今日内容
1 介绍RPA
1.1 RPA是什么
# RPA(Robotic Process Automation,机器人流程自动化[自动化流程机器人])是一种通过软件机器人(或称为 “数字员工”)模拟人类在计算机上的操作行为,来自动执行重复性、规则性业务流程的技术
1.2 RPA使用场景
# 功能作用
# 1 模拟人类操作:可自动完成点击、输入、复制、粘贴、数据提取、文件处理等操作。
-web端:网页操作
-手机端:app操作,微信小程序。。。
-PC端:win 软件操作,文件夹操作。。。
# 2 基于规则驱动:需要明确的业务规则,当流程逻辑固定、输入输出可预期时,RPA 能高效运行。
-开发了一个app--》换脸app---》公司需要有测试--》测试app的功能---》点击,输入,点击一套操作
# 3 非侵入式集成:无需改造现有 IT 系统(如 ERP、CRM、网页平台等),通过界面交互实现自动化,降低实施难度。
-公司---》员工管理系统---》你是hr--》录入新员工---》100个
-让100个新员工---》个人信息--》统计到excel表格中---》录入到我们系统
-拿到excel表格了---》一条条录入--》非常耗时--》重复性操作
-使用RPA编写一套流程---》自动的完成数据录入
-我们没有改 :员工管理系统 系统的源代码
-侵入式集成:直接使用代码,操作数据库录入
-ai帮我们 写代码导入
# 4 提升效率与准确性:替代人工完成重复性工作,减少人为错误,同时可 7×24 小时不间断运行。
# 常见应用场景包括:
财务对账、发票处理、数据录入与迁移、报表生成、客服信息查询、供应链订单处理等
淘宝卖家---》批量发货
-淘宝后台,一个个点击发货按钮
-我们发送了快递
-买家看不到
-淘宝后台点击发货按钮--》买家才能看到
1.3 目前主流RPA工具
## 1 国际知名产品
UiPath
全球市场份额领先的 RPA 工具,功能全面,支持可视化流程设计(拖拽式操作),适合复杂流程自动化。提供丰富的预置活动库(如 Excel、数据库、网页操作等),支持 AI 集成(如 OCR、自然语言处理),社区版免费供个人学习使用,企业版适合大型组织部署。
Automation Anywhere
另一国际巨头,以 “云原生” 为特色,支持云端部署和管理机器人,适合分布式团队协作。提供 “智商机器人”(IQ Bot),集成 AI 能力处理非结构化数据(如扫描件、手写体),适合需要智能处理的场景。
Blue Prism
较早进入 RPA 领域的工具,以 “企业级稳定性” 著称,严格遵循 IT 治理标准,适合对合规性、安全性要求高的行业(如金融、医疗)。流程设计更偏向代码逻辑,学习门槛稍高,多应用于大型企业核心业务流程。
## 2 国内主流产品
影刀 RPA(Yingdao)
国内市场表现突出的 RPA 工具,主打 “简单易用”,界面友好,适合无编程基础的用户快速上手。支持 Windows、网页、移动端应用自动化,集成了 OCR、API 调用等功能,在电商、零售、互联网行业应用广泛,提供免费版和企业版。
实在 RPA:AI能力是独一档的存在,开创 “RPA + 大模型” 模式——第三代RPA数字员工,在非结构化数据处理方面表现出色。实在 RPA 提供了高度定制化服务,其智能体(实在Agent)可自训练优化,能更好地适应复杂多变的业务场景。
八爪鱼 RPA:以简单易用、功能强大著称,提供了丰富的模板和组件,用户可通过拖拽式操作快速搭建自动化流程。八爪鱼 RPA 在电商、数据采集等领域应用广泛
来也科技(laiye)
结合 RPA 与 AI 能力(如对话机器人),形成 “RPA+AI” 解决方案。工具支持流程录制、可视化设计,适合政务、金融、制造业等场景,提供针对不同行业的预置模板,降低实施成本。
艺赛旗(IS-RPA)
国内较早自主研发的 RPA 工具,支持复杂流程自动化和大规模机器人管理,强调与企业现有系统的集成能力,在能源、物流等行业有较多案例。
## 3 开源框架 使用代码操作---》可操作性更强--》可定制性更强
Robot Framework:免费且灵活,具有强大的可扩展性和丰富的库支持。它采用关键字驱动的测试框架,易于学习和维护,适合小型团队和个人开发者进行自动化测试和流程自动化。
OpenRPA:社区活跃,提供了跨平台的自动化解决方案。OpenRPA 支持多种编程语言,能够与现有系统无缝集成,为开发者提供了广阔的创新空间。
1.4 使用RPAFramework自动刷抖音
# 必须用代码--》要求水平高---》早期开发人员---》给公司定制RPA工具
# 了解
# pip install rpaframework
from RPA.Browser.Selenium import Selenium
import time
class DouyinAutoScroller:
def __init__(self):
self.browser = Selenium()
def open_douyin(self):
"""打开网页版抖音"""
print("打开网页版抖音")
self.browser.open_available_browser("https://www.douyin.com/")
self.browser.maximize_browser_window()
# 等待页面加载
print("等待页面加载...")
time.sleep(10) # 初始等待时间,确保页面完全加载
def run(self):
"""运行自动化流程"""
try:
print("===== 开始自动刷抖音流程 =====")
self.open_douyin()
print("===== 自动刷抖音流程完成 =====")
except Exception as e:
print(f"执行过程中发生严重错误: {str(e)}")
raise
finally:
# 关闭浏览器
self.browser.close_all_browsers()
if __name__ == "__main__":
bot = DouyinAutoScroller()
bot.run()
2 影刀RPA安装-注册-启动
# 1 图形化界面软件---》我们可以点点点,不需要写代码(影刀支持代码操作--如果会代码-更可定制)--》能够完成自动化的操作
# 2 下载软件,安装到电脑上---》mac、win、linux---》不断更新迭代--》后期可能会越来越强大
-https://www.yingdao.com/product/
-win:功能最全,最新功能在上面
-Mac:阉割版,有的功能只能win有,mac没有---》不讲mac的使用
-mac装个win虚拟机
-信创系统(如统信UOS、银河麒麟、Linux)
# 3 下载免费版
-目前免费
-企业版:扫码获取企业服务--》跟企业对接
# 4 安装
# 5 桌面双击打开
# 6 注册完账号(社区版:足够用)(企业版收费)
# 7 登录进去

3 使用RPA自动下载热门视频
# 0 使用影刀RPA可以实现
-操作web:网页:抖音,小红书,bilibil,京东自动秒杀商品,12306买票。。。
-点击:抖音点赞
-评论:自动评论
-数据抓取:下载小说,图片,视频。。。。
-允许人来操作的:百度文库---》一篇pdf---》你账号(非会员)登录后--》不能下载---》能用影刀自动下载吗?
-自动化下载---》可以
-操作PC端:
-百度网盘软件:把百度网盘中的学习视频资料--》都下载到本地
-微信/qq: 自动回复,自动发送文件
-win机器上装的软件--》自动化操作
-游戏自动挂机
-操作手机:够用:【手机连接到电脑上:电脑上使用影刀,手机上安装对应app】
-美团app抢优惠券
-各种app的自动化操作
-手机可以正常使用即可
-自动操作手机,模拟人的行为
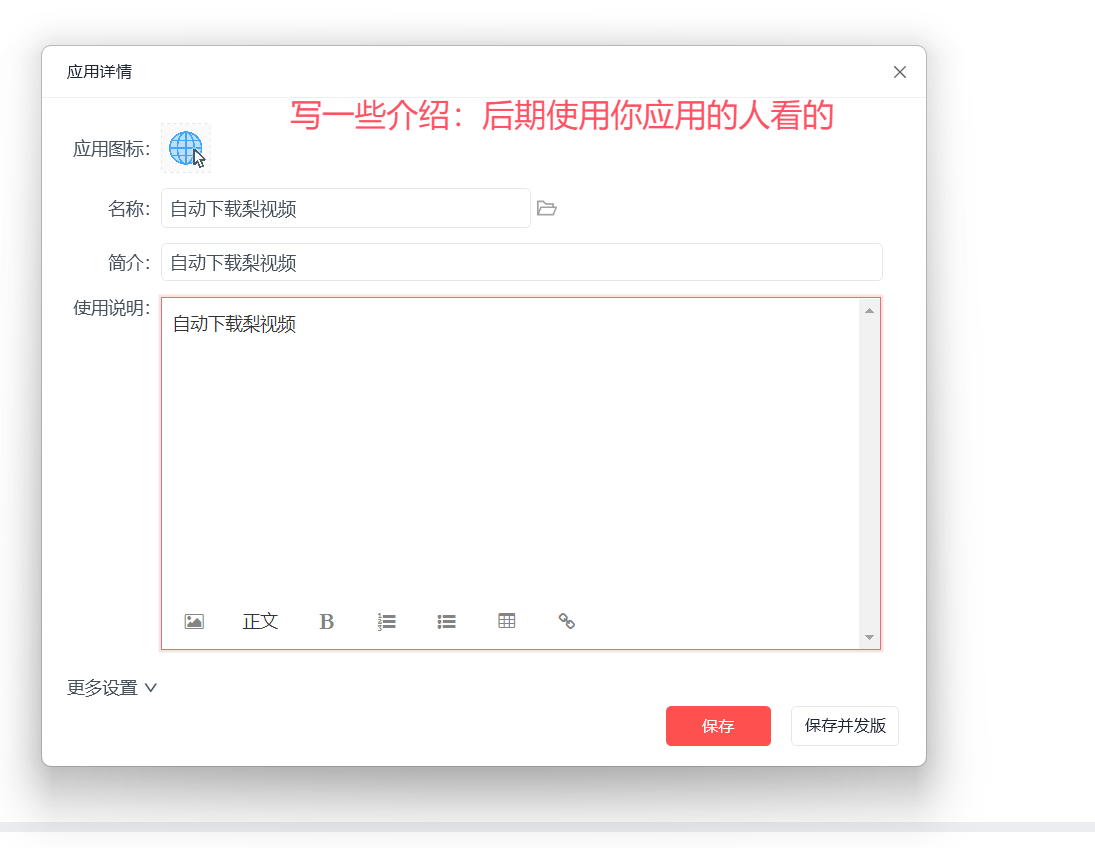
# 1 目标:
-使用影刀RPA打开 梨视频 ---》自动下载热门视频到本地
- 数据抓取[爬虫:获取互联网中的数据]
# 2 使用影刀流程
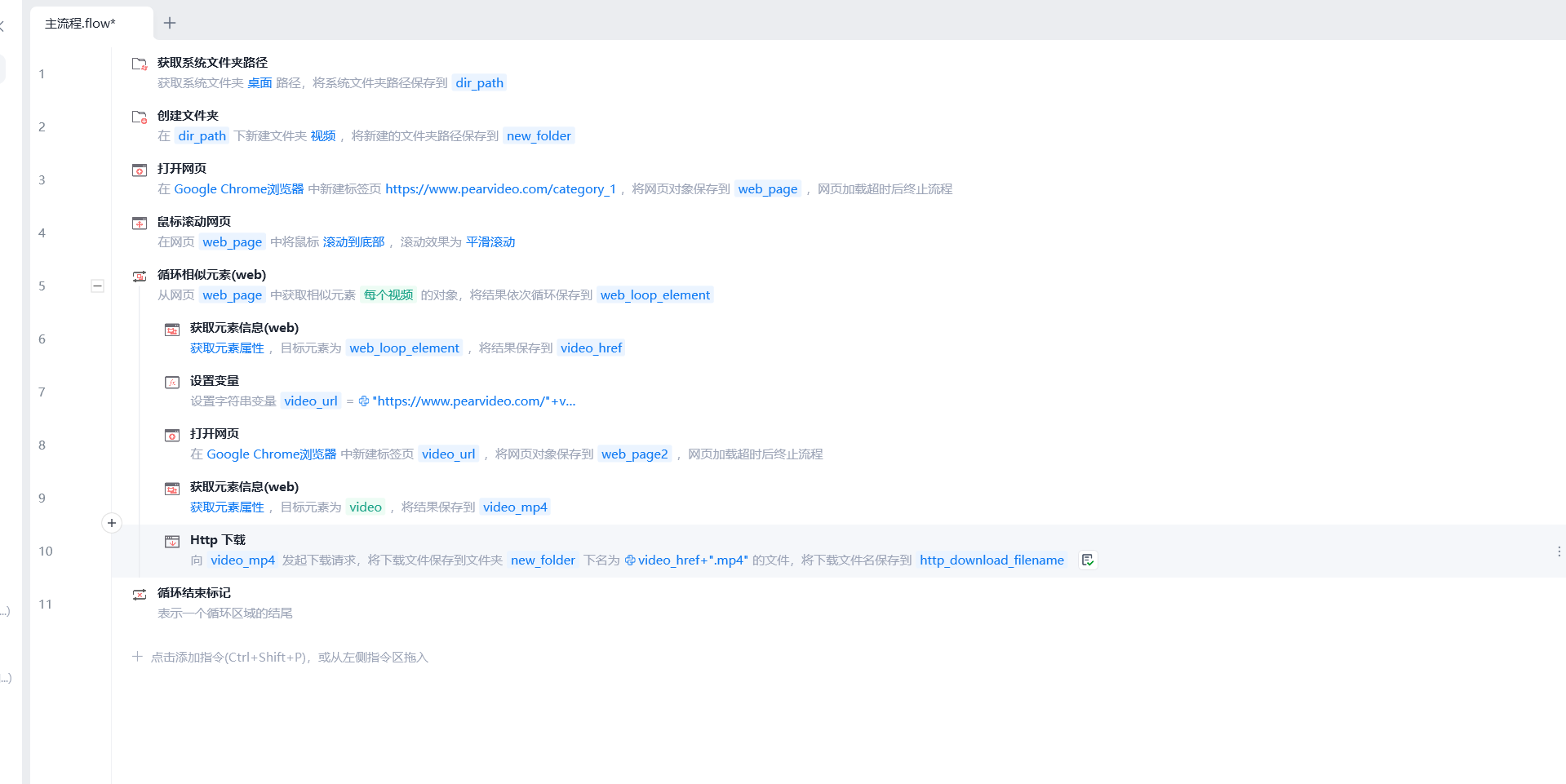
1 获取桌面地址
2 在桌面上创建一个文件夹[视频]--》存放视频
3 打开网页:梨视频
4 鼠标滚动【加载下一页】:案例中滚了一次[获取两页的数据]
-自行滚更多页码--》获取更多视频
5 循环 每一个视频
5.1 获取每一个视频地址
5.2 打开每个视频地址
5.3 获取网页中视频的链接地址 xx.mp4
5.4 下载这个视频,放到文件夹中
6 结束循环
3.1 步骤
# 1 新建PC自动化应用
# 2 获取系统文件夹路径
# 3 创建视频文件夹:在桌面
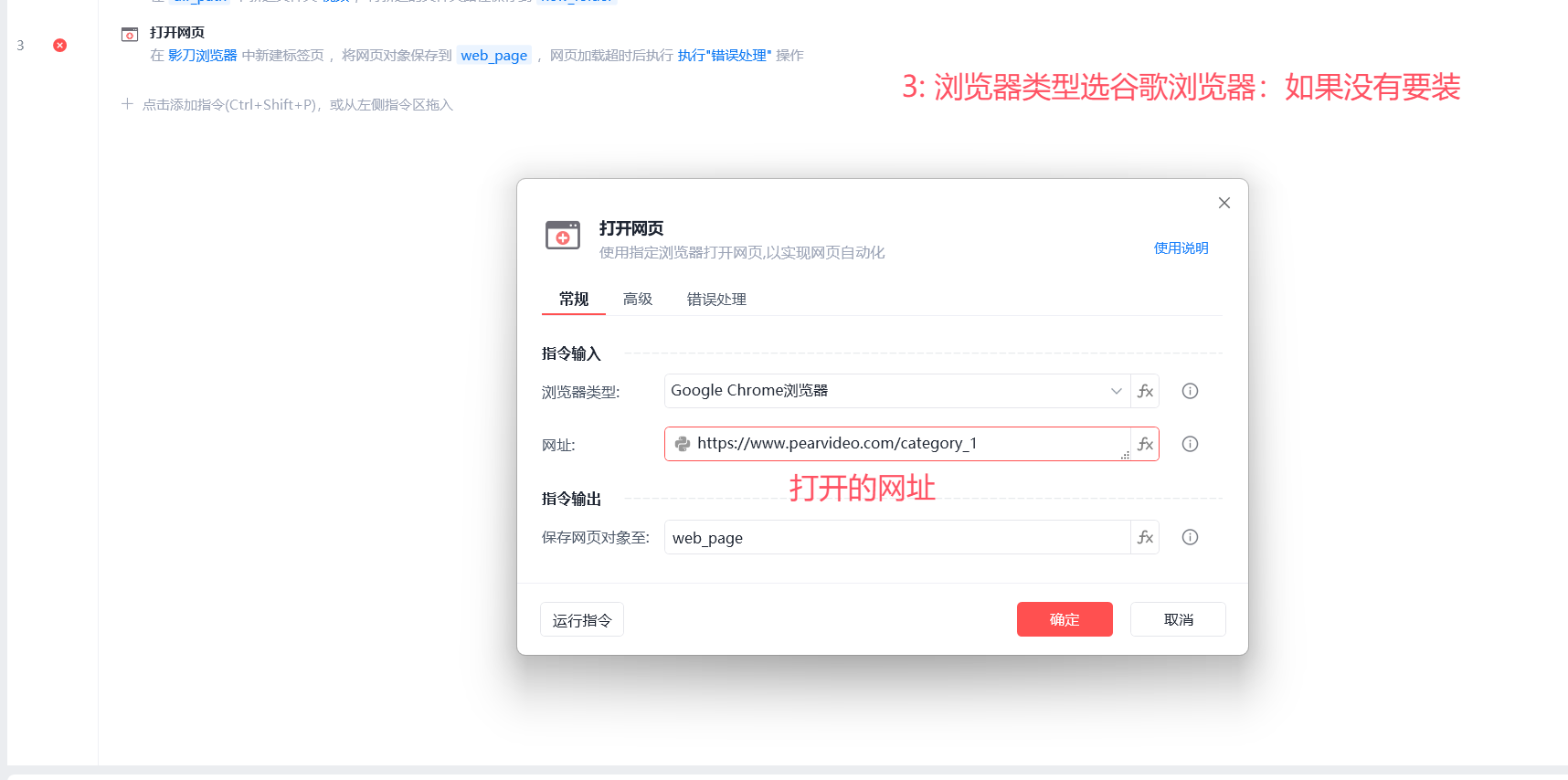
# 4 打开网页:第一次会提示装驱动
使用谷歌浏览器:跟我一致,如果没有谷歌浏览器,要先安装一个
需要装谷歌浏览器驱动:影刀自动操作谷歌浏览器需要这个扩展软件
# 5 安装驱动
https://www.yingdao.com/yddoc/rpa/710821364073103360
# 6 鼠标滚动
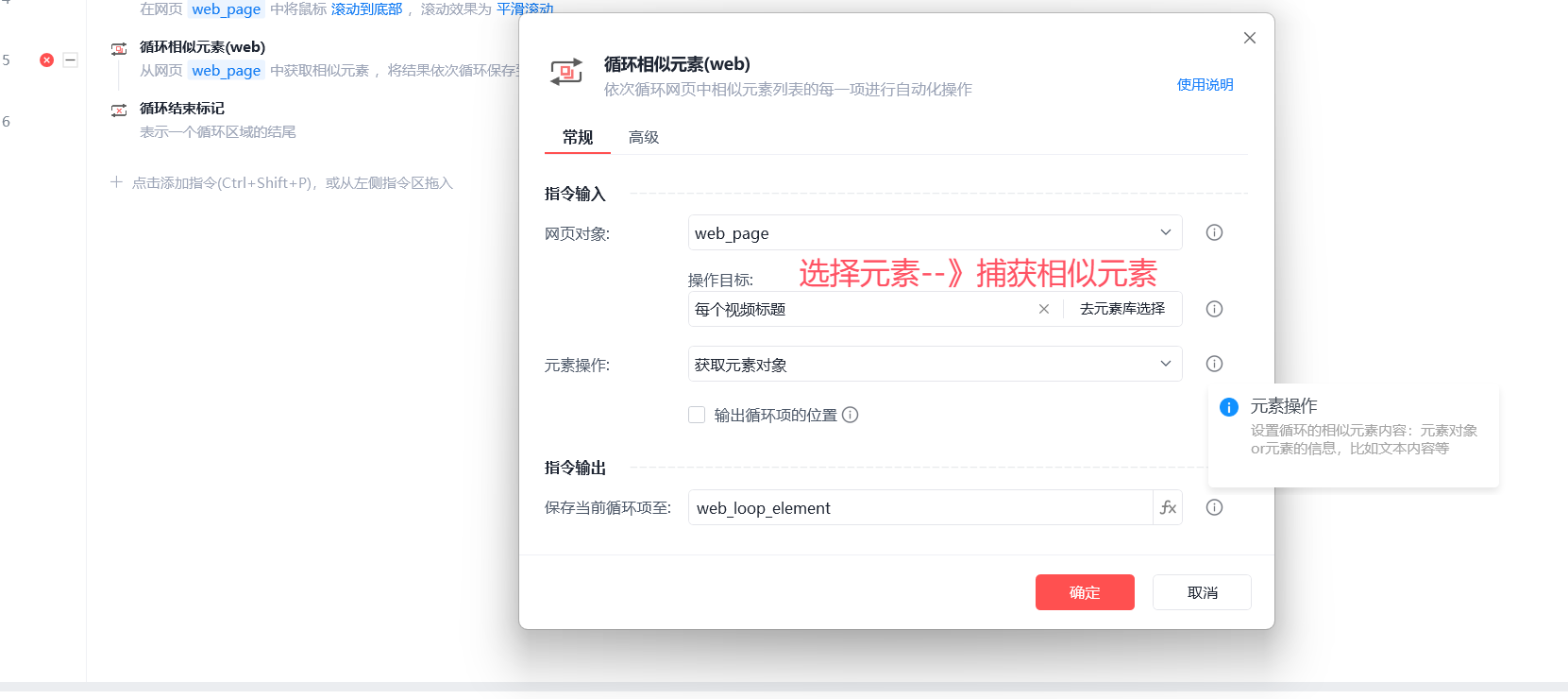
# 7 循环相似元素--》一定找到a标签
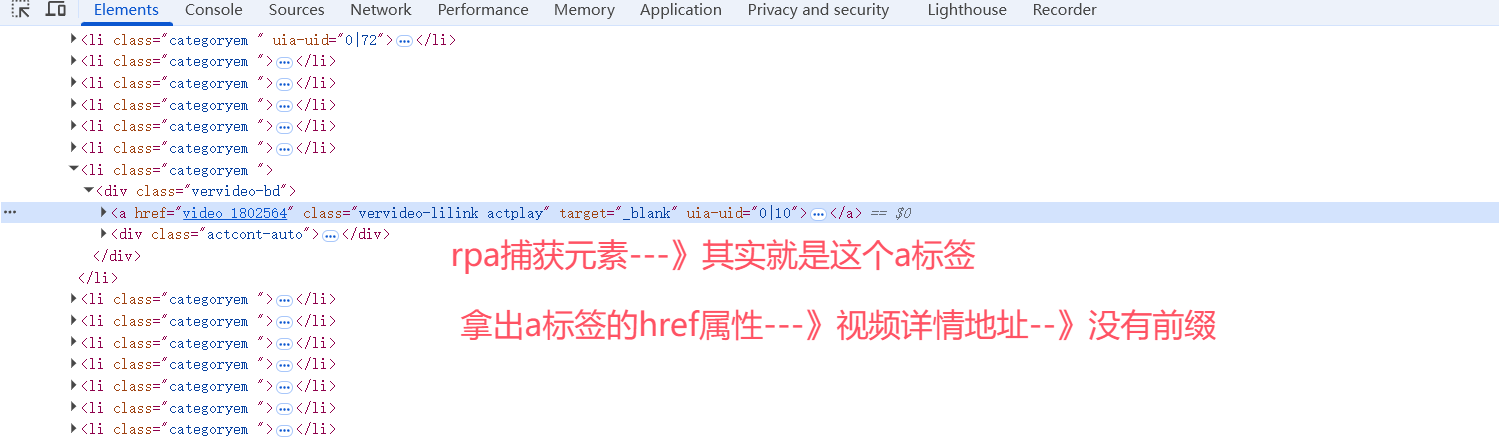
-捕获元素
-捕获相似元素--》把当前页面中所有一样的,都选出俩
-一个个循环它
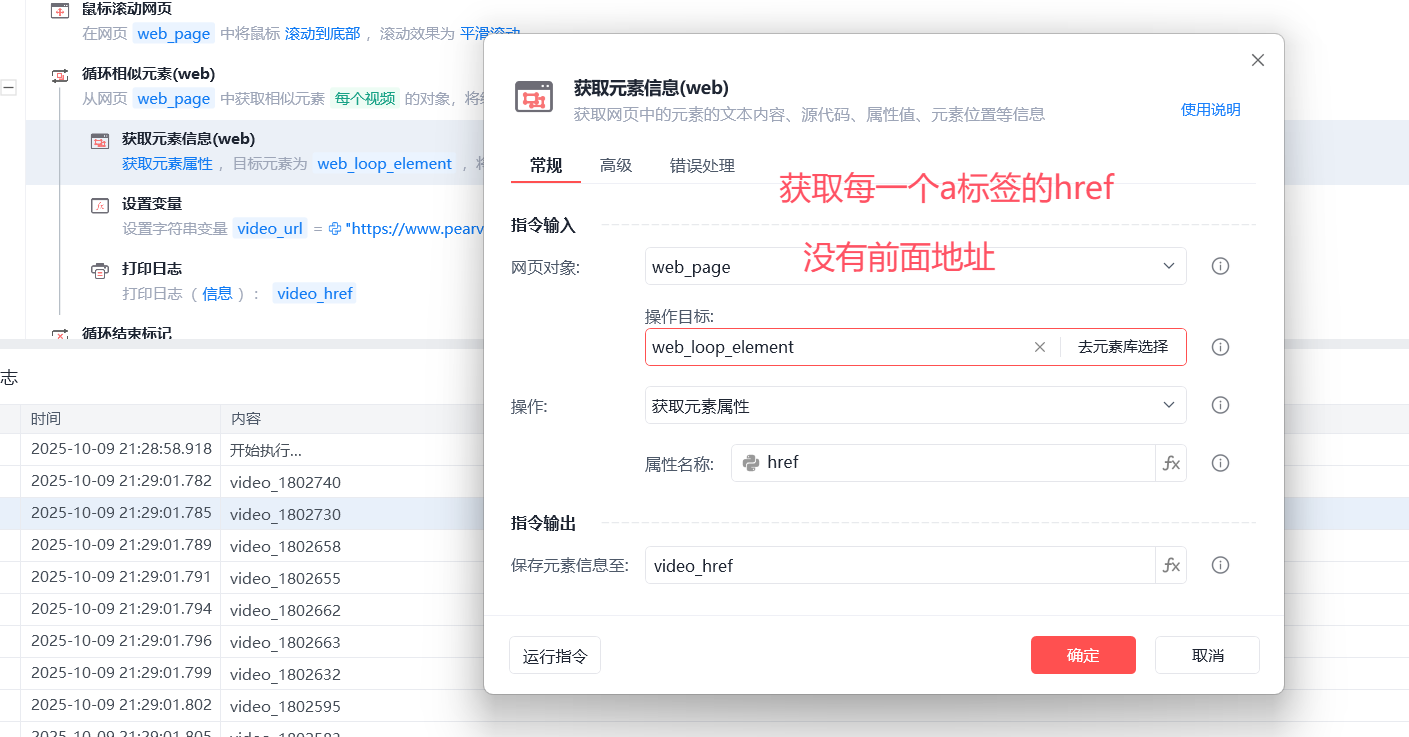
# 7.1 获取元素信息
-href信息
# 7.2 设置变量
-拼接上前面地址:https://www.pearvideo.com/+href信息
-变成这种地址:https://www.pearvideo.com/video_1802264
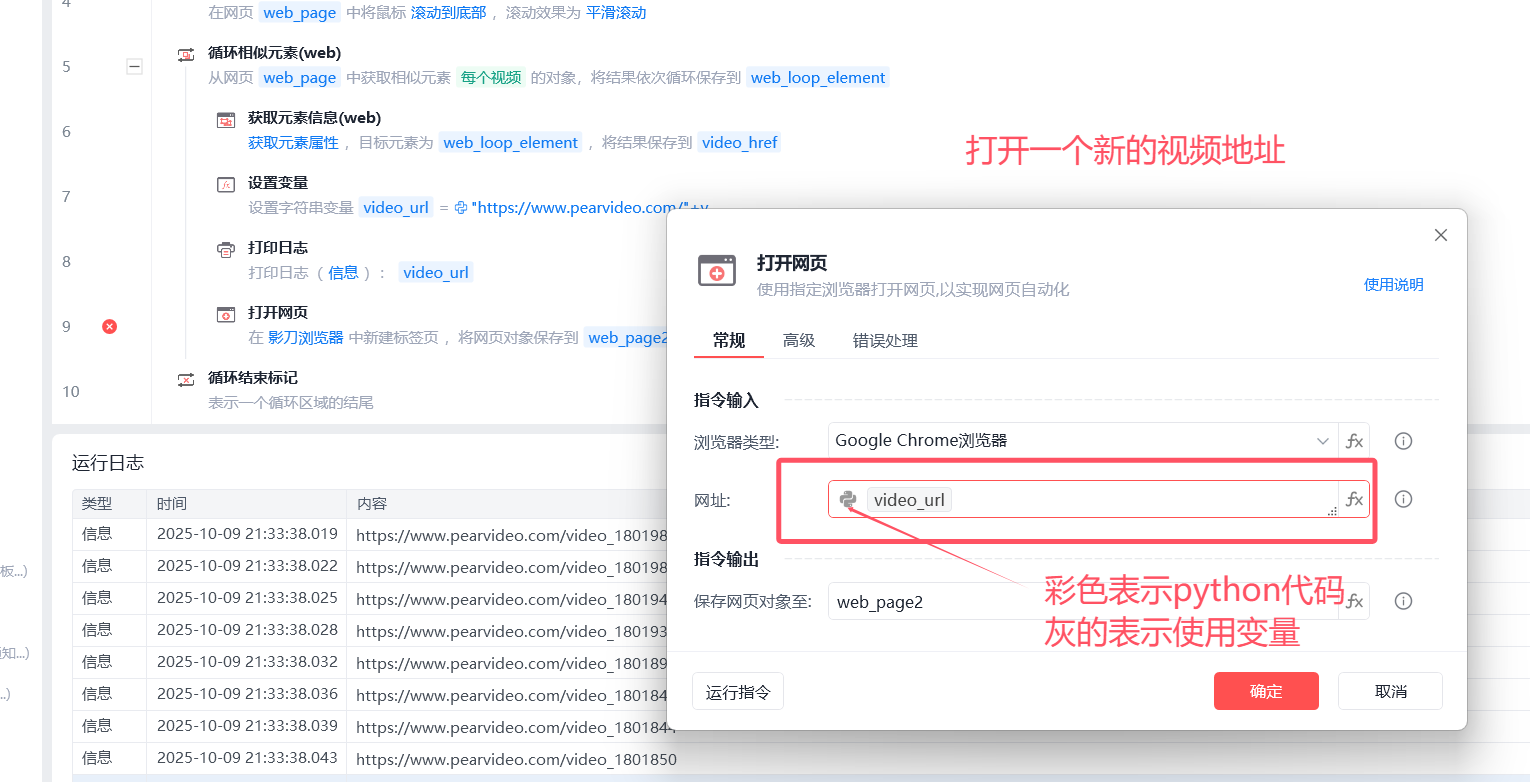
# 7.3 打开视频详情地址
-打开网页:选择网页地址为上面的变量
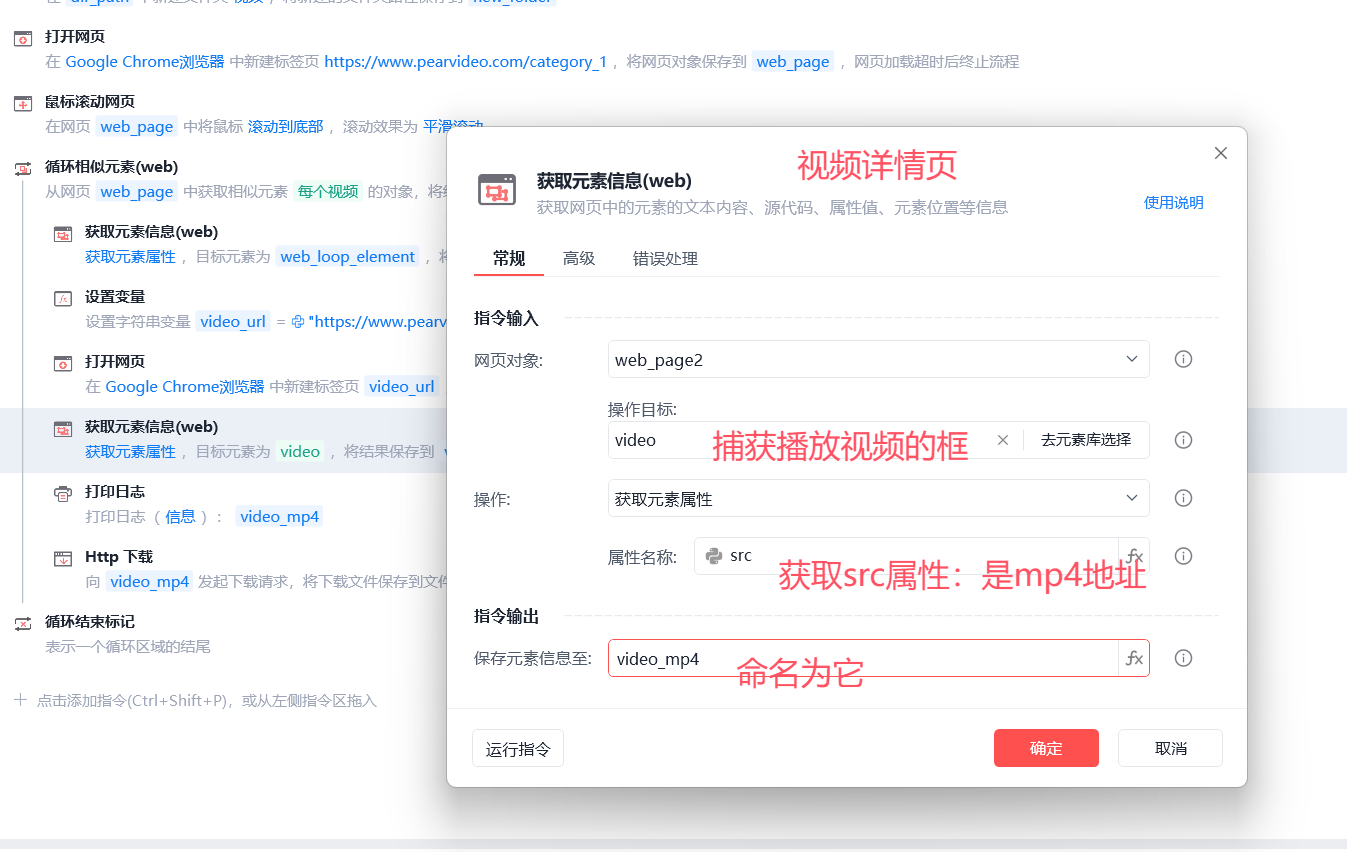
# 7.4 获取元素信息
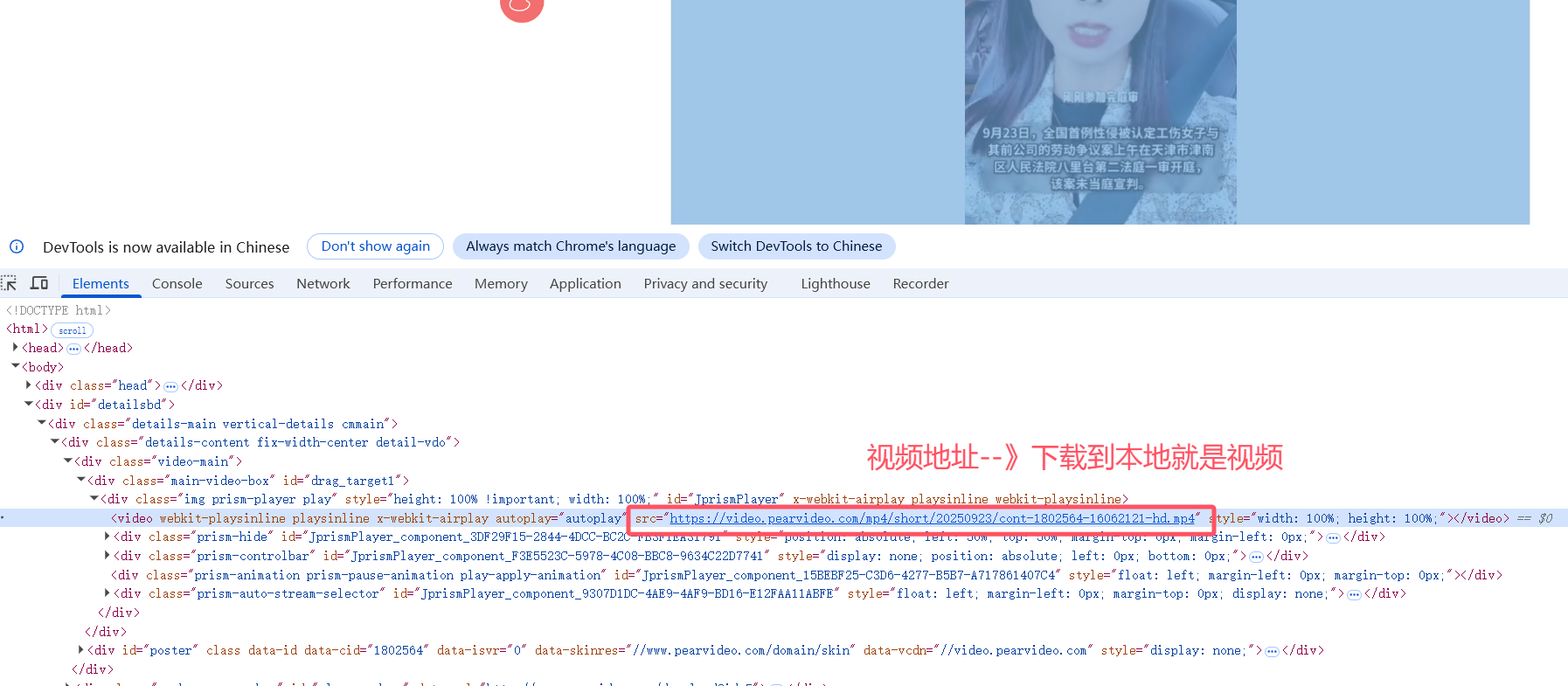
-获取video的src属性---》是mp4地址







4 下载视频优化
# 1 重新理一下过程
1 获取桌面地址[影刀提供给我们的]--》设置给一个变量:dir_path
-获取系统文件路径:桌面,下载地址,图片地址。。。。
2 创建文件夹---》设置给一个变量:new_folder
-创建文件夹:在 dir_path 下面创建
-父目录是:dir_path--》点击fx--》可以选
-新建文件夹名字:视频---》桌面创建出一个文件夹叫 视频
3 打开网页----》设置给一个变量:web_page
-使用谷歌浏览器
-装驱动:保证彩色的才可以用
-作用:后续我们选择元素,捕获元素用
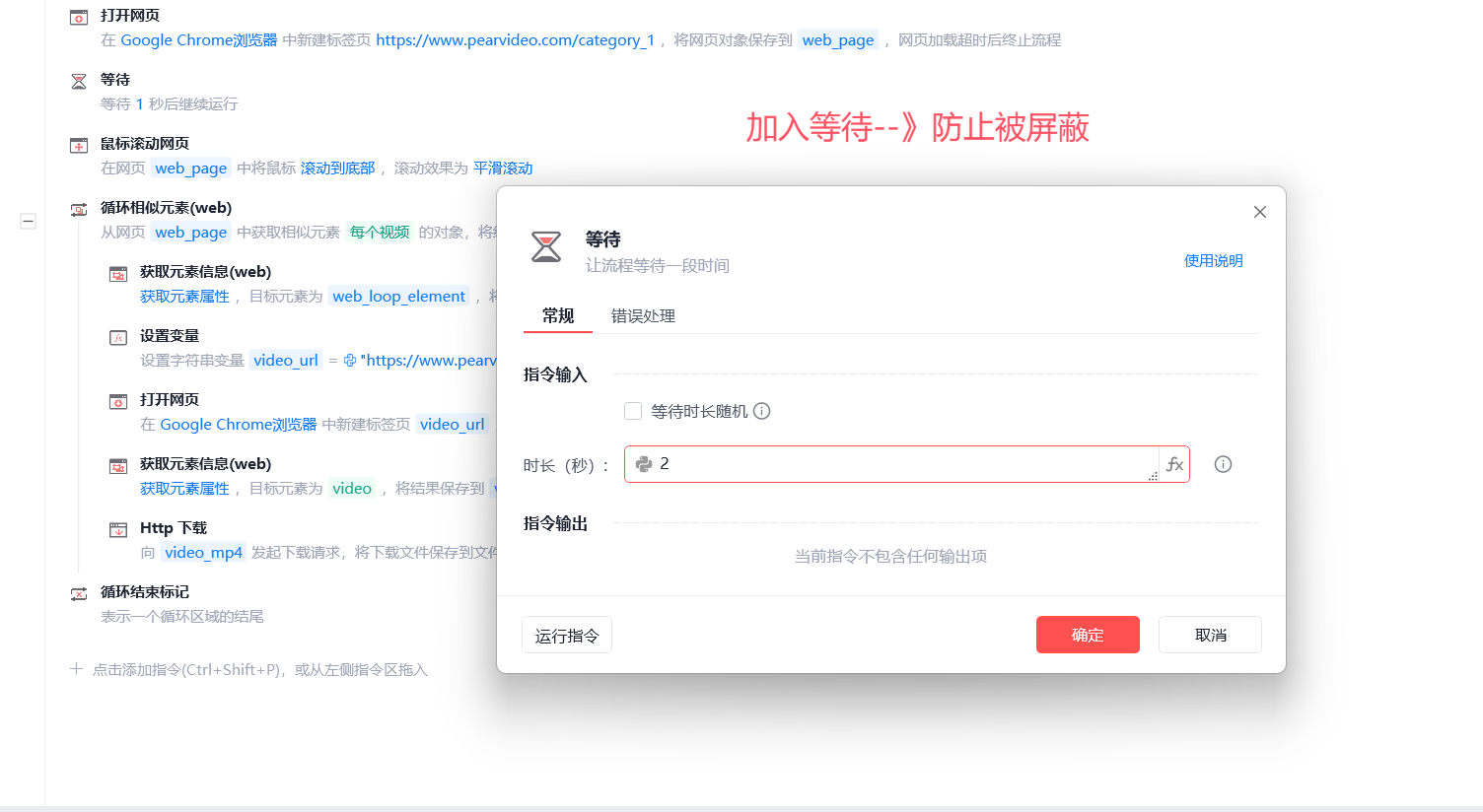
4 一打开就往下滑动网页--》太像机器了--》容易被对应的网址给记录--》不允许你访问
-等待2s
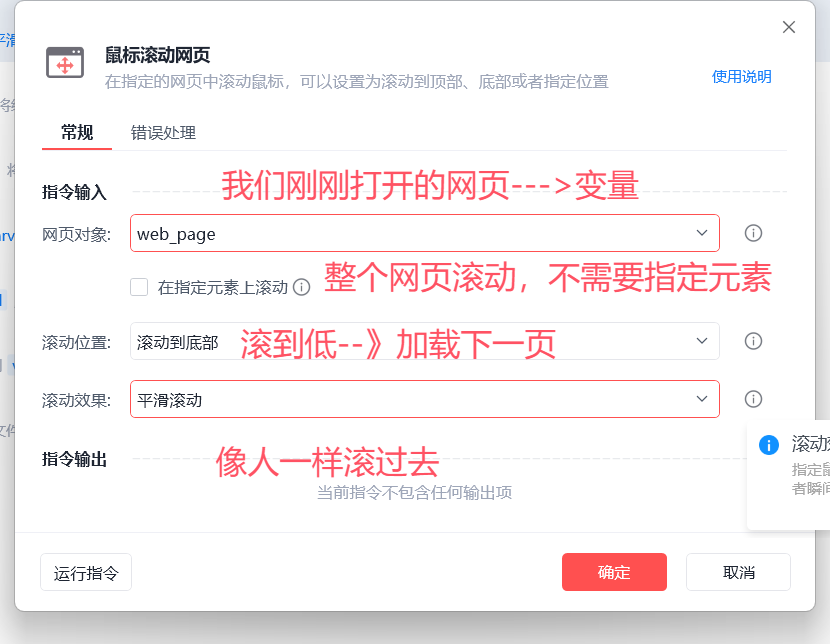
5 鼠标滚动网页
6 循环相似元素--》每一个元素的变量名:web_loop_element
-捕获相似元素
6.1 获取每个元素的 href属性--》a标签的href属性--》变量名:video_href--》video_1802564
-超链接---》点击可以跳转到另一个页面---》前端知识---》不需要了解
6.2 设置变量---》变量名:video_url
-由于a标签的href属性只有:video_1802564
-我们要拼成:https://www.pearvideo.com/video_1802564
-python代码:"https://www.pearvideo.com/"+video_href
6.3 打开网页:一个个视频--》这个在循环中--》设置给一个变量:web_page2
-打开地址:video_url
6.4 获取元素信息:获取视频地址:mp4---》video_mp4
-捕获video标签--》获取它的元素--》src
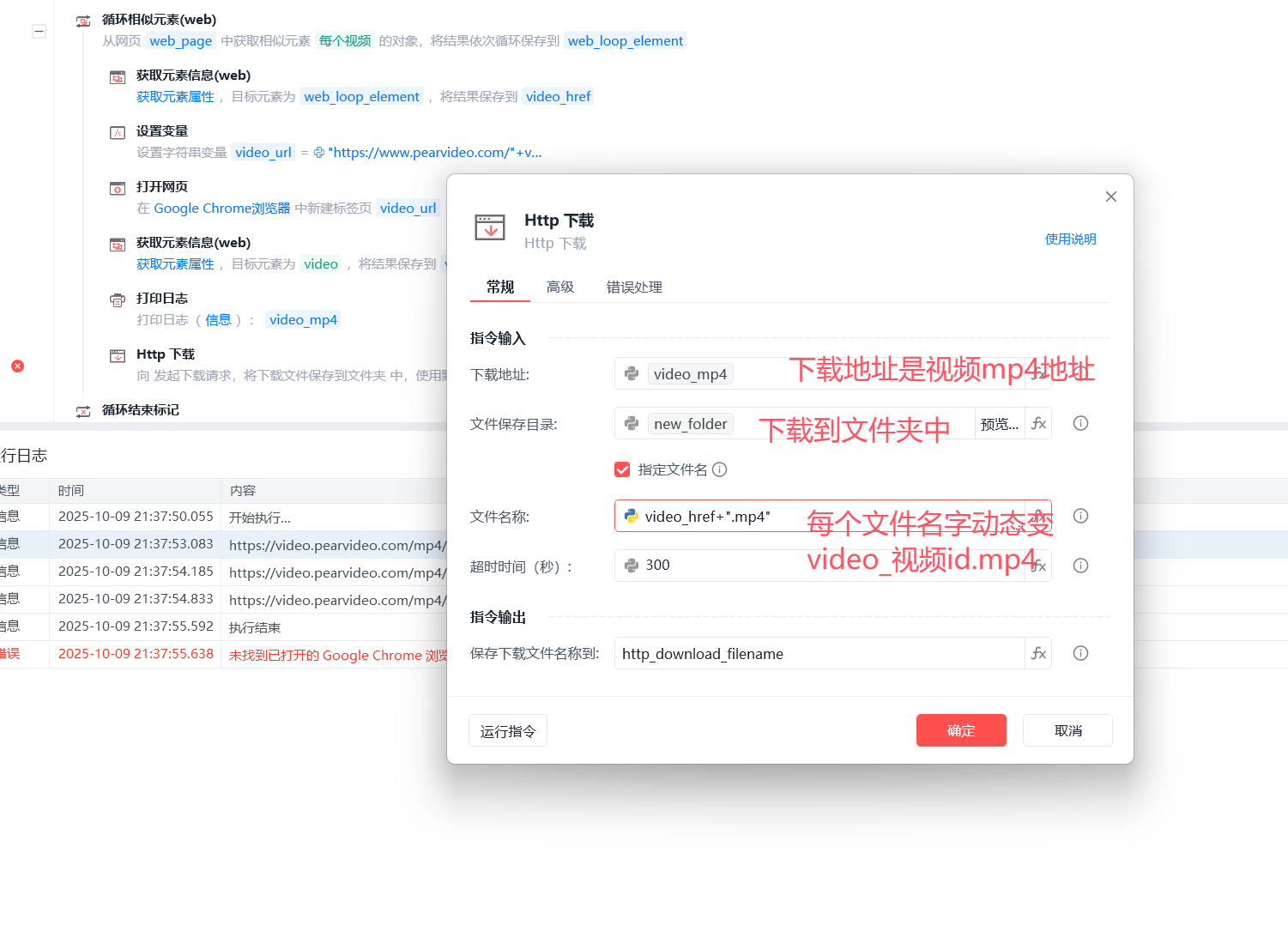
6.5 下载视频:http下载
-下载地址:video_mp4
-保存到:new_folder
-指定文件名:video_href+".mp4"
# 扩展----
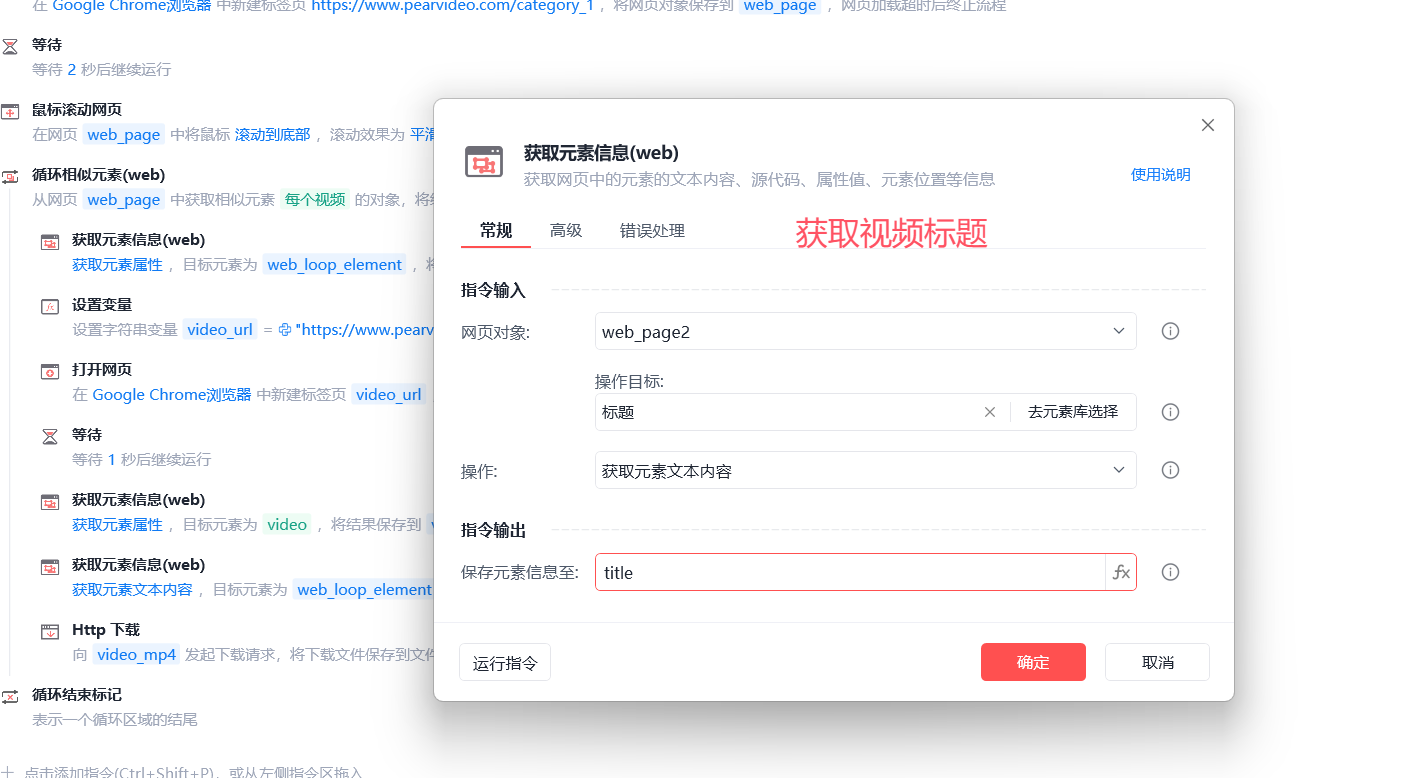
# 1 修改成 视频名字--》作为下载的视频名
-获取视频标题
-存在问题:特殊字符不能做名字
# 2 每次打开一个新的页面,为了防止反扒,都要等待1s


 浙公网安备 33010602011771号
浙公网安备 33010602011771号