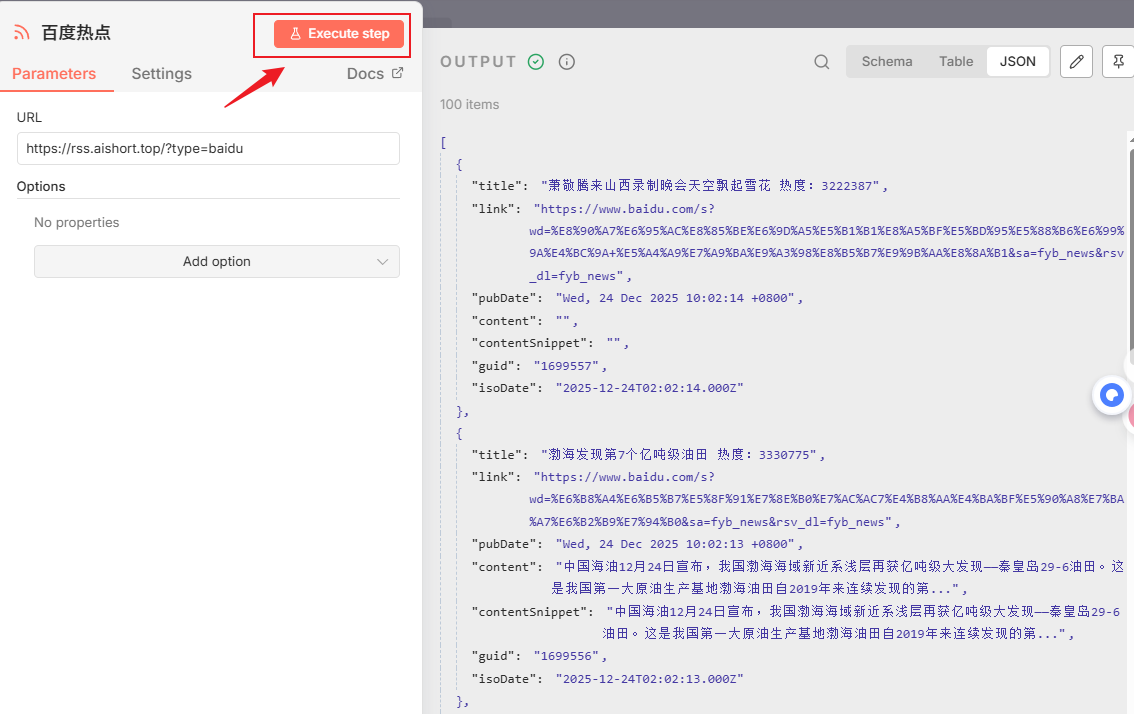
点击节点设置一下订阅地址,一个节点订阅的是百度热点,另一个节点订阅的是微信最新的文章。
地址分别是:
https://rss.aishort.top/?type=baidu
https://rss.aishort.top/?type=wasi
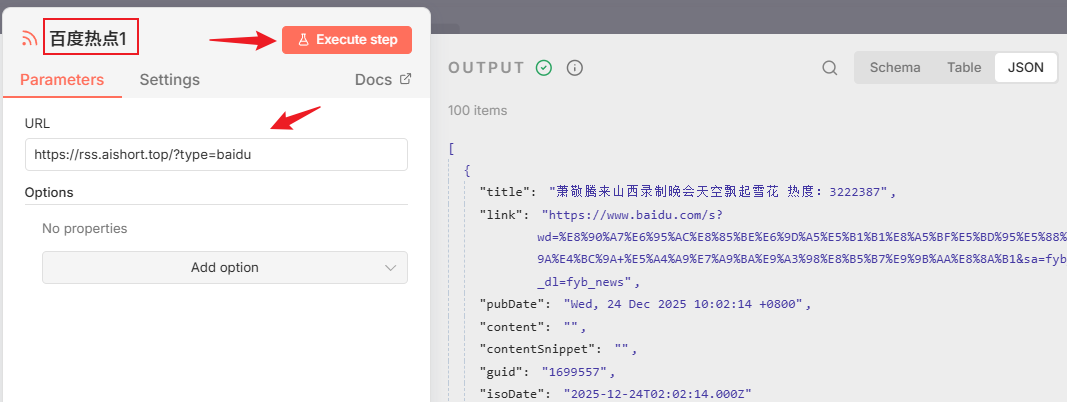
添加好之后执行一下测试,看到获取成功,一个获得了100个items数据,另外一个获得了10个items数据:
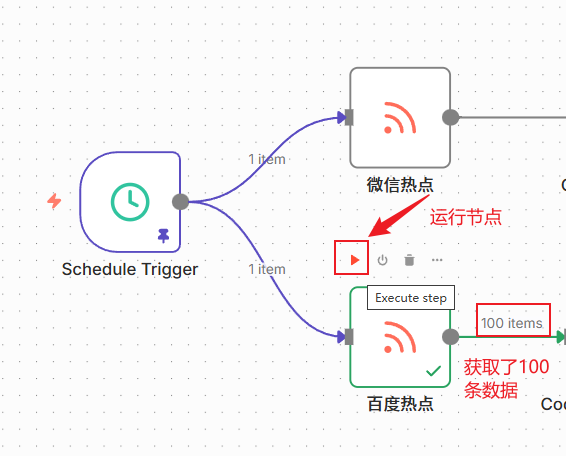
三、数据预处理
为什么要做个数据的预处理?有的时候获取的数据,可能格式不是我们要的,或者没有我们需要的数据。比如,这现在这两个节点最终返回的内容数据结构都是这样的,如果到时候全部存到文件表格中,就会发现我们不知道这篇内容的来源是哪里的,如果节点多了就更难区分了。
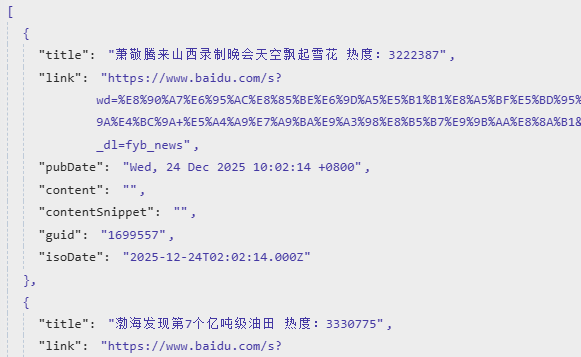
所以,现在我添加两个Code代码节点,对数据进行处理,在数据中添加内容的来源属性Source字段,从而来标记内容的来源是百度还是微信。
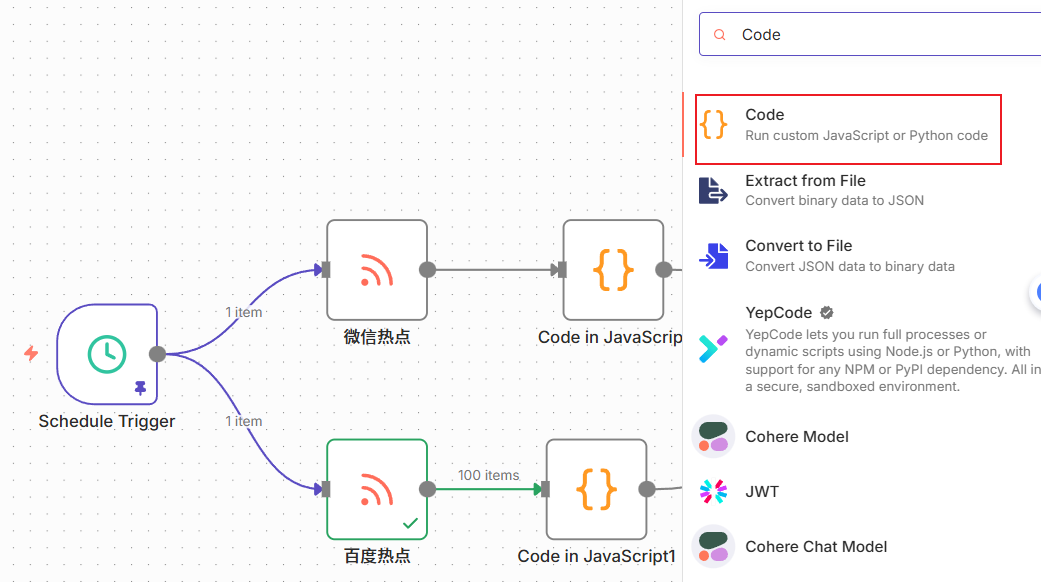
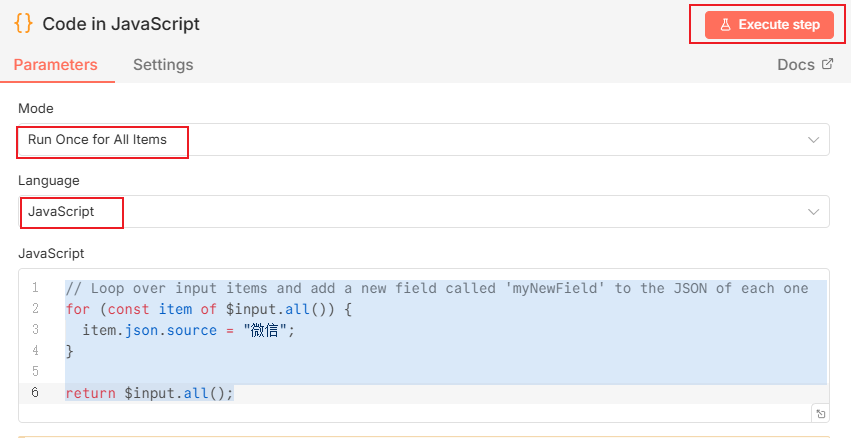
进入code里面,按照如下配置,添加一个来源的属性,这个代码的意思就是给所有返回的内容加一个Source字段来标记内容的来源
代码可以是js也可以是python,代码可以使用大模型生成,提示词如下:
 图一
图一
 图二
图二
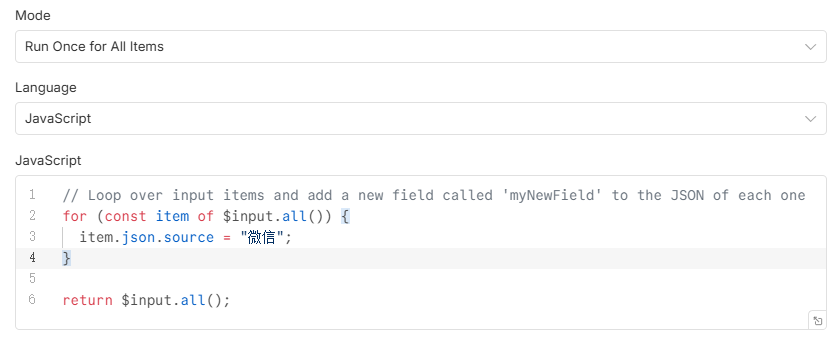
生成code代码提示词:图1是需要被处理的数据对应的结构样式,图2是n8n的code节点。现在需要你基于code节点创建js代码,给图1的列表中每一个字典添加一个Source字段来标记内容的来源,比如内容来源设置为百度或者微信等
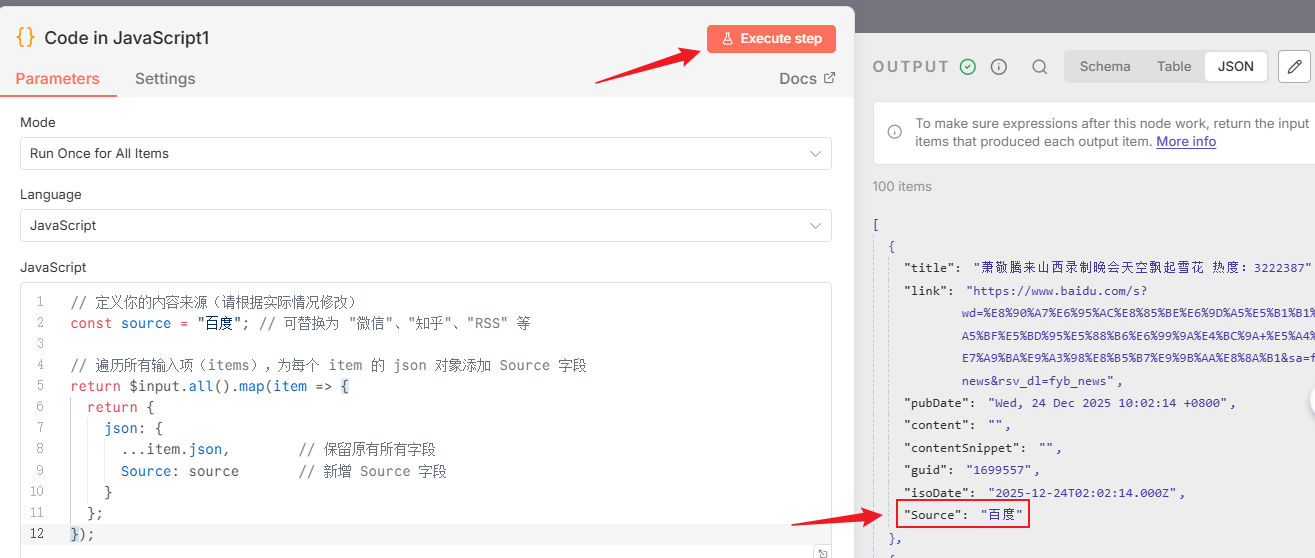
我们执行一下Code节点,就可以看到,现在的数据多了一个来源的标注,到时候我们给每个不同的订阅分支设置不同来源,就很好区分了:
代码如下:
for (const item of $input.all()) {
item.json.source = "微信";
}
return $input.all();
//或者下面的也可以,上下两组代码二选一
const source = "百度";
return $input.all().map(item => {
return {
json: {
...item.json,
Source: source
}
};
});
四、合并数据
接下来我们需要把多个rss地址获取的数据合并成一个,方便后续统一存储。这个时候我们需要用到这个节点,搜索merge,添加这个节点,然后把不同分支都连进来。
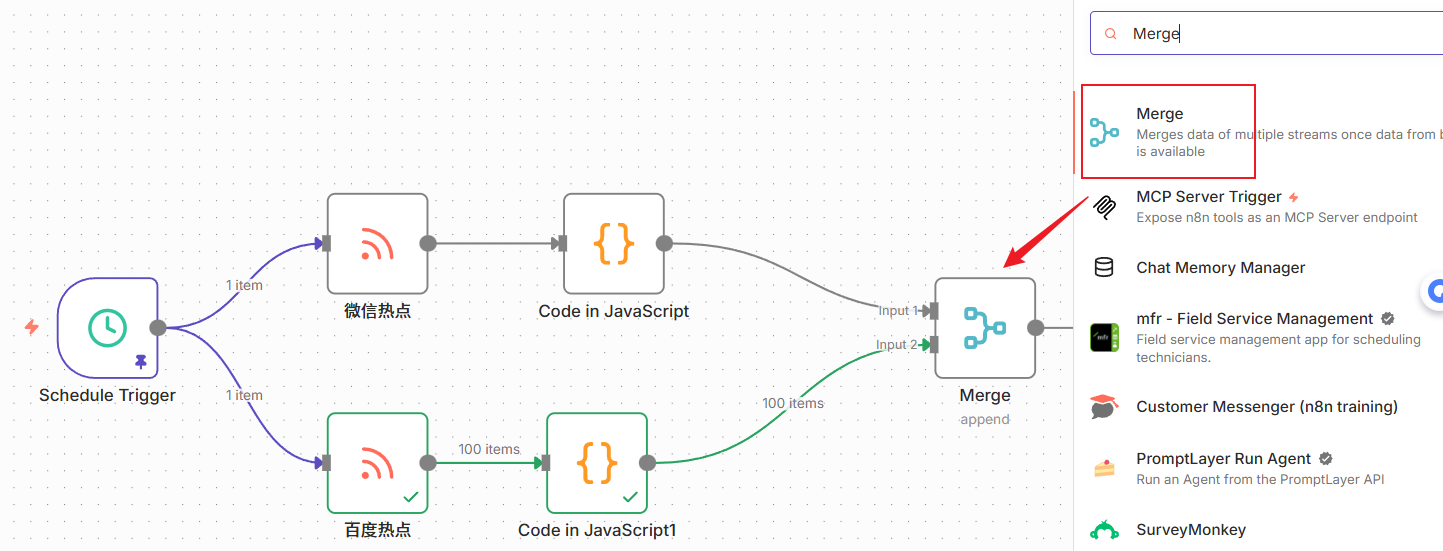
然后进入设置一下节点,模式选择append,下面那个数字代表合并多少个分支,如果你订阅的比较多,可以修改这个数字增加入口点。
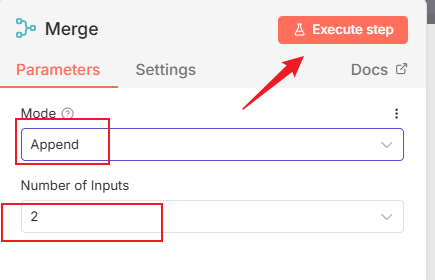
设置好后,点击“执行步骤”,可以看到,现在项目合在一起了:
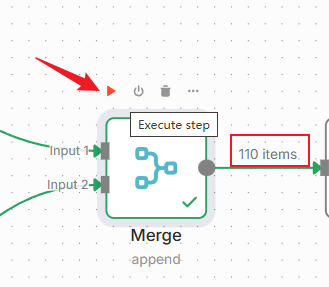
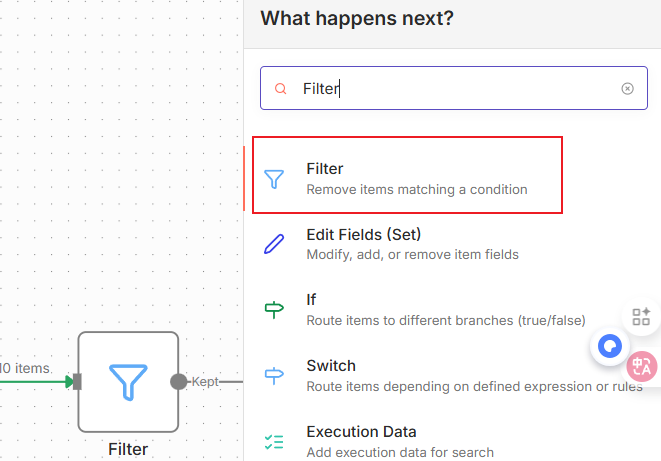
五、数据过滤
有的时候,数据很多,我们需要筛选,比如说我只要发布日期在1天之内的内容(当前时间上下24小时内)那该怎么办呢?这个时候筛选节点就登场了,我们在合并的节点后面加上这个节点:
接着设置一下过滤的条件如下:
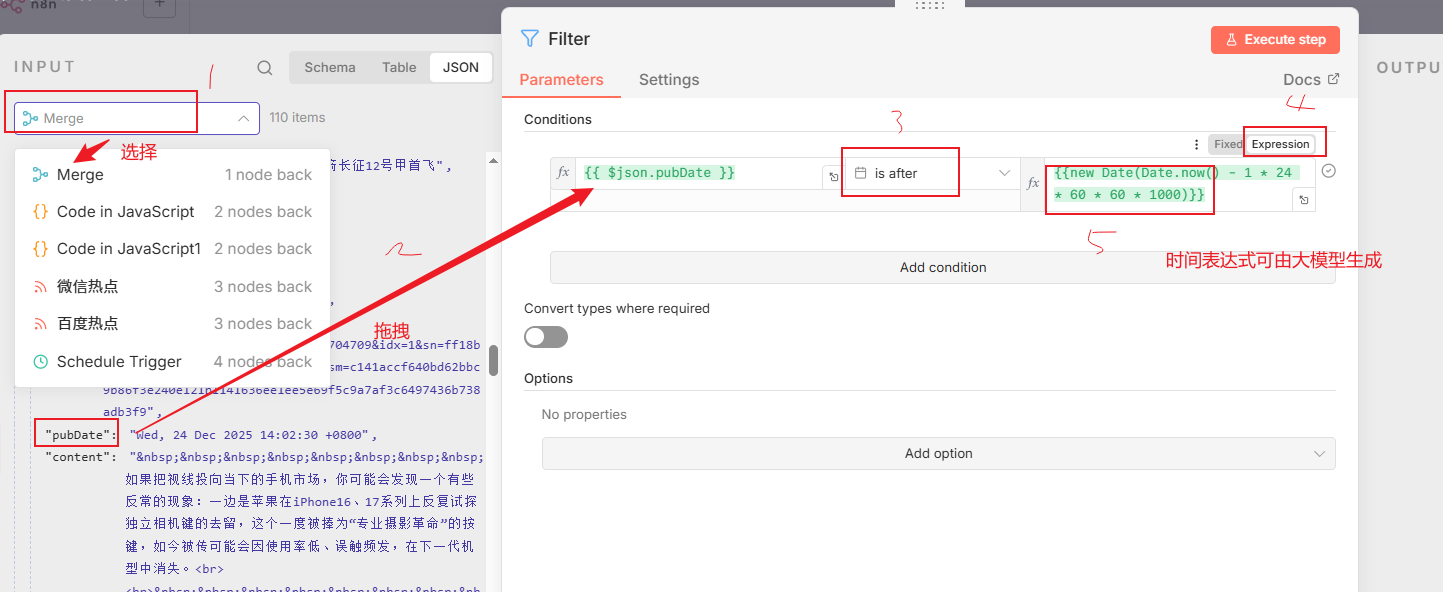
时间表达式:{{new Date(Date.now() - 1 * 24 * 60 * 60 * 1000)}}
这个是UTC时间转换为北京时间的表达式:{{ new Date(new Date().getTime() - 1 * 60 * 60 * 1000).toLocaleString('en-US', { timeZone: 'Asia/Shanghai', year: 'numeric', month: '2-digit', day: '2-digit', hour: '2-digit', minute: '2-digit', second: '2-digit' }) }}
设置之后,直接运行该节点,可以看到过滤了些内容为110items:
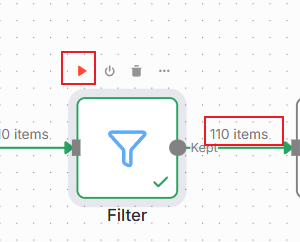
六、合并项目
接下来这是个重点,我们在批量获取数据,如果最终获得的items数据是这种大于1个的,如上图的,有110个items,那么Filter的下一个节点就会批量执行110次,这是n8n最容易出问题的地方,大家一定注意。
为了解决这个问题,如果不是需要循环处理数据的情况,就比如我们这个,我接下来应该是要把所有内容组装成一个JSON,然后一口气就行后续处理,而不是一条一条频繁处理。所以我们接下来要用这个节点 aggregate,这个节点的作用就是可以将前面的多个items合并到一个变量中。
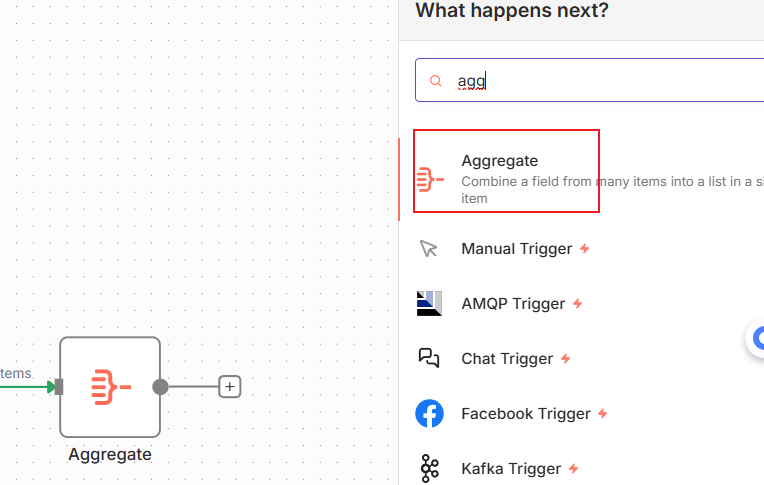
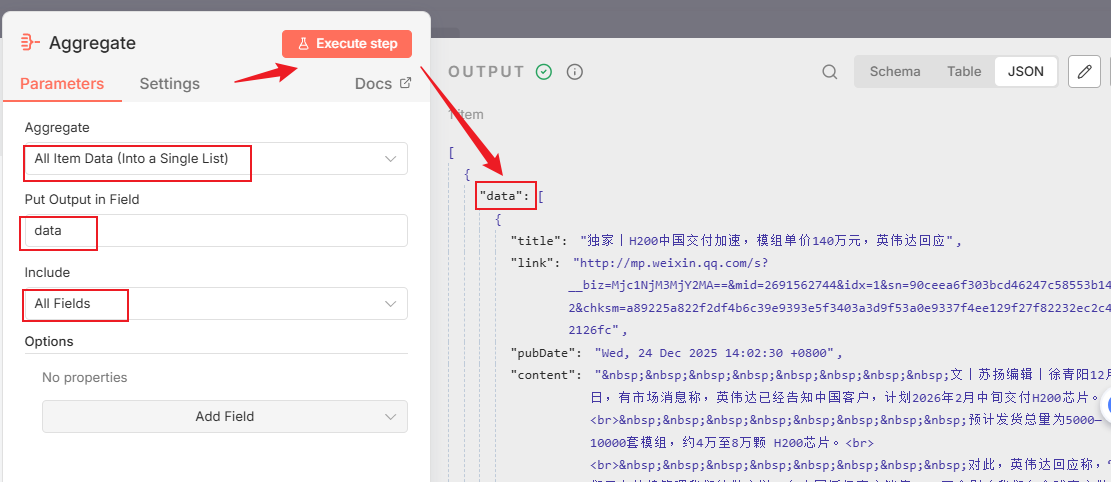
按照如下的设置之后,执行节点,所有内容数据就都到data中了,接下来在画布上看,就只有一个items了:
七、录入飞书
1、安装飞书社区节点
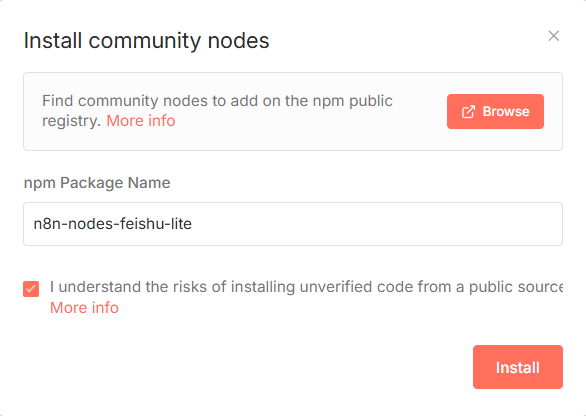
录入飞书需要用到一飞书的社区节点,它包含了飞书各种操作,我们进入节点地址https://www.npmjs.com/package/n8n-nodes-feishu-lite ,然后复制安装命令npm i n8n-nodes-feishu-lite。然后进入n8n的设置里面找到社区节点,进行安装
2、添加飞书凭证
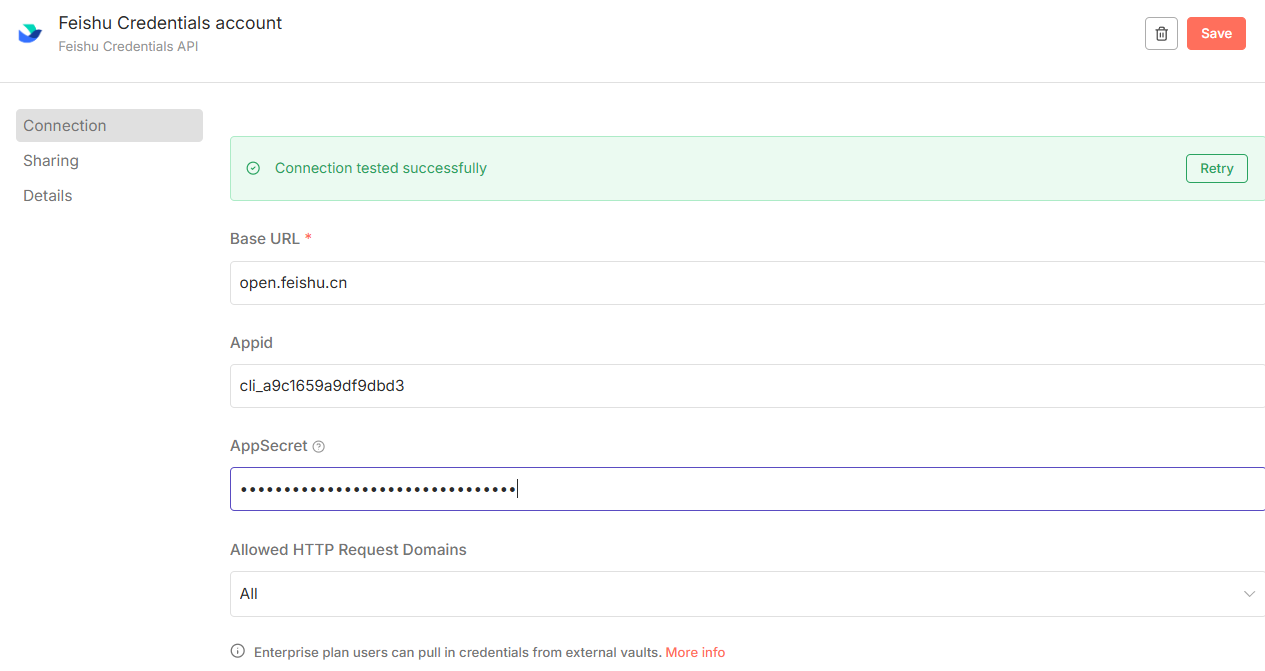
安装完成之后,我们要去添加一下飞书的凭证:

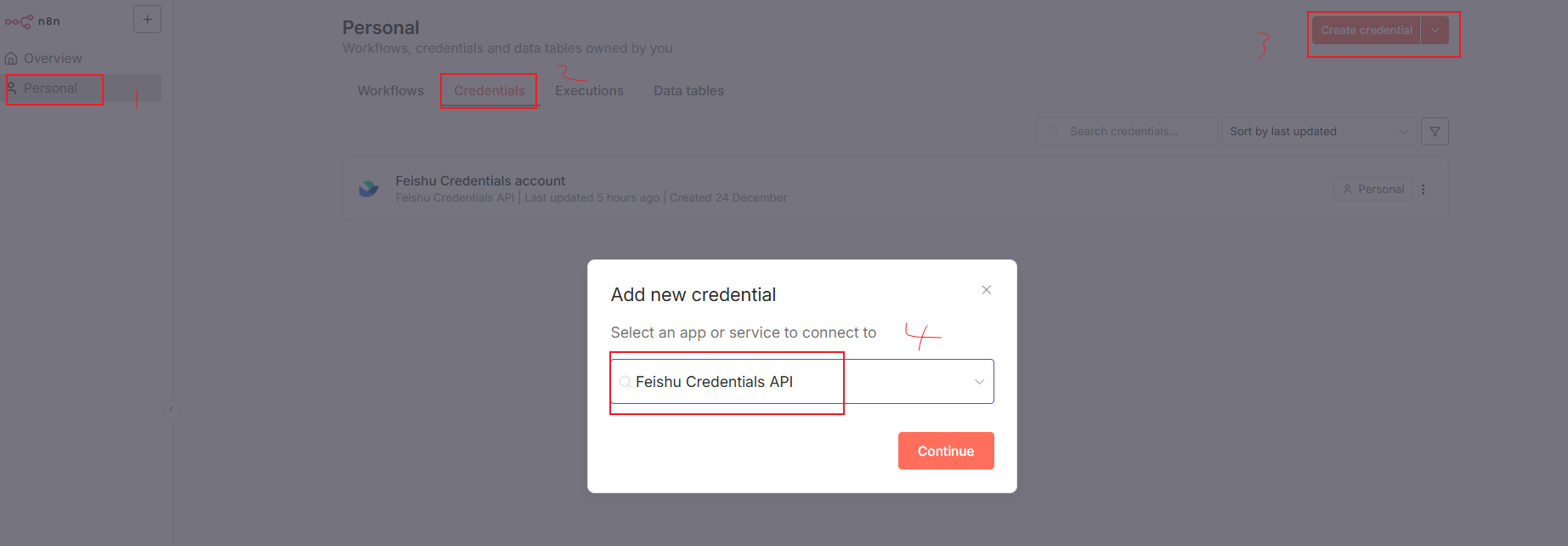
这里需要输入飞书的AppID和密钥等信息:
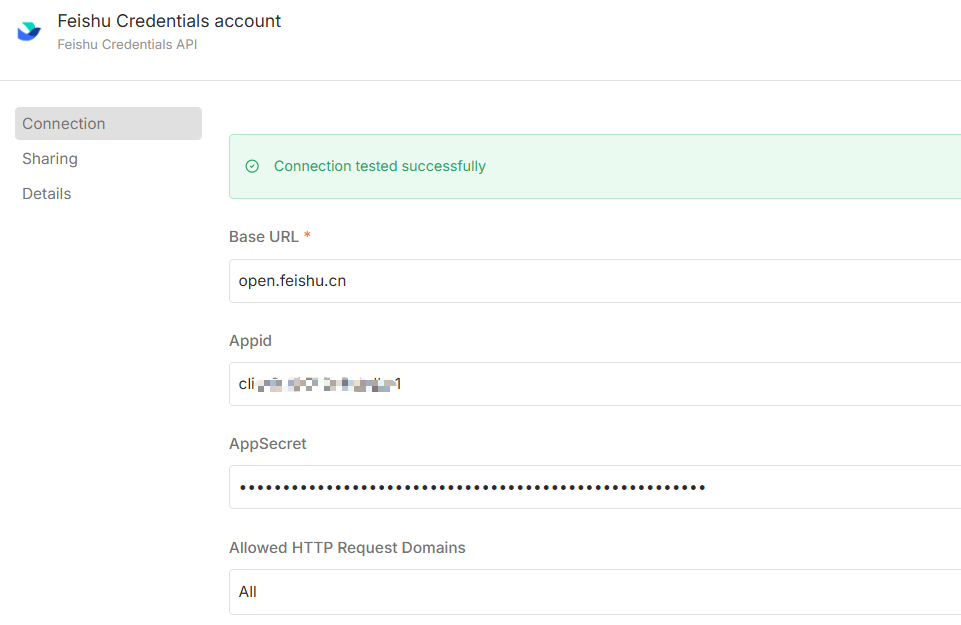
飞书的AppID和密钥等信息获取流程如下:
1.打开飞书网站,进行注册并登录:https://www.feishu.cn/
2.登录飞书后,进入飞书的【工作台】https://pcn05gjv5rgb.feishu.cn/next/workplace/
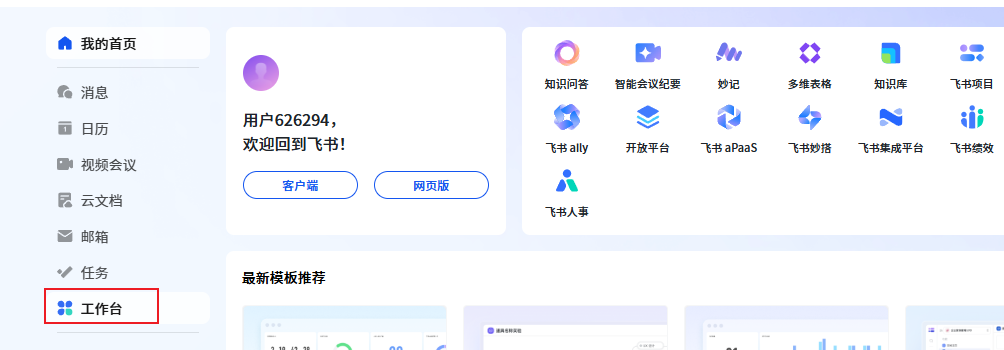
3.在工作台页面右上角点击【创建应用】
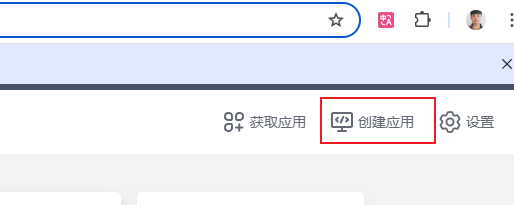
4.再点击创建应用后,页面会跳转到 https://open.feishu.cn/ ,点击新页面右上角的【开发者后台】
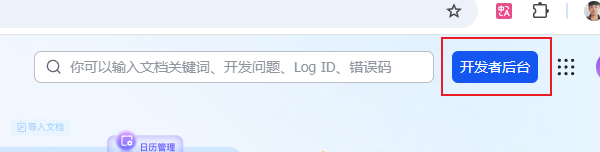
5.在【开发者后台https://open.feishu.cn/app?lang=zh-CN 】页面,点击【创建企业自建应用】
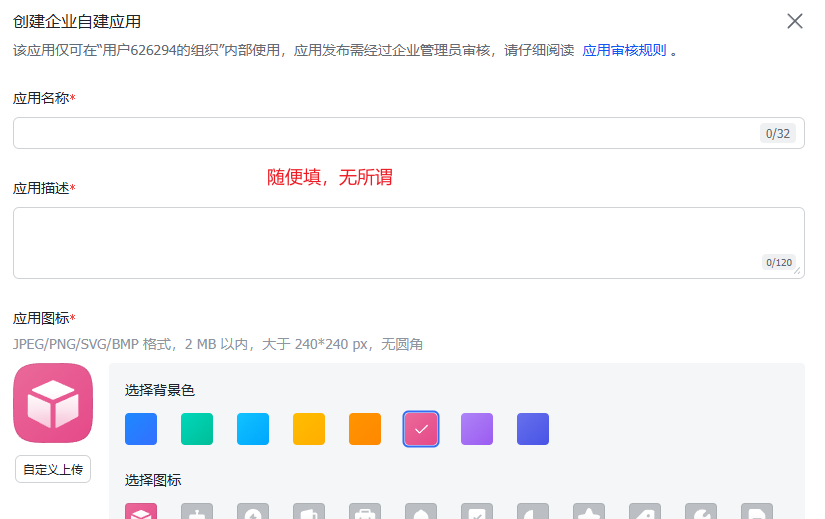
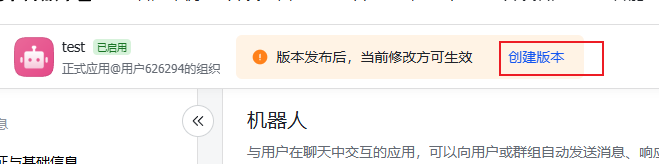
6.应用创建成功后,会进入到以下页面,可以看到以下提示:
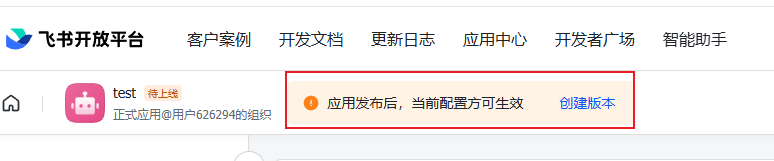
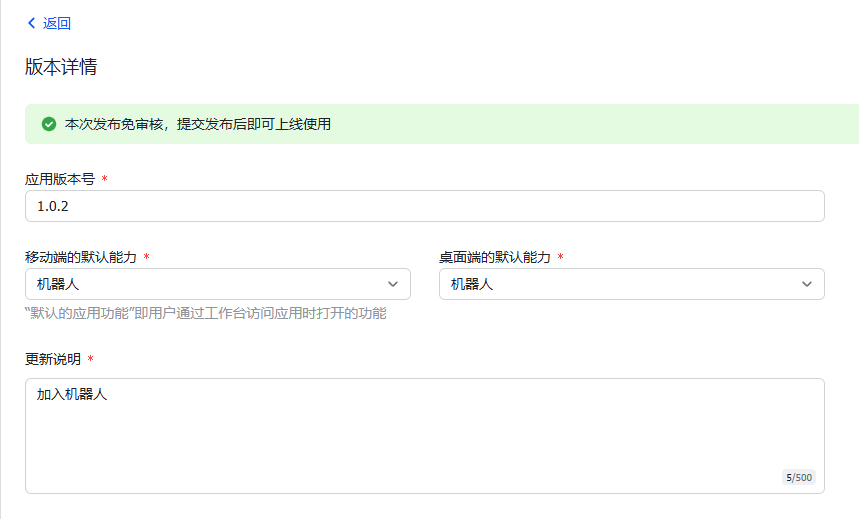
7.点击上图中的【创建版本】,填写对应信息后保存

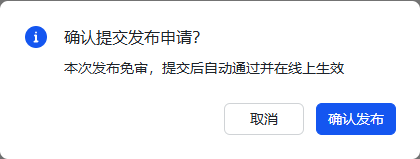
8.在出现的弹窗中点击【确认发布】
9.在发布后返回的页面中左侧功能栏中,点击【权限管理】,在主页中选择【云文档】并开通所有权限
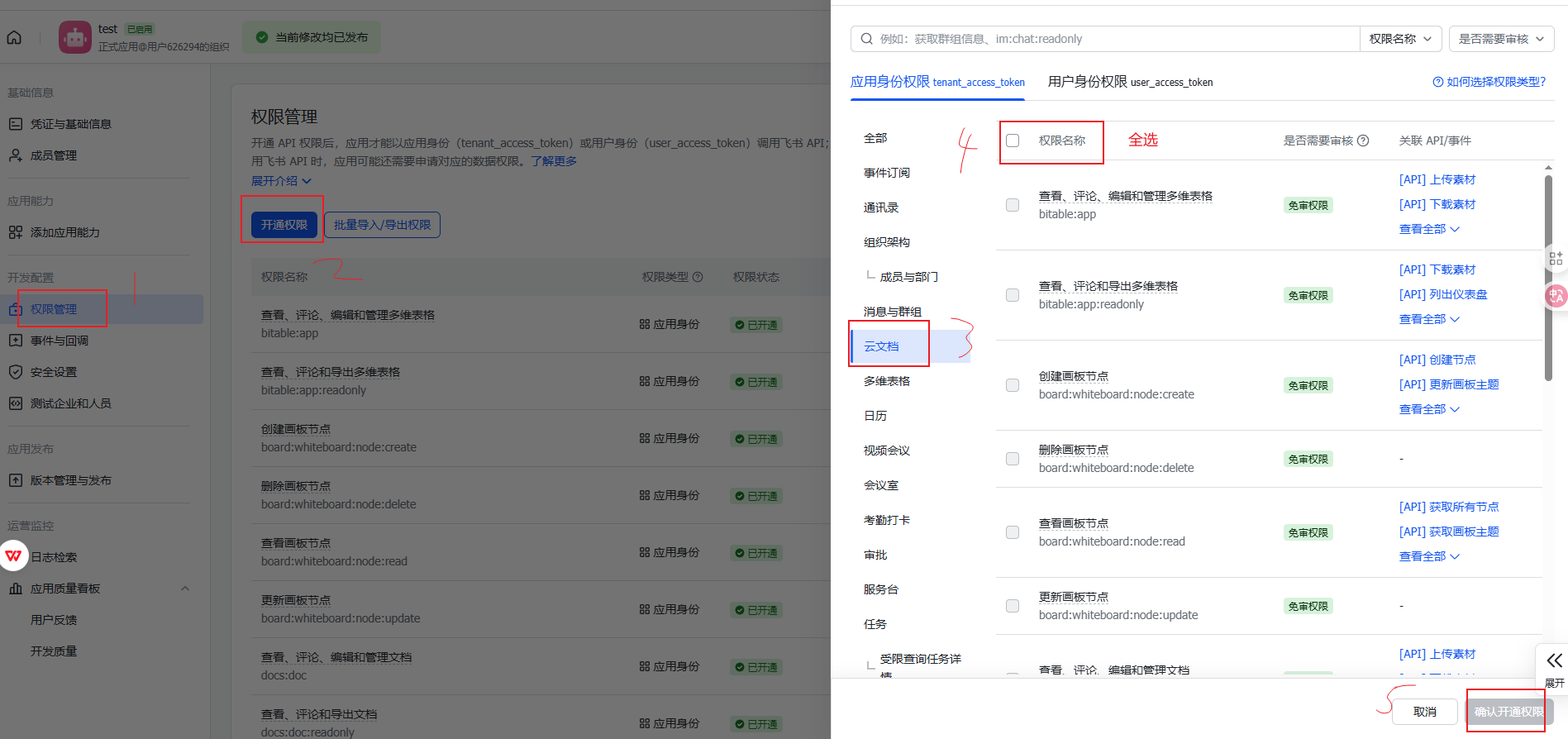
然后在当前页面会看到提示信息,进行版本发布:
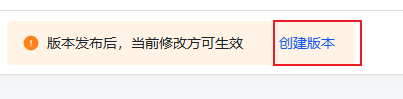
填写版本相关信息:
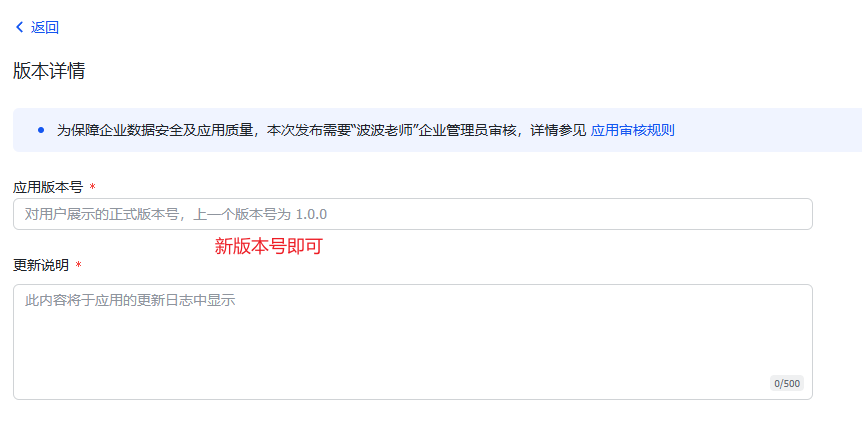
进行线上发布:
登录飞书客户端,会收到一条审批通知,线上审批通过即可:
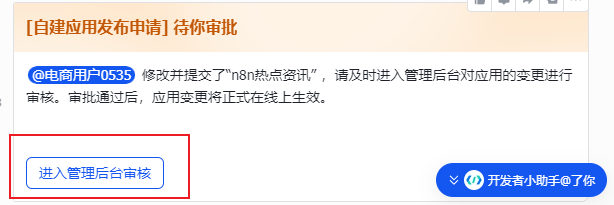
10.在当前主页左侧功能栏找到【凭证与基础信息】,其中的App ID和App Secret就是添加飞书凭证需要的内容

11.飞书凭证添加内容:
3、开通飞书相关权限
接下来为了实现最大自由化的控制飞书资源,需要按照下面的教程,将文件夹的资源分配给飞书应用,这一步很重要,关系到n8n能不能自由的创建编辑表格,参考教程: https://open.feishu.cn/document/faq/trouble-shooting/how-to-add-permissions-to-app 。
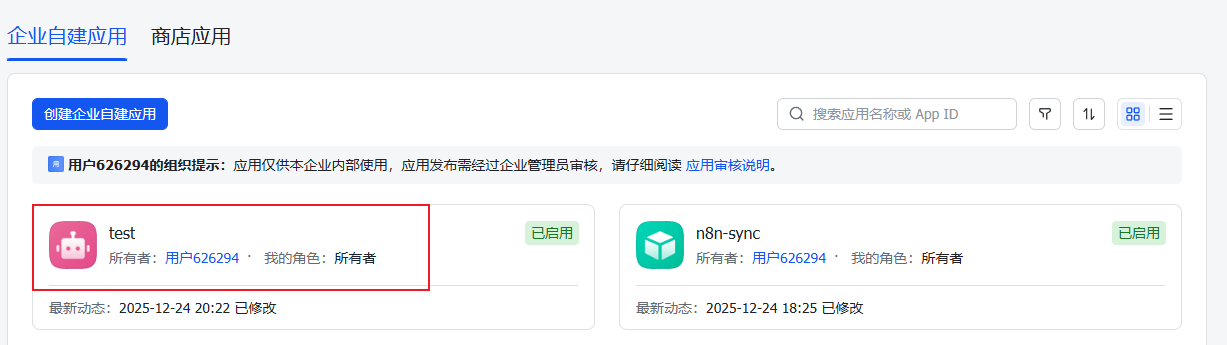
1.访问【开发者后台】 https://open.feishu.cn/app ,选择目标应用。
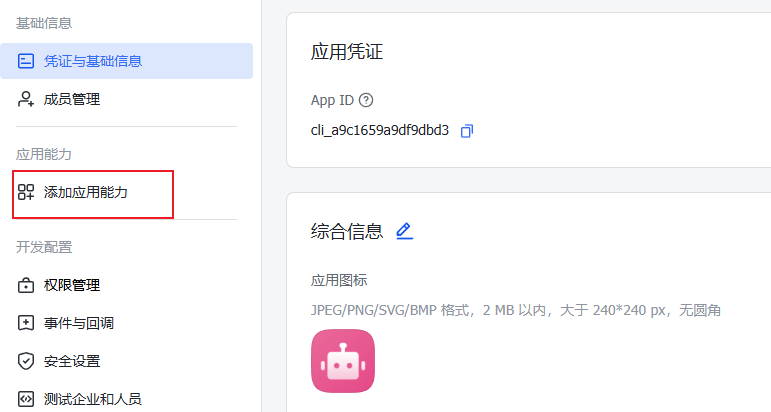
2.在应用管理页面,点击添加应用能力。
3.找到机器人卡片,点击 +添加。
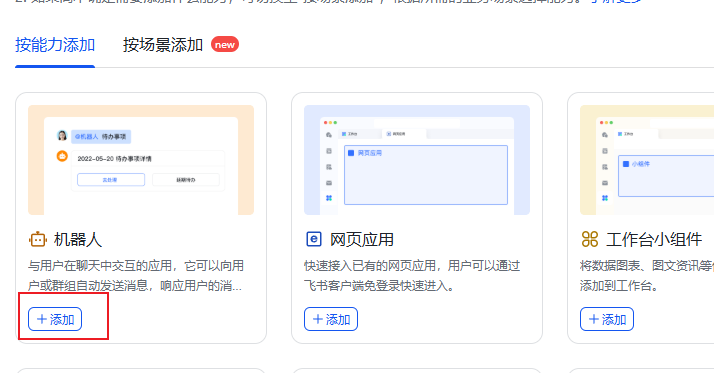
4.发布当前应用版本,并确保发布版本的可用范围包含文件夹资源的所有者。
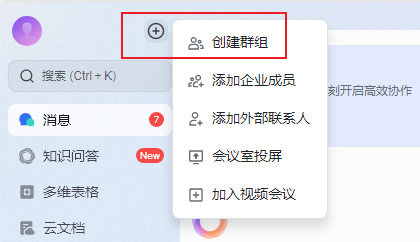
5.在飞书客户端,创建一个新的群组,将应用添加为群机器人。
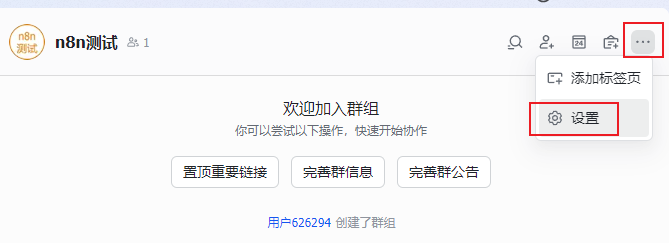
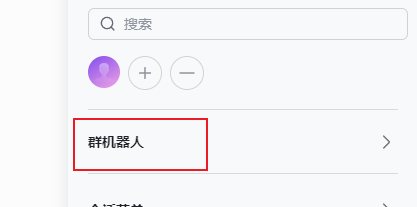
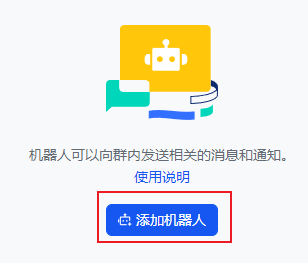
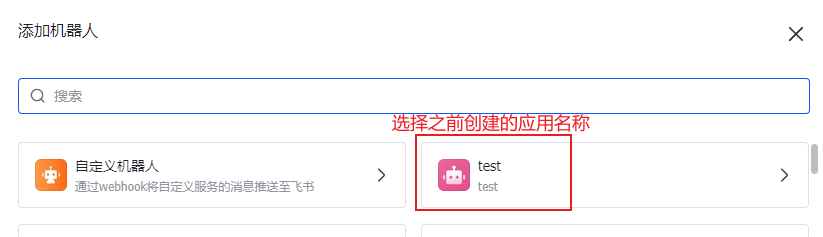
6.来到飞书首页 https://www.feishu.cn/ ,选择【云文档】进行登录
7.创建一个文件夹,自定义名称
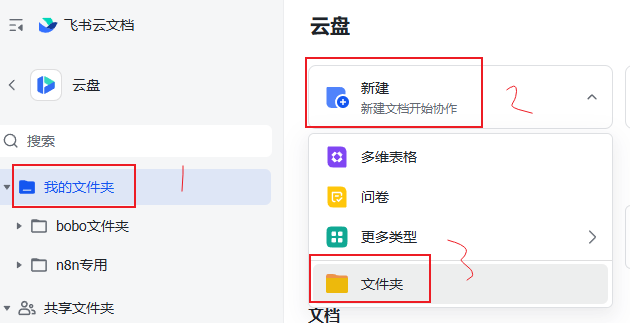
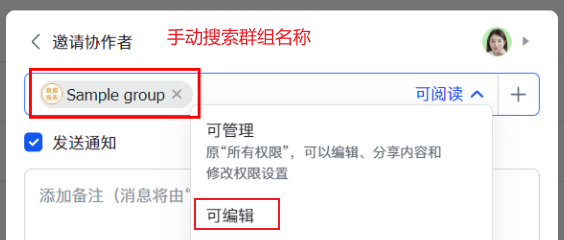
8.将文件夹分享给刚刚新建的群组,并设置可编辑权限。
4、创建电子表格
以上准备工作都完毕之后,我们添加一下创建电子表格节点,我们想要让工作流定时跑,每天都会生成一个电子表格,里面是当天的内容,搜索 feishu 找到下面这个节点然后将【创建电子表格】,添加进来:

配置节点:
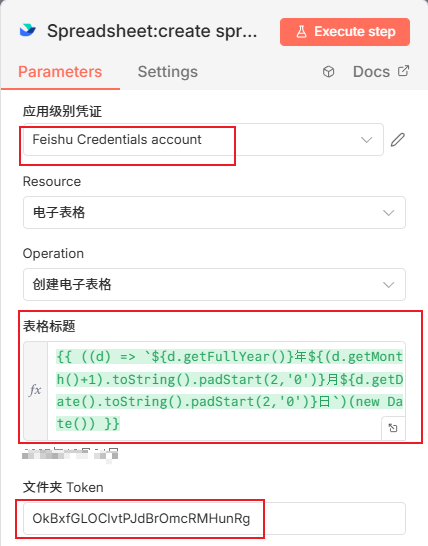
表格标题表达式:今天的日期
{{ ((d) => `${d.getFullYear()}年${(d.getMonth()+1).toString().padStart(2,'0')}月${d.getDate().toString().padStart(2,'0')}日`)(new Date()) }}
文件夹Token为:
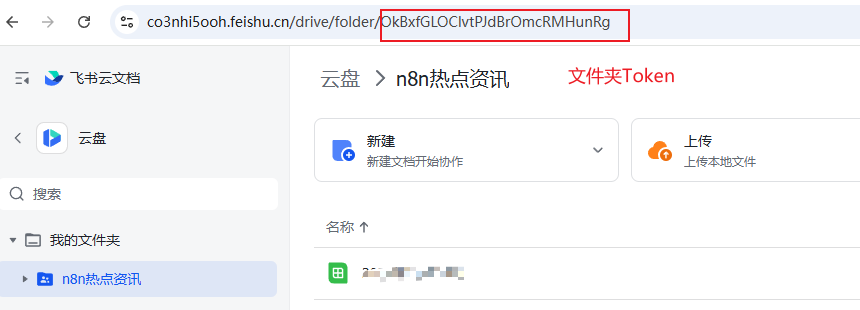
执行节点后,在飞书云文档页面会看到刚才新建的名字为当天日期的文档文件。
5、写入电子表格
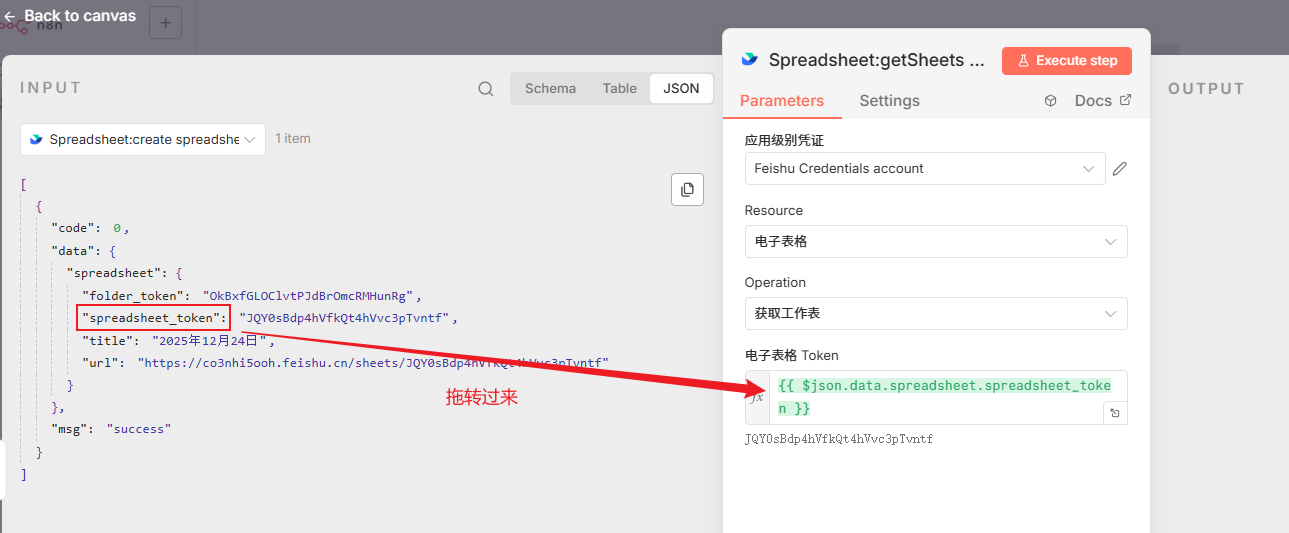
好了,终于到了最后一步写数据了,在进行写数据之前,还需要添加一个获取工作表的节点:
配置节点:一个表格里面还可以有许多不同的表单,我们需要获取当前表格的表单ID,以确认后续要往哪个表单写入数据
接下来还需要按飞书的要求对数据进行处理,否则无法写入飞书
这个处理还是有点复杂的,需要用到代码节点,把前面的JSON数据处理成适合写入飞书表格的格式:
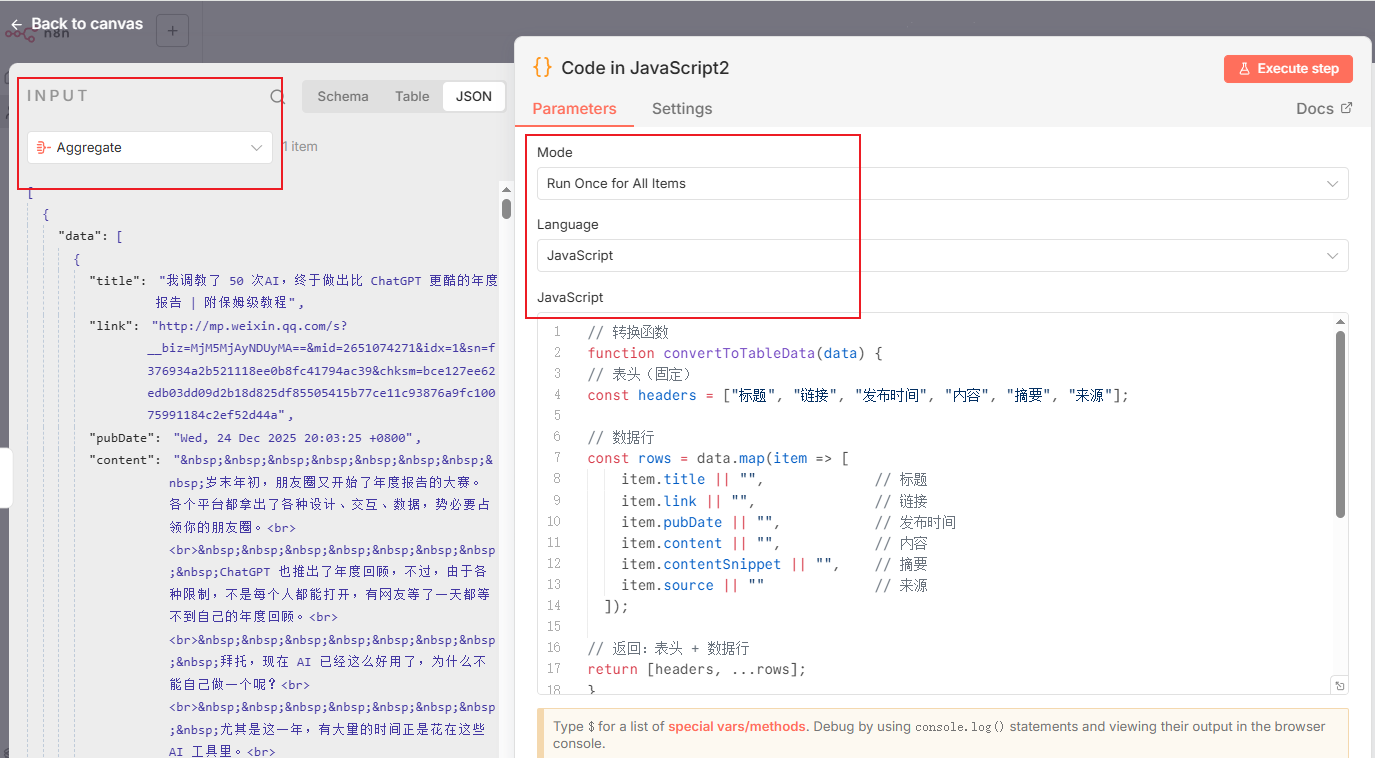
代码如下:
// 转换函数
function convertToTableData(data) {
// 表头(固定)
const headers = ["标题", "链接", "发布时间", "内容", "摘要", "来源"];
// 数据行
const rows = data.map(item => [
item.title || "", // 标题
item.link || "", // 链接
item.pubDate || "", // 发布时间
item.content || "", // 内容
item.contentSnippet || "", // 摘要
item.source || "" // 来源
]);
// 返回:表头 + 数据行
return [headers, ...rows];
}
// Add a new field called 'myNewField' to the JSON of the item
// 原始数据
const inputData = $('Aggregate').item.json.data;
console.log(inputData)
// 执行转换
const tableData = convertToTableData(inputData);
// 打印结果(可在控制台查看)
console.log(tableData);
$input.item.json.tableData = tableData;
return $input.item;
最后添加一下最后一个【电子表格-写入数据】节点,然后进行如下节点配置:
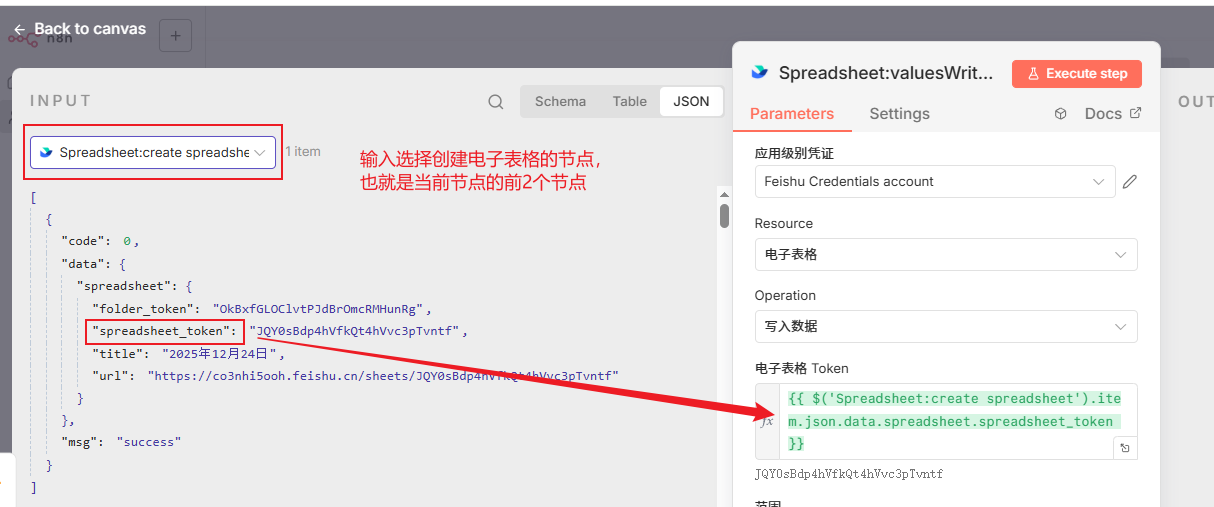
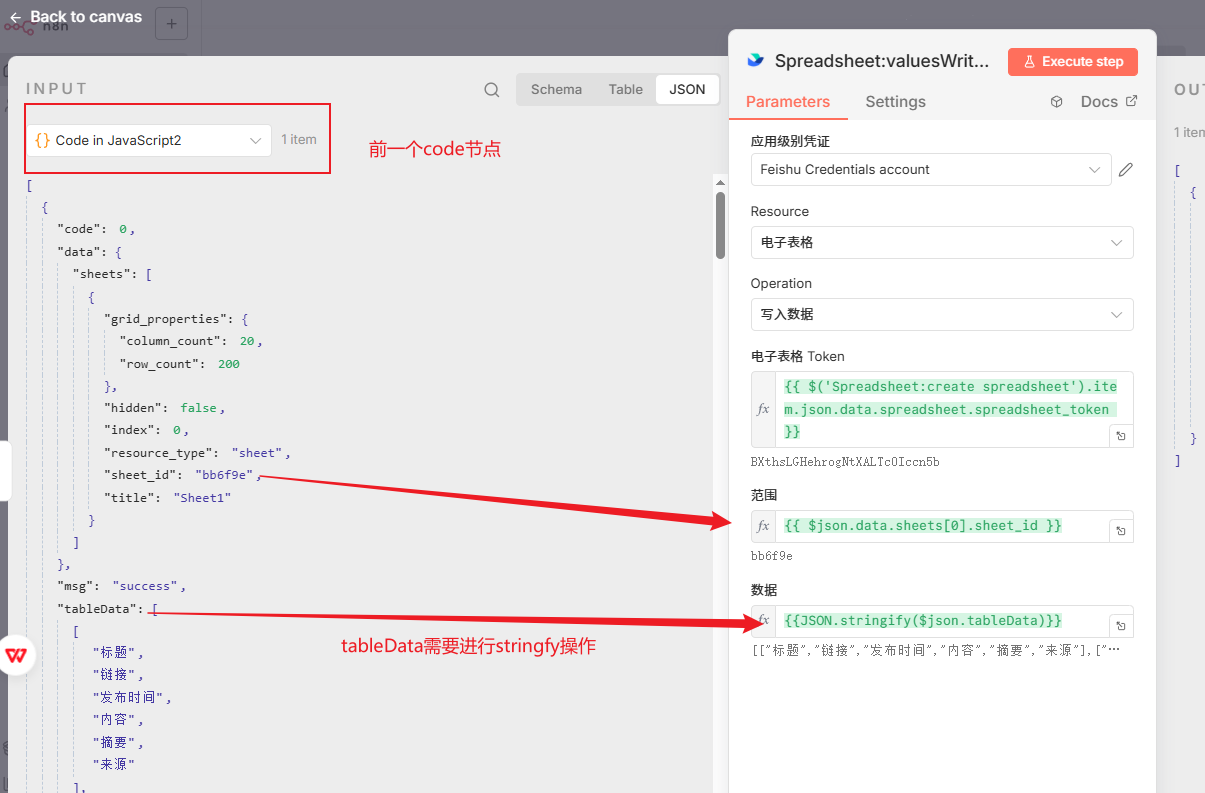
数据项填充:{{JSON.stringify($json.tableData)}} 意思是将json.tableData这个json对象转换为json格式字符串,因为飞书节点需要的是json格式字符串而不是json对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号