day34大模型应用开发-模型本地部署
模型本地部署
模型本地部署主流方式
在AI技术快速迭代的2025年,大模型部署已成为开发者必须掌握的技能,如何针对不同需求选择最优部署方案,成为技术团队的核心挑战。下面我们系统梳理三大主流部署方案,涵盖个人开发、边缘计算、企业服务核心场景,助你精准匹配技术方案。
-
个人开发者首选:Ollama——量化模型管理神器
- 定位:个人PC/Mac本地快速部署
- 核心价值:开箱即用的模型管家
-
企业级服务引擎:vLLM——高并发生产部署
- 定位:百人以上团队API服务
- 核心价值:企业级高并发生产部署
-
全平台利器:LM Studio——跨设备开发桥接器
- 定位:个人开发者的瑞士军刀
- 突出特性:可视化模型实验室
Ollama部署
Ollama简介
目前市面上主流的,成本最低的部署本地大模型的方法就是通过 Ollama 了:Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。

核心功能:
- 简化部署:
Ollama简化了部署大型语言模型的过程,即使是非专业用户也能轻松管理和运行这些复杂的模型。 - 模型管理:支持多种流行的大型语言模型,如
Llama、Falcon等,并提供丰富的命令行工具。 - 模型定制:用户可以通过
Modelfile文件自定义模型参数和行为,实现模型的个性化设置。
技术优势:
- 轻量级与可扩展:
Ollama保持较小的资源占用,同时具备良好的可扩展性,允许用户根据硬件条件和项目需求进行优化。 - API 支持:提供简洁的 API 接口,方便开发者集成到各种应用程序中。
- 兼容
OpenAI接口:Ollama支持OpenAI的 API 标准,可以作为OpenAI的私有化部署方案。
使用场景:
- 本地开发:开发者可以在本地环境中快速部署和测试大型语言模型,无需依赖云端服务。
- 数据隐私保护:用户可以在本地运行模型,确保数据不离开本地设备,从而提高数据处理的隐私性和安全性。
- 多平台支持:
Ollama支持macOS、Windows、Linux以及Docker容器,具有广泛的适用性。
Ollama 的目标是让大型语言模型的使用更加简单、高效和灵活,无论是对于开发者还是终端用户。
Ollama 安装和使用
Ollama 的下载和安装非常简单,打开浏览器,访问 Ollama 官方网站:https://ollama.com/download,下载适用的安装包。
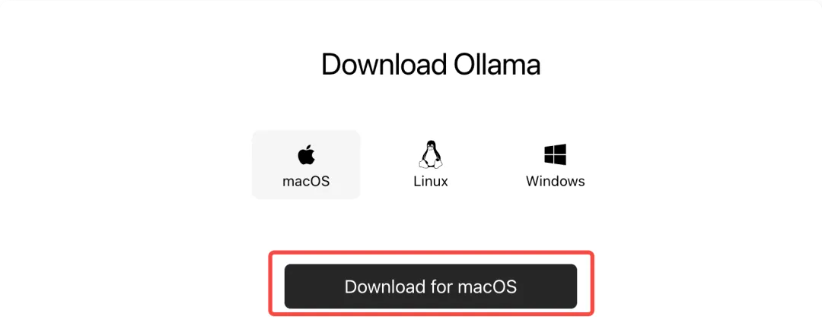
下载完成后,直接双击安装包并按照提示完成安装。
安装完成后,我们直接打开命令行执行 ollama --version 判断是否安装成功:

ollama 会在我们本地服务监听 11434 端口:
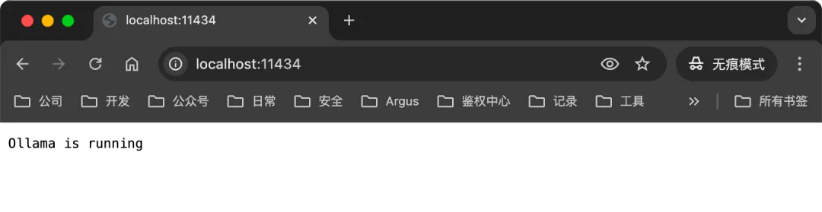
然后我们可以直接使用 ollama run 模型名称 来下载和运行我们想要的模型。
ollama 支持的模型列表,我们可以到 https://ollama.com/search 查看:
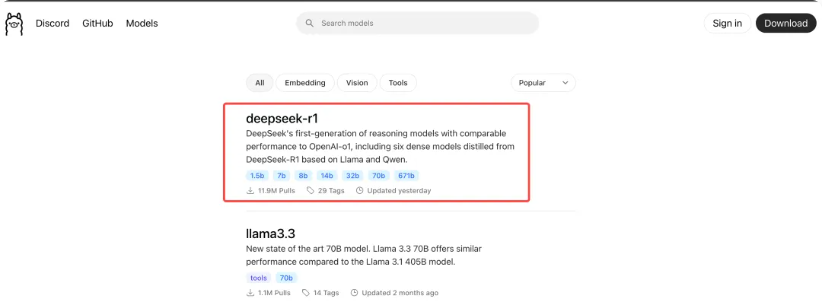
可以看到第一个支持的就是最近最火的 DeepSeek 模型,已经有接近 1200 万次下载了,另外 ollama 还支持下面这些主流模型:
| 模型名称 | 简介 |
|---|---|
| Llama | 由Meta开发的通用语言模型,擅长多种语言任务,如文本生成、问答等。Llama 3.1(8B参数)是其较受欢迎的版本之一,文件大小约4.7GB。 |
| Qwen | 阿里云推出的模型,具备强大的语言理解和生成能力。Qwen 2(7B参数)文件大小约4.4GB,适合多种应用场景。 |
| Gemma | 谷歌推出的模型,注重语言的准确性和逻辑性。Gemma 2(9B参数)文件大小约5.5GB,适合需要高精度的语言任务。 |
| Mistral | 以高效和性能平衡著称,适合资源有限的设备。Mistral(7B参数)文件大小约4.1GB。 |
| Phi | 专注于生成高质量文本,适合创意写作等任务。Phi 3(3.8B参数)文件大小约2.3GB。 |
| GLM | 智谱推出的模型,适合中文处理任务。GLM 4(9B参数)文件大小约5.5GB。 |
| CodeLlama | 专为代码生成和理解优化的模型,适合编程辅助等场景。CodeLlama(7B参数)文件大小约3.8GB。 |
| LLaVA | 结合视觉和语言能力的模型,适合多模态任务。LLaVA(7B参数)文件大小约4.5GB。 |
在模型详情页我们可以看到目前支持的模型的不同版本,包括每个模型展用的磁盘大小:注意这里不是说你磁盘有这么大就够了,如llama3.1虽然8b 的模型大小是 4.7GB,但是至少需要 8GB 显存才能正常使用。
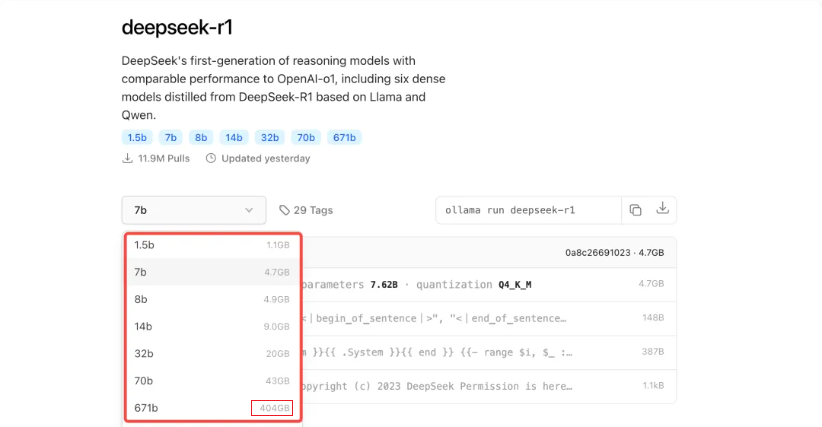
然后,直接在控制台使用 ollama run 模型名称 来下载我们想要的模型就可以了:


模型文件存储位置
Ollama 模型默认存储在以下路径:
- Linux/Mac:
~/.ollama/models/ - Windows:
C:\Users\<用户名>\.ollama\models
目前我们已经拥有了一个基础的本地模型,但是这种交互方式太不友好了,下面我们通过一些工具来提升我们本地模型的使用体验。
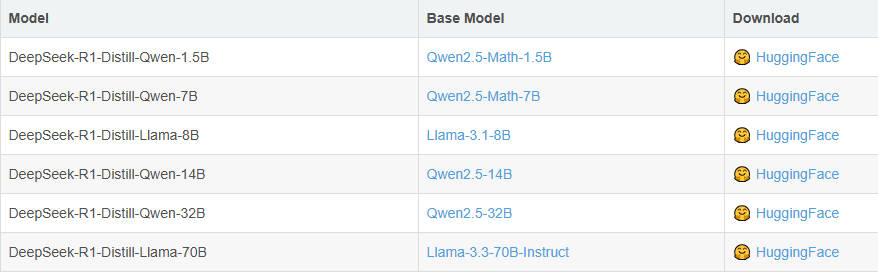
deepseek蒸馏模型
在deepseek的R系列模型中还提供了6种基于Qwen和Llama的蒸馏版本,显著提升小模型性能。这六个蒸馏小模型是DeepSeek-R1-Distill-Qwen系列(包括1.5B、7B、14B、32B)和DeepSeek-R1-Distill-Llama系列(包括8B、70B)。
蒸馏模型是一种通过将复杂、大型模型(称为教师模型)的知识迁移到一个更小、更简单的模型(称为学生模型)中,以实现模型压缩和加速推理的技术。在DeepSeek系列中,就是将R1系列大模型作为教师模型,通过特定的蒸馏方法,把知识传递给基于Qwen和Llama系列构建的学生模型。其原理是:
通过模仿教师模型的输出,训练一个较小的学生模型,从而实现知识的传递。在训练过程中,首先利用训练数据集让教师模型生成针对输入数据的响应,这些输出结果构成了后续学生模型训练的重要参考数据。然后,学生模型以此为基础进行微调,通过优化自身的参数,使其尽可能地学习和模仿教师模型的行为模式和决策逻辑,从而实现知识从教师模型到学生模型的迁移。在此过程中,学生模型不断调整自身的内部结构和参数值,以适应从教师模型传递过来的知识和经验,逐步提升自身的性能表现
具体来说,DeepSeek的蒸馏过程是通过使用R1生成的80w个推理数据样本,对较小的基础模型(例如Qwen和Llama系列)进行微调而创建的。尽管规模变小,但这些蒸馏版本仍保留了较强的推理能力。因为它们继承了R1大模型的知识和推理模式,所以在一些推理任务上能够取得不错的成绩。
意义和作用
- 降低部署门槛:蒸馏后的轻量级模型能够在资源受限的设备上运行,如移动设备、边缘计算设备等,大大扩展了AI技术的应用范围。
- 提升运行效率:小型模型具有更快的推理速度和更低的能耗,这对于需要实时响应的应用场景尤为重要。
- 个性化定制:蒸馏技术使得模型能够针对特定场景进行优化,满足不同应用的具体需求。
DeepSeek-R1部署方案
伴随着DeepSeek R1模型使用需求不断深化,如何才能部署更高性能的满血版DeepSeek R1模型,就成了很多应用场景下的当务之急。受限于DeepSeek R1 671B(6710亿参数)的模型规模,通常情况下部署DeepSeek R1满血版模型需要1200G-1400G左右显存(考虑百人内并发情况),也就是需要60块4090或者18块A100的显卡才能够顺利运行(总成本约在260万-320万左右)。哪怕是在半精度的情况下,实际测试下来也需要占用490G的显存,也就是需要24块4090或者7块A100才能够顺利运行(总成本约在120万至240万左右)。
在此情况下,如何以更少的成本获得尽可能好的模型性能——也就是如果进行DeepSeek R1的高性能部署,就成了重中之重。基本来说,目前的解决方案有以下2种:
第一种:采用“强推理、若训练”的硬件配置:
如选择国产芯片、或者采购DeepSeek一体机、甚至是选择MacMini集群等,都是不错的选择。这些硬件模型训练性能较弱,但推理能力强悍,对于一些不需要进行模型训练和微调、只需要推理(也就是对话)的场景来说,是个非常不错的选择。
例如,45万左右成本,就能购买能运行DeepSeek R1满血版模型的Mac Mini集群,相比购买英伟达显卡,能够节省很大一部分成本。但劣势在于Mac M系列芯片并不适合进行模型训练和微调。

第二种:采用DeepSeek R1 Distill蒸馏模型:
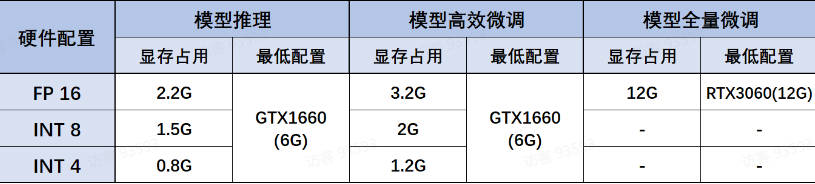
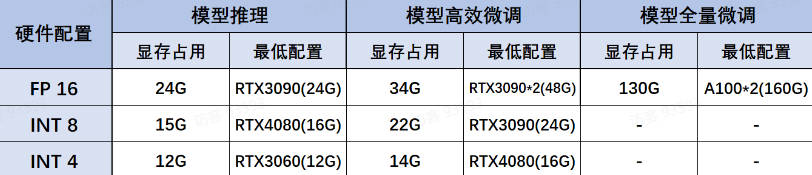
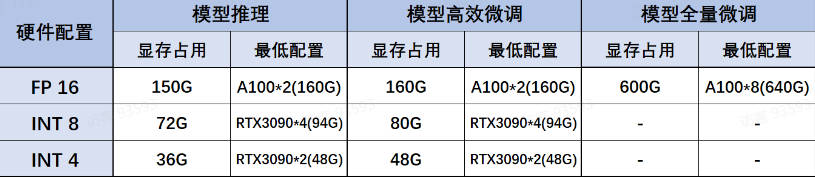
DeepSeek R蒸馏模型组同样推理性能不俗,且蒸馏模型尺寸在1.5B到70B之间,可以适配于任何硬件环境和各类不同的使用需求。其中各蒸馏模型、各量化版本、各不同使用场景(如模型推理、模型高效微调和全量微调)下模型所需最低配置如下:
-
Deepseek-R1-Distill-Qwen-1.5B:
- 性能指数:2颗星,推理能力达到GPT-4o级别
- 适用场景:移动端应用或者个人助理
-
Deepseek-R1-Distill-Qwen-7B
- 性能指数:3颗星,推理能力达到o1-mini的70%左右
- 适用场景:高校实验室或者小型团队适用

-
Deepseek-R1-Distill-Qwen-14B
- 性能指数:4颗星,推理能力达到o1-mini的80%左右
- 适用场景:适用于一般商业场景
-
Deepseek-R1-Distill-Qwen-32B
- 性能指数:5颗星,推理能力达到o1-mini性能级别
- 适用场景:适用于高性能要求的商业场景

-
Deepseek-R1-Distill-Llama-8B
- 性能指数:3颗星,推理能力达到o1-mini的70%左右
- 适用场景:高校实验室或者小型团队适用

-
Deepseek-R1-Distill-Llama-70B
- 性能指数:5颗星,推理能力达到o1-mini的性能级别
- 适用场景:适用于高性能要求的商业场景
CherryStudio+Ollama
第一步:先下载安装一个CherryStudio
这个是我个人最推荐的零基础入门大模型首选的客户端,相比OpenWebUI、AnythingLLM等CherryStudio安装部署简单、页面简洁美观、各种功能齐全,并且还是最先支持MCP的客户端,可以说是零基础搭建专属智能体的不二之选了。
CherryStudio官网链接:https://docs.cherry-ai.com/
CherryStudio适用于Windows、macOS以及Linux三种操作环境,你可以根据自己的环境选择合适的安装包。
注意:如果第一次在使用Cherry Studui的时候出现uv 和 bun未安装的话,可以手动下载安装:

下载路径:
下载成功后,将下载的文件存放在如下目录中:
-
Windows:
C:\Users\用户名\.cherrystudio\bin -
macOS、Linux:
~/.cherrystudio/bin
第二步:获取大模型API-Key
CherryStudio可以接入各种不同类型的大模型,包括国外的OpenAI、Gemini等公司的大模型,国内的智谱、深度求索等公司的大模型,同时兼容通过 Ollama 部署的本地大模型。功能很强大!
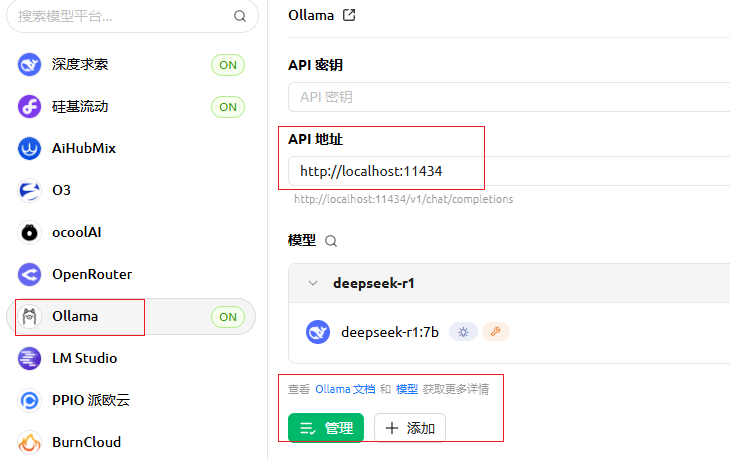
调用ollama推理服务
ollama serve服务启动后,我们可以使用代码调用 ollama 提供的 API 进行推理。
from openai import OpenAI
client = OpenAI(api_key="sk-33333", base_url="http://localhost:11434/v1/")
messages=[
{"role": "system", "content": "你是一个乐于助人的体育界专家。"},
{"role": "user", "content": "请问,9.8和9.11哪个更大?"},
]
data = client.chat.completions.create(
model="deepseek-r1:7b",
stream=False,
messages=messages
)
print(data.choices[0].message)
本地模型多轮对话:
from openai import OpenAI
# 实例化客户端
client = OpenAI(api_key="whatever", base_url="http://localhost:11434/v1/")
def multi_chat_with_model(msg): #msg表示用户提出的问题
text = '张三,男,1990年10月25日出生于中国台湾省高雄市。\
2013年毕业于北京工业大学的信息工程专业,由于在校表现良好,毕业后被中科院信息技术部破格录取。'
messages=[
{"role": "system", "content": text},
{"role": "user", "content": msg}
]
while True:
response = client.chat.completions.create(
model="deepseek-r1:7b",
messages=messages
)
# 获取模型回答
answer = response.choices[0].message.content
print(f"模型回答: {answer}")
# 询问用户是否还有其他问题
user_input = input("您还有其他问题吗?(输入退出以结束对话): ")
if user_input == "退出":
break
# 记录用户回答
messages.append({"role": "assistant", "content": answer})
messages.append({"role": "user", "content": user_input})
#多轮对话测试
multi_chat_with_model('张三哪一年毕业的?')
Ollama ModelFile(模型文件)
Modelfile 是 Ollama 的配置文件,用于定义和自定义模型的行为。通过它,你可以:
- 调整生成参数(如温度、重复惩罚)
- 添加系统级提示(
SYSTEM指令) - 等等
新建 Modelfile:创建一个文本文件(如 my-model.Modelfile),写入配置。
ollama create model_name -f ./my-model.Modelfile
# 基础模型(必须)
FROM <模型名>
# 系统提示(定义模型的默认行为)
SYSTEM """
你是一个专业的 Python 程序员,回答需包含代码示例,并用中文解释。
"""
# 调整生成参数
PARAMETER temperature 0.7 # 控制随机性(0-1,越高越有创意)
PARAMETER num_ctx 4096 # 上下文窗口大小
PARAMETER num_predict 512 # 最大生成长度
# 模板(控制对话格式)
TEMPLATE """{{ .System }}
{{ .Prompt }}"""
运行模型:
ollama run model_name
vLLm本地部署(重点)
简介
vLLM(Verbally Language Model)是伯克利大学LMSYS组织开源的大语言模型高速推理框架,旨在极大地提升实时场景下的语言模型服务的吞吐量与内存使用效率。它利用了全新的注意力算法,从而在性能上实现了显著的提升。简单来讲,vLLM是一个快速且易于使用的库,用于进行大型语言模型的推理和部署。
vLLM安装过程相对复杂,需要用户具备一定的技术基础。它依赖于Python环境,并需要通过pip进行安装。此外,vLLM还提供了CUDA版本,以支持GPU加速。
vLLM和Ollama在部署大模型时各有优劣。选择哪种工具取决于具体的需求和场景。如果需要一个简单易用、快速部署的解决方案,并且对推理速度要求不高,那么Ollama可能是一个不错的选择。而如果追求高性能的推理和灵活的配置选项,并且具备一定的技术基础,那么vLLM可能更适合。
部署过程
安装Python环境
需要安装 Python3.9或以上的开发环境。
下载Deepseek模型
我们需要下载 DeepSeek-R1-Distill-Qwen-7B 或者 DeepSeek-R1-Distill-Qwen-1.5B 模型。可以在国内的“魔塔社区”https://modelscope.cn/models进行模型搜索和下载。

魔塔社区作为一个开源的模型服务共享平台,为AI开发者提供了丰富多样的资源和工具,极大地促进了AI技术的普及和应用。
模型数量多且领域广:首批上架模型超过300个,覆盖视觉、语音、自然语言处理、多模态等AI主要领域,任务覆盖超过60个,包含150多个SOTA(业界领先)模型和十多个大模型。
支持多种操作:提供简洁高效的模型服务及算力平台,支持模型微调、部署、推理及应用搭建。
安装ModelScope包ModelScope 是一个模型中心,我们使用它来下载模型。在终端或命令提示符中执行以下命令安装 ModelScope Python 包: pip install modelscope
下载模型: 使用 modelscope download 命令下载模型:
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir E:\deepseek-7b
下载指令解释:
--model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B: 指定要下载的模型为 deepseek-ai/DeepSeek-R1-Distill-Qwen-7B。
--local_dir your_local_path: 指定模型下载后保存的本地路径。请将 your_local_path 替换为您电脑上实际想要保存模型的路径。 例如,如果您想将模型保存在 /home/user/models/deepseek-7b 目录下
deepseek-ai/DeepSeek-R1-Distill-Qwen-7B 模型文件较大,请确保您的磁盘空间足够 (至少预留 15GB 以上空间)。
安装vLLM
模型下载完成后,我们需要安装 vLLM。为了避免不同 Python 项目之间的包冲突,建议您使用 Python 虚拟环境来安装 vLLM。在终端或命令提示符中,切换到您希望创建虚拟环境的目录,并执行以下命令:
conda create -n myenv python=3.11
这将在当前目录下创建一个名为 myenv 的虚拟环境。然后激活虚拟环境后,您的终端或命令提示符前会显示 (myenv),表示您已进入虚拟环境:
conda activate <环境名称>
在激活的虚拟环境中,执行以下命令安装 vLLM:pip install vllm
使用vLLM启动推理任务
现在,我们可以使用 vLLM 启动推理服务。假设您将模型下载到 /home/user/models/deepseek-7b 目录。则可以基于如下指令启动vLLM服务:
vllm serve /home/user/models/deepseek-7b --port 8102 --max-model-len 16384
指令解释:
/home/user/models/deepseek-7b: 模型文件夹路径。
--port 8102: 服务端口号。 8102 是服务启动后监听的端口。您可以根据需要修改端口号,例如 --port 8000。在后续代码调用中,需要使用相同的端口号。
--max-model-len 16384: 模型最大上下文长度。 16384 表示模型处理的最大输入序列长度。您可以根据您的 GPU 显存大小和需求调整此参数。对于 deepseek-ai/DeepSeek-R1-Distill-Qwen-7B 模型,16384 是一个较大的上下文长度。您可以尝试减小此值以减少显存占用,例如 --max-model-len 8192 或更小。
观察终端输出,如果看到类似 INFO: Started server process 和 INFO: Uvicorn running on ... 的信息,则表示 vLLM 服务启动成功。
调用vLLM推理服务
服务启动后,我们可以使用代码调用 vLLM 提供的 API 进行推理。
from openai import OpenAI
# 配置 OpenAI API 密钥和 Base URL 以连接 vLLM 服务
openai_api_key = "EMPTY"# vLLM 服务不需要 API 密钥,可以使用任意字符串
openai_api_base = "http://127.0.0.1:8102/v1"# 请确保端口号与您启动 vLLM 服务时设置的端口号一致
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
messages=[
{"role": "system", "content": "你是一个乐于助人的体育界专家。"},
{"role": "user", "content": "请问,9.8和9.11哪个更大?"},
]
data = client.chat.completions.create(
#本都大模型存储的文件夹名字
model="deepseek-1.5b",
stream=False,
messages=messages
)
print(data.choices[0].message)
LM Studio
简介
LM Studio 功能比 ollama 更强一些,而且有 UI 界面可以直接使用,更适合新手小白。因此,更加推荐大家尝试和使用这个软件去部署本地大模型。LM Studio集成了:
- 模型下载与管理
- 本地推理(CPU / GPU)
- 可视化聊天界面
- OpenAI 接口兼容 API 服务
LM Studio 的优势

LM Studio 适合谁
| 用户类型 | 适用理由 |
|---|---|
| AI 初学者 | 图形界面操作,无需编程即可使用 |
| 开发者 | 替代 GPT 用于插件、代码补全 |
| 安全敏感行业 | 全本地运行,数据不出内网 |
| 学术研究人员 | 快速部署、测试多种大模型 |
| 企业技术团队 | 低成本构建私有 LLM 服务平台 |
下载安装
官网:lmstudio.ai/ 同样,找到对应的版本,直接下载就可以了。

下载完成后同样会显示一个图标,直接点开登录就可以。

选择等级:
模型下载:

启动推理
启动本地API:
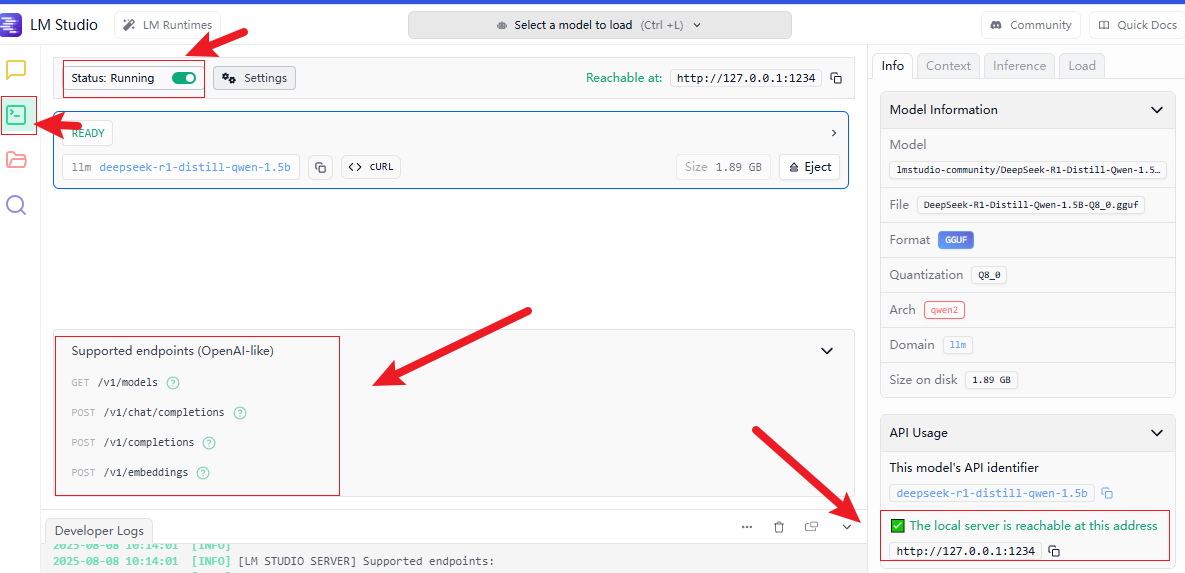
推理服务代码:
import requests
def query_model(prompt):
url = "http://localhost:1234/v1/chat/completions"
headers = {
"Content-Type": "application/json"
}
data = {
"model": "deepseek-r1-distill-qwen-1.5b",
"messages": [
{"role": "user", "content": prompt}
],
"temperature": 0.7,
"top_p": 0.95
}
response = requests.post(url, json=data, headers=headers)
return response.json()
# 使用示例
result = query_model("什么是网络空间安全?")
print(result['choices'][0]['message']['content'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号