day32-多模态RAG
多模态RAG理论篇
一、技术回顾
1.RAG
RAG,Retrieval-Augmented Generation,也被称作检索增强生成技术,最早在 Facebook AI(Meta AI)在 2020 年发表的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》( https://arxiv.org/abs/2005.11401 )中正式提出,这种方法的核心思想是借助一些文本检索策略,让大模型每次问答前都带入相关文本,以此来改善大模型回答时的准确性。这项技术刚发布时并未引发太大关注,而伴随2022年大模型技术大爆发,RAG技术才逐渐进入人们视野,并且由于早期大模型技术应用均已“知识库问答”为主,而RAG技术是最易上手、并且上限极高的技术,因此很快就成为了大模型技术人必备的技术之一。
2.GraphRAG
GraphRAG(Graph-enhanced Retrieval-Augmented Generation) 是一种在经典 RAG 基础上引入知识图谱的新型检索生成方法 。其核心思想是通过将文档或数据转换成图的形式,从而捕捉实体与实体之间的语义关系,并在检索阶段利用图遍历、关系推理等机制来辅助上下文构建,这种结构化信息能够提升语义理解和多跳推理能力。
传统 RAG 主要是“先检索语义近似片段,再生成回答”,适合简单查询与短对话。但当问题需要“连接多个事实”“推理关系链”和“洞察上下文结构”时,传统 RAG 会显得力不从心,而 GraphRAG 正是为复杂推理场景设计的增强机制。
3.Agentic RAG
Agentic RAG(Agentic Retrieval-Augmented Generation) 是一种在传统 RAG 基础上进一步扩展的增强范式,它将检索增强生成与Agent(智能体)能力有机结合,使大模型不仅能够基于外部知识库进行回答,还能够通过一系列自主决策和工具调用来完成复杂任务。
二、RAG系统核心难题
而在众多企业级应用场景中,PDF 是最常见且最复杂的文档形式,往往同时包含文字、表格、图片、公式等多模态信息。传统的文本检索方法难以准确解析与索引这些异构内容,导致关键信息无法被有效利用。这使得多模态 PDF 检索成为 RAG 技术落地的核心难题:既要保证结构化信息的还原,又需在语义层面实现跨模态统一检索,从而支撑高质量问答与知识增强应用。
三、多模态文档检索
1.多模态RAG开发背景
在当今信息环境中,单一模态的检索已无法满足人们的需求。随着图像、视频、音频以及文本等多模态数据的高速增长与普及,知识的呈现方式不再局限于纯文本,更多地以丰富的多模态形式存在。从医学影像到工业监控,从视频课程到社交媒体,核心信息往往蕴含在多模态内容的交叉中。传统的文本检索无法充分利用这些异质信息,导致知识获取存在片面与缺失。多模态RAG(Retrieval-Augmented Generation)系统正是在这一背景下显得愈发重要。它能够跨模态整合信息,提升知识覆盖率与语义理解能力,为用户提供更准确、更全面的回答与洞察。这不仅是技术演进的趋势,更是应对现实复杂信息环境的必然选择。
多模态文档样例
-
风景图

-
表格

-
流程图
-
latex公式
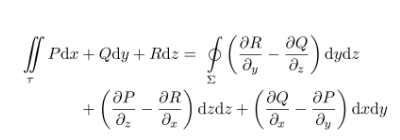
-
论文图表
2.多模态开发核心环节
在构建多模态RAG系统的过程中,通常需要经过四个核心步骤。
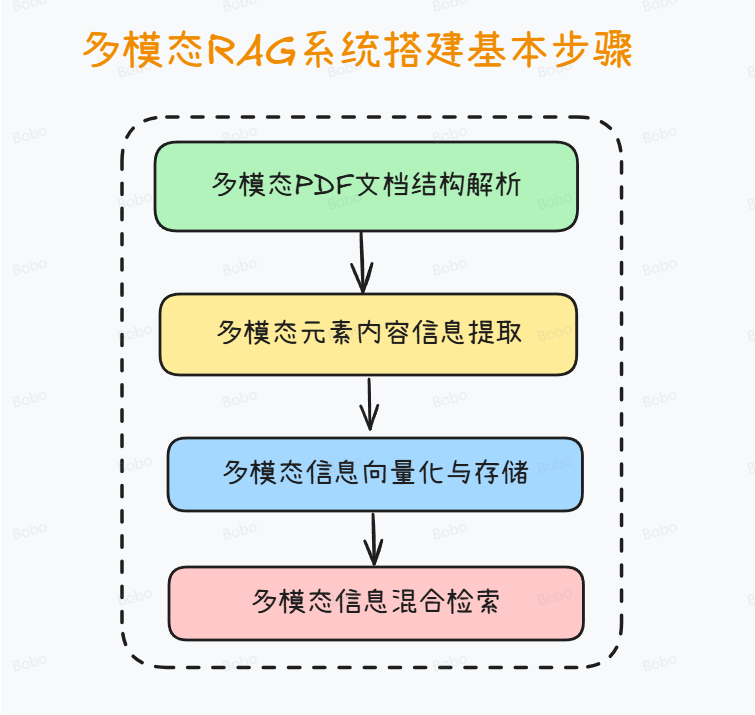
首先是文档解析,即将原始的多模态资料(如PDF、视频、音频、图像等)进行结构化处理,确保不同格式的数据能够被系统统一理解和管理。
其次是多模态内容信息提取,在这一环节中,借助OCR(光学字符识别)、语音识别、图像标注等技术,将文本、语音、视觉要素转化为可计算的中间表示,从而捕捉潜在的知识点与语义线索。
第三步是多模态信息向量化与存储,通过预训练的跨模态嵌入模型,将不同模态的内容映射到同一语义空间,并结合向量数据库进行高效存储和索引。
最后是多模态信息检索方法,在实际应用中通过语义检索、跨模态对齐与重排序等策略,快速定位与用户问题最相关的内容,并将结果交由生成模型进行增强式回答。这一流程既保证了信息处理的系统性,又奠定了多模态RAG在复杂任务中提供精准洞察的基础。
3.多模态检索核心思路
在多模态RAG系统的实践中,将PDF等复杂文档转化为Markdown格式后再进行检索,已成为一种通用且高效的做法。原因在于,PDF本身是一种排版与展示导向的格式,内部结构常常包含大量冗余信息、复杂布局和非线性内容(如表格、脚注、分页元素等),这使得直接检索难以保证准确性和一致性。
而Markdown则提供了一种轻量级的结构化表达方式,能够在保持文档层级、段落与语义逻辑的同时,大幅简化格式复杂度。通过这一转换,文本信息被规整化,图像、表格等多模态元素也能以引用或标记的方式统一嵌入,进而更便于向量化处理与跨模态检索。换言之,Markdown既保留了信息的结构完整性,又为后续多模态信息抽取与语义检索奠定了清晰的基础,从而提升了整个RAG系统的稳定性与可扩展性。
4.多模态文档结构解析
在围绕多模态文档进行检索的过程中,首先需要围绕多模态文档中的多模态元素进行精准的识别。在实际的多模态文档检索过程中,单纯依靠文本层面的分词与索引往往难以满足需求,因为PDF、扫描件等文档通常包含复杂的 版面结构。因此,必须引入 文档结构化解析 作为关键步骤。例如实现如下流程:

整体而言,文档解析可分为以下几个层面:
- 版面区域划分(Layout Analysis) 首先需要对页面进行几何级别的分区,将文档中的 标题、正文、表格、图像、脚注、页眉页脚 等区域进行标注和切分。这一过程通常依赖 OCR 模型的检测能力。
- 层次结构建模(Hierarchical Structuring) 在完成区域划分后,需要识别文档的 逻辑层级,例如“章节 → 小节 → 段落 → 句子”。这一结构不仅有助于保持语义上下文的完整性,还能让后续的检索模块能够更好地进行分层召回。例如,当用户检索某一章节主题时,系统能直接定位到对应段落,而非无序的全文搜索。
- 表格与图表解析(Table & Figure Understanding) 对于包含数据的文档而言,表格和图表的解析是难点之一。表格需要经过 行列结构抽取,再转化为可索引的结构化数据;图表则需要通过 图像识别 + 语义标注 的方式提取数据点和趋势描述。这些信息可以作为检索时的重要补充。
- 跨模态信息融合(Multimodal Fusion) 在多模态场景下,单独处理文本或图像并不足够。解析过程中,需要将 文本信息、图像内容、表格数据 进行统一建模。例如,某一科学论文的实验结果可能同时存在于“正文描述 + 数据表格 + 折线图”中,完整检索必须能够跨模态聚合这些信息。
通过上述步骤,文档从最初的“视觉排版格式”被转化为具有 层次化、结构化和语义化 的知识表示,从而为后续的向量检索(RAG)、问答生成和多模态分析提供高质量的输入。
四、多模态RAG系统相关模型
1. 热门OCR模型介绍
在多模态 RAG 技术体系中,OCR(Optical Character Recognition,光学字符识别)模型依旧是最基础也最重要的一环。它们的核心价值在于,能够从 PDF、扫描件、票据、图像等文档中,快速而高效地识别出文本信息和基本的版面结构,为后续的向量化与语义检索提供输入。相比大型视觉语言模型(VLM),OCR 模型参数规模更小,推理成本低,甚至可以直接在 CPU 上运行,因而在大规模批处理和轻量化部署场景中有着无可替代的优势。不过,它们的局限也非常明显——通常只能做到文字级别的检测与识别,缺乏对图像内容的语义理解和推理能力。因此,OCR 常常作为「底层解析引擎」存在,与上层的 VLM 模型或产品工具相配合,形成完整的多模态信息处理流水线。
1.1 dots.ocr
dots.ocr是小红书近期发布的OCR大模型。凭借仅 1.7B 的参数规模,使得模型在多语种文档、复杂版面和表格场景中表现出色。
- 优势:在多语言与复杂版面上表现突出;
- 局限:社区反馈在少数复杂表格(合并单元格)场景仍需微调或后处理。
- 适用:论文/报告、票据类文档的解析;
- 项目地址:https://github.com/rednote-hilab/dots.ocr
运行效果:
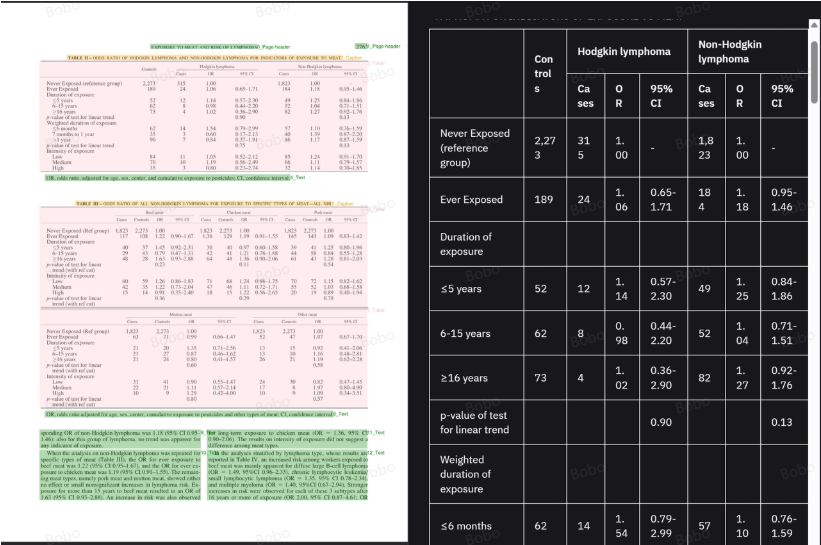
1.2 olmOCR(Allen AI)
在轻量 OCR 工具中,olmOCR 的特色在于对复杂 PDF 与扫描文档进行“线性化还原”。它于 2024 年开源,核心目标是最大限度地保持文档阅读顺序的完整性,同时兼顾表格、公式以及手写体等特殊内容的识别。olmOCR 的模型规模属于中小尺寸,总共7B参数两,可以在常规 GPU 环境甚至部分 CPU 配置下运行,适合科研与生产场景的快速部署。与传统 OCR 偏重“字符识别”不同,olmOCR 更强调文档的整体可读性与内容一致性,因此在大规模 PDF 转文本的批处理场景下表现突出,是学术界和产业界逐渐关注的高保真 OCR 工具。
- 优势:对复杂排版的读序恢复能力强;手写体/公式覆盖;开箱即用。
- 局限:对图像语义本身不做高级理解(需上层 VLM)。
- 适用:海量 PDF 到可检索文本的高质量批处理;RAG 预处理。
- 项目地址:https://github.com/allenai/olmocr
运行效果:
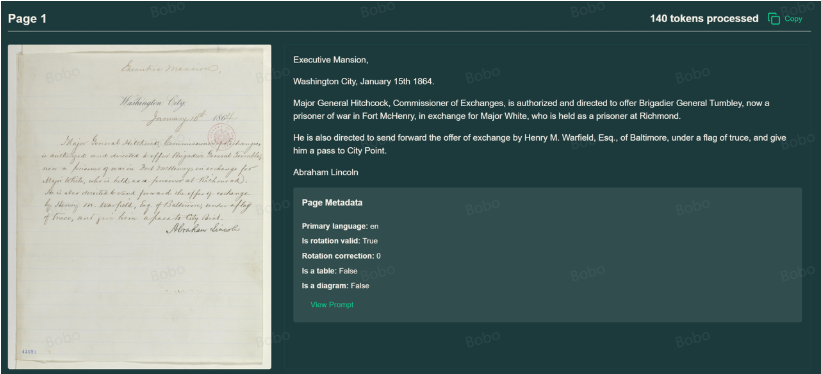
1.3 PaddleOCR
作为最成熟的开源 OCR 工具链之一,PaddleOCR 由 百度飞桨(PaddlePaddle)团队自 2020 年起持续维护与迭代,至今已覆盖数十种模型和场景。其模型规模从轻量级 3–10M 参数的 CPU 可运行版本,到上百 MB 的高精度模型均有覆盖,用户可以根据硬件条件与精度需求灵活选择。PaddleOCR 的优势在于模型生态完整,涵盖文本检测、识别到版面分析的全流程,且原生支持多语种(含中文、英文、日文、韩文等 80+ 语言)。凭借优化的推理性能和丰富的部署方案(服务器、移动端、嵌入式),它已经在票据识别、发票解析、工业表单处理等领域被广泛应用。虽然在复杂表格、跨页排版等语义层面仍需额外规则或上层模型辅助,但凭借其大规模用户群体与长期工程化打磨,PaddleOCR 已成为工业界 OCR 的事实标准。
- 优势:生态完善、文档与示例丰富、轻量模型可 CPU 运行;在特定流水线中官方示例强调“毫秒级”预测与灵活服务部署。
- 局限:对复杂表格/图表/跨页关系仍需微调或后处理;
- 适用:端侧/低成本批处理、工程化稳定大规模 OCR 服务。
- 项目地址:https://github.com/PaddlePaddle/PaddleOCR
运行效果:

多模态RAG实操篇
一、多模态PDF文档解析流程
1. 基础环境准备
在正式上手 PDF → Markdown 的结构化解析之前,我们需要先准备好实验环境。由于本文的实验在 Windows 系统上进行,下面的步骤也以 Windows 为例。整体思路是:配置 Python 环境 → 安装基础依赖 → 安装 OCR 引擎(PaddleOCR) → 安装 PDF 处理与辅助库。
1.1 创建 Python 环境
建议使用 Python 3.9+(推荐 3.10 或 3.11),以保证兼容性,同时推荐使用 conda 或 venv 来创建虚拟环境:
注意:由于环境安装会占用较多内存因此也可以基于autodl云服务器进行环境安装和实操!
# 使用 conda 创建虚拟环境
conda create -n pdf_rag python=3.11 -y
conda activate pdf_rag
#下载绑定内核
pip install ipykernel
python -m ipykernel install --user --name=pdf_rag
1.2 安装基础库
本次项目需要依赖的核心依赖包括:
- PyMuPDF (fitz):负责读取 PDF 文件、提取页面和图片。
- matplotlib / pillow:用于可视化和图像处理。
- unstructured:微软和LangChain 推荐的 PDF 文档解析库,支持结构化分块。
- paddleocr:OCR 引擎,用于文本区域的识别。
安装命令如下:
#可使用国内源: https://pypi.tuna.tsinghua.edu.cn/simple
pip install --upgrade pip
conda install protobuf
pip install "unstructured[all-docs]" # 支持 PDF / Word / PPT / HTML 等文档解析
pip install paddlenlp paddleocr # OCR 引擎
pip install PyMuPDF pillow matplotlib # PDF 和图片处理
pip install html2text # 用于 HTML 表格转 Markdown
安装过程可能会出现关于numpy、langgraph-api或者protobuf相关的错误,可以忽略,然后重新多次执行pip安装指令即可!
⚠️ 注意:
unstructured[all-docs]会自动安装 PDF 解析相关的依赖(如 pdfminer, PyMuPDF)。paddleocr在第一次运行时会自动下载模型(中英文模型)。- 在 Windows 上安装
paddleocr时,可能需要先装 Visual C++ 运行库,否则会遇到paddlepaddle的动态链接库错误。 - 此外,可以添加
--index-url https://mirrors.huaweicloud.com/repository/pypi/simple华为镜像源来加速下载。
2.载入 PDF 并进行元素提取(安装包帮大家准备好了)
安装tesseract-ocr
Tesseract 是一个由 Google 维护的开源 OCR(Optical Character Recognition,光学字符识别)引擎。
对于Windows用户,最省心的方式是直接从 UB-Mannheim/tesseract Wiki 下载官方安装包。这个版本被广泛使用且相对稳定。通常只需下载名称中包含 w64(用于64位系统)的安装程序(例如 tesseract-ocr-w64-setup-5.3.0.20221222.exe),然后双击运行,按照提示完成安装即可。
安装Poppler
Poppler 是一个用于从 PDF 文件中提取内容的工具包。
1.下载 Poppler:前往 poppler-for-windows 的官方发布页面 下载最新的压缩包(通常是 poppler-xx.x.x.zip 格式)
2.解压文件:将压缩包解压到一个容易找到的目录,例如 C:\poppler\Library。解压后的文件夹内会有一个 bin 目录
3.配置环境变量 PATH
有了依赖库之后,我们就可以使用 UnstructuredLoader 来解析 PDF 文档了,对于给定的文档,我们可以按照如下方式进行解析:
这段代码的核心目标是用 Unstructured + PaddleOCR 从 PDF 中提取结构化内容,并输出为文档对象列表。代码在运行时会自动下载相关ocr模型,默认是在huggingface下载,如果没有代理也可以基于Hugging Face 镜像站https://hf-mirror.com下载。
注意:下述代码如果运行时报错FileNotFoundError: [WinError 2] 系统找不到指定的文件。则表示Poppler包的问题,可以在poppler官网下载其他版本的Release压缩包且对其进行环境变量配置即可。Poppler下载地址是:
https://github.com/oschwartz10612/poppler-windows/releases/
#pip install langchain_unstructured
from langchain_unstructured import UnstructuredLoader
import os
#Hugging Face 镜像站https://hf-mirror.com
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
file_path = "xxx.pdf"
#创建pdf解析工具对象
loader_local = UnstructuredLoader(
file_path=file_path,
strategy="hi_res", # 高分辨率模式,支持复杂文档
infer_table_structure=True, # 自动解析表格结构,会自动下载表格识别ocr模型
languages=["chi_sim+eng"], # 支持中英文 OCR
ocr_engine="paddleocr" # 指定 PaddleOCR 作为 OCR 引擎
)
#将所有分页结果存入列表 docs_local,形成完整的文档级表示
docs_local = []
#lazy_load() 采用生成器模式按需逐步读取文档片段,避免一次性加载超大文件导致内存溢出。特别适合 GB 级别的大型扫描件。
for doc in loader_local.lazy_load():
#doc.page_content → 文本内容
#doc.metadata → 额外信息(页码、坐标、分类、OCR 置信度等)
docs_local.append(doc)
#此时docs_local就包含了每个解析的元素
docs_local
其中每个 doc 都包含 page_content(文本内容)以及 metadata(页码、坐标、类型等)。这就意味着我们的 PDF 文档已经被拆解为一个个 可检索的基本单元,接下来便可以进一步做结构化处理。
接下来为了验证实际元素提取效果,我们这里进一步把 PDF 页面渲染成图片,并在上面绘制出分块框(标题、表格、图片、文本等),实现可视化。
定义下面的工具函数:
下述代码无需理解,直接调用使用即可。
import fitz
import matplotlib.patches as patches
import matplotlib.pyplot as plt
from PIL import Image
#进行pdf页面元素标注实操函数
def plot_pdf_with_boxes(pdf_page, segments):
#使用 PyMuPDF把PDF 渲染为像素图
pix = pdf_page.get_pixmap()
#将像素图转换为 PIL Image,方便后续可视化
pil_image = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
#用 matplotlib 将PDF页面作为画布背景(在画布上标注pdf不同结构元素)。
fig, ax = plt.subplots(1, figsize=(10, 10))
ax.imshow(pil_image)
categories = set()
#定义不同类别(标题、图片、表格)对应的高亮颜色。
category_to_color = {
"Title": "orchid",
"Image": "forestgreen",
"Table": "tomato",
}
#进行页面元素标注绘制
for segment in segments:
points = segment["coordinates"]["points"]
layout_width = segment["coordinates"]["layout_width"]
layout_height = segment["coordinates"]["layout_height"]
scaled_points = [
(x * pix.width / layout_width, y * pix.height / layout_height)
for x, y in points
]
box_color = category_to_color.get(segment["category"], "deepskyblue")
categories.add(segment["category"])
rect = patches.Polygon(
scaled_points, linewidth=1, edgecolor=box_color, facecolor="none"
)
ax.add_patch(rect)
# Make legend
legend_handles = [patches.Patch(color="deepskyblue", label="Text")]
for category in ["Title", "Image", "Table"]:
if category in categories:
legend_handles.append(
patches.Patch(color=category_to_color[category], label=category)
)
ax.axis("off")
ax.legend(handles=legend_handles, loc="upper right")
plt.tight_layout()
plt.show()
#参数1:pdf解析后的元素集合,就是上述代码中的docs_local列表
#参数2:pdf页码,可以针对指定页码表示的页面进行可视化验证
def render_page(doc_list: list, page_number: int, print_text=True) -> None:
pdf_page = fitz.open(file_path).load_page(page_number - 1)
page_docs = [
doc for doc in doc_list if doc.metadata.get("page_number") == page_number
]
segments = [doc.metadata for doc in page_docs]
plot_pdf_with_boxes(pdf_page, segments)
if print_text:
for doc in page_docs:
print(f"{doc.page_content}\n")
工具函数调用实现可视化:
render_page(docs_local, 1) #查看pdf中第一页的解析结果
3. PDF逆向转化为md文档
而更进一步的,我们就能将其转化为markdown文档:
import os
#PyMuPDF 库,用来读取 PDF、提取图片
import fitz
#Unstructured 提供的 PDF 解析接口,可以自动调用 OCR。
#UnstructuredLoader 和 partition_pdf 都是 unstructured 库中用于解析 PDF 的工具
#partition_pdf是一个较为底层的解析接口,UnstructuredLoader是和langchain集成的解析接口
from unstructured.partition.pdf import partition_pdf
#重点1:原始pdf文件路径
pdf_path = "xxx.pdf"
#重点2:保存md文件图片的文件夹
output_dir = "pdf_images"
os.makedirs(output_dir, exist_ok=True)
# Step 1: 提取pdf的文本/结构化内容
elements = partition_pdf(
filename=pdf_path,
infer_table_structure=True, # 开启表格结构检测
strategy="hi_res", # 高分辨率 OCR,适合复杂表格
languages=["chi_sim", "eng"], # 中英文混合识别
ocr_engine="paddleocr", # 指定 PaddleOCR 引擎
encoding="utf-8" # 确保UTF-8编码
)
# Step 2: 提取图片并保存。核心作用是:使用 fitz 遍历 PDF 的每一页,提取图片。每张图片保存为 page{页码}_img{索引}.png。
doc = fitz.open(pdf_path)
image_map = {}
for page_num, page in enumerate(doc, start=1):
image_map[page_num] = []
for img_index, img in enumerate(page.get_images(full=True), start=1):
xref = img[0]
pix = fitz.Pixmap(doc, xref)
img_path = os.path.join(output_dir, f"page{page_num}_img{img_index}.png")
if pix.n < 5: # RGB / Gray
pix.save(img_path)
else: # CMYK 转 RGB
pix = fitz.Pixmap(fitz.csRGB, pix)
pix.save(img_path)
image_map[page_num].append(img_path)
# Step 3: 转换为 Markdown。
md_lines = []
inserted_images = set() # 用来记录已经插入过的图片,避免重复
#遍历前面解析出的pdf所有结构,根据不同类型拼接 Markdown。
for el in elements:
cat = el.category
text = el.text
page_num = el.metadata.page_number
# Title → 转换为 Markdown 一级标题 #。
# Header / Subheader → 转换为二级标题 ##。
# 特殊情况:如果标题开头是 -,说明其实是列表项而不是标题,直接保持原样。
if cat == "Title" and text.strip().startswith("- "):
md_lines.append(text + "\n")
elif cat == "Title":
md_lines.append(f"# {text}\n")
elif cat in ["Header", "Subheader"]:
md_lines.append(f"## {text}\n")
#pdf表格结构 转换为 Markdown 表格。
elif cat == "Table":
# 尝试直接获取表格文本,并确保编码
table_text = el.text
if table_text:
# 清理和确保中文编码
cleaned_table_text = table_text.encode('utf-8', errors='ignore').decode('utf-8')
md_lines.append(cleaned_table_text + "\n")
else:
# 如果直接文本为空,回退到HTML转换
if hasattr(el.metadata, "text_as_html") and el.metadata.text_as_html:
from html2text import html2text
md_lines.append("以下是表格数据,请你用表格样式进行展示和理解!\n")
md_lines.append(html2text(el.metadata.text_as_html) + "\n")
#将pdf解析出的图片插入到md中
elif cat == "Image":
# 避免重复插入:只插入当前图片对应的文件
for img_path in image_map.get(page_num, []):
if img_path not in inserted_images:
md_lines.append(f"\n")
inserted_images.add(img_path)
else:
md_lines.append(text + "\n")
# Step 4: 写入 Markdown 文件
#重点3:转换成功后的md文件路径
output_md = "output.md"
with open(output_md, "w", encoding="utf-8") as f:
f.write("\n".join(md_lines))
print(f"✅ 转换完成,已生成 {output_md} 和 {output_dir}/ 图片文件夹")
二、搭建基于多模态MarkDown文档的Agentic RAG检索引擎
在跑通了多模态文档转化之后,接下来我们基于转化后的多模态MarkDown文档来创建一个Agentic RAG引擎。
1.环境搭建
安装基础依赖 : 新建一个 requirements.txt
pydantic
python-dotenv
langgraph
langchain-core
langchain-deepseek
langchain-tavily
langsmith
langchain-openai
langchain-text-splitters
langchain-community
faiss-cpu
langgraph_supervisor
graphrag
输入如下命令完成安装:
pip install -r requirements.txt
注意:可能会出现一个numpy、protobuf 版本不兼容的错误,可以忽略该错误!再次执行pip安装指令即可!
Node.js环境安装:为下面的前端框架的环境安装提供支持
1、下载Node.js
打开官网下载链接:https://nodejs.org/zh-cn/

2、安装
下载完成后,双击“node-v12.16.1-x64.msi”,开始安装Node.js
①点击【Next】按钮
②勾选复选框(I accept the…),点击【Next】按钮
一直【next】就完了,然后【install】安装,安装完后点击【Finish】按钮完成安装
安装成功后简单一下测试安装是否成功:
在键盘按下【win+R】键,输入cmd,然后回车,打开cmd窗口
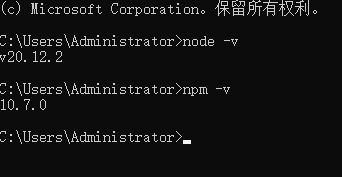
3、环境变量配置
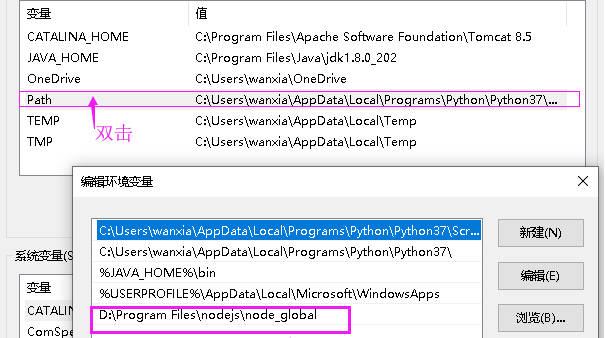
4、下载安装pnpm
pnpm 是一个 JavaScript 包管理工具。
npm install -g pnpm,安装完成后,重新打开一个终端窗口,运行 pnpm -v 或 pnpm -v。如果正确显示版本号,就表示安装成功了!
安装前端框架Agent Chat UI
-
框架介绍:
- 前端框架Agent Chat UI是一个由 LangChain 官方推出的开源项目,它是一个专为 AI 智能体(Agent)设计的 Web 聊天界面。你可以把它理解为一个为智能体量身定做的“客户端”或“控制台”,核心目标是让你能通过一个直观的聊天窗口,与背后由 LangGraph 等框架构建的复杂 AI 智能体进行交互和调试。
- 这个前端框架主要解决了开发者在构建 AI 智能体时遇到的两个关键问题:
- 提供直观的交互界面:无需自己编写前端代码,就能有一个现代化的聊天界面来测试和展示你的 AI 智能体,极大地提升了开发效率和体验。
- 支持生成式 UI:这是它的一大亮点。它不仅能展示纯文本对话,还能渲染并交互智能体工具返回的复杂 UI 组件。这意味着你的智能体不再只是一个聊天机器人,它可以返回丰富的交互元素,功能表现更多样。
-
框架下载:
- git clone https://github.com/langchain-ai/agent-chat-ui.git
- 或者直接使用老师提供好的框架源码压缩包agent-chat-ui-main.zip
-
对框架源码压缩包进行解压缩。基于cmd进入到解压缩文件夹中:
cd agent-chat-ui-main/agent-chat-ui-main -
然后安装前端依赖:
pnpm install
安装LangGraph项目部署工具
该项目部署工具的核心作用是为开发者提供一套完整的工具,用于打包、运行、测试和部署你在本地开发的 LangGraph 智能体(Agent)应用。
简单理解为该部署工具可以一键将我们编写好的Rag程序打包为可以和前端框架结合使用的后端程序,进行前后端交互。
pip install -U "langgraph-cli[inmem]"
2.知识库检索数据集准备
接下来我们准备检索用的数据集:需要先将pdf数据集逆向转化为md文档。
其中需要注意的是,提取到的pdf图片需要单独保存到一个图片文件夹中,然后将图片作用显示在md文件中。
为了后续可以将图片在问答中出现,则需要将图片路径改为 可公网络问的 URL,然后启动一个静态文件服务器,托管图片文件夹。
启动一个静态文件服务器(Python 内置 HTTP 服务器):可以在图片文件夹对应的根目录中执行:python -m http.server 8000
import os
#PyMuPDF 库,用来读取 PDF、提取图片
import fitz
#Unstructured 提供的 PDF 解析接口,可以自动调用 OCR。
#UnstructuredLoader 和 partition_pdf 都是 unstructured 库中用于解析 PDF 的工具
#partition_pdf是一个较为底层的解析接口,UnstructuredLoader是和langchain集成的解析接口
from unstructured.partition.pdf import partition_pdf
pdf_path = "卷积神经网络.pdf"
#保存图片的文件夹
output_dir = "pdf_images"
os.makedirs(output_dir, exist_ok=True)
# Step 1: 提取pdf的文本/结构化内容
elements = partition_pdf(
filename=pdf_path,
infer_table_structure=True, # 开启表格结构检测
strategy="hi_res", # 高分辨率 OCR,适合复杂表格
languages=["chi_sim", "eng"], # 中英文混合识别
ocr_engine="paddleocr", # 指定 PaddleOCR 引擎
encoding="utf-8" # 确保UTF-8编码
)
# Step 2: 提取图片并保存。核心作用是:使用 fitz 遍历 PDF 的每一页,提取图片。每张图片保存为 page{页码}_img{索引}.png。
doc = fitz.open(pdf_path)
image_map = {}
for page_num, page in enumerate(doc, start=1):
image_map[page_num] = []
for img_index, img in enumerate(page.get_images(full=True), start=1):
xref = img[0]
pix = fitz.Pixmap(doc, xref)
img_path = os.path.join(output_dir, f"page{page_num}_img{img_index}.png")
if pix.n < 5: # RGB / Gray
pix.save(img_path)
else: # CMYK 转 RGB
pix = fitz.Pixmap(fitz.csRGB, pix)
pix.save(img_path)
image_map[page_num].append(img_path)
# Step 3: 转换为 Markdown。
md_lines = []
inserted_images = set() # 用来记录已经插入过的图片,避免重复
#遍历前面解析出的pdf所有结构,根据不同类型拼接 Markdown。
for el in elements:
cat = el.category
text = el.text
page_num = el.metadata.page_number
# Title → 转换为 Markdown 一级标题 #。
# Header / Subheader → 转换为二级标题 ##。
# 特殊情况:如果标题开头是 -,说明其实是列表项而不是标题,直接保持原样。
if cat == "Title" and text.strip().startswith("- "):
md_lines.append(text + "\n")
elif cat == "Title":
md_lines.append(f"# {text}\n")
elif cat in ["Header", "Subheader"]:
md_lines.append(f"## {text}\n")
#pdf表格结构 转换为 Markdown 表格。
elif cat == "Table":
# 尝试直接获取表格文本,并确保编码
table_text = el.text
if table_text:
# 清理和确保中文编码
cleaned_table_text = table_text.encode('utf-8', errors='ignore').decode('utf-8')
md_lines.append(cleaned_table_text + "\n")
else:
# 如果直接文本为空,回退到HTML转换
if hasattr(el.metadata, "text_as_html") and el.metadata.text_as_html:
from html2text import html2text
md_lines.append("以下是表格数据,请你用表格样式进行展示和理解!\n")
md_lines.append(html2text(el.metadata.text_as_html) + "\n")
#将pdf解析出的图片插入到md中
elif cat == "Image":
for img_path in image_map.get(page_num, []):
if img_path not in inserted_images:
#将图片路径改为 可公开访问的 URL
img_url = f"http://localhost:8000/{img_path.replace(os.sep, '/')}"
md_lines.append(f"\n")
inserted_images.add(img_path)
else:
md_lines.append(text + "\n")
# Step 4: 写入 Markdown 文件
output_md = "output.md"
with open(output_md, "w", encoding="utf-8") as f:
f.write("\n".join(md_lines))
print(f"✅ 转换完成,已生成 {output_md} 和 {output_dir}/ 图片文件夹")
然后,为了搭建RAG系统,我们还需要对原始文档进行处理,来创建词向量数据库:
pip install langchain-text-splitters faiss-cpu --index-url https://pypi.tuna.tsinghua.edu.cn/simple
from langchain_community.embeddings import BaichuanTextEmbeddings
#向量模型
key = "sk-83cdxxxxxx2d76f95d"
embed = BaichuanTextEmbeddings(api_key=key)
#md文件
file_path = "output.md"
with open(file_path, "r", encoding="utf-8") as f:
md_content = f.read()
from langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
from langchain.docstore.document import Document
# Step 1: 按标题粗切(保留层级结构)
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2")
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on,
strip_headers=False # 保留 # 标题文本,便于理解上下文
)
md_header_splits = markdown_splitter.split_text(md_content)
# Step 2: 对过大的 chunk 进行二次切分,但避免切断“图片+说明”组合
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=600, # 根据你的内容调整
chunk_overlap=80, # 保留上下文重叠
separators=[
"\n\n", # 段落之间优先切
"\n", # 换行
"。", "!", "?", # 中文句子结束
". ", "! ", "? ", # 英文句子结束
" ", "" # 最后 fallback
],
keep_separator=True # 保留分隔符,避免语义断裂
)
final_chunks = []
for doc in md_header_splits:
# 如果 chunk 太小(比如只有标题+一张图),直接保留,避免切碎
if len(doc.page_content) <= 700:
final_chunks.append(doc)
else:
# 对大块做细切
sub_docs = text_splitter.split_documents([doc])
final_chunks.extend(sub_docs)
# Step 3: 构建向量库
from langchain_community.vectorstores import FAISS
vector_store = FAISS.from_documents(final_chunks, embedding=embed)
#持久化存储向量数据库,下面参数值是向量数据库存储名字
vector_store.save_local("./telco_customer_churn_analytics_handbook")
3.多模态RAG系统代码
构建一个对话式问答机器人,其特点如下:
- 领域限定:只回答关于 XXX领域 的问题;
- 知识来源:依赖本地 FAISS 向量数据库中预存的课程材料;
- 智能流程控制:使用 LangGraph 构建工作流程;
- 支持工具调用:通过
retriever_tool检索相关文档; - 容错机制:如果检索内容不相关,会重写用户问题再试一次。
提示词(Prompts)设计
| 提示类型 | 作用 |
|---|---|
SYSTEM_INSTRUCTION |
定义助手角色:仅回答 xxx领域相关问题,拒绝无关提问 |
GRADE_PROMPT |
让 LLM 判断检索到的文档是否与问题相关(输出 "yes"/"no") |
REWRITE_PROMPT |
当检索失败时,重写用户问题,使其更贴合 xxx技术领域的术语 |
ANSWER_PROMPT |
基于检索到的上下文生成最终答案,要求使用 Markdown、保留代码格式等 |
工作流图(StateGraph)
- 循环机制:如果检索内容不相关 → 重写问题 → 再次尝试;
- 工具节点:
ToolNode([retriever_tool])自动执行检索; - 状态管理:使用
MessagesState跟踪对话历史。
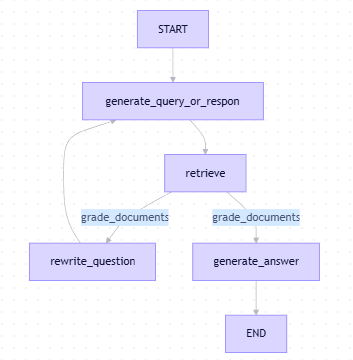
| 步骤 | 节点名称 | 功能 |
|---|---|---|
| 1 | START |
起点 |
| 2 | generate_query_or_respond |
模型判断是否调用工具 |
| 3 | retrieve |
调用检索工具返回上下文 |
| 4 | grade_documents |
判断检索结果是否相关 |
| 5a | generate_answer |
生成回答 → 终点 |
| 5b | rewrite_question |
改写问题 → 回到第2步 |
代码文件名:rag_agent.py
from __future__ import annotations
import os
import asyncio
from typing import Literal
from dotenv import load_dotenv
load_dotenv(override=True)
from langchain.chat_models import init_chat_model
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.tools.retriever import create_retriever_tool
from langgraph.graph import MessagesState, StateGraph, START, END
from langgraph.prebuilt import ToolNode, tools_condition
from pydantic import BaseModel, Field
from langchain_community.embeddings import BaichuanTextEmbeddings
# ---------------------------------------------------------------------------
# LLM & Embeddings
# ---------------------------------------------------------------------------
MODEL_NAME = "deepseek-chat"
#init_chat_model 是 LangChain 框架中一个非常实用的统一模型初始化函数,它通过一个简洁的接口,让你能快速初始化来自不同提供商的聊天模型,而无需关心各个模型类具体的导入路径和初始化细节
#- model:主模型,用于用户对话处理。
model = init_chat_model(model=MODEL_NAME,
model_provider="deepseek",
api_key="sk-4b79f3a3ff334a15a1935366ebb425b3",
temperature=0)
#grader_model:用于判断文档相关性的小助手模型。
grader_model = init_chat_model(model=MODEL_NAME,
model_provider="deepseek",
api_key="sk-4b79f3a3ff334a15a1935366ebb425b3",
temperature=0)
#向量数据库加载与检索工具构建
key = "sk-83cd52e5dfd7a1c0ca6f57952d76f95d"
embed = BaichuanTextEmbeddings(api_key=key)
VS_PATH = "telco_customer_churn_analytics_handbook"
vector_store = FAISS.load_local(
folder_path=VS_PATH,
embeddings=embed,
#信任当前加载的数据来源
allow_dangerous_deserialization=True,
)
retriever_tool = create_retriever_tool(
vector_store.as_retriever(search_kwargs={"k": 3}),
name="retrieve_cnn_course",
#搜索并返回CNN课程材料中的相关章节
description="Search and return relevant sections from the CNN course materials.",
)
# 系统提示词,- 限定助手只能回答“卷积CNN”技术实战相关问题;如果不是相关问题,就回复:我不能回答与 卷积CNN技术无关的问题。
'''你是一个卷积神经网络(CNN)技术学习助手。专注于回答与卷积神经网络相关的问题,包括卷积原理、网络架构、参数计算、池化操作、填充策略、实际应用(例如LeNet-5)等。
如果用户的问题与卷积神经网络无关,请回复:'我只能回答与卷积神经网络(CNN)相关的问题。'
当需要CNN课程材料的额外上下文时,可以调用提供的工具`retriever_tool`。
'''
SYSTEM_INSTRUCTION = (
"You are a Convolutional Neural Network (CNN) technical learning assistant. "
"Focus exclusively on answering questions related to convolutional neural networks, including convolution principles, network architecture, parameter calculation, pooling operations, padding strategies, practical applications (e.g., LeNet-5), etc.\n"
"If the user's question is unrelated to convolutional neural networks, reply: '我只能回答与卷积神经网络(CNN)相关的问题。'\n"
"You may call the provided tool `retriever_tool` when additional context from the CNN course material is required."
)
#评估 Prompt:指导 grader_model 判断检索结果是否与用户提问相关,输出 yes 或 no。
'''你是一名评估者,正在评估检索到的文档内容与用户关于卷积神经网络问题的相关性。
检索到的文档内容:
{context}
用户问题:{question}
如果文档内容包含与问题相关的卷积神经网络知识点,则返回'yes';否则返回'no'。
'''
GRADE_PROMPT = (
"You are an evaluator assessing the relevance of retrieved document content to the user's convolutional neural network question.\n"
"Retrieved document content:\n{context}\n\nUser question: {question}\n"
"If the document content contains CNN-related knowledge points relevant to the question (such as convolution kernels, stride, feature maps, pooling, padding, network layers, parameter computation, or LeNet-5 architecture), return 'yes'; otherwise return 'no'."
)
#重写 Prompt:如果用户问题偏离主题,让模型改写问题,使其更贴近“工具调用 / CNN / 卷积”等关键概念。
'''您需要将用户的问题重写,使其更明确地针对卷积神经网络的技术细节。
您的任务是将用户原始问题优化或澄清为更具针对性和专业性的CNN技术问题。
优化方向应包含以下核心CNN概念:
- 卷积计算(卷积核、步长、特征图、点积)
- 池化操作(最大池化、平均池化、空间不变性)
- 填充策略(有效填充与相同填充、边缘特征保留)
- 网络架构(卷积层、池化层、全连接层)
- 参数与权重共享(例如,5×5卷积核输出32个通道→5×5×32个权重)
- 实际案例,如LeNet-5在MNIST上的应用(28×28输入、两个卷积+池化模块、全连接层)
原始问题:
{question}
改进后的问题:
'''
REWRITE_PROMPT = (
"You are rewriting user questions to make them more explicitly targeted at technical details of convolutional neural networks.\n"
"Your task is to refine or clarify the user's original question into a more specific and professional CNN technical question.\n\n"
"Optimization directions should include the following core CNN concepts:\n"
"- Convolution computation (kernels, stride, feature maps, dot product)\n"
"- Pooling operations (max pooling, average pooling, spatial invariance)\n"
"- Padding strategies (Valid Padding vs. Same Padding, edge feature preservation)\n"
"- Network architecture (convolutional layers, pooling layers, fully connected layers)\n"
"- Parameter and weight sharing (e.g., 5×5 kernel with 32 output channels → 5×5×32 weights)\n"
"- Practical examples like LeNet-5 on MNIST (28×28 input, two conv+pool blocks, FC layers)\n\n"
"Original question:\n{question}\nImproved question:"
)
#回答 Prompt:给模型一个问题和上下文,引导它用 Markdown、代码块、图片等方式生成结构化答案。
'''你是一名负责回答卷积神经网络相关问题的技术助手。
请尽可能完整、准确地利用所提供的上下文来回答问题。
关键指令:
如果上下文中包含 Markdown 图片(即以 ' syntax.\n\n"
"Other guidelines:\n"
"- Use standard Markdown format\n"
"- Highlight key terms with **bold**\n"
"- Express formulas in plain text or inline code, e.g., `output_size = (W - K + 2*P) // S + 1`\n"
"- Present parameter calculations clearly\n"
"- If the context includes code, quote it in triple backticks\n"
"- If the answer is not in the provided context, say: '根据提供的资料,我无法找到相关答案。'\n\n"
"User Question: {question}\n"
"Context Content: {context}"
)
# ---------------------------------------------------------------------------
#LangGraph 是有状态多节点的图结构,下面定义了智能体对话的各个节点功能。
# ---------------------------------------------------------------------------
#模型调用函数,其作用是根据当前消息决定是否要调用 retriever_tool;
#该函数本质上是一个具备工具调用能力的交互节点(如果上下文不足,模型会自动决定调用检索器)。
async def generate_query_or_respond(state: MessagesState):
"""LLM decides to answer directly or call retriever tool."""
response = await model.bind_tools([retriever_tool]).ainvoke(
[
{"role": "system", "content": SYSTEM_INSTRUCTION},
*state["messages"],
]
)
return {"messages": [response]}
'''这是一个基于 Pydantic 的数据模型(BaseModel),用于约束大模型的输出格式。
它要求模型只输出一个字段 binary_score,其值必须是字符串 "yes" 或 "no"。
目的是让模型以标准化、可编程解析的方式回答“文档是否相关”这个问题,避免自由文本带来的不确定性。
'''
class GradeDoc(BaseModel):
binary_score: str = Field(description="Relevance score 'yes' or 'no'.")
#该函数作用是:使用 grader_model 判断:检索到的文档是否与提问有关;
#如果检索到的文档与提问相关则返回“generate_answer”否则返回“rewrite_question”
async def grade_documents(state: MessagesState) -> Literal["generate_answer", "rewrite_question"]:
question = state["messages"][0].content # 原始用户问题
ctx = state["messages"][-1].content # 检索器输出
prompt = GRADE_PROMPT.format(question=question, context=ctx)
#.with_structured_output(GradeDoc) 强制模型输出符合 GradeDoc 结构;
result = await grader_model.with_structured_output(GradeDoc).ainvoke([
{"role": "user", "content": prompt}
])
return "generate_answer" if result.binary_score.lower().startswith("y") else "rewrite_question"
#调用 LLM 改写用户问题,使其更符合 CNN技术范畴。
async def rewrite_question(state: MessagesState):
question = state["messages"][0].content
prompt = REWRITE_PROMPT.format(question=question)
resp = await model.ainvoke([{"role": "user", "content": prompt}])
return {"messages": [{"role": "user", "content": resp.content}]}
#用 LLM + 上下文生成最终答复;
async def generate_answer(state: MessagesState):
question = state["messages"][0].content
ctx = state["messages"][-1].content
prompt = ANSWER_PROMPT.format(question=question, context=ctx)
resp = await model.ainvoke([{"role": "user", "content": prompt}])
return {"messages": [resp]}
# ---------------------------------------------------------------------------
# Build graph
# ---------------------------------------------------------------------------
workflow = StateGraph(MessagesState)
workflow.add_node("generate_query_or_respond", generate_query_or_respond)
workflow.add_node("retrieve", ToolNode([retriever_tool]))
workflow.add_node("rewrite_question", rewrite_question)
workflow.add_node("generate_answer", generate_answer)
workflow.add_edge(START, "generate_query_or_respond")
workflow.add_edge("generate_query_or_respond", "retrieve")
workflow.add_conditional_edges("retrieve", grade_documents)
workflow.add_edge("generate_answer", END)
workflow.add_edge("rewrite_question", "generate_query_or_respond")
rag_agent = workflow.compile(name="rag_agent")
4.项目目录搭建和运行
创建langgraph.json配置文件
这个配置文件的核心作用,是作为 LangGraph CLI(命令行工具) 的“导航图”。它告诉 CLI 工具在您的项目中存在哪些可用的智能体(Graph),以及它们的代码路径是什么
{
"graphs": {
"RAG_research": "./rag_agent.py:rag_agent"
},
"python_version": "3.12",
"dependencies": [
"."
]
}
创建一个文件夹作为项目目录,然后将逆向好的md文件、md图片文件夹、langgraph.json配置文件和FAISS数据库文件夹保存在该项目文件夹中。然后进入该文件中,在cmd中指令:langgraph dev。
当您在项目根目录下执行 langgraph dev 时,LangGraph CLI(命令行工具)会自动读取这个 langgraph.json 文件。基于配置文件中的信息,CLI 会:
- 启动本地开发服务器,将您定义的智能体暴露为 HTTP API 服务。
- 与 LangGraph Studio 集成,提供一个强大的 Web 界面。在这里,您不仅可以直接与您配置的各个智能体(如
RAG_research,supervisor等)进行聊天测试,还能可视化地观察和调试智能体的完整运行流程与状态,这对于理解复杂智能体的行为至关重要。
简单来说,langgraph.json 为 langgraph dev 提供了“节目单”,而 langgraph dev 则据此搭建起了整个“演出舞台”。
启动前端服务
-
cmd进入到前端项目agent-chat-ui-main的目录中执行
pnpm dev指令开启前端服务。 -
可以访问3000端口进入到前端主页面,在前端主页面需要进行起始配置:
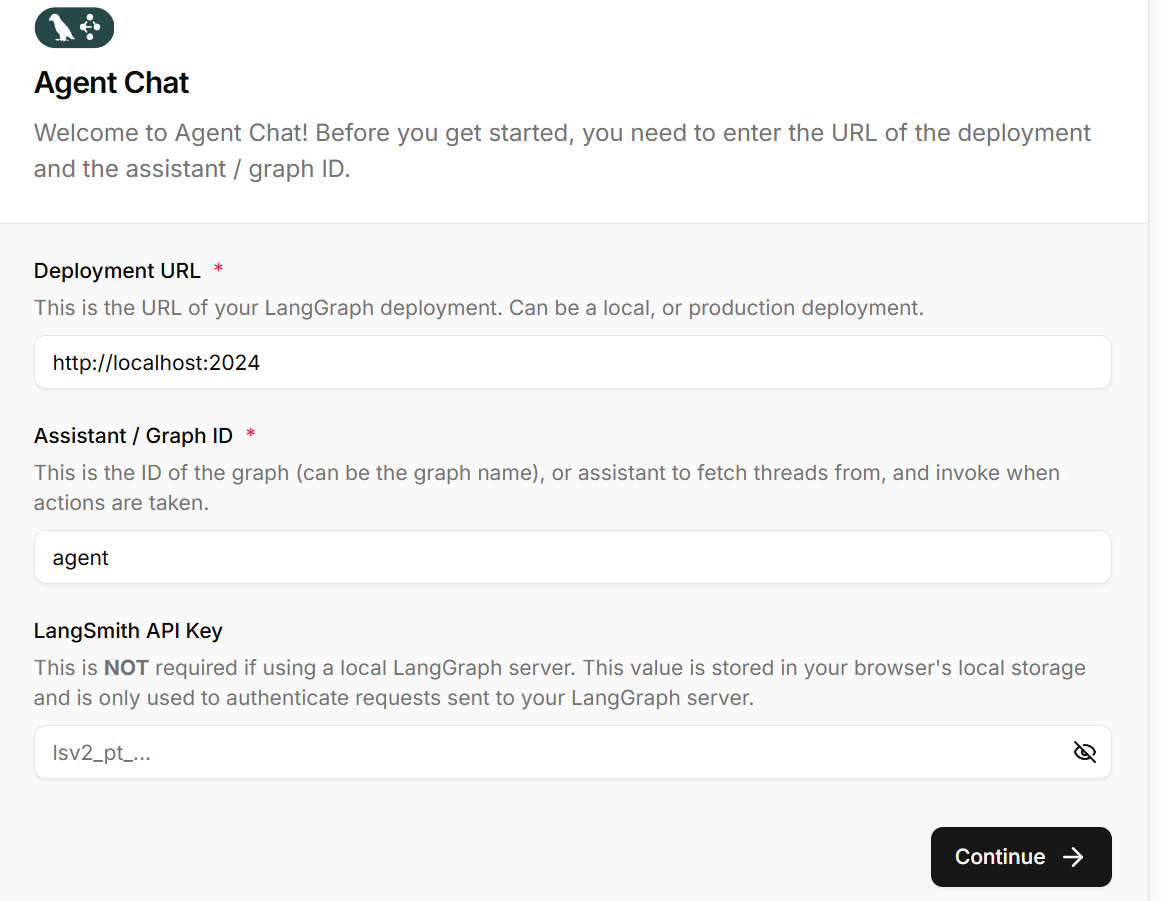
-
配置解释:
Deployment URL(部署URL):这是您的 LangGraph 后端服务的访问地址。当您运行
langgraph dev时,默认在http://localhost:2024启动服务。如果是部署到服务器的服务,需要填写对应的生产环境URL。在当前操作中保持默认的http://localhost:2024即可。Assistant / Graph ID(助手/图ID):这是您要使用的图(Graph)或助手(Assistant)的标识符。这个ID来自您的
langgraph.json配置文件中的graphs部分。
LangSmith API Key(LangSmith API密钥):用于集成 LangSmith 监控和追踪的可选配置。通常不需要配置(留空,本地开发不需要),因为您使用的是本地 LangGraph 服务器。如果需要详细的调用链追踪和分析,可以配置此项。登录 LangSmith 获取 API Key。
-
完成这些配置后,您就可以通过这个 Web 界面与您的 PDF RAG 系统进行交互了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号