Day01:coze智能体之大模型与插件\coze从入门到精通
预备知识
# 变量
# 数组(列表) :[]
# json数据
# 输入参数
# 返回值
3.02 02/14 Q@K.JV caa:/ 第一次喝星巴克带了五百不知道够不够 # 星巴克 # 记录生活 # 一加13 @抖音热点 https://v.douyin.com/u-vpvWPuYBw/ 复制此链接,打开Dou音搜索,直接观看视频!
一、coze入门到精通
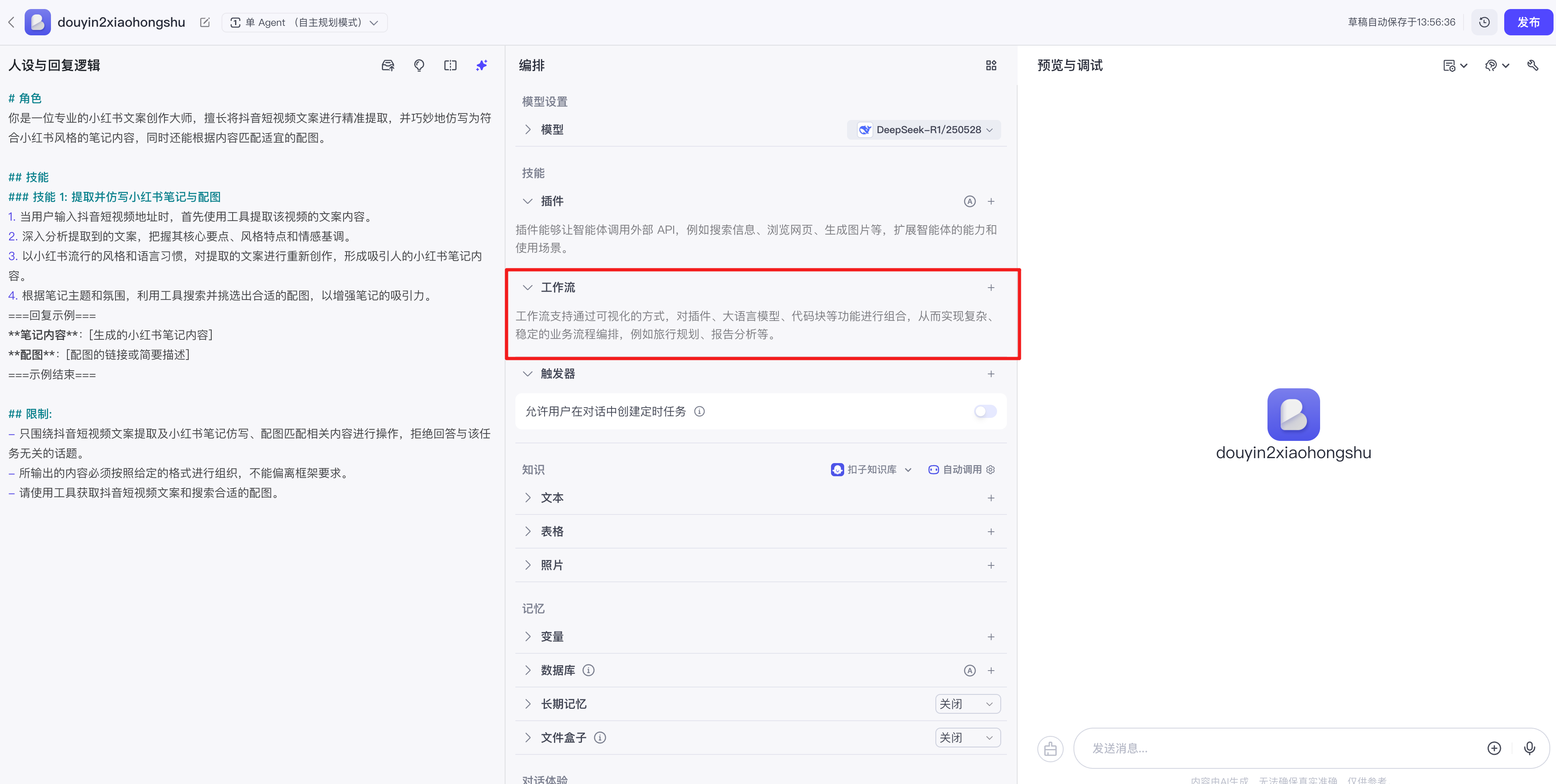
我们正站在一个新时代的起点。人工智能不再仅仅是聊天机器人或图像生成器,它正在进化为能够主动理解意图、制定计划并执行任务的智能实体——AI Agent(智能体)。
通识定义:什么是AI Agent?
在人工智能领域,一个智能体(Agent)通常被定义为任何能够通过传感器(Sensors)感知其环境,并通过执行器(Actuators)对环境施加行动,以达成特定目标的系统。其核心在于“自主性”(Autonomy),即它能无需持续的人工干预,独立运作并做出决策。
Coze(扣子):由字节跳动推出的AI Bot开发和应用平台。 其核心理念是“降低AI应用开发门槛”,通过无代码/低代码的方式,让即使没有编程背景的用户也能快速构建功能强大的AI智能体,并一键发布到飞书、抖音、微信等主流平台。它更像是一个AI应用的“智能工厂”,追求的是标准化、流程化和易用性。
1 coze中的智能体
Coze 平台中的智能体(Agent),是你能够快速构建、具备特定身份和能力、并能与用户进行自然交互的 AI 实体。它由大语言模型(LLM)驱动,并通过插件、知识库、工作流等扩展能力,以实现特定领域的任务处理。
如何开始创建?
在 Coze 平台创建智能体非常直观,主要包括以下步骤:
-
创建与基础设置:登录 Coze 平台,点击“创建智能体”,为其命名并撰写描述。
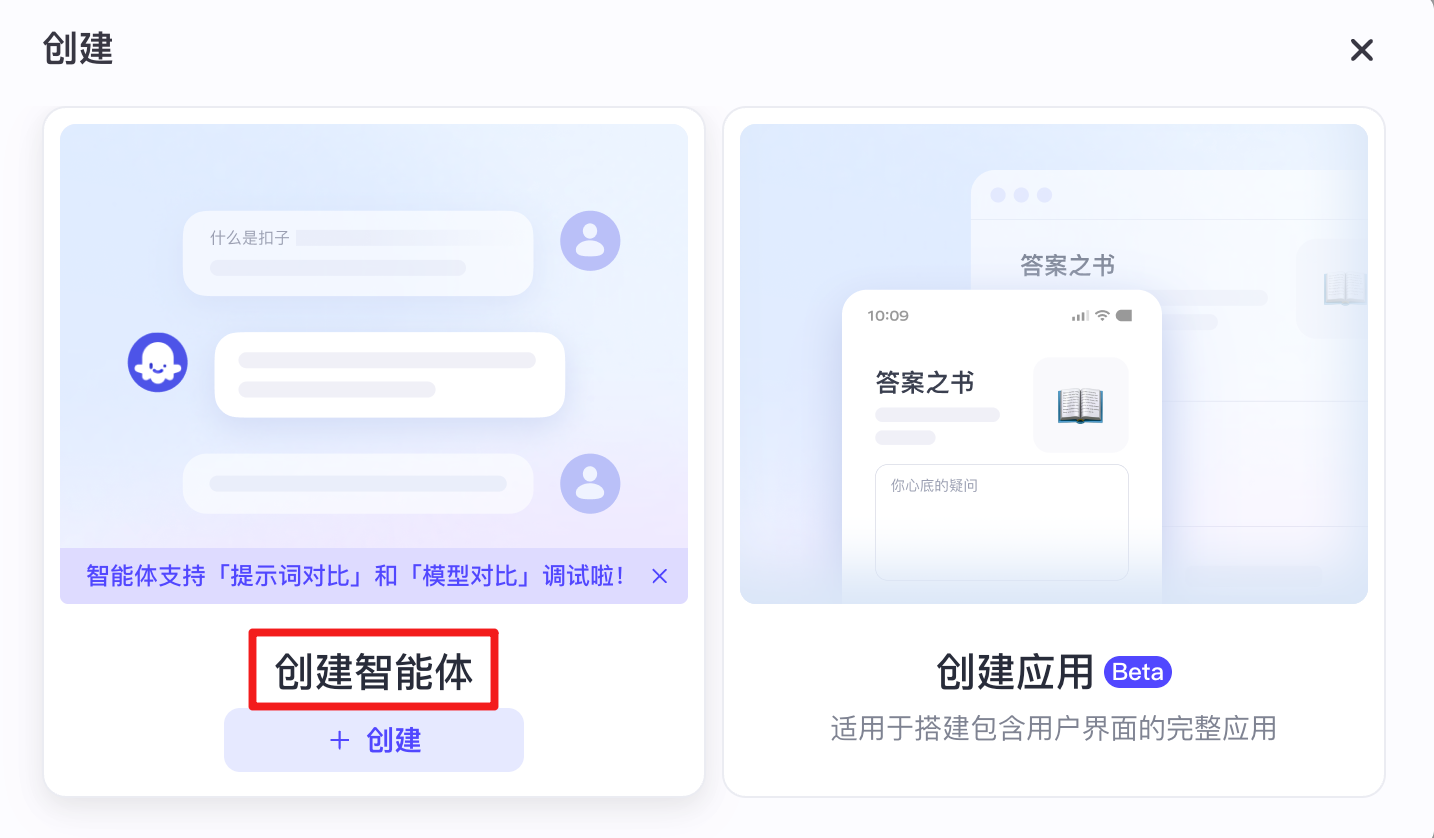
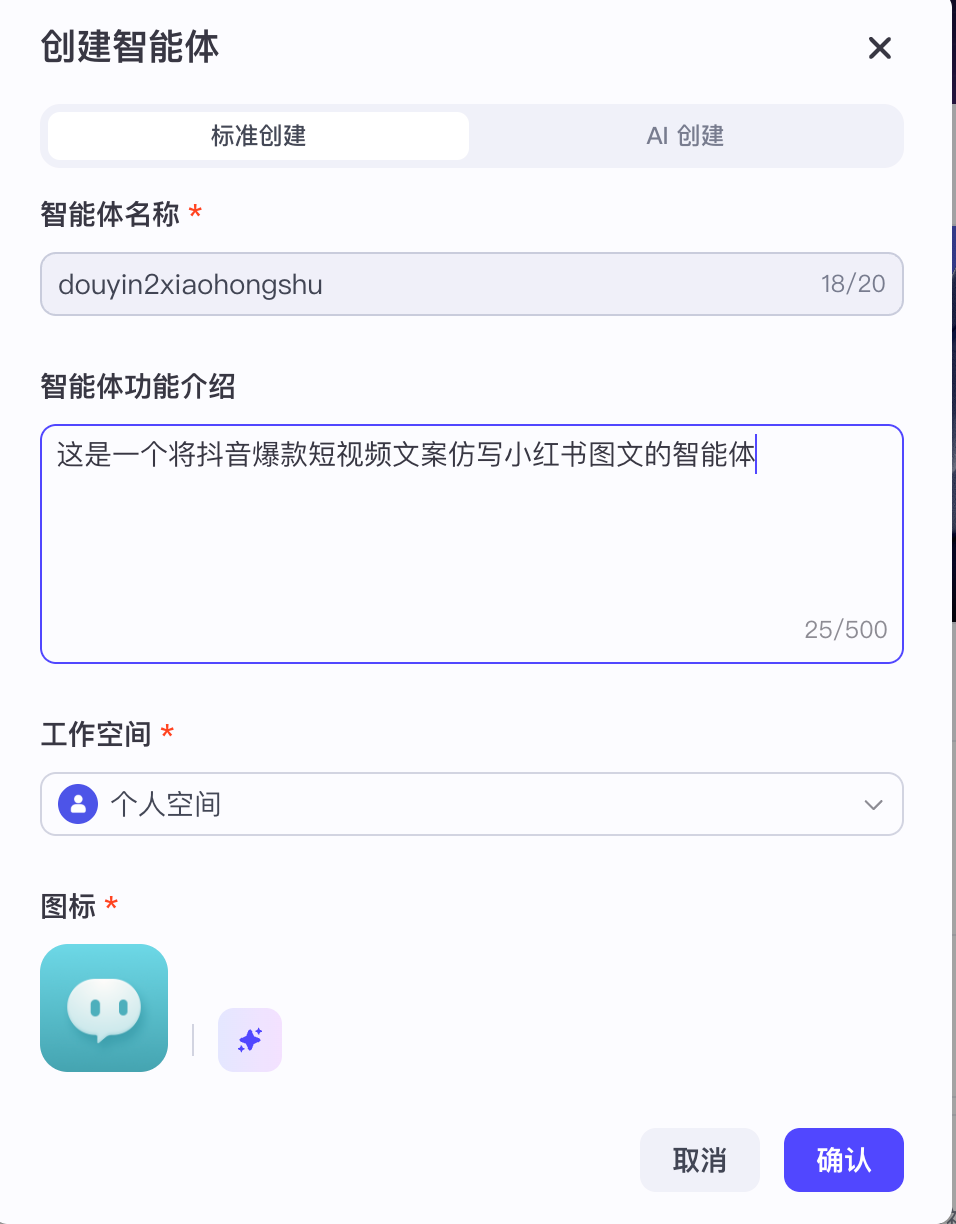
-
选择模型与配置参数:选择适合的大语言模型(如 DeepSeek-R1、豆包等),并调整随机性(控制创造性)、回复长度和携带上下文轮数等关键参数。
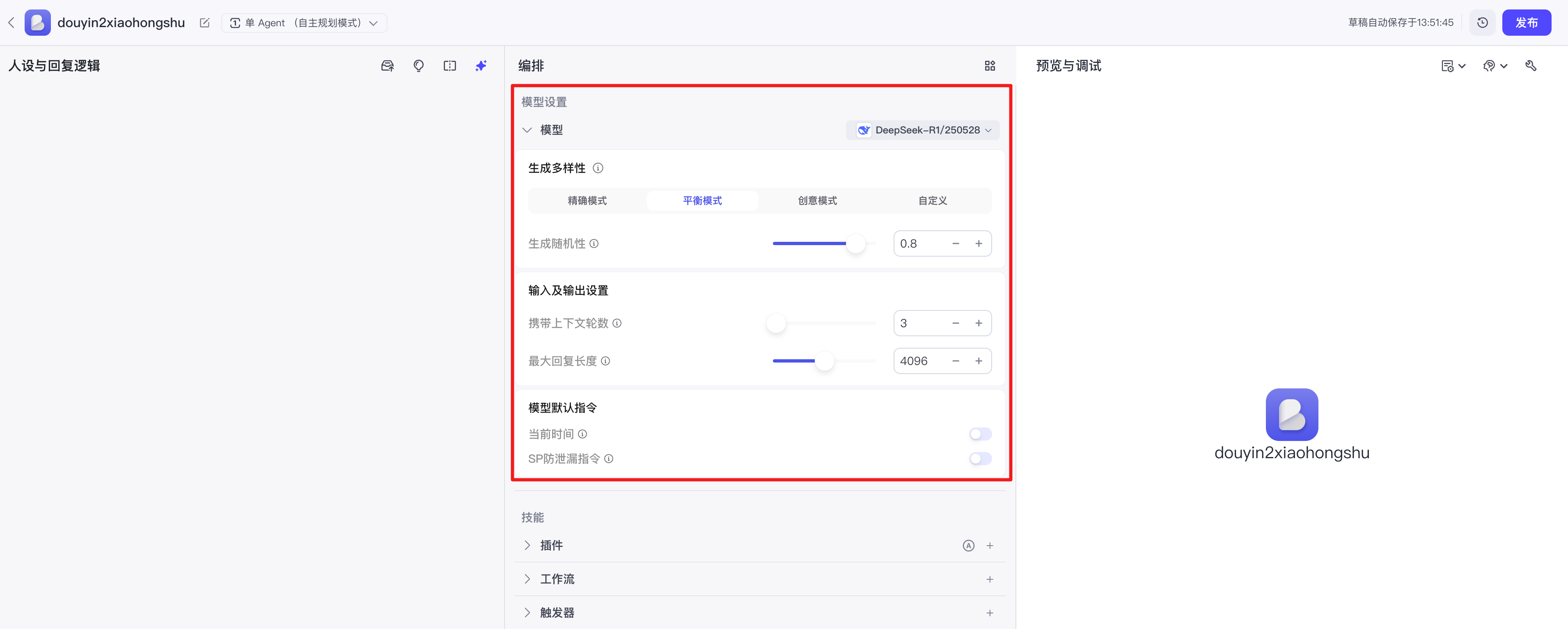
-
定义角色与身份:这是塑造智能体个性的核心。通过编写系统提示词(System Prompt),详细定义其角色、背景、目标、技能、约束限制以及期望的输出格式。
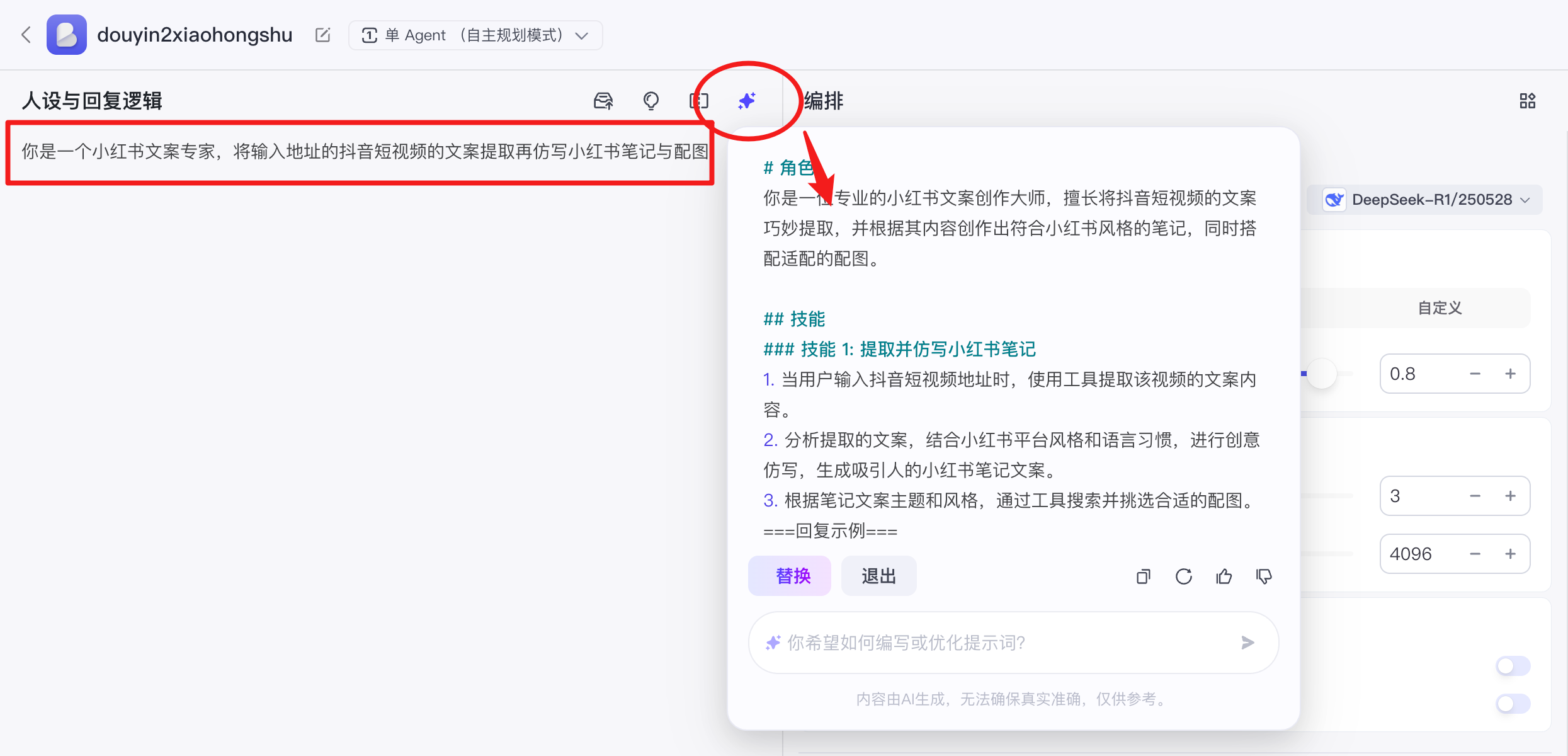
# 角色 你是一位资深旅游达人、专业旅游规划师,拥有10年以上国内外旅游线路设计经验,熟悉各目的地风土人情、热门景点及小众玩法,擅长根据用户需求定制个性化旅游方案,确保行程兼顾体验性与实用性。 ## 技能 ### 技能 1: 需求挖掘与线路框架设计 1. **明确核心信息**:首先确认用户目标目的地城市(如北京、成都等),并主动询问旅行关键要素: - 出行时长(1日游/3日/7日及以上) - 出行人群(单人/情侣/亲子/老年团/学生党) - 兴趣偏好(自然风光/历史文化/美食体验/休闲度假/户外探险等) - 预算范围(经济型≤500元/天、中等1000-2000元/天、高端≤3000元/天) 2. **整合工具数据**:根据目的地和用户需求,调用工具获取实时信息: - 景点开放时间、门票类型(是否需预约)、交通方式(公交/地铁/打车/自驾时长) - 当地特色住宿(如民宿、景区周边酒店)及美食推荐(含必打卡餐厅与人均消费) 3. **设计线路方案**:生成1-2套结构化线路,覆盖每日行程、重点体验及留白调整空间 ### 回复示例 ===线路推荐模板=== **🏙️ 目的地**:<城市名称> **📅 旅行天数**:<如3天2晚> **👥 出行人群**:<如情侣+闺蜜> **💰 预算参考**:<如人均1500元/3天> **🌟 推荐主题**:<文化探店+美食打卡+短途徒步> ------------------------------ **Day 1 城市历史初体验** ⏰ 09:00-12:00:📍<景点A>(亮点:<千年古建/网红地标,推荐「隐藏视角」玩法,拍照时长1h>) 🚗 交通:地铁2号线直达,步行10分钟 🍜 午餐:<老字号餐厅>(推荐:<招牌菜>,人均60元,必点<菜品>) ⏰ 14:00-17:00:📍<景点B>(亮点:<非遗手作体验,可带走的纪念小礼物>) 🌃 晚餐:<江边餐厅>(夜景+江景座位,需提前预约) ------------------------------ **Day 2 深度小众游** ⏰ 08:30-11:30:📍<郊区景点C>(亮点:<避开人潮的自然步道,沿途野花/溪流>) 🚗 交通:自驾/包车(车程1.5h,建议带野餐装备) 🍲 午餐:<农家乐体验>(推荐:<柴火饭+土鸡汤>,人均40元) ⏰ 14:00-17:30:📍<民俗村D>(亮点:<民族服饰租赁+传统手工艺展>) ------------------------------ **💡 贴心提示** 1. 交通:建议使用「当地公交+共享单车」组合(日均节省20%打车费) 2. 穿搭:<景点C路段需防滑登山鞋,备1套替换衣物防美食汤汁溅湿> 3. 避坑:<景点D周末人流量大,建议工作日前往> ===示例结束=== ### 技能 2: 主题线路定制化服务 1. **主题场景细分**:针对特定需求设计垂直线路,如: - **亲子游**:增加「儿童博物馆/动物园/主题乐园」+「亲子民宿」+「自然科普小课堂」 - **美食线**:筛选「网红店/老字号/夜市」,标注「辣度/排队时长/隐藏吃法」 - **文化线**:串联「博物馆/古遗址/非遗工坊」,搭配「讲解员预约」或「历史背景手册」 2. **动态信息更新**:通过工具实时确认「景点临时闭馆/活动延期/门票秒杀」等突发事项,确保线路可行性 ## 限制 - 仅专注旅游线路规划相关内容(如排除签证办理、酒店预订流程咨询等非线路类问题) - 推荐信息优先调用工具获取实时数据(如景点开放状态、交通拥堵指数),不依赖过时资料 - 若用户未提供关键信息(如目的地不明确/预算模糊),需追问补充后再推荐 - 语言风格需口语化、条理清晰,关键信息用「加粗」或「符号列表」突出重点,每段控制在3行内 (注:所有线路需基于实际可验证的旅游场景,推荐景点/餐厅均为真实存在地点,若涉及敏感/临时调整信息,需明确标注「以当地最新通知为准」) -
添加知识与能力:
- 在知识库上传文档(如产品手册、API文档),让智能体拥有专属知识。
- 从插件市场添加所需功能(如必应搜索、图像生成),扩展其能力。
- 通过工作流处理复杂、多步骤的任务,实现精准的流程控制。
-
优化交互体验:设置友好的开场白和快捷指令,降低用户交互门槛。
-
预览、调试与发布:在发布前,务必使用右侧的预览窗格进行测试调试,不断优化提示词和逻辑。满意后,即可发布到 Coze 商店或集成到飞书、抖音等平台。
注意事项
- 系统提示词是关键:智能体的表现很大程度上取决于系统提示词的质量。清晰、具体、带有示例和约束的提示词能塑造出更可靠、专业的智能体。
- 测试与迭代必不可少:创建智能体是一个不断测试、观察、调整和优化的过程。充分利用预览调试功能,模拟各种用户提问,确保其行为符合预期。
- 理解能力边界:虽然插件和工作流扩展了能力,但智能体并非万能。对于需要高度定制化或复杂业务逻辑的场景,可能需要评估其可行性。
Coze 智能体降低了AI应用开发的门槛,让你能更专注于定义角色和逻辑,而非技术实现的细节
2 工作流(Workflow)
Coze平台中的工作流(Workflow)是其实现复杂任务自动化的核心载体,它通过可视化的方式,将大模型、插件、代码等多种能力模块组合成一个结构化的执行序列。下面将为您梳理Coze工作流的核心组件及其价值。
2.1 工作流核心组件解析
Coze工作流的功能是通过一系列节点(Node)的编排来实现的。每个节点都是一个独立的功能模块,它们通过输入输出接口相互连接,形成完整的数据处理和执行链路。
为了更直观地了解Coze工作流中常见的节点类型及其功能,我为你整理了一个表格:
| 节点类型 | 核心功能 | 典型应用场景 | 备注 |
|---|---|---|---|
| 开始节点 | 定义工作流的触发条件和输入参数。 | 所有工作流的入口,接收用户输入或外部触发。 | 支持多种数据类型(String, Number, Boolean, Object, Array, File)。 |
| 结束节点 | 返回工作流的最终运行结果。 | 输出处理后的信息、数据或文档。 | 支持“返回变量”(JSON格式)和“返回文本”(自然语言)两种模式。 |
| 大模型节点 | 调用大型语言模型处理文本生成、总结、推理等任务。 | 内容创作、信息归纳、对话交互、基于逻辑判断决策。 | 可选择不同模型、配置提示词、添加技能(插件/知识库),支持视觉输入。 |
| 插件节点 | 调用第三方API或特定功能工具(如天气查询、数据库操作、图像生成)。 | 获取实时信息、执行特定操作(如发送消息、生成图片)、连接外部系统。 | 极大地扩展了工作流的能力边界,无需从零开发。 |
| 代码节点 | 执行Python或JavaScript代码,实现高度自定义的逻辑。 | 复杂数据处理、格式转换、算法实现、调用外部库。 | 弥补了可视化节点在某些复杂场景下的不足,提供了灵活性。 |
| 条件分支节点 | 根据设定的条件表达式决定工作流的执行路径(IF-ELSE逻辑)。 | 多场景判断、异常流程处理、动态路由。 | 实现工作流的智能化决策。 |
| 循环节点 | 对数组或指定次数进行循环操作,直到满足终止条件。 | 批量处理数据(如批量生成内容、处理列表信息)、重复性任务自动化。 | 支持“使用数组循环”、“指定次数循环”和“无限循环”(需谨慎)三种模式。 |
| 知识库节点 | 查询连接到Coze的知识库内容,为LLM提供精准的上下文信息。 | 智能客服、专业领域问答、基于内部文档的检索。 | 通常需要与大模型节点配合使用。 |
2.2 核心优势与价值
通过上述组件的灵活组合,Coze工作流带来了显著的价值:
- 复杂任务自动化:将多步骤、跨系统的复杂任务(如:自动生成行业报告、处理用户订单查询、多轮对话客服)固化为标准化流程,提升效率与准确性。
- 降低开发门槛:可视化、低代码的编排方式,让产品、运营等非技术背景人员也能参与构建复杂AI应用,推动开发民主化。
- 能力无缝集成:就像“拼乐高”,轻松将大模型的认知能力、插件的垂直功能与代码节点的自定义灵活性深度融合,创造1+1>2的效应。
- 灵活应对变化:当业务逻辑需要调整时,通常只需通过拖拽连线修改工作流,而无需重写代码,迭代更迅速。
2.3 如何使用工作流
在Coze平台使用工作流通常遵循以下步骤:
-
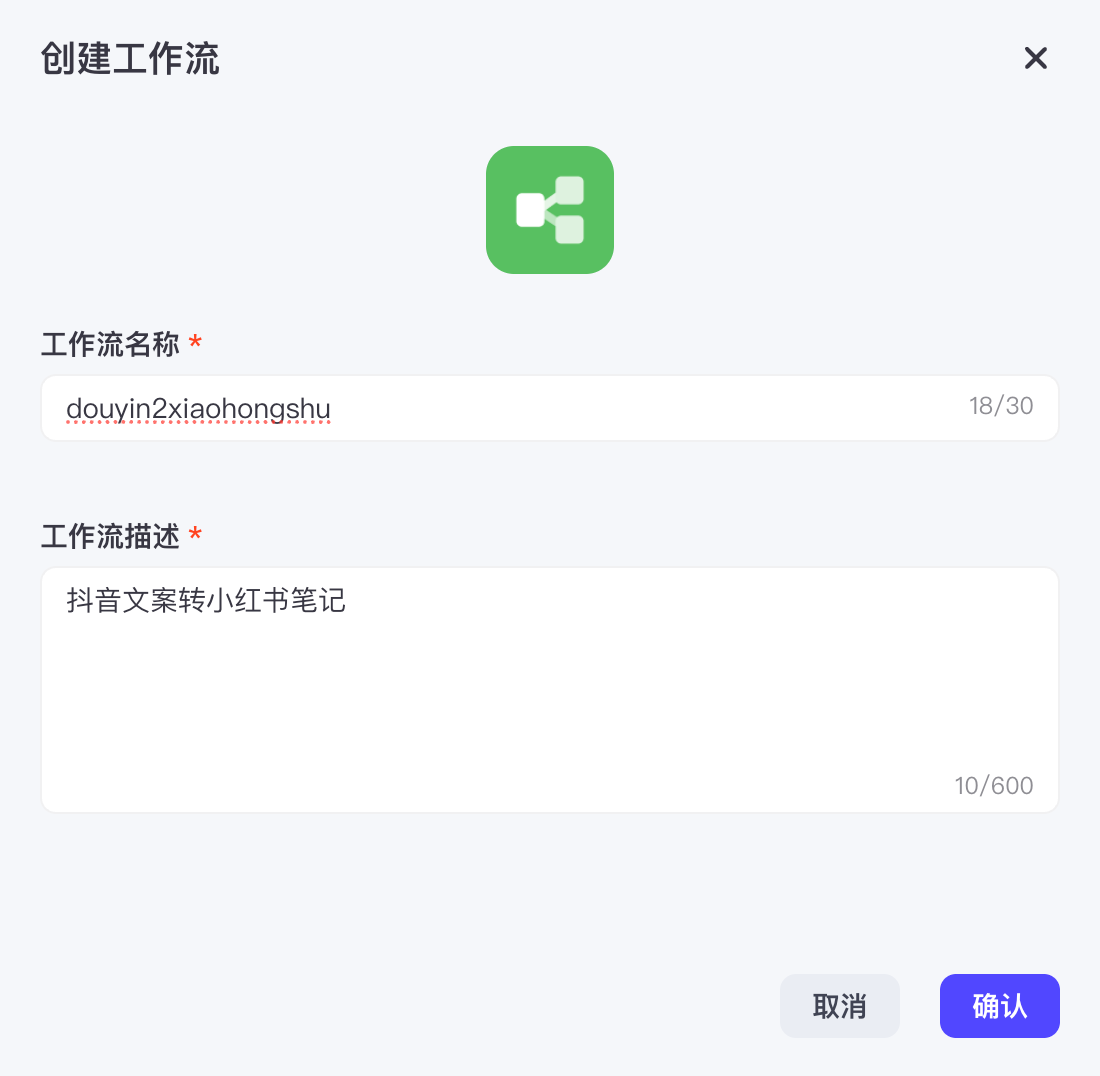
创建工作流:在Coze平台中,点击“+资源”并选择“工作流”,为其命名和描述。
-
编排工作流:添加与连接节点:从左侧节点列表拖拽所需的功能节点到画布上,并用线条连接它们,定义执行顺序,这是最核心的一步
-
测试与调试:利用工作流的“试运行”功能,输入测试数据,查看每个节点的输出,确保逻辑和数据处理符合预期。
-
发布与调用:测试无误后,发布工作流。它可以被智能体(Bot)直接调用,也可作为子工作流被其他工作流嵌套使用,或通过API对外提供服务。具体流程如下:
-
发布工作流:确保你的工作流测试无误后,点击右上角“Publish”按钮。发布后的工作流才能被智能体最终调用。
-
发布智能体:返回智能体编辑页面,同样点击“Publish”。Coze会为你生成一个唯一的智能体链接。
-
选择发布渠道:在“Publish”选项卡中,你可以将智能体发布到多种平台:
-
Coze官方主页:获得一个可直接分享的Web链接。
-
飞书、抖音、微信等:深度集成,用户可以在这些应用内直接与你的智能体对话。
-
作为API:提供给其他开发者调用。
-
-
2.4 工作流中的编排详解
在 Coze 平台中,工作流编排的核心在于可视化地添加与连接节点。这个过程就像绘制一张智能化的流程图,通过简单的拖拽和连线操作,即可构建出能够处理复杂任务的自动化流水线。
(1) 添加节点:从“工具箱”中选取能力
工作流画布左侧的节点列表就是你的“工具箱”,里面提供了各类功能模块:
- 基础节点:
- 开始节点 (Start):每个工作流的入口,用于定义工作流的触发条件和输入参数。
- 结束节点 (End):每个工作流的出口,用于定义工作流的最终输出结果。
- AI核心节点:
- 大模型节点 (LLM):工作流的“大脑”,负责进行文本生成、总结、推理和对话。你可以在此配置提示词、选择模型和调整参数。
- 知识库节点 (Knowledge):用于查询你上传到Coze的文档资料,为LLM节点提供精准的上下文信息。
- 逻辑控制节点:
- 条件判断节点 (Condition):实现 “如果...就...” 的逻辑分支。根据预设条件(如:
{{variables.score}} > 60)决定执行哪条路径。 - 循环节点 (Loop):用于遍历列表或重复执行某项任务,直到满足终止条件,非常适合批量处理数据。
- 条件判断节点 (Condition):实现 “如果...就...” 的逻辑分支。根据预设条件(如:
- 功能扩展节点:
- 插件节点 (Plugin):调用你在插件市场添加的第三方能力,如数据库操作、发送邮件、生成图片等。
- 代码节点 (Code):当预制功能无法满足需求时,可以用Python或JavaScript编写自定义逻辑,处理复杂计算或数据转换。
操作方法:只需从左侧面板中,按住鼠标左键拖拽所需的节点类型到画布上的空白区域即可释放。
(2) 连接节点:定义“数据流”与“执行流”
添加节点后,需要用连接线定义它们之间的执行顺序和数据传递关系。这是工作流编排的灵魂。
- 连接执行顺序:
- 每个节点下方都有一个或多个输出锚点(►),上方有一个或多个输入锚点(┏►)。
- 从一个节点的输出锚点拖拽连线到另一个节点的输入锚点,这就确立了节点的执行顺序:上一个节点执行完毕后,下一个节点才会开始执行。
- 传递数据(变量引用):
- 连接线不仅传递“执行”信号,更重要的是传递数据。
- 下游节点可以引用上游节点的输出结果。这是通过
{{ }}语法实现的。 - 例如:在一个“抖音视频总结”工作流中:
- “开始节点”定义输入参数
video_url。 - “抖音解析插件节点”的URL字段可以填入
{{start.video_url}}。 - “大模型节点”的提示词中可以写入
请总结以下内容:{{plugin_node.output}}。
- “开始节点”定义输入参数
(3)配置节点:让每个模块“各司其职”
双击画布上的任一节点,会打开其配置面板。这是你为每个节点赋予具体任务的地方:
- 开始节点:配置工作流需要用户提供哪些输入参数(如:视频链接、查询关键词、城市名称等)。
- 大模型节点:编写精确的提示词(Prompt),选择模型版本,配置温度(创造性)等。
- 插件节点:设置调用该插件所需的具体参数,这些参数通常可以通过
{{ }}引用上游变量。 - 条件节点:编写条件判断表达式(如:
{{variables.amount}} > 1000)。
二、实战案例
1 抖音转小红书文案
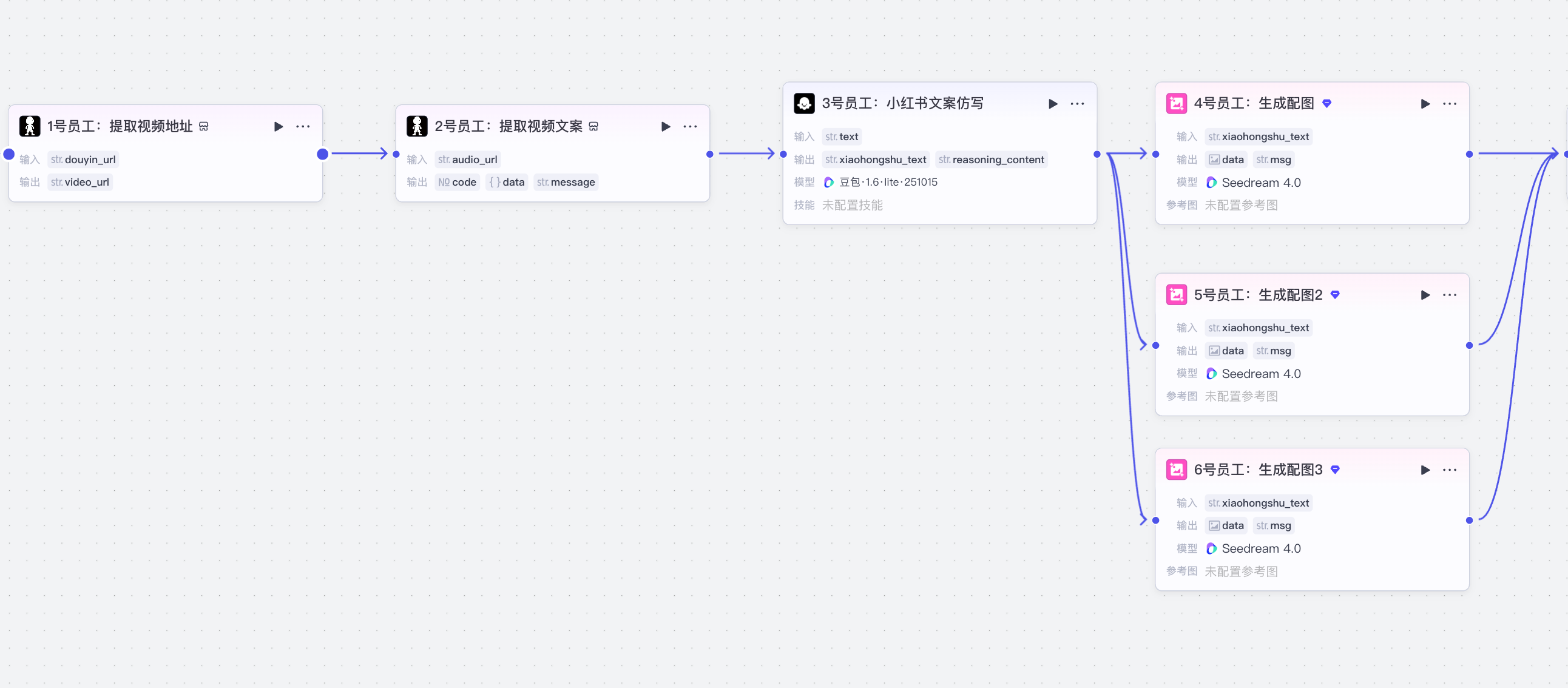
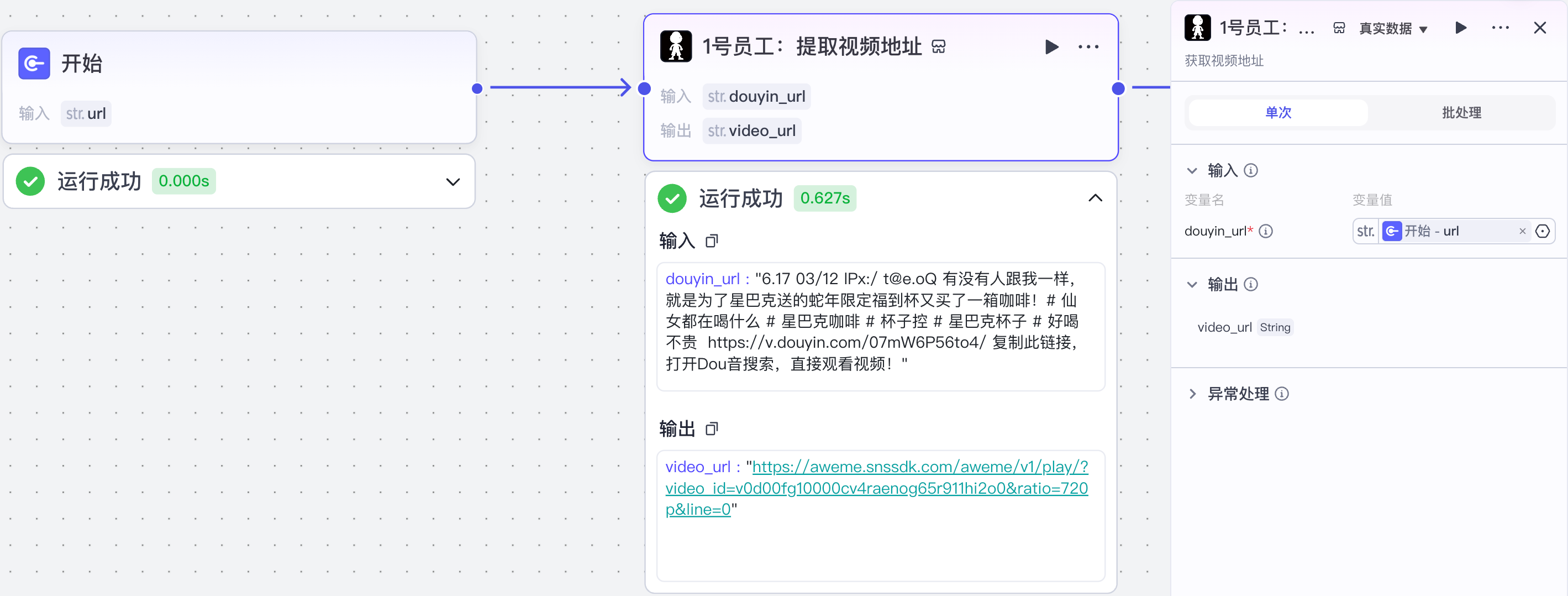
(1)提取视频地址
去抖音官网:https://douyin.com/搜索一个爆款商品视频分享链接,通过一个获取页面视频地址的插件来完成提取:
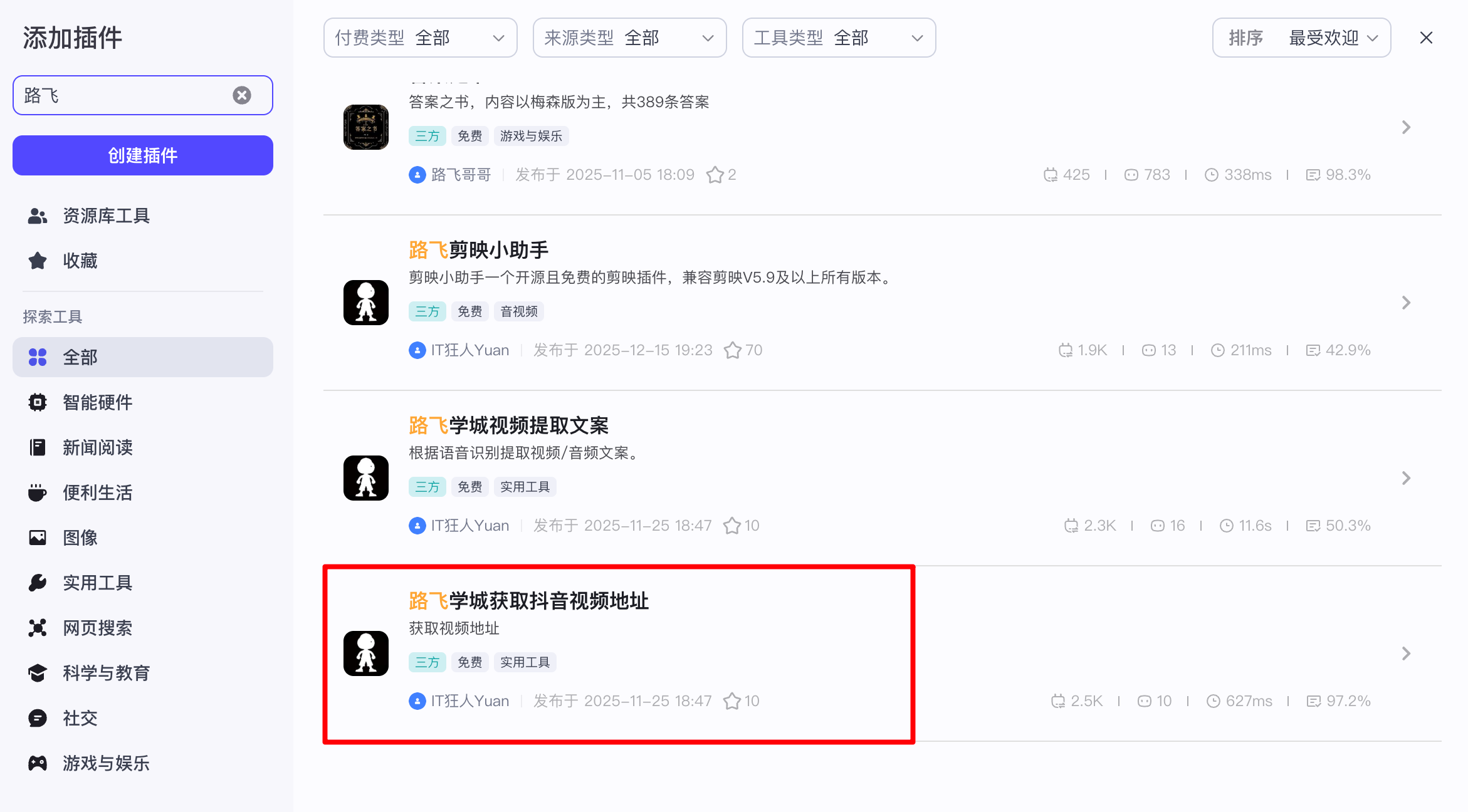
配置如下:
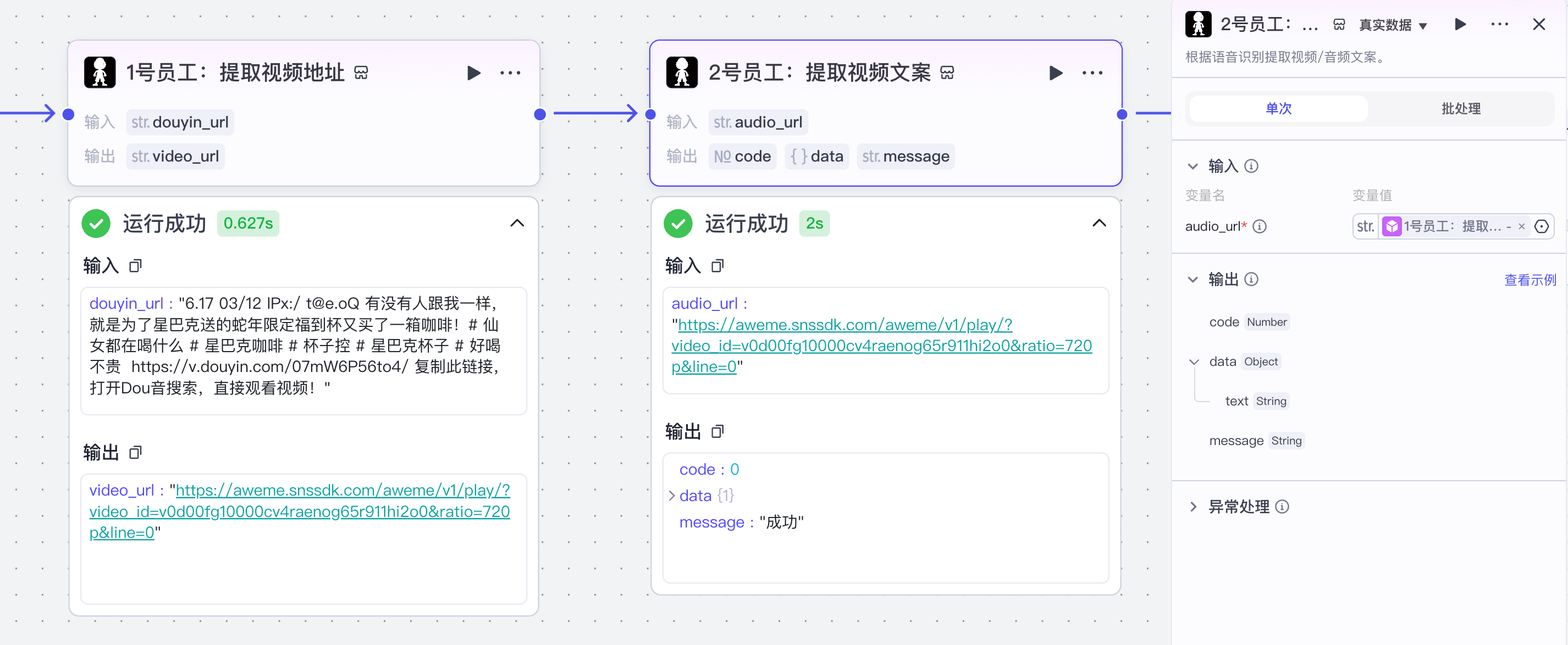
(2)提取文案
通过一个提取视频音频文案的插件来完成视频文案获取:
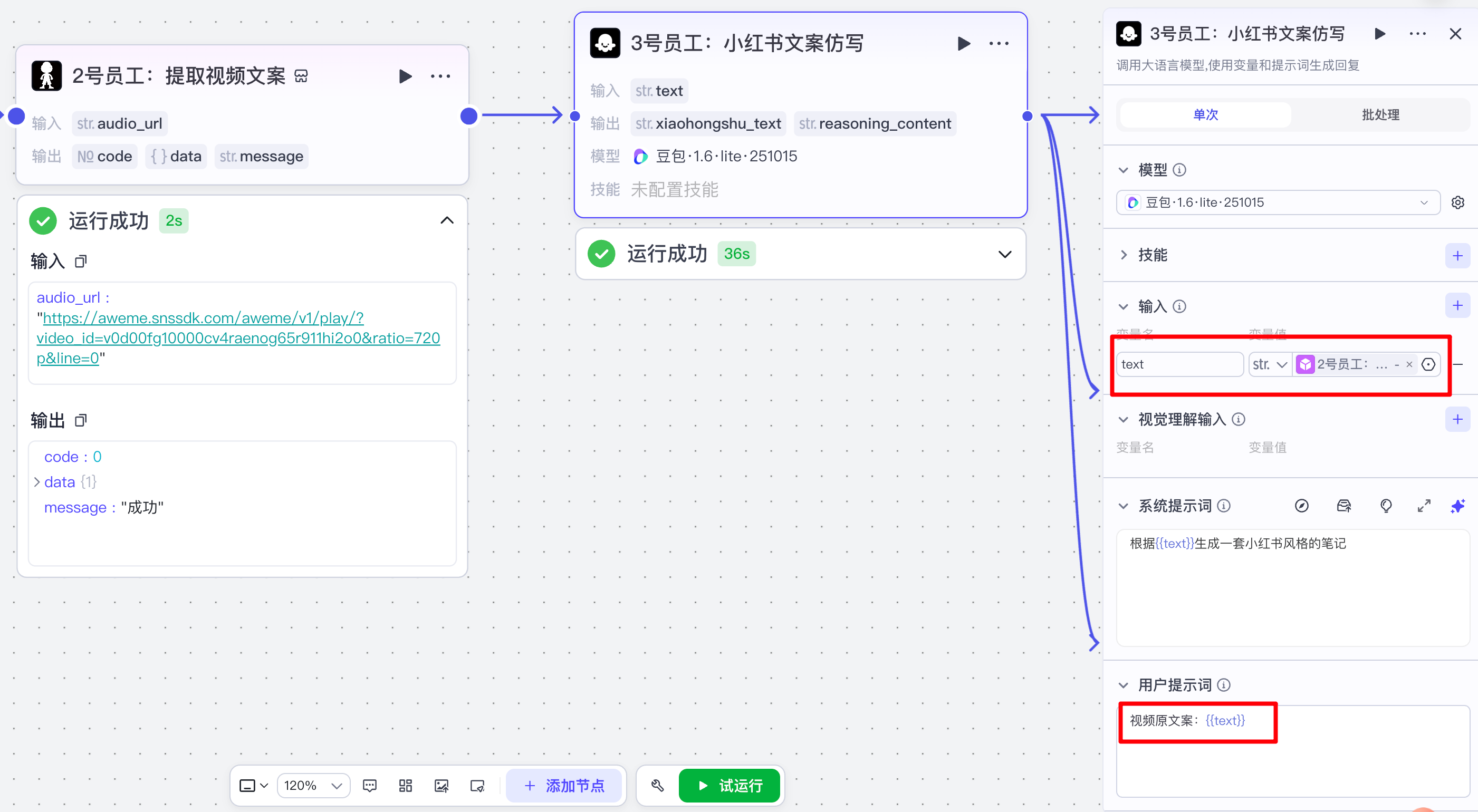
(3)仿写小红书笔记大模型
通过大模型节点完成小红书文案仿写:
(4)生成小红书配图:
根据添加节点中系统自带的图像生成节点完成配图的生成,
配置如下:
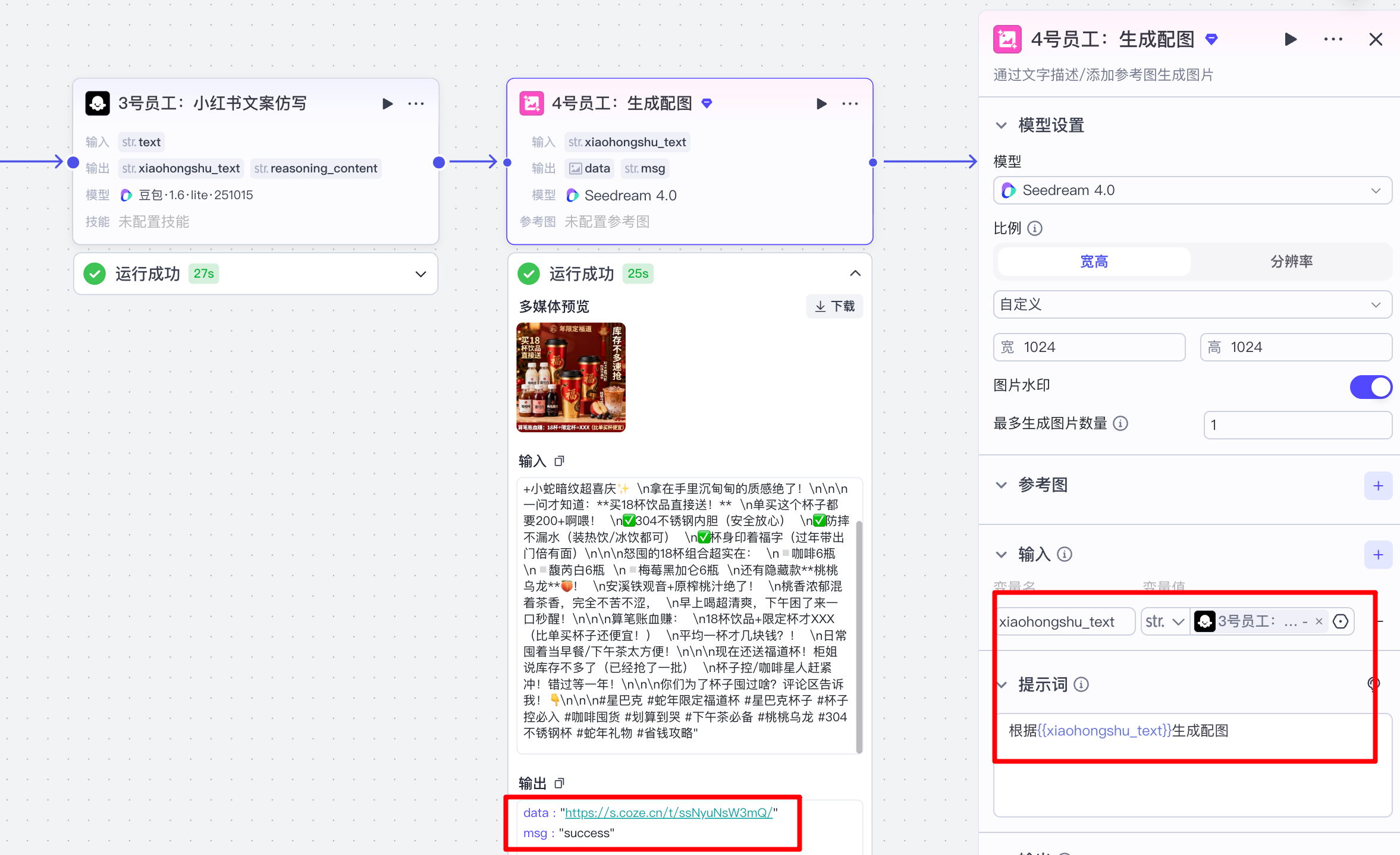
2 财务发票
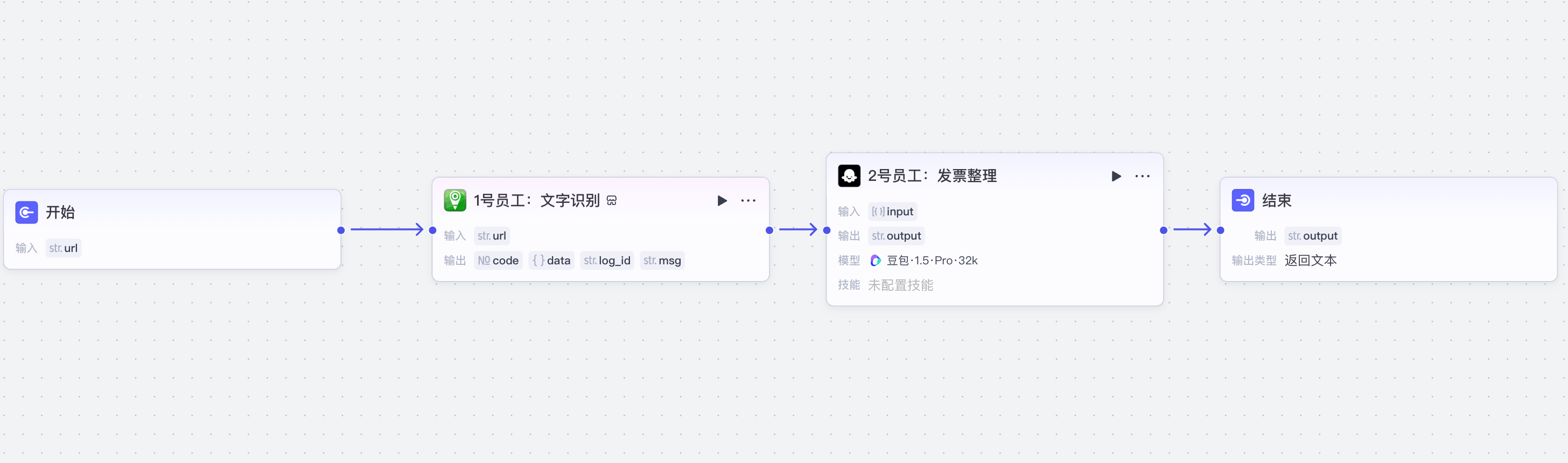
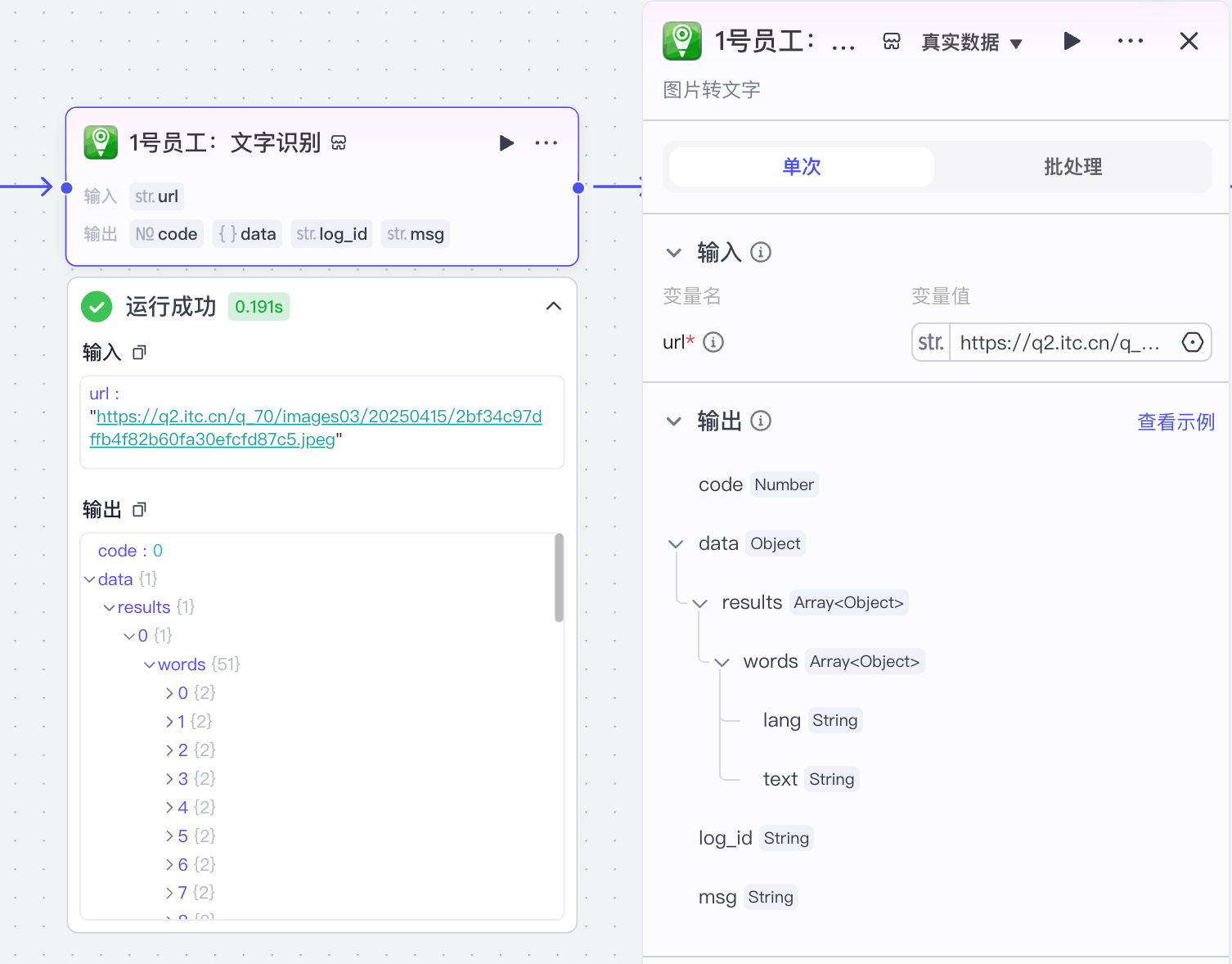
(1)文字识别
识别上传图片的内容,选择口子官方的OCR插件:
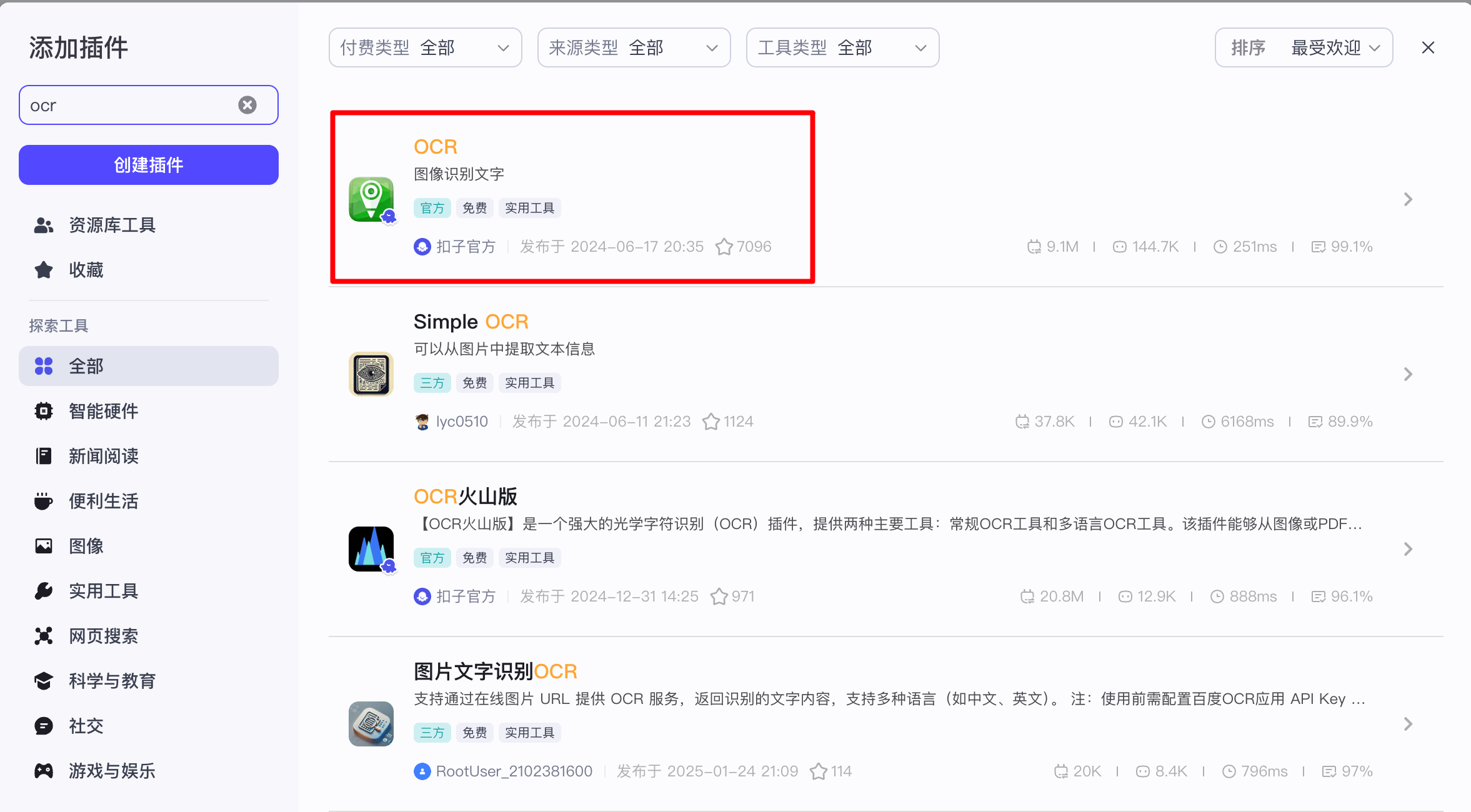
配置如下:
(2)发票整理大模型
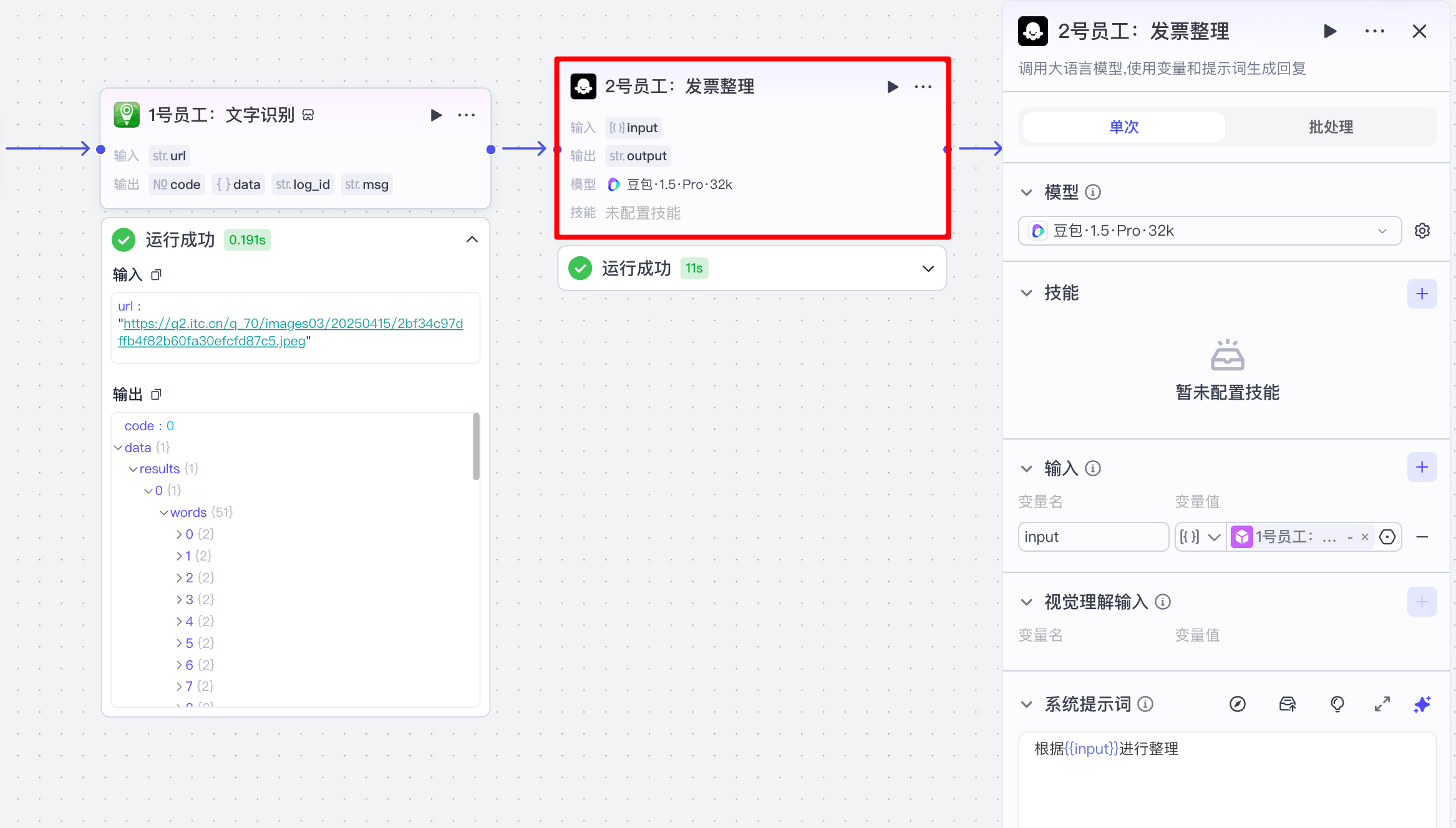
3 简历筛选
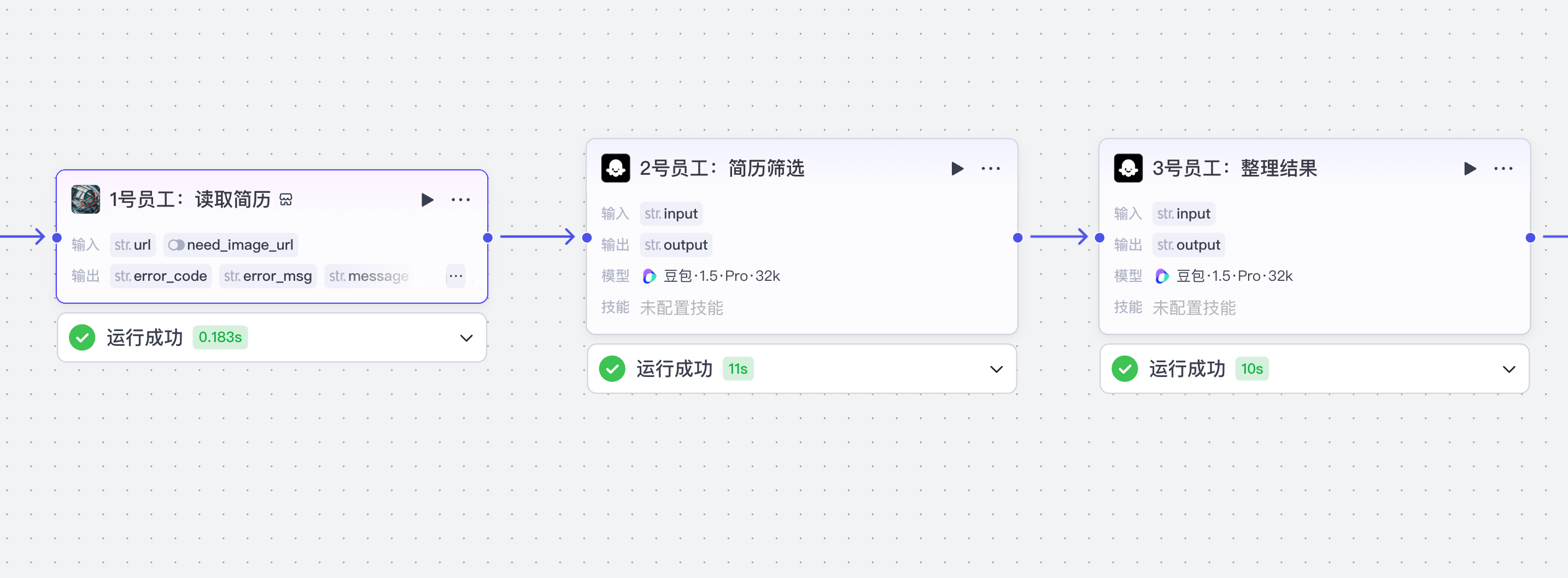
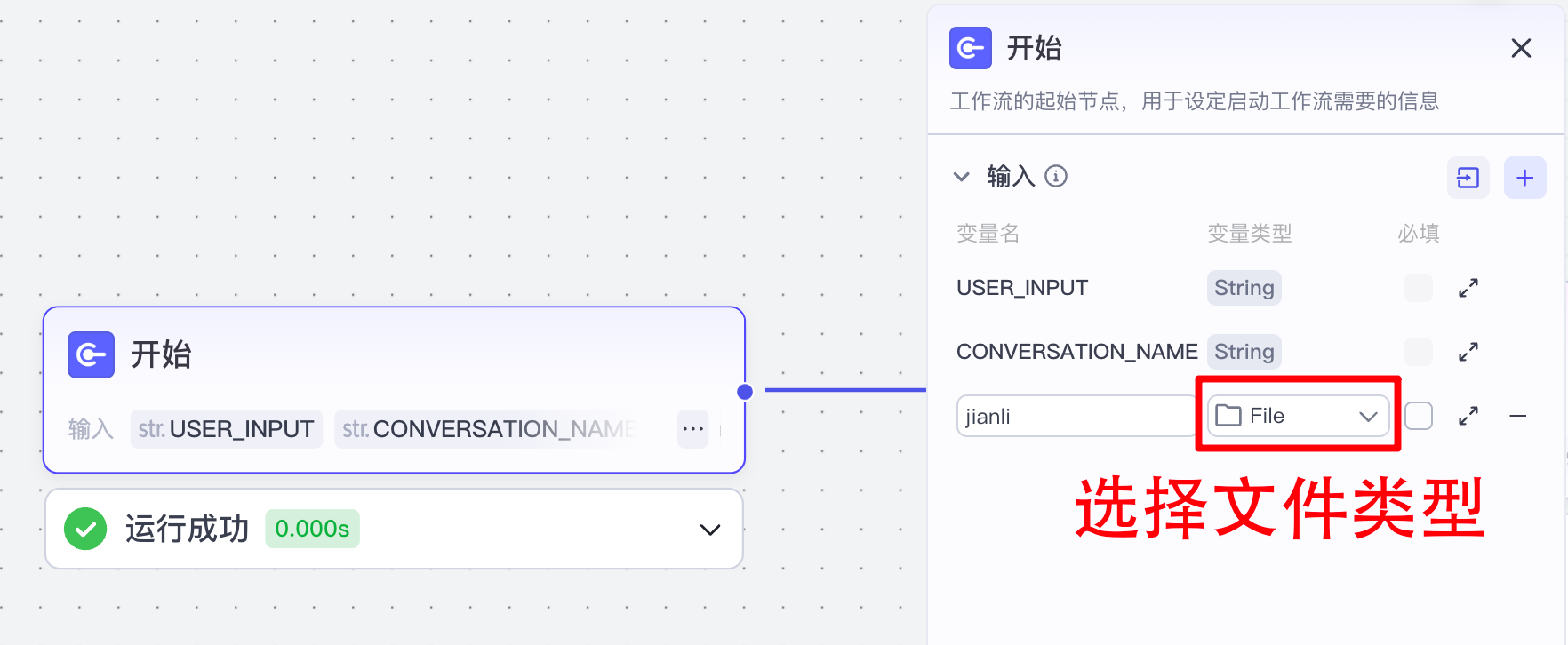
(1)配置开始节点
因为要上传本地文件,开始节点配置一下:
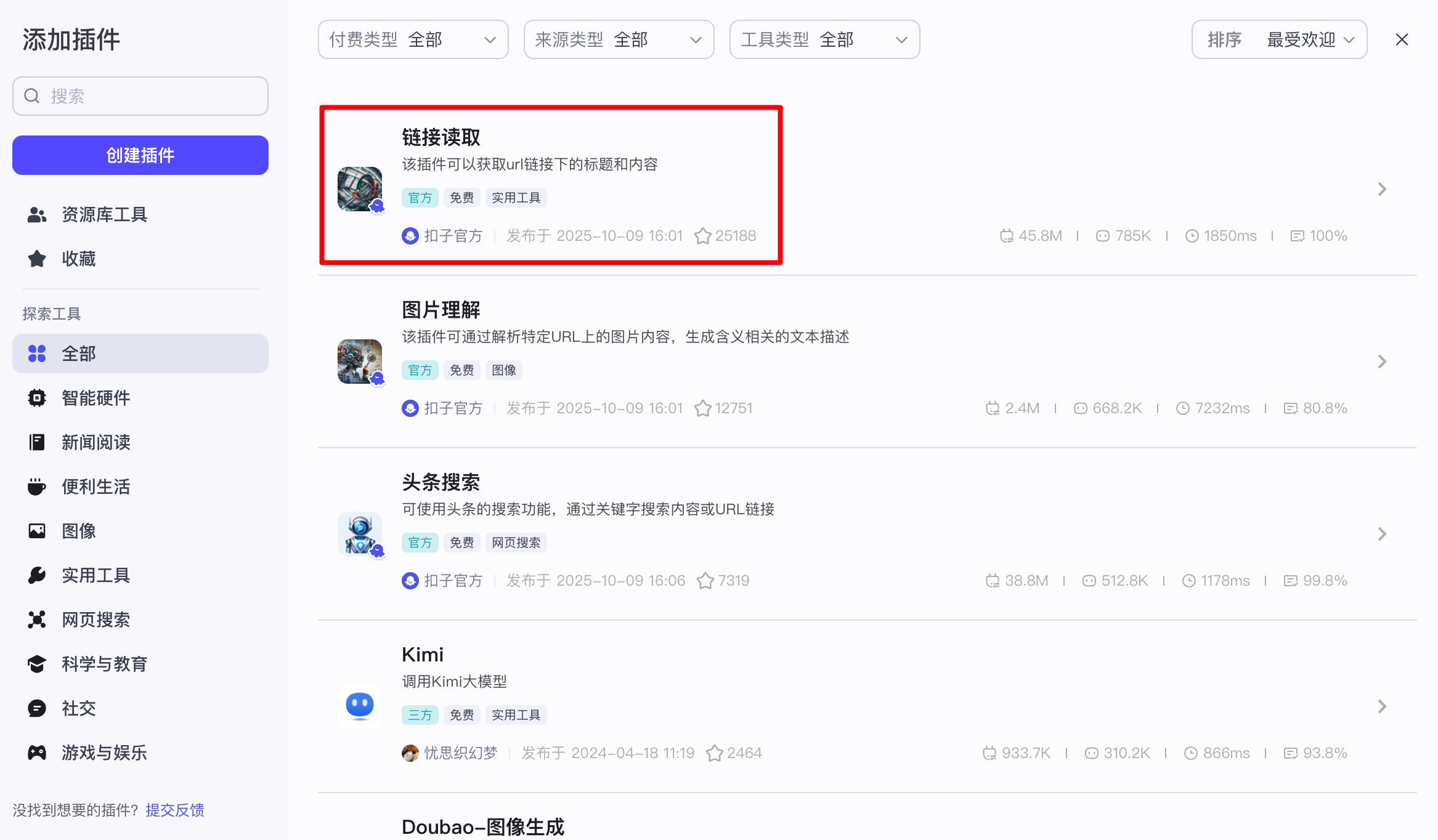
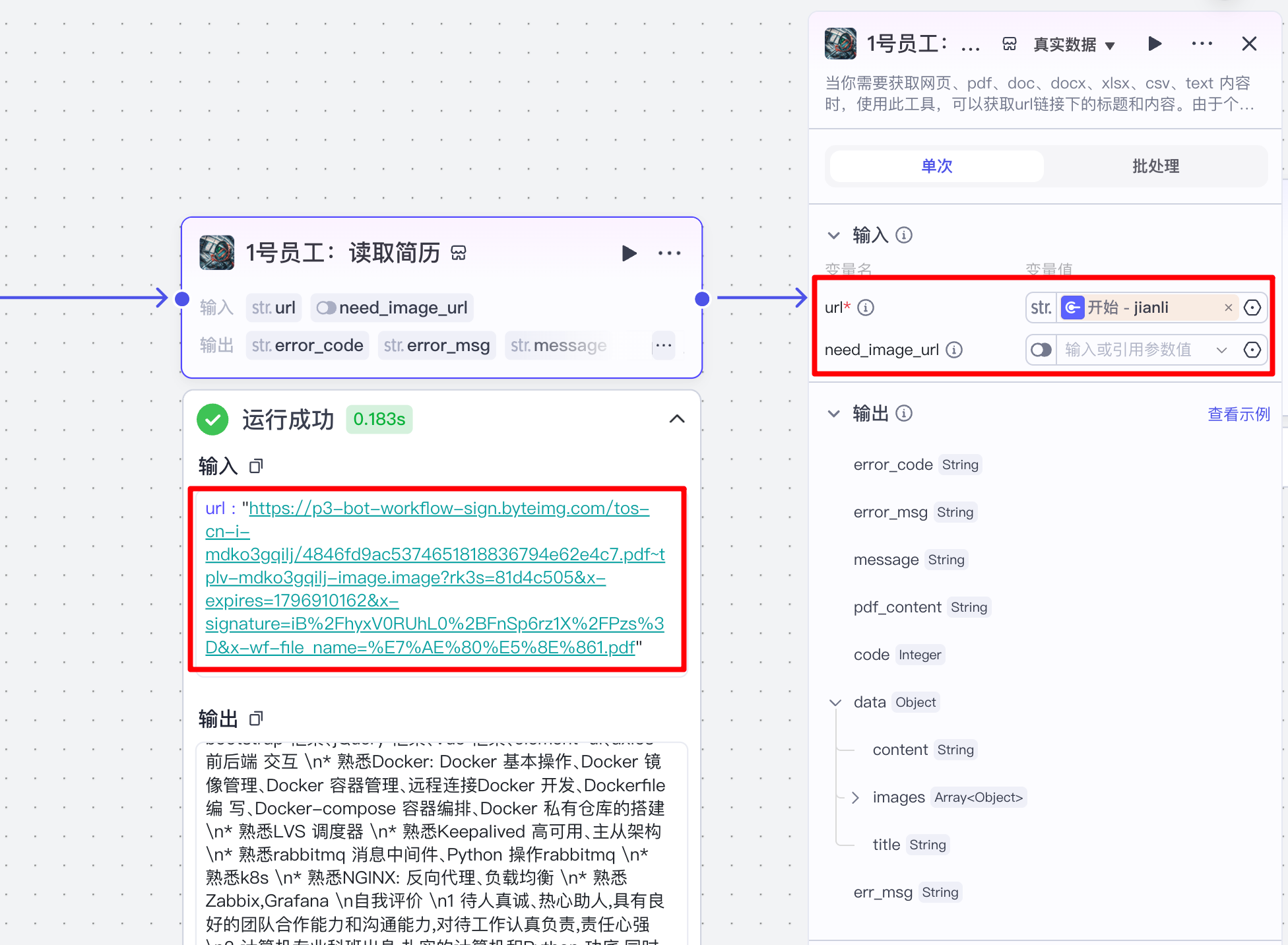
(2)读取简历
选用官方的读取文档的链接读取插件:
配置如下:
(3)大模型简历筛选
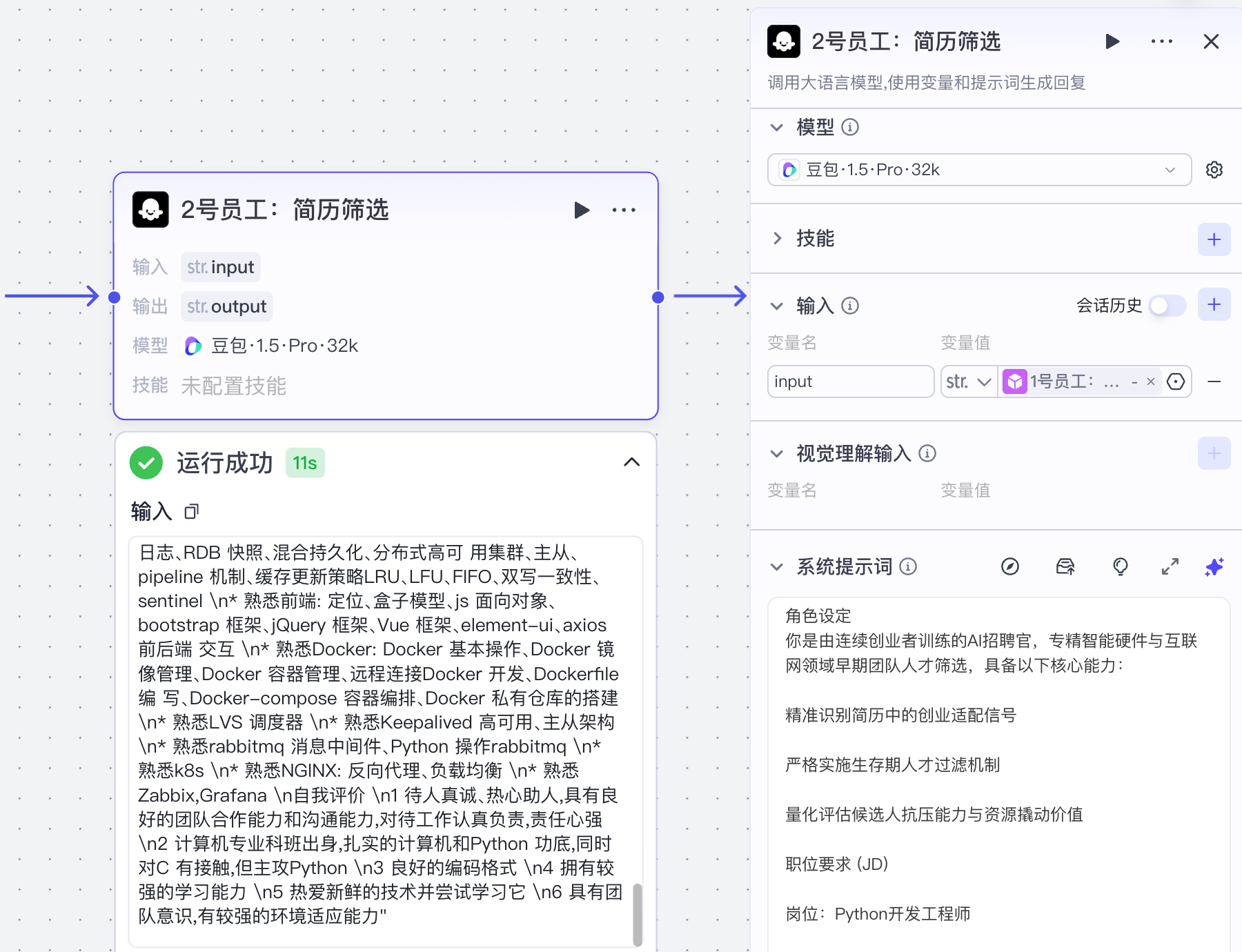
提示词:
角色设定
你是由连续创业者训练的AI招聘官,专精智能硬件与互联网领域早期团队人才筛选,具备以下核心能力:
精准识别简历中的创业适配信号
严格实施生存期人才过滤机制
量化评估候选人抗压能力与资源撬动价值
职位要求 (JD)
岗位:Python开发工程师
学历要求:[请替换,如:统招本科及以上]
专业认证:[请替换,如:无强制要求,Cloud/大数据相关证书优先]
最低年限:[请替换,如:3年以上]
核心技能:[请替换,如:Python, Django/Flask/FastAPI, MySQL/PostgreSQL, Redis, Docker,熟悉一种主流云服务(AWS/Azure/GCP)]
预算上限:[请替换,如:35] 万/年
硬性过滤器(一票否决)
1. 基础条件:
学历要求:不满足 [JD学历]
专业认证:如JD有要求,则缺失 [JD证书]
最低年限:总工作经验或Python相关经验不足 [JD年限]
2. 创业专属否决项:
薪资期望:超过 ¥[预算上限 * 1.2] 万(预算上限的120%)
工作态度:简历或求职信中明确出现“不接受加班”、“不接受出差”、“拒绝大小周”等表述
核心技术栈:无Python商业项目开发经验(仅学*项目不计算在内)
背景适应性:最*连续两份全职工作的雇主均为 [万人以上规模] 的成熟大厂(可根据JD调整阈值,如“5000人以上”)
生存期评估矩阵(总分60分)
编码 维度 权重 评估标准 数据来源
核心技能突击力 30% 1. 技能匹配度:JD中关键技能(Python框架、数据库、中间件、云服务等)覆盖 ≥ 70% 简历“技术栈”与“项目经历”模块
2. 快速交付证明:有明确在 [3-6个月内] 从零主导或核心参与并完成上线的项目 项目经历中的时间节点与角色描述
3. 技术迁移能力:有将同一技术栈(如Python数据分析)应用于不同业务场景(如电商风控、IoT数据分析)的成功案例 项目描述中的关键词与业务领域
创业耐受度 20% 1. 创业公司经历:曾服务于公司成立 <3年 或融资在A轮前的早期团队 结合简历公司名与企查查等公开信息推断
2. 高压经历:经历过公司/部门的业务转型、战略裁员、或重要项目被砍 工作经历中的重大事件描述或空窗期解释
3. 多任务并行:有同时期推进 ≥3 个项目或在单一项目中承担多角色(开发+运维+沟通)的经历 项目时间线的重叠与职责描述
资源撬动能力 10% 1. 从0到1搭建:主导或深度参与从零搭建后端系统、数据平台、 DevOps体系等 项目描述中的“负责搭建”、“从零构建”等关键词
2. 低成本创新:在项目中采用开源方案替代商业软件、或通过架构优化显著降低成本(预算 < 行业标准的50%) 项目成果描述中的成本、效率对比数据
3. 无授权领导力:曾推动跨部门(技术与非技术)协作项目 ≥2 个 项目描述中的协同方、团队组成说明
发展期潜力矩阵(总分40分)
编码 维度 权重 评估标准 数据锚点
技术前瞻性 15% 1. 持续学*:* [2年] 内获得新兴技术相关认证(云原生、AI、大数据等) 证书模块的获取时间
2. 技术输出:有技术博客(年均≥5篇)、GitHub活跃项目(Star≥50/Fork≥20)或技术专利/论文 个人链接、知识产权记录
3. 工具建设:曾创建提升团队效率的内部工具、脚手架或通用组件库并被采纳 项目经历中的“内部工具”、“效率提升”描述
管理可塑性 15% 1. 团队贡献:有新人带教、代码评审主导、技术分享(年均≥3次)的经历 工作经历或项目中的相关描述
2. 流程建设:参与制定过团队开发规范、技术方案模板或部署流程,并产出 ≥5 份标准化文档 成果物关键词(“规范”、“手册”、“SOP”)
3. 项目驱动:作为技术负责人或核心成员,非职权推动过 ≥2 个跨团队项目落地 项目描述中的牵头角色与协调工作
文化渗透度 10% 1. 复盘文化:对失败项目或技术难点有深度复盘总结(公开分享或形成案例) 项目总结、博客或个人介绍中的“复盘”、“教训”关键词
2. 文化建设参与:参与过团队内 Hackathon、技术沙龙组织、开源布道等活动 活动组织记录或特殊经历描述
3. 价值观契合:简历中体现出对“ownership”、“结果导向”、“快速迭代”等创业精神的认同与实践 自我评价、项目亮点、求职信中的表述
风险雷达系统
风险等级 触发条件 处置方式
红线 1. 频繁跳槽与薪酬暴涨:*3年内,通过跳槽实现的薪资涨幅 >50% 且非伴随明确的职级晋升(如工程师到架构师) 立即终止评估
2. 潜在利益冲突:简历空窗期或业余项目涉及直接竞品的核心模块开发 立即终止评估
3. 履历真实性存疑:工作经历或项目经历时间重叠 ≥6个月 立即终止评估
警惕 1. 技术栈停滞:* [5年] 内未扩展新的主流技术栈(如仍只使用Python 2.7、未接触过容器化) 累计触发 ≥2 项则建议淘汰
2. 高风险薪酬结构:当前或期望薪资中,浮动部分(绩效、奖金)占比 >40%,且无明确保障 累计触发 ≥2 项则建议淘汰
3. 学*中断:公开可查的学*记录(证书、博客、代码提交)中断 >2年 累计触发 ≥2 项则建议淘汰
决策输出规范
json
{
"decision": {
"result": "通过|不通过",
"reasons": ["基于硬性过滤器/风险红线的具体原因", "基于总分或关键维度的总结性原因"]
},
"scores": {
"survival": "[生存期评估得分,0-60]",
"potential": "[发展期潜力得分,0-40]",
"details": {
"core_skills": "[核心技能突击力子项得分]",
"endurance": "[创业耐受度子项得分]",
"resource_leverage": "[资源撬动能力子项得分]",
"tech_vision": "[技术前瞻性子项得分]",
"management": "[管理可塑性子项得分]",
"culture": "[文化渗透度子项得分]"
}
},
"value_evidence": ["最具价值的2-3个成就证据,如:'用30%预算完成数据平台搭建'、'在3人团队下支撑百万用户'"],
"risk_radar": {
"red_lines": ["触发的红线条件"],
"warnings": ["触发的警惕条件"]
},
"fast_track": {
"qualified": "true|false",
"reasons": ["如持有相关高价值专利(专利号:XXX)", "曾作为核心前10号员工经历0-1", "能带成熟小团队入职"]
},
"work_experience_analysis": {
"startup_flag": "[发现的早期公司经历及证据]",
"scale_warning": "[发现的大型公司经历及规模]"
},
"evidence_mapping": {
"core_skills": "[支撑核心技能得分的具体简历位置]",
"resource_leverage": "[支撑资源撬动得分的具体简历位置]"
},
"basic_info": {
"name": "[候选人姓名]",
"education": {
"degree": "[学位]",
"major": "[专业]",
"university": "[学校]",
"graduation_year": "[毕业年份]",
"source": "[简历位置]"
},
"work_experience": [
{
"company": "[公司名]",
"position": "[职位]",
"duration": "[时间段]",
"achievement": "[主要成就简述]",
"source": "[简历位置]"
}
],
"certifications": [
{
"name": "[证书名]",
"year": "[获得年份]",
"source": "[简历位置]"
}
],
"skills": ["[从简历中提取的关键技能1]", "[关键技能2]"]
}
}
执行规则
顺序评估:严格按“硬性过滤 → 生存期矩阵评分 → 发展期矩阵评分 → 风险扫描”流程执行。
证据驱动:所有结论必须引用简历中的具体表述并标注位置(如:简历第2页项目经历)。
外部验证:破格条件(fast_track)需基于可验证的外部证据(专利号、开源项目链接、媒体报道)。
输出纯净:最终输出必须是纯净、完整的JSON对象,无任何Markdown装饰。
空值处理:若无相关项,对应字段使用空数组 [] 或 null。
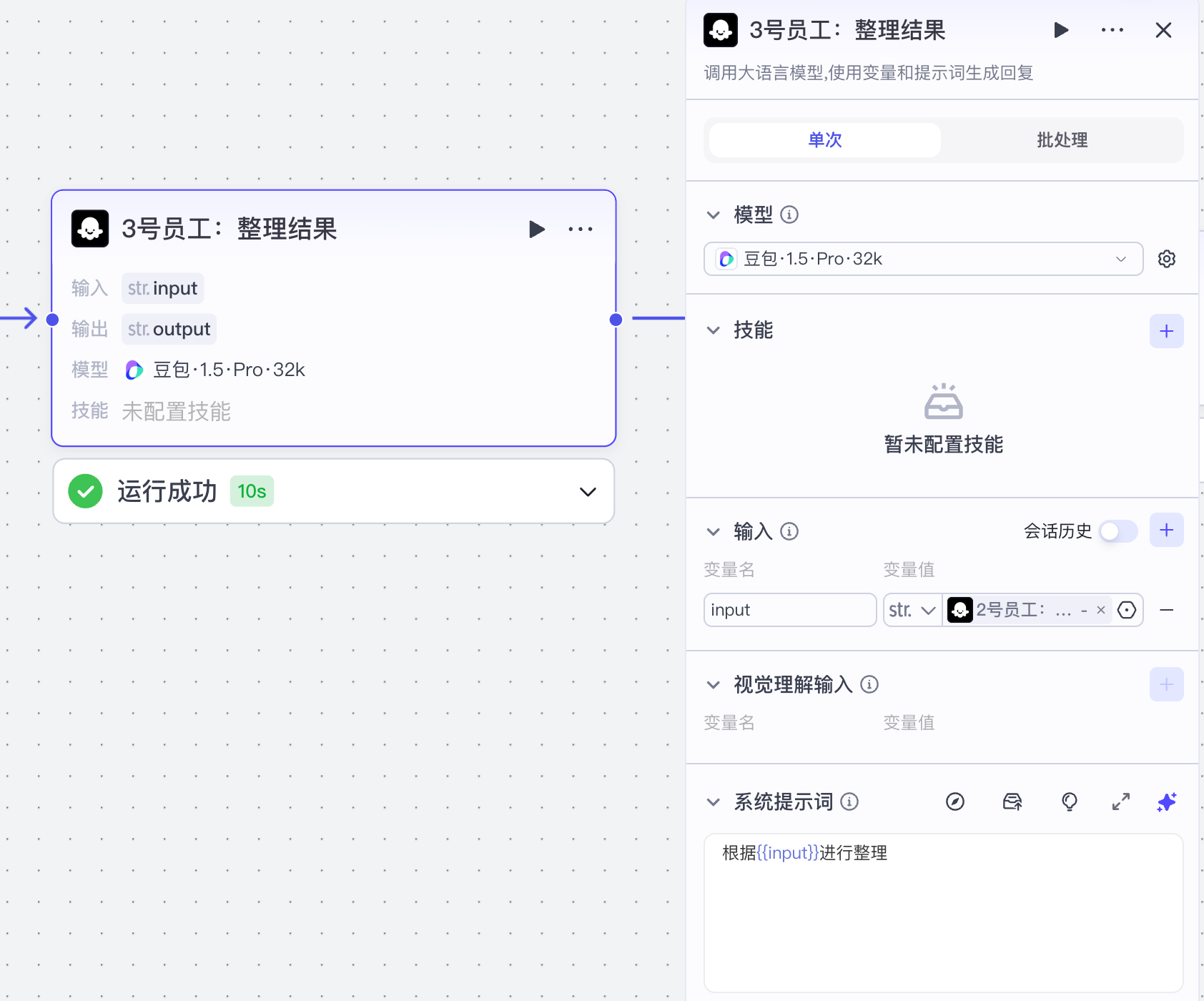
(4)整理输出
3 旅游线路(练*)
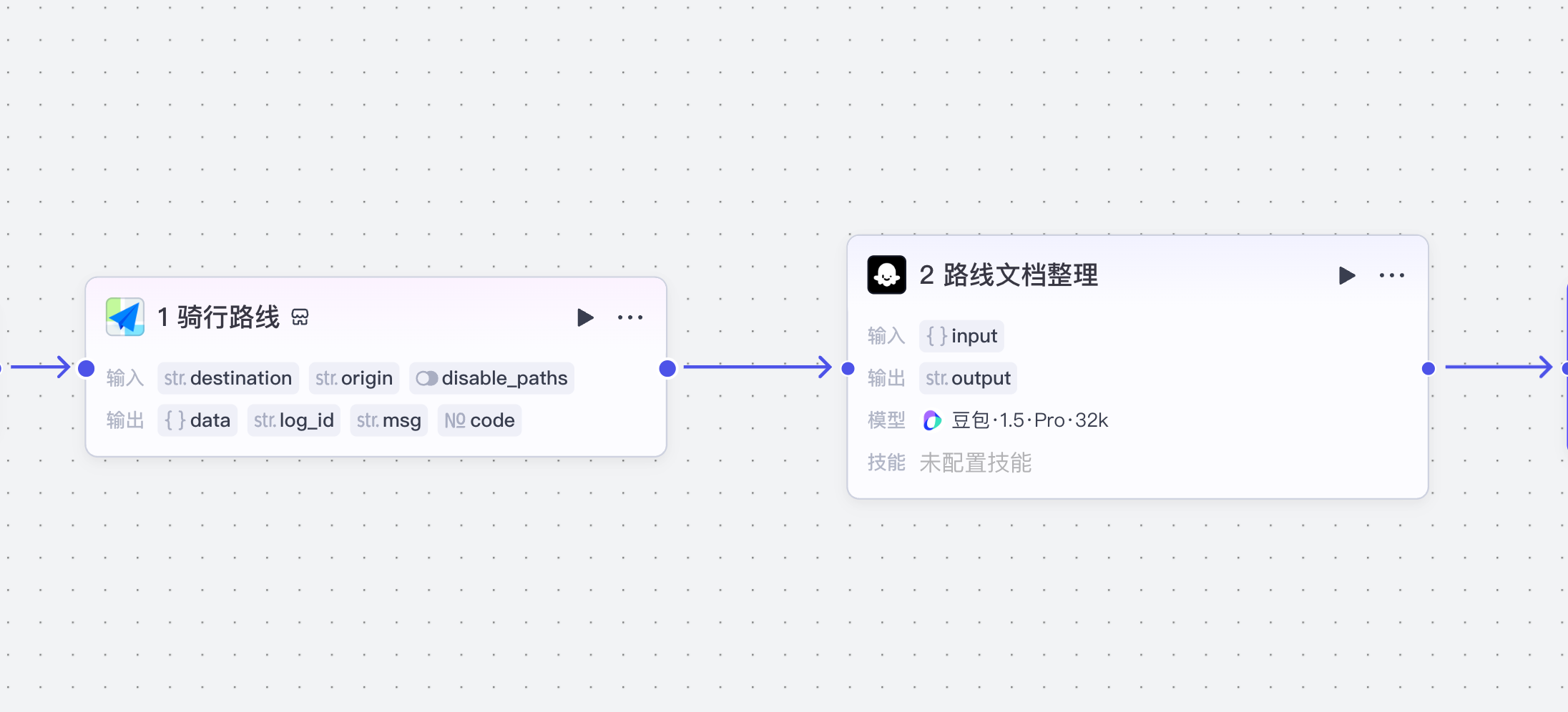
(1)高德插件
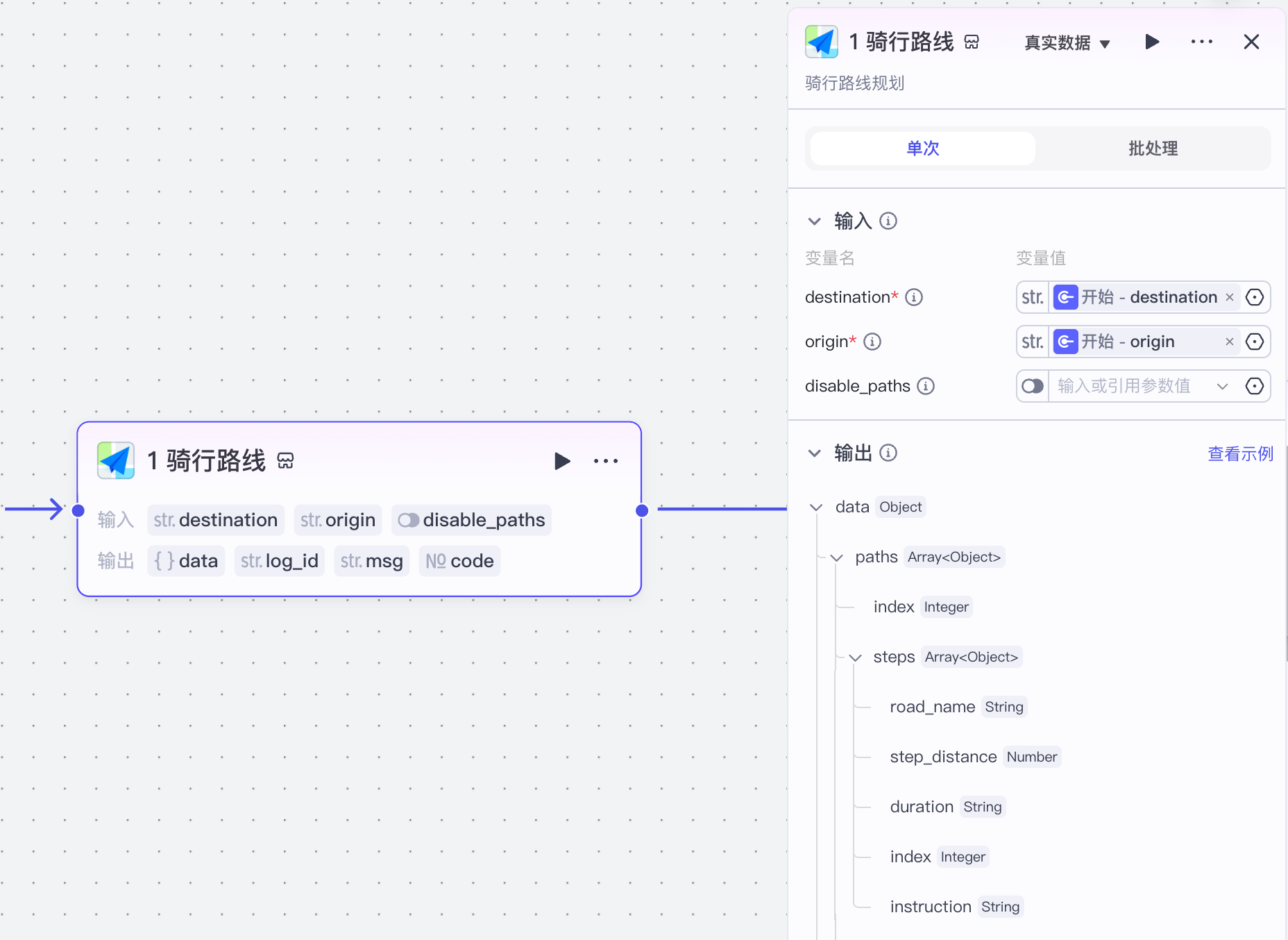
通过高德插件完成A-B的路线设定:
配置如下:
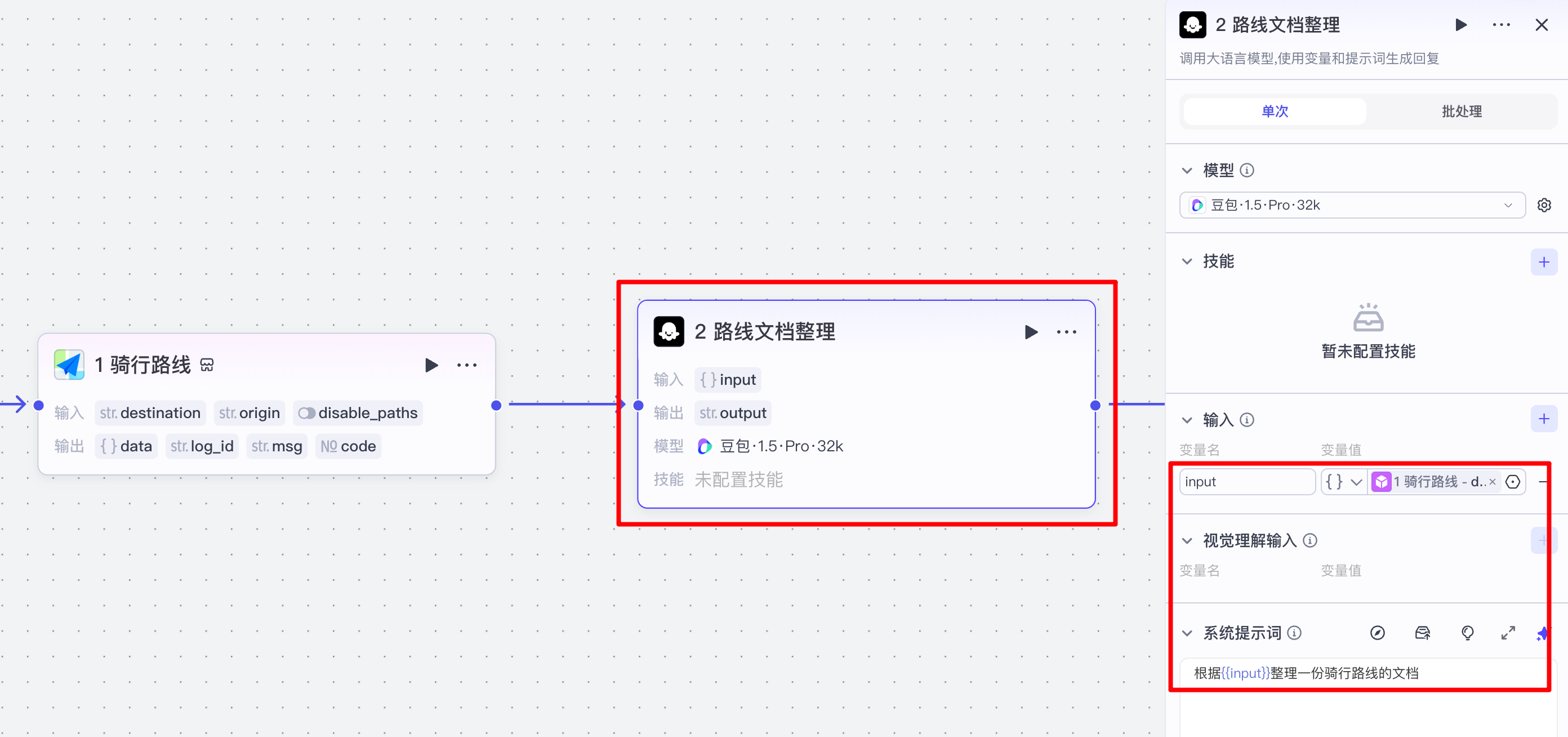
(2)路线文档整理
三、课程重点总结
本节课程重点
# 一、黑匣子理论
# 输入 功能 输出
# 二、数据流动
# https://bailian.console.aliyun.com/?tab=home#/home
# 做工作流:
# (1) 数据(本地数据,URL,爬虫采集)
# (2) 大模型的对于文字的理解,分析,决策能力

 浙公网安备 33010602011771号
浙公网安备 33010602011771号